深入理解C语言(5):程序环境和预处理详解


- 文章主题:程序环境和预处理详解🌏
- 所属专栏:深入理解C语言📔
- 作者简介:更新有关深入理解C语言知识的博主一枚,记录分享自己对C语言的深入解读。😆
- 个人主页:[₽]的个人主页🏄🌊
程序环境和预处理详解
- 前言
- 程序的翻译环境和执行环境
- 详解编译+链接
- 翻译环境
- 编译本身也分为几个阶段:
- 运行环境
- 预处理详解
- 预定义符号
- define
- #define 定义标识符
- #define 定义宏
- #define 的替换规则
- #和##
- 带副作用的宏参数
- 宏和函数对比
- 命名约定
- #undef
- 命令行定义
- 条件编译
- 文件包含
- 头文件被包含的方式:
- 嵌套文件包含
- 其他预处理指令
- 总结
前言
程序的运行离不开起相对应的环境,其中翻译环境中的编译环境中的预处理环境又是我们了解甚少的一个环境,下文就是关于程序环境和预处理环境的详解。😆
程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
- 翻译环境:在这个环境中源代码被转换为可执行的机器指令。
- 执行环境:它用于实际执行代码。
详解编译+链接
翻译环境
程序编译过程:

- 组成一个程序的每个源文件通过编译过程分别转换成目标代码(
object code)。- 每个目标文件由链接器(
linker)捆绑在一起,形成一个单一而完整的可执行程序。- 链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人 的程序库,将其需要的函数也链接到程序中。
编译本身也分为几个阶段:
例:
sum.c
int g_val = 2016;
void print(const char *str)
{
printf("%s\n", str);
}
test.c
#include <stdio.h>
int main()
{
extern void print(char *str);
extern int g_val;
printf("%d\n", g_val);
print("hello bit.\n");
return 0;
}
发生的编译与链接:

如何查看编译期间的每一步发生了什么呢?(vs code文本编辑器)
test.c
#include <stdio.h>
int main()
{
int i = 0;
for(i=0; i<10; i++)
{
printf("%d ", i);
}
return 0;
}
- 预处理 选项
gcc -E test.c -o test.i
预处理完成之后就停下来,预处理之后产生的结果都放在test.i文件中。- 编译 选项
gcc -S test.c
编译完成之后就停下来,结果保存在test.s中。- 汇编
gcc -c test.c
汇编完成之后就停下来,结果保存在test.o中。
运行环境
程序执行的过程:
- 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
- 程序的执行便开始。接着便调用
main函数。 - 开始执行程序代码。这个时候程序将使用一个运行时堆栈(
stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。 - 终止程序。正常终止
main函数;也有可能是意外终止。
预处理详解
预定义符号
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
这些预定义符号都是语言内置的。
例:
printf("file:%s line:%d\n", __FILE__, __LINE__);
define
#define 定义标识符
标识符对应的值也是文本,所以不仅是复制粘贴后会被解析成数值的数字文本,其余的文本也均可,甚至与不写也可以(但不会像非预编译指令中的变量那样赋随机值,逻辑不同,对应的也不是内存,可能其中根本就不会存在有值),因为宏定义的标识符有时候起到的作用就仅仅是标识一部文本的作用或者整个文件的作用,一般会和条件编译语句中检测是否用预定义指令定义了一个标识符的结构搭配在一起使用,这是标识符起到的作用就真的是检测其是否定义的作用了,这就是什么相当于官方定义的标识符的程序创建时一开始就自带创建和变化的预定义符号中的最后一个
__STDC__,要么符合ANSI C标准为1.要么就为未定义的原因了,估计也是为了符合标识符这一预定义指令的风格,方便和条件编译指令通过标识符判断是否定义了表示的效果搭配在一起用的,该编译器内部是否用ANSI C的标准就可以直接通过条件编译的预处理指令把这一效果给打印出来。
语法:
#define name stuff
例:
#define MAX 1000
#define reg register //为 register这个关键字,创建一个简短的名字
#define do_forever for(;;) //用更形象的符号来替换一种实现
#define CASE break;case //在写case语句的时候自动把 break写上。
// 如果定义的 stuff过长,可以分成几行写,除了最后一行外,每行的后
// 面都加一个反斜杠(续行符)。宏和预定义多行书写时都会用到续行符。
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n" ,\__FILE__,__LINE__ , \__DATE__,__TIME__ )
提问:
在
define定义标识符的时候,要不要在最后加上;?
例:
#define MAX 1000;
#define MAX 1000
建议不要加上 ; ,这样容易导致问题,就算不产生问题也会影响程序运行的效率,是不好的习惯。
如:
if(condition)
max = MAX;
else
max = 0;
因为在C语言中else前的语句一定得是if,所以在这里预处理的阶段经过文本替换以后else前的语句实际上是;,就会造成后面编译的错误。
#define 定义宏
#define 机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(
macro)或定义宏(define macro)。
下面是宏的申明方式:
#define name( parament-list ) stuff
其中的 parament-list 是一个由逗号隔开的符号表,它们可能出现在stuff中。
注:
参数列表的左括号必须与name紧邻。
如果两者之间有任何空白存在,参数列表就会被解释为stuff的一部分。
如:
#define SQUARE( x ) x * x
这个宏接收一个参数 x 。如果在上述声明之后,你把SQUARE( 5 );置于程序中,预处理器就会用5 * 5这个表达式替换上面的表达式。
但是,这个宏存在一个问题:
观察下面的代码段:
int a = 5;
printf("%d\n" ,SQUARE( a + 1) );
乍一看,你可能觉得这段代码将打印36这个值。
事实上,它将打印11。
为什么?
替换文本时,参数x被替换成
a + 1,所以这条语句实际上变成了:printf ("%d\n",a + 1 * a + 1 );
这样就比较清晰了,由替换产生的表达式并没有按照预想的次序进行求值。
在宏定义上加上两个括号,这个问题便轻松的解决了:
#define SQUARE(x) (x) * (x)
这样预处理之后就产生了预期的效果:
printf ("%d\n",(a + 1) * (a + 1) );
这里还有一个宏定义:
#define DOUBLE(x) (x) + (x)
定义中我们使用了括号,想避免之前的问题,但是这个宏可能会出现新的错误。
int a = 5;
printf("%d\n" ,10 * DOUBLE(a));
这将打印什么值呢?
看上去,好像打印100,但事实上打印的是55。
我们发现替换之后:
printf ("%d\n",10 * (5) + (5));
乘法运算先于宏定义的加法,所以出现了
55。
这个问题,的解决办法是在宏定义表达式两边加上一对括号就可以了。
#define DOUBLE(x) ( ( x ) + ( x ) )
提示:
所以用于针对数值表达式进行求值的宏定义都应该用这种方式加上括号,避免在使用宏时由于参数中的操作符或邻近操作符之间不可预料的优先级之间的相互作用。
#define 的替换规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
- 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。(指在程序中用宏时参数如果用的也是预处理时的标识符时,会先把标识符中的数据替换之后再把宏中的文本替换,因为都是在预处理时就处理的东西,所以做的到赶在它文本预处理之前就把参数中的内容赶上它预处理替换的进度给替换进去了,不是预处理处的变量就做不到这一点,只能在预处理文本替换后,才能再把变量的值在编译之后的完整的汇编语言再在汇编过程中把汇编语言转换成二进制语言再在很后面的运行过程中才能在内存操作中把它变量的值引用进去)
- 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值所替换。
- 最后,再次对结果文件进行扫描,看看它是否包含任何由
#define定义的符号。如果是,就重复上述处理过程。(可能因为一些原因没有处理的#define定义的符号就会在第二次做完,只会判断两次,如果还没有判断完也就不会继续判断了,一般也很少会出现这种情况。
注意:
- 宏参数和
#define定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。(即宏可以被嵌套(针对于同类而言,不同类不能用嵌套这种说法),但只能嵌套标识符,不能嵌套完全一样的宏)- 当预处理器搜索
#define定义的符号的时候,字符串常量的内容并不被搜索,当然标识符不行则也一样可以判断出同性质的宏参数也不行,得用后面提到的#的知识点来解决该问题。(可以理解成不是处在同一个图层的文本效果,字符与字符串中与宏相同的符号为避免与宏中的标识符相冲突,并不会被替换,而是字符(串)中是什么文本就依然用什么文本)
#和##
前面说过与预定义相关的所有文本都不会在字符串中的内容给检测到,但在宏中的参数可以有一种方法让这种参数插入到字符串中。如何把参数插入到字符串中?
首先我们看看这样的代码:
char* p = "hello ""bit\n";
printf("hello"" bit\n");
printf("%s", p);
这里输出的是不是
hello bit ?
答案是确定的:是。
我们发现字符串是有自动连接的特点的。
那我们是不是可以写这样的代码?:
#define PRINT(FORMAT, VALUE)\
printf("the value is "FORMAT"\n", VALUE);
...
PRINT("%d", 10);
这里只有当字符串作为宏参数的时候才可以把字符串放在字符串中。
另外一个技巧是:
使用 # ,把一个不是字符串的宏参数变成对应的字符串。
例:
int i = 10;
#define PRINT(FORMAT, VALUE)\
printf("the value of " #VALUE "is "FORMAT "\n", VALUE);
...
PRINT("%d", i+3);//产生了什么效果?
代码中的 #VALUE 会被预处理器处理为:
"VALUE"。
最终的输出的结果应该是:
the value of i+3 is 13
## 的作用
##可以把位于它两边的符号合成一个符号。
它允许宏定义从分离的文本片段创建标识符。
#define ADD_TO_SUM(num, value) \
sum##num += value;
...
ADD_TO_SUM(5, 10);//作用是:给sum5增加10.
注:
这样的连接必须产生一个合法的标识符。否则其结果就是未定义的。
宏参数虽然也是直接文本复制粘贴,但他还是无法直接把两个宏参数合到一起的整个字符当做一个变量名去用,这种情况下就必须要借用##来帮助其实现这种效果了。
带副作用的宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果。副作用就是表达式求值的时候出现的永久性效果(主要即指一些变量的值在参数执行一次语句后只就会因为带有副作用发生了变化而影响后面的宏语句的情况)(因为宏是直接将文本复制粘贴的缘故副作用会被叠加多次而不是函数的形成一份赋值形参的逻辑,所以将带有一次副作用的语句带入一个出现多次的宏中时,参数的副作用也会随着叠加,造成危险情况发生)。
例:
x+1;//不带副作用
x++;//带有副作用
MAX宏可以证明具有副作用的参数所引起的问题。
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
...
x = 5;
y = 8;
z = MAX(x++, y++);
printf("x=%d y=%d z=%d\n", x, y, z);//输出的结果是什么?
所以输出的结果是:
x=6 y=10 z=9
宏和函数对比
宏通常被应用于执行简单的运算(书写复杂的运算和逻辑为防止参数的作错误执行会比函数书写起来复杂很多)。
比如在两个数中找出较大的一个。
#define MAX(a, b) ((a)>(b)?(a):(b))
那为什么不用函数来完成这个任务?
原因有二:
- 用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。
所以宏比函数在程序的规模和速度方面更胜一筹。(只是文本的复制粘贴不需要繁杂的调用返回操作) - 更为重要的是函数的参数必须声明为特定的类型。
所以函数只能在类型合适的表达式上使用。反之这个宏则可以适用于整形、长整型、浮点型等,可以用于>来比较的类型(参数的范围和执行参数运算与操作的范围比函数要大得多)。
宏是类型无关的。
宏的缺点:
当然和函数相比宏也有劣势的地方:
3. 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序
的长度。
4. 宏是没法调试的(因为是在预处理阶段就执行完了,且宏中可以有多个语句,也可以一个完整的语句都没有,调试时以宏的文本来看的话,为避免显示过于复杂,编译器的效果就干脆处理成是直接一步就过去了,这也是为什么一般在宏中只写简单语句的原因,复杂的宏体出错后难以通过调试得出问题的原因)。
5. 3. 宏由于类型无关,也就不够严谨(一些对参数类型要求严谨的逻辑不能由宏来书写)。
6. 宏可能会带来运算符优先级的问题,导致程容易出现错(且规避这种情况时括号过多也会使稍复杂的结构就繁杂不清)。
宏有时候可以做函数做不到的事情。比如:宏的参数可以出现类型(通过类型名的文本来表示意思),但是函数做不到(函数的参数不是文本,而是量,最多也只能通过参数的大小来大概的辨别类型的情况,或者字符串,但这些都远没有宏方便)。
#define MALLOC(num, type)\
(type *)malloc(num * sizeof(type))
...
//使用
MALLOC(10, int);//类型作为参数
//预处理器替换之后:
(int *)malloc(10 * sizeof(int));
宏和函数的一个对比
| 属性 | #define定义宏 | 函数 |
|---|---|---|
| 代码长度 | 每次使用时,宏代码都会被插入到程序中。除了非常小的宏之外,程序的长度会大幅度增长 | 函数代码只出现于一个地方;每次使用这个函数时,都调用那个地方的同一份代码 |
| 执行速度 | 更快 | 存在函数的调用和返回的额外开销,所以相对慢一些 |
| 操作符优先级 | 宏参数的求值是在所有周围表达式的上下文环境里,除非加上括号,否则邻近操作符的优先级可能会产生不可预料的后果,所以建议宏在书写的时候多些括号。 | 函数参数只在函数调用的时候求值一次(相当于将参数处的代码当作一个表达式将其算出结果之后再将其放入到函数中对应该参数创造的形参中),它的结果值传递给函数。表达式的求值结果更容易预测。 |
| 带有副作用的参数 | 参数可能被替换到宏体中的多个位置,所以带有副作用的参数求值可能会产生不可预料的结果。(带有副作用的文本参数被直接复制粘贴宏中多少次就会被执行多少次) | 函数参数只在传参的时候求值一次,结果更容易控制。(有副作用也只会在将值带入函数形参中被求值的那一次时在整个函数运行中造成一次副作用) |
| 参数类型 | 宏的参数与类型无关(因为本质就是把该参数当成是一个文本(参数的作用本质就是把其当作文本的形式复制粘贴到宏体的多个位置)),只要对参数的操作是合法的,它就可以使用于任何参数类型。 | 函数的参数是与类型有关的,如果参数的类型不同,就需要不同的函数,即使他们执行的任务是相同的。(小则警告,大则导致与变量有关的逻辑算出来的结果出错) |
| 调试 | 宏是不方便调试的(调试时直接一步跳过,内部的具体逻辑是看不到的) | 函函数是可以逐语句调试的(因为是调用到那一个函数体当中了,每一步具体的逻辑都可以直接被看到) |
| 递归 | 宏是不能递归的(即自己嵌套自己,递归不行但宏可以自己嵌套标识符,此时标识符会被先执行) | 函数是可以递归的(可以自己嵌套自己,执行多次) |
命名约定
一般来讲函数和宏的使用语法很相似。所以语言本身没法帮我们区分二者。
那我们平时的一个习惯是:
把宏名全部大写
函数名不要全部大写(但有意思的是一些库中自带的宏基本上字母全部又都是小写的,自己写时稍稍注意要去大写即可)
#undef
这条指令用于移除一个宏定义。
#undef NAME
//如果现存的一个名字需要被重新定义,
//那么它的旧名字首先要被移除。
//(或者后续不用该名字时,也可以先采用移除操作)
命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处。(假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大些,我们需要一个数组能够大些。(即通过在命令行中通过命令行的语法对预定义的标识符进行一些赋值来实现较方便的不同版本的测试作用,在一些没有这写功能的编译器下试图这么做的话则会因为标识符未定义而在后续如果运用了该标识符的话出错(在VS中会被错误的检测成语法错误,但本质应是运行错误,因为你不实际在C语言语法中用这个标识符的话,就完全不会出现错误)))
#include <stdio.h>
int main()
{int array [ARRAY_SIZE];int i = 0;for(i = 0; i< ARRAY_SIZE; i ++){array[i] = i;}for(i = 0; i< ARRAY_SIZE; i ++){printf("%d " ,array[i]);}printf("\n" );return 0;
}
编译指令:
//linux 环境演示(linux具有命令行预定义标识符的能力)
gcc -D ARRAY_SIZE=10 programe.c
条件编译
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的。因为我们有条件编译指令。
比如说:
调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译。
#include <stdio.h>
#define __DEBUG__//这里就体现了标识符预定义之后不确定其代表的常量值时//是完全符合语法规范的,因为既可以在条件编译时充当//#ifdef的条件,又可以在命令行中去重新赋值,只要不将//其直接拿来用就行
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0; i<10; i++)
{
arr[i] = i;
#ifdef __DEBUG__
printf("%d\n", arr[i]);//为了观察数组是否赋值成功。
#endif //__DEBUG__
}
return 0;
}
常见的条件编译指令:
1.
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__
//..
#endif
2.多个分支的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
3.判断是否被定义
#if defined(symbol) //defined(symbol)和!defined(symbol)是C语言中独属于条件编译的
#ifdef symbol //具有真假判断性的表达式,且与普通定义不同,括号紧挨其后(与关
#if !defined(symbol)//键字sizeof相同,函数和宏不同括号不一定紧挨其后但是一定要有,
#ifndef symbol //所有的预处理指令都是清一色的可以用续行符来达到分行写的目的,
4.嵌套指令 //且续行符的语法规则是续行符两边的空格全都可以忽略不计)在#if中
#if defined(OS_UNIX)//还能够被分别简写为#ifdef和#ifndef
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif
文件包含
我们已经知道, #include 指令可以使另外一个文件被编译。就像它实际出现于 #include 指令的地方一样。
这种替换的方式很简单:
预处理器先删除这条指令,并用包含文件的内容替换。
这样一个源文件被包含10次,那就实际被编译10次(与函数每次调用都回到定义处的原理不同,与预定义逻辑相同的很简单的复制粘贴逻辑,预处理指令均是预处理时对编辑后的C语言代码文本的文本操作,所以不是复制粘贴就会是在原文本的删除操作(即条件编译实现选择性编译效果的底层逻辑))。
头文件被包含的方式:
- 本地文件包含
#include "filename"//同源码文件相同位置处自己写的文件就被称作本地,//因为和写源码的地方完全相同
查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。如果找不到就提示编译错误。
Linux环境的标准头文件的路径:
/usr/include
VS环境的标准头文件的路径:
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//这是VS2013的默认路径
注意按照自己的安装路径去找,如果安装路径变化自然储存的位置和编译器查找的位置会发生变化。
- 库文件包含
#include <filename.h>
查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
这样是不是可以说,对于库文件也可以使用""的形式包含?
答案是肯定的,可以。
但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。
嵌套文件包含
如果出现这样的场景:

comm.h和comm.c是公共模块。
test1.h和test1.c使用了公共模块。
test2.h和test2.c使用了公共模块。
test.h和test.c使用了test1模块和test2模块。
这样最终程序中就会出现两份comm.h的内容。这样就造成了文件内容的重复。
如何解决这个问题?
答案:条件编译。
每个头文件的开头写:
#ifndef __TEST_H__
#define __TEST_H__
//头文件的内容
#endif //__TEST_H__
// 因为如果引用了相同头文件的文件也会因为复制粘贴具有相同的结构,
// __TEST_H__标识符就被定义了,防止在下一次引用时被重复嵌套了,
// __TEST_H__一旦被引用过就会被预定义了就一定可以通过条件编译在
// 预处理阶段就防止相同的文本出现在C语言的文本文件中,相同的文本文件
// 更不会因此被编译了
或者:
#pragma once//检测在同一程序中的引用情况,让其在同一程序中只引用一次
就可以避免头文件的重复引入。
笔试题:
- 头文件中的 ifndef/define/endif是干什么用的?
- #include <filename.h> 和 #include "filename.h"有什么区别?
答:
1.ifndef属于条件编译指令,检测的是标识符的未定义,如果#ifndef后的标识符未定义的话就编译#ifndef涵盖下的C语言文本,反之则不编译其涵盖下的C语言文本,如果其后仍有条件编译语句就继续判断符合条件可编译的语句,如果直接是#endif就直接没有可编译的语句。define属于预处理指令中的预定义指令,用于定义标识符和宏。#endif属于条件编译指令,是单个条件编译结构结束的标志
2. #include <filename.h>属于库文件包含,直接去标准路径中查找头文件,没找到则提示编译错误,#include "filename.h"属于本地文件包含,先在源文件所在的目录下(本地)查找,如果未找到则像库文件查找一样在标准位置查找头文件,没找到则提示编译错误,其中标准库中的头文件也可以被本地文件包含查找到,但这样效率更低,且不容易区分谁是库文件谁是本地文件了。
其他预处理指令
#error
#pragma
#line
...
//不做介绍,自己去了解。
#pragma pack()//在结构体部分介绍过
#pragma pack()详细戳这:深入理解C语言(3):自定义类型详解
总结
以上就是博主对程序环境和预处理的详解,😄希望对你的C语言学习有所帮助!作为刚学编程的小白,可能在一些设计逻辑方面有些不足,欢迎评论区进行指正!看都看到这了,点个小小的赞或者关注一下吧(当然三连也可以~),你的支持就是博主更新最大的动力!让我们一起成长,共同进步!
相关文章:
深入理解C语言(5):程序环境和预处理详解
文章主题:程序环境和预处理详解🌏所属专栏:深入理解C语言📔作者简介:更新有关深入理解C语言知识的博主一枚,记录分享自己对C语言的深入解读。😆个人主页:[₽]的个人主页🏄…...
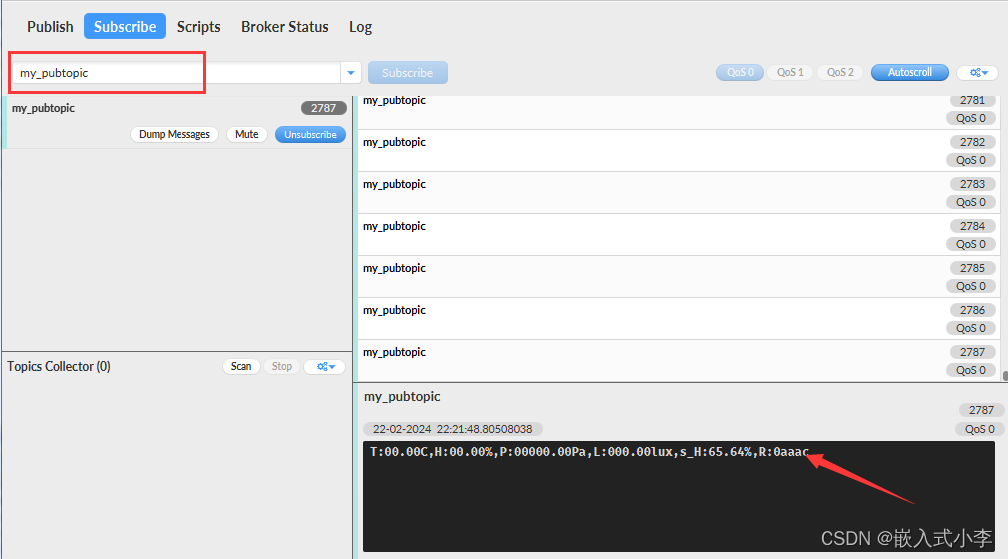
ESP8266智能家居(3)——单片机数据发送到mqtt服务器
1.主要思想 前期已学习如何用ESP8266连接WIFI,并发送数据到服务器。现在只需要在单片机与nodeMCU之间建立起串口通信,这样单片机就可以将传感器测到的数据:光照,温度,湿度等等传递给8266了,然后8266再对数据…...
—— 筑梦之路)
lvm逻辑卷创建raid阵列(不常用)—— 筑梦之路
RAID卷介绍 逻辑卷管理器(LVM)不仅仅可以将多个磁盘和分区聚合到一个逻辑卷中,以此提高单个分区的存储容量,还可以创建和管理独立磁盘的冗余阵列(RAID)卷,防止磁盘故障并提高性能。它支持常用的RAID级别,支持的RAID的级别有 0、1…...

LayUI发送Ajax请求
页面初始化操作 var processData null $(function () {initView();initTable();// test(); })function initView() {layui.use([laydate, form], function () {var laydate layui.laydate;laydate.render({elem: #applyDateTimeRange,type: datetime,range: true});}); }初始…...

平时积累的FPGA知识点(10)
平时在FPGA群聊等积累的FPGA知识点,第10期: 41 ZYNQ系列芯片的PL中使用PS端送过来的时钟,这些时钟名字是自动生成的吗? 解释:是的。PS端设置的是ps_clk,用report_clocks查出来的时钟名变成了clk_fpga_0&a…...
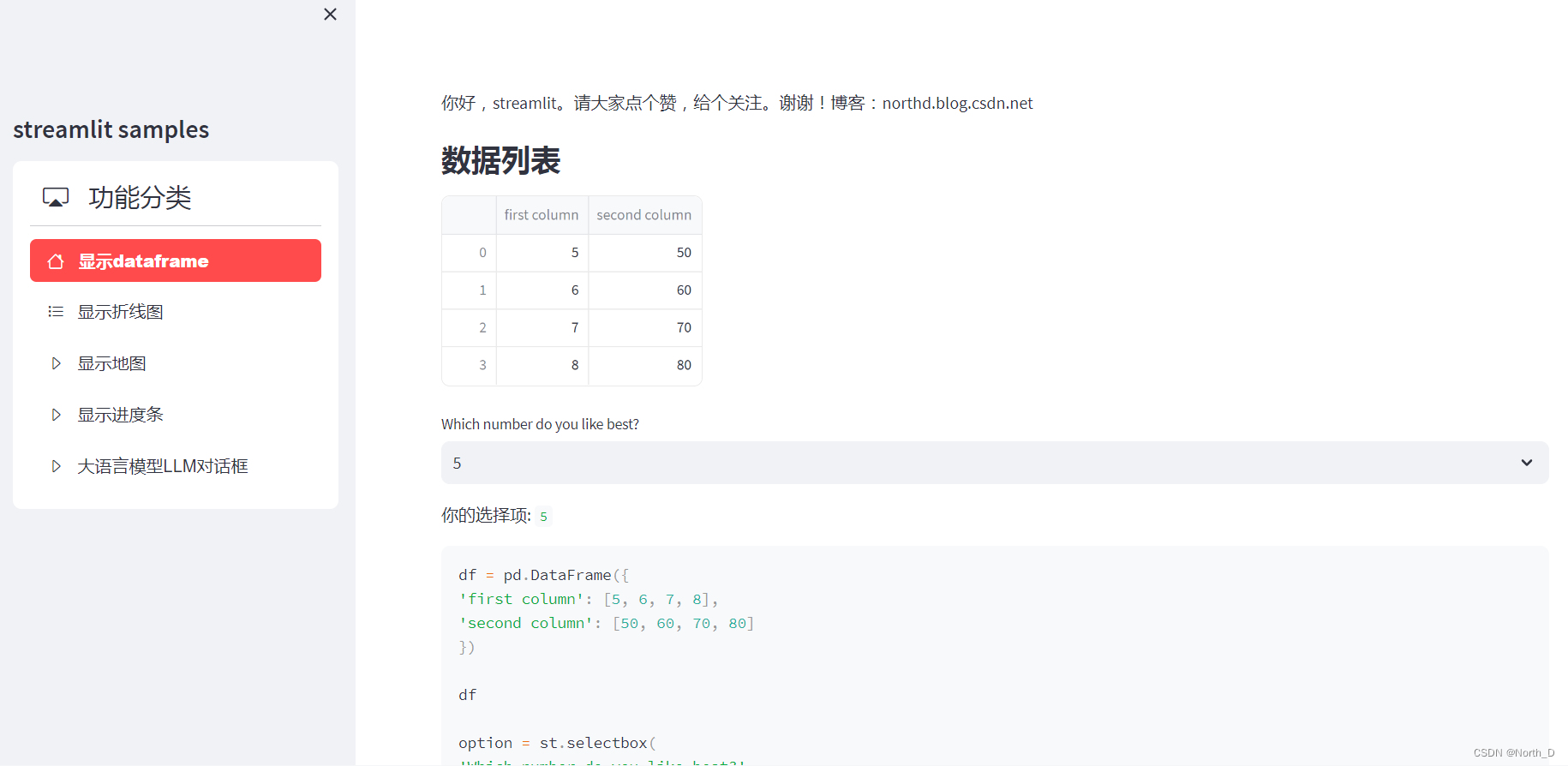
使用Streamlit构建纯LLM Chatbot WebUI傻瓜教程
文章目录 使用Streamlit构建纯LLM Chatbot WebUI傻瓜教程开发环境hello Streatelit显示DataFrame数据显示地图WebUI左右布局设置st.sidebar左侧布局st.columns右侧布局 大语言模型LLM Chatbot WebUI设置Chatbot页面布局showdataframe()显示dataframeshowLineChart()显示折线图s…...
电脑死机卡住怎么办 电脑卡住鼠标也点不动的解决方法
在我们使用电脑的过程中,可能由于电脑硬件或者软件的问题,偶尔会出现电脑卡住的情况,很多电脑小白都不知道电脑卡住了怎么办,鼠标也点不动,键盘也没用,一旦发生了这种情况,大家可以来参考一下小编分享的电脑死机卡住的解决方法。 电脑卡住鼠标也点不动的解决方法 方…...

RAG 语义分块实践
每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。 原文标题:Semantic chunking in practice 原文地址:https://medium.com/@boudhayan-dev/semantic-chunking-in-practice-23a8bc33d56d 语义分块的实践 回顾 …...

12 Autosar_SWS_MemoryMapping.pdf解读
AUTOSAR中MemMap_autosar memmap-CSDN博客 1、Memory Map的作用 1.1 避免RAM的浪费:不同类型的变量,为了对齐造成的空间两份; 1.2 特殊RAM的用途:比如一些变量通过位掩码来获取,如果map到特定RAM可以通过编译器的位掩码…...

【Linux取经路】文件系统之缓冲区
文章目录 一、先看现象二、用户缓冲区的引入三、用户缓冲区的刷新策略四、为什么要有用户缓冲区五、现象解释六、结语 一、先看现象 #include <stdio.h> #include <string.h> #include <unistd.h>int main() {const char* fstr "Hello fwrite\n"…...
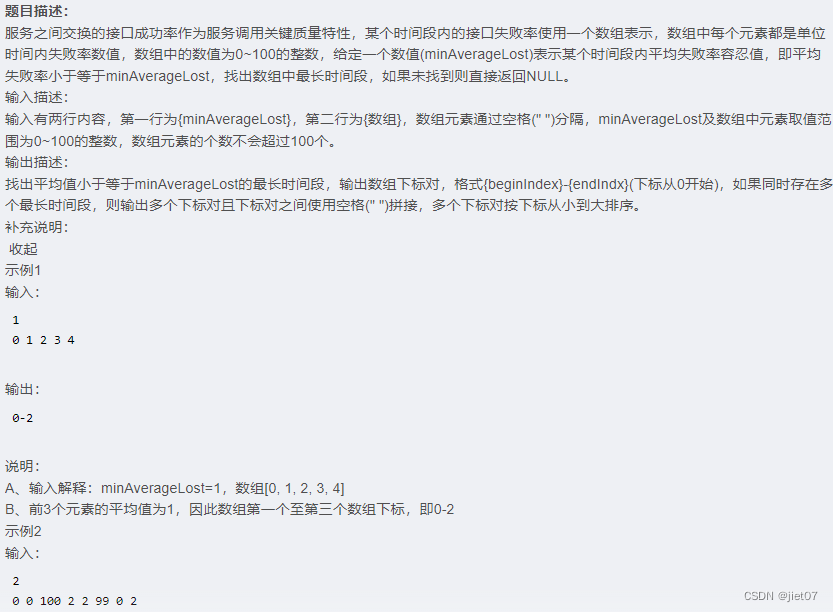
华为OD机试真题-查找接口成功率最优时间段-2023年OD统一考试(C卷)--Python3--开源
题目: 考察内容: for 时间窗口list(append, sum, sort) join 代码: """ 题目分析:最长时间段 且平均值小于等于minLost同时存在多个时间段,则输出多个,从大到小排序未找到返回 NULL 输入…...
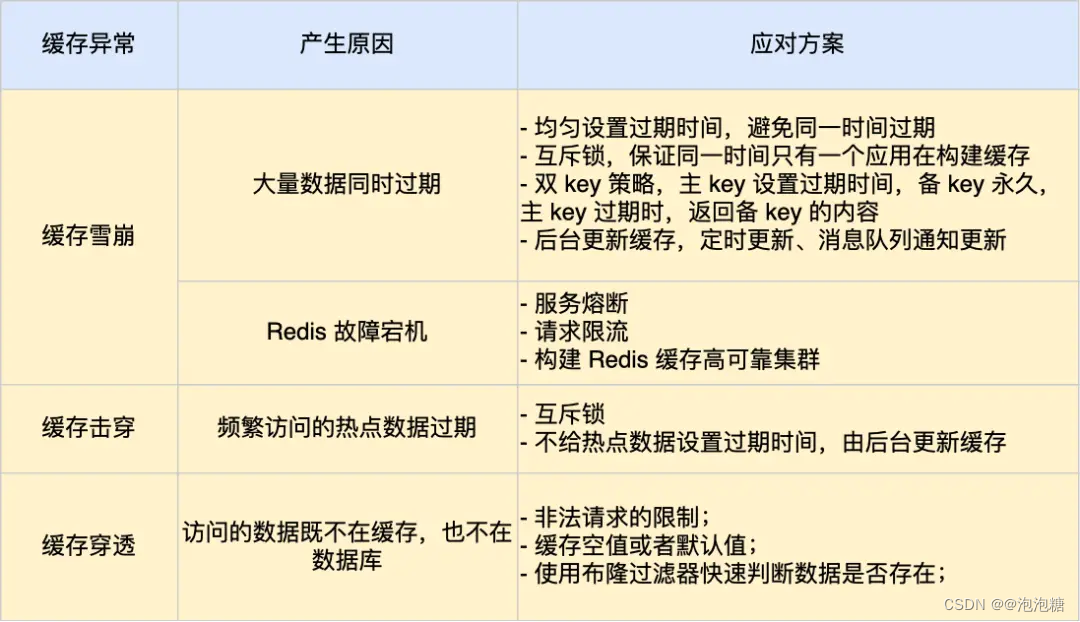
缓存篇—缓存雪崩、缓存击穿、缓存穿透
缓存异常会面临的三个问题:缓存雪崩、击穿和穿透。 其中,缓存雪崩和缓存击穿主要原因是数据不在缓存中,而导致大量请求访问了数据库,数据库压力骤增,容易引发一系列连锁反应,导致系统奔溃。不过࿰…...

Python实现视频转音频、音频转文本的最佳方法
文章目录 Python实现视频转音频和音频转文字视频转音频步骤 1:导入moviepy库步骤 2:选择视频文件步骤 3:创建VideoFileClip对象步骤 4:提取音频步骤 5:保存音频文件 音频转文字步骤 1:导入SpeechRecognitio…...

阿里云SSL免费证书到期自动申请部署程序
阿里云的免费证书只有3个月的有效期,不注意就过期了,还要手动申请然后部署,很是麻烦,于是写了这个小工具。上班期间抽空写的,没有仔细测试,可能存在一些问题,大家可以自己clone代码改改…...
【进阶版】)
Vue全局事件防止重复点击(等待请求)【进阶版】
继《Vue全局指令防止重复点击(等待请求)》之后,感觉指令方式还是不太友好,而且嵌套闭包比较麻烦,于是想到了Vue的全局混入,利用混入,给组件绑定click事件。 一、实现原理 与指令方式大致一样&…...

C#程序反编译经验总结
1. 反编译出的代码有问题时,可以用多个反编译工具之间的代码相互印证。(比如.net reflector 与ILSpy) 2. 有时Visual Studio编译的错误信息不明确时, 可以msbuild编译程序,msbuild的错误信息相对完整一些。 2.1 编译错误…...
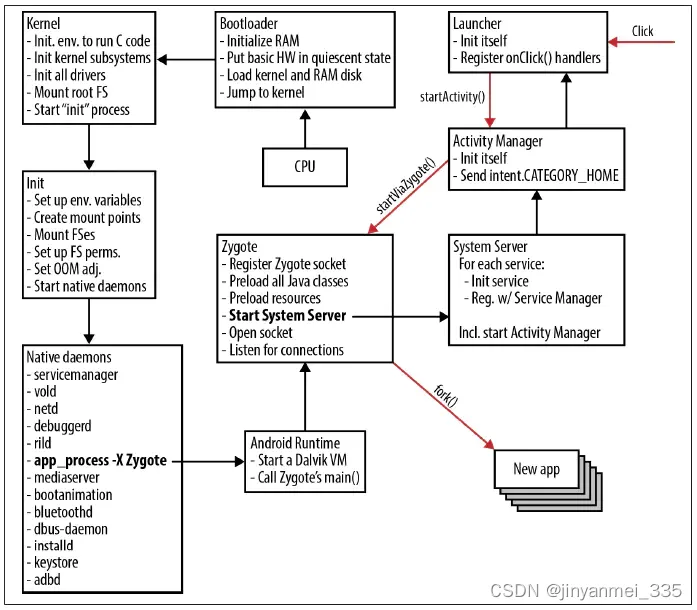
Android系统启动流程
android的启动流程是从底层开始进行的,具体如下所示: Android是基于Linux内核的系统,Android的启动过程主要分为两个阶段,首先是Linux内核的启动,然后是Android框架的启动。 可以将Andorid系统的启动流程分为以下五个…...
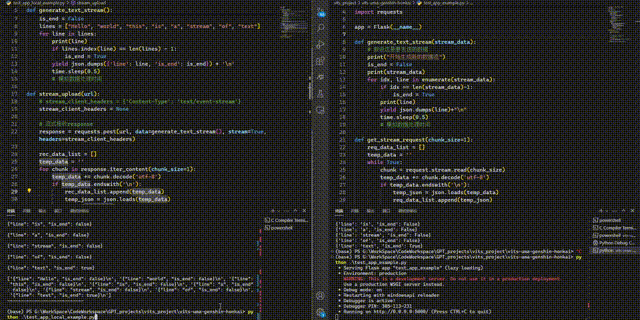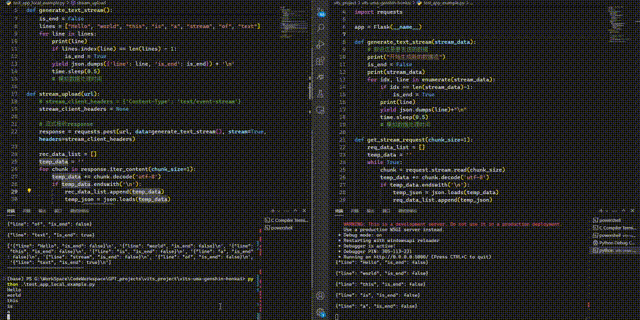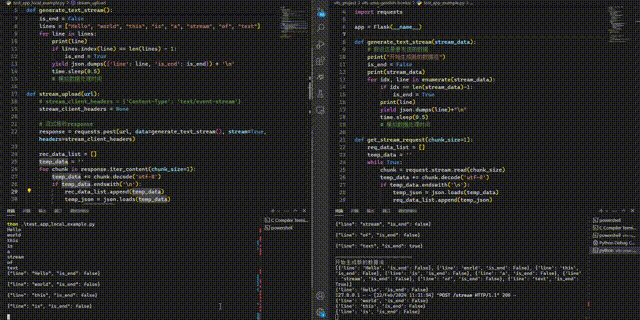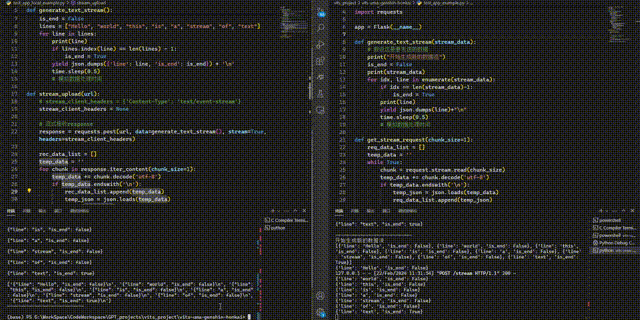
Flask——基于python完整实现客户端和服务器后端流式请求及响应
文章目录 本地客户端Flask服务器后端客户端/服务器端流式接收[打字机]效果 看了很多相关博客,但是都没有本地客户端和服务器后端的完整代码示例,有的也只说了如何流式获取后端结果,基本没有讲两端如何同时实现流式输入输出,特此整…...
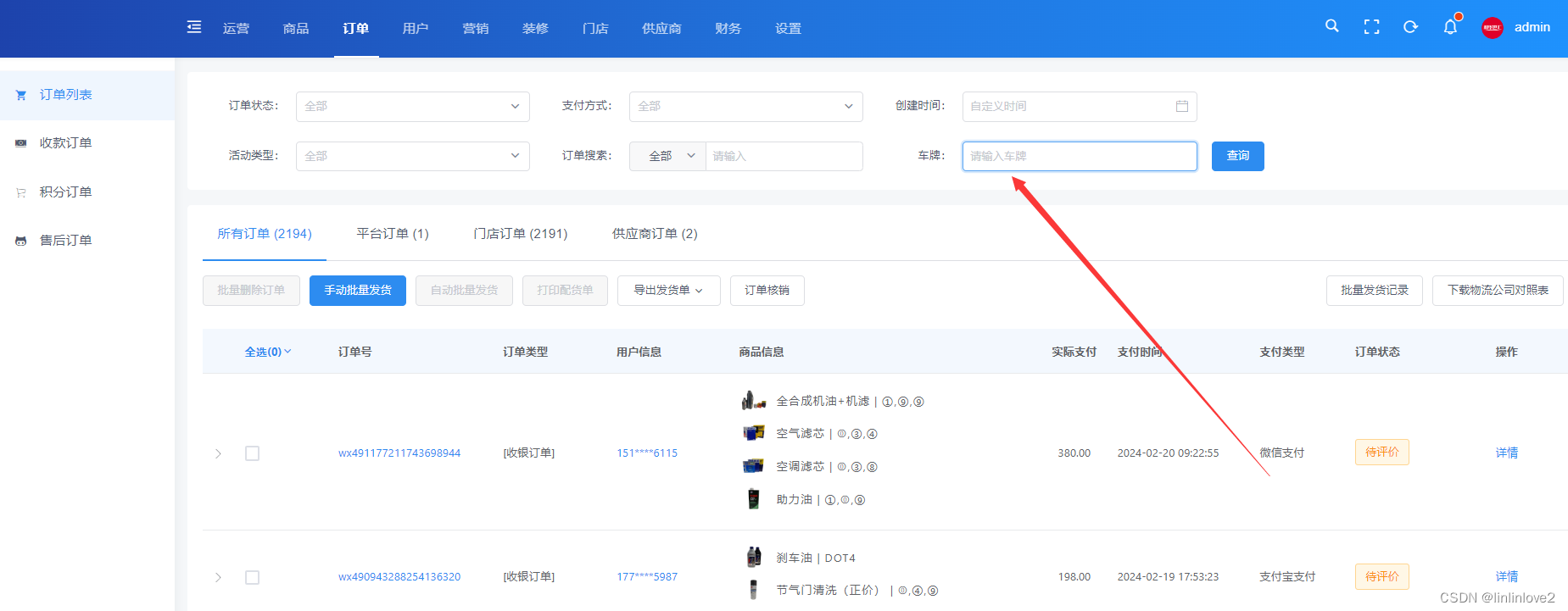
crmeb多门店商城系统二次开发 增加车辆车牌搜索功能、车辆公里数
1、增加的数据库 ALTER TABLE eb_store_order ADD cart_number VARCHAR(255) NOT NULL DEFAULT COMMENT 车牌 AFTER erp_order_id, ADD curmileage VARCHAR(255) NOT NULL DEFAULT COMMENT 当前里程 AFTER cart_number; ALTER TABLE eb_store_cart ADD cart_number VARCHAR(…...

深度好文|关于人类智能与自主系统
上个世纪 50 年代,在二战结束没多久,人们开始研究和设计智能系统。作为信息学的分支,人类开始了最早对于人工智能的研究。时间来到 60 年代,人们对于计算机的发展充满了信心,人们断言“20年内机器能够做任何人所能做的…...

AIGC 检测‘信息密度‘到底是什么?嘎嘎降 AI 帮你 AI 率从 65% 降到 8%
AIGC 检测"信息密度"到底是什么?嘎嘎降 AI 帮你 AI 率从 65% 降到 8% AIGC 检测算法 4.0 版本看的 5 项底层指标里——信息密度权重排第二(约 25%)。理解了这一项你才知道为什么"工整学术风"也会被判 AI。这篇文章把&quo…...

51单片机计算器DIY:除了加减乘除,你的LCD1602和矩阵键盘还能这样玩?
51单片机计算器进阶指南:解锁LCD1602与矩阵键盘的隐藏玩法 当你在51单片机上成功实现了一个基础计算器后,是否想过这两个核心外设——LCD1602液晶屏和4x4矩阵键盘——还能玩出什么新花样?本文将带你超越简单的加减乘除,探索硬件模…...

高效管理300+模组:XCOM 2专业模组管理器AML完整指南
高效管理300模组:XCOM 2专业模组管理器AML完整指南 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/x…...

为什么选择nxdumptool:Switch游戏备份的完全指南
为什么选择nxdumptool:Switch游戏备份的完全指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirrors/nx/nxdum…...

如何用Hitboxer解决游戏按键冲突:5步实现职业级操作精度
如何用Hitboxer解决游戏按键冲突:5步实现职业级操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下左右方向键而角色卡顿?或者…...

扛住十万并发的“冷面保安”:一文扒透限流的四大经典算法与代码实战
在高并发架构中,如果说缓存和 MQ 是替服务器扛伤害的“防弹衣”,那么限流(Rate Limiting)就是守在系统大门外的“冷面保安”。他的核心逻辑极其冷酷:不管外面排队的人有多急,只要超过了系统的最大接待能力&…...

终极免费Windows音频调校指南:用Equalizer APO解锁专业音质
终极免费Windows音频调校指南:用Equalizer APO解锁专业音质 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是否对电脑的音质总是不满意?无论是听音乐、看电影还是玩游戏&…...

微信好友关系检测工具完整指南:如何快速发现谁删除了你
微信好友关系检测工具完整指南:如何快速发现谁删除了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...

5个实用技巧:用CaptfEncoder快速搞定网络安全编码任务
5个实用技巧:用CaptfEncoder快速搞定网络安全编码任务 【免费下载链接】CaptfEncoder Captfencoder is opensource a rapid cross platform network security tool suite, providing network security related code conversion, classical cryptography, cryptograp…...

RoboMaster新手必看:CAN通讯驱动GM6020电机,从ID配置到线序接法的保姆级避坑指南
RoboMaster新手必看:CAN通讯驱动GM6020电机,从ID配置到线序接法的保姆级避坑指南 第一次接触RoboMaster比赛的新手们,面对CAN总线驱动GM6020这类电调电机一体式设备时,常常会遇到"明明发送了CAN包但电机就是不转"的困扰…...