人工智能深度学习
目录
人工智能
深度学习
机器学习
神经网络
机器学习的范围
模式识别
数据挖掘
统计学习
计算机视觉
语音识别
自然语言处理
机器学习的方法
回归算法
神经网络
SVM(支持向量机)
聚类算法
降维算法
推荐算法
其他
机器学习的分类
机器学习模型的评估
机器学习的应用
机器学习的子类--深度学习
机器学习的父类--人工智能
人工智能
人类通过直觉可以解决的问题,如:自然语言理解,图像识别,语音识别等,计算机很难解决,而人工智能就是要解决这类问题
深度学习
其核心就是自动将简单的特征组合成更加复杂的特征,并用这些特征解决问题
机器学习
机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,
机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法
神经网络
最初是一个生物学的概念,一般是指大脑神经元,触点,细胞等组成的网络,用于产生意识,帮助生物思考和行动,后来人工智能受神经网络的启发,发展出了人工神经网络
机器学习的范围
机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。

模式识别
模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern Recognition And Machine Learning》这本书中,Christopher M. Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。
数据挖掘
数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。
统计学习
统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。
计算机视觉
计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果,因此未来计算机视觉界的发展前景不可估量。
语音识别
语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
自然语言处理
自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。
机器学习的方法
回归算法
在大部分机器学习课程中,回归算法都是介绍的第一个算法。原因有两个:一.回归算法比较简单,介绍它可以让人平滑地从统计学迁移到机器学习中。二.回归算法是后面若干强大算法的基石,如果不理解回归算法,无法学习那些强大的算法。回归算法有两个重要的子类:即线性回归和逻辑回归。
实现方面的话,逻辑回归只是对对线性回归的计算结果加上了一个Sigmoid函数,将数值结果转化为了0到1之间的概率(Sigmoid函数的图像一般来说并不直观,你只需要理解对数值越大,函数越逼近1,数值越小,函数越逼近0),接着我们根据这个概率可以做预测,例如概率大于0.5,则这封邮件就是垃圾邮件,或者肿瘤是否是恶性的等等。从直观上来说,逻辑回归是画出了一条分类线,见下图。
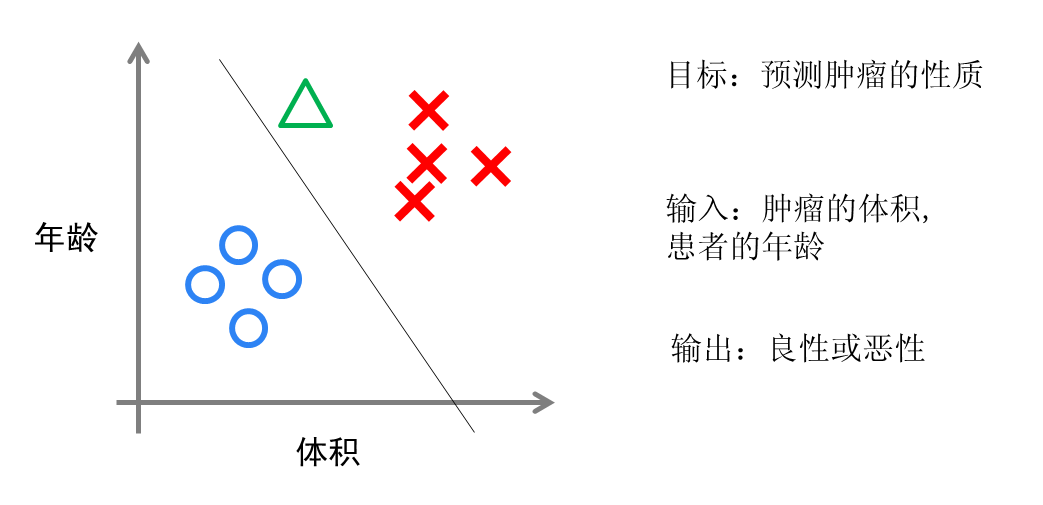
逻辑回归算法划出的分类线基本都是线性的(也有划出非线性分类线的逻辑回归,不过那样的模型在处理数据量较大的时候效率会很低),这意味着当两类之间的界线不是线性时,逻辑回归的表达能力就不足。
神经网络
让我们看一个简单的神经网络的逻辑架构。在这个网络中,分成输入层,隐藏层,和输出层。输入层负责接收信号,隐藏层负责对数据的分解与处理,最后的结果被整合到输出层。每层中的一个圆代表一个处理单元,可以认为是模拟了一个神经元,若干个处理单元组成了一个层,若干个层再组成了一个网络,也就是"神经网络"。
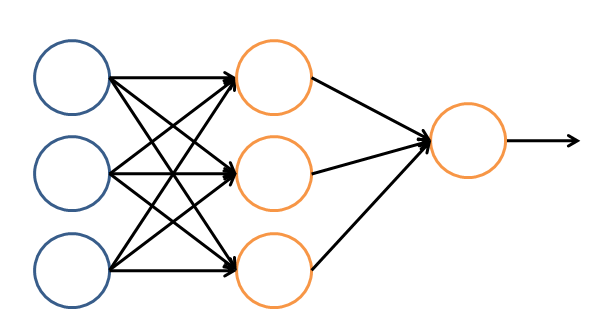
在神经网络中,每个处理单元事实上就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到下一个层次。通过这样的过程,神经网络可以完成非常复杂的非线性分类。
SVM(支持向量机)
支持向量机算法从某种意义上来说是逻辑回归算法的强化:通过给予逻辑回归算法更严格的优化条件,支持向量机算法可以获得比逻辑回归更好的分类界线。但是如果没有某类函数技术,则支持向量机算法最多算是一种更好的线性分类技术。
但是,通过跟高斯“核”的结合,支持向量机可以表达出非常复杂的分类界线,从而达成很好的的分类效果。“核”事实上就是一种特殊的函数,最典型的特征就是可以将低维的空间映射到高维的空间。

我们如何在二维平面划分出一个圆形的分类界线?在二维平面可能会很困难,但是通过“核”可以将二维空间映射到三维空间,然后使用一个线性平面就可以达成类似效果。也就是说,二维平面划分出的非线性分类界线可以等价于三维平面的线性分类界线。于是,我们可以通过在三维空间中进行简单的线性划分就可以达到在二维平面中的非线性划分效果。

支持向量机是一种数学成分很浓的机器学习算法(相对的,神经网络则有生物科学成分)。在算法的核心步骤中,有一步证明,即将数据从低维映射到高维不会带来最后计算复杂性的提升。于是,通过支持向量机算法,既可以保持计算效率,又可以获得非常好的分类效果。因此支持向量机在90年代后期一直占据着机器学习中最核心的地位,基本取代了神经网络算法。直到现在神经网络借着深度学习重新兴起,两者之间才又发生了微妙的平衡转变。
聚类算法
无监督算法中最典型的代表就是聚类算法。
让我们还是拿一个二维的数据来说,某一个数据包含两个特征。我希望通过聚类算法,给他们中不同的种类打上标签,我该怎么做呢?简单来说,聚类算法就是计算种群中的距离,根据距离的远近将数据划分为多个族群。
聚类算法中最典型的代表就是K-Means算法。
降维算法
降维算法也是一种无监督学习算法,其主要特征是将数据从高维降低到低维层次。
降维算法的主要作用是压缩数据与提升机器学习其他算法的效率。通过降维算法,可以将具有几千个特征的数据压缩至若干个特征。另外,降维算法的另一个好处是数据的可视化,例如将5维的数据压缩至2维,然后可以用二维平面来可视。降维算法的主要代表是PCA算法(即主成分分析算法)。
推荐算法
推荐算法是目前业界非常火的一种算法,在电商界,如亚马逊,天猫,京东等得到了广泛的运用。推荐算法的主要特征就是可以自动向用户推荐他们最感兴趣的东西,从而增加购买率,提升效益。推荐算法有两个主要的类别:
一类是基于物品内容的推荐,是将与用户购买的内容近似的物品推荐给用户,这样的前提是每个物品都得有若干个标签,因此才可以找出与用户购买物品类似的物品,这样推荐的好处是关联程度较大,但是由于每个物品都需要贴标签,因此工作量较大。
另一类是基于用户相似度的推荐,则是将与目标用户兴趣相同的其他用户购买的东西推荐给目标用户,例如小A历史上买了物品B和C,经过算法分析,发现另一个与小A近似的用户小D购买了物品E,于是将物品E推荐给小A。
两类推荐都有各自的优缺点,在一般的电商应用中,一般是两类混合使用。推荐算法中最有名的算法就是协同过滤算法。
其他
除了以上算法之外,机器学习界还有其他的如高斯判别,朴素贝叶斯,决策树等等算法。但是上面列的六个算法是使用最多,影响最广,种类最全的典型。机器学习界的一个特色就是算法众多,发展百花齐放。
下面做一个总结,按照训练的数据有无标签,可以将上面算法分为监督学习算法和无监督学习算法,但推荐算法较为特殊,既不属于监督学习,也不属于非监督学习,是单独的一类。
机器学习的分类
目前机器学习主流分为:监督学习,无监督学习,强化学习。
a) 监督学习是最常见的一种机器学习,它的训练数据是有标签的,训练目标是能够给新数据(测试数据)以正确的标签。例如,将邮件进行是否垃圾邮件的分类,一开始我们先将一些邮件及其标签(垃圾邮件或非垃圾邮件)一起进行训练,学习模型不断捕捉这些邮件与标签间的联系进行自我调整和完善,然后我们给一些不带标签的新邮件,让该模型对新邮件进行是否是垃圾邮件的分类。
b) 无监督学习常常被用于数据挖掘,用于在大量无标签数据中发现些什么。无监督主要有三种:聚类、离散点检测和降维。
它的训练数据是无标签的,训练目标是能对观察值进行分类或者区分等。例如无监督学习应该能在不给任何额外提示的情况下,仅依据所有“猫”的图片的特征,将“猫”的图片从大量的各种各样的图片中将区分出来。
c) 强化学习通常被用在机器人技术上(例如机械狗),它接收机器人当前状态,算法的目标是训练机器来做出各种特定行为。工作流程多是:机器被放置在一个特定环境中,在这个环境里机器可以持续性地进行自我训练,而环境会给出或正或负的反馈。机器会从以往的行动经验中得到提升并最终找到最好的知识内容来帮助它做出最有效的行为决策。
机器学习模型的评估
拿猫的识别来举例,假设机器通过学习,已经具备了一定的识别能力。那么,我们输入4张图片,机器的判断如下:

常用的评价指标有三种:准确率(precision)、召回率(recall)和精准率(accuracy),其中:
Precision = TP/(TP+FP),表示我们抓到的人中,抓对了的比例;
Recall = TP/ (TP+FN),表示我们抓到的坏人占所有坏人的比例;
Accuracy = (TP + TN)/ All ,表示识别对了(好人被识别成好人,坏人被识别成坏人)的比例。
三个指标越高,表示算法的适应性越好。
机器学习的应用
机器学习与大数据的结合产生了巨大的价值。基于机器学习技术的发展,数据能够“预测”。对人类而言,积累的经验越丰富,阅历也广泛,对未来的判断越准确。例如常说的“经验丰富”的人比“初出茅庐”的小伙子更有工作上的优势,就在于经验丰富的人获得的规律比他人更准确。而在机器学习领域,根据著名的一个实验,有效的证实了机器学习界一个理论:即机器学习模型的数据越多,机器学习的预测的效率就越好。
机器学习界的名言:成功的机器学习应用不是拥有最好的算法,而是拥有最多的数据!
在大数据的时代,有好多优势促使机器学习能够应用更广泛。例如随着物联网和移动设备的发展,我们拥有的数据越来越多,种类也包括图片、文本、视频等非结构化数据,这使得机器学习模型可以获得越来越多的数据。同时大数据技术中的分布式计算Map-Reduce使得机器学习的速度越来越快,可以更方便的使用。种种优势使得在大数据时代,机器学习的优势可以得到最佳的发挥。
机器学习的子类--深度学习
2006年,Geoffrey Hinton在科学杂志《Science》上发表了一篇文章,论证了两个观点:
1.多隐层的神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;
2.深度神经网络在训练上的难度,可以通过“逐层初始化” 来有效克服。
通过这样的发现,不仅解决了神经网络在计算上的难度,同时也说明了深层神经网络在学习上的优异性。从此,神经网络重新成为了机器学习界中的主流强大学习技术。同时,具有多个隐藏层的神经网络被称为深度神经网络,基于深度神经网络的学习研究称之为深度学习。
目前业界许多的图像识别技术与语音识别技术的进步都源于深度学习的发展,除了本文开头所提的Cortana等语音助手,还包括一些图像识别应用,其中典型的代表就是下图的百度识图功能。
深度学习属于机器学习的子类。基于深度学习的发展极大的促进了机器学习的地位提高,更进一步地,推动了业界对机器学习父类人工智能梦想的再次重视。
机器学习的父类--人工智能
人工智能是机器学习的父类。深度学习则是机器学习的子类。如果把三者的关系用图来表明的话,则是下图:
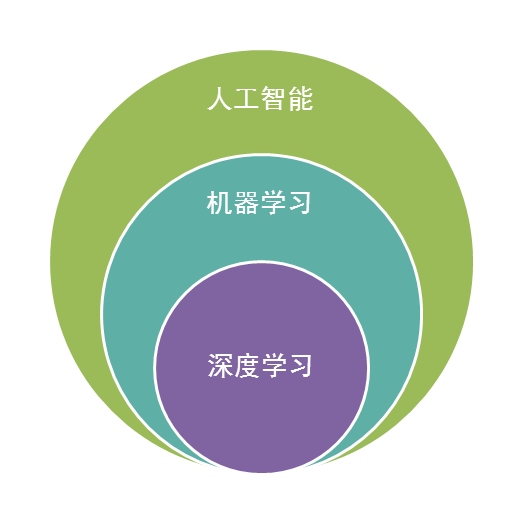
总结起来,人工智能的发展经历了如下若干阶段,从早期的逻辑推理,到中期的专家系统,这些科研进步确实使我们离机器的智能有点接近了,但还有一大段距离。直到机器学习诞生以后,人工智能界感觉终于找对了方向。基于机器学习的图像识别和语音识别在某些垂直领域达到了跟人相媲美的程度。机器学习使人类第一次如此接近人工智能的梦想。
让我们再看一下机器人的制造,在我们具有了强大的计算,海量的存储,快速的检索,迅速的反应,优秀的逻辑推理后我们如果再配合上一个强大的智慧大脑,一个真正意义上的人工智能也许就会诞生,这也是为什么说在机器学习快速发展的现在,人工智能可能不再是梦想的原因。
人工智能的发展可能不仅取决于机器学习,更取决于前面所介绍的深度学习,深度学习技术由于深度模拟了人类大脑的构成,在视觉识别与语音识别上显著性的突破了原有机器学习技术的界限,因此极有可能是真正实现人工智能梦想的关键技术。无论是谷歌大脑还是百度大脑,都是通过海量层次的深度学习网络所构成的。也许借助于深度学习技术,在不远的将来,一个具有人类智能的计算机真的有可能实现。

相关文章:
人工智能深度学习
目录 人工智能 深度学习 机器学习 神经网络 机器学习的范围 模式识别 数据挖掘 统计学习 计算机视觉 语音识别 自然语言处理 机器学习的方法 回归算法 神经网络 SVM(支持向量机) 聚类算法 降维算法 推荐算法 其他 机器学习的分类 机器…...

python reshape 和 transpose的区别
reshape() 和 transpose() 是用于改变数组或张量形状的两种不同方法, 它们的主要区别在于如何重新排列元素以及是否可以改变轴的顺序。 1 reshape() reshape() 函数用于改变数组或张量的形状,但是不改变元素的排列顺序。它只是简单地将数组的维度重新…...

音视频技术-网络视频会议“回声”的消除
目录 一、“回音”的成因原理 二、解决思路 三、解决方案 1、方案一 2...

有哪些令人惊讶的心理学效应
大家可以想象一个场景: 如果一次考试,你考了95分,比上次还进步了10分,你会感到高兴吗? 听起来很牛逼啊,值得干杯庆祝,好好开心几天了。 这时,你看到同桌这次居然是一百分…...
二叉树基础知识总结
目录 二叉树基础知识 概念 : 根节点的五个形态 : 特殊的二叉树 满二叉树 : 完全二叉树 : 二叉搜索树 : 平衡二叉搜索树 : 二叉树的性质 : 二叉树的存储结构 二叉树的顺序存储结构 二叉树的链式存储结构 二叉树的遍历方式 : 基础概念 前中后遍历 层序遍历 :…...

IDEA2023.3.4开启SpringBoot项目的热部署【简单明了4步操作】
添加devtools依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional> </dependency>IDEA开启自动编译 …...

QT中调用python
一.概述 1.Python功能强大,很多Qt或者c/c开发不方便的功能可以由Python编码开发,尤其是一些算法库的应用上,然后Qt调用Python。 2.在Qt调用Python的过程中,必须要安装python环境,并且Qt Creator中编译器与Python的版…...
Sora基础知识学习
...

开源博客项目Blog .NET Core源码学习(9:Autofac使用浅析)
开源博客项目Blog使用Autofac注册并管理组件和服务,Autofac是面向.net 的开源IOC容器,支持通过接口、实例、程序集等方式注册组件和服务,同时支持属性注入、方法注入等注入方式。本文学习并记录Blog项目中Autofac的使用方式。 整个Blog解…...

Go语言中的TLS加密:深入crypto/tls库的实战指南
Go语言中的TLS加密:深入crypto/tls库的实战指南 引言crypto/tls库的核心组件TLS配置:tls.Config证书加载与管理TLS握手过程及其实现 构建安全的服务端创建TLS加密的HTTP服务器配置TLS属性常见的安全设置和最佳实践 开发TLS客户端应用编写使用TLS的客户端…...
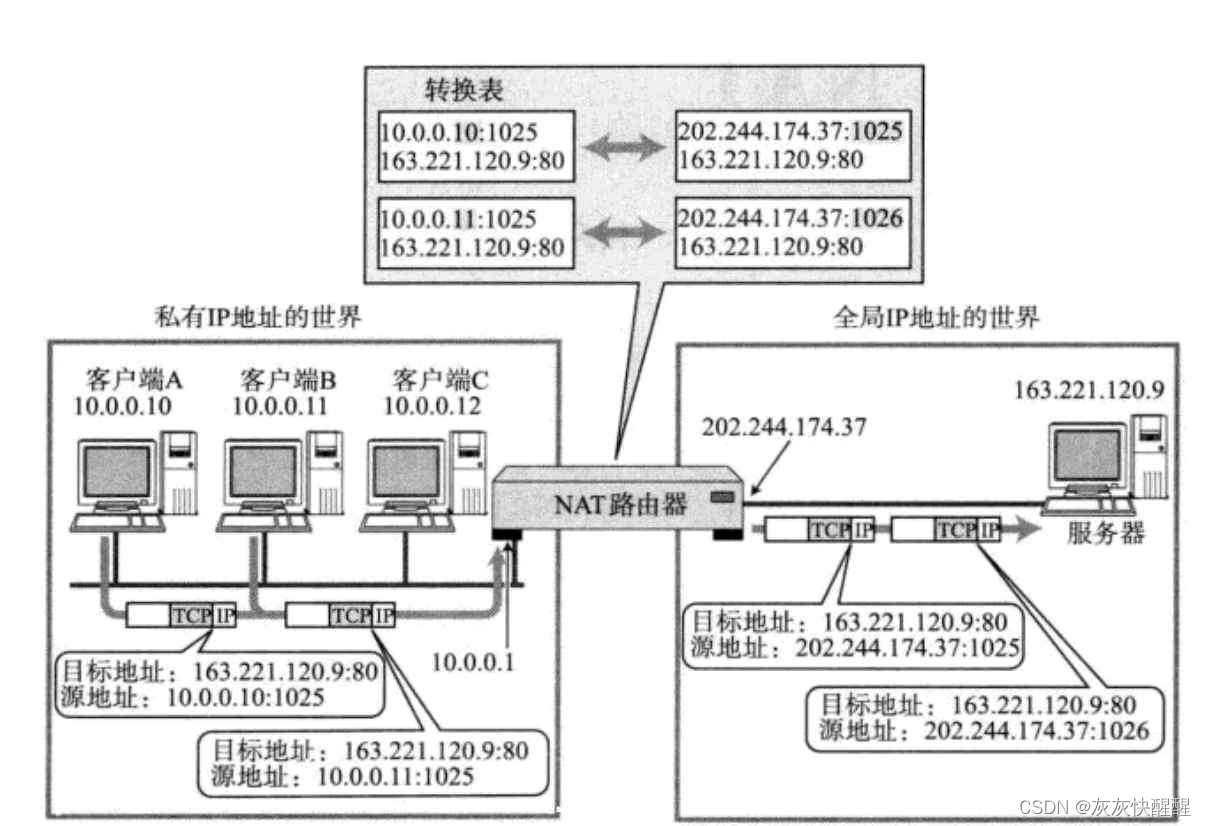
网络原理-TCP/IP(7)
目录 网络层 路由选择 数据链路层 认识以太网 以太网帧格式 认识MAC地址 对比理解MAC地址和IP地址 认识MTU ARP协议 ARP协议的作用 ARP协议工作流程 重要应用层协议DNS(Domain Name System) DNS背景 NAT技术 NAT IP转换过程 NAPT NAT技术的优缺点 网络层 路由…...
HarmonyOS4.0系列——08、整合UI常用组件
HarmonyOS4.0 系列——08、UI 组件 Blank Blank 组件在横竖屏占满空余空间效果 // xxx.ets Entry Component struct BlankExample {build() {Column() {Row() {Text(Button).fontSize(18)Blank()Toggle({type: ToggleType.Switch}).margin({top: 14,bottom: 14,left: 6,righ…...

【Spring Boot 3】【JPA】一对多单向关联
【Spring Boot 3】【JPA】一对多单向关联 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...

工信部等九部门:打造一批实现制造过程数字孪生的数字化转型标杆工厂
“人工智能技术与咨询” 发布 培育一批科技领军人才、青年骨干人才,以及一批既懂原材料工业又懂数字技术的复合型人才。依托职业教育提质培优行动计划,加速培育数字化转型急需紧缺的工程师和技术技能人才。支持引进数字化转型海外高端人才。 ÿ…...
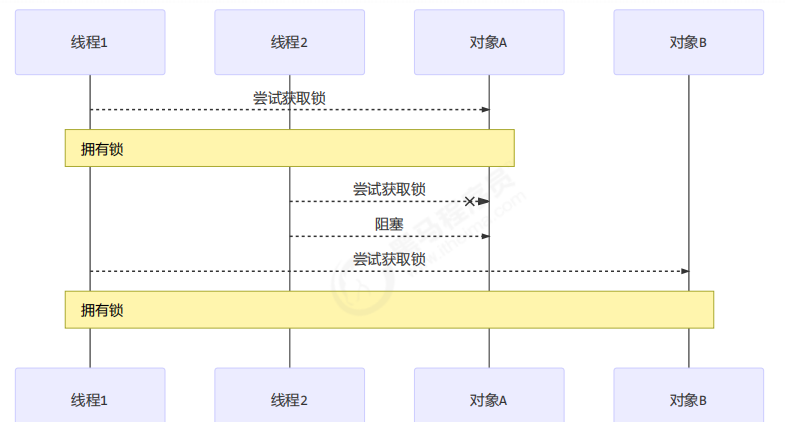
并发编程(2)基础篇-管程
4 共享模型之管程 本章内容 共享问题synchronized线程安全分析Monitorwait/notify线程状态转换活跃性Lock 4.1 共享带来的问题 4.1.1 小故事 老王(操作系统)有一个功能强大的算盘(CPU),现在想把它租出去ÿ…...

OpenAI文生视频大模型Sora概述
Sora,美国人工智能研究公司OpenAI发布的人工智能文生视频大模型(但OpenAI并未单纯将其视为视频模型,而是作为“世界模拟器” ),于2024年2月15日(美国当地时间)正式对外发布。 Sora可以根据用户…...
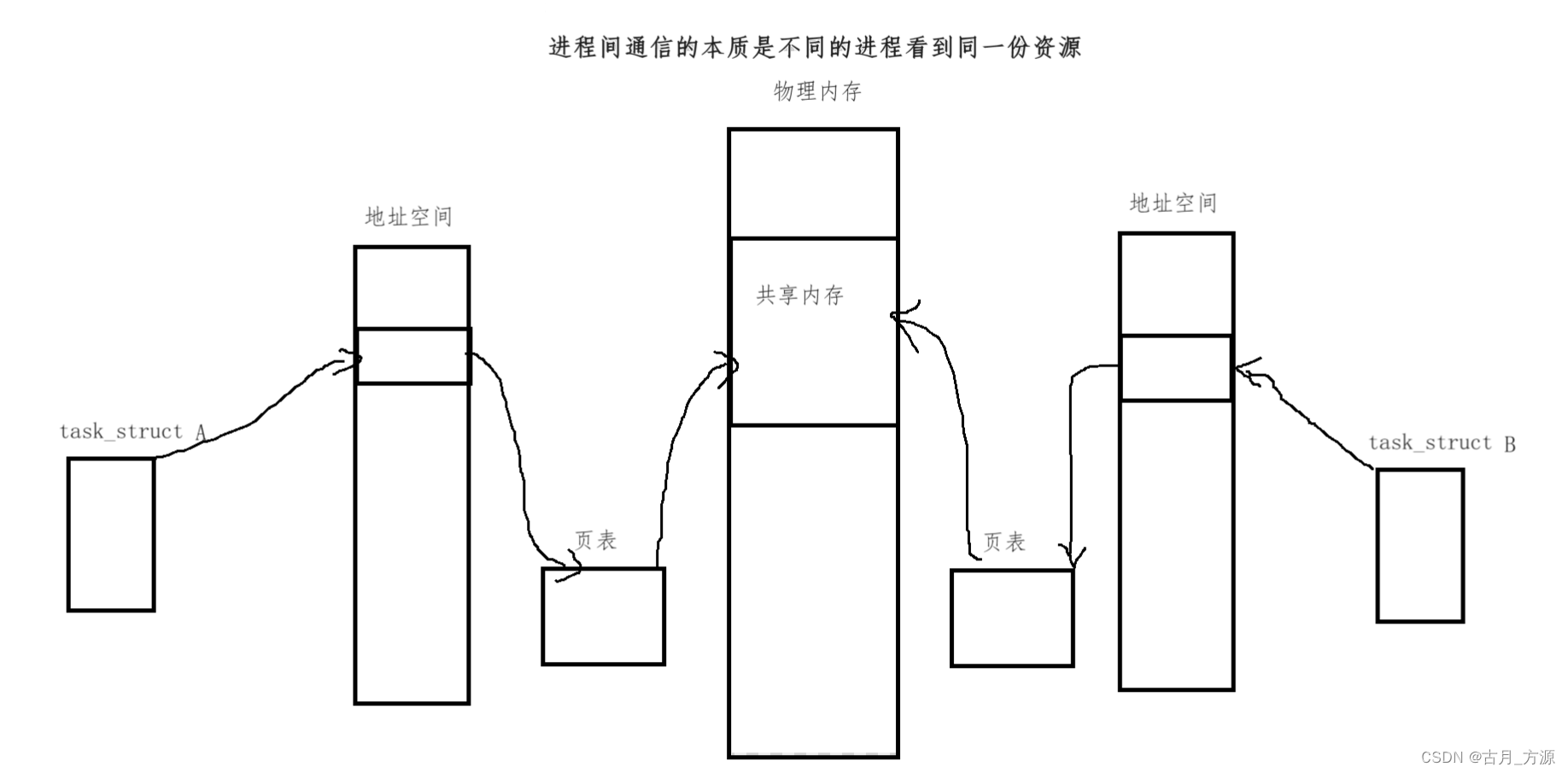
[linux]进程间通信(IPC)———共享内存(shm)(什么是共享内存,共享内存的原理图,共享内存的接口,使用演示)
一、什么是共享内存 共享内存区是最快的(进程间通信)IPC形式。一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据。注意:…...

Go 原子操作有哪些?
Go atomic包是最轻量级的锁(也称无锁结构),可以在不形成临界区和创建互斥量的情况下完成并发安全的值替换操作,不过这个包只支持int32/int64/uint32/uint64/uintptr这几种数据类型的一些基础操作(增减、交换、载入、存…...
爬虫知识--02
免费代理池搭建 # 代理有免费和收费代理 # 代理有http代理和https代理 # 匿名度: 高匿:隐藏访问者ip 透明:服务端能拿到访问者ip 作为后端,如何拿到使用代理人的ip 请求头中:x-forwor…...

SCI一区 | Matlab实现GAF-PCNN-MSA格拉姆角场和双通道PCNN融合注意力机制的多特征分类预测
SCI一区 | Matlab实现GAF-PCNN-MSA格拉姆角场和双通道PCNN融合注意力机制的多特征分类预测 目录 SCI一区 | Matlab实现GAF-PCNN-MSA格拉姆角场和双通道PCNN融合注意力机制的多特征分类预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 1.【SCI一区级】Matlab实…...

2026届最火的六大AI辅助论文网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术飞速发展着,智能内容生成也就是AIGC,正一步步渗透到学术…...

ESP32 OTA升级避坑指南:用Python脚本一键搭建本地服务器,告别手动配置
ESP32 OTA升级实战:Python自动化方案与高频问题破解 当你的ESP32设备部署在难以物理接触的场合——比如嵌入墙体的智能开关、高架桥上的环境监测节点,或是旋转机械内部的振动传感器,固件更新就成了开发者的噩梦。传统烧录器方案需要专人携带设…...

【软考高级架构】案例题考前突击——分布式一致性在互联网金融平台的应用
案例分析题:分布式一致性在互联网金融平台的应用 案例背景 某互联网金融平台为了满足高并发、高可用的业务需求,采用了基于微服务和分布式架构的系统设计。平台核心业务包括账户余额管理、交易流水记录、资金划转等关键模块。 为提升系统性能,架构师引入了如下关键设计:…...

强化学习入门:用Python实现Q-Learning算法
在软件测试领域,随着AI技术的不断渗透,掌握强化学习相关知识,能够帮助测试从业者更好地理解智能测试工具的底层逻辑,甚至开发出更高效的自动化测试方案。Q-Learning作为强化学习的经典入门算法,以其简洁的原理和广泛的…...

2026年制造业员工入转调离全流程自动化趋势?——从“系统孤岛”到“Agent全闭环”的效能革命
2026年,全球制造业正处于从“设备自动化”向“组织智能化”跨越的关键拐点。 随着人口红利消退与用工结构性矛盾加剧,工厂对于人力资源的精准配置已不仅是行政命题,而是直接影响产线柔性与交付周期的核心生产力命题。 传统的HR管理模式在面对…...

Qt实战:手把手教你优化QCustomPlot曲线图,解决坐标轴覆盖数据点的坑
Qt实战:深度优化QCustomPlot曲线图显示效果 在Qt应用开发中,数据可视化是提升用户体验的关键环节。QCustomPlot作为Qt生态中最受欢迎的2D绘图库之一,以其轻量级和高性能著称,被广泛应用于工业控制、科学研究和金融分析等领域。然而…...

Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作
Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作 上个月老板丢给我一个任务:把现有的Electron应用搬到鸿蒙PC上。我花了两天把代码跑通了,build了一版安装包,一看体积——180MB。老板看了一眼࿰…...

NewJob智能识别插件:求职时间管理的终极解决方案
NewJob智能识别插件:求职时间管理的终极解决方案 【免费下载链接】NewJob 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 项目地址: https://gitcode.com/GitHub_Trending/ne/NewJob 在…...

从0开始详解网络安全自学全流程!附对应的视频教程和学习笔记
从0开始详解网络安全自学全流程!附对应的视频教程和学习笔记 今天给大家梳理了从0开始详解网络安全自学全流程!对应的视频教程和学习笔记也都整理好了,大家去文末自取就行。 第一步:刑法 为什么学:划清合法与违法的红…...

高性能Go Web框架Volo:设计原理、核心功能与生产实践
1. 项目概述:一个高性能的Go语言Web框架最近在折腾一个需要处理高并发请求的API服务,选型时又一次把目光投向了Go生态。说实话,Go的Web框架选择不少,从轻量级的Gin、Echo,到功能更全的Beego、Iris,各有各的…...