MySQL|MySQL基础(求知讲堂-学习笔记【详】)
MySQL基础
目录
- MySQL基础
- 一、 MySQL的结构
- 二、 管理数据库
- 1)查询所有的数据库
- 2)创建数据库
- 3)修改数据库的字符编码
- 4)删除数据库
- 5)切换操作的数据库
- 三、表的概念
- 四、字段的数据类型
- 4.1 整型
- 4.2 浮点型(float和double)
- 4.3 定点数
- 4.4 字符串
- 4.5 二进制数据
- 4.6 日期时间类型
- 五、管理表
- 5.1 查看当前数据库的所有表
- 5.2 创建表
- 5.3 修改表
- 1)给表添加一个字段
- 2)给表添加多个字段
- 3)修改字段数据类型
- 4)修改字段的名称
- 5)删除表的一到多个字段
- 6)修改表名
- 5.4 删除表
- 5.5 查看表结构
- 5.6 当然,也可以使用工具管理表,学习课程推荐[在这里(时长:8'47'')](https://www.bilibili.com/video/BV1e64y117iM/?p=18&vd_source=af535a87de5ddfde1f3bdd19bbbc73b9)(更简便---但是上面咱们列出来的SQL语言也要知道)
- 六、管理数据(从这开始是重点内容)
- 6.1 查询表的所有数据
- 6.2 给表插入数据
- 6.3主键-自动增长及字段-默认值设置
- 6.4 修改数据
- 6.4 删除表
- 七、 查询数据(重点)
- 7.1 简单查询
- 7.2 条件查询
- 7.2.1 比较条件
- 7.2.2 逻辑条件
- 7.2.3 判空条件
- 7.2.4 模糊条件
- 7.3 聚合查询
- 7.4 排序查询
- 7.5 分页查询
- 7.6 分组查询
- 7.7 sql中完成if判断
- 7.7.1 case流程控制函数
- 7.7.2 IF()函数
- 7.7.3 字符串的集合操作ELT()
- 八、附源码
一、 MySQL的结构
先有数据库 --> 再有表 -->再有数据(行 --> 列)
MySQL可以创建多个数据库,一个库可以创建多张表,一张表有多行数据,一行数据有多个列(字段)

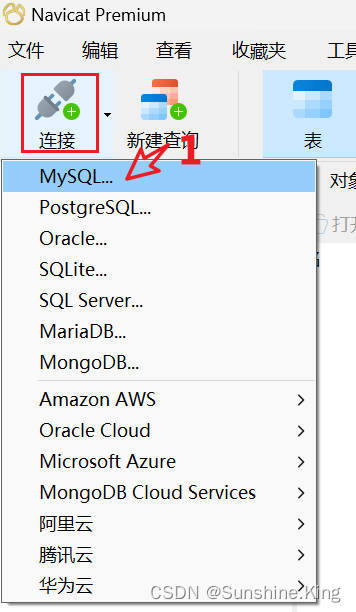



二、 管理数据库
注意:mysql的关键字不区分大小写
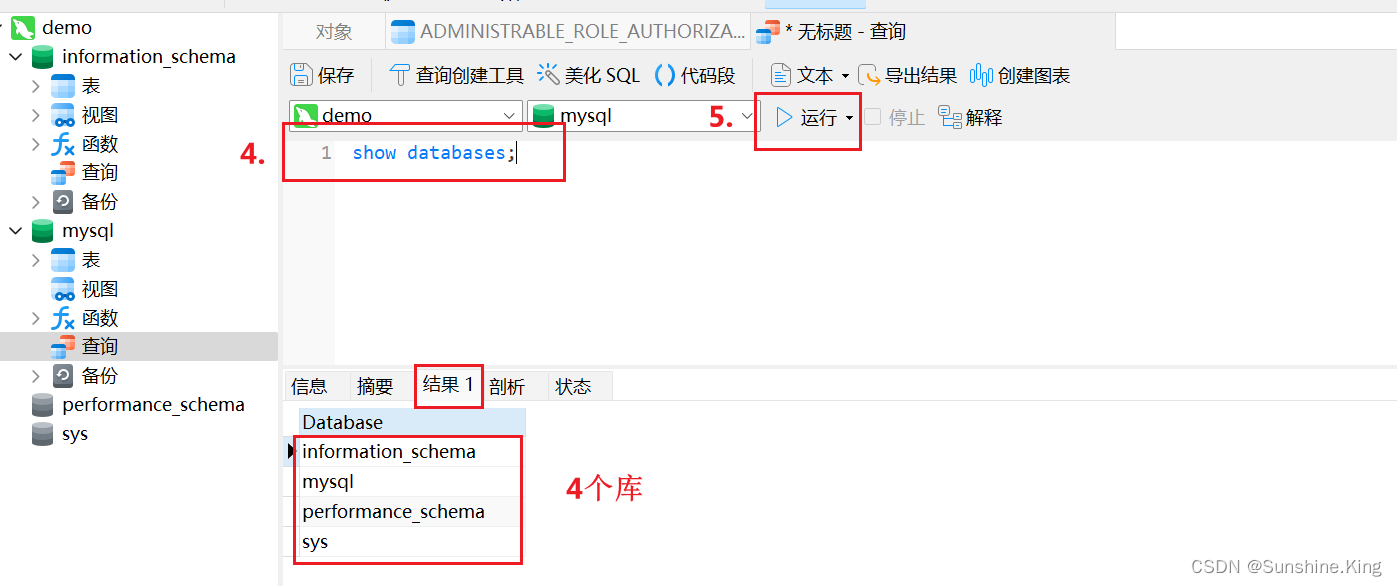
1)查询所有的数据库
show databases;
2)创建数据库
格式:
create database 数据库名 default character set 字符编码 collate 字符编码校验规则;
示例:
create database demo default character set utf8 collateutf8_general_ci;
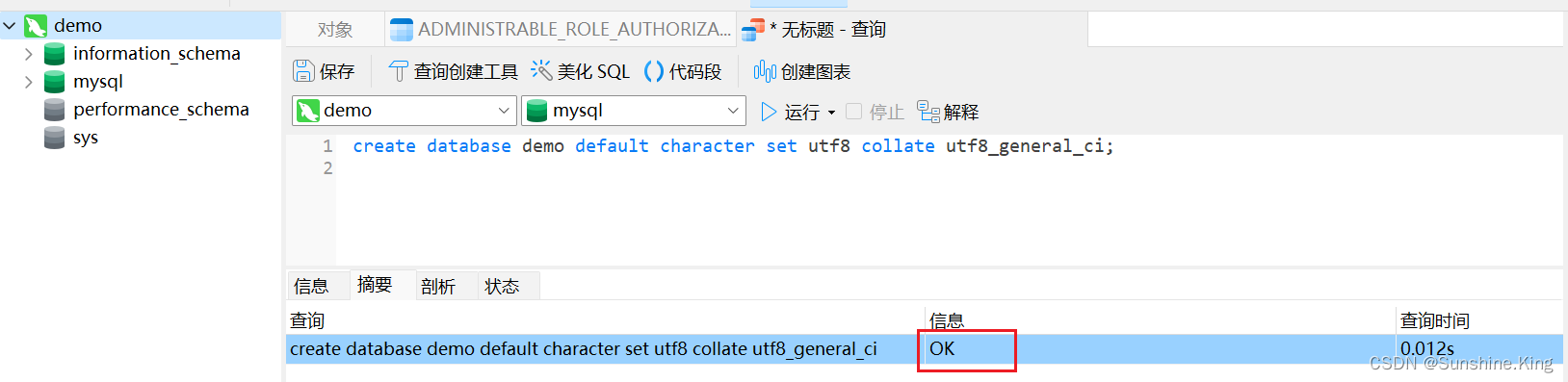
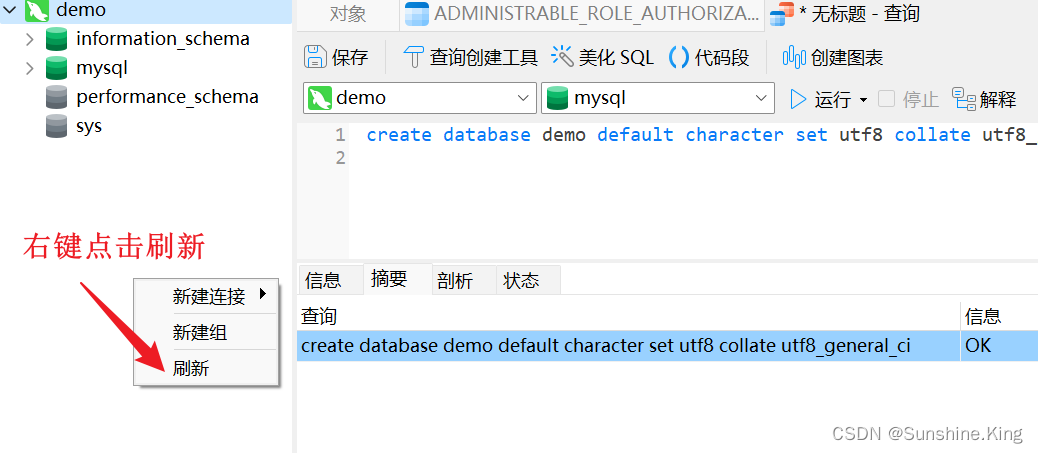
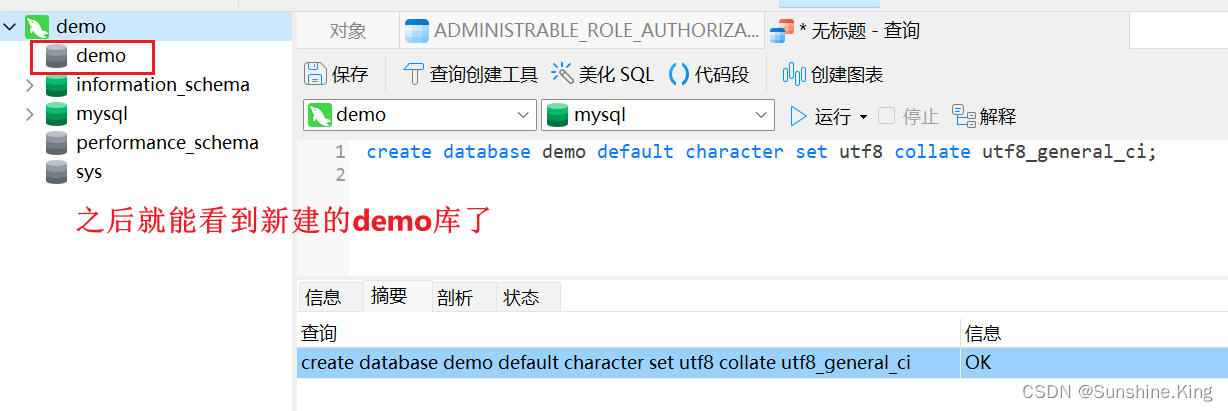
方法二(使用工具,删除数据库等操作也同理):右键
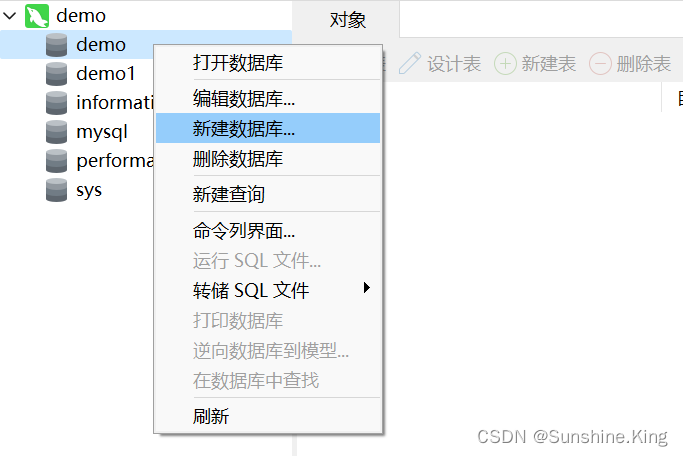
3)修改数据库的字符编码
格式:
alter database 数据库名 default character set 字符编码;
例:
alter database demo default character set gbk;
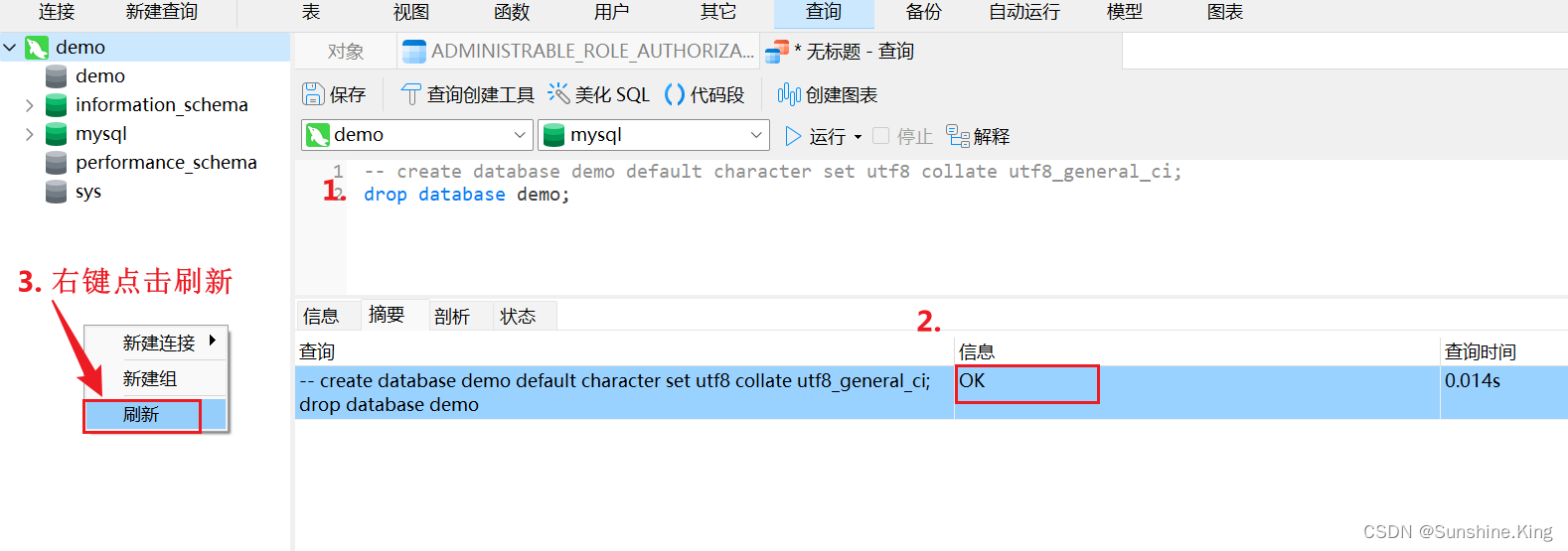
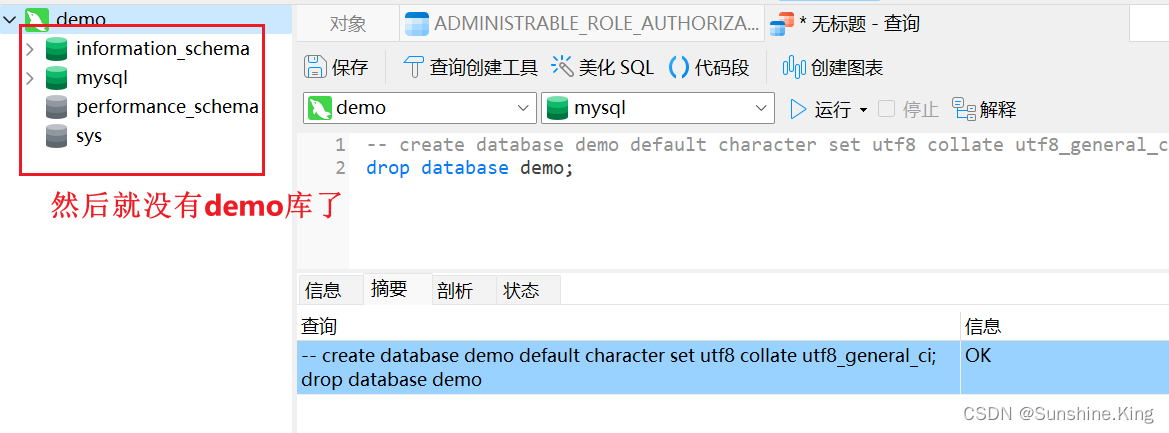
4)删除数据库
格式:
drop database 数据库名;
示例:
drop database demo;
5)切换操作的数据库
格式:
use 数据库名;
示例:
use demo;
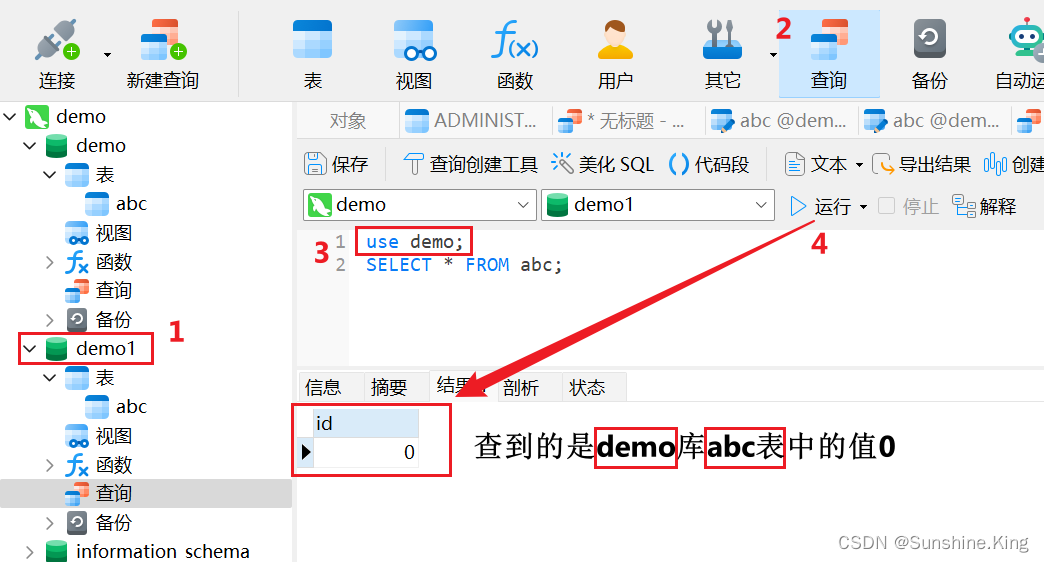
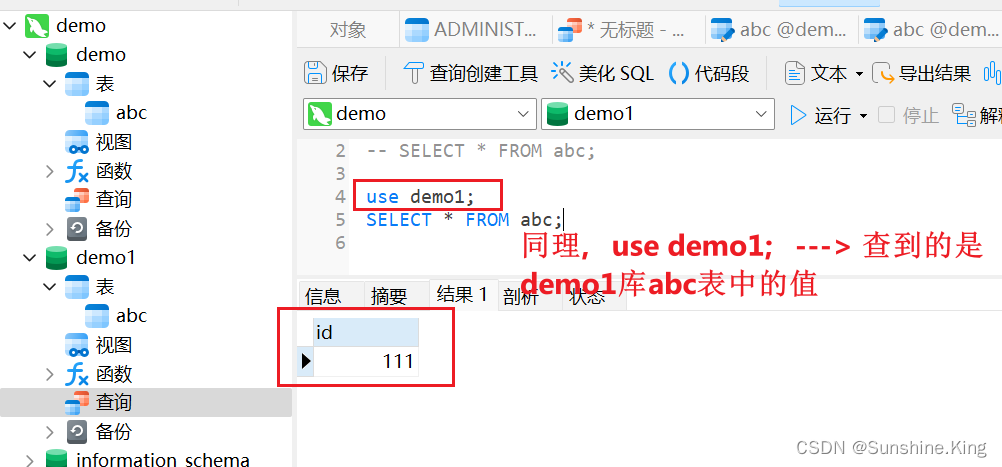
①. 先创建两个库:demo、demo1;
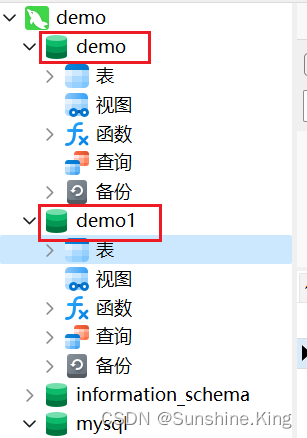
②. 各自创建一个表(这里创建的abc表);
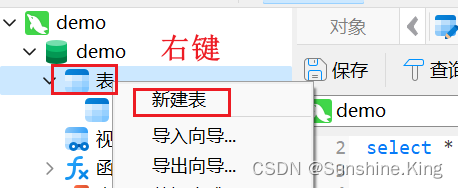

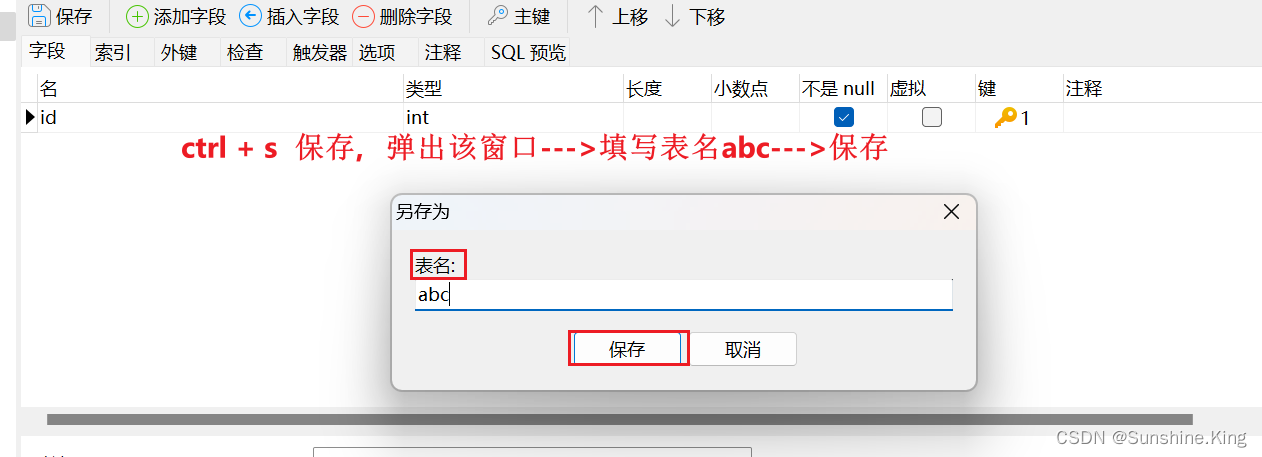
demo1同理
③. 表里添加数据(demo:0;demo1: 111);
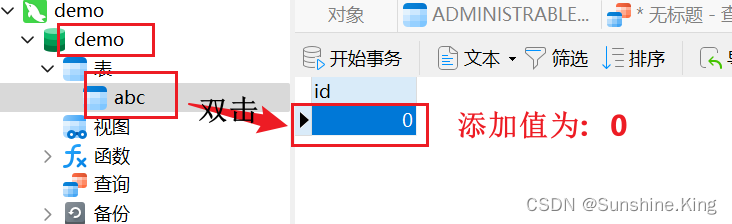
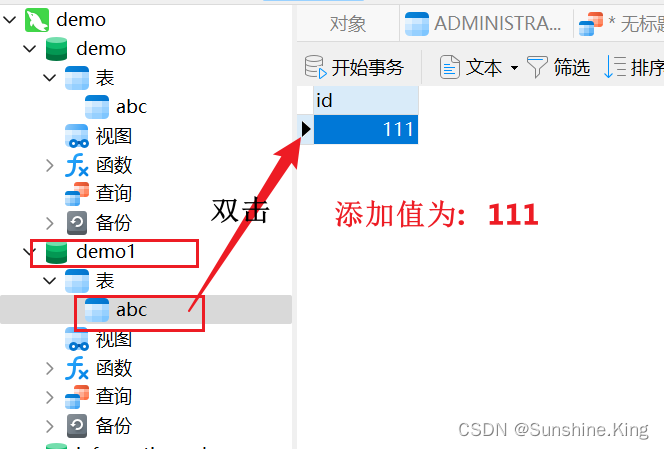
三、表的概念
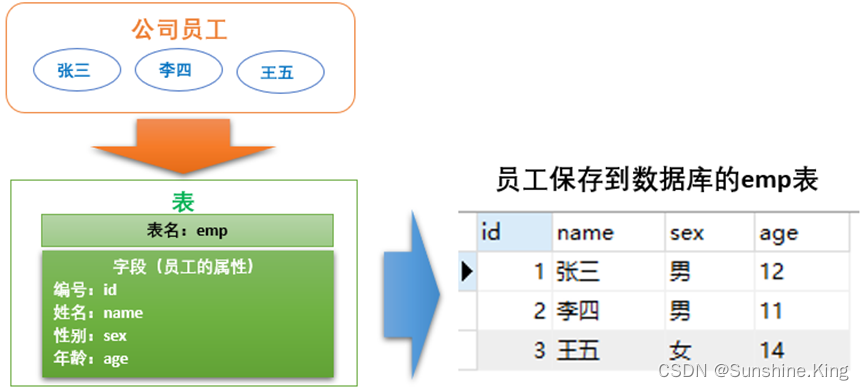
如果要把公司的所有员工都存到数据库:
1.需创建一个表来保存员工信息,给表一个名字—emp,且这个表名在当前的数据库下表名是唯一的,一般表名的命名要见名知义,首选英文名称;
2.给表定义要存什么,员工是一个概念,对于要存员工的什么(信息)进行进一步的分解,根据实际情况来分解—id、姓名、性别、年龄;
3.表存数据是以行的形式来存储,一个行数据就一个完整的概念,对于该emp表来说,它的一行数据就一个员工;
4.在步骤2,我们又知道员工的整体概念被分解一个个单独信息(id,姓名,性别,年龄),这些就被称为一行的多个列,正是这些多个列的信息构成一行完整的数据;
5.被分解一个个单独信息,我们称之为字段(属性);
6.表名—字段名的关系,具体到我们现在的员工表的例子,就是员工有哪些字段(属性),这样就通过表名—字段名这样的形式,就把员工给描述清楚了;
7.字段名和表名也是一样,最好有含义,首选英文名称;
四、字段的数据类型
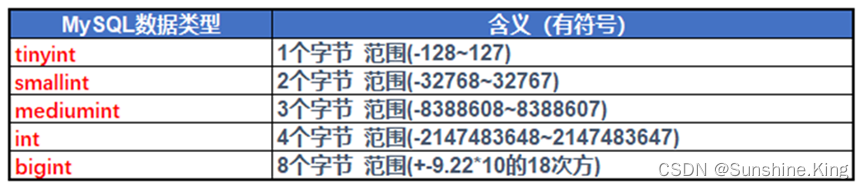
4.1 整型
存整数的
4.2 浮点型(float和double)
- 存小数,使用的时候看需要多大的精度(有效数字)
- 浮点型是存储近似值,不适合用来存储必须精确的数值,例如金钱

4.3 定点数
存储精确的数值

m代表有效数字的位数,在1~65之间。
d代表小数位,在0~30之间,但是同时需要d<m。
注:浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值
4.4 字符串

4.5 二进制数据
- 保存图片、压缩包、视频
- 这些如果保存到数据库,先把这些转成二进制的数据,再保存到数据库
- 这个不太常用,因为我们现在有其他更好的方式来存储这些大的文件
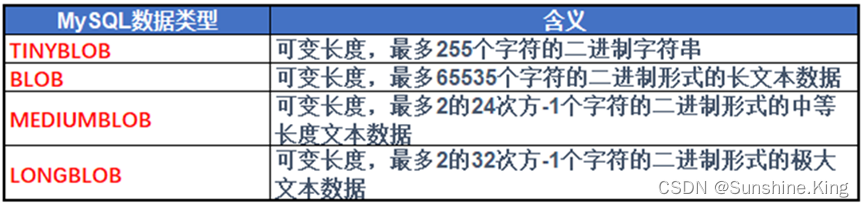
4.6 日期时间类型

注:
TIMESTAMP和DATETIME的不同点:
1、两者的存储方式不一样
对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。而对于DATETIME,不做任何改变,基本上是原样输入和输出。
2、两者所能存储的时间范围不一样
timestamp所能存储的时间范围为:‘1970-01-01 00:00:01.000000’ 到 ‘2038-01-1903:14:07.999999’。
datetime所能存储的时间范围为:‘1000-01-01 00:00:00.000000’ 到 ‘9999-12-3123:59:59.999999’。
总结:TIMESTAMP和DATETIME除了存储范围和存储方式不一样,没有太大区别。当然,对于跨时区的业务,TIMESTAMP更为合适。
五、管理表
注意:mysql的关键字不区分大小写
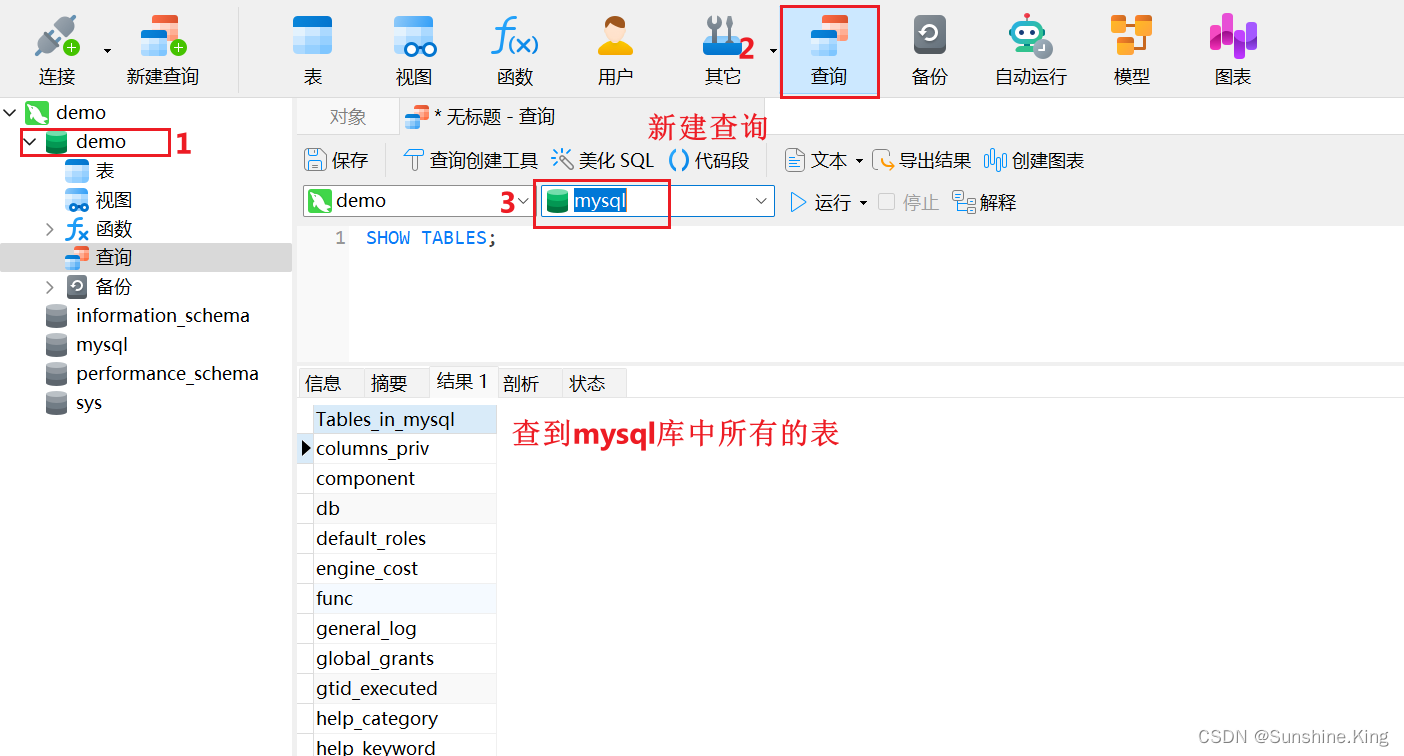
5.1 查看当前数据库的所有表
#查看当前操作的数据库有哪些表
show tables;
5.2 创建表
格式:
CREATE TABLE 表名 (字段名 字段类型 NOT NULL AUTO_INCREMENT, //主键的值不能是null字段名 字段类型 , ... 字段名 字段类型 ,PRIMARY KEY (字段名)) ;
** 示例 :**
#创建学生表
create table student(id int(10) not null,name varchar(100),age int(2),primary key(id)
);
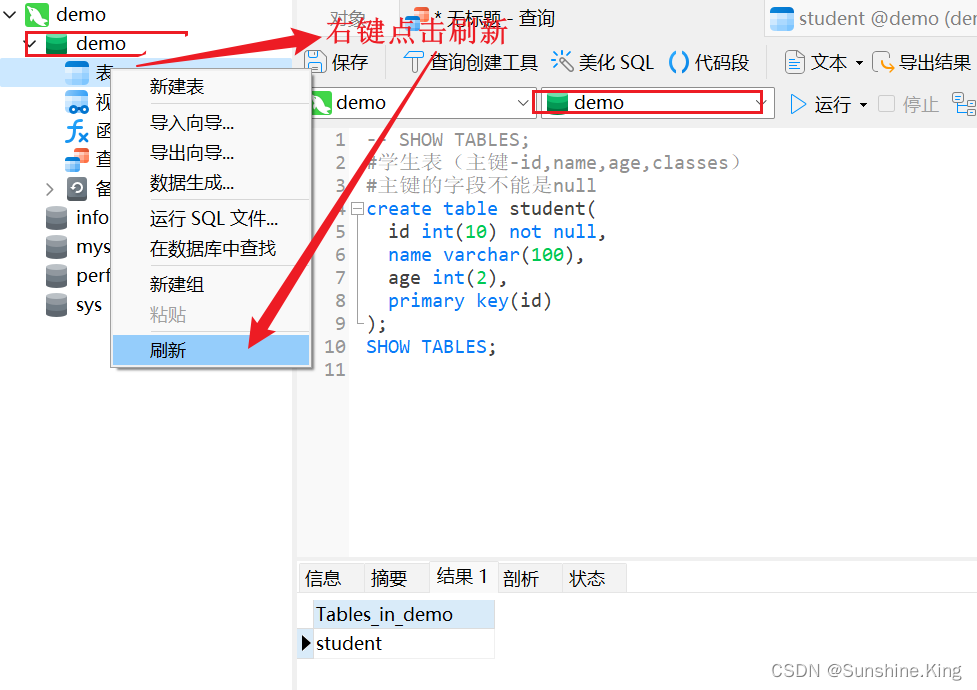

5.3 修改表
1)给表添加一个字段
格式:
alter table 表名 add column 字段名 字段类型;
示例:
alter table student add column classes varchar(10);
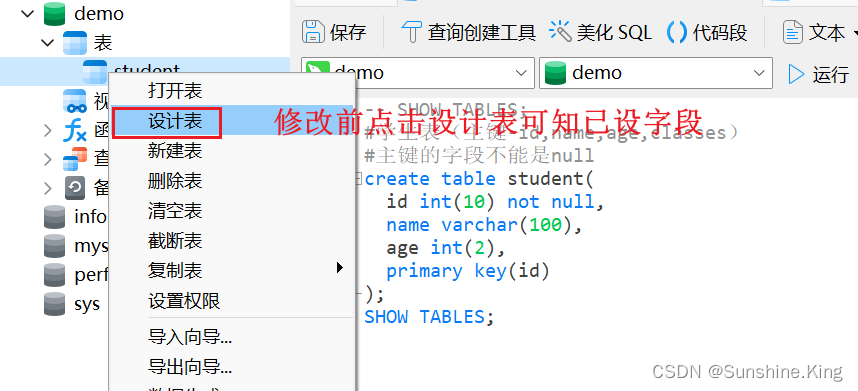
已设字段:
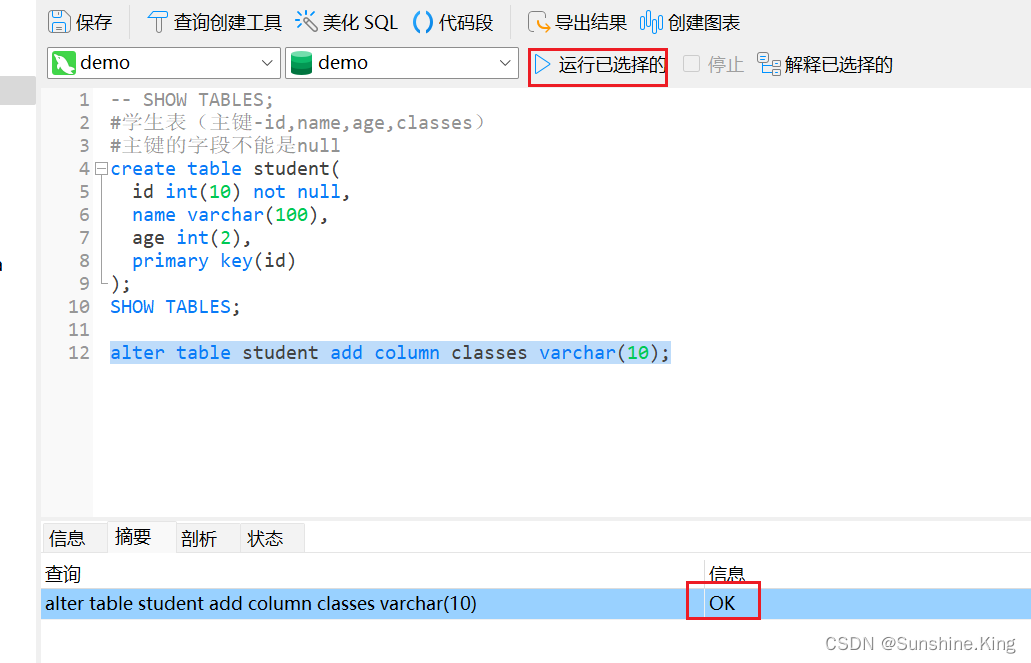
再点击设计表:
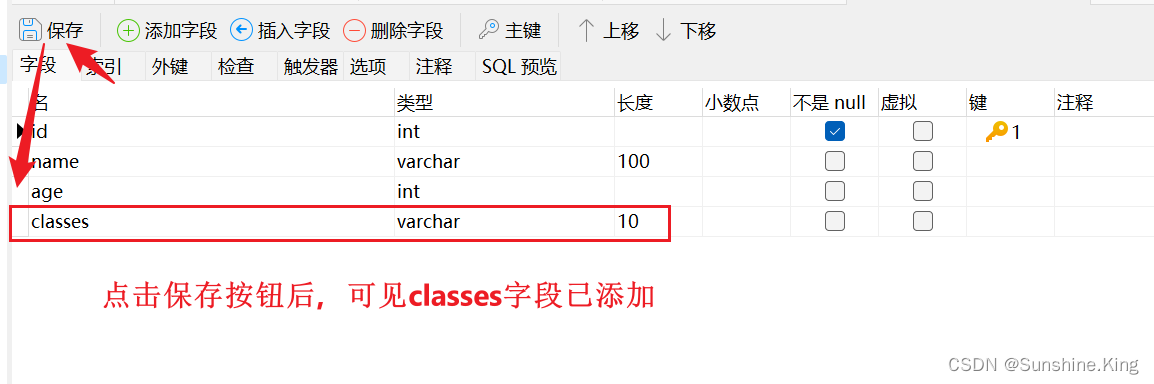
2)给表添加多个字段
格式:
alter table 表名 add 字段名 字段类型,add 字段名 字段类型,...,add 字段名 字段类型;
示例:
alter table student add a int,add b int,add c int;
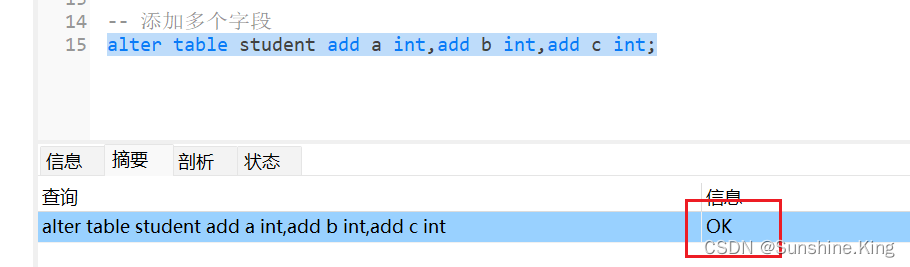
点击设计表–>点击保存–>可见a,b,c字段:
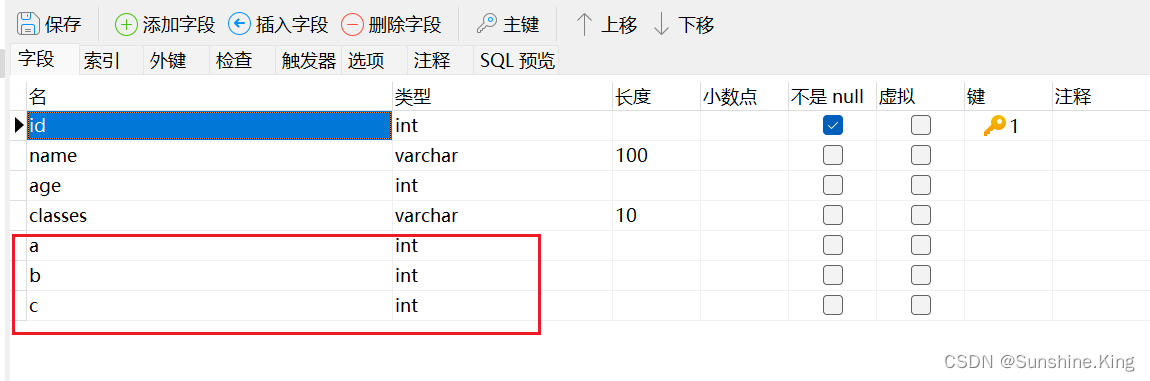
3)修改字段数据类型
格式:
alter table 表名 modify column 字段名 字段类型;
示例:
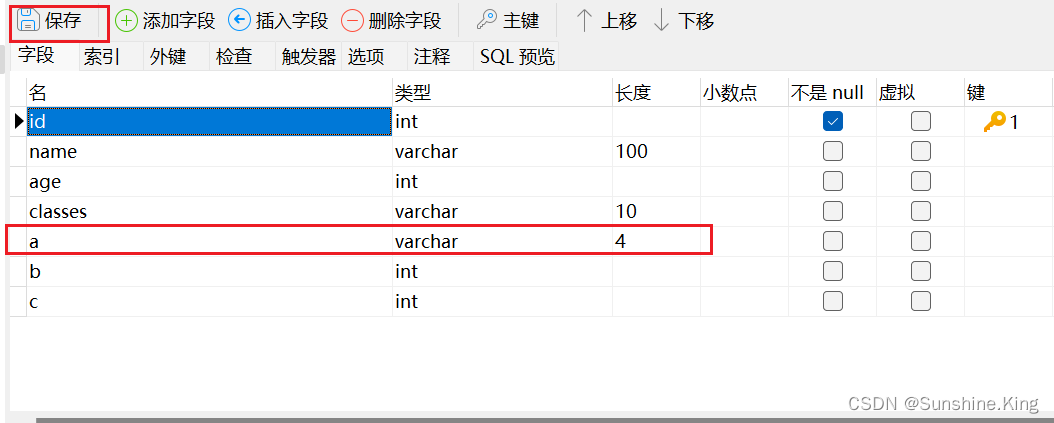
alter table student modify column a varchar(4);
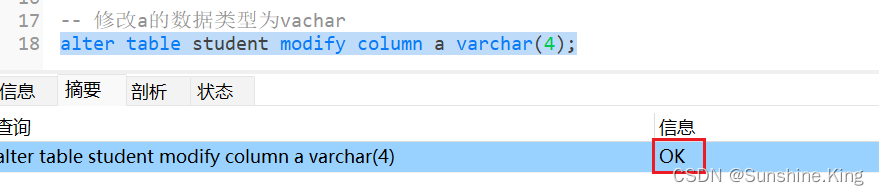
点击设计表–>点击保存–>
4)修改字段的名称
格式:
alter table 表名 change column 原字段名 新字段名 字段的数据类型;
示例:
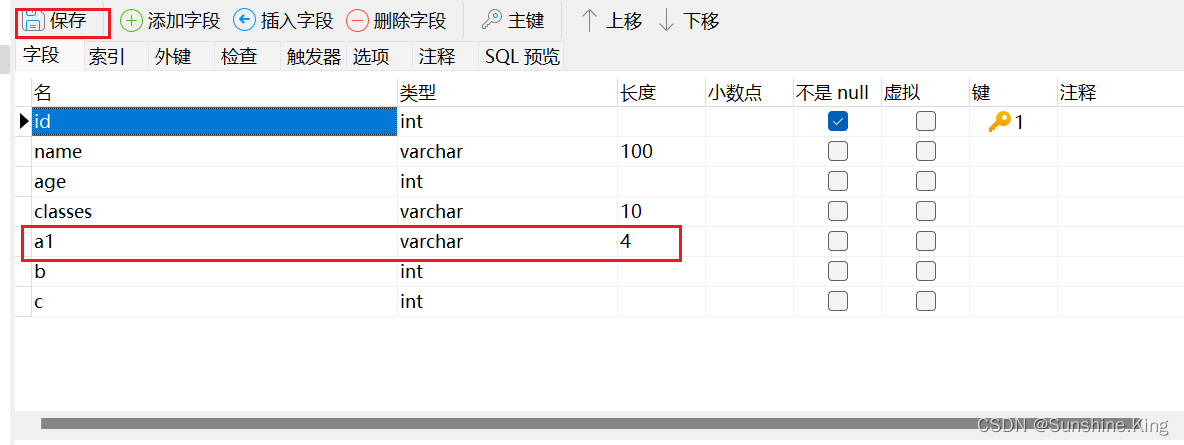
alter table student change column a a1 int;
点击-运行已选择的–>
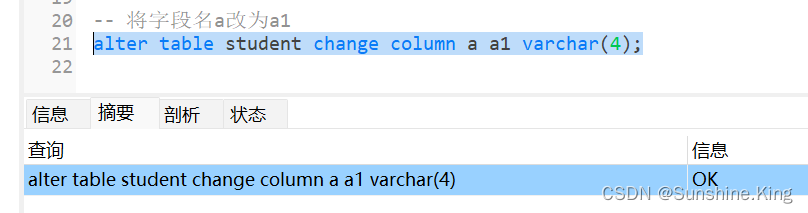
点击设计表–>点击保存–>
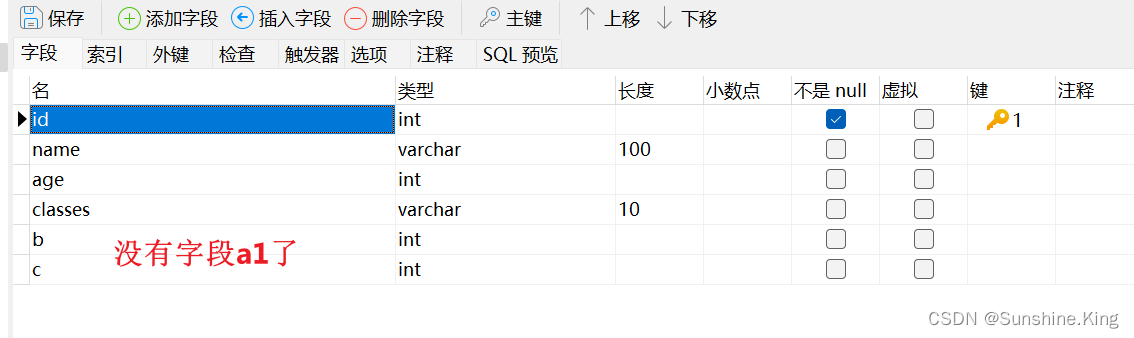
5)删除表的一到多个字段
格式:
alter table 表名 drop column 字段名;alter table 表名 drop column 字段名,...,drop column 字段名;
示例:
alter table student drop column a1;alter table student drop column b,drop column c;
点击-运行已选择的–>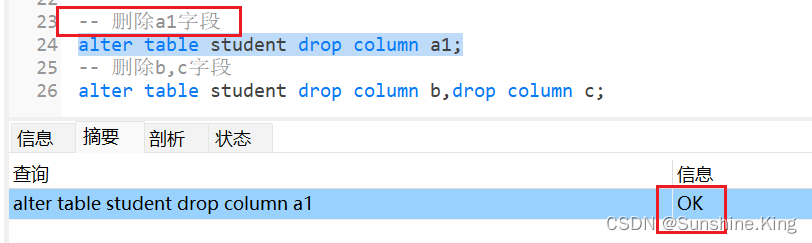
点击设计表–>点击保存–>
6)修改表名
格式:
alter table 原表名 rename to 新表名;
示例:
alter table student rename to stu;
点击-运行已选择的–>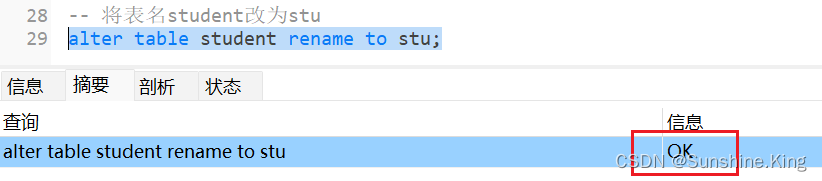
刷新可见表名改为了stu: 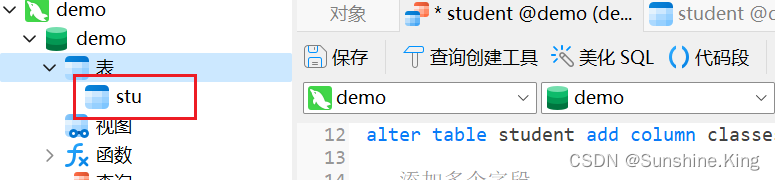
5.4 删除表
格式:
drop table 表名;
示例:
drop table stu;
点击-运行已选择的–>

刷新后不见stu表了:
5.5 查看表结构
格式:
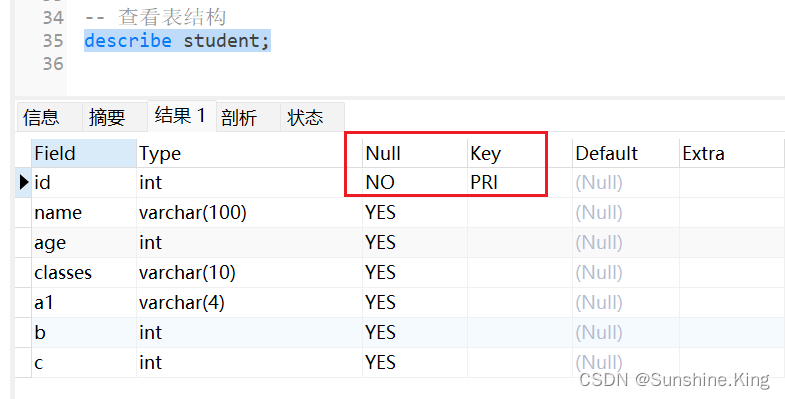
describe 表名;
示例:
describe student;
点击-运行已选择的–>
5.6 当然,也可以使用工具管理表,学习课程推荐在这里(时长:8’47’')(更简便—但是上面咱们列出来的SQL语言也要知道)
六、管理数据(从这开始是重点内容)
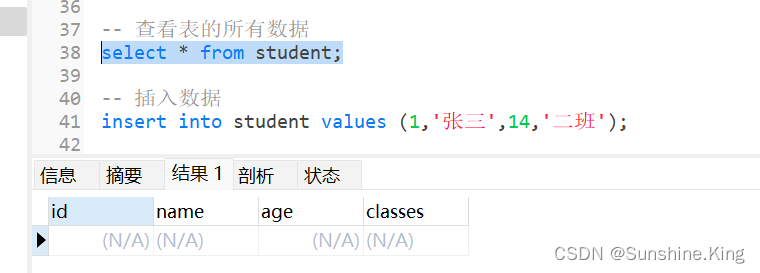
6.1 查询表的所有数据
格式:
select * from 表名;
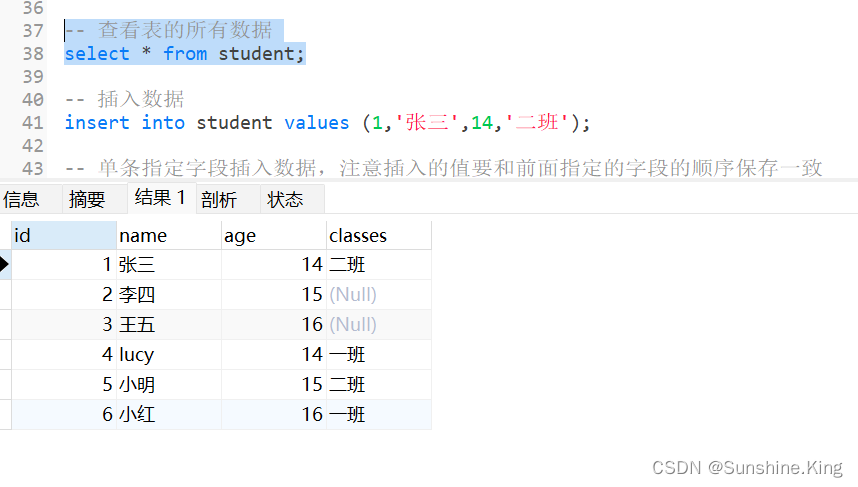
示例(这里又新建了一张student表):
select * from student;
点击-运行已选择的–>

6.2 给表插入数据
1)单条全量插入数据,注意 ''(一组单引号)代表字符串,在给所有字段插入数据时,要根据表结构的字段顺序—设计表中的顺序—给值
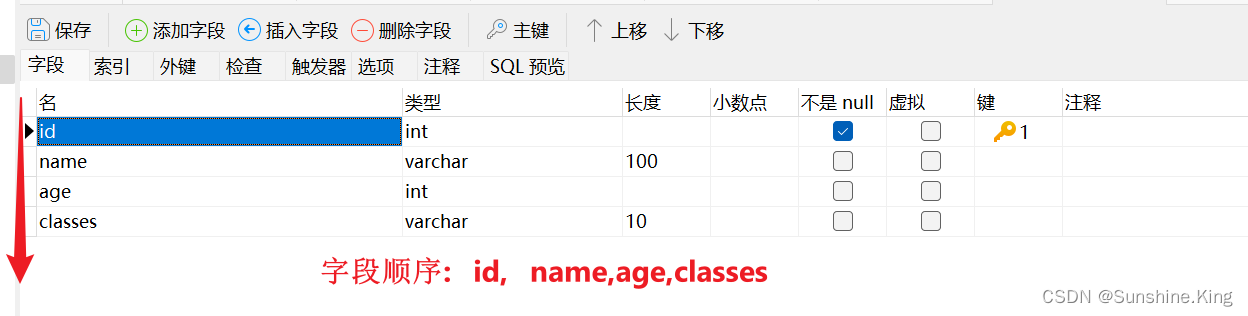
** 格式:**
insert into 表名 values (字段1的值,字段2的值,...,字段n的值);
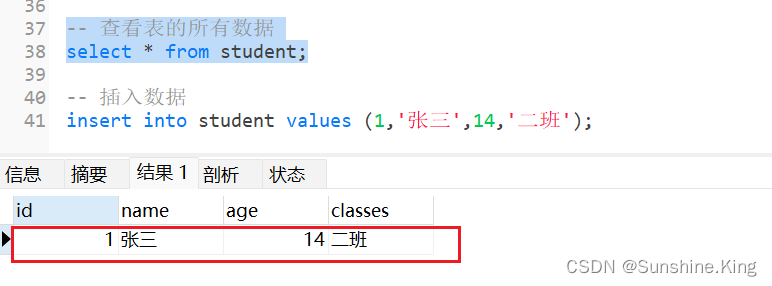
示例:
insert into student values (1,'张三',14,'男');

2)单条指定字段插入数据
格式:
insert into 表名 (字段1,字段2,...,字段n) values (字段1的值,字段2的值,...,字段n的值);
insert into 表名 (字段1,字段3,字段5) values (字段1的值,字段3的值,字段5的值);
示例:
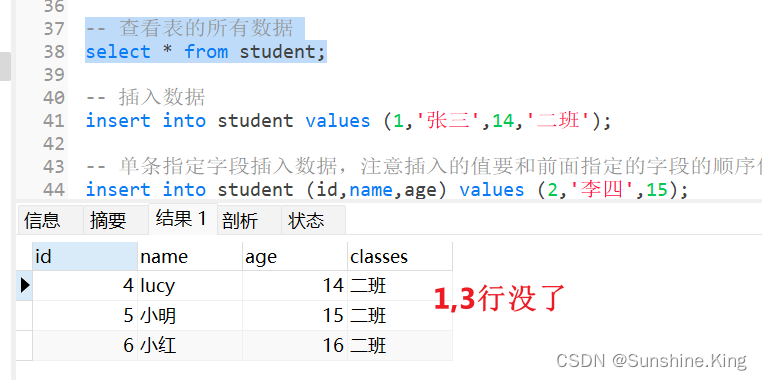
insert into student (id,name,age) values (2,'李四',15);
insert into student (name,age,id) values ('王五',16,3);

注:插入的值要和前面指定的字段的顺序保存一致
3)批量插入数据
格式:
insert into 表名 values (字段1的值,字段2的值,...,字段n的值),(字段1的值,字段2的值,...,字段n的值),...(字段1的值,字段2的值,...,字段n的值);
示例:
insert into student values (4,'lucy',14,'一班'),(5,'小明',15,'二班'),(6,'小红',16,'一班');
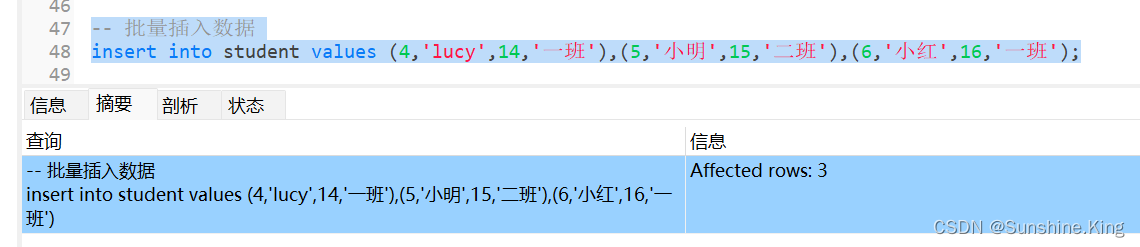
注:在插入数据时,如果某一个字段是自动递增的,可以不用插入这个字段的值,而由数据库自己计算填充
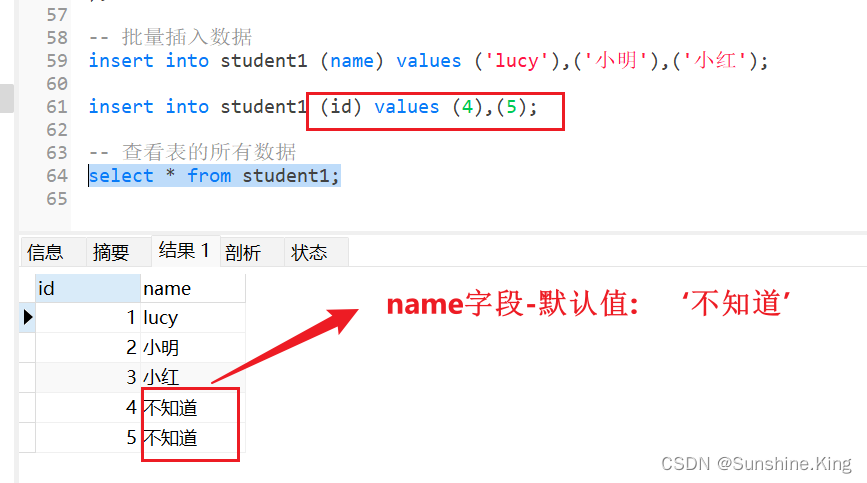
6.3主键-自动增长及字段-默认值设置
格式:
主键字段名 字段类型 not null auto_increment,#主键-自动增长auto_increment
字段名 字段类型 default '这里写要设置的默认值',#字段默认值设置default--
示例:
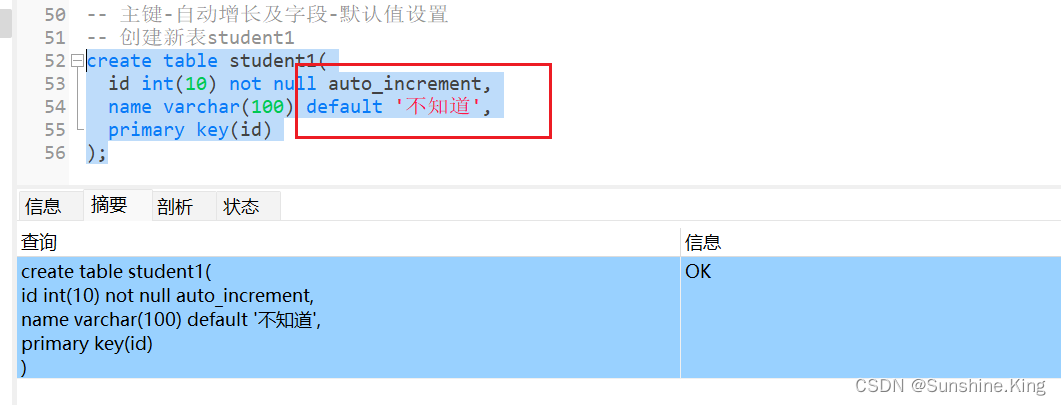
-- 创建新表student1
create table student1(id int(10) not null auto_increment,#主键-自动增长auto_incrementname varchar(100) default '不知道',#字段默认值设置default--primary key(id)
);
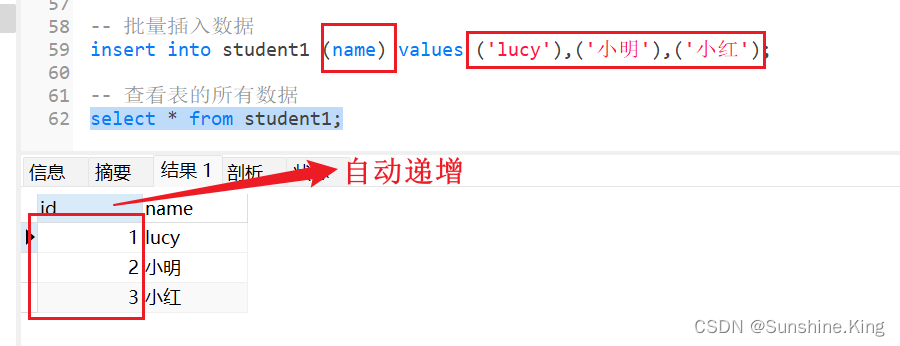
-- 批量插入数据
-- 主键自动递增
insert into student1 (name) values ('lucy'),('小明'),('小红');
-- 表的字段有默认值,则不给其值的话-就自动填默认值
insert into student1 (id) values (4),(5);-- 查看表的所有数据
select * from student1;
6.4 修改数据
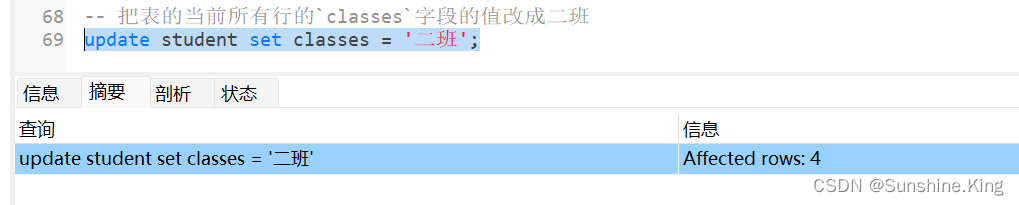
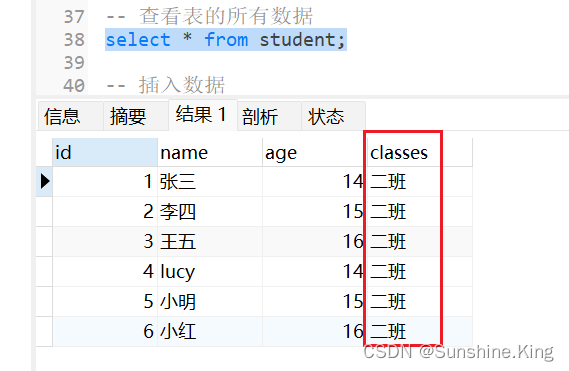
1)修改一到多个指定字段的所有行的值
格式:
update 表名 set 字段名 = 值,字段名 = 值,...,字段名 = 值;
示例:
把表的当前所有行的classes字段的值改成二班:
update student set classes = '二班';
2)按条件修改指定字段的值
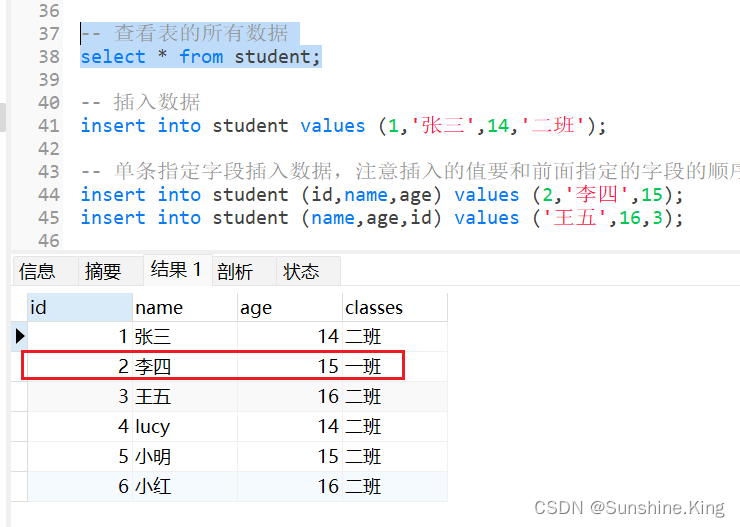
格式:
update 表名 set 字段名 = 值 where 字段名 = 值;
示例:
把id为2的学生的班级修改为一班
update student set classes = '一班' where id = 2;

3)按条件修改一到多个指定字段的所有行的值
-
这种查询是前面2种查询的结合使用
-
按条件改表某一行的某几个字段,注意不加where条件会改变当前所有行的数据
格式:
update 表名 set 字段名 = 值,字段名 = 值,...,字段名 = 值 where 字段名 = 值;
示例:
把id为3的学生的姓名改为张三,年龄改为12,班级改为一班
update student set name = '张三',age = 12,classes = '一班' where id = 3;

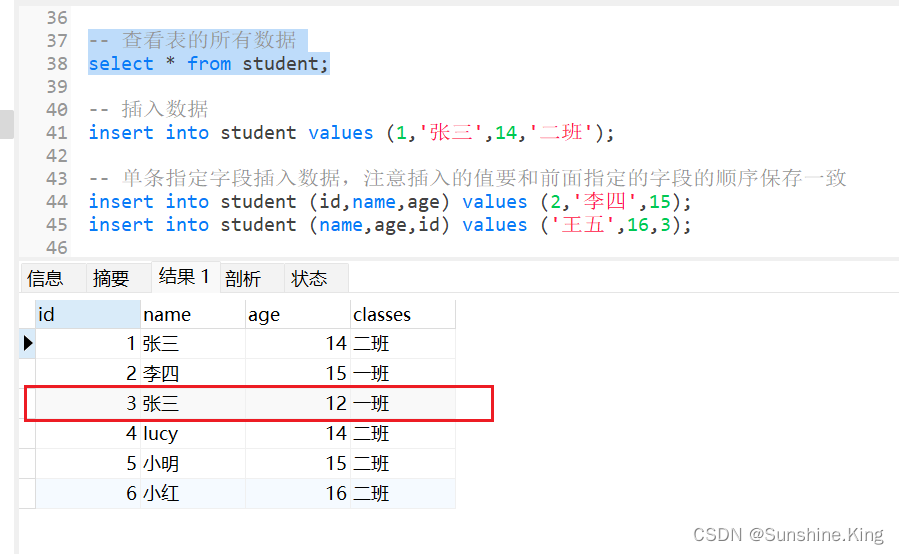
6.4 删除表
删除表都是按行删除
1)按条件删除
格式:
delete from 表名 where 字段名 = 值;
示例:
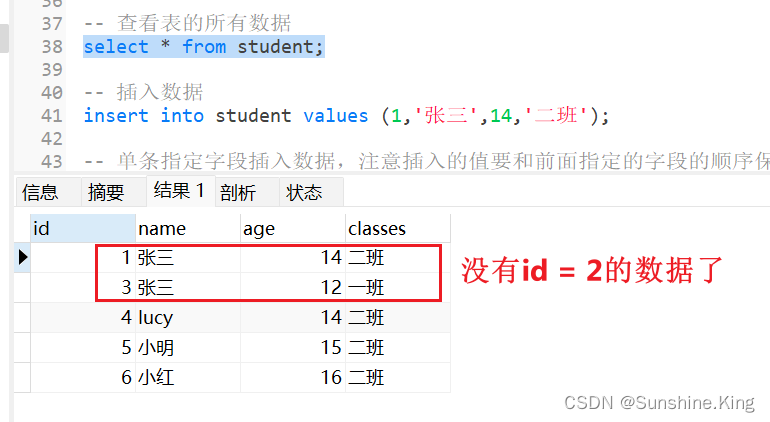
删除学生表中id为2的对应行数据
delete from student where id = 2;

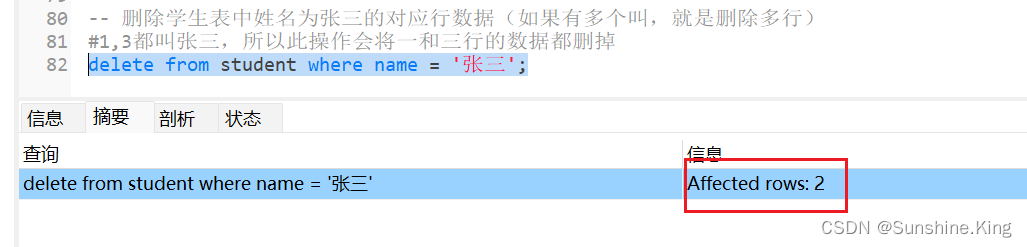
删除学生表中姓名为张三的对应行数据(如果有多个叫,就是删除多行)
delete from student where name = '张三';
2)整体删除,删除表当前的所有行数据
格式:
delete from 表名;
示例:
删除学生表的所有行数据
delete from student;

注:
如果表中有字段是字段递增类型的,使用delete删除全表后,自动递增的起始点保留。例如,一个表的id已经自动递增到了10,那么使用delete删除全表后,再次insert插入数据时,id是从10继续往后递增,而不会从0开始计算。
如果想要让自动递增也回归初始状态,需要把表drop掉,然后重新建表。
另外,如果表中有字段是字段递增类型的时候,删除中间的某条数据,不会影响递增的累加。例如,一个表的id已经自动递增到了10,那么使用delete删除id为3的那行数据,再次insert插入数据时,id是从10继续往后递增,中间缺失的3就缺失了,除非你在insert的时候指定插入的id字段的值为3。
七、 查询数据(重点)
7.1 简单查询
1)查询所有列
格式:
select * from 表名;
示例:
select * from student;
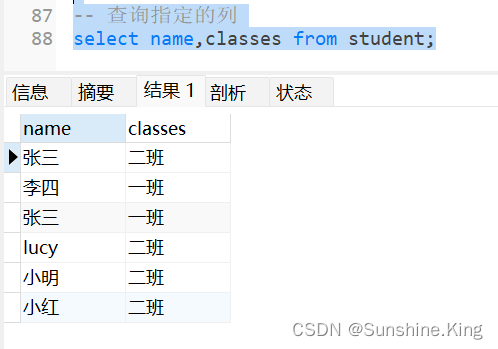
2)查询指定的列
格式:
select 字段,字段,...,字段 from 表名;
示例:
select name,classes from student;
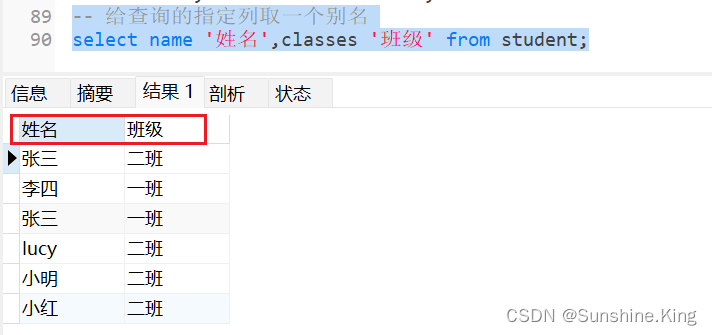
3)给查询的指定列取一个别名
格式:
select 字段名 别名,字段名 别名 from 表名;
示例:
select name '姓名',classes '班级' from student;
注:取别名在多表联合查询时可能会用,例如表a有一个字段叫name,表b有一个字段叫name,我们就可以通过设置别名来区分这两个name
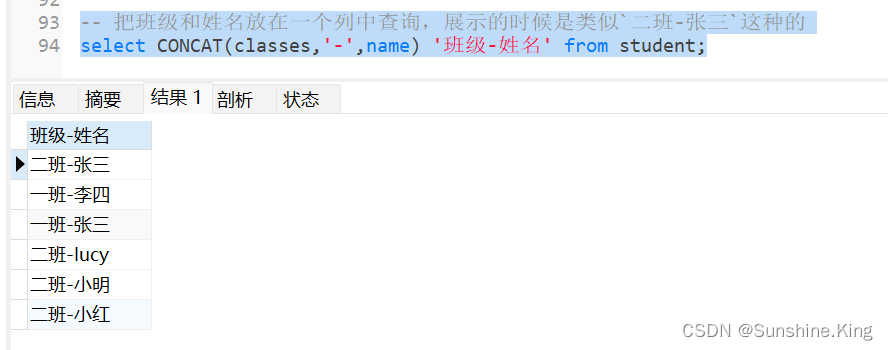
4)合并列查询
例如,我们想做把班级和姓名放在一个列中查询,展示的时候是类似二班-张三这种的
select CONCAT(classes,'-',name) '班级-姓名' from student;
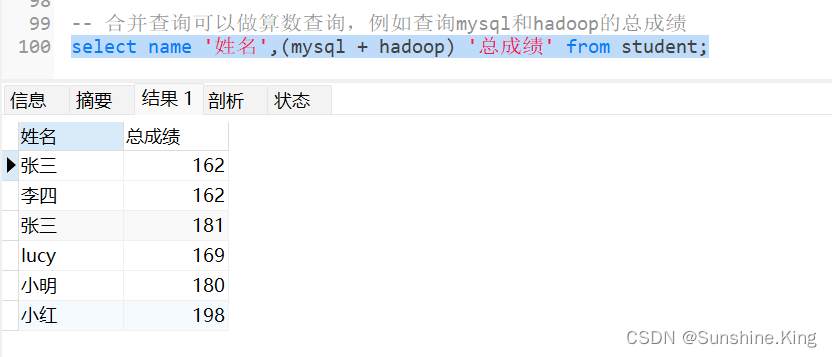
合并查询可以做算数查询,例如查询mysql和hadoop的总成绩
select name '姓名',(mysql + hadoop) '总成绩' from student;
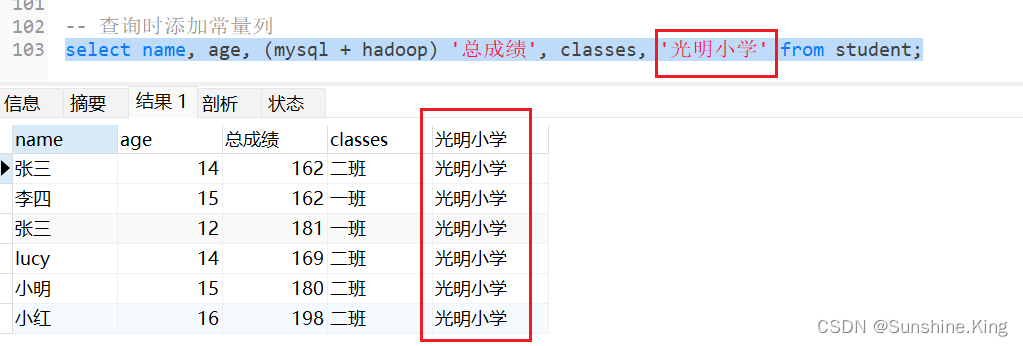
5)查询时添加常量列
就是直接查询一个普通的字符串,这个字符串在查询中就会作为一个常量在结果集中展示
select name, age, (mysql + hadoop) '总成绩', classes, '光明小学' from student;
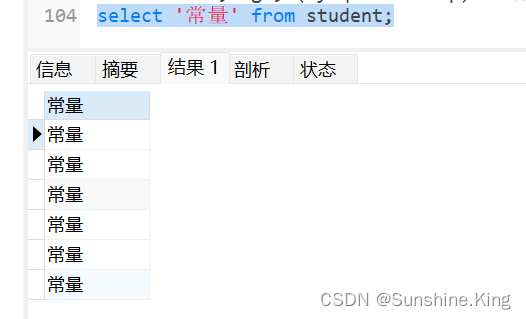
select '常量' from student;
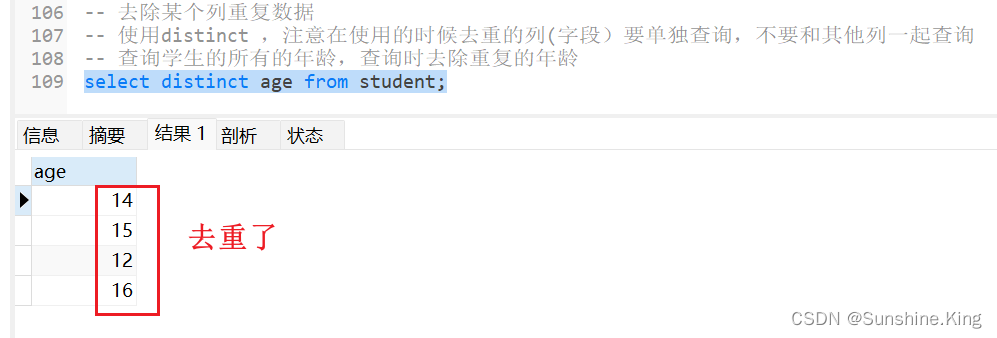
6)去除某个列重复数据
使用distinct ,注意在使用的时候去重的列(字段)要单独查询,不要和其他列一起查询
格式:
select distinct 字段名 from 表名;
示例:
查询学生的所有的年龄,查询时去除重复的年龄
select distinct age from student;
7.2 条件查询
基本格式:
select 字段,字段,...,字段 from 表名 where 查询条件;
7.2.1 比较条件
| 符号 | 含义 |
|---|---|
| = | 等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| != | 不等于 |
| between and | 在a和b两个值之间,包含a和b |
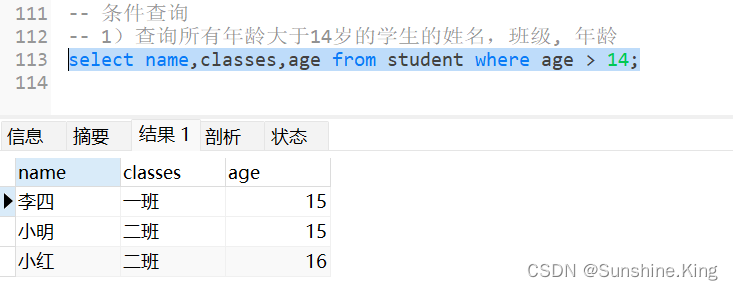
1)查询所有年龄大于14岁的学生的姓名,班级,年龄
select name,classes,age from student where age > 14;
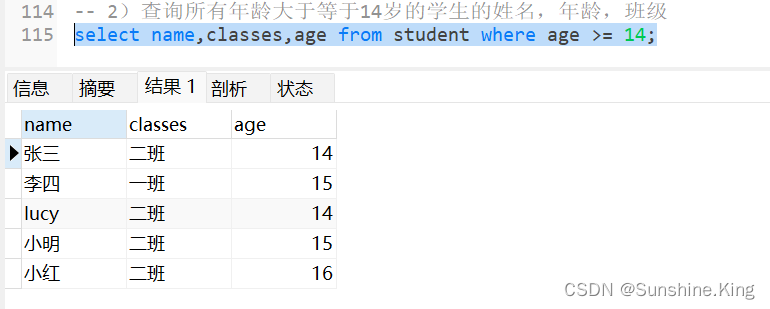
2)查询所有年龄大于等于14岁的学生的姓名,年龄,班级
select name,classes,age from student where age >= 14;
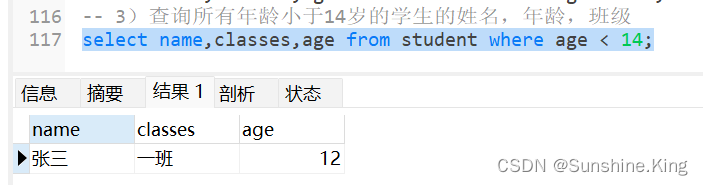
3)查询所有年龄小于14岁的学生的姓名,年龄,班级
select name,classes,age from student where age < 14;
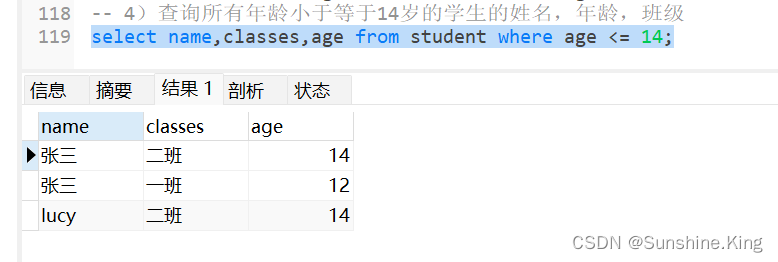
4)查询所有年龄小于等于14岁的学生的姓名,年龄,班级
select name,classes,age from student where age <= 14;
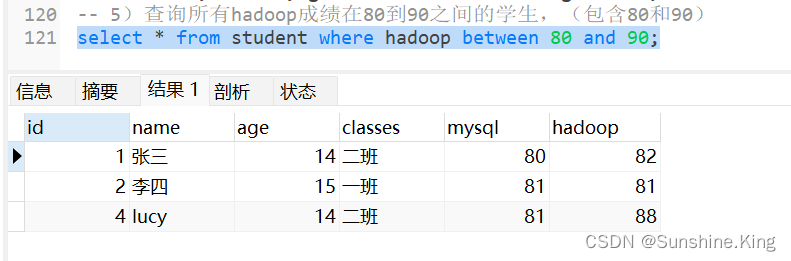
5)查询所有hadoop成绩在80到90之间的学生(包含80和90)
select * from student where hadoop between 80 and 90;
7.2.2 逻辑条件
| 符号 | 含义 |
|---|---|
| and | 并且 |
| or | 或者 |
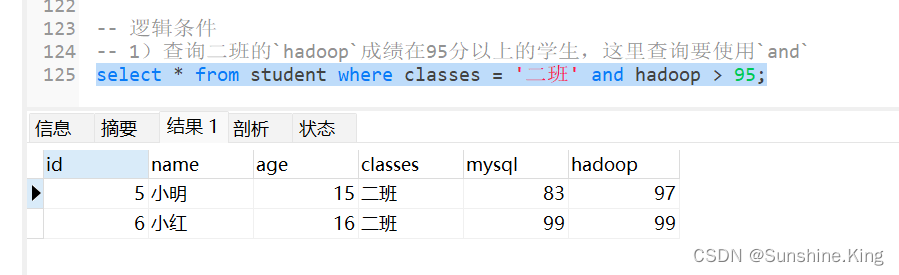
1)查询二班的hadoop成绩在95分以上的学生,这里查询要使用and
select * from student where classes = '二班' and hadoop > 95;
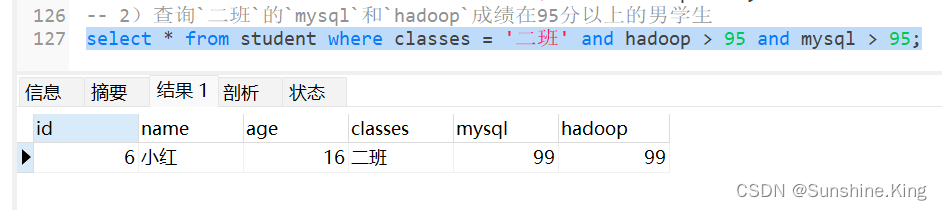
2)查询二班的mysql和hadoop成绩在95分以上的男学生
select * from student where classes = '二班' and hadoop > 95 and mysql > 95;
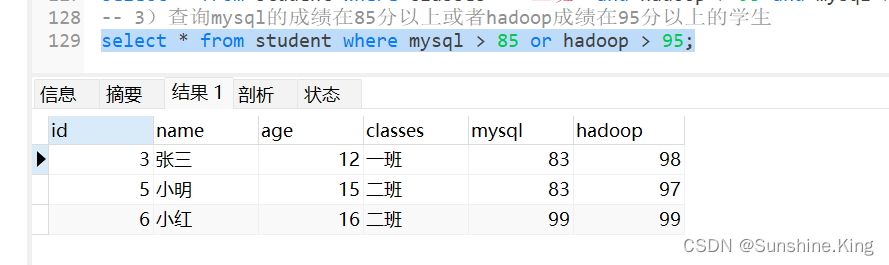
3)查询mysql的成绩在85分以上或者hadoop成绩在95分以上的学生
select * from student where mysql > 85 or hadoop > 95;
4)查询mysql的成绩在85分以上或者haddop成绩在95分以上或者id为4的学生
select * from student where mysql > 85 or hadoop > 95 or id = 4;
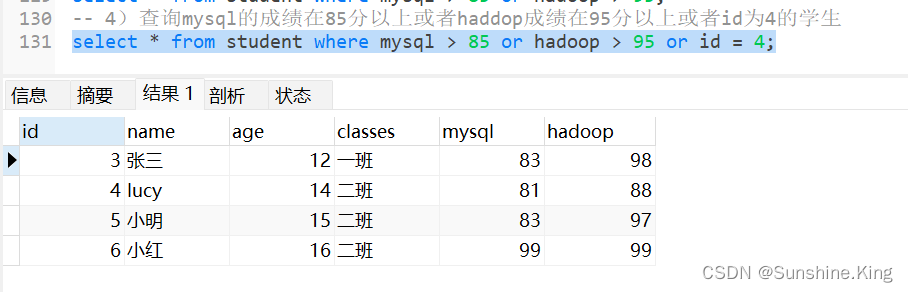
5)比较条件和逻辑条件混合使用
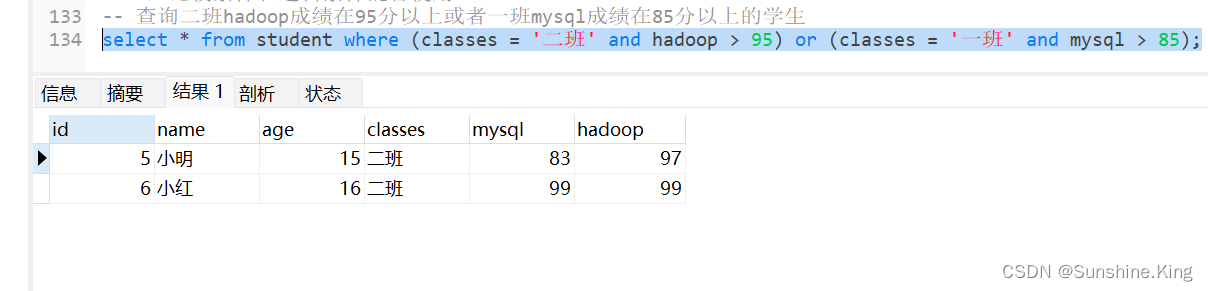
查询二班hadoop成绩在95分以上或者一班mysql成绩在85分以上的学生
select * from student where (classes = '二班' and hadoop > 95) or (classes = '一班' and mysql > 85);
7.2.3 判空条件
| 符号 | 含义 |
|---|---|
='' | 是空字符串'' |
| is nul | 是null值 |
| is not null | 不是null值 |
| <> | 不是,非 |
<>'' | 不是空字符串'',也不是null值 |
1)查询name是''的数据
SELECT * from student where name = '';
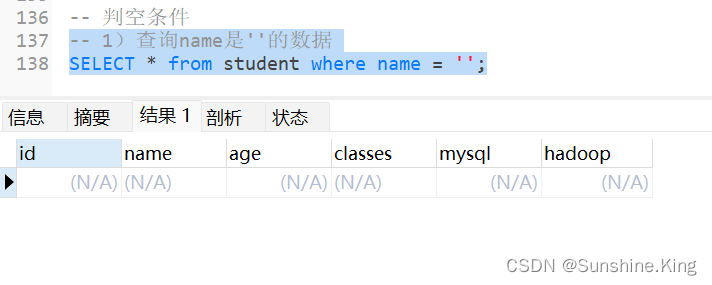
显然,此表中没有name是
''的数据
2)查询name是null的数据
SELECT * from student where name is null;
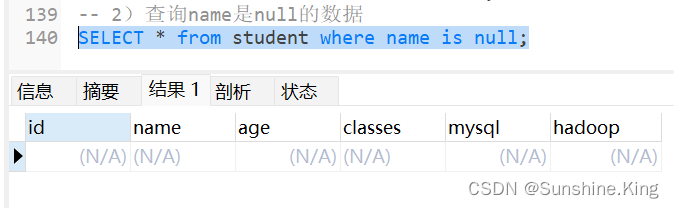
显然,此表中没有name是null的数据
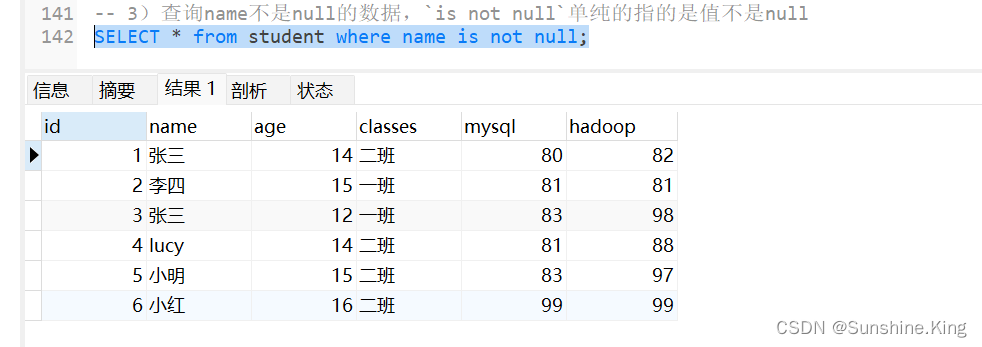
3)查询name不是null的数据,is not null单纯的指的是值不是null
SELECT * from student where name is not null;
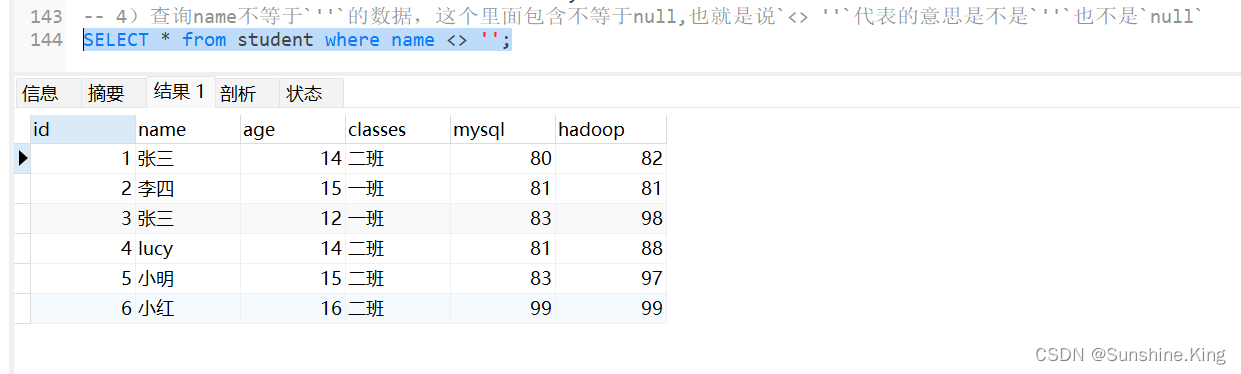
4)查询name不等于''的数据,这个里面包含不等于null,也就是说<> ''代表的意思是不是''也不是null
SELECT * from student where name <> '';
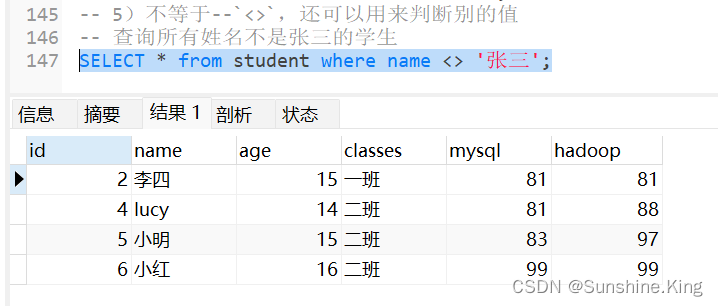
5)不等于–<>,还可以用来判断别的值
例如:
查询所有姓名不是张三的学生
SELECT * from student where name <> '张三';
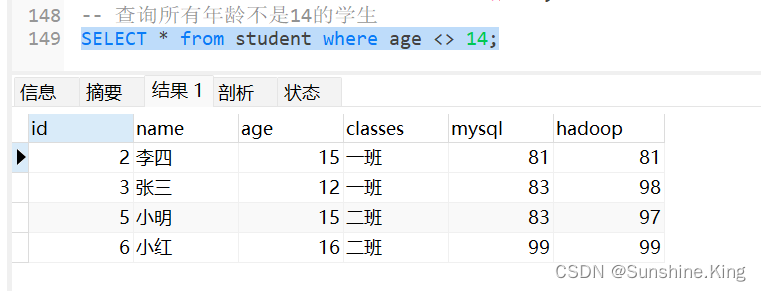
查询所有年龄不是14的学生
SELECT * from student where age <> 14;
7.2.4 模糊条件
字段类型为字符串时,查询字段值是否包含某些子串
例如:查询姓张的学生都有哪些,这个需要模糊查询
| 符号 | 含义 |
|---|---|
| like | 包含 |
| not like | 不包含 |
模糊查询like主要是用来查询字符串,配合_或者%一起使用
-
_是匹配0到1个字符 -
%是匹配0到多个字符
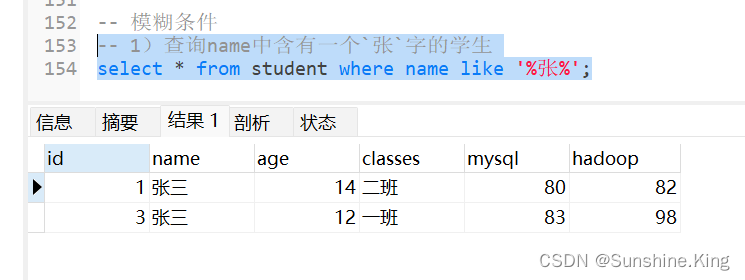
1)查询name中含有一个张字的学生
select * from student where name like '%张%';
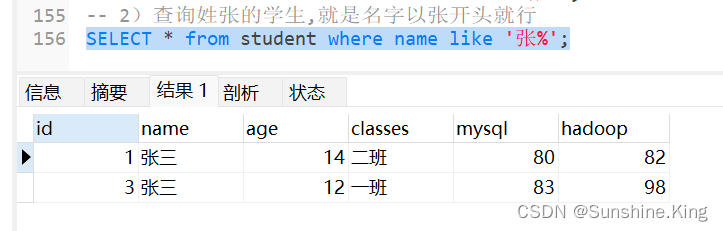
2)查询姓张的学生,就是名字以张开头就行
SELECT * from student where name like '张%';
3)查询姓张的学生中,名字是三个字的
SELECT * from student where name like '张__';
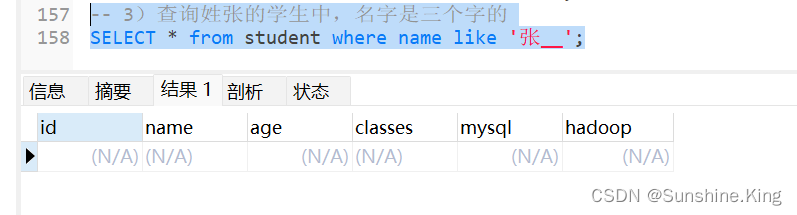
显然,此表中没有名字是三个字的姓张的学生
4)查询三个字的名字,张在中间的学生
SELECT * from student where name like '_张_';
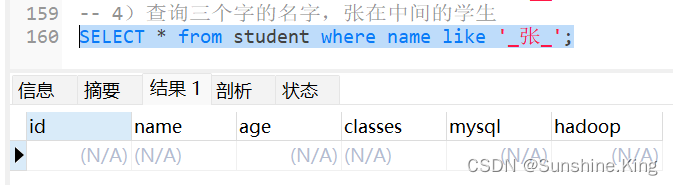
显然,此表中没有名字是三个字的张在中间的学生
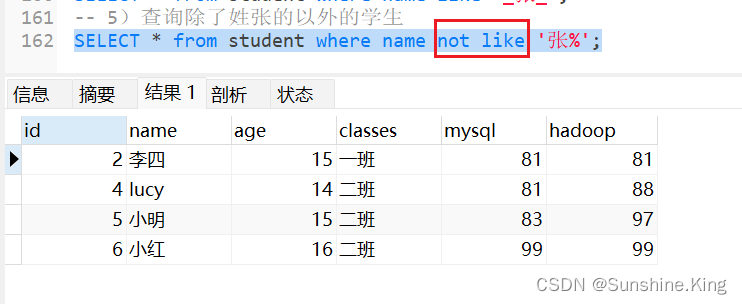
5)查询除了姓张的以外的学生
SELECT * from student where name not like '张%';
7.3 聚合查询
| 函数 | 含义 |
|---|---|
| sum | 求和 |
| avg | 求平均数 |
| max | 最大值 |
| min | 最小值 |
| count | 计数 |
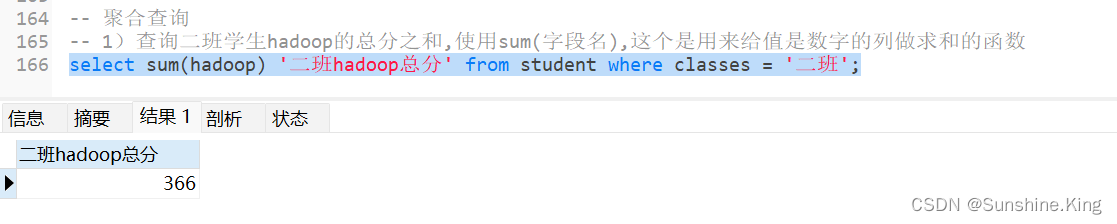
1)查询二班学生hadoop的总分之和,使用sum(字段名),这个是用来给值是数字的列做求和的函数
select sum(hadoop) '二班hadoop总分' from student where classes = '二班';
2)求一班mysql的平均成绩,平均数是avg(字段名),这个是用来给值是数字的列做求平均数的函数
select AVG(mysql) from student where classes = '一班';

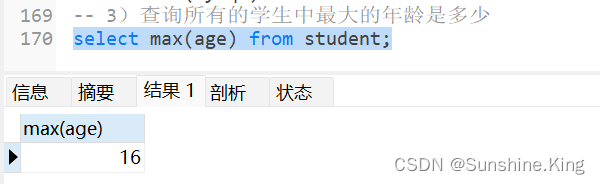
3)查询所有的学生中最大的年龄是多少
select max(age) from student;
注意一个问题,聚合查询,就是需要计算哪个列的数据就只查询哪个列
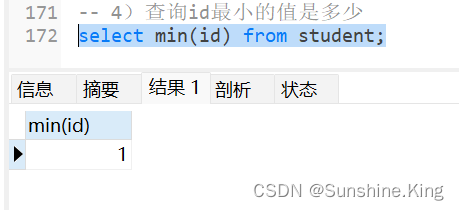
4)查询id最小的值是多少
select min(id) from student;
5)查询一班有多少个学生,使用count(),括号里面可以直接用*,或者某字段,或者常量
select count(*) from student where classes = '一班';

select count(id) from student where classes = '一班';
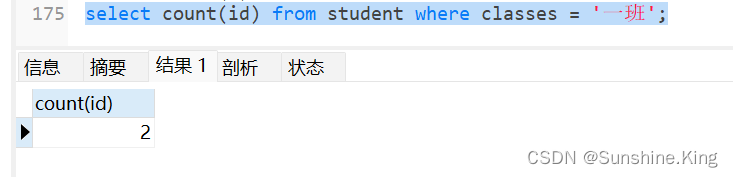
select count(1) from student where classes = '一班';
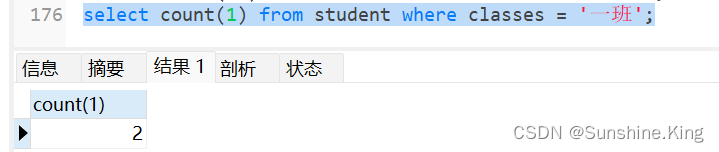
注:在之前的 MySQL版本,使用count(*)效率低,这个问题在MySQL8中已经不存在
7.4 排序查询
| 排序 | 含义 |
|---|---|
| order by 字段 | 正序 |
| order by 字段 asc | 正序,正序可以省略asc |
| order by 字段 desc | 倒序 |
排序查询使用order by 字段 desc,字段desc,…,字段desc,想要以哪个字段排序就order by谁
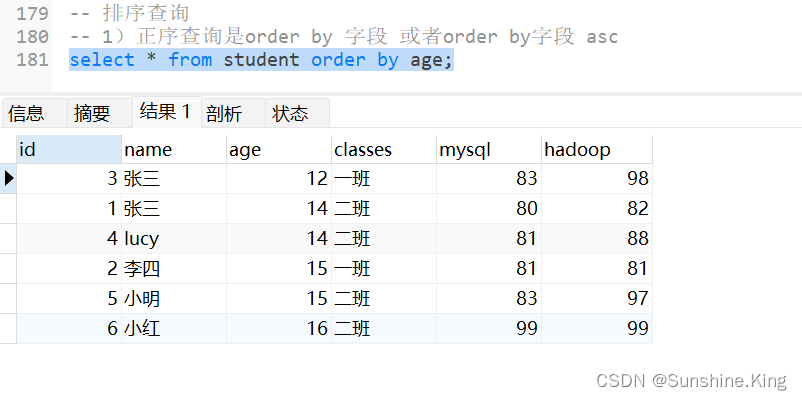
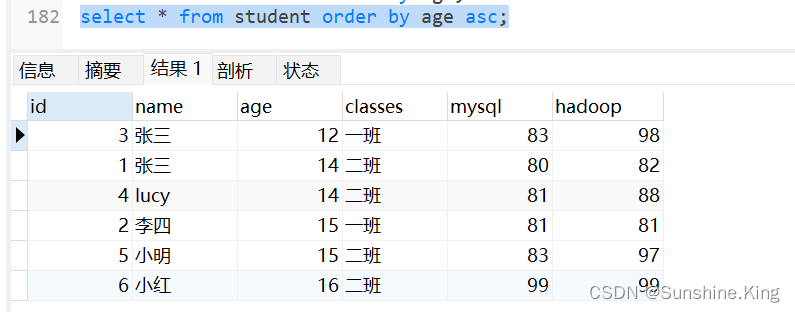
1)正序查询是order by 字段 或者order by字段 asc
select * from student order by age;
select * from student order by age asc;
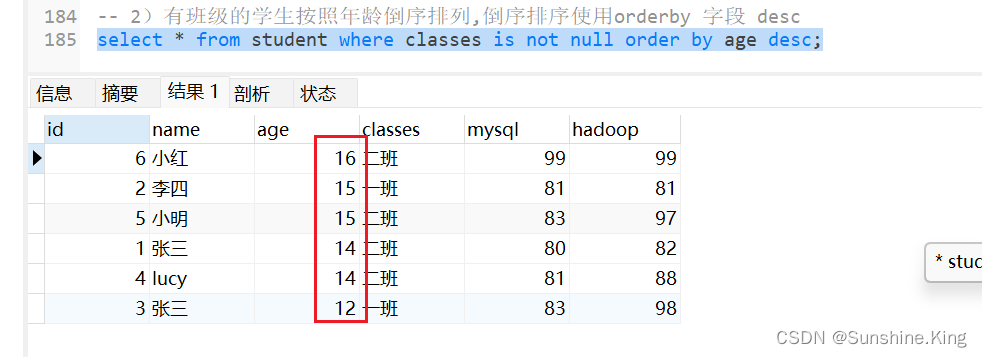
2)有班级的学生按照年龄倒序排列,倒序排序使用orderby 字段 desc
select * from student where classes is not null order by age desc;
3)可以排序多个字段,并且正序倒序可以混合使用
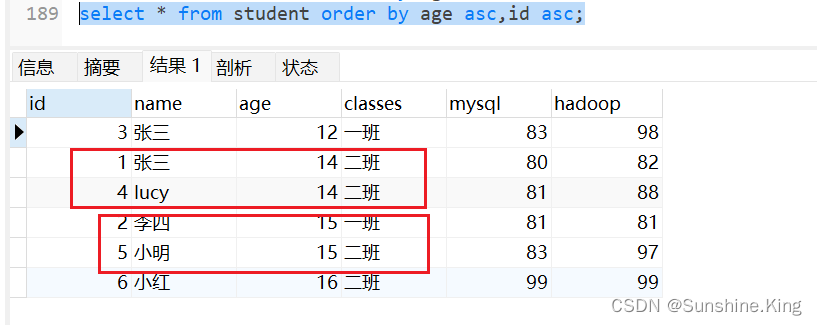
根据年龄正序排序,如果年龄相同则根据id正序排序
select * from student order by age,id;
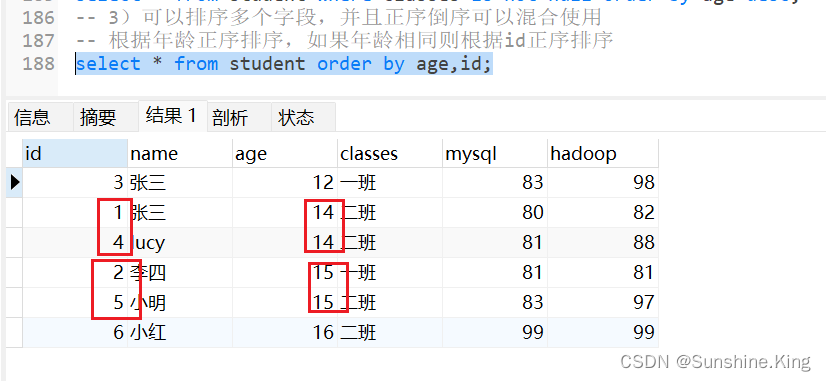
select * from student order by age asc,id asc;
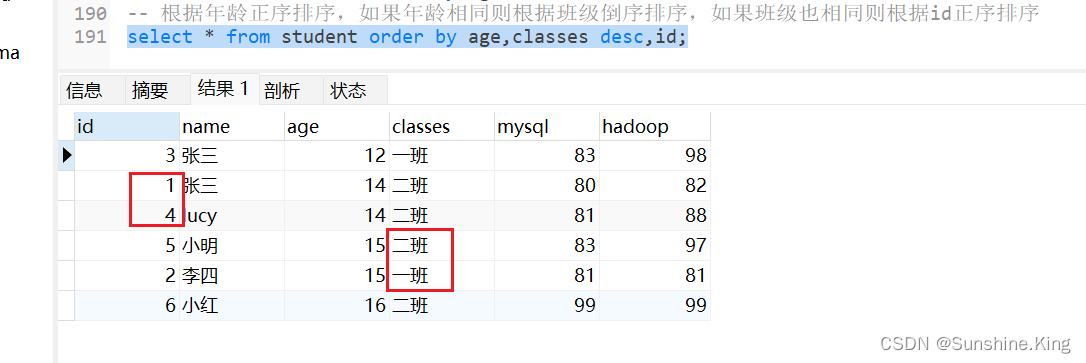
根据年龄正序排序,如果年龄相同则根据班级倒序排序,如果班级也相同则根据id正序排序
select * from student order by age,classes desc,id;
5)如果where条件和order by同时使用,order by放在where条件的后面
select * from student where classes is not null order by age;
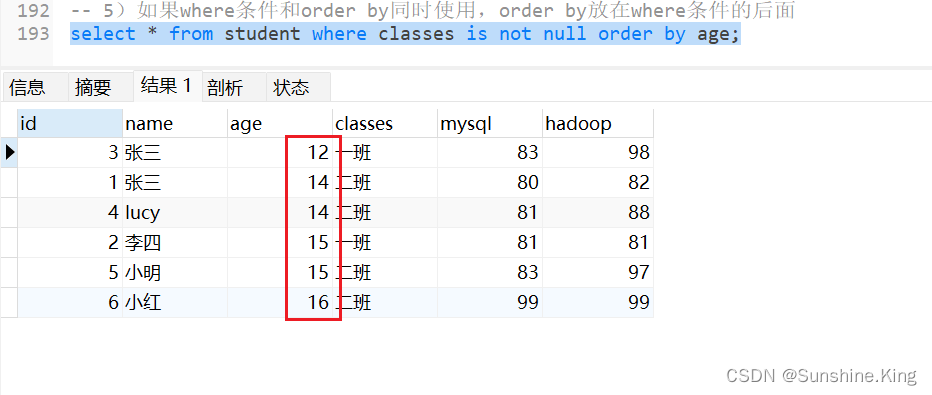
7.5 分页查询
分页查询,就是在已查询得到的结果集中,截取其中一部分。
格式:
-
limit 偏移量,步长
-
limit 步长,这种写法是默认偏移量的值是0
名词解释:
偏移量,查询的起始位置到起始第一行数据的差的行数。如果偏移量的值是0,就是从第1行开始查询。
步长,就是当前查询的条数。
例如:
分页查询学生表,从第1行开始,查询3条数据
select * from student limit 0,3;
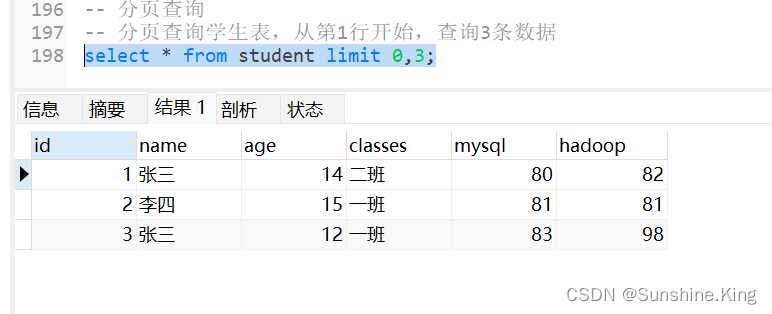
select * from student limit 3;
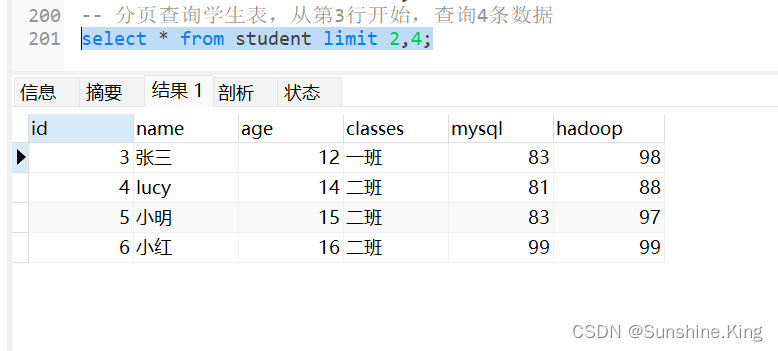
分页查询学生表,从第3行开始,查询4条数据
select * from student limit 2,4;
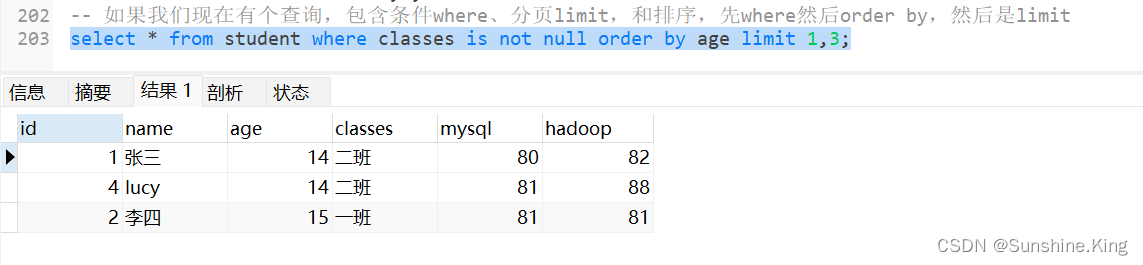
如果我们现在有个查询,包含条件where、分页limit,和排序,先where然后order by,然后是limit
select * from student where classes is not null order by age limit 1,3;
7.6 分组查询
按照指定的一个或多个字段分组查询(主要用于统计数据),分组查询多数时候与聚合查询一起使用
格式:
group by 字段
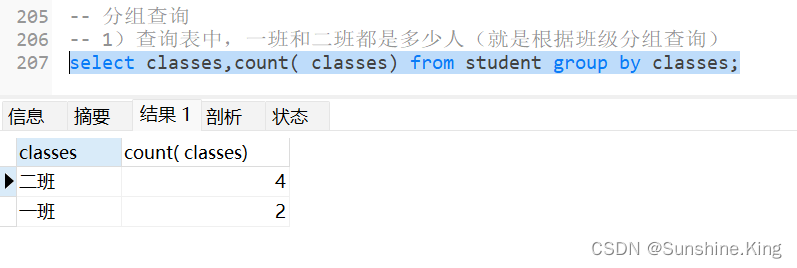
1)查询表中,一班和二班都是多少人(就是根据班级分组查询)
select classes,count( classes) from student group by classes;
考虑到班级可能存在null值的情况
select classes,count( classes) from student where classes is not null group by classes;

4)在做完分组之后,可以在分组上做聚合查询,聚合查询结果是每个分组的自己的结果
查询每个的班级的学生总数和hadoop成绩的最高分
select classes,count(classes) '学生数',max(hadoop) '班级hadoop最高分' from student where classes is not null group by classes;

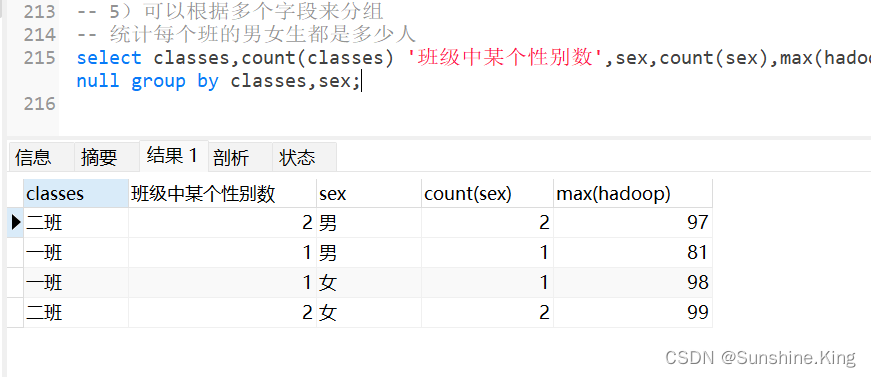
5)可以根据多个字段来分组
例如:统计每个班的男女生都是多少人
- 我们可以在group by class之后在加入一个字段sex做更细致的分组,就变成group by class,sex
- 意思就是先按照班级分组,然后在每个班级组的内部再按照性别分组
- 最后得到的结果就是精细到班级的性别的分组
- 这个时候我们再使用聚合查询的时候实际上是在做每个班级内部的性别分组基础上做聚合查询
select class,count(class) '班级中每个性别数',sex,count(sex),max(hadoop) from student where classes is not null group by classes,sex;
6)对分组查询的聚合函数结果加筛选条件
示例1:查询班级人数大于1个人的班级
-
首先,先按照班级做分组查询,并且对每个班级的人数进行计数
-
然后,再按照计数看大于1的计数,使用having count(class) > 1筛选
select classes,count(classes) from student where classes is not null group by classes having count(classes) > 1;

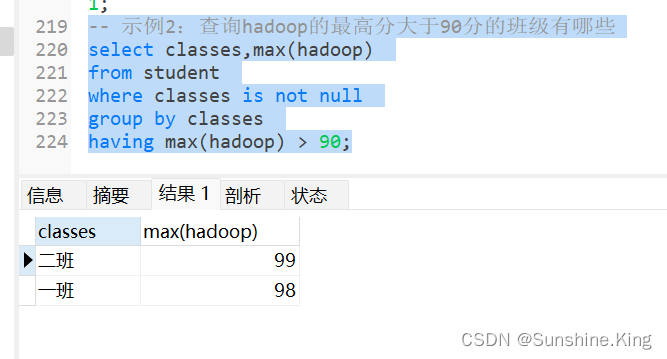
示例2:查询hadoop的最高分大于90分的班级有哪些
-
做班级分组查询,并且在分组的基础上对hadoop做max查询
-
用having 筛选max中大于90的数据
select classes,max(hadoop) from student where classes is not null group by classes having max(hadoop) > 90;
注意:
- 分组查询一般是与聚合查询结合使用,针对每个分组去做聚合(最大值,最小值,计数…)e
- 查询中如果有where、group by(包含having)、order by,使用的顺序group by(包含having) 必须在where之后,orderby之前
select classes,max(hadoop) from student where classes is not null group by classes having max(hadoop) >= 90 order by classes;
- 查询中如果有where、group by(包含having)、order by、limit,使用的顺序groupby(包含having) 必须在where之后,order by之前,limit必须在orderby之后
也就是where > group by > order by > limit
这样,我们前面学习的所有查询就都可以任意混合使用了
7.7 sql中完成if判断
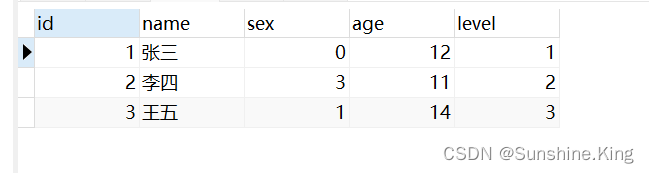
数据准备:
新建一张user表,如下:
sex: 0-男,1-女,3-未知;
level: 1-超级VIP客户,2-VIP客户,3-普通客户;
7.7.1 case流程控制函数
- 写法一
格式:
CASE expression
WHEN value1 THEN returnvalue1
WHEN value2 THEN returnvalue2
WHEN value3 THEN returnvalue3
……
ELSE defaultreturnvalue
END
示例:
查询user表,性别用中文(0-男,1-女,3-未知)表示
SELECT name,(
CASE sex
WHEN 0 THEN '男'
WHEN 1 THEN '女'
ELSE '未知'
END
) '性别'
FROM user;

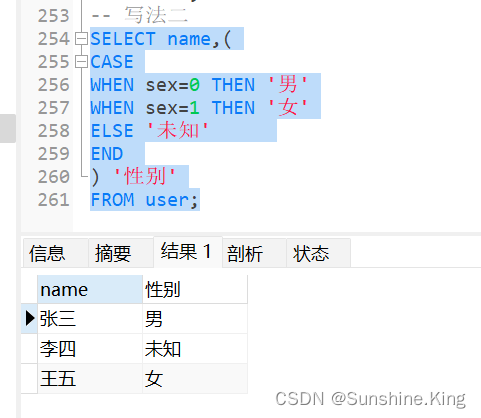
- 写法二
格式:
CASE
WHEN condition1 THEN returnvalue1
WHEN condition2 THEN returnvalue2
WHEN condition3 THEN returnvalue3
……
ELSE defaultreturnvalue
END
示例:
查询user表,性别用中文(0-男,1-女,3-未知)表示
SELECT name,(
CASE
WHEN sex=0 THEN '男'
WHEN sex=1 THEN '女'
ELSE '未知'
END
) '性别'
FROM user;
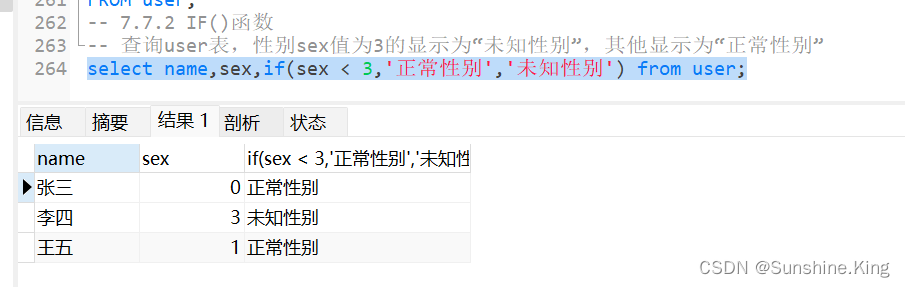
7.7.2 IF()函数
使用CASE函数可以实现非常复杂的逻辑判断,可是若只是实现“如果符合条件则返回A,否则返回B”这样简单的判断逻辑的话,使用CASE函数就过于繁琐。
MySQL提供了IF()函数用于简化这种逻辑判断。
格式:
IF(expr1,expr2,expr3);
示例:
查询user表,性别sex值为3的显示为“未知性别”,其他显示为“正常性别”
select name,sex,if(sex < 3,'正常性别','未知性别') from user;
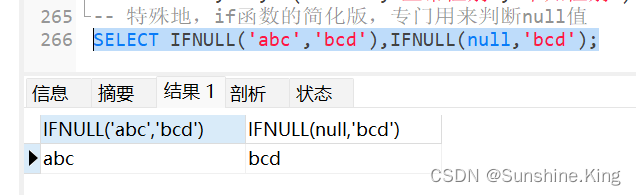
特殊地,if函数的简化版,专门用来判断null值
格式:
#判断 如果value1 不是null,返回value1;如果value1 为null,返回value2;
ifnull(value1,value2)
示例:
SELECT IFNULL('abc','bcd'),IFNULL(null,'bcd');
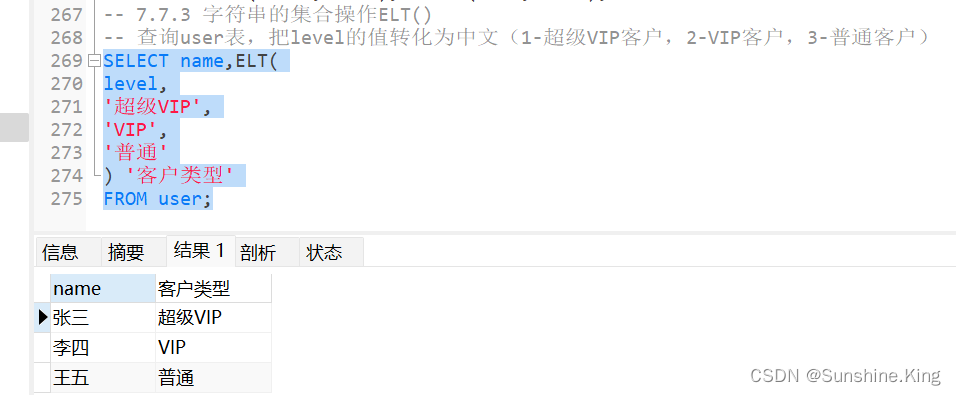
7.7.3 字符串的集合操作ELT()
格式:
#如果 N = 1,返回 str1,如果N =2,返回 str2,等等。如果 N 小于 1 或大于参数的数量,返回 NULL。
ELT(N,str1,str2,str3,...)
示例:
查询user表,把level的值转化为中文(1-超级VIP客户,2-VIP客户,3-普通客户)
SELECT name,ELT(
level,
'超级VIP',
'VIP',
'普通'
) '客户类型'
FROM user;
八、附源码
-- SHOW TABLES;
#学生表(主键-id,name,age,classes)
#主键的字段不能是null
create table student(id int(10) not null,name varchar(100),age int(2),primary key(id)
);
SHOW TABLES;
--
alter table student add column classes varchar(10);-- 添加多个字段
alter table student add a int,add b int,add c int;-- 修改a的数据类型为vachar
alter table student modify column a varchar(4);-- 将字段名a改为a1
alter table student change column a a1 varchar(4);-- 删除a1字段
alter table student drop column a1;
-- 删除b,c字段
alter table student drop column b,drop column c;-- 将表名student改为stu
alter table student rename to stu;-- 删除stu表
drop table stu;-- 查看表结构
describe student;-- 查看表的所有数据
select * from student;-- 插入数据
insert into student values (1,'张三',14,'二班');-- 单条指定字段插入数据,注意插入的值要和前面指定的字段的顺序保存一致
insert into student (id,name,age) values (2,'李四',15);
insert into student (name,age,id) values ('王五',16,3);-- 批量插入数据
insert into student values (4,'lucy',14,'一班'),(5,'小明',15,'二班'),(6,'小红',16,'一班');-- 主键-自动增长及字段-默认值设置
-- 创建新表student1
create table student1(id int(10) not null auto_increment,#主键-自动增长auto_incrementname varchar(100) default '不知道',#字段默认值设置default--primary key(id)
);-- 批量插入数据
-- 主键自动递增
insert into student1 (name) values ('lucy'),('小明'),('小红');
-- 表的字段有默认值,则不给其值的话-就自动填默认值
insert into student1 (id) values (4),(5);-- 查看表的所有数据
select * from student1;-- 把表的当前所有行的`classes`字段的值改成二班
update student set classes = '二班';-- 把id为2的学生的班级修改为一班
update student set classes = '一班' where id = 2;-- 把id为3的学生的姓名改为张三,年龄改为12,班级改为一班
update student set name = '张三',age = 12,classes = '一班' where id = 3;-- 删除学生表中id为2的对应行数据
delete from student where id = 2;-- 删除学生表中姓名为张三的对应行数据(如果有多个叫,就是删除多行)
#1,3都叫张三,所以此操作会将一和三行的数据都删掉
delete from student where name = '张三';-- 删除学生表的所有行数据
delete from student;-- 查询指定的列
select name,classes from student;-- 给查询的指定列取一个别名
select name '姓名',classes '班级' from student;-- 把班级和姓名放在一个列中查询,展示的时候是类似`二班-张三`这种的
select CONCAT(classes,'-',name) '班级-姓名' from student;-- 添加多个字段
alter table student add mysql int,add hadoop int;-- 合并查询可以做算数查询,例如查询mysql和hadoop的总成绩
select name '姓名',(mysql + hadoop) '总成绩' from student;-- 查询时添加常量列
select name, age, (mysql + hadoop) '总成绩', classes, '光明小学' from student;
select '常量' from student;-- 去除某个列重复数据
-- 使用distinct ,注意在使用的时候去重的列(字段)要单独查询,不要和其他列一起查询
-- 查询学生的所有的年龄,查询时去除重复的年龄
select distinct age from student;-- 条件查询
-- 1)查询所有年龄大于14岁的学生的姓名,班级, 年龄
select name,classes,age from student where age > 14;
-- 2)查询所有年龄大于等于14岁的学生的姓名,年龄,班级
select name,classes,age from student where age >= 14;
-- 3)查询所有年龄小于14岁的学生的姓名,年龄,班级
select name,classes,age from student where age < 14;
-- 4)查询所有年龄小于等于14岁的学生的姓名,年龄,班级
select name,classes,age from student where age <= 14;
-- 5)查询所有hadoop成绩在80到90之间的学生,(包含80和90)
select * from student where hadoop between 80 and 90;-- 逻辑条件
-- 1)查询二班的`hadoop`成绩在95分以上的学生,这里查询要使用`and`
select * from student where classes = '二班' and hadoop > 95;
-- 2)查询`二班`的`mysql`和`hadoop`成绩在95分以上的男学生
select * from student where classes = '二班' and hadoop > 95 and mysql > 95;
-- 3)查询mysql的成绩在85分以上或者hadoop成绩在95分以上的学生
select * from student where mysql > 85 or hadoop > 95;
-- 4)查询mysql的成绩在85分以上或者haddop成绩在95分以上或者id为4的学生
select * from student where mysql > 85 or hadoop > 95 or id = 4;
-- 5)比较条件和逻辑条件混合使用
-- 查询二班hadoop成绩在95分以上或者一班mysql成绩在85分以上的学生
select * from student where (classes = '二班' and hadoop > 95) or (classes = '一班' and mysql > 85);-- 判空条件
-- 1)查询name是''的数据
SELECT * from student where name = '';
-- 2)查询name是null的数据
SELECT * from student where name is null;
-- 3)查询name不是null的数据,`is not null`单纯的指的是值不是null
SELECT * from student where name is not null;
-- 4)查询name不等于`''`的数据,这个里面包含不等于null,也就是说`<> ''`代表的意思是不是`''`也不是`null`
SELECT * from student where name <> '';
-- 5)不等于--`<>`,还可以用来判断别的值
-- 查询所有姓名不是张三的学生
SELECT * from student where name <> '张三';
-- 查询所有年龄不是14的学生
SELECT * from student where age <> 14;-- 模糊条件
-- 1)查询name中含有一个`张`字的学生
select * from student where name like '%张%';
-- 2)查询姓张的学生,就是名字以张开头就行
SELECT * from student where name like '张%';
-- 3)查询姓张的学生中,名字是三个字的
SELECT * from student where name like '张__';
-- 4)查询三个字的名字,张在中间的学生
SELECT * from student where name like '_张_';
-- 5)查询除了姓张的以外的学生
SELECT * from student where name not like '张%';-- 聚合查询
-- 1)查询二班学生hadoop的总分之和,使用sum(字段名),这个是用来给值是数字的列做求和的函数
select sum(hadoop) '二班hadoop总分' from student where classes = '二班';
-- 2)求一班mysql的平均成绩,平均数是avg(字段名),这个是用来给值是数字的列做求平均数的函数
select AVG(mysql) from student where classes = '一班';
-- 3)查询所有的学生中最大的年龄是多少
select max(age) from student;
-- 4)查询id最小的值是多少
select min(id) from student;
-- 5)查询一班有多少个学生,使用`count()`,括号里面可以直接用*,或者某字段,或者常量
select count(*) from student where classes = '一班';
select count(id) from student where classes = '一班';
select count(1) from student where classes = '一班';-- 排序查询
-- 1)正序查询是order by 字段 或者order by字段 asc
select * from student order by age;
select * from student order by age asc;-- 2)有班级的学生按照年龄倒序排列,倒序排序使用orderby 字段 desc
select * from student where classes is not null order by age desc;
-- 3)可以排序多个字段,并且正序倒序可以混合使用
-- 根据年龄正序排序,如果年龄相同则根据id正序排序
select * from student order by age,id;
select * from student order by age asc,id asc;
-- 根据年龄正序排序,如果年龄相同则根据班级倒序排序,如果班级也相同则根据id正序排序
select * from student order by age,classes desc,id;
-- 5)如果where条件和order by同时使用,order by放在where条件的后面
select * from student where classes is not null order by age;-- 分页查询
-- 分页查询学生表,从第1行开始,查询3条数据
select * from student limit 0,3;
select * from student limit 3;
-- 分页查询学生表,从第3行开始,查询4条数据
select * from student limit 2,4;
-- 如果我们现在有个查询,包含条件where、分页limit,和排序,先where然后order by,然后是limit
select * from student where classes is not null order by age limit 1,3;-- 分组查询
-- 1)查询表中,一班和二班都是多少人(就是根据班级分组查询)
select classes,count( classes) from student group by classes;
-- 考虑到班级可能存在null值的情况
select classes,count( classes) from student where classes is not null group by classes;
-- 4)在做完分组之后,可以在分组上做聚合查询,聚合查询结果是每个分组的自己的结果
select classes,count(classes) '学生数',max(hadoop) '班级hadoop最高分' from student where classes is not null group by classes;
-- alter table student add column sex varchar(10);
-- 5)可以根据多个字段来分组
-- 统计每个班的男女生都是多少人
select classes,count(classes) '班级中某个性别数',sex,count(sex),max(hadoop) from student where classes is not null group by classes,sex;
-- 6)对分组查询的聚合函数结果加筛选条件
-- 示例1:查询班级人数大于1个人的班级
select classes,count(classes) from student where classes is not null group by classes having count(classes) > 1;
-- 示例2:查询hadoop的最高分大于90分的班级有哪些
select classes,max(hadoop)
from student
where classes is not null
group by classes
having max(hadoop) > 90;-- 7.7 sql中完成if判断
-- 数据准备
-- 新建一张user表
-- sex:0-男,1-女,3-未知;
-- level:1-超级VIP客户,2-VIP客户,3-普通客户;
create table user(id int(10) not null,name varchar(100),sex int(10),age int(2),level int(10),primary key(id)
);
-- 批量插入数据
insert into user values (1,'张三',0,12,1),(2,'李四',3,11,2),(3,'王五',1,14,3);
SELECT * FROM user;
-- 7.7.1 case流程控制函数
-- 查询user表,性别用中文(0-男,1-女,3-未知)表示
SELECT name,(
CASE sex
WHEN 0 THEN '男'
WHEN 1 THEN '女'
ELSE '未知'
END
) '性别'
FROM user;
-- 写法二
SELECT name,(
CASE
WHEN sex=0 THEN '男'
WHEN sex=1 THEN '女'
ELSE '未知'
END
) '性别'
FROM user;
-- 7.7.2 IF()函数
-- 查询user表,性别sex值为3的显示为“未知性别”,其他显示为“正常性别”
select name,sex,if(sex < 3,'正常性别','未知性别') from user;
-- 特殊地,if函数的简化版,专门用来判断null值
SELECT IFNULL('abc','bcd'),IFNULL(null,'bcd');
-- 7.7.3 字符串的集合操作ELT()
-- 查询user表,把level的值转化为中文(1-超级VIP客户,2-VIP客户,3-普通客户)
SELECT name,ELT(
level,
'超级VIP',
'VIP',
'普通'
) '客户类型'
FROM user;
相关文章:
MySQL|MySQL基础(求知讲堂-学习笔记【详】)
MySQL基础 目录 MySQL基础一、 MySQL的结构二、 管理数据库1)查询所有的数据库2)创建数据库3)修改数据库的字符编码4)删除数据库5)切换操作的数据库 三、表的概念四、字段的数据类型4.1 整型4.2 浮点型(float和double)…...

10.docker exec -it /bin/bash报错解决、sh与bash区别
报错 进入容器时,报如下错误 dockeruserdell-PowerEdge-R740:~$ docker exec -it daf2 /bin/bash OCI runtime exec failed: exec failed: unable to start container process: exec: "/bin/bash": stat /bin/bash: no such file or directory: unknown…...
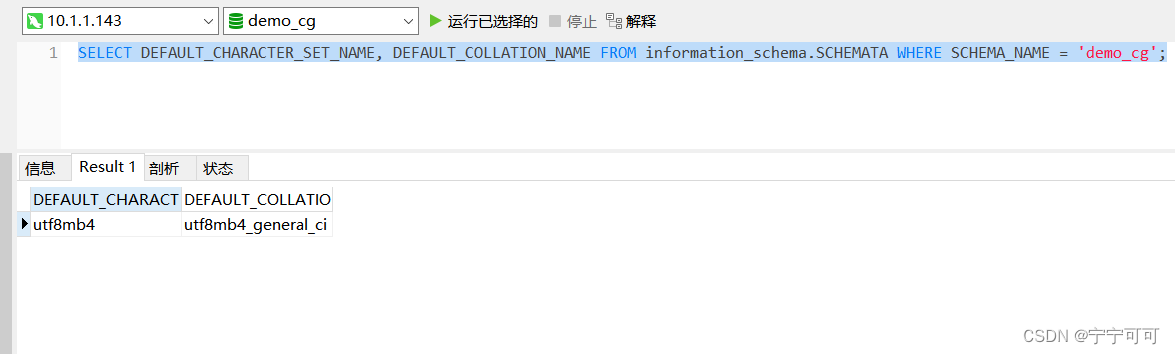
查询数据库的编码集Oracle,MySQL
1、查询数据库的编码集Oracle,MySQL 1.1、oracle select * from v$nls_parameters where parameterNLS_CHARACTERSET; 查询版本:SELECT * FROM v$version 2、MySQL编码集 SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME FROM information_schema.SC…...

电商数据采集+跨境电商|API电商数据采集接口洞悉数字新零售发展
随着全球经济一体化和电子商务的快速发展,网络购物的需求日益增加。不断涌现的电商企业使得行业的竞争情况愈演愈烈。在这种情况下,企业不仅要加大经营力度,还要在自己的基础设施和技术上持续投入,才能更好的适应市场和消费习惯。…...

linux之用户和用户组
文章目录 一、简介1.1 用户1.2 用户组1.3 UID和GID1.4 用户账户分类 二、用户2.1 添加新的用户账号:useradd2.2 删除账号:userdel2.3 修改账号:usermod(modmodify)2.4 用户口令的管理:passwd2.5 切换用户:su 三、用户组3.1 增加一…...

人工智能深度学习
目录 人工智能 深度学习 机器学习 神经网络 机器学习的范围 模式识别 数据挖掘 统计学习 计算机视觉 语音识别 自然语言处理 机器学习的方法 回归算法 神经网络 SVM(支持向量机) 聚类算法 降维算法 推荐算法 其他 机器学习的分类 机器…...

python reshape 和 transpose的区别
reshape() 和 transpose() 是用于改变数组或张量形状的两种不同方法, 它们的主要区别在于如何重新排列元素以及是否可以改变轴的顺序。 1 reshape() reshape() 函数用于改变数组或张量的形状,但是不改变元素的排列顺序。它只是简单地将数组的维度重新…...

音视频技术-网络视频会议“回声”的消除
目录 一、“回音”的成因原理 二、解决思路 三、解决方案 1、方案一 2...

有哪些令人惊讶的心理学效应
大家可以想象一个场景: 如果一次考试,你考了95分,比上次还进步了10分,你会感到高兴吗? 听起来很牛逼啊,值得干杯庆祝,好好开心几天了。 这时,你看到同桌这次居然是一百分…...
二叉树基础知识总结
目录 二叉树基础知识 概念 : 根节点的五个形态 : 特殊的二叉树 满二叉树 : 完全二叉树 : 二叉搜索树 : 平衡二叉搜索树 : 二叉树的性质 : 二叉树的存储结构 二叉树的顺序存储结构 二叉树的链式存储结构 二叉树的遍历方式 : 基础概念 前中后遍历 层序遍历 :…...

IDEA2023.3.4开启SpringBoot项目的热部署【简单明了4步操作】
添加devtools依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional> </dependency>IDEA开启自动编译 …...

QT中调用python
一.概述 1.Python功能强大,很多Qt或者c/c开发不方便的功能可以由Python编码开发,尤其是一些算法库的应用上,然后Qt调用Python。 2.在Qt调用Python的过程中,必须要安装python环境,并且Qt Creator中编译器与Python的版…...
Sora基础知识学习
...

开源博客项目Blog .NET Core源码学习(9:Autofac使用浅析)
开源博客项目Blog使用Autofac注册并管理组件和服务,Autofac是面向.net 的开源IOC容器,支持通过接口、实例、程序集等方式注册组件和服务,同时支持属性注入、方法注入等注入方式。本文学习并记录Blog项目中Autofac的使用方式。 整个Blog解…...

Go语言中的TLS加密:深入crypto/tls库的实战指南
Go语言中的TLS加密:深入crypto/tls库的实战指南 引言crypto/tls库的核心组件TLS配置:tls.Config证书加载与管理TLS握手过程及其实现 构建安全的服务端创建TLS加密的HTTP服务器配置TLS属性常见的安全设置和最佳实践 开发TLS客户端应用编写使用TLS的客户端…...
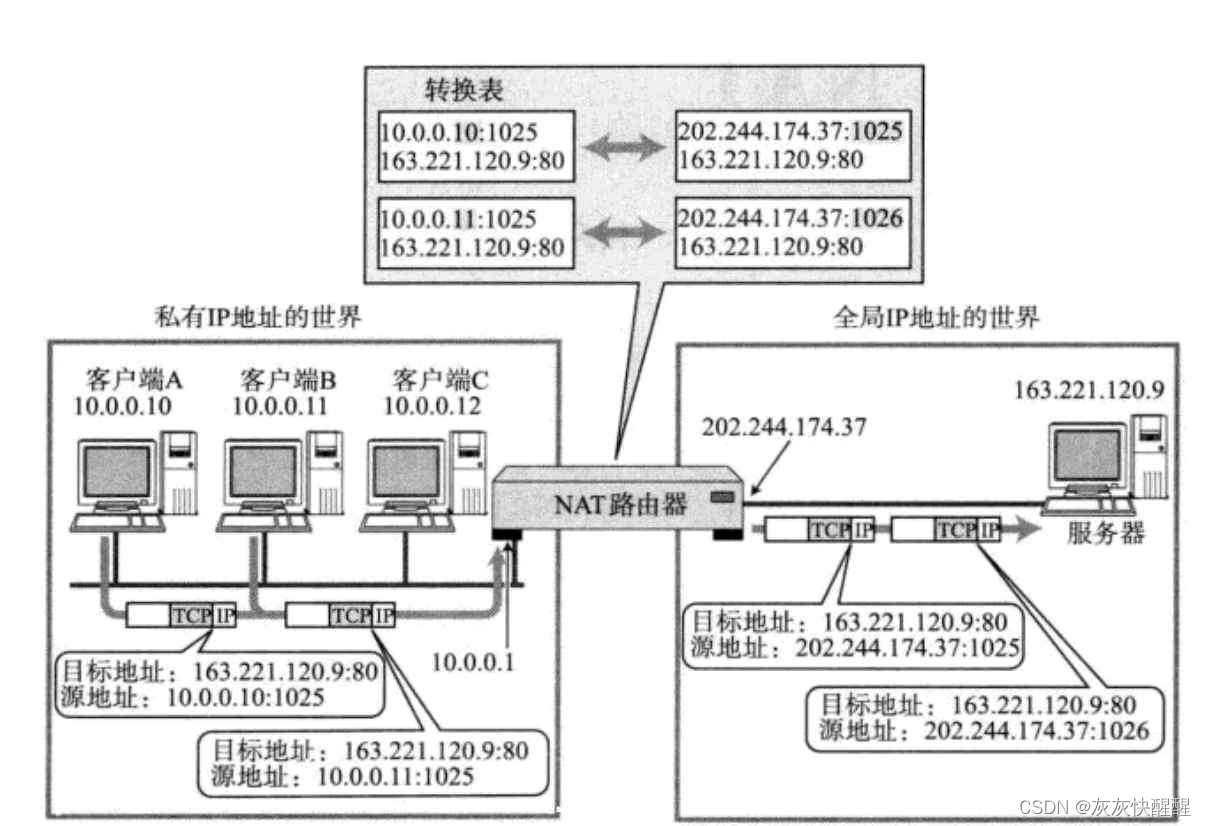
网络原理-TCP/IP(7)
目录 网络层 路由选择 数据链路层 认识以太网 以太网帧格式 认识MAC地址 对比理解MAC地址和IP地址 认识MTU ARP协议 ARP协议的作用 ARP协议工作流程 重要应用层协议DNS(Domain Name System) DNS背景 NAT技术 NAT IP转换过程 NAPT NAT技术的优缺点 网络层 路由…...
HarmonyOS4.0系列——08、整合UI常用组件
HarmonyOS4.0 系列——08、UI 组件 Blank Blank 组件在横竖屏占满空余空间效果 // xxx.ets Entry Component struct BlankExample {build() {Column() {Row() {Text(Button).fontSize(18)Blank()Toggle({type: ToggleType.Switch}).margin({top: 14,bottom: 14,left: 6,righ…...

【Spring Boot 3】【JPA】一对多单向关联
【Spring Boot 3】【JPA】一对多单向关联 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...

工信部等九部门:打造一批实现制造过程数字孪生的数字化转型标杆工厂
“人工智能技术与咨询” 发布 培育一批科技领军人才、青年骨干人才,以及一批既懂原材料工业又懂数字技术的复合型人才。依托职业教育提质培优行动计划,加速培育数字化转型急需紧缺的工程师和技术技能人才。支持引进数字化转型海外高端人才。 ÿ…...
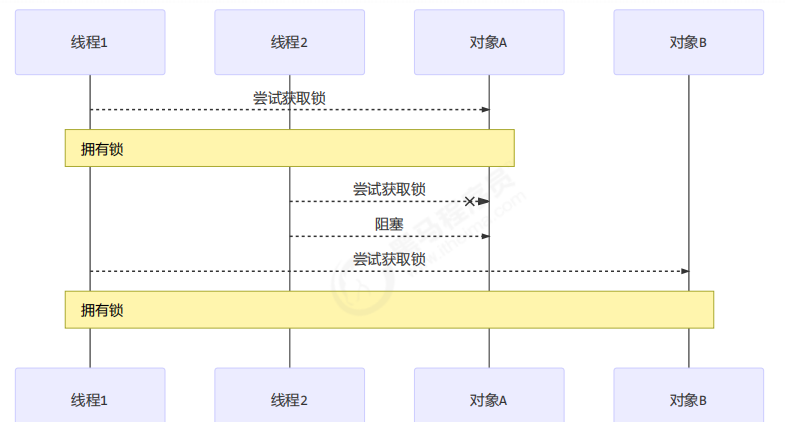
并发编程(2)基础篇-管程
4 共享模型之管程 本章内容 共享问题synchronized线程安全分析Monitorwait/notify线程状态转换活跃性Lock 4.1 共享带来的问题 4.1.1 小故事 老王(操作系统)有一个功能强大的算盘(CPU),现在想把它租出去ÿ…...
:本地部署完整指南)
One API 部署教程(上):本地部署完整指南
前言 One API 是一个开源的 AI API 聚合管理平台,可以让你用一个统一的接口调用多个 AI 平台的 API(如 OpenAI、DeepSeek、通义千问等)。 为了让大家能全面了解 One API,我决定写一个系列教程: One API 部署教程(上):本地部署完整指南(本文) One API 部署教程(中)…...

别再为交叉项头疼了!手把手教你用MATLAB时频工具箱搞定WVD、PWVD和SPWVD
别再为交叉项头疼了!手把手教你用MATLAB时频工具箱搞定WVD、PWVD和SPWVD 信号处理工程师和研究者们常常面临一个棘手问题:如何从复杂的非平稳信号中提取清晰的时频特征?Wigner-Ville分布(WVD)系列方法作为经典解决方案…...

摆脱人员穿戴约束,无感定位颠覆 UWB 强制管理模式
摆脱人员穿戴约束,无感定位颠覆 UWB 强制管理模式一、UWB 先天短板:深陷强制穿戴、强管控困局传统 UWB 定位天生依赖基站有源标签,想要实现厘米级定位,前提必须是全员强制佩戴标签手环/胸卡。不仅硬性要求内部人员全天候穿戴&…...

打破iOS修改壁垒:H5GG技术架构与实战路径全解析
打破iOS修改壁垒:H5GG技术架构与实战路径全解析 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 在iOS生态中,游戏与应用修改一直被视为技术门槛较高的领域&…...

如何构建拼多多数据采集系统:面向电商决策者的战略投资方案
如何构建拼多多数据采集系统:面向电商决策者的战略投资方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在拼多多平台占据中国电商市场重要份额的…...

STM32体重秤电子秤称重超重报警Proteus仿真资源包
STM32体重秤电子秤称重超重报警Proteus仿真资源包 【下载地址】STM32体重秤电子秤称重超重报警Proteus仿真资源包 本资源包提供了基于STM32单片机的体重秤电子秤称重超重报警系统的完整解决方案。资源内容包括源代码、Proteus仿真文件以及全套相关资料,帮助用户快速…...

【亲测免费】 探索高效编程新境界:RT809F编程器软件深度体验
探索高效编程新境界:RT809F编程器软件深度体验 【下载地址】RT809F编程器软件 本仓库提供了RT809F编程器的配套软件下载。RT809F是一款高度集成、功能强大的编程和调试工具,专为各种微控制器、闪存、EEPROM以及各种类型的IC设计。通过这款软件࿰…...

HS2-HF_Patch汉化补丁:3分钟打造完美中文游戏体验
HS2-HF_Patch汉化补丁:3分钟打造完美中文游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗…...
开发的经验总结)
使用AI(龙虾)开发的经验总结
一、使用AI辅助开发的两个核心前提 1.先搞清楚再开口:明确问题边界与目标 在向AI描述问题之前,开发者必须自己先理清整个业务流程、技术上下文和预期目标。这包括: 代码需要改哪里? 明确具体的文件、类、方法或模块。改什么&#…...

接入Taotoken后我的月度API账单变得清晰可追溯且易于管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 接入Taotoken后我的月度API账单变得清晰可追溯且易于管理 在开发工作中,我们常常需要调用不同的大模型API来满足多样化…...