爬虫知识--02
免费代理池搭建
# 代理有免费和收费代理
# 代理有http代理和https代理
# 匿名度:
高匿:隐藏访问者ip
透明:服务端能拿到访问者ip
作为后端,如何拿到使用代理人的ip
请求头中:x-forword-for
如一个 HTTP 请求到达服务器之前,经过了三个代理 Proxy1、Proxy2、Proxy3,IP 分别为 IP1、IP2、IP3,用户真实IP为IP0,那么按照XFF标准,服务端最终会收到以下信息:
X-Forwarded-For: IP0, IP1, IP2
如果拿IP3,remote-addr中
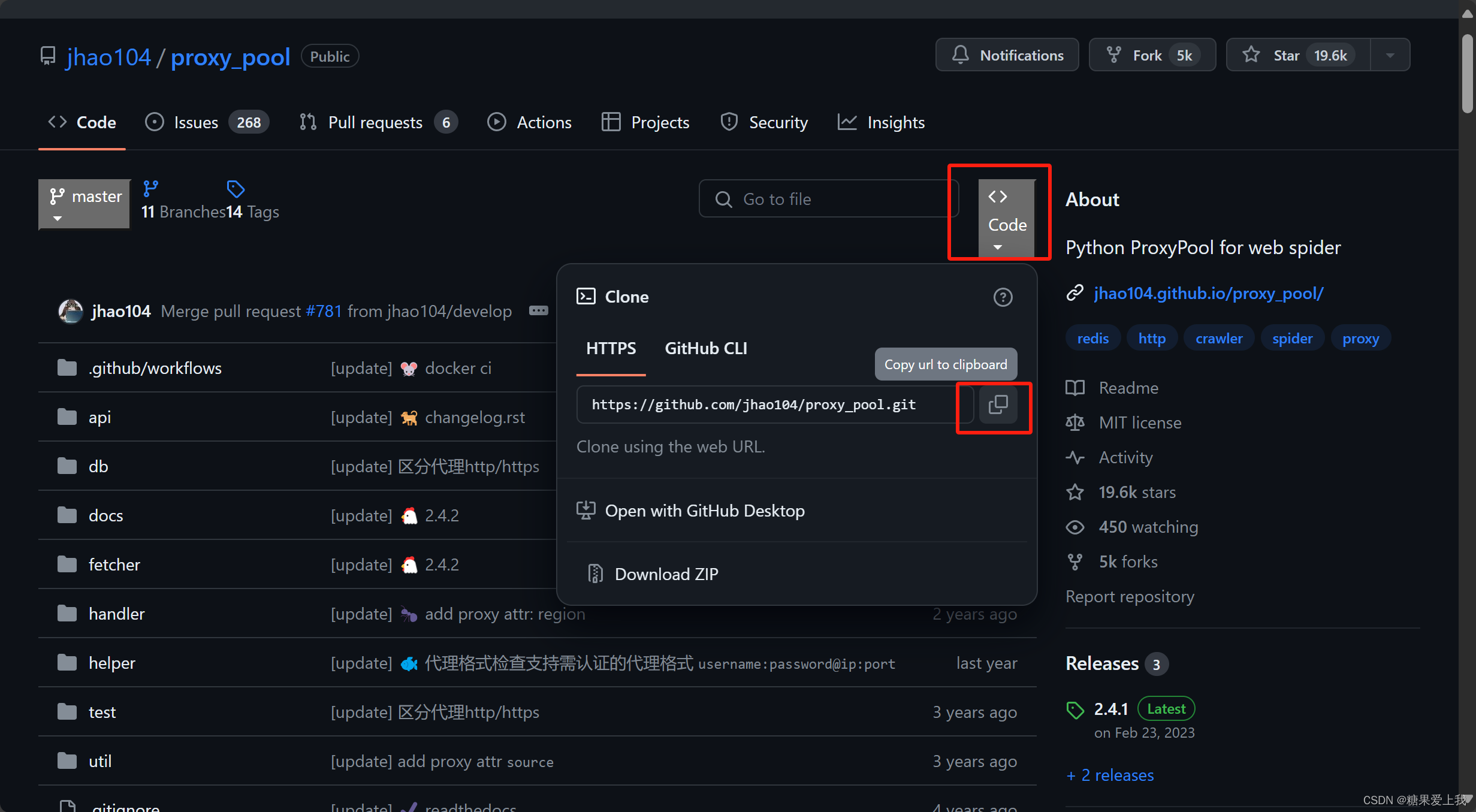
# 搭建免费代理池:https://github.com/jhao104/proxy_pool
使用python,爬取免费的代理,解析出ip和端口,地区,存到库中
使用flask,搭建了一个web服务,只要向 /get 发送一个请求,他就随机返回一个代理ip
# 步骤:
1、把项目下载下来
2、安装依赖,虚拟环境 pip install -r requirements.txt
3、修改配置文件
DB_CONN = 'redis://127.0.0.1:6379/2'
4、启动爬虫:python proxyPool.py schedule
5、启动web服务:python proxyPool.py server
6、以后访问:http://127.0.0.1:5010/get/ 可以拿到随机的免费ip
7、使用代码:
import requestsres = requests.get('http://192.168.1.51:5010/get/?type=https').json() print(res['proxy'])# 访问某个代理 res1=requests.get('https://www.baidu.com',proxies={'http':res['proxy']}) print(res1)# 项目下载:



代理池使用
# 使用django写个项目,只要一访问,就返回访问者ip
# 编写步骤:
1、编写django项目,写一个视图函数:def index(request):ip=request.META.get('REMOTE_ADDR')return HttpResponse('您的ip 是:%s'%ip)2、配置路由:
from app01.views import index urlpatterns = [path('', index), ]3、删除settings.py 中的数据库配置
4、把代码上传到服务端,运行djagno项目
python3.8 manage.py runserver 0.0.0.0:80805、本地测试:
import requests res=requests.get('http://127.0.0.1:5010/get/?type=http').json() print(res['proxy']) res1=requests.get('http://47.113.229.151:8080/',proxies={'http':res['proxy']}) print(res1.text)
爬取某视频网站
注意:
1 发送ajax请求,获取真正视频地址
2 发送ajax请求时,必须携带referer
3 返回的视频地址,需要处理后才能播放import requests import reres = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0') # print(res.text) # 解析出所有视频地址---》re解析 video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text) for video in video_list:real_url = 'https://www.pearvideo.com/' + videovideo_id = video.split('_')[-1]# 必须携带referer,referer是视频详情地址# contId 是视频id号header={'Referer':real_url}res = requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=%s&mrd=0.05520583472057039'%video_id,headers=header)real_mp4_url=res.json()['videoInfo']['videos']['srcUrl']mp4 = real_mp4_url.replace(real_mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)print('能播放的视频地址:',mp4)# 把视频下载到本地res=requests.get(mp4)with open('./video/%s.mp4'%video_id,'wb') as f:for line in res.iter_content():f.write(line)
爬取新闻
# 解析库:汽车之家
# bs4 解析库 pip3 install beautifulsoup4lxml: pip3 install lxml
# 爬取所有数据:
import requests from bs4 import BeautifulSoupres = requests.get('https://www.autohome.com.cn/news/1/#liststart') print(res.text)# 取出文章详情:
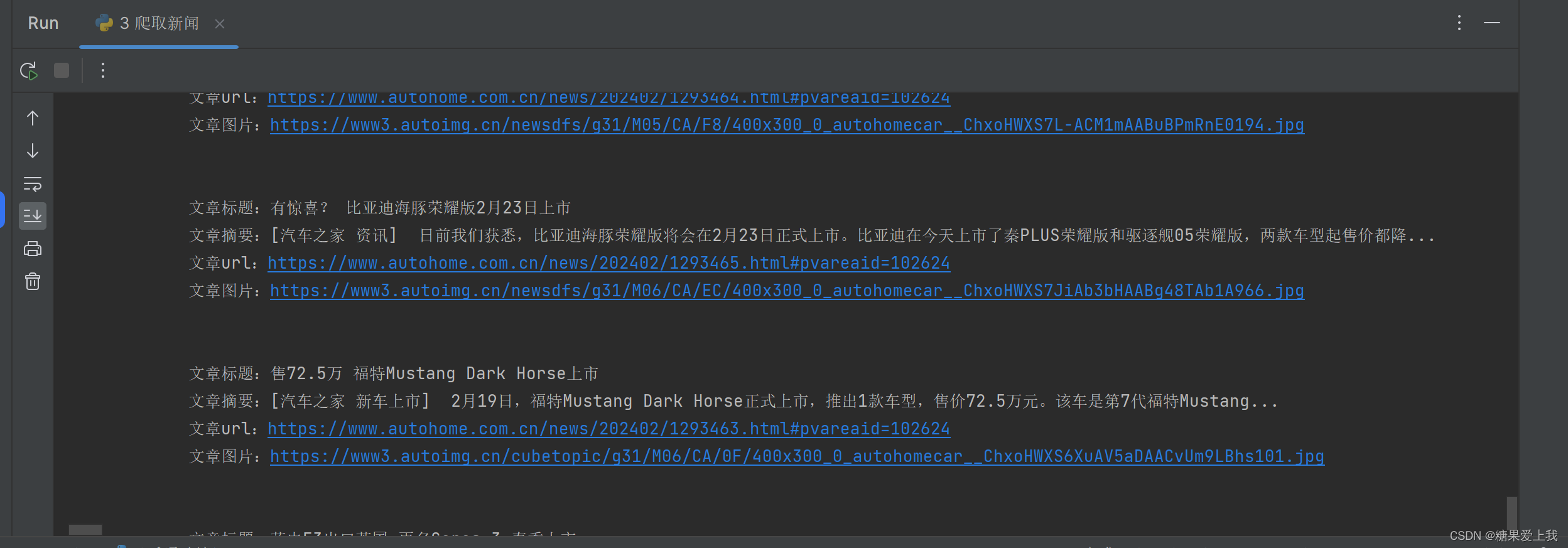
import requests from bs4 import BeautifulSoupres = requests.get('https://www.autohome.com.cn/news/1/#liststart') print(res.text)soup = BeautifulSoup(res.text, 'html.parser') # 解析库 ul_list = soup.find_all(name='ul', class_='article') # 找到所有 类名是article 的ul标签 for ul in ul_list: # 查找ul标签下的li标签li_list = ul.find_all(name='li')for li in li_list:h3 = li.find(name='h3') # 查找li标签下的所有h3标题if h3:title = h3.text # 拿出h3标签的文本内容content = li.find('p').text # 拿出li标签下的第一个p标签的文本内容url = 'https:' + li.find(name='a').attrs['href'] # .attrs 拿到标签属性img = li.find('img')['src'] # 拿出img标签的属性src,可以直接取print('''文章标题:%s文章摘要:%s文章url:%s文章图片:%s''' % (title, content, url, img))
bs4介绍和遍历文档树
# bs4的概念:是解析 xml/html 格式字符串的解析库
不但可以解析(爬虫),还可以修改# 解析库:
from bs4 import BeautifulSouphtml_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title" id='id_xx' xx='zz'>lqz <b>The Dormouse's story <span>彭于晏</span></b> xx</p><p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p><p class="story">...</p> """ # soup=BeautifulSoup(html_doc,'html.parser') soup = BeautifulSoup(html_doc, 'lxml') # pip3 install lxml1、文档容错能力:
res=soup.prettify()
print(res)2、遍历文档树: 文档树:html开头 ------html结尾,中间包含了很多标签
print(soup.html.head.title)3、通过 . 找到p标签 只能找到最先找到的第一个
print(soup.html.body.p)
print(soup.p)4、获取标签的名称
p = soup.html.body.p
print(p.name)5、获取标签的属性
p = soup.html.body.p
print(p.attrs.get('class')) # class 特殊,可能有多个,所以放在列表汇总
print(soup.a.attrs.get('href'))
print(soup.a['href'])6、获取标签的文本内容
标签对象.text # 拿标签子子孙孙 标签对象.string # 该标签有且只有自己有文本内容才能拿出来 标签对象.strings # 拿子子孙孙,都放在生成器中 print(soup.html.body.p.b.text) print(soup.html.body.p.text) print(soup.html.body.p.string) # 不能有子 孙 print(soup.html.body.p.b.string) # 有且只有它自己print(soup.html.body.p.strings) # generator 生成器---》把子子孙孙的文本内容都放在生成器中,跟text很像 print(list(soup.html.body.p.strings)) # generator 生成器---》把子子孙孙的文本内容都放在生成器中,跟text很像7、嵌套选的:
soup.html.body# -----了解-----------:
# 子节点、子孙节点 print(soup.p.contents) # p下所有子节点,只拿直接子节点 print(soup.p.children) # 直接子节点 得到一个迭代器,包含p下所有子节点 for i,child in enumerate(soup.p.children):print(i,child)print(soup.p.descendants) #获取子孙节点,p下所有的标签都会选择出来 generator for i,child in enumerate(soup.p.descendants):print(i,child)# 父节点、祖先节点 print(soup.a.parent) #获取a标签的父节点 print(list(soup.a.parents)) #找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...# 兄弟节点 print(soup.a.next_sibling) #下一个兄弟 print(soup.a.previous_sibling) #上一个兄弟print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象 print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
搜索文档树
# 解析库:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p id="my_p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b> </p><p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p><p class="story">...</p> """from bs4 import BeautifulSoupsoup = BeautifulSoup(html_doc, 'lxml')# 五种过滤器: 字符串、正则表达式、列表、True、方法
1、字符串(和):res=soup.find(id='my_p') res=soup.find(class_='boldest') res=soup.find(href='http://example.com/elsie') res=soup.find(name='a',href='http://example.com/elsie',id='link1',class_='sister') # 多个是and条件 # 可以写成 # res=soup.find(attrs={'href':'http://example.com/elsie','id':'link1','class':'sister'}) # print(res)2、正则表达式:
import re res=soup.find_all(href=re.compile('^http')) res=soup.find_all(name=re.compile('^b')) res=soup.find_all(name=re.compile('^b')) print(res)3、列表(或):
res=soup.find_all(name=['body','b','a']) res=soup.find_all(class_=['sister','boldest']) print(res)4、布尔:
res=soup.find_all(id=True) res=soup.find_all(name='img',src=True) print(res)5、方法:
def has_class_but_no_id(tag):return tag.has_attr('class') and not tag.has_attr('id') print(soup.find_all(has_class_but_no_id))6、搜索文档树可以结合遍历文档树一起用
res=soup.html.body.find_all('p') res=soup.find_all('p') print(res)7、find 和find_all的区别:find 就是find_all,只要第一个
8、recursive=True limit=1
res=soup.find_all(name='p',limit=2) # 限制条数 res=soup.html.body.find_all(name='p',recursive=False) # 是否递归查找 print(res)
css选择器
# 解析库:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p id="my_p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b> </p><p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p><p class="story">...</p> """from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'lxml')# css 选择器:
''' .类名 #id body body a # 终极大招:css选择器,复制 '''res=soup.select('a.sister') res=soup.select('p#my_p>b') res=soup.select('p#my_p b') print(res)import requests from bs4 import BeautifulSoup header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } res=requests.get('https://www.zdaye.com/free/',headers=header) # print(res.text) soup=BeautifulSoup(res.text,'lxml') res=soup.select('#ipc > tbody > tr:nth-child(2) > td.mtd') print(res[0].text)
今日思维导图:
相关文章:
爬虫知识--02
免费代理池搭建 # 代理有免费和收费代理 # 代理有http代理和https代理 # 匿名度: 高匿:隐藏访问者ip 透明:服务端能拿到访问者ip 作为后端,如何拿到使用代理人的ip 请求头中:x-forwor…...

SCI一区 | Matlab实现GAF-PCNN-MSA格拉姆角场和双通道PCNN融合注意力机制的多特征分类预测
SCI一区 | Matlab实现GAF-PCNN-MSA格拉姆角场和双通道PCNN融合注意力机制的多特征分类预测 目录 SCI一区 | Matlab实现GAF-PCNN-MSA格拉姆角场和双通道PCNN融合注意力机制的多特征分类预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 1.【SCI一区级】Matlab实…...
Observability:使用 OpenTelemetry 和 Elastic 监控 OpenAI API 和 GPT 模型
作者: 来自 Elastic David Hope ChatGPT 现在非常火爆,甚至席卷了整个互联网。 作为 ChatGPT 的狂热用户和 ChatGPT 应用程序的开发人员,我对这项技术的可能性感到非常兴奋。 我看到的情况是,基于 ChatGPT 的解决方案将会呈指数级…...
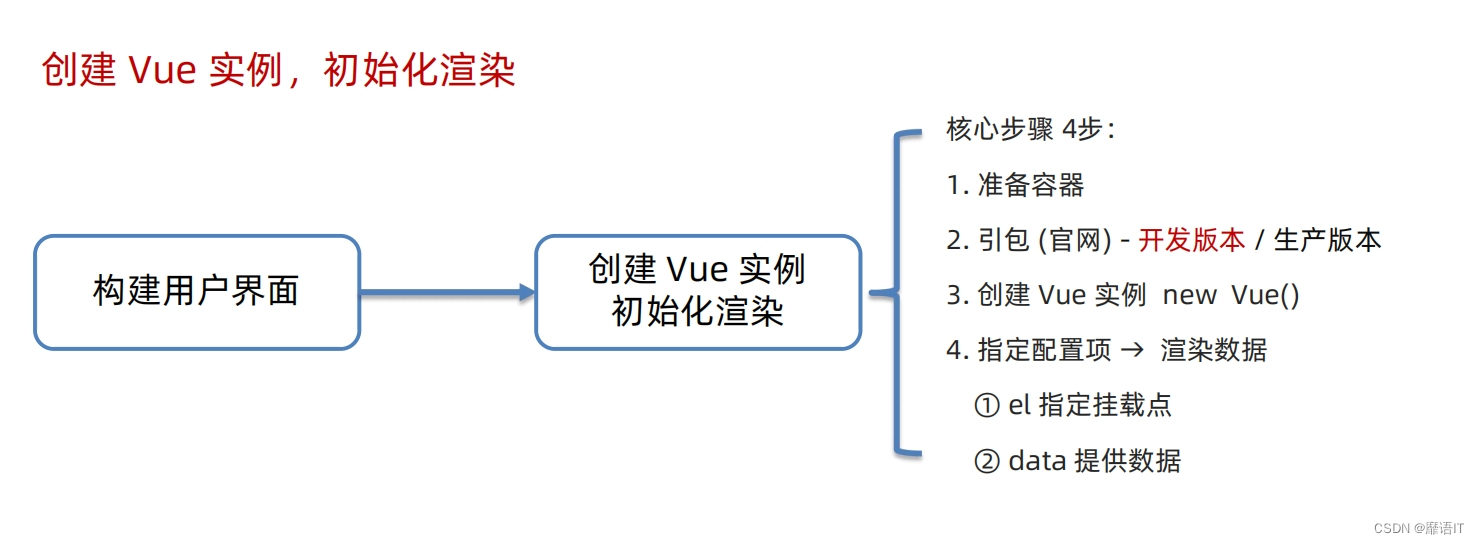
靡语IT:Vue精讲(一)
Vue简介 发端于2013年的个人项目,已然成为全世界三大前端框架之一,在中国大陆更是前端首选。 它的设计思想、编码技巧也被众多的框架借鉴、模仿。 纪略 2013年,在Google工作的尤雨溪,受到Angular的启发,从中提取自…...
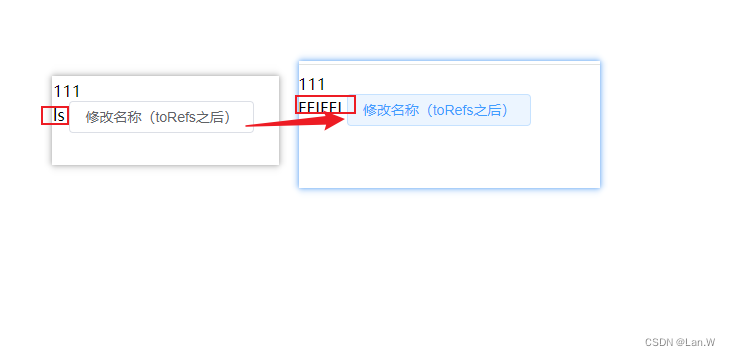
vue3 toRefs之后的变量修改方法
上效果 修改值需要带上解构之前的对象名obj, changeName:()>{ // toRefs 解决后变量修改值方法: 解构前变量.字段新值 obj.name FEIFEI; } } 案例源码 <!DOCTYPE html> <html> <head><me…...
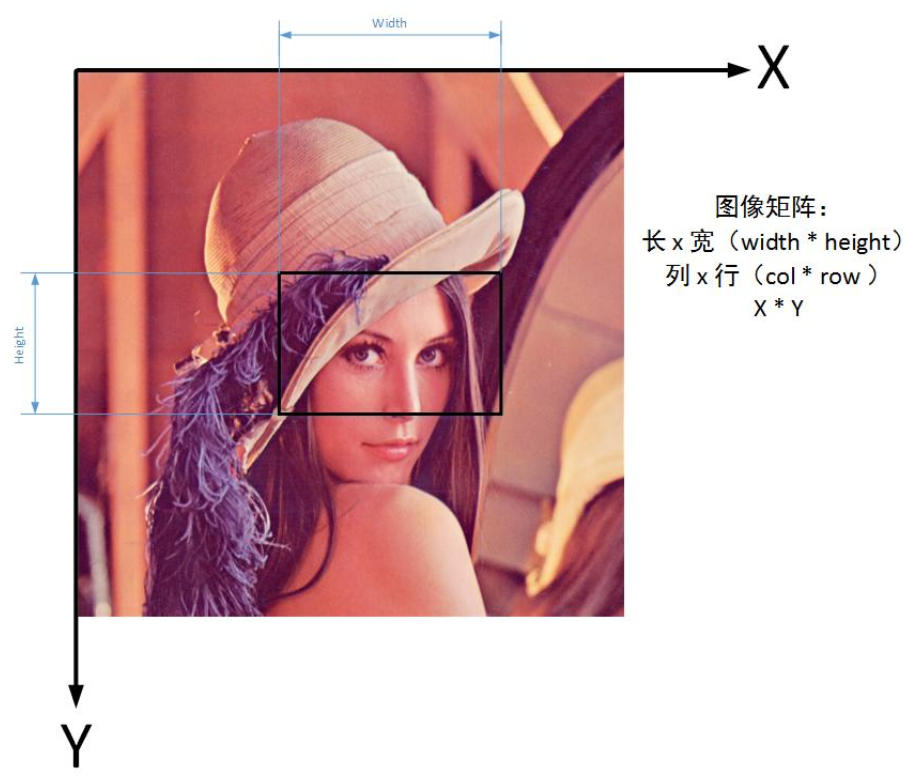
【教程】详解相机模型与坐标转换
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 由于复制过来,如果有格式问题,推荐大家直接去我原网站上查看: 相机模型与坐标转换 - 生活大爆炸 目录 经纬度坐标系 转 地球直角坐标系大地直角坐标系 转 经纬度坐标系地理坐标…...
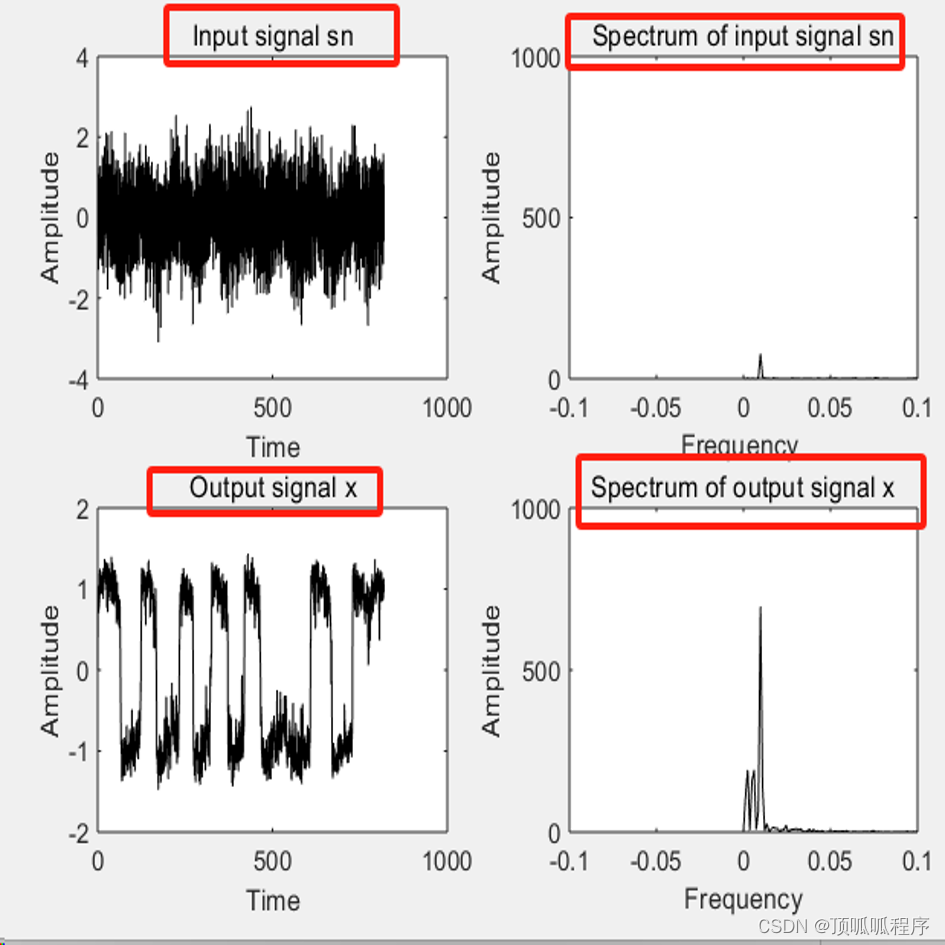
171基于matlab的随机共振微弱信号检测
基于matlab的随机共振微弱信号检测,随机共振描述了过阻尼布朗粒子受周期性信号和随机噪声的共同作用下,在非线性双稳态系统中所发生的跃迁现象. 随机共振可用于弱信号的检测。程序已调通,可直接运行。...
petalinux_zynq7 驱动DAC以及ADC模块之三:实现C语言API并编译出库被python调用
前文: petalinux_zynq7 C语言驱动DAC以及ADC模块之一:建立IPhttps://blog.csdn.net/qq_27158179/article/details/136234296petalinux_zynq7 C语言驱动DAC以及ADC模块之二:petalinuxhttps://blog.csdn.net/qq_27158179/article/details/1362…...
:S32K3xx基于RTD-SDK在S32DS上配置ADC的硬件触发同步采样与软件采样过程)
NXP实战笔记(五):S32K3xx基于RTD-SDK在S32DS上配置ADC的硬件触发同步采样与软件采样过程
目录 1、概述 1.1、软件触发 1.2、硬件触发 - BCTU 1.3、硬件触发 - TRGMUX 1.4、ADC的校准 1.5、ADC时钟配置 2、BTCU硬件触发ADC的SDK配置 3、软件触发ADC 3.1、选择相应Port作为ADC的输入 3.2、ADC配置 3.3、代码示例 1、概述 恩智浦 S32K3xx 系列汽车微控制器…...
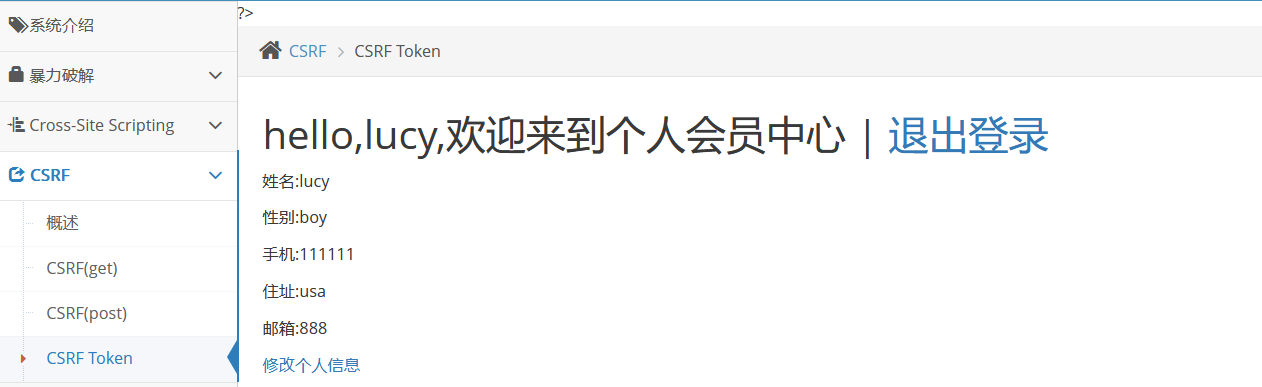
pikachu靶场-CSRF
CSRF: 介绍: Cross-site request forgery简称为"CSRF”。 在CSF的攻击场景中攻击者会伪造一个请求(这个请求一般是一个链接) 然后欺骗目标用户进行点击,用户一旦点击了这个请求,整个攻击也就完成了࿰…...

【结合OpenAI官方文档】解决Chatgpt的API接口请求速率限制
OpenAI API接口请求速率限制 速率限制以五种方式衡量:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟令牌数)、TPD(每天令牌数)和IPM(每分钟图像数&#x…...

C语言实现基础数据结构——栈
目录 栈 栈的实现 数组栈 数组栈的实现 栈的初始化 栈的销毁 数据入栈 判断栈是否为空 数据出栈 获取栈顶元素 获取栈内数据个数 项目实现 栈的基础练习 有效的括号 栈 栈是一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的…...

船舶制造5G智能工厂数字孪生可视化平台,推进船舶行业数字化转型
船舶制造5G智能工厂数字孪生可视化平台,推进船舶行业数字化转型。随着数字化时代的到来,船舶行业正面临着前所未有的机遇与挑战。为了适应这一变革,船舶制造企业需要加快数字化转型的步伐,提高生产效率、降低成本并增强市场竞争力…...

【网络编程】okhttp深入理解
newCall 实际上是创建了一个 RealCall 有三个参数:OkHttpClient(通用配置,超时时间等) Request(Http请求所用到的条件,url等) 布尔变量forWebSocket(webSocket是一种应用层的交互方式,可双向交互…...

大功率厚膜电阻器制造 – 优化性能?
通过优化工业大功率电阻器制造工艺,制造商可以提高电阻器的性能和可靠性、容差、额定电压、TCR、稳定性和额定功率。 在本文中,我们将介绍工业功率电阻器的制造过程。我们讨论了材料选择和生产技术及其对性能的潜在影响。 完美的电阻器 在其整个使用寿…...
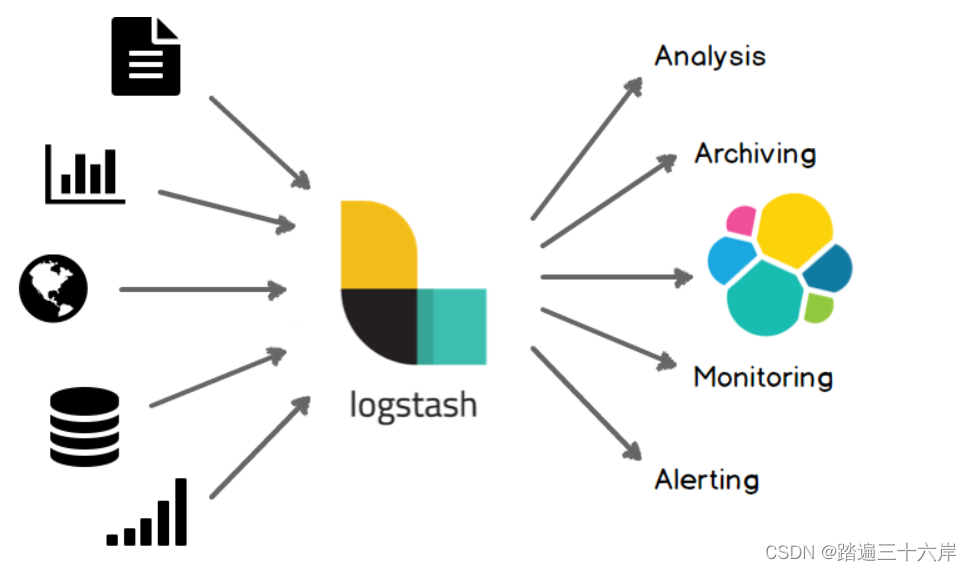
ElasticStack安装(windows)
官网 : Elasticsearch 平台 — 大规模查找实时答案 | Elastic Elasticsearch Elastic Stack(一套技术栈) 包含了数据的整合 >提取 >存储 >使用,一整套! 各组件介绍: beats 套件:从各种不同类型的文件/应用中采集数据。比如:a,b,cd,e,aa,bb,ccLogstash:…...

gitlab的使用
前一篇文章我们已经知道Git人人都是中心,那他们怎么交互数据呢? • 使用GitHub或者码云等公共代码仓库 • 使用GitLab私有仓库 目录 一、安装配置gitlab 安装 初始化 这里初始化完成以后需要记住一个初始密码 查看状态 二、使用浏览器访问…...
基于springboot+vue的植物健康系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

Python爬虫实战入门:爬取360模拟翻译(仅实验)
文章目录 需求所需第三方库requests 实战教程打开网站抓包添加请求头等信息发送请求,解析数据修改翻译内容以及实现中英互译 完整代码 需求 目标网站:https://fanyi.so.com/# 要求:爬取360翻译数据包,实现翻译功能 所需第三方库 …...
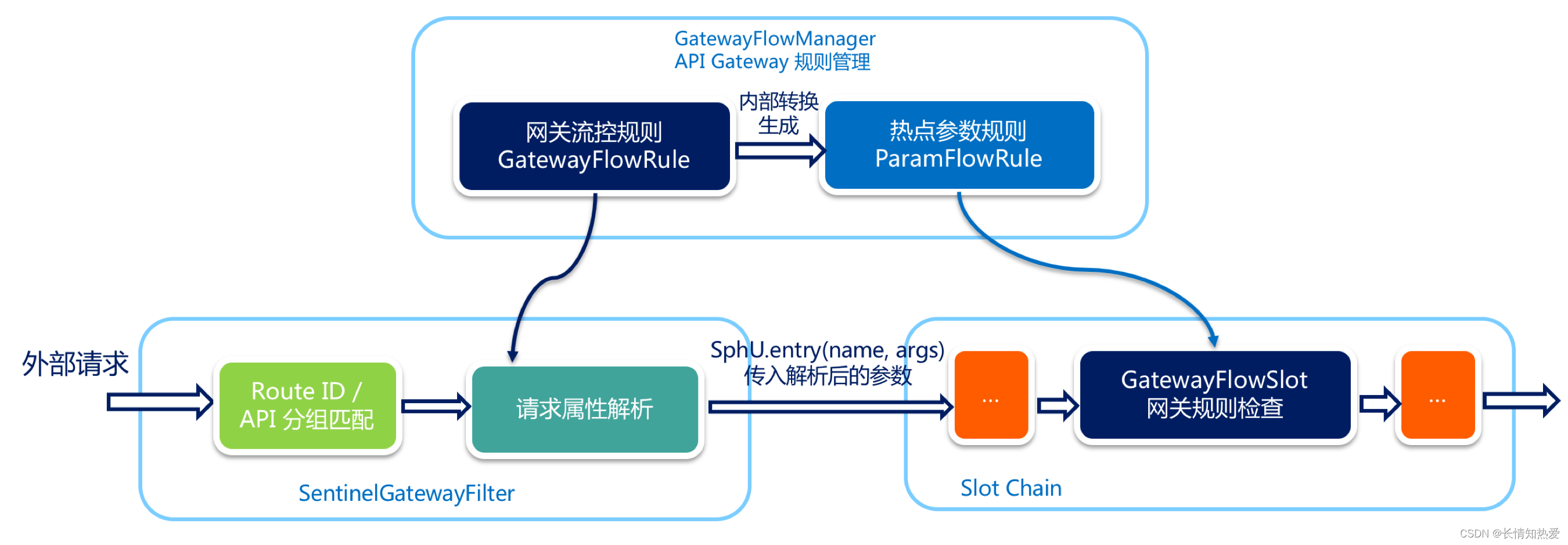
微服务-微服务API网关Spring-clould-gateway实战
1. 需求背景 在微服务架构中,通常一个系统会被拆分为多个微服务,面对这么多微服务客户端应该如何去调用呢? 如果根据每个微服务的地址发起调用,存在如下问题: 1.客户端多次请求不同的微服务,会增加客户端…...

告别打包失败!Matlab开发者必看:Runtime版本精准匹配与离线部署全攻略
MATLAB Runtime精准匹配与离线部署实战指南 当MATLAB开发者遭遇Runtime版本陷阱 深夜的办公室里,王工程师盯着屏幕上第7次打包失败的红色错误提示,揉了揉酸胀的眼睛。这个场景对许多MATLAB开发者来说并不陌生——明明在自己的R2022b Update 3环境中完美运…...

3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析
3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

题解:洛谷 U327333 Max Sum Plus Plus 2
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

3分钟掌握BilibiliDown:您的专业B站视频离线下载解决方案
3分钟掌握BilibiliDown:您的专业B站视频离线下载解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirror…...
)
手把手教你搭建低成本雷达测试环境:从暗室搭建到模拟器参数设置(基于国产设备实战)
低成本雷达测试环境搭建实战:国产设备方案与操作指南 在车载毫米波雷达研发领域,测试环节往往占据着项目预算的显著部分。传统方案依赖进口设备和专业暗室,动辄数百万元的投入让许多中小型团队望而却步。本文将揭示一个行业内的真实情况&…...

在OpenClaw项目中接入Taotoken实现多模型Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw项目中接入Taotoken实现多模型Agent工作流 对于使用OpenClaw框架构建智能体工作流的开发者而言,如何稳定、灵…...

云英谷开启招股:拟募资11亿港元 5月27日上市 小米华为红杉是股东
雷递网 雷建平 5月18日云英谷科技股份有限公司(简称:“云英谷”,股票代码:“03310”)日前开启招股,准备2026年5月27日在港交所上市。云英谷发行价为20.81港元,发行5285.92万股,募资总…...

探索Artisan:用开源软件解码咖啡烘焙的数据科学
探索Artisan:用开源软件解码咖啡烘焙的数据科学 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan 在咖啡烘焙的世界里,每一次烘焙都是一次精确的化学反应。从…...

STM32驱动OV7670摄像头,从寄存器配置到LCD显示的避坑全记录
STM32与OV7670摄像头实战:从寄存器配置到LCD显示的全链路解析 1. 项目背景与硬件架构设计 在嵌入式视觉系统中,OV7670作为一款低成本CMOS图像传感器,与STM32的组合常被用于智能门禁、工业检测等场景。本项目的核心挑战在于解决传感器输出数据…...

LATENCY和INITIATION_INTERVAL同时约束时HLS决策
一、关于Latency和II同时约束 1.对同一个设计的II和latency同时约束,这两者在很多情况下是存在冲突的。 2.对同一个函数或者循环,使用HLS调度器来优化,HLS调度器内置设置了一些优先级的规则, 这种规则大多情况和设计者的直觉不一样…...