Python爬虫知识图谱
下面是一份详细的Python爬虫知识图谱,涵盖了从基础入门到进阶实战的各个环节,涉及网络请求、页面解析、数据提取、存储优化、反爬策略应对以及法律伦理等多个方面,并配以关键点解析和代码案例,以供读者深入学习和实践。
一、Python爬虫基础概念
1.1 网络爬虫简介
- 网络爬虫是一种自动浏览互联网上的信息资源,并按照一定规则抓取所需数据的程序或脚本。它模仿人类访问网页的行为,获取并解析网页内容。
- 作用:网络爬虫在大数据分析、搜索引擎索引构建、舆情监测、市场趋势分析等领域有着广泛的应用。
1.2 Python爬虫生态
- requests库:用于发起HTTP(S)请求,获取网页内容。如:
import requests
response = requests.get('https://www.example.com')
print(response.text)
- urllib模块:Python内置库,同样可用于HTTP请求,但相比requests功能略少,但在某些无第三方依赖要求的情况下可以使用。
- HTML解析库:
- BeautifulSoup:基于Python编写的解析库,适合处理不规范的HTML文档,方便地查找标签及属性。
- lxml:一个高效的XML和HTML解析库,支持XPath表达式,速度较快且功能强大。
二、Python爬虫入门实践
2.1 发送网络请求
- 请求头部设置:包括User-Agent、Cookie、Referer等,用于模拟浏览器行为,避免被服务器识别为爬虫。
headers = {
'User-Agent': 'Mozilla/5.0',
}
response = requests.get('https://www.example.com', headers=headers)
2.2 页面解析
- `BeautifulSoup`解析HTML示例:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
title_element = soup.find('title')
if title_element:
title = title_element.text
- `lxml`结合XPath解析:
from lxml import etree
html = etree.HTML(response.text)
title = html.xpath('//title/text()')[0]
三、中级爬虫技术
3.1 异步请求与并发控制
- 异步爬虫能显著提高爬取效率,利用`asyncio`和`aiohttp`实现:
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
html_contents = await asyncio.gather(*tasks)
# ... 进一步处理抓取内容
- Scrapy框架内建了基于Twisted的异步引擎,可以方便地实现并发请求。
3.2 动态加载网页处理
- 对于JavaScript动态渲染的网页,可以采用:
- Selenium:自动化测试工具,可直接执行JavaScript代码并获取渲染后的DOM。
- Splash:基于Lua的JS渲染服务,Scrapy可以通过中间件与其交互。
- Pyppeteer:基于Chromium的无头浏览器驱动,提供JavaScript执行环境来获取渲染后的内容。
四、数据持久化与存储
4.1 数据存储方式
- 文件存储:如CSV、JSON格式,易于阅读和与其他工具集成。
import json
data = [{'title': title, 'url': url} for title, url in zip(titles, links)]
with open('data.json', 'w') as f:
json.dump(data, f)
# 或者CSV存储
import csv
with open('data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Title', 'Url'])
writer.writerows(zip(titles, links))
- 数据库存储:使用SQLAlchemy、pymysql等库连接关系型数据库(如MySQL、PostgreSQL);或者利用MongoDB-Python驱动连接非关系型数据库MongoDB。
4.2 使用pandas进行数据处理和存储
- pandas具有强大的数据处理能力,可以将爬取的数据转换成DataFrame再进行存储。
import pandas as pd
df = pd.DataFrame({'title': titles, 'url': links})
df.to_sql('articles', con=engine, if_exists='append', index=False)
五、爬虫优化与反爬措施应对
5.1 代理IP池与User-Agent切换
- 使用`rotating_proxies`等库管理代理IP池,每次请求时随机选取IP地址:
from rotating_proxies import ProxyManager
proxy_manager = ProxyManager('proxies.txt')
proxy = next(proxy_manager)
proxies = {'http': 'http://' + proxy, 'https': 'https://' + proxy}
response = requests.get('https://www.example.com', proxies=proxies)
- 使用`fake_useragent`库随机生成User-Agent:
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-Agent': ua.random}
5.2 反爬策略识别与破解
- 处理Cookies和Session:确保爬虫在处理需要登录验证的网站时维持会话状态。
- 针对验证码问题,可以尝试OCR识别、机器学习破解,或者购买验证码识别服务。
- 对于滑块验证码、点击验证码等复杂类型,可能需要定制化的解决方案,例如模拟用户操作。
六、Scrapy框架详解
6.1 Scrapy项目结构与配置
- 创建项目:`scrapy startproject project_name`
- 配置settings.py:包括下载延迟(DOWNLOAD_DELAY)、并发请求数(CONCURRENT_REQUESTS)、是否启用cookies(COOKIES_ENABLED)等。
6.2 Spider编写与响应处理
- 编写Spider类,定义初始URL、解析函数以及如何提取和处理数据。
class ArticleSpider(scrapy.Spider):
name = 'article_spider'
start_urls = ['http://example.com/articles']
def parse(self, response):
for article in response.css('.article'):
item = ArticleItem()
item['title'] = article.css('.title::text').get()
item['author'] = article.css('.author::text').get()
yield item
- 利用Item Pipeline处理提取后的数据,例如去重、清洗、入库等操作。
七、法律法规与道德规范
7.1 法律法规遵守
- 在中国,了解《网络安全法》、《个人信息保护法》及其他相关法律法规,确保爬取数据时不侵犯个人隐私、版权等权益。
- 国际上,如GDPR要求对欧洲公民数据有严格规定,爬虫应当遵守相关数据保护政策。
7.2 道德爬虫实践
- 尊重网站robots.txt文件中的规定,不在禁止抓取的目录下爬取数据。
- 设置合理的爬取间隔,避免给目标网站带来过大压力。
- 不恶意破坏网站正常运行,不非法传播或利用所爬取的数据。
相关文章:

Python爬虫知识图谱
下面是一份详细的Python爬虫知识图谱,涵盖了从基础入门到进阶实战的各个环节,涉及网络请求、页面解析、数据提取、存储优化、反爬策略应对以及法律伦理等多个方面,并配以关键点解析和代码案例,以供读者深入学习和实践。 一、Pyth…...

安宝特AR汽车行业解决方案系列1-远程培训
在汽车行业中,AR技术的应用正悄然改变着整个产业链的运作方式,应用涵盖培训、汽修、汽车售后、PDI交付、质检以及汽车装配等,AR技术为多个环节都带来了前所未有的便利与效率提升。 安宝特AR将以系列推文的形式为读者逐一介绍在汽车行业中安宝…...
微服务篇之分布式系统理论
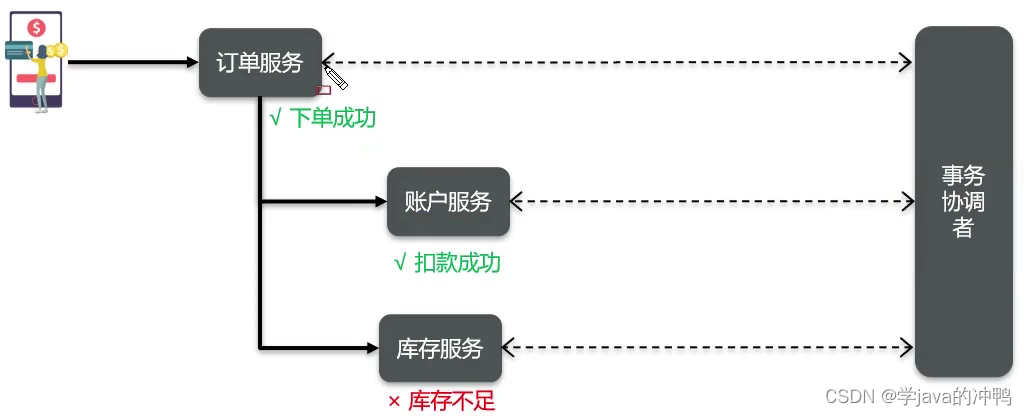
一、CAP定理 1.什么是CAP 1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标: 1. Consistency(一致性)。 2. Availability(可用性)。 3. Partition tolerance ࿰…...

MLflow【部署 01】MLflow官网Quick Start实操(一篇学会部署使用MLflow)
一篇学会部署使用MLflow 1.版本及环境2.官方步骤Step-1 Get MLflowStep-2 Start a Tracking ServerStep 3 - Train a model and prepare metadata for loggingStep 4 - Log the model and its metadata to MLflowStep 5 - Load the model as a Python Function (pyfunc) and us…...

NDK的log.h使用__android_log_print报错app:buildCMakeDebug[x86_64]
org.gradle.api.tasks.TaskExecutionException: Execution failed for task :app:buildCMakeDebug[x86_64] 重点是 Execution failed for task :app:buildCMakeDebug[x86_64]. 我的代码: #include <android/log.h> #define LOG_TAG "MyJNI" #d…...

【计算机网络:DHCP协议】
文章目录 前言一、DHCP是什么?二、DHCP的工作原理1.基本流程发现(DISCOVER)提供(OFFER)请求(REQUEST)确认(ACKNOWLEDGEMENT) 2.DHCP租约的概念3.DHCP续租过程 三、DHCP服…...

http前生今世
HTTP/0.9,仅支持GET方法,并且响应中没有HTTP头信息,只有文档内容。 HTTP/1.0增加了对POST方法、状态码、HTTP头信息等的支持,这一版本也是广泛应用的历史性版本。 HTTP/1.1引入了持久连接(Persistent Connections&…...
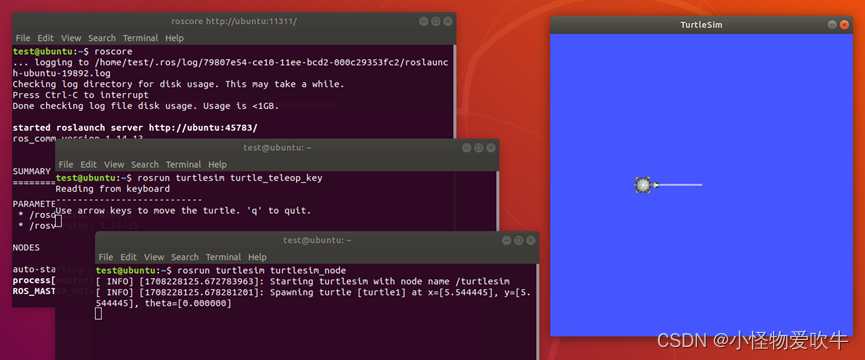
一键安装ROS适用于Ubuntu22/20/18
一键安装ROS适用于Ubuntu22/20/18 1、简介 ROS(Robot Operating System,机器人操作系统)是一个用于机器人软件开发的框架。它提供了一套工具和库,用于机器人应用程序的开发、测试和部署。ROS是由美国斯坦福大学机器人实验室&…...

OLED透明屏厂家:开启2024年新征程
随着科技的不断进步和创新,OLED透明屏作为一种前沿的显示技术,正逐渐走进人们的视野,成为多个领域的焦点。在2024年2月21日这个特殊的日子,我们这家领先的OLED透明屏厂家正式开工,预示着我们将迎来一个充满机遇和挑战的…...
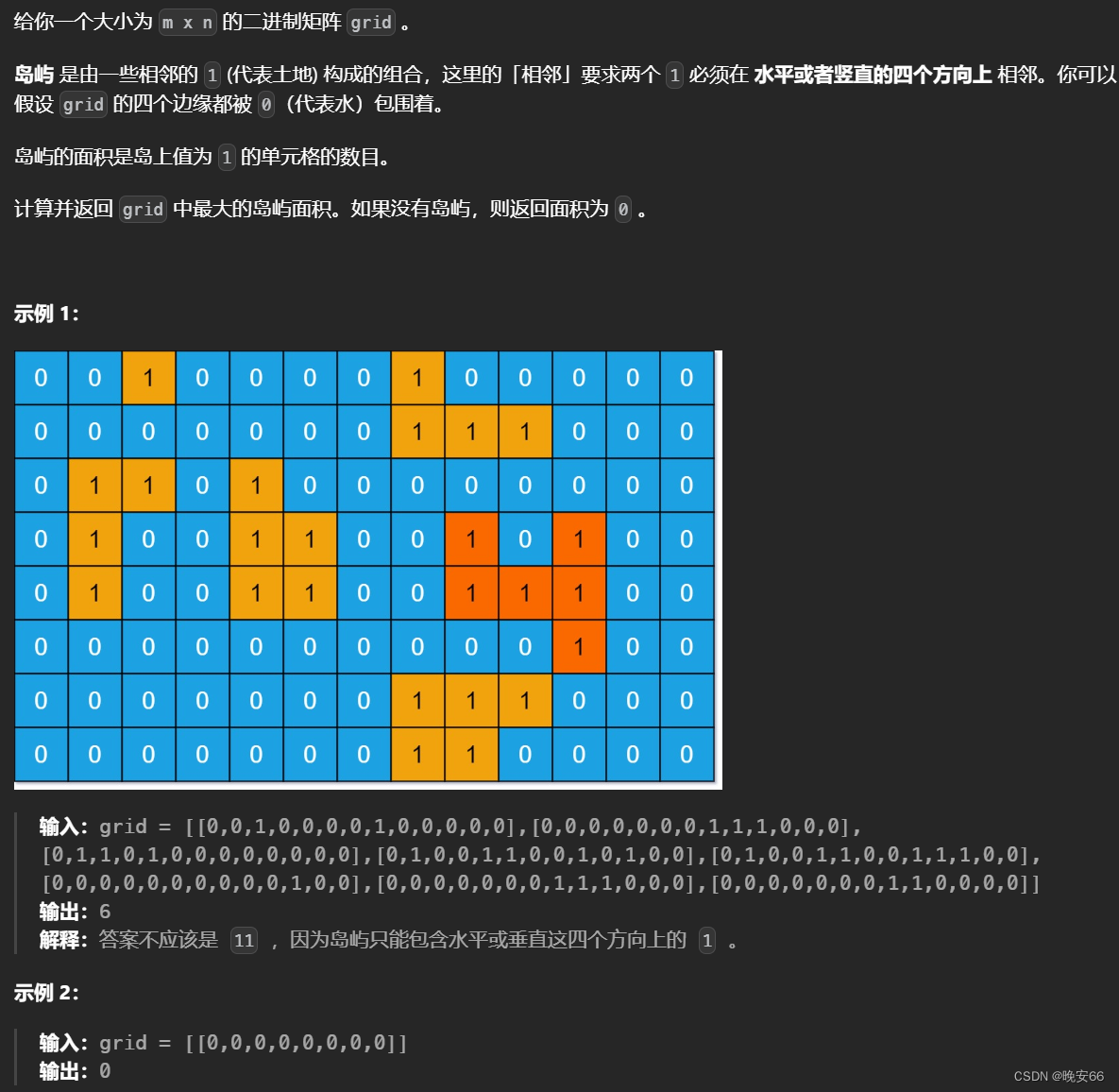
【算法与数据结构】200、695、LeetCode岛屿数量(深搜+广搜) 岛屿的最大面积
文章目录 一、200、岛屿数量1.1 深度优先搜索DFS1.2 广度优先搜索BFS 二、695、岛屿的最大面积2.1 深度优先搜索DFS2.2 广度优先搜索BFS 三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、200、岛屿数量 1.1 深度优先搜…...

第四十一回 还道村受三卷天书 宋公明遇九天玄女-python创建临时文件和文件夹
宋江想回家请老父亲上山,晁盖说过几天带领山寨人马一起去。宋江还是坚持一个人去。 宋江到了宋家村,被两个都头和捕快们追捕,慌不择路,躲进了一所古庙。一会儿,听见有人说:小童奉娘娘法旨,请星主…...
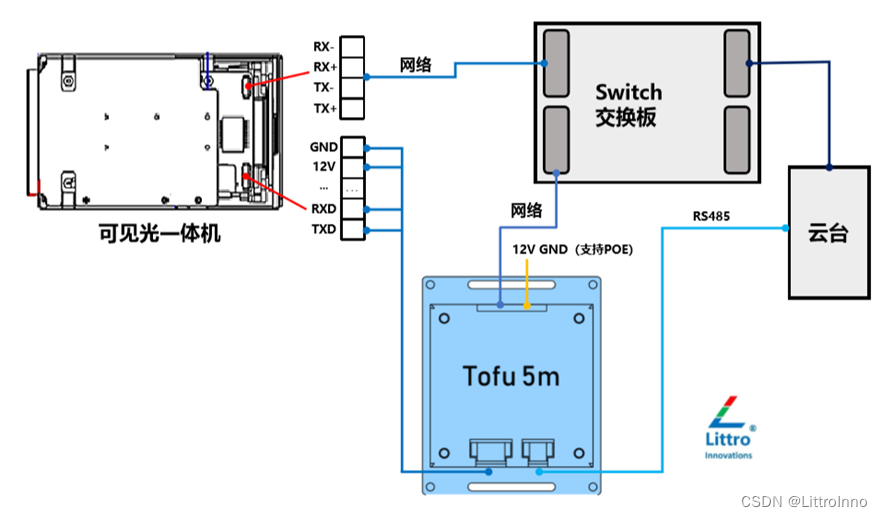
Tofu5m 高速实时推理Yolov8
Tofu5m 是高性价比目标识别跟踪模块,支持可见光视频或红外网络视频的输入,支持视频下的多类型物体检测、识别、跟踪等功能。 Yolov8推理速度达到40帧每秒。 实测视频链接:Tofu5m识别跟踪模块_哔哩哔哩_bilibili 产品支持视频编码、设备管理…...
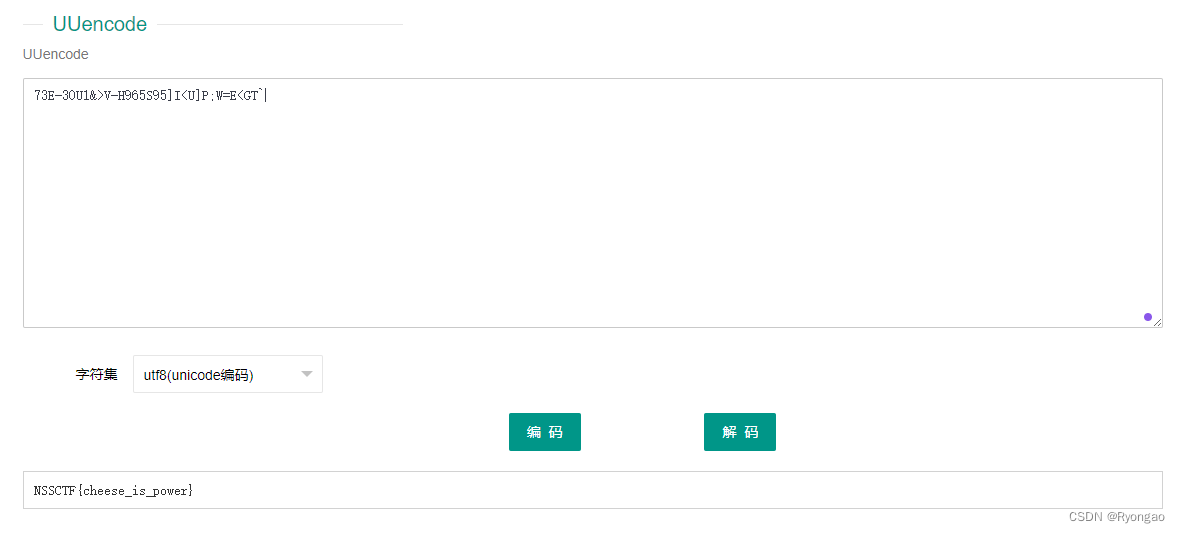
[SWPUCTF 2021 新生赛]crypto8
第一眼看见是乱码不确定是什么的编码 看了下感觉是UUencode编码 UUencode编码是一种古老的编码方式,通常用于将二进制数据转换成可打印字符的形式。UUencode编码采用一种基于64个字符的编码表,将每3个字节的数据编码为4个可打印字符,以实现…...
)
学习使用js调用动态函数名(动态变量函数名)
学习使用js调用动态函数名-动态变量函数名 背景代码 背景 函数名写在 html 上,在 js 中定义这个变量,js 报错该函数不存在,在此给出解决方法 代码 //html代码如下 <a data-function"qipa" class"clickMe">250&l…...

CSS 圆形的时钟秒针状的手柄绕中心点旋转的效果
<template><!-- 创建一个装载自定义加载动画的容器 --><view class="cloader"><!-- 定义加载动画主体部分 --><view class="clface"><!-- 定义类似秒针形状的小圆盘 --><view class="clsface"><!-…...

MYSQL--存储过程操作
一:概念: 存储过程实际上对标了JAVA当中的方法,两者是相似的,同时需要注意的一点是,MYSQL仅仅在5.0版本之后才出现这种存储操作的过程; 优点: 1.存储过程能够让运行的速度变得更加迅速ÿ…...

C#上位机与三菱PLC的通信09---开发自己的通讯库(A-3E版)
1、A-3E报文回顾 具体细节请看: C#上位机与三菱PLC的通信05--MC协议之QnA-3E报文解析 C#上位机与三菱PLC的通信06--MC协议之QnA-3E报文测试 2、为何要开发自己的通讯库 前面开发了自己的A-1E协议的通讯库,实现了数据的读写,对于封装的通…...
——代码随想录算法训练营Day38)
【LeetCode】70. 爬楼梯(简单)——代码随想录算法训练营Day38
题目链接:70. 爬楼梯 题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到…...
)
图数据库 之 Neo4j - Cypher语法基础(5)
节点(Nodes) Cypher使用()来表示一个节点。 () # 最简单的节点形式,表示一个任意无特征的节点,其实就是一个空节点(movie) # 如果想指向一个节点在其他地方,我们可以给节点添加一个变量名(如movie),表示一个变量名为 movie的节点。(:Movie) # 表示一个标签为 Movie 的匿名…...

打造智能物品租赁平台:Java与SpringBoot的实践
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...

基于CMS8S6990评估板实现高精度电压电流测量:从血氧仪到通用测量工具的移植实践
1. 项目缘起与核心思路最近终于拿到了中微半导体(CMSemicon)正版的CMS8S6990血氧仪开发板。这块板子给我的第一印象就是“精致”,尺寸不大,但该有的接口和功能一应俱全,颇有点“麻雀虽小,五脏俱全”的味道。…...

为什么所有人都在聊RAG?看这篇,小白也能彻底搞懂
你是否有过这样的经历——你满怀期待地问 AI 一个专业问题,它流畅地给了你一段"答案",引经据典、逻辑自洽。 结果一查,发现全是错的。一本正经地胡说八道。 这就是大语言模型(LLM)的致命短板:它…...
)
今日算法(二叉树剪枝)
题目描述给你二叉搜索树的根节点 root,同时给定最小边界 low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在 [low, high] 中。修剪树不应该改变保留在树中的元素的相对结构(即如果没有被移除,原有的父子代关系都应当保…...

卡梅德生物技术快报|多肽库筛选技术构建药物递送功能肽库:流程、算法与质控体
1. 研究背景与问题提出在多肽药物递送系统开发中,功能肽的序列空间巨大,传统逐序列合成与测试方法通量低、成本高、周期长,无法覆盖构象多样性与体内复杂环境。纳米载体蛋白冠、亚细胞器定位困难、多肽稳定性不足等问题,亟需高通量…...

Linux用户与权限管理实战:从基础命令到SELinux/ACL高级应用
1. 项目概述:为什么用户管理是Linux系统的基石在Linux世界里,无论你是管理一台个人服务器,还是运维一个庞大的集群,用户和组的管理都是你绕不开的第一课。很多人觉得这无非就是useradd和passwd几个命令,但真正踩过坑的…...

Stateflow实战:构建LKA系统状态机的模块化建模与数据管理
1. 从零理解LKA系统与Stateflow建模 第一次接触车道保持辅助系统(LKA)时,我盯着那个能在高速上自动修正方向的方向盘看了半天。这玩意儿到底怎么判断什么时候该介入?后来才知道,核心就是藏在控制器里的状态机逻辑。Sta…...

3步打造智能设计转换桥梁:从Figma到Unity的无缝对接方案
3步打造智能设计转换桥梁:从Figma到Unity的无缝对接方案 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBridge 在现代游戏开发…...

ARM弱内存序模型解析:多核并发编程中的内存屏障与同步原语
1. 项目概述:为什么我们需要深入理解ARM的存储一致性模型? 在嵌入式开发、移动计算乃至如今的服务器领域,ARM架构已经无处不在。作为一名长期与底层硬件和操作系统打交道的开发者,我见过太多因对内存模型理解不足而导致的“幽灵”…...

AD画完板子别急着下单!5分钟搞定DRC规则检查,避开这些坑才能顺利发嘉立创
AD设计必看:DRC规则检查深度解析与实战避坑指南 在PCB设计领域,完成布线只是成功的一半。许多工程师在AD(Altium Designer)中精心设计完电路板后,常常因为忽略DRC(Design Rule Check)检查而遭遇生产返工、延迟甚至完全报废的惨痛经历。本文将…...

OpenArm开源机械臂终极指南:从零开始构建你的7自由度人形手臂
OpenArm开源机械臂终极指南:从零开始构建你的7自由度人形手臂 【免费下载链接】openarm A fully open-source humanoid arm for physical AI research and deployment in contact-rich environments. 项目地址: https://gitcode.com/GitHub_Trending/op/openarm …...