HBase 进阶
参考来源: B站尚硅谷HBase2.x
目录
- Master 架构
- RegionServer 架构
- 写流程
- MemStore Flush
- 读流程
- HFile 结构
- 读流程
- 合并读取数据优化
- StoreFile Compaction
- Region Split
- 预分区(自定义分区)
- 系统拆分
Master 架构
Master详细架构
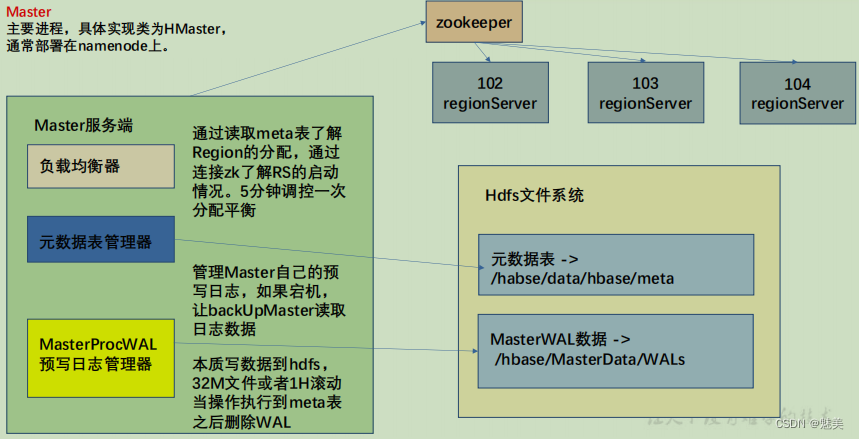
- 1)Meta 表格介绍:(警告:不要去改这个表)
全称 hbase:meta,只是在 list 命令中被过滤掉了,本质上和 HBase 的其他表格一样。
RowKey:
([table],[region start key],[region id]) 即 表名,region 起始位置和 regionID。
列:
info:regioninfo 为 region 信息,存储一个 HRegionInfo 对象。
info:server 当前 region 所处的 RegionServer 信息,包含端口号。
info:serverstartcode 当前 region 被分到 RegionServer 的起始时间。
如果一个表处于切分的过程中,即 region 切分,还会多出两列 info:splitA 和 info:splitB,存储值也是 HRegionInfo 对象,拆分结束后,删除这两列。
注意:在客户端对元数据进行操作的时候才会连接 master,如果对数据进行读写,直接连接zookeeper 读取目录/hbase/meta-region-server 节点信息,会记录 meta 表格的位置。直接读取即可,不需要访问 master,这样可以减轻 master 的压力,相当于 master 专注 meta 表的写操作,客户端可直接读取 meta 表。
在 HBase 的 2.3 版本更新了一种新模式:Master Registry。客户端可以访问 master 来读取meta 表信息。加大了 master 的压力,减轻了 zookeeper 的压力。
RegionServer 架构
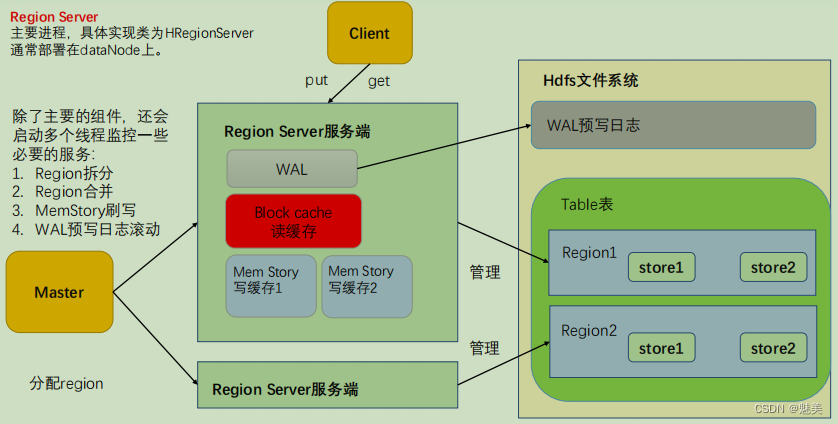
- 1)MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile,写入到对应的文件夹 store 中。 - 2)WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。 - 3)BlockCache
读缓存,每次查询出的数据会缓存在 BlockCache 中,方便下次查询。
写流程
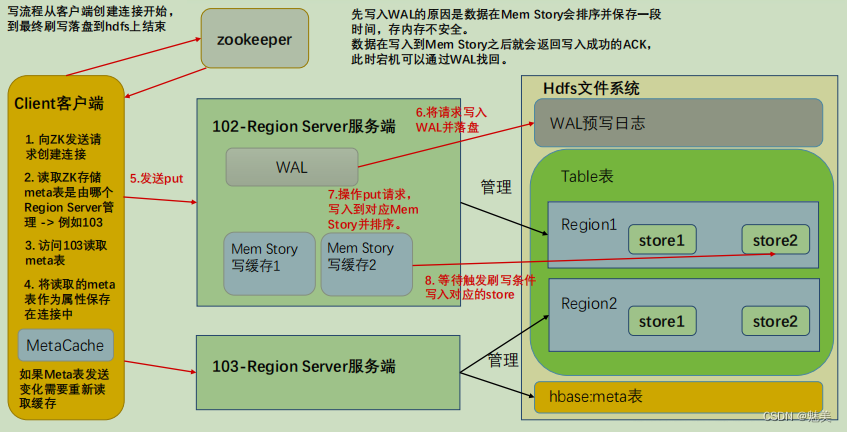
- 写流程:
写流程顺序正如 API 编写顺序,首先创建 HBase 的重量级连接
(1)首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
(2)访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢;
之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
(3)调用Table的put方法写入数据,此时还需要解析RowKey,对照缓存的MetaCache,查看具体写入的位置有哪个 RegionServer;
(4)将数据顺序写入(追加)到 WAL,此处写入是直接落盘的,并设置专门的线程控制 WAL 预写日志的滚动(类似 Flume);
(5)根据写入命令的 RowKey 和 ColumnFamily 查看具体写入到哪个 MemStory,并且在 MemStory 中排序;
(6)向客户端发送 ack;
(7 )等达到 MemStore 的刷写时机后,将数据刷写到对应的 story 中。
MemStore Flush
MemStore 刷写由多个线程控制,条件互相独立:
主要的刷写规则是控制刷写文件的大小,在每一个刷写线程中都会进行监控
(1)当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),
其所在 region 的所有 memstore 都会刷写。
当 memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值 128M)
* hbase.hregion.memstore.block.multiplier(默认值 4)
时,会刷写同时阻止继续往该 memstore 写数据(由于线程监控是周期性的,所以有可能面对数据洪峰,尽管可能性比较小)
(2)由 HRegionServer 中的属性 MemStoreFlusher 内部线程 FlushHandler 控制。标准为LOWER_MARK(低水位线)和 HIGH_MARK(高水位线),意义在于避免写缓存使用过多的内
存造成 OOM
当 region server 中 memstore 的总大小达到低水位线
java_heapsize
*hbase.regionserver.global.memstore.size(默认值 0.4)
*hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),
region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server中所有 memstore 的总大小减小到上述值以下。
当 region server 中 memstore 的总大小达到高水位线
java_heapsize
*hbase.regionserver.global.memstore.size(默认值 0.4)
时,会同时阻止继续往所有的 memstore 写数据。
(3)为了避免数据过长时间处于内存之中,到达自动刷写的时间,也会触发 memstore flush。由 HRegionServer 的属PeriodicMemStoreFlusher 控制进行,由于重要性比较低,5min才会执行一次。
自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认
1 小时)。
(4)当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到hbase.regionserver.max.log 以下(该属性名已经废弃,现无需手动设置,最大值为 32)。
读流程
HFile 结构
在了解读流程之前,需要先知道读取的数据是什么样子的。
HFile 是存储在 HDFS 上面每一个 store 文件夹下实际存储数据的文件。里面存储多种内容。包括数据本身(keyValue 键值对)、元数据记录、文件信息、数据索引、元数据索引和一个固定长度的尾部信息(记录文件的修改情况)。键值对按照块大小(默认 64K)保存在文件中,数据索引按照块创建,块越多,索引越大。每一个 HFile 还会维护一个布隆过滤器(就像是一个很大的地图,文件中每有一种 key,就在对应的位置标记,读取时可以大致判断要 get 的 key 是否存在 HFile 中)。
KeyValue 内容如下:
rowlength -----------→ key 的长度
row -----------------→ key 的值
columnfamilylength --→ 列族长度
columnfamily --------→ 列族
columnqualifier -----→ 列名
timestamp -----------→ 时间戳(默认系统时间)
keytype -------------→ Put
由于 HFile 存储经过序列化,所以无法直接查看。可以通过 HBase 提供的命令来查看存储在 HDFS 上面的 HFile 元数据内容。
[jjm@hadoop102 hbase]$ bin/hbase hfile -m -f /hbase/data/命名空间/表名/regionID/列族/HFile 名
读流程
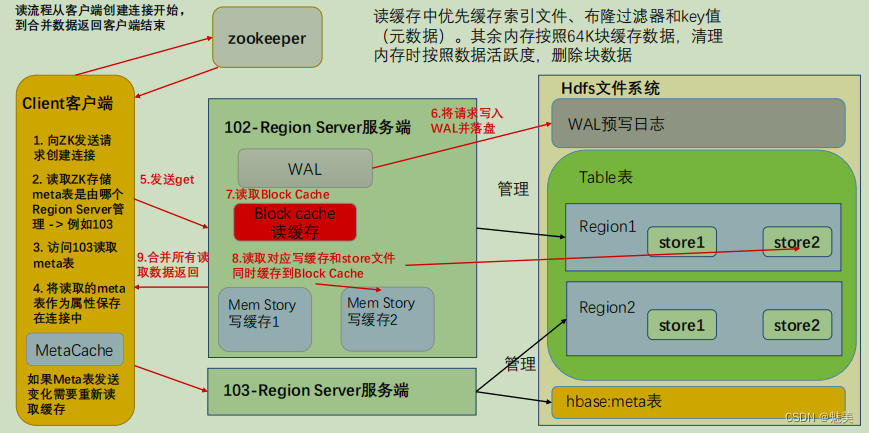
创建连接同写流程。
(1)创建 Table 对象发送 get 请求。
(2)优先访问 Block Cache,查找是否之前读取过,并且可以读取 HFile 的索引信息和布隆过滤器。
(3)不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和store 中的文件。
(4)最终将所有读取到的数据合并版本,按照 get 的要求返回即可。
合并读取数据优化
每次读取数据都需要读取三个位置,最后进行版本的合并。效率会非常低,所有系统需要对此优化。
(1)HFile 带有索引文件,读取对应 RowKey 数据会比较快。
(2)Block Cache 会缓存之前读取的内容和元数据信息,如果 HFile 没有发生变化(记录在 HFile 尾信息中),则不需要再次读取。
(3)使用布隆过滤器能够快速过滤当前 HFile 不存在需要读取的RowKey,从而避免读取文件。(布隆过滤器使用 HASH 算法,不是绝对准确的,出错会造成多扫描一个文件,对读取数据结果没有影响)
StoreFile Compaction
由于 memstore 每次刷写都会生成一个新的 HFile,文件过多读取不方便,所以会进行文件的合并,清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction会将临近的若干个较小的 HFile 合并成一个较大的 HFile,并清理掉部分过期和删除的数据,有系统使用一组参数自动控制,Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉所有过期和删除的数据,由参数 hbase.hregion.majorcompaction控制,默认 7 天。
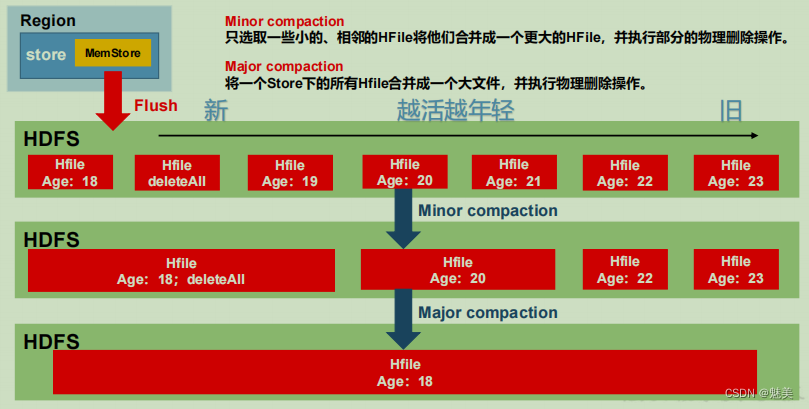
Minor Compaction 控制机制:
参与到小合并的文件需要通过参数计算得到,有效的参数有 5 个
(1)hbase.hstore.compaction.ratio(默认 1.2F)合并文件选择算法中使用的比率。
(2)hbase.hstore.compaction.min(默认 3) 为 Minor Compaction 的最少文件个数。
(3)hbase.hstore.compaction.max(默认 10) 为 Minor Compaction 最大文件个数。
(4)hbase.hstore.compaction.min.size(默认 128M)为单个 Hfile 文件大小最小值,小于这个数会被合并。
(5)hbase.hstore.compaction.max.size(默认 Long.MAX_VALUE)为单个 Hfile 文件大小最大值,高于这个数不会被合并。
小合并机制为拉取整个 store 中的所有文件,做成一个集合。之后按照从旧到新的顺序遍历。
判断条件为:
① 过小合并,过大不合并
② 文件大小/ hbase.hstore.compaction.ratio < (剩余文件大小和) 则参与压缩。所有把比值设置过大,如 10 会最终合并为 1 个特别大的文件,相反设置为 0.4,会最终产生 4 个 storeFile。不建议修改默认值
③ 满足压缩条件的文件个数达不到个数要求(3 <= count <= 10)则不压缩。
Region Split
Region 切分分为两种,创建表格时候的预分区即自定义分区,同时系统默认还会启动一个切分规则,避免单个 Region 中的数据量太大。
预分区(自定义分区)
每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个 region 维护的rowKey 范围,则该数据交给这个 region 维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高 HBase 性能。
1)手动设定预分区
create 'staff1','info', SPLITS => ['1000','2000','3000','4000']
2)生成 16 进制序列预分区
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO =>
'HexStringSplit'}
3)按照文件中设置的规则预分区
(1)创建 splits.txt 文件内容如下:
aaaa
bbbb
cccc
dddd
(2)然后执行:
create 'staff3', 'info',SPLITS_FILE => 'splits.txt'
4)使用 JavaAPI 创建预分区
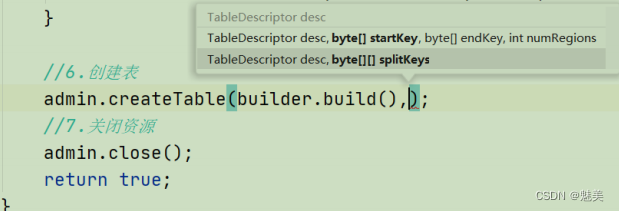
package com.jjm.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseConnect {public static void main(String[] args) throws IOException {// 1.获取配置类Configuration conf = HBaseConfiguration.create();// 2.给配置类添加配置conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");// 3.获取连接Connection connection = ConnectionFactory.createConnection(conf);// 4.获取 adminAdmin admin = connection.getAdmin();// 5.获取 descriptor 的 builderTableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf("bigdata", "staff4"));// 6. 添加列族builder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info")).build());// 7.创建对应的切分byte[][] splits = new byte[3][];splits[0] = Bytes.toBytes("aaa");splits[1] = Bytes.toBytes("bbb");splits[2] = Bytes.toBytes("ccc");// 8.创建表admin.createTable(builder.build(),splits);// 9.关闭资源admin.close();connection.close();}
}
系统拆分
Region 的拆分是由 HRegionServer 完成的,在操作之前需要通过 ZK 汇报 master,修改对应的 Meta 表信息添加两列 info:splitA 和 info:splitB 信息。之后需要操作 HDFS 上面对应的文件,按照拆分后的 Region 范围进行标记区分,实际操作为创建文件引用,不会挪动数据。刚完成拆分的时候,两个 Region 都由原先的 RegionServer 管理。之后汇报给Master,由Master将修改后的信息写入到Meta表中。等待下一次触发负载均衡机制,才会修改Region的管理服务者,而数据要等到下一次压缩时,才会实际进行移动。
不管是否使用预分区,系统都会默认启动一套 Region 拆分规则。不同版本的拆分规则有差别。系统拆分策略的父类为 RegionSplitPolicy。
0.94 版本之前 => ConstantSizeRegionSplitPolicy
( 1 ) 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过hbase.hregion.max.filesize (10G),该 Region 就会进行拆分。
0.94 版本之后,2.0 版本之前 => IncreasingToUpperBoundRegionSplitPolicy
( 2 ) 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该 Region 就会进行拆分。其中 initialSize 的默认值为 2*hbase.hregion.memstore.flush.size,R 为当前 Region Server 中属于该 Table 的Region 个数(0.94 版本之后)。
具体的切分策略为:
第一次 split:1^3 * 256 = 256MB
第二次 split:2^3 * 256 = 2048MB
第三次 split:3^3 * 256 = 6912MB
第四次 split:4^3 * 256 = 16384MB > 10GB,因此取较小的值 10GB
后面每次 split 的 size 都是 10GB 了。
2.0 版本之后 => SteppingSplitPolicy
(3)Hbase 2.0 引入了新的 split 策略:如果当前 RegionServer 上该表只有一个 Region,按照 2 * hbase.hregion.memstore.flush.size 分裂,否则按照 hbase.hregion.max.filesize 分裂。这叫大道至简,学海抽丝。
相关文章:
HBase 进阶
参考来源: B站尚硅谷HBase2.x 目录 Master 架构RegionServer 架构写流程MemStore Flush读流程HFile 结构读流程合并读取数据优化 StoreFile CompactionRegion Split预分区(自定义分区)系统拆分 Master 架构 Master详细架构 1)Meta 表格介…...
一周学会Django5 Python Web开发-Django5路由命名与反向解析reverse与resolve
锋哥原创的Python Web开发 Django5视频教程: 2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计25条视频,包括:2024版 Django5 Python we…...

好奇!为什么gateway和springMVC之间依赖冲突?
Gateway和SpringMVC之间存在冲突,可能是因为它们分别基于不同的技术栈。具体来说: 技术栈差异:Spring Cloud Gateway 是建立在 Spring Boot 2.x 和 Spring WebFlux 基础之上的,它使用的是非阻塞式的 Netty 服务器。而 Spring MVC…...

一些内网渗透总结
windows命令收集 信息收集: 查看系统版本和补丁信息: systeminfo 查看系统开放端口: netstat -ano 查看系统进程: tasklist /svc 列出详细进程: tasklist /V /FO CSV 查看ip地址和dns信息: ipconfig /all 查看当前用户: whoami /user 查看计算机用户列表: net user 查看计算机…...
C#版字节跳动SDK - SKIT.FlurlHttpClient.ByteDance
前言 在我们日常开发工作中对接第三方开放平台,找一款封装完善且全面的SDK能够大大的简化我们的开发难度和提高工作效率。今天给大家推荐一款C#开源、功能完善的字节跳动SDK:SKIT.FlurlHttpClient.ByteDance。 项目官方介绍 可能是全网唯一的 C# 版字…...

深度学习系列60: 大模型文本理解和生成概述
参考网络课程:https://www.bilibili.com/video/BV1UG411p7zv/?p98&spm_id_frompageDriver&vd_source3eeaf9c562508b013fa950114d4b0990 1. 概述 包含理解和分类两大类问题,对应的就是BERT和GPT两大类模型;而交叉领域则对应T5 2.…...

SpringBoot 使用 JWT 保护 Rest Api 接口
用 spring-boot 开发 RESTful API 非常的方便,在生产环境中,对发布的 API 增加授权保护是非常必要的。现在我们来看如何利用 JWT 技术为 API 增加授权保护,保证只有获得授权的用户才能够访问 API。 一、Jwt 介绍 JSON Web Token (JWT)是一个开…...

大蟒蛇(Python)笔记(总结,摘要,概括)——第10章 文件和异常
目录 10.1 读取文件 10.1.1 读取文件的全部内容 10.1.2 相对文件路径和绝对文件路径 10.1.3 访问文件中的各行 10.1.4 使用文件的内容 10.1.5 包含100万位的大型文件 10.1.6 圆周率中包含你的生日吗 10.2 写入文件 10.2.1 写入一行 10.2.2 写入多行 10.3 异常 10.3.1 处理Ze…...
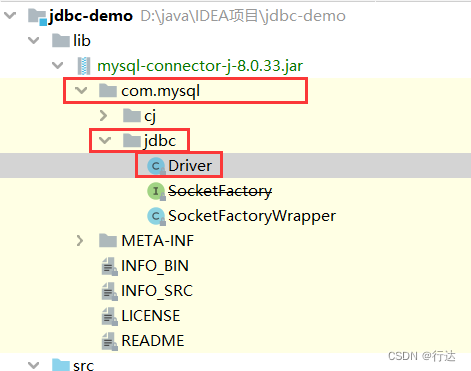
使用JDBC操作数据库(IDEA编译器)
目录 JDBC的本质 JDBC好处 JDBC操作MySQL数据库 1.创建工程导入驱动jar包 2.编写测试代码 相关问题 JDBC的本质 官方(sun公司) 定义的一套操作所有关系型数据库的规则,即接口各个数据库厂商去实现这套接口,提供数据库驱动jar包我们可以使用这…...
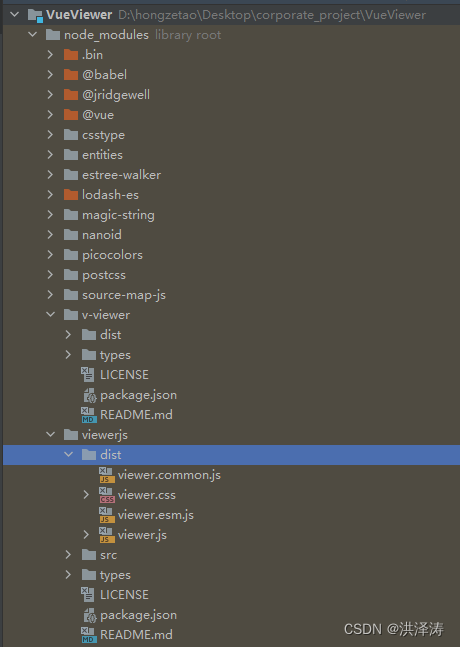
Vue图片浏览组件v-viewer,支持旋转、缩放、翻转等操作
Vue图片浏览组件v-viewer,支持旋转、缩放、翻转等操作 之前用过viewer.js,算是市场上用过最全面的图片预览。v-viewer,是基于viewer.js的一个图片浏览的Vue组件,支持旋转、缩放、翻转等操作。 基本使用 安装:npm安装…...

大蟒蛇(Python)笔记(总结,摘要,概括)——第2章 变量和简单的数据类型
目录 2.1 运行hello_world.py时发生的情况 2.2 变量 2.2.1 变量的命名和使用 2.2.2 如何在使用变量时避免命名错误 2.2.3 变量是标签 2.3 字符串 2.3.1 使用方法修改字符串的大小写 2.3.2 在字符串中使用变量 2.3.3 使用制表符或换行符来添加空白 2.3.4 删除空白 2.3.5 删除…...
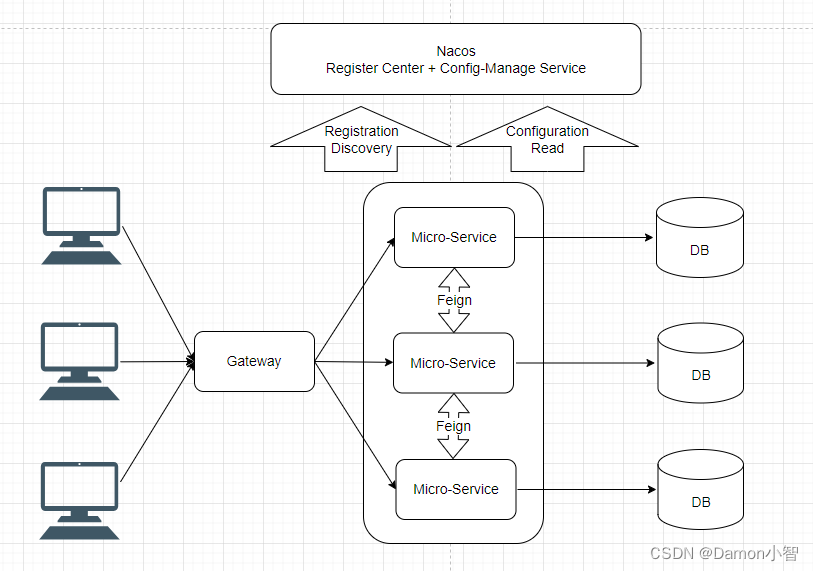
SpringCloud-Gateway网关的使用
本文介绍如何再 SpringCloud 项目中引入 Gateway 网关并完成网关服务的调用。Gateway 网关是一个在微服务架构中起到入口和路由控制的关键组件。它负责处理客户端请求,进行路由决策,并将请求转发到相应的微服务。Gateway 网关还可以实现负载均衡、安全认…...

想要学习编程,有什么推荐的书籍吗
如果你要变得更好,C语言是一个极佳的选择,其原因有二。首先,C语言缺乏任何现代的安全功能,这意味着你必须更为警惕,时刻了解真正发生的事情。如果你能写出安全、健壮的C代码,那你就能用任何编程语言写出安全…...

LWM(LargeWorldModel)大世界模型-可文字可图片可视频-多模态LargeWorld-视频问答成功运行-实现循环问答多次问答
Large World Model(LWM)现在大火,其最主要特点是不仅能够针对文本进行检索交互,还能对图片、视频进行问答交互,自从上文《LWM(LargeWorldModel)大世界模型-可文字可图片可视频-多模态LargeWorld-详细安装记录》发出后&…...

线阵相机之帧超时
1 帧超时的效果 在帧超时时间内相机若未采集完一张图像所需的行数,则相机会直接完成这张图像的采集,并自动将缺失行数补黑出图,机制有以下几种选择: 1. 丢弃整张补黑的图像 2. 保留补黑部分出图 3.丢弃补黑部分出图...

模型转换案例学习:等效替换不支持算子
文章介绍 Qualcomm Neural Processing SDK (以下简称SNPE)支持Caffe、ONNX、PyTorch和TensorFlow等不同ML框架的算子。对于某些特定的不支持的算子,我们介绍一种算子等效替换的方法来完成模型转换。本案例来源于https://github.com/quic/qidk…...

js 数组排序的方式
var numberList [5, 100, 94, 71, 49, 36, 2, 4]; 冒泡排序: 相邻的数据进行两两比较,小数放在前面,大数放在后面,这样一趟下来,最小的数就被排在了第一位,第二趟也是如此,如此类推࿰…...
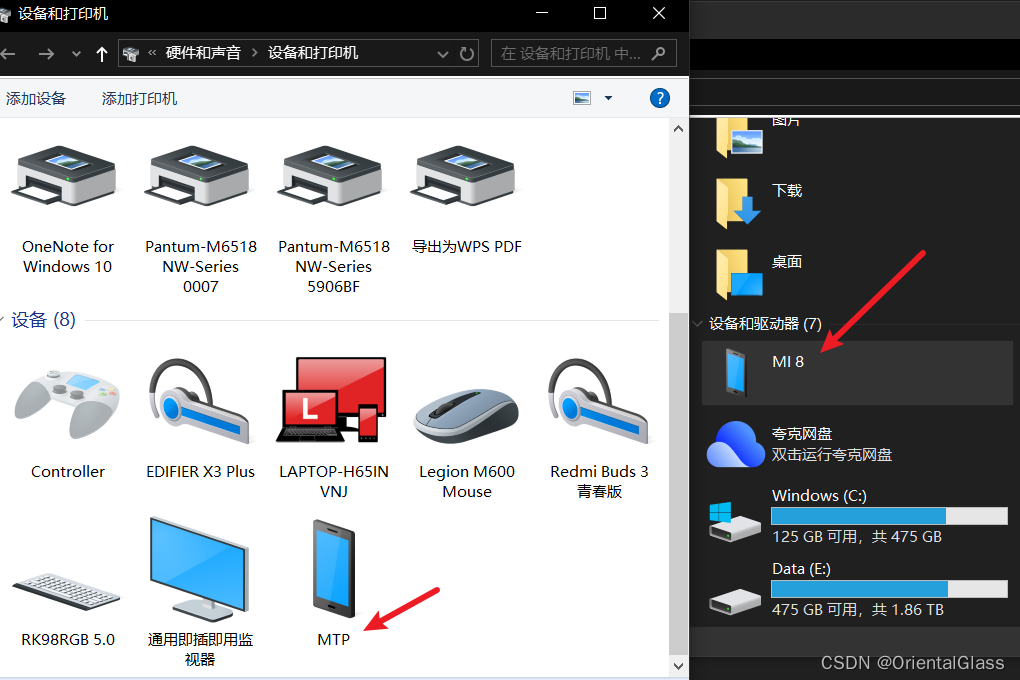
手机连接电脑后资源管理器无法识别(识别设备但无法访问文件)
问题描述 小米8刷了pixel experience系统,今天用电脑连接后无法访问手机文件,但是手机选择了usb传输模式为文件传输 解决办法 在设备和打印机页面中右键选择属性 点击改变设置 卸载驱动,注意勾选删除设备的驱动程序软件 卸载后重新连接手机,电脑弹出希望对设备进行什么操作时…...
安装unget包 sqlsugar时报错,完整的报错解决
前置 .net6的开发环境 问题 ? 打开unget官网,搜索报错的依赖Oracle.ManagedDataAccess.Core unget官网 通过unget搜索Oracle.ManagedDataAccess.Core查看该依赖的依赖 发现应该是需要的依赖Oracle.ManagedDataAccess.Core(>3.21.100)不支持.net6的环境 解…...

oracle数据库事务的四大特性与隔离级别与游标
数据库事务的四大特性: 这里提到了 ACID 四个特性,分别是: A(Atomicity): 原子性,确保事务中的所有操作要么全部执行成功,要么全部不执行,不存在部分执行的情况。 C(…...

Linux网络编程实战:从Socket基础到高并发服务器设计
1. 项目概述:从套接字到应用,理解网络编程的基石当我们谈论Linux下的应用开发,尤其是那些需要与外界通信的程序时,“网络编程”是一个绕不开的核心技能。而“Internet Domain应用编程”这个听起来有些学术的标题,实际上…...

避开勒让德函数那些坑:GRACE数据处理中MATLAB高效计算与调试技巧
GRACE数据处理中的勒让德函数实战:MATLAB高效计算与调试全指南 当你在深夜的实验室里盯着屏幕上那个不断报错的MATLAB脚本,勒让德函数的计算结果与文献数据相差了几个数量级,而论文截稿日期就在三天后——这种场景对处理GRACE球谐数据的研究者…...

Noisereduce的PyTorch实现:将降噪算法集成到神经网络中的完整教程
Noisereduce的PyTorch实现:将降噪算法集成到神经网络中的完整教程 【免费下载链接】noisereduce Noise reduction in python using spectral gating (speech, bioacoustics, audio, time-domain signals) 项目地址: https://gitcode.com/gh_mirrors/no/noisereduc…...

Delphi二进制迷宫破解:IDR交互式重构器的逆向工程革命
Delphi二进制迷宫破解:IDR交互式重构器的逆向工程革命 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 在逆向工程的世界里,Delphi编译的程序犹如一座座精心设计的迷宫——结构复杂、入…...

不止是省9.9刀:解锁特斯拉Model 3的‘行驶中保持WiFi’功能,打造家庭移动娱乐中心
不止是省9.9刀:解锁特斯拉Model 3的‘行驶中保持WiFi’功能,打造家庭移动娱乐中心 特斯拉Model 3的车载4G网络虽然方便,但在信号不佳的区域或需要大流量娱乐的场景下,往往显得力不从心。更让许多家庭用户纠结的是,高级…...

华为昇腾Atlas200边缘设备开箱即用指南:从CANN环境到YOLOv8模型部署的保姆级避坑教程
华为昇腾Atlas200边缘设备实战:YOLOv8模型部署全流程避坑指南 第一次拿到华为昇腾Atlas200边缘计算设备时,那种既兴奋又忐忑的心情记忆犹新。作为一款专为AI推理设计的边缘设备,Atlas200凭借其强大的算力和紧凑的体型,在智能安防…...

我做了一个仅有 1.3 MB 的 macOS 原生 AI 助手:AskNow
我就问个问题,怎么占用我一个多G的内存! 近半年以来,我们的信息流几乎被 Agent 刷屏。 Claude Code、Codex、OpenClaw,以及各种各样的 AI 应用都在快速出现。大家都在说:AI 已经不只是聊天机器人了,现在是 …...

终极指南:使用Play Integrity API Checker保护你的Android应用安全
终极指南:使用Play Integrity API Checker保护你的Android应用安全 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-a…...

Go语言性能分析:pprof与trace
Go语言性能分析:pprof与trace 1. pprof使用 import ("net/http/pprof"_ "net/http/pprof" )func main() {http.ListenAndServe(":6060", nil) }2. trace使用 import "runtime/trace"func main() {f, _ : os.Create("t…...
)
给Yahboom Dofbot机械臂写个‘身份证’:手把手教你从零创建URDF模型(附完整代码)
从零构建Yahboom Dofbot机械臂的URDF数字身份证:一份工程师视角的完整指南 当你第一次拆开Yahboom Dofbot机械臂的包装时,那些精致的金属关节和伺服电机可能会让你既兴奋又忐忑。作为ROS机器人开发的标准起点,URDF模型就像是机械臂的"数…...