第N3周:Pytorch文本分类入门
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rbOOmire8OocQ90QM78DRA) 中的学习记录博客** >- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore")
#win10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")from torchtext.datasets import AG_NEWS
train_iter = AG_NEWS(split='train')#加载 AG News 数据集from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator#返回分词器
tokenizer = get_tokenizer('basic_english')def yield_tokens(data_iter):for _, text in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])#设置默认索引
print(vocab(['here', 'is', 'an', 'example']))text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: int(x) - 1
print(text_pipeline('here is an example '))
print(label_pipeline('10'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list,text_list,offsets =[],[],[0]for(_label,_text)in batch:#标签列表label_list.append(label_pipeline(_label))#文本列表processed_text =torch.tensor(text_pipeline(_text),dtype=torch.int64)text_list.append(processed_text)#偏移量,即语句的总词汇量offsets.append(processed_text.size(0))label_list =torch.tensor(label_list,dtype=torch.int64)text_list=torch.cat(text_list)offsets=torch.tensor(offsets[:-1]).cumsum(dim=0)#返回维度dim中输入元素的累计和return label_list.to(device),text_list.to(device),offsets.to(device)
#数据加载器
dataloader =DataLoader(train_iter,batch_size=8,shuffle =False,collate_fn=collate_batch)from torch import nn
class TextClassificationModel(nn.Module):def __init__(self,vocab_size,embed_dim,num_class):super(TextClassificationModel,self).__init__()self.embedding =nn.EmbeddingBag(vocab_size,#词典大小embed_dim,#嵌入的维度sparse=False)#self.fc =nn.Linear(embed_dim,num_class)self.init_weights()def init_weights(self):initrange =0.5self.embedding.weight.data.uniform_(-initrange,initrange)self.fc.weight.data.uniform_(-initrange,initrange)self.fc.bias.data.zero_()def forward(self,text,offsets):embedded =self.embedding(text,offsets)return self.fc(embedded)num_class = len(set([label for(label,text)in train_iter]))
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size,em_size,num_class).to(device)import time
def train(dataloader):model.train() #切换为训练模式total_acc,train_loss,total_count =0,0,0log_interval =500start_time =time.time()for idx,(label,text,offsets) in enumerate(dataloader):predicted_label =model(text,offsets)optimizer.zero_grad()#grad属性归零loss =criterion(predicted_label,label)#计算网络输出和真实值之间的差距,labe1为真实值loss.backward()#反向传播optimizer.step() #每一步自动更新#记录acc与losstotal_acc +=(predicted_label.argmax(1)==label).sum().item()train_loss +=loss.item()total_count +=label.size(0)if idx %log_interval ==0 and idx >0:elapsed =time.time()-start_timeprint('|epoch {:1d}|{:4d}/{:4d}batches''|train_acc {:4.3f}train_loss {:4.5f}'.format(epoch,idx,len(dataloader),total_acc/total_count,train_loss/total_count))total_acc,train_loss,total_count =0,0,0start_time =time.time()def evaluate(dataloader):model.eval() #切换为测试模式total_acc,train_loss,total_count =0,0,0with torch.no_grad():for idx,(label,text,offsets)in enumerate(dataloader):predicted_label =model(text,offsets)loss = criterion(predicted_label,label) #计算loss值#记录测试数据total_acc +=(predicted_label.argmax(1)==label).sum().item()train_loss +=loss.item()total_count +=label.size(0)return total_acc/total_count,train_loss/total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
#超参数
EPOCHS=10 #epoch
LR=5 #学习率
BATCH_SIZE=64 #batch size for training
criterion =torch.nn.CrossEntropyLoss()
optimizer =torch.optim.SGD(model.parameters(),lr=LR)
scheduler =torch.optim.lr_scheduler.StepLR(optimizer,1.0,gamma=0.1)
total_accu =Nonetrain_iter,test_iter =AG_NEWS()#加载数据
train_dataset =to_map_style_dataset(train_iter)
test_dataset =to_map_style_dataset(test_iter)
num_train=int(len(train_dataset)*0.95)split_train_,split_valid_=random_split(train_dataset,[num_train,len(train_dataset)-num_train])
train_dataloader =DataLoader(split_train_,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)
valid_dataloader =DataLoader(split_valid_,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)
test_dataloader=DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)for epoch in range(1,EPOCHS +1):epoch_start_time =time.time()train(train_dataloader)val_acc,val_loss =evaluate(valid_dataloader)if total_accu is not None and total_accu >val_acc:scheduler.step()else:total_accu =val_accprint('-'*69)print('|epoch {:1d}|time:{:4.2f}s|''valid_acc {:4.3f}valid_loss {:4.3f}'.format(epoch,time.time()-epoch_start_time,val_acc,val_loss))print('-'*69)print('Checking the results of test dataset.')
test_acc,test_loss =evaluate(test_dataloader)
print('test accuracy {:8.3f}'.format(test_acc))
文本构建向量的基本原理:
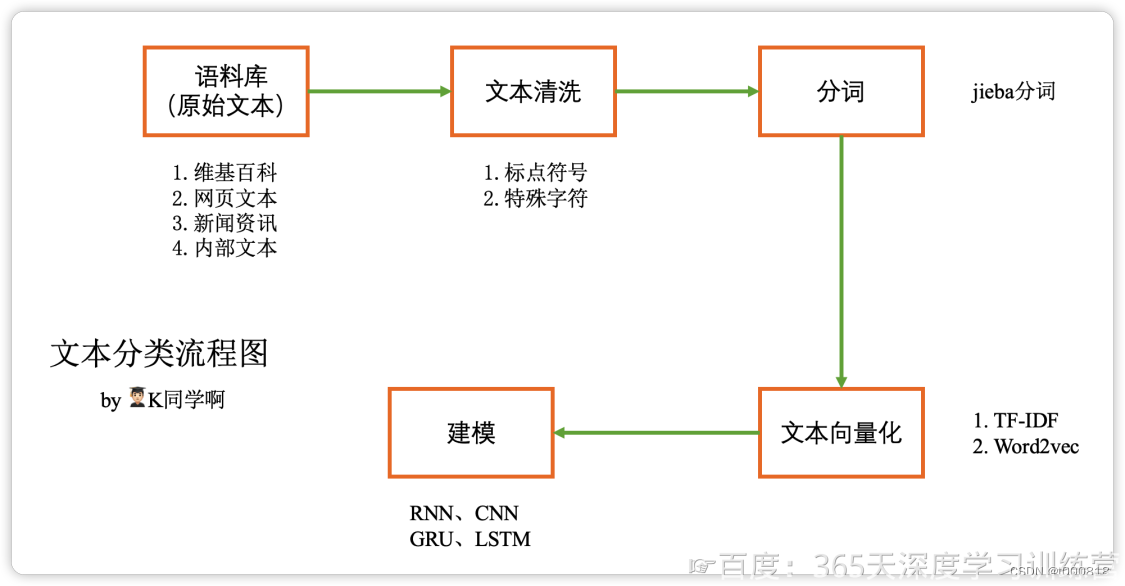
下面是运行结果:
D:\Code\pythonProject_PyTorch\venv\Scripts\python.exe D:\Code\pythonProject_PyTorch\PytorchText.py
[475, 21, 30, 5297]
[475, 21, 30, 5297]
9
|epoch 1| 500/1782batches|train_acc 0.721train_loss 0.01110
|epoch 1|1000/1782batches|train_acc 0.871train_loss 0.00606
|epoch 1|1500/1782batches|train_acc 0.877train_loss 0.00562
---------------------------------------------------------------------
|epoch 1|time:11.86s|valid_acc 0.782valid_loss 0.009
---------------------------------------------------------------------
|epoch 2| 500/1782batches|train_acc 0.903train_loss 0.00451
|epoch 2|1000/1782batches|train_acc 0.906train_loss 0.00442
|epoch 2|1500/1782batches|train_acc 0.906train_loss 0.00436
---------------------------------------------------------------------
|epoch 2|time:11.64s|valid_acc 0.845valid_loss 0.007
---------------------------------------------------------------------
|epoch 3| 500/1782batches|train_acc 0.919train_loss 0.00374
|epoch 3|1000/1782batches|train_acc 0.917train_loss 0.00383
|epoch 3|1500/1782batches|train_acc 0.915train_loss 0.00393
---------------------------------------------------------------------
|epoch 3|time:11.61s|valid_acc 0.905valid_loss 0.004
---------------------------------------------------------------------
|epoch 4| 500/1782batches|train_acc 0.927train_loss 0.00339
|epoch 4|1000/1782batches|train_acc 0.926train_loss 0.00342
|epoch 4|1500/1782batches|train_acc 0.922train_loss 0.00352
---------------------------------------------------------------------
|epoch 4|time:11.62s|valid_acc 0.870valid_loss 0.006
---------------------------------------------------------------------
|epoch 5| 500/1782batches|train_acc 0.942train_loss 0.00276
|epoch 5|1000/1782batches|train_acc 0.945train_loss 0.00268
|epoch 5|1500/1782batches|train_acc 0.945train_loss 0.00266
---------------------------------------------------------------------
|epoch 5|time:11.67s|valid_acc 0.913valid_loss 0.004
---------------------------------------------------------------------
|epoch 6| 500/1782batches|train_acc 0.946train_loss 0.00259
|epoch 6|1000/1782batches|train_acc 0.946train_loss 0.00261
|epoch 6|1500/1782batches|train_acc 0.946train_loss 0.00261
---------------------------------------------------------------------
|epoch 6|time:11.71s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
|epoch 7| 500/1782batches|train_acc 0.948train_loss 0.00255
|epoch 7|1000/1782batches|train_acc 0.946train_loss 0.00260
|epoch 7|1500/1782batches|train_acc 0.948train_loss 0.00250
---------------------------------------------------------------------
|epoch 7|time:11.68s|valid_acc 0.912valid_loss 0.004
---------------------------------------------------------------------
|epoch 8| 500/1782batches|train_acc 0.948train_loss 0.00252
|epoch 8|1000/1782batches|train_acc 0.948train_loss 0.00249
|epoch 8|1500/1782batches|train_acc 0.950train_loss 0.00244
---------------------------------------------------------------------
|epoch 8|time:11.52s|valid_acc 0.913valid_loss 0.004
---------------------------------------------------------------------
|epoch 9| 500/1782batches|train_acc 0.949train_loss 0.00249
|epoch 9|1000/1782batches|train_acc 0.950train_loss 0.00246
|epoch 9|1500/1782batches|train_acc 0.950train_loss 0.00248
---------------------------------------------------------------------
|epoch 9|time:11.57s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
|epoch 10| 500/1782batches|train_acc 0.950train_loss 0.00246
|epoch 10|1000/1782batches|train_acc 0.950train_loss 0.00243
|epoch 10|1500/1782batches|train_acc 0.949train_loss 0.00249
---------------------------------------------------------------------
|epoch 10|time:11.74s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
Checking the results of test dataset.
test accuracy 0.909Process finished with exit code 0
总结:PyTorch version、torchtext version、Supported Python version版本一定要对应,可以参考:https://blog.csdn.net/shiwanghualuo/article/details/122860521
相关文章:
第N3周:Pytorch文本分类入门
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rbOOmire8OocQ90QM78DRA) 中的学习记录博客** >- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)** import torch import…...
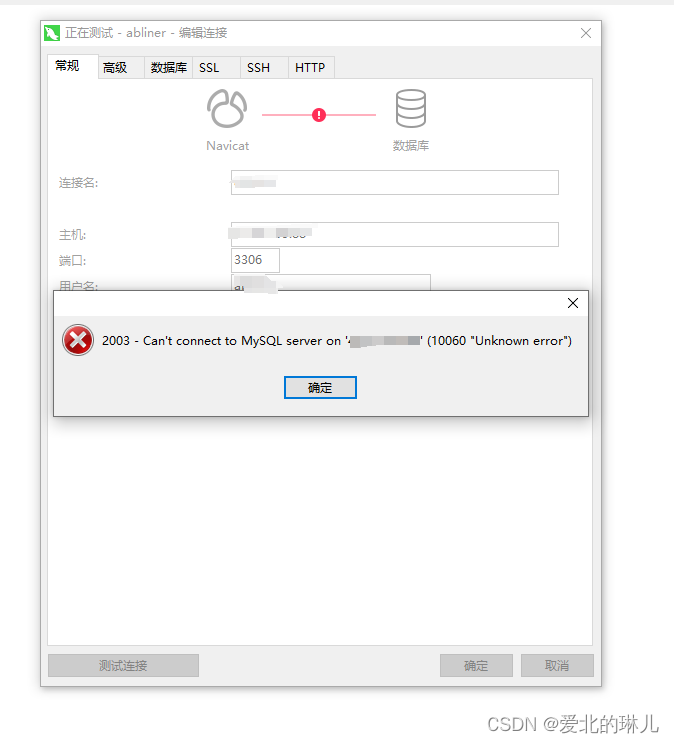
宝塔面板安装了mysql5.7和phpMyadmin,但是访问phpMyadmin时提示502 Bad Gateway
操作流程截图如下: 原因是没有选择php版本 选择php版本 下一页找到phpMyAdmin,选择设置 目前只有纯净态,说明没有php环境,前去安装php环境 点击安装,选择版本,这里选择的是7.4版本,编译安…...
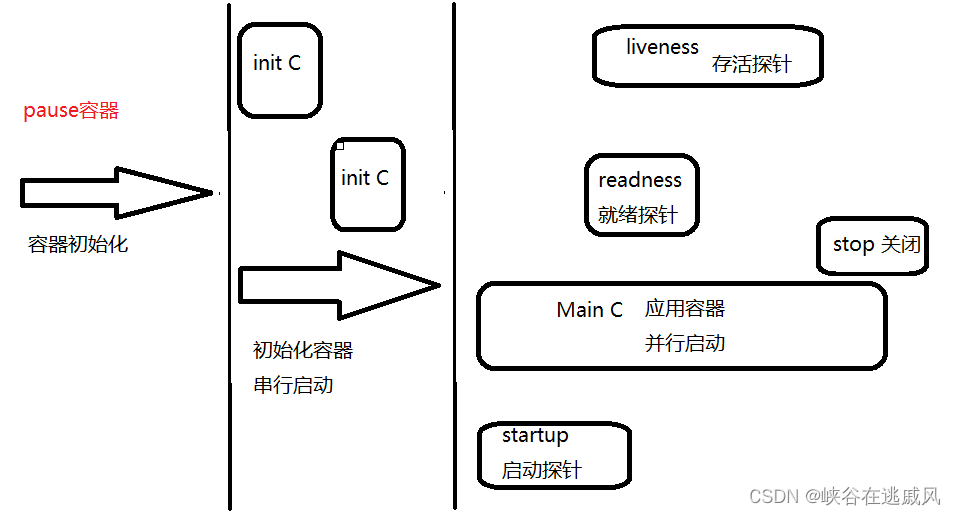
K8S—Pod详解
目录 一 Pod基础概念 1.1 Pod是什么 1.2 为什么要使用Pod?Pod在K8S集群中的使用方式? 1.3 基础容器pause 二 Pod的分类 2.1 自主式Pod和控制器管理的Pod 2.2 容器的分类 2.2.1 基础容器(infrastructure container) 2.2.2…...

深度学习中数据的转换
原始(文本、音频、图像、视频、传感器等)数据被转化成结构化且适合机器学习算法或深度学习模型使用的格式。 原始数据转化为结构化且适合机器学习和深度学习模型使用的格式,通常需要经历以下类型的预处理和转换: 文本数据…...

如何系统地自学 Python?
目录 Python 数据类型 控制结构 函数和模块 文件操作 异常处理 类和对象 列表推导式和生成器 匿名函数和高阶函数 面向对象编程 总结 Python Python是一种面向对象、解释型计算机程序设计语言,由Guido van Rossum于1989年发明,第一个公开发行…...

【软考】传输层协议之UDP
目录 一、说明二、特点 一、说明 1.用户数据报协议(User Datagram Protocol)是一种不可靠的、无连接的协议,可以保证应用程序进程间的通信 2.与TCP相比,UDP是一种无连接的协议,它的错误检测功能要弱很多 3.TCP有助于提…...
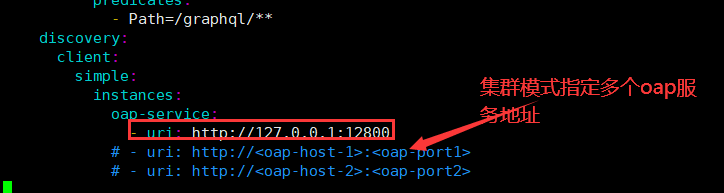
微服务-微服务链路追踪组件Skywalking实战
自动化监控系统Prometheus&Grafana实战: https://vip.tulingxueyuan.cn/detail/v_60f96e69e4b0e6c3a312c726/3?fromp_6006cac4e4b00ff4ed156218&type8&parent_pro_idp_6006d8c8e4b00ff4ed1569b2 APM-性能监控项目班: https://vip.tuling…...

Stream、Collections、Collectors用法
当涉及Java编程中的集合处理时,Stream、Collections和Collectors是三个常用的工具。以下是它们各自的主要功能和使用的一些方法的概要: Stream: 概要:Stream 是 Java 8 引入的一个强大工具,用于处理集合数据的流式操作…...

Jetson Xavier NX 与笔记本网线连接 ,网络共享,ssh连接到vscode
Jetson Xavier NX 与笔记本网线连接 ,网络共享,ssh连接到vscode Jetson Xavier NX桌面版需要连接显示屏、鼠标和键盘,操作起来并不方便,因此常常需要ssh远程连接到本地笔记本电脑,这里介绍一种连接方式,通过…...
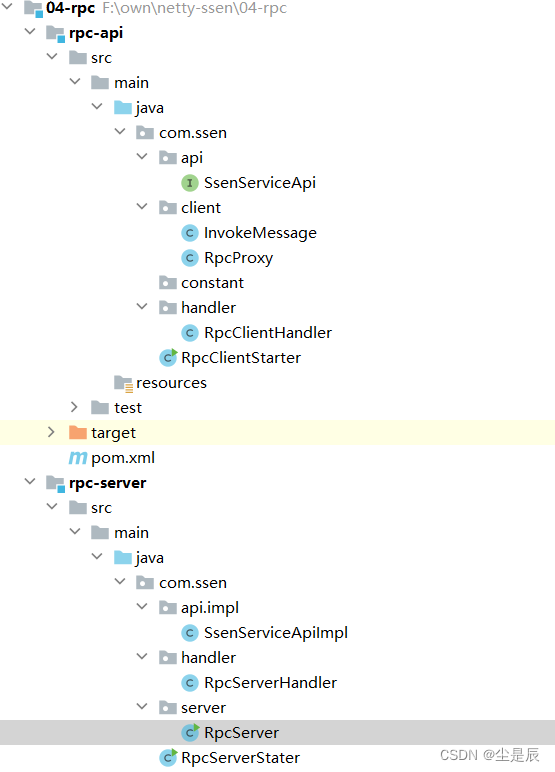
利用netty手写rpc框架
前言:利用netty异步事件驱动的网络通信模型,来实现rpc通信 一、大致目录结构: 二、两个端:服务端(发布),客户端(订阅消费),上代码: 1.服务端&am…...

js+views 压缩上传的图片
安装image-conversion插件,在before-upload方法中对上传的图片文件进行处理 遇到的问题: 1、因为在上传文件之前的钩子中对图片进行了压缩处理,所以组件中上传的data会丢失,需要重新赋值 2、imageConversion 的引入需要使用impor…...
【安卓基础5】中级控件
🏆作者简介:|康有为| ,大四在读,目前在小米安卓实习,毕业入职 🏆本文收录于 安卓学习大全持续更新中,欢迎关注 🏆安卓学习资料推荐: 视频:b站搜动脑学院 视频…...
Arthas—【学习篇】
1. Arthas官网 arthas 2. 下载 从 Maven 仓库下载 最新版本,点击下载:编辑在新窗口打开 点击这个 mavrn-central 即可显示下面的图片 #从 Github Releases 页下载 Releases alibaba/arthas GitHub 3. 解压 将压缩包复制到一个位置&…...

css pointer-events 多层鼠标点击事件
threejs 无法滑动视角,菜单界面覆盖threejs操作事件。 pointer-events /* Keyword values */ pointer-events: auto; pointer-events: none; pointer-events: visiblePainted; /* SVG only */ pointer-events: visibleFill; /* SVG only */ pointer-events: visib…...

k8s中基于alpine的pod无法解析域名问题
现象 在pod内无法解析指定域名 # 执行ping bash-4.4# ping xx-xx-svc-0.xxx-fcp.svc.cluster.local ping: bad address xx-xx-svc-0.xxx-fcp.svc.cluster.local排查经过 # 执行nslookup bash-4.4# nslookup xx-xx-svc-0.xxx-fcp.svc.cluster.local Server: 172.43.0…...

缩小ppt文件大小的办法
之前用别人模版做了个PPT,100多M,文件存在卡顿问题 解决办法: 1.找到ppt中哪个文件过大,针对解决 2.寻找视频/音频文件,减少体积 3.字体文件是不是过多的问题。 一、文件寻找的内容步骤: 步骤: 1.把p…...
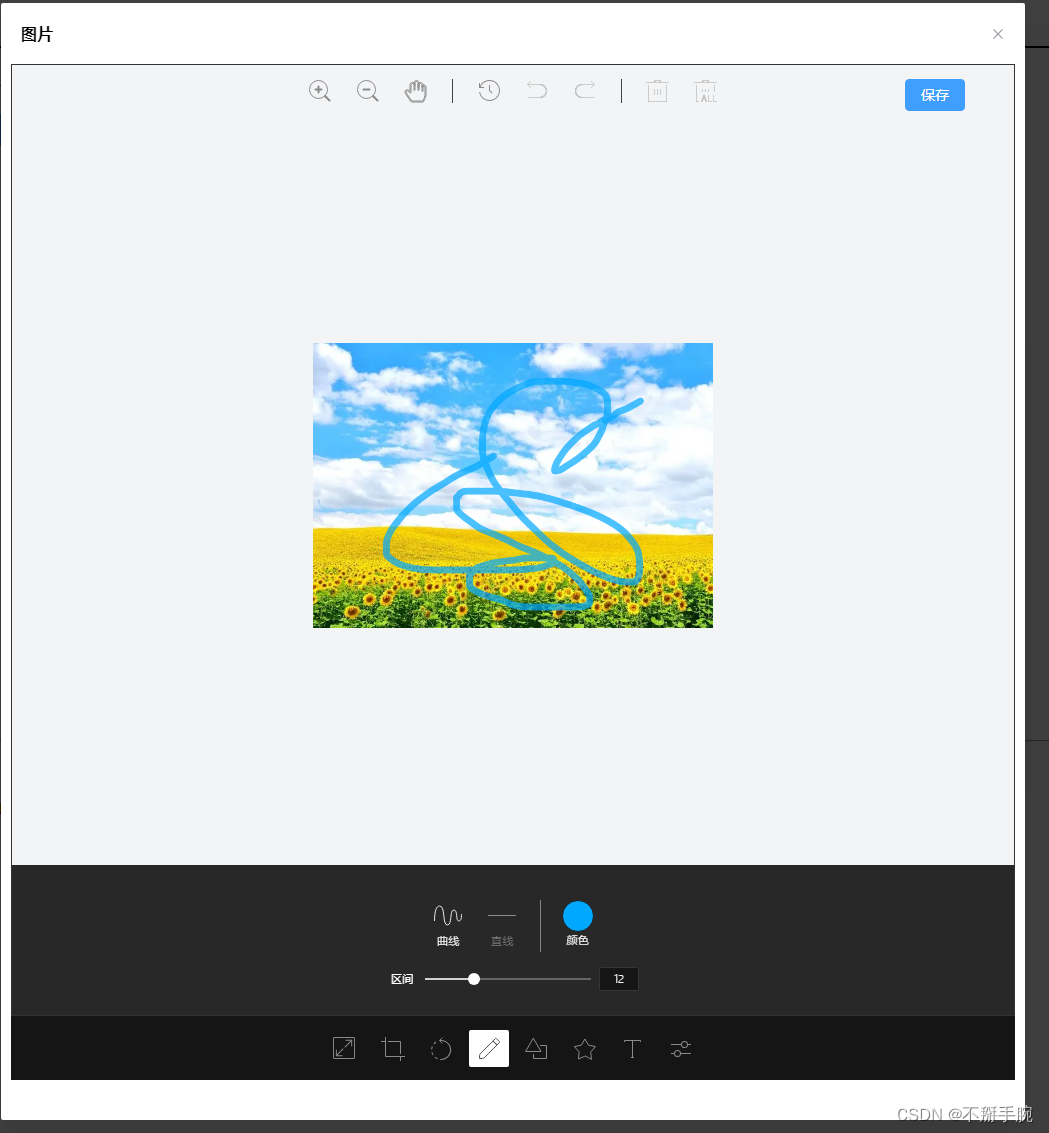
vue3中使用 tui-image-editor进行图片处理,并上传
效果图 下载包 pnpm i tui-image-editor pnpm i tui-color-picker调用组件 //html部分 <el-dialog v-model"imgshow" destroy-on-close width"40%" draggable align-center :show-close"true":close-on-click-modal"false">&l…...

18.贪心算法
排序贪心 区间贪心 删数贪心 统计二进制下有多少1 int Getbit_1(int n){int cnt0;while(n){nn&(n-1);cnt;}return cnt; }暴力加一维前缀和优化 #include <iostream> #include <climits> using namespace std; #define int long long const int N2e510; in…...
[AI]部署安装有道QanyThing
前提条件: 1、win10系统更新到最新的版本,系统版本最好为专业版本 winver 查看系统版本,内部版本要大于19045 2、CPU开启虚拟化 3、开启虚拟化功能,1、2、3每步完成后均需要重启电脑; 注:windows 虚拟…...
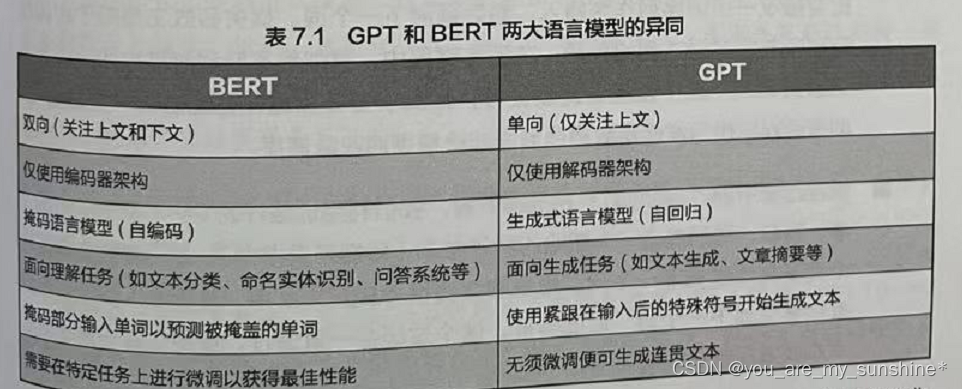
NLP_BERT与GPT争锋
文章目录 介绍小结 介绍 在开始训练GPT之前,我们先比较一下BERT和 GPT 这两种基于 Transformer 的预训练模型结构,找出它们的异同。 Transformer架构被提出后不久,一大批基于这个架构的预训练模型就如雨后春笋般地出现了。其中最重要、影响…...

Cursorify:构建AI驱动的深度集成开发环境框架
1. 项目概述:从“智能代码补全”到“深度集成开发环境”的跨越最近在开发者社区里,一个名为“Cursorify”的项目引起了不小的讨论。乍一看这个标题,很多人的第一反应可能是“哦,又一个基于Cursor的插件或者工具”。但当你真正深入…...

【无人机路径规划】基于K-means 聚类和遗传算法实现多架无人机任务区域进行划分,并优化各区域内的访问路径附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

免费开源AMD Ryzen处理器调试工具:5分钟掌握SMUDebugTool终极指南
免费开源AMD Ryzen处理器调试工具:5分钟掌握SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

FPGA实战:用Z80与8051软核构建可运行BASIC的复古计算机
1. 项目概述:在FPGA上复活经典8位计算机如果你和我一样,对上世纪七八十年代那些经典的8位计算机架构——比如Zilog Z80和Intel 8051——抱有浓厚的兴趣,同时又对现代FPGA技术着迷,那么这个项目绝对会让你兴奋。它不是一个简单的仿…...
大语言模型实战:从Transformer到QLoRA微调与RAG应用
1. 项目概述:为什么我们需要一门关于大语言模型的课程?如果你在过去一年里关注过技术圈,那么“大语言模型”这个词一定已经听得耳朵起茧了。从ChatGPT的横空出世,到各类开源模型的百花齐放,再到企业级应用的遍地开花&a…...

如何通过Xiaomusic开源项目解锁小爱音箱的完整音乐播放功能
如何通过Xiaomusic开源项目解锁小爱音箱的完整音乐播放功能 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic Xiaomusic是一款开源智能音乐播放器,专为小米…...

从BERT到GPT-4:大语言模型的技术演进与应用实践
1. 从单向到双向:大语言模型如何重塑AI的认知边界如果你在2018年之前问我,一个AI模型能不能同时理解一句话里每个词的前后文关系,我会告诉你这很难。那时的主流模型,比如OpenAI的GPT初代,就像一个只能从左到右阅读的读…...

WinRing0深度解析:Windows硬件访问的终极解决方案
WinRing0深度解析:Windows硬件访问的终极解决方案 【免费下载链接】WinRing0 WinRing0 is a hardware access library for Windows. 项目地址: https://gitcode.com/gh_mirrors/wi/WinRing0 WinRing0是一个功能强大的Windows硬件访问库,为开发者提…...
双向DC-AC逆变器的恒压恒频(V/f)控制)
学Simulink——电池储能系统(BESS)双向DC-AC逆变器的恒压恒频(V/f)控制
目录 手把手教你学Simulink——电池储能系统(BESS)双向DC-AC逆变器的恒压恒频(V/f)控制 一、背景与挑战 1.1 什么是 V/f 控制?为什么 BESS 需要它? 1.2 核心痛点与设计目标 二、系统架构与核心控制推导 2.1 整体架构:电压源特性的“自主构建” 2.2 核心数学推导:…...

在Windows上安装APK的终极指南:5步掌握APK Installer工具
在Windows上安装APK的终极指南:5步掌握APK Installer工具 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接安装Android应用…...