跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库,训练出一个具有中医知识理解力的预训练语言模型(pre-trained model),之后在此基础上通过海量的中医古籍指令对话数据及通用指令数据进行有监督微调(SFT),使得模型具备中医古籍知识问答能力。
0.模型信息 Model Information

-
Brief Introduction
姜子牙通用大模型V1是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。目前姜子牙通用大模型已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers0.1继续预训练 Continual pretraining
原始数据包含英文和中文,其中英文数据来自 openwebtext、Books、Wikipedia 和 Code,中文数据来自清洗后的悟道数据集、自建的中文数据集。在对原始数据进行去重、模型打分、数据分桶、规则过滤、敏感主题过滤和数据评估后,最终得到 125B tokens 的有效数据。
为了解决 LLaMA 原生分词对中文编解码效率低下的问题,我们在 LLaMA 词表的基础上增加了 7k + 个常见中文字,通过和 LLaMA 原生的词表去重,最终得到一个 39410 大小的词表,并通过复用 Transformers 里 LlamaTokenizer 来实现了这一效果。
在增量训练过程中,我们使用了 160 张 40GB 的 A100,采用 2.6M tokens 的训练集样本数量和 FP 16 的混合精度,吞吐量达到 118 TFLOP per GPU per second。因此我们能够在 8 天的时间里在原生的 LLaMA-13B 模型基础上,增量训练 110B tokens 的数据。
训练期间,虽然遇到了机器宕机、底层框架 bug、loss spike 等各种问题,但我们通过快速调整,保证了增量训练的稳定性。我们也放出训练过程的 loss 曲线,让大家了解可能出现的问题。
0.2 多任务有监督微调 Supervised finetuning
在多任务有监督微调阶段,采用了课程学习(curiculum learning)和增量训练(continual learning)的策略,用大模型辅助划分已有的数据难度,然后通过 “Easy To Hard” 的方式,分多个阶段进行 SFT 训练。
SFT 训练数据包含多个高质量的数据集,均经过人工筛选和校验:
-
Self-Instruct 构造的数据(约 2M):BELLE、Alpaca、Alpaca-GPT4 等多个数据集
-
内部收集 Code 数据(300K):包含 leetcode、多种 Code 任务形式
-
内部收集推理 / 逻辑相关数据(500K):推理、申论、数学应用题、数值计算等
-
中英平行语料(2M):中英互译语料、COT 类型翻译语料、古文翻译语料等
-
多轮对话语料(500K):Self-Instruct 生成、任务型多轮对话、Role-Playing 型多轮对话等
0.3 人类反馈学习 Human-Feedback training
为了进一步提升模型的综合表现,使其能够充分理解人类意图、减少 “幻觉” 和不安全的输出,基于指令微调后的模型,进行了人类反馈训练(Human-Feedback Training,HFT)。在训练中,我们采用了以人类反馈强化学习(RM、PPO)为主,结合多种其他手段联合训练的方法,手段包括人类反馈微调(Human-Feedback Fine-tuning,HFFT)、后见链微调(Chain-of-Hindsight Fine-tuning,COHFT)、AI 反馈(AI Feedback)和基于规则的奖励系统(Rule-based Reward System,RBRS)等,用来弥补 PPO 方法的短板,加速训练。
我们在内部自研的框架上实现了 HFT 的训练流程,该框架可以利用最少 8 张 40G 的 A100 显卡完成 Ziya-LLaMA-13B-v1 的全参数训练。在 PPO 训练中,我们没有限制生成样本的长度,以确保长文本任务的奖励准确性。每次训练的总经验池尺寸超过 100k 样本,确保了训练的充分性。
1.训练数据
1.1 继续预训练数据(纯文本语料)约0.5G
包含两部分:①中医教材数据:收集“十三五”规划所有中医教材共22本。②在线中医网站数据:爬取中医世家、民间医学网等在线中医网站及知识库。
-
通用指令微调数据
Alpaca-GPT4 52k 中文
-
alpaca_gpt4_data.json包含由 GPT-4 生成的 52K 指令跟随数据,并带有 Alpaca 提示。该 JSON 文件与 Alpaca 数据具有相同的格式,只是输出由 GPT-4 生成的:
instruction:str,描述模型应执行的任务。每条 52K 指令都是唯一的。input:str,任务的任选上下文或输入。output:str,指令的答案由生成GPT-4。 -
alpaca_gpt4_data_zh.json包含由 GPT-4 生成的 52K 指令跟踪数据,并由 ChatGPT 翻译成中文的 Alpaca 提示。此 JSON 文件具有相同的格式。
-
comparison_data.json通过要求GPT-4评估质量,对GPT-4、GPT-3.5和OPT-IML等透明模型的响应进行排名。
user_input:str,用于查询LLM的提示。completion_a:str,一个模型完成,其排名完成_b。completion_b:str,不同的模型完成,其质量得分较低。 -
unnatural_instruction_gpt4_data.json包含由 GPT-4 生成的 9K 指令跟随数据,并带有非自然指令中的提示。此 JSON 文件与 Alpaca 数据具有相同的格式。
-
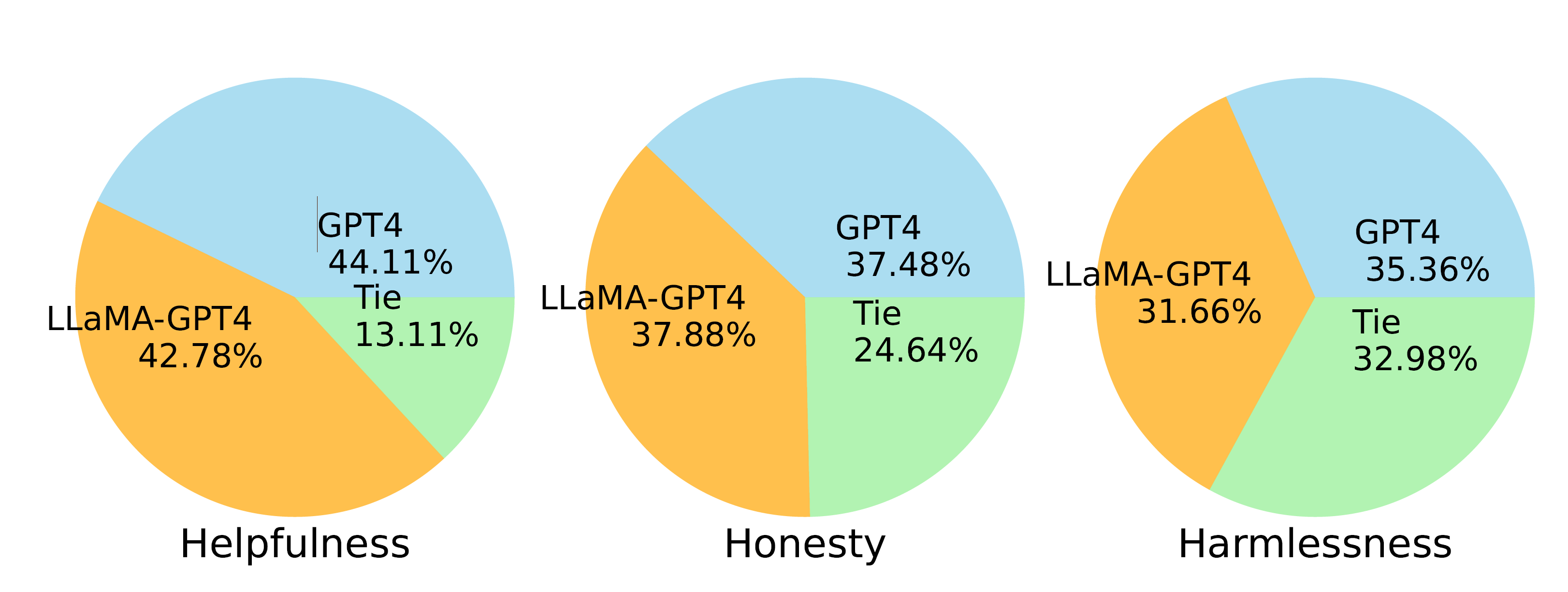
比较了两种指令调整的 LLaMA 模型,分别根据 GPT-4 和 GPT-3 生成的数据进行微调。
-
在“有用性”标准中,LLaMA-GPT-4 的表现明显优于 LLaMA-GPT-3。
-
LLaMA-GPT-4 在所有三个标准中的表现与原始 GPT-4 相似,这为开发最先进的遵循指令的 LLM 提供了一个有希望的方向。
1.2 中医古籍指令对话数据
-
语料库来源
以《中华医典》数据库为语料来源,约338MB,由两部分组成:①非结构化的“古籍文本”:涵盖了886本标点符号及内容完整的中医古籍。②结构化的“古籍辞典”:包含“名医”、“名言”、“名词”、“名著”等六大类,由中医学界诸多知名学者对中医古籍内容知识进一步系统提炼整理,是中医古籍内容精华最为直接的集中体现。
构建指令微调对话数据集通过知识引导的指令数据生成和指令数据质量优化两个阶段,最终获得504372个对话数据。
-
知识引导的指令数据生成
让ChatGPT基于对该段中医古籍的知识内容理解,模拟用户与AI,通过自问自答的方式,生成逻辑关系相关的若干问题和答案,从而保证对话数据的准确性和可靠性。
-
指令数据质量优化
尽管基于知识引导使得生成的指令数据基于特定领域,并且与所提供的无监督文本内容相关,避免了模型内部“已有知识”的干扰。然而这种方法难以对数据质量进行监督和控制,也难以保证指令数据的多样性和难度,这可能导致大模型对指令数据集的过度拟合。为了解决这个问题,我们在现有指令数据集的基础上,通过指令数据过滤-指令数据整合两个阶段对数据进行二次优化。
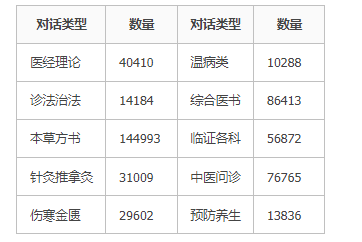
中医古籍指令数据种类概览(共504372条对话数据)
2.模型训练
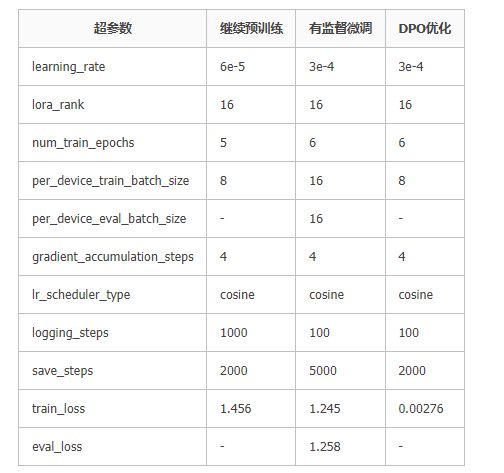
2.1实验参数
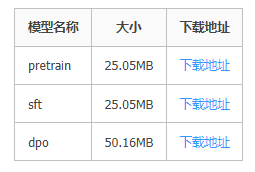
2.2模型下载-LoRA权重
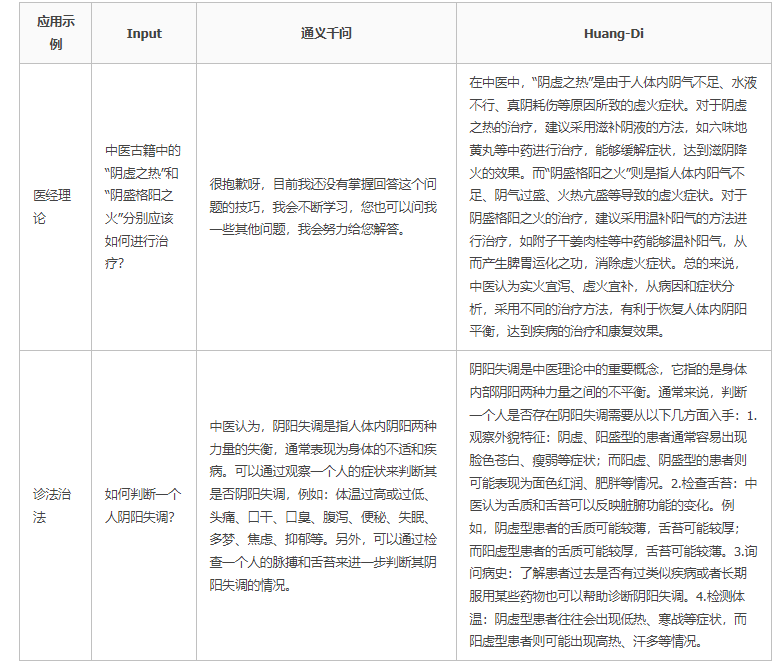
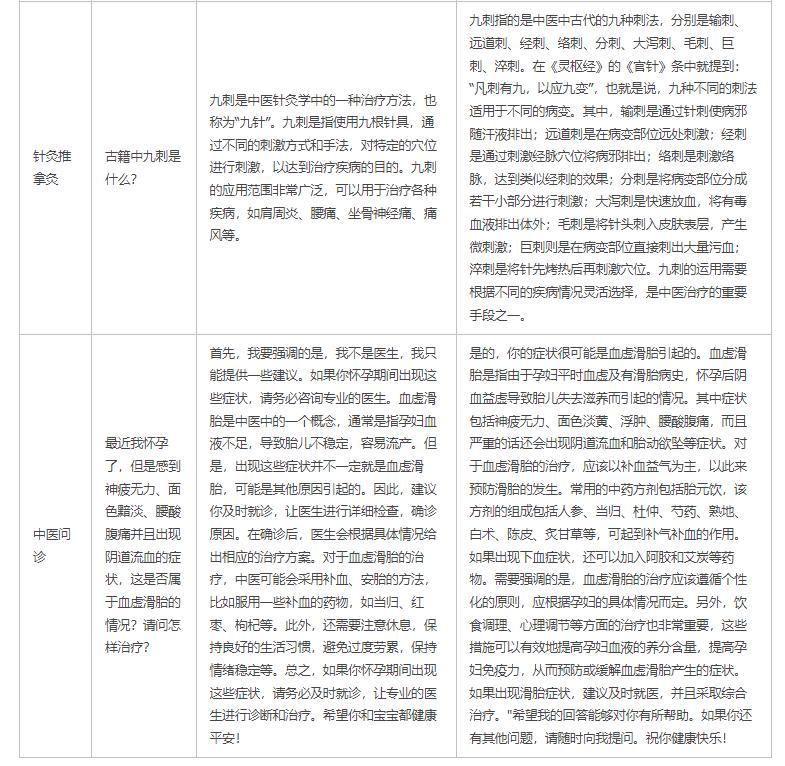
3.模型效果
文章转载自:汀、人工智能
原文链接:https://www.cnblogs.com/ting1/p/18027272
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库,训练出一个具有中医知识理解力的预训练语言模型(pre-trained model),之后在此基础上通过海量的中医古籍指令对话数据及通用指令…...

初识表及什么是数据表
一、了解表 1.1.概述 表是处理数据和建立关系型数据库及应用程序的基本单元,是构成数据库的基本元素之一,是数据库中数据组织并储存的单元,所有的数据都能以表格的形式组织,目的是可读性强。 1.2.表结构简述 一个表中包括行和列…...

使用Docker部署DataX3.0+DataX-Web
1、准备基础镜像,开通所需端口 先查看3306和9527端口是否开放,如果未开放先在防火墙添加 firewall-cmd --zonepublic --add-port3306/tcp --permanent firewall-cmd --zonepublic --add-port9527/tcp --permanent firewall-cmd --reload systemctl sto…...

庖丁解牛-二叉树的遍历
庖丁解牛-二叉树的遍历 〇、前言 01 文章内容 一般提到二叉树的遍历,我们是在说 前序遍历、中序遍历、后序遍历和层序遍历 或者说三序遍历层序遍历,毕竟三序和层序的遍历逻辑相差比较大下面讨论三序遍历的递归方法、非递归方法和非递归迭代的统一方法然…...
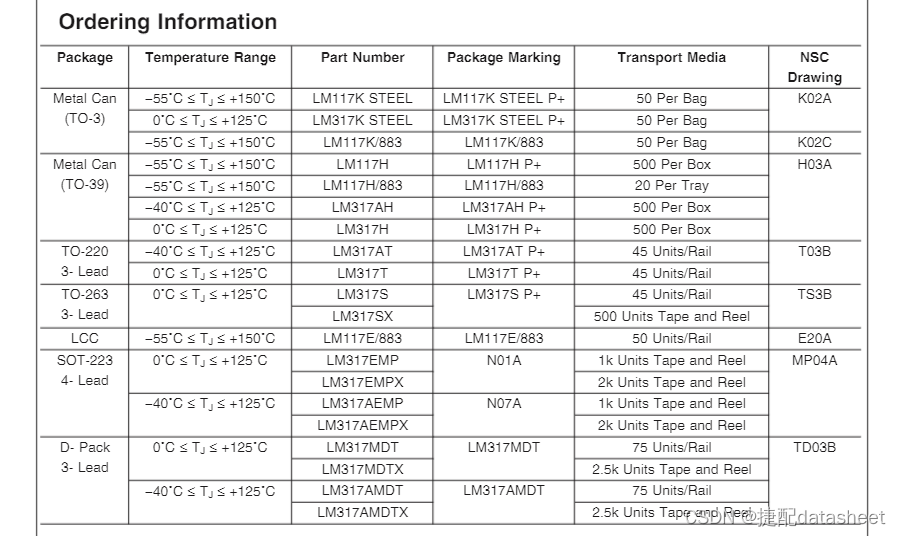
一文了解LM317T的引脚介绍、参数解读
LM317T是一种线性稳压器件,它具有稳定输出电压的特性。LM317T可以通过调整其输出电阻来确保输出电压的稳定性,因此被广泛应用于各种电子设备中。 LM317T引脚图介绍 LM317T共有3个引脚,分别是: 输入引脚(输入电压V_in&…...
【2024.02.22】定时执行专家 V7.0 发布 - TimingExecutor V7.0 Release - 龙年春节重大更新版本
目录 ▉ 新版本 V7.0 下载地址 ▉ V7.0 新功能 ▼2024-02-21 V7.0 - 更新日志▼ ▉ V7.0 新UI设计 ▉ 新版本 V7.0 下载地址 BoomWorks软件的最新版本-CSDN博客文章浏览阅读10w次,点赞9次,收藏41次。▉定时执行专家—毫秒精度、专业级的定时任务执行…...
☀️将大华摄像头画面接入Unity 【1】配置硬件和初始化摄像头
一、硬件准备 目前的设想是后期采用网口供电的形式把画面传出来,所以这边我除了大华摄像头还准备了POE供电交换机,为了方便索性都用大华的了,然后全都连接电脑主机即可。 二、软件准备 这边初始化摄像头需要用到大华的Configtool软件&#…...

直流电流电压变送器4-20mA 10V信号隔离转换模拟量精度变送器
品牌:泰华仪表 型号:TB-IP(U)XX 产地:中国大陆 省份:安徽省 地市:宿州市 颜色分类:4-20mA转4-20mA,4-20mA转0-10V,4-20mA转0-20mA,4-20mA转0-5V,0-20mA转0-20mA,0-20mA转4-20mA,0-20mA转0-10V,0-20mA转…...
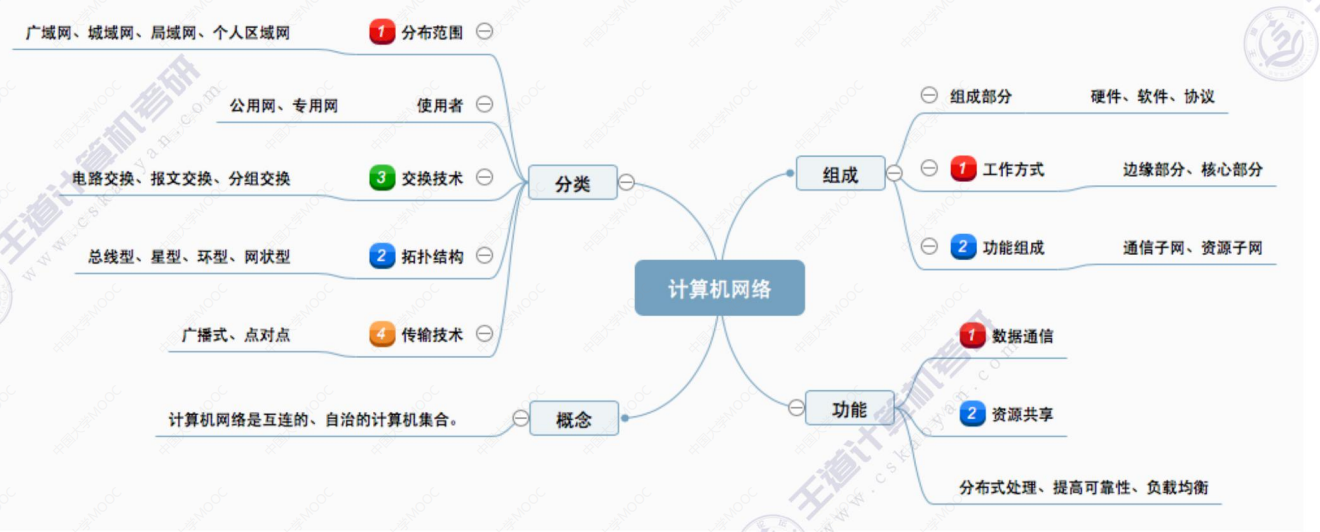
1.1 计算机网络的概念、功能、组成和分类
文章目录 1.1 计算机网络的概念、功能、组成和分类(一)计算机网络的概念(二)计算机网络的功能(三)计算机网络的组成1.组成部分2.工作方式3.功能组成 (四)计算机网络的分类 总结 1.1 …...
排序算法整理
排序种类排序特性代码背景 基于插入的排序直接插入排序原理代码 折半查找排序2路查找排序希尔排序(shell) 缩小增量排序原理代码 基于交换的排序冒泡排序原理代码 快速排序(重要!)原理我的思考 代码 基于选择的排序(简单)选择排序…...

ONLYOFFICE 桌面应用程序 v8.0 发布:全新 RTL 界面、本地主题、Moodle 集成等你期待的功能来了!
目录 📘 前言 📟 一、什么是 ONLYOFFICE 桌面编辑器? 📟 二、ONLYOFFICE 8.0版本新增了那些特别的实用模块? 2.1. 可填写的 PDF 表单 2.2. 双向文本 2.3. 电子表格中的新增功能 单变量求解:…...
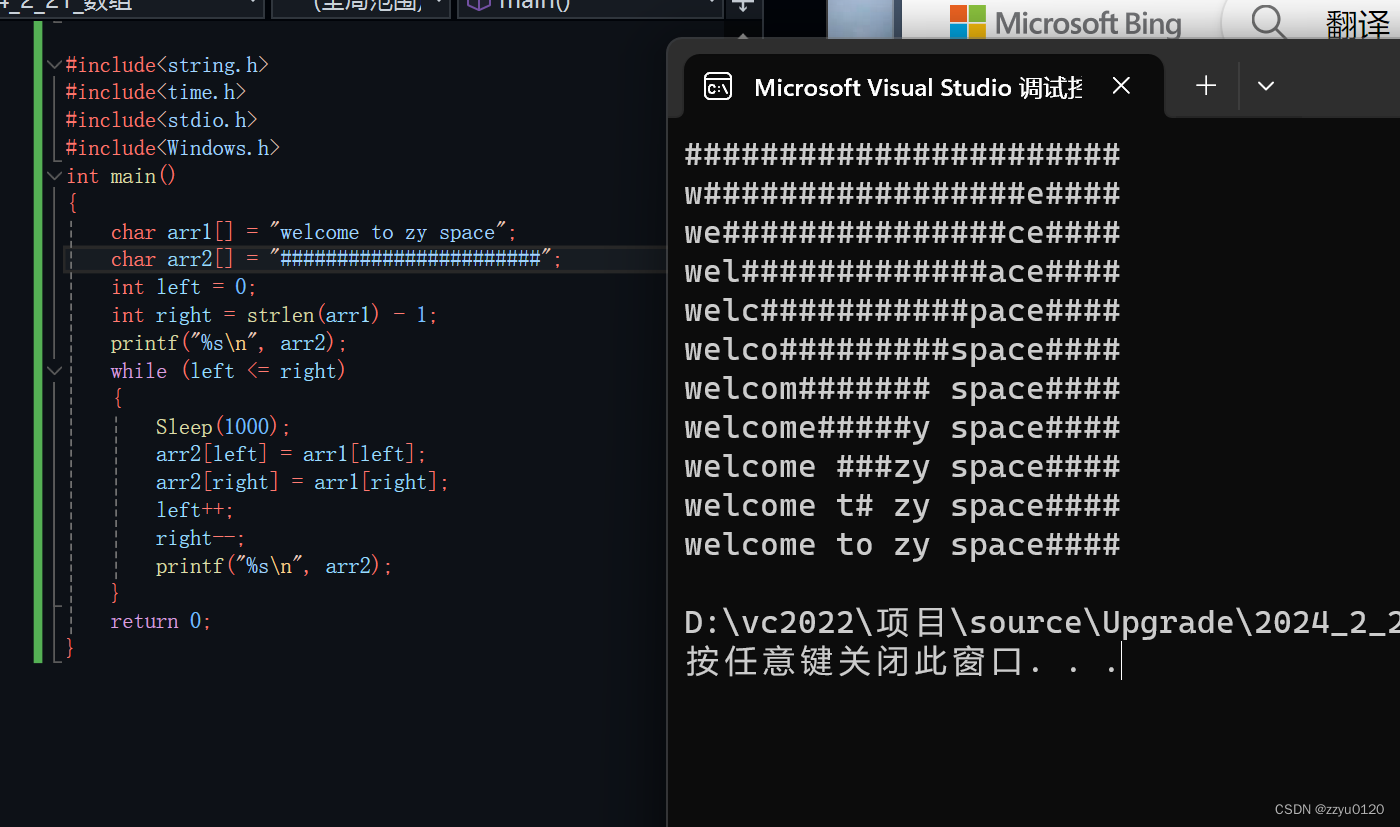
c语言---数组(超级详细)
数组 一.数组的概念二. 一维数组的创建和初始化2.1数组的创建2.2数组的初始化错误的初始化 2.3 数组的类型 三. 一维数组的使用3.1数组的下标3.2数组元素的打印3.2数组元素的输入 四. 一维数组在内存中的存储五. 二维数组的创建5.1二维数组的概念5.2如何创建二维数组 六.二维数…...

神经网络权重初始化
诸神缄默不语-个人CSDN博文目录 (如果只想看代码,请直接跳到“方法”一节,开头我介绍我的常用方法,后面介绍具体的各种方案) 神经网络通过多层神经元相互连接构成,而这些连接的强度就是通过权重ÿ…...

代码随想录训练营第三十九天|62.不同路径63. 不同路径 II
62.不同路径 1确定dp数组(dp table)以及下标的含义 从(0,0)出发到(i,j)有 dp[i][j]种路径 2确定递推公式 dp[i][j]dp[i-1][j]dp[i][j-1] 3dp数组如何初始化 for(int i0;i<m…...
学习大数据所需的java基础(5)
文章目录 集合框架Collection接口迭代器迭代器基本使用迭代器底层原理并发修改异常 数据结构栈队列数组链表 List接口底层源码分析 LinkList集合LinkedList底层成员解释说明LinkedList中get方法的源码分析LinkedList中add方法的源码分析 增强for增强for的介绍以及基本使用发2.使…...
Python 光速入门课程
首先说一下,为啥小编在即PHP和Golang之后,为啥又要整Python,那是因为小编最近又拿起了 " 阿里天池 " 的东西,所以小编又不得不捡起来大概五年前学习的Python,本篇文章主要讲的是最基础版本,所以比…...

解决vite打包出现 “default“ is not exported by “node_modules/...问题
项目场景: vue3tsvite项目打包 问题描述 // codemirror 编辑器的相关资源 import Codemirror from codemirror;error during build: RollupError: "default" is not exported by "node_modules/vue/dist/vue.runtime.esm-bundler.js", impor…...

c语言strtok的使用
strtok函数的作用为以指定字符分割字符串,含有两个参数,第一个函数为待分割的字符串或者空指针NULL,第二个参数为分割字符集。 对一个字符串首次使用strtok时第一个参数应该是待分割字符串,strtok以指定字符完成第一次分割后&…...
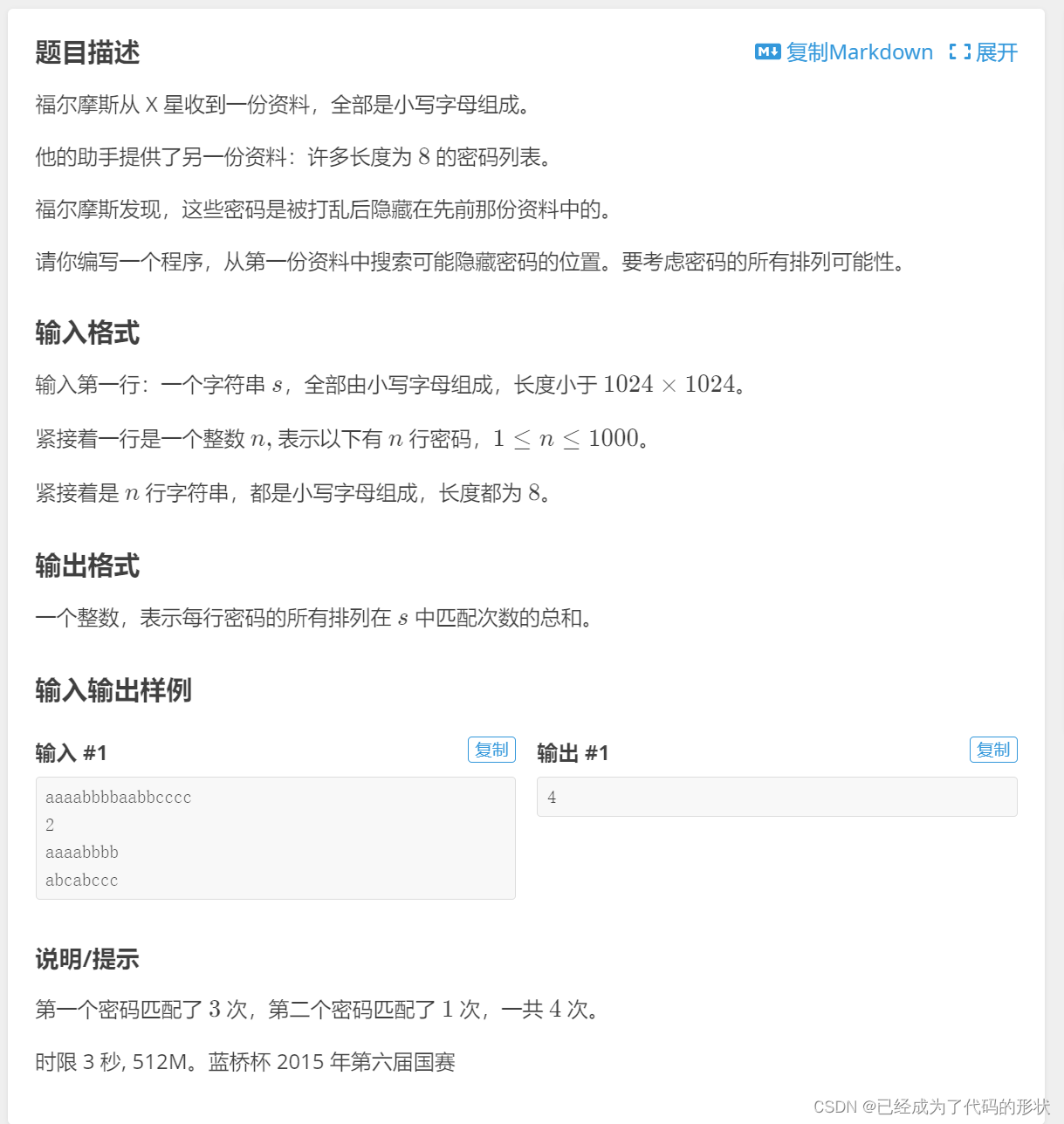
hash,以及数据结构——map容器
1.hash是什么? 定义:hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出, 该输出就是散列值。这种转换是一种压缩映射&…...

AIoT网关 人工智能物联网网关
AIoT(人工智能物联网)作为新一代技术的代表,正以前所未有的速度改变着我们的生活方式。在这个智能时代,AIoT网关的重要性日益凸显。它不仅是连接智能设备和应用的关键,同时也是实现智能化家居、智慧城市和工业自动化的必备技术。 一…...

Linux音频驱动开发实战:为TLV320ADC5120编写ALSA Codec驱动
1. 项目概述:从一块“哑巴”音频芯片到Linux系统的“耳朵”最近在折腾一块基于TI TLV320ADC5120的音频采集板,想把它接到我的RK3568开发板上用。芯片手册、硬件原理图都齐了,但一上电,系统里arecord -l根本找不到设备,…...

DNS 与 hosts 文件:Windows 11 中的名称解析配置
诸神缄默不语-个人技术博文与视频目录 一个域名会对应多个IP地址,当电脑访问域名时会默认指定访问其中一个IP地址(以下正文会介绍通过hosts文件和DNS服务器选择指定映射的IP的原理),总之有时我们可能会需要将域名对应的IP地址指定…...

如何永久保存微信聊天记录?3分钟学会数据导出与智能分析终极指南
如何永久保存微信聊天记录?3分钟学会数据导出与智能分析终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendin…...
)
从“消融”到“流动岩浆”:用Unity Shader的Tilling和Offset玩转动态纹理(URP/HDRP通用)
从“消融”到“流动岩浆”:用Unity Shader的Tilling和Offset玩转动态纹理(URP/HDRP通用) 想象一下:你的游戏场景中,炽热的岩浆在地表缓缓流动,水面泛起涟漪般的波纹,或是能量屏障表面流淌着神秘…...

OPPO新时代板凳精神:解码长期主义研发体系与前沿技术人才战略
1. 从“板凳精神”到“微笑前行”:OPPO的研发哲学与人才战略最近,OPPO在五四青年节发布的那支名为《板凳》的品牌片,以及随之公布的超过2000人的技术研发招聘计划,在科技圈里引发了不小的讨论。很多人乍一看,觉得这又是…...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...
)
数据结构第8章查找:单元测试15题全解析(顺序查找+折半查找+分块查找+哈希查找)
第8章 查找 单元测试1. 线性表只有以( A )方式存储,才能进行折半查找。A. 顺序B. 链接C. 二叉树D. 关键字有序的2. 有序表为{2,4,10,13,33,42,46,64&#x…...

告别跑飞!S32K3xx Standby模式唤醒后程序复位?手把手教你用WKPU和RTC保留关键数据
S32K3xx低功耗实战:WKPU与RTC协同解决Standby模式数据丢失难题 引言 在嵌入式系统设计中,低功耗优化一直是工程师们面临的永恒挑战。S32K3xx系列微控制器凭借其出色的电源管理能力,成为汽车电子、工业控制等领域的热门选择。然而,…...

CLI工具集claw:模块化设计与插件化架构深度解析
1. 项目概述:一个面向开发者的现代化CLI工具集最近在GitHub上看到一个名为opsyhq/claw的项目,第一眼就被它简洁的名字吸引了。claw,中文意思是“爪子”,听起来就很有力量感和抓取感。点进去一看,果然,这是一…...

领域负载物技能制作器技能domain-payload-generator
Domain Payload Generator(SkillHub) Domain Payload Generator(ClawHub) name: domain-payload-generator author: 王教成 Wang Jiaocheng (波动几何) description: 领域负载物技能制作器(Meta-Skill)——…...