Python爬虫技术详解:从基础到高级应用,实战与应对反爬虫策略【第93篇—Python爬虫】
前言
随着互联网的快速发展,网络上的信息爆炸式增长,而爬虫技术成为了获取和处理大量数据的重要手段之一。在Python中,requests模块是一个强大而灵活的工具,用于发送HTTP请求,获取网页内容。本文将介绍requests模块的基础用法,并通过实际代码演示,带领读者一步步掌握常用爬虫技术。

安装requests模块
首先,确保你的Python环境中已经安装了requests模块。如果没有安装,可以使用以下命令进行安装:
pip install requests
基础用法
发送GET请求
import requestsurl = 'https://www.example.com'
response = requests.get(url)print(response.text)
以上代码通过requests.get()方法发送了一个GET请求,并将服务器的响应存储在response对象中。response.text包含了网页的HTML内容。
发送带参数的GET请求
import requestsurl = 'https://www.example.com/search'
params = {'q': 'python', 'page': 1}
response = requests.get(url, params=params)print(response.text)
在这个例子中,我们通过params参数传递了查询字符串参数,这对于搜索等需要动态参数的场景非常有用。
发送POST请求
import requestsurl = 'https://www.example.com/login'
data = {'username': 'your_username', 'password': 'your_password'}
response = requests.post(url, data=data)print(response.text)
通过requests.post()方法,我们可以发送POST请求并传递表单数据,模拟登录等操作。
代码实战:爬取网页内容
让我们通过一个实际的例子,使用requests模块爬取并解析网页内容。
import requests
from bs4 import BeautifulSoupurl = 'https://www.example.com'
response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')# 解析网页内容
title = soup.title.text
paragraphs = soup.find_all('p')# 打印结果
print(f'Title: {title}\n')
print('Paragraphs:')
for paragraph in paragraphs:print(paragraph.text)
在这个示例中,我们使用了BeautifulSoup库来解析HTML内容。首先,我们获取网页内容,然后通过BeautifulSoup的解析器解析HTML。最后,通过选择器定位标题和段落等信息,实现对网页内容的抽取。
进阶用法
设置请求头
有些网站可能需要模拟浏览器进行访问,因此我们可以通过设置请求头来伪装请求:
import requestsurl = 'https://www.example.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)print(response.text)
在这个例子中,我们通过headers参数设置了用户代理,模拟了一个浏览器访问。
处理Cookies
有些网站通过Cookies来进行用户认证和跟踪,我们可以使用requests模块来处理Cookies:
import requestsurl = 'https://www.example.com'
response = requests.get(url)# 获取Cookies
cookies = response.cookies# 使用Cookies进行后续请求
response2 = requests.get('https://www.example.com/some_page', cookies=cookies)print(response2.text)
处理异常
在实际爬虫中,网络请求可能会遇到各种异常情况,为了保证爬虫的稳定性,我们可以添加异常处理:
import requestsurl = 'https://www.example.com'try:response = requests.get(url)response.raise_for_status() # 检查请求是否成功print(response.text)
except requests.exceptions.HTTPError as errh:print(f"HTTP Error: {errh}")
except requests.exceptions.ConnectionError as errc:print(f"Error Connecting: {errc}")
except requests.exceptions.Timeout as errt:print(f"Timeout Error: {errt}")
except requests.exceptions.RequestException as err:print(f"Request Exception: {err}")
代码实战:使用requests模块爬取天气数据
为了进一步加深对requests模块的理解,我们将通过一个实际的案例,使用该模块爬取实时天气数据。在这个例子中,我们将使用OpenWeatherMap提供的API来获取天气信息。
首先,你需要在OpenWeatherMap注册账号并获取API Key。然后,我们可以使用以下代码来获取实时天气信息:
import requests
import json# 替换为你自己的OpenWeatherMap API Key
api_key = 'your_api_key'
city = 'Berlin' # 替换为你要查询的城市# 构造API请求URL
url = f'http://api.openweathermap.org/data/2.5/weather?q={city}&appid={api_key}'try:response = requests.get(url)response.raise_for_status() # 检查请求是否成功# 解析JSON格式的响应weather_data = response.json()# 提取天气信息temperature = weather_data['main']['temp']description = weather_data['weather'][0]['description']# 打印结果print(f'Current temperature in {city}: {temperature}°C')print(f'Weather description: {description}')except requests.exceptions.HTTPError as errh:print(f"HTTP Error: {errh}")
except requests.exceptions.ConnectionError as errc:print(f"Error Connecting: {errc}")
except requests.exceptions.Timeout as errt:print(f"Timeout Error: {errt}")
except requests.exceptions.RequestException as err:print(f"Request Exception: {err}")
在这个例子中,我们构造了一个API请求URL,发送GET请求获取天气信息。然后,使用json模块解析返回的JSON数据,并提取出温度和天气描述信息。最后,打印结果。
这个实例展示了如何使用requests模块来访问API,并处理返回的JSON数据。这对于获取实时数据或者进行数据分析非常有用。在实际项目中,你可以根据需要扩展这个例子,比如添加更多的天气信息或者结合其他API来获取更多有用的数据。
高级应用:使用Session保持会话状态
在某些情况下,我们需要保持会话状态,模拟用户在同一个会话中进行多个请求,比如登录后爬取需要登录状态的页面。为了实现这一功能,可以使用Session对象。
以下是一个简单的例子,模拟登录GitHub并获取登录后的用户页面:
import requestslogin_url = 'https://github.com/login'
user_url = 'https://github.com/your_username'# 替换为你的GitHub用户名和密码
username = 'your_username'
password = 'your_password'# 创建一个Session对象
session = requests.Session()# 发送登录请求
login_data = {'login': username, 'password': password}
login_response = session.post(login_url, data=login_data)# 检查登录是否成功
if 'Sign out' in login_response.text:print('Login successful!')# 使用保持会话状态的Session对象进行后续请求user_response = session.get(user_url)# 处理用户页面的响应print(user_response.text)
else:print('Login failed.')
在这个例子中,我们使用Session对象首先发送登录请求,将登录信息保存在会话中。然后,使用同一个会话对象进行后续的请求,这样就能够保持登录状态,获取登录后的页面内容。
附加内容:处理动态网页和反爬虫策略
在实际爬虫过程中,经常会遇到动态网页和反爬虫策略。动态网页是指页面的内容通过JavaScript等前端技术动态加载,而不是一开始就包含在HTML中。为了处理这种情况,我们可以使用Selenium等工具。
使用Selenium处理动态网页
首先,确保你已经安装了Selenium:
pip install selenium
然后,通过以下代码使用Selenium模拟浏览器行为:
from selenium import webdriver
import timeurl = 'https://example.com'
driver = webdriver.Chrome() # 请确保已安装ChromeDriver,并将其路径添加到系统环境变量中try:driver.get(url)# 等待页面加载time.sleep(3)# 获取页面内容page_content = driver.page_sourceprint(page_content)finally:driver.quit()
在这个例子中,我们使用了Chrome浏览器驱动,打开了一个网页并等待3秒,然后获取了页面的源代码。通过这种方式,我们可以获取到动态加载的内容。
处理反爬虫策略
有些网站为了防止被爬虫访问,采取了一些反爬虫策略,比如设置访问频率限制、验证码验证等。在面对这些情况时,我们可以采取以下措施:
-
设置请求头: 模拟浏览器行为,设置合适的User-Agent和Referer等请求头,使请求看起来更像正常用户的访问。
-
使用代理IP: 轮换使用代理IP可以降低被封禁的风险,但注意代理IP的合法性和稳定性。
-
处理验证码: 使用第三方库或者服务识别和处理验证码,自动化解决验证码问题。
-
合理设置访问频率: 避免过于频繁的访问,可以通过设置访问间隔或者使用随机休眠时间来规避被封禁的风险。
请注意,爬虫行为应当遵循网站的使用规则,并尊重相关法律法规。过于频繁或不当的爬取行为可能导致IP封禁或其他法律责任。在实际应用中,可以根据具体情况灵活调整策略,确保爬虫的合法性和稳定性。
总结:
通过本文的详细介绍,读者对Python爬虫技术有了从基础到高级的全面了解。我们从requests模块的基础用法开始,包括发送GET和POST请求、处理参数、设置请求头、处理Cookies、异常处理等方面。通过实际的代码演示,读者学会了如何使用requests模块进行网络爬取,并解析HTML内容,实现数据的抽取。
随后,我们进行了一个实际的爬虫项目,使用requests模块获取实时天气数据,并通过JSON解析提取所需信息。这个实例展示了如何使用爬虫技术获取实时数据,为数据分析和应用提供支持。
在高级应用部分,我们介绍了使用Session对象保持会话状态,模拟用户在同一个会话中进行多个请求的方法。同时,我们提及了使用Selenium处理动态网页和一些反爬虫策略的方法,使得爬虫能够更好地应对复杂的网站结构和防护机制。
最后,强调了在实际应用中需要遵循网站的使用规则,合法合规地进行网络爬取。在面对动态网页和反爬虫策略时,我们介绍了一些常见的应对措施,包括使用Selenium、设置请求头、使用代理IP、处理验证码等。
希望本文能够帮助读者建立起扎实的爬虫基础,理解爬虫技术的广泛应用,同时对于高级应用和反爬虫策略有一定的认识。在实际项目中,读者可以根据需要灵活运用这些技术,提升爬虫的效率和稳定性。
相关文章:
Python爬虫技术详解:从基础到高级应用,实战与应对反爬虫策略【第93篇—Python爬虫】
前言 随着互联网的快速发展,网络上的信息爆炸式增长,而爬虫技术成为了获取和处理大量数据的重要手段之一。在Python中,requests模块是一个强大而灵活的工具,用于发送HTTP请求,获取网页内容。本文将介绍requests模块的…...

关于TypeReference的使用
关于TypeReference的使用 在项目中,有遇到TypeReference的使用,其主要在字符串转对象过程中,对于序列化和反序列化中也有效果,将字符串转换成自定义对象. 1 说明 以常见为例,在com.alibaba.fastjson包下面的TypeReference类,是指Type的Reference,表示某类型的一个指…...

阿里大文娱前端一面
引言 我目前本科大四,正在春招找前端,有大厂内推的友友可以聊一聊,球球给孩子的机会吧。 我整理了一份10w字的前端技术文档:https://qx8wba2yxsl.feishu.cn/docx/Vb5Zdq7CGoPAsZxMLztc53E1n0k?fromfrom_copylink,对…...

Clickhouse系列之连接工具连接、数据类型和数据库
基本操作 一、使用连接工具连接二、数据类型1、数字类型IntFloatDecimal 2、字符串类型StringFixedStringUUID 3、时间类型DateTimeDateTime64Date 4、复合类型ArrayEnum 5、特殊类型Nullable 三、数据库 一、使用连接工具连接 上一篇介绍了clickhouse的命令行登录,…...

【深入理解设计模式】原型设计模式
原型设计模式 原型设计模式(Prototype Pattern)是一种创建型设计模式,它允许通过复制已有对象来创建新对象,而无需直接依赖它们的具体类。这种模式通常用于需要频繁创建相似对象的场景,以避免昂贵的创建操作或初始化过…...

Python算法题集_图论(课程表)
Python算法题集_课程表 题207:课程表1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【循环递归全算】2) 改进版一【循环递归缓存】3) 改进版二【循环递归缓存反向计算】4) 改进版三【迭代剥离计数器检测】 4. 最优算法5. 相关资源 本…...
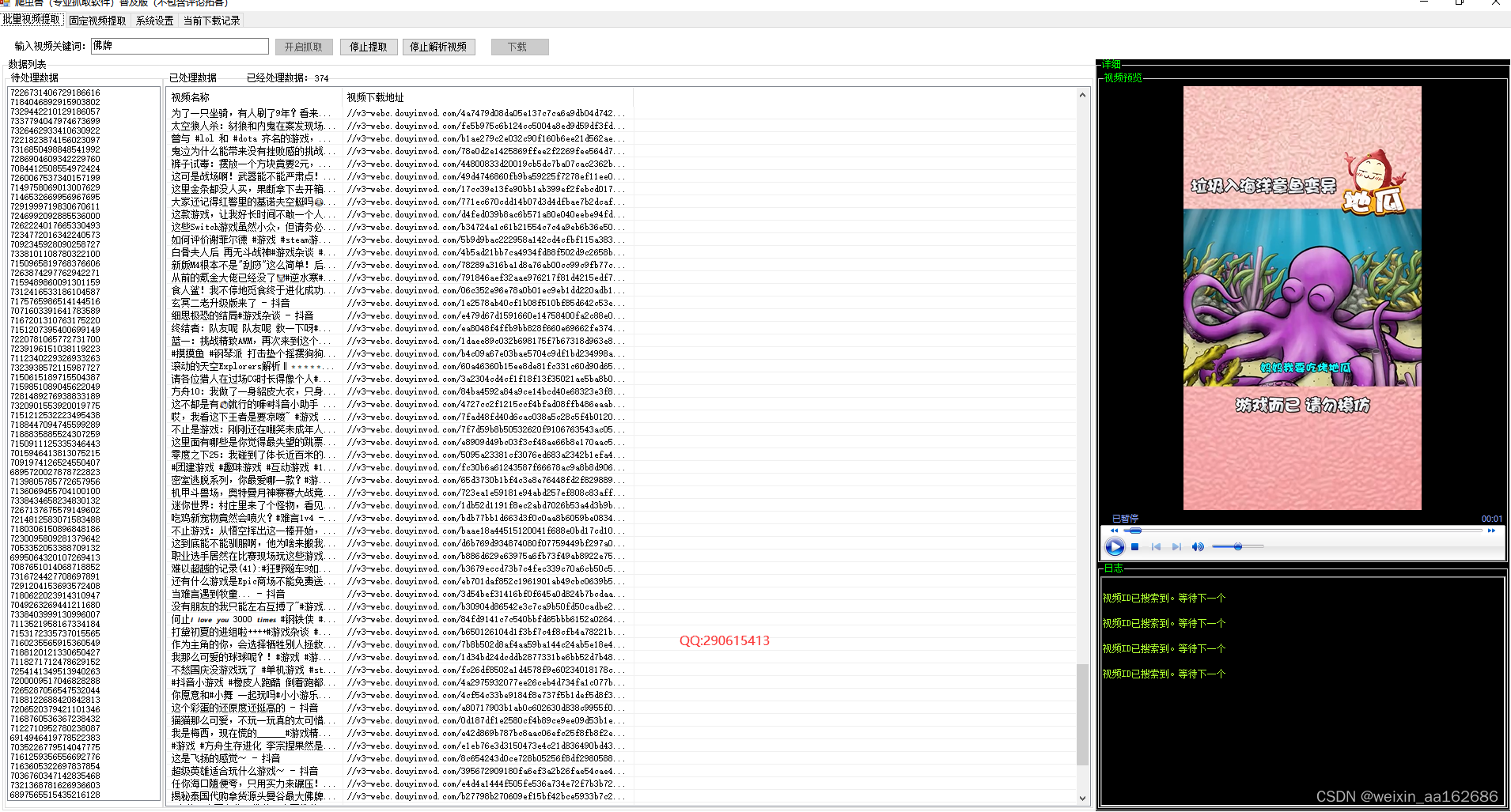
视频评论挖掘软件|抖音视频下载工具
针对抖音视频下载的需求,我们开发了一款功能强大的工具,旨在解决用户在获取抖音视频时需要逐个复制链接、下载的繁琐问题。我们希望用户能够通过简单的关键词搜索,实现自动批量抓取视频,并根据需要进行选择性批量下载。因此&#…...
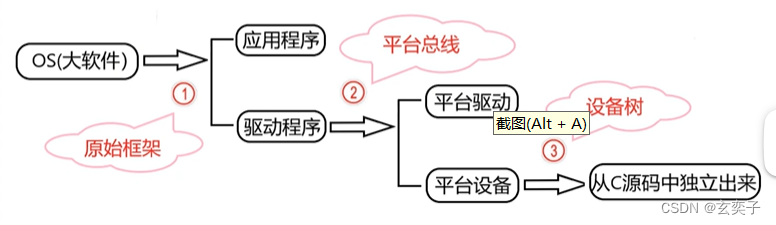
Linux学习方法-框架学习法——Linux驱动架构的演进
配套视频学习链接:https://www.bilibili.com/video/BV1HE411w7by?p4&vd_sourced488bc722b90657aaa06a1e8647eddfc 目录 Linux驱动演进的过程 Linux驱动的原始架构(Linux V2.4) 平台总线架构(platform) Linux设备树 Linux驱动演进的趋势 Linux驱动演进的过程…...
)
Spring Boot基础面试问题(一)
上篇文章中10个Spring Boot面试问题的标准答案: 什么是Spring Boot?它与Spring框架有什么区别? 标准回答:Spring Boot是基于Spring框架的快速开发框架,它简化了Spring应用程序的搭建和配置过程,提供了一套自…...
电路设计(28)——交通灯控制器的multisim仿真
1.功能设定 南北、东西两道的红灯时间、绿灯时间均为24S,数码管显示倒计时。在绿灯的最后5S内,黄灯闪烁。有夜间模式:按下按键进入夜间模式。在夜间模式下,数码管显示计数最大值,两个方向的黄灯不停闪烁。 2.电路设计 …...
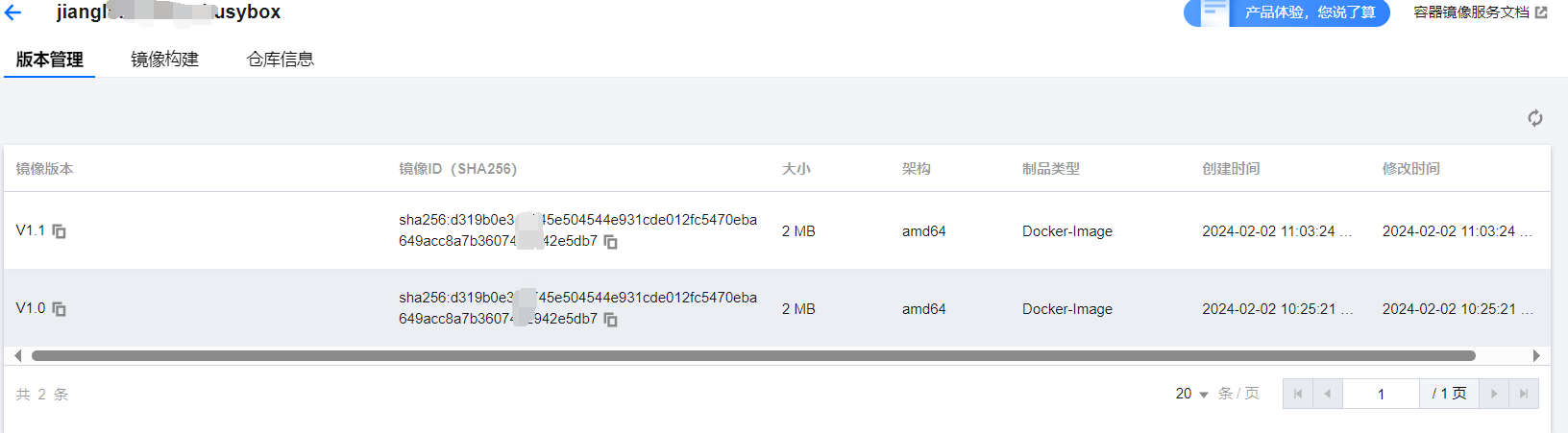
【Docker】免费使用的腾讯云容器镜像服务
需要云服务器等云产品来学习Linux可以移步/-->腾讯云<--/官网,轻量型云服务器低至112元/年,新用户首次下单享超低折扣。 目录 1、设置密码 2、登录实例(sudo docker login xxxxxx) 3、新建命名空间(每个命名空…...

如何让qml使用opengl es
要让 QML 使用 OpenGL ES,您需要确保项目配置正确,并在应用程序中使用 QSurfaceFormat 来设置 OpenGL ES 渲染。 以下是一些步骤来配置 QML 使用 OpenGL ES: 1、项目配置:在您的项目配置文件(例如 .pro 文件…...

金航标电子位于广西柳州鹿寨县天线生产基地于大年正月初九开工了!!
金航标电子位于广西柳州鹿寨县天线生产基地于大年正月初九开工了!!!金航标kinghelm( http://www.kinghelm.com.cn )总部位于中国深圳市,兼顾技术、成本、管理、效率和可持续发展。东莞塘厦实验室全电波暗…...

FlinkCDC详解
1、FlinkCDC是什么 1.1 CDC是什么 CDC是Chanage Data Capture(数据变更捕获)的简称。其核心原理就是监测并捕获数据库的变动(例如增删改),将这些变更按照发生顺序捕获,将捕获到的数据,写入数据…...

力扣代码学习日记六
Problem: 66. 加一 思路 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外,这个整数不会以零开头。 示例 1: 输…...

「Python系列」Python标准库
文章目录 一、 os 模块:文件和目录操作二、 sys 模块:与Python解释器交互三、 datetime 模块:日期和时间处理四、 json 模块:处理JSON数据五、 re 模块:正则表达式六、 time模块1. 获取当前时间2. 延迟执行(…...
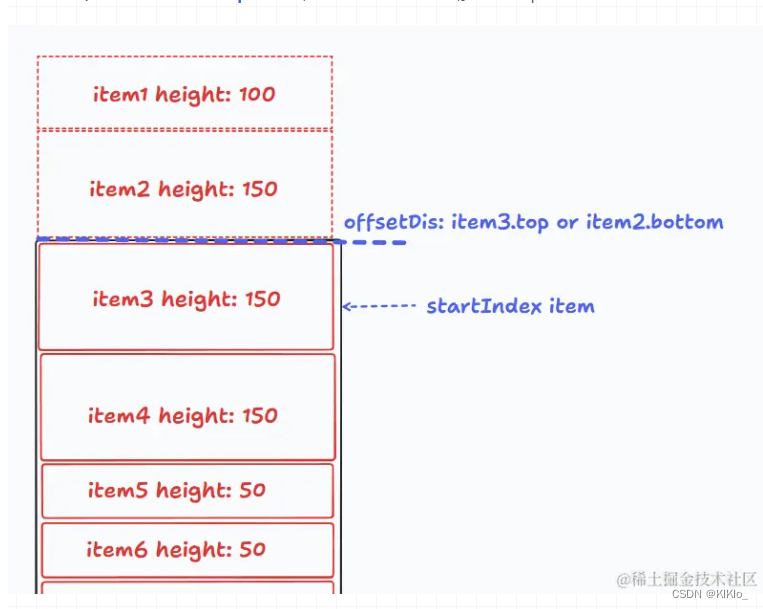
虚拟列表【vue】等高虚拟列表/非等高虚拟列表
文章目录 1、等高虚拟列表2、非等高虚拟列表 1、等高虚拟列表 参考文章1 参考文章2 <!-- eslint-disable vue/multi-word-component-names --> <template><divclass"waterfall-wrapper"ref"waterfallWrapperRef"scroll"handleScro…...
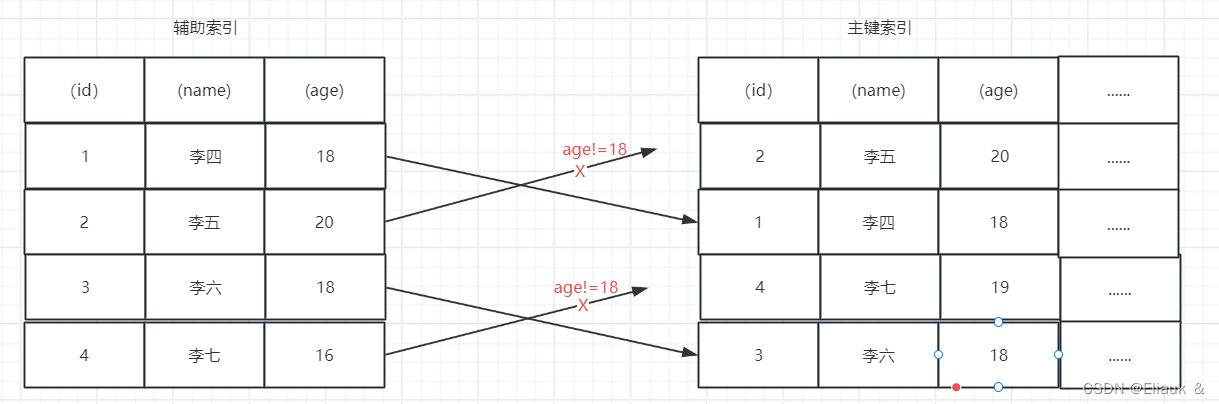
【MySQL】如何理解索引(高频面试点)
一、前言 首先这个博客会介绍一些关于MySQL中索引的基本内容以及一些基本的语法,当然里面也会有些常见的面试题的解答。 二、关于索引 1、概念 索引是一种能够帮助MySQL高效的去磁盘检索数据的一种数据结构。在MySQL的Innodb存储引擎中呢,采用的是B树的…...
:S32K3xx如何产生中心对称三相六路波形)
NXP实战笔记(四):S32K3xx如何产生中心对称三相六路波形
目录 1、概述 1.1、理论基础 2、RTD实现 2.1、Emios时基配置 2.1.1、EmiosMcl 2.1.2、EmiosCommon 2.2、Emios PWM配置 2.3、TRGMUX 2.4、LCU 2.5、外设信号配置 3、代码实现 4、测试结果 1、概述 电机控制中需要产生三相六路SVPWM进行占空比与周期调制,怎么通过RT…...

关于uniapp H5应用无法在触摸屏正常显示的处理办法
关于uniapp H5应用无法在触摸屏正常显示的处理办法 1、问题2、处理3、建议 1、问题 前几天, 客户反馈在安卓触摸大屏上无法正确打开web系统(uni-app vue3开发的h5 应用),有些页面显示不出内容。该应用在 pc 端和手机端都可以正常…...

从PUMA560到你的项目:手把手教你将经典DH建模流程迁移到自定义机械臂
从PUMA560到自定义机械臂:DH建模实战迁移指南 当机械臂从教科书案例走向真实项目时,最令人头疼的莫过于面对一个全新构型却不知如何下手。本文将以工业界经典的PUMA560为跳板,拆解一套可迁移的DH建模方法论,带您跨越从理论到实践的…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...

C++定时器避坑指南:线程安全、资源泄漏与时间轮参数怎么调?一次讲清楚
C定时器避坑指南:线程安全、资源泄漏与时间轮参数调优实战 在分布式系统和高并发场景中,定时器如同系统的心跳机制,其稳定性直接决定服务可靠性。去年某电商平台大促期间,由于定时任务堆积导致的雪崩效应,造成近千万损…...

MySQL 索引底层 B+ 树原理
聊 MySQL 索引,不讲 B 树,那就是在耍流氓。 大家好,我是乱码字符。今天咱们深入聊聊 MySQL 索引的底层数据结构——B 树。这篇文章能让你彻底搞明白,为什么有时候明明加了索引,查询却还是慢成狗。 先说说为什么要用树结…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...

VS Code光标主题定制指南:提升开发效率与视觉舒适度
1. 项目概述:一个为开发者量身定制的光标主题集合如果你和我一样,每天有超过8个小时的时间是在代码编辑器里度过的,那么你一定对那个在屏幕上闪烁的光标再熟悉不过了。它不仅仅是文本插入点,更是我们思维在数字世界中的延伸。然而…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...

如何选蜂蜜品牌?2026年5月推荐靠谱蜂蜜品牌避坑指南
一、引言买蜂蜜怕踩坑?市面上的蜂蜜产品琳琅满目,但勾兑蜜、浓缩蜜、添加糖浆的“科技蜜”层出不穷,消费者往往花了高价却买不到真正的纯正好蜜。对于注重健康饮食、追求天然原生态食品的消费者而言,如何从海量品牌中筛选出真正无…...

【最新 v2.7.1 版本安装包】OpenClaw 零基础无痛部署,无需命令零代码保姆级快速上手
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...
架构与实现)
基于RAG与向量数据库的智能信息管理系统(IIMS)架构与实现
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的项目,叫“IIMS-By-AI”。乍一看这个标题,可能有点摸不着头脑,但拆解一下就能明白它的野心:IntelligentInformationManagementSystem, By AI。…...