Selenium浏览器自动化测试框架详解
selenium简介
介绍
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
功能
优势
- 框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
- 使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
- 使用简单,可使用Java,Python等多种语言编写用例脚本。
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
下面是主要的两大好处:
通过编写模仿用户操作的 Selenium 测试脚本,可以从终端用户的角度来测试应用程序。通过在不同浏览器中运行测试,更容易发现浏览器的不兼容性。Selenium 的核心,也称browser bot,是用 JavaScript 编写的。这使得测试脚本可以在受支持的浏览器中运行。browser bot 负责执行从测试脚本接收到的命令,测试脚本要么是用 HTML 的表布局编写的,要么是使用一种受支持的编程语言编写的。
官方文档
chromedriver下载:
chromedriver与chrome的对应关系表:
基本使用
安装: pip install selenium
from selenium import webdriverbrowser = webdriver.Chrome(executable_path='chromedriver.exe') # 声明一个浏览器对象 指定使用chromedriver.exe路径browser.get("https://www.baidu.com") # 打开Chrome
input = browser.find_element_by_id("kw") # 通过id定位到input框
input.send_keys("python") # 在输入框内输入pythonprint(browser.current_url) # 打印url
print(browser.get_cookies()) # 打印Cookies
print(browser.page_source) # 打印网页源代码browser.close() # 关闭浏览器获取单节点
from selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.taobao.com")
# 找到搜索框
input_id = browser.find_element_by_id("q") # 通过id找
input_name = browser.find_element_by_name("q") # 通过name属性值找
input_css = browser.find_element_by_css_selector("#q") # 根据css选择器找
input_xpath = browser.find_element_by_xpath('//*[@id="q"]') # 根据xpath找
print(input_id,input_name,input_css,input_xpath)
browser.close()
"""
<selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")>
<selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")>
<selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")>
<selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")>
"""# 其他获取单个节点方法
"""
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
"""
# 通过方法
# find_element(By.ID,"q") # 参数为查找方式和值获取多节点
from selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.taobao.com")lis = browser.find_elements_by_css_selector(".service-bd li") # 注意是elements多个s
print(lis) # 输出为列表"""
[<selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="454d656c-1730-410e-891e-210bfdf0d248")>, <selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="119177aa-014a-48c1-8bea-8ca9a50b446e")>, <selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="974860cf-1218-4ddf-a745-85f86090e188")>, <selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="e5877c0c-f4df-4847-9875-1c81d56f21ee")>]
"""# 其他获取多个节点方法
"""
find_elements_by_id("q")
find_elements_by_name("q")
find_elements_by_css_selector("#q")
find_elements_by_xpath('//*[@id="q"]')
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
"""
# 通过方法
# find_elements(By.CSS_SELECTOR,".service-bd li") # 参数为查找方式和值节点交互
import time
from selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.taobao.com")"""
selenium可以驱动浏览器来执行一些动作:
输入文字用send_keys()
清空文字用clear()
点击按钮用click()
"""input = browser.find_element_by_id("q")
input.send_keys("iPhone") #在搜索框输入iPhoneinput.clear() # 清空搜索框的文字
time.sleep(2)
input.send_keys("iPad") # 在搜索框输入iPadbutton = browser.find_element_by_class_name("btn-search") # 获取点击按钮
button.click() # 点击搜索动作链#
from selenium import webdriver
from selenium.webdriver import ActionChains # 引入动作链
browser = webdriver.Chrome()
url = "https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"
browser.get(url)browser.switch_to.frame("iframeResult") # 切换到元素所在的frame[框架]
"""
可以传入id、name、index以及selenium的WebElement对象,index从0开始
"""source = browser.find_element_by_css_selector("#draggable") # 找到被拖拽对象
target = browser.find_element_by_css_selector("#droppable") # 找到目标actions = ActionChains(browser) # 声明actions对象
actions.drag_and_drop(source,target) # 拖拽元素的起点和终点
actions.perform() # 执行动作action.click_and_hold() # 点击且长按,更多方法查看官方文档执行JavaScript代码
from selenium import webdriverbrowser = webdriver.Chrome()
url = "https://www.zhihu.com/explore"
browser.get(url)browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 将进度条下拉到最底部
browser.execute_script("alert('hello word')") # 弹出alert提示窗获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()url = "https://www.zhihu.com/explore"browser.get(url)"""
WebElement常用属性:get_attribute 获取属性值text 获取文本值id 获取节点idlocation 获取节点在页面中的相对位置tag_name 获取标签名称size 获取节点大小(宽和高)
"""# 获取属性
logo = browser.find_element_by_id("zh-top-link-logo") # 获取logo节点
print(logo) # 返回值为WebElement对象logo_class = logo.get_attribute("class") # 获取zh-top-link-logo节点的class属性值
print(logo_class)# 获取文本值
text_Ele = browser.find_element_by_css_selector(".question_link") # 通过css选择器获取文本内容所在的标签
text = text_Ele.text # 取出标签内的文本内容
print(text)# 获取ID 位置 标签名和大小
test = browser.find_element_by_class_name("zu-top-add-question")
print(test.id) # 0bfe7ae6-ebd9-499a-8f4e-35ae34776687
print(test.location) # {'x': 759, 'y': 7}
print(test.tag_name) # button
print(test.size) # {'height': 32, 'width': 66}切换frame
from selenium import webdriverbrowser = webdriver.Chrome()url = "https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"browser.get(url)
"""
网页中有一种节点叫做iframe,也就是子Frame,相当于页面的子页面,
他的结构和外部网页的结构完全一致。
selenium打开页面后,他默认是在父级Frame里面操作,
而此时如果页面中还有子Frame,他是不能获取到子Frame里面的节点的,
这时候就需要使用switch_to.frame()方法来切换Frame。
"""
browser.switch_to.frame("iframeResult")
logo = browser.find_elements_by_class_name("logo")
print(logo)# [<selenium.webdriver.remote.webelement.WebElement (session="1ccb11403013c749ce9fceda50a00975", element="88e5924e-d655-44c3-a905-8af1947b9d86")>]延时等待
---------------------------隐式等待-------------------------
from selenium import webdriverbrowser = webdriver.Chrome()
# 隐式等待
browser.implicitly_wait(2) # 设定等待时间url = "https://www.zhihu.com/explore"
browser.get(url)
input = browser.find_element_by_class_name("aaa")
print(input)
# 报错信息
"""raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":".aaa"}(Session info: chrome=75.0.3770.142)
""""""
如果selenium没有在DOM中找到节点,将继续等待,超出设定事件后,则抛出找不到节点的异常。
当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间在查找DOM,默认时间是0
"""--------------------------显式等待------------------------
# 显示等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome()
browser.get("https://www.taobao.com/")
wait = WebDriverWait(browser,2)input = wait.until(EC.presence_of_element_located((By.ID,"q")))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,".btn-search")))
print(input,button)# 等待条件
# EC.presence_of_element_located 节点出现
# EC.element_to_be_clickable 可点击
# 更多等待条件查看260页"""
引入WebDriverWait对象指定最长等待时间,调用它的until方法,
传入要等待的条件expected_conditions,比如这里传入例如presence_of_element_located
这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的搜索框。
这样可以做到的效果就是,在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点,
如果10秒还没有加载出来,就抛出异常。
""""""
异常:
TimeoutException
""""""
指定要查找的节点,然后指定一个最长等待时间,如果在规定时间内加载出来了这个节点,
就返回查找的节点,如果到了规定时间依然没有加载出该节点,则抛出【超时】异常
"""前进和后退
import timefrom selenium import webdriverbrowser = webdriver.Chrome()
browser.get("https://www.baidu.com")
browser.get("https://www.taobao.com")
browser.get("https://www.jd.com")browser.back() # 后退
time.sleep(2)
browser.forward() # 前进
browser.close() # 关闭浏览器# 连续访问三个页面cookies
from selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.zhihu.com/explore")
cookies = browser.get_cookies() # 获取cookies
print(cookies)browser.add_cookie({"name":"name","domain":"www.zhihu.com","vlue":"germey"})browser.delete_all_cookies() # 删除所有cookies选项卡管理
import time
from selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.baidu.com")
browser.execute_script("window.open()")
print(browser.window_handles)
# ['CDwindow-7106D94FF002752ADF198B986343E31D', 'CDwindow-B669BA9559DBB78D8D6EC9C5AA699C40']browser.switch_to.window(browser.window_handles[1])
browser.get("https://www.taobao.com")
time.sleep(1)browser.switch_to.window(browser.window_handles[0])
browser.get("https://jd.com")"""
1、打开百度网页
2、新开一个选项卡,调用execute_script()方法传入JavaScript语法window.open()
3、切换到新打开的选项卡,调用window_handles属性获取当前开启的所有选项卡,返回的是选项卡的代号列表,
要想切换选项卡只需要调用switch_to.window()方法,这里我们将第二个选项卡代号传入,
即跳转到第二个选项卡,在第二个选项卡里打开新页面https://www.taobao.com,然后切换回第一个选项卡打开jd页面
"""异常处理
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get("https://www.baidu.com")
try:browser.find_element_by_id("hello")
except Exception as e:print(e) # 打印错误信息 Exception捕获所有错误信息赋给e
finally:browser.close()"""
在使用selenium的过程中,难免遇到一些异常,例如超时、节点未找到错误,
一旦出现此类错误,程序便不会在继续运行了,这里我们使用try except语句来捕获各种异常
"""
选项卡切换
import timefrom selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
browser = webdriver.Chrome(executable_path='D:\chromedriver.exe',options=option) # 声明一个浏览器对象 option.add_experimental_option('excludeSwitches', ['enable-automation'])
browser.get("https://www.baidu.com") # 打开Chromeinput = browser.find_element_by_id("kw") # 通过id定位到input框
input.send_keys("爱奇艺") # 在输入框内输入python
browser.find_element_by_id("su").click()
time.sleep(3)
browser.find_element_by_xpath('//*[@id="1"]/h3').click()
time.sleep(10)
browser.switch_to_window(browser.window_handles[1]) # 切换到新打开的选项卡定位爱奇艺的搜索框search = browser.find_element_by_xpath("//input[@class='search-box-input']").send_keys("青春有你")browser.close() # 关闭浏览器无头浏览器
from selenium import webdriver
from selenium.webdriver.chrome.options import Options# 创建chrome参数对象
opt = Options()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
opt.add_argument('--headless')
# 创建chrome无界面对象
driver = webdriver.Chrome(options=opt)
driver.get("http://www.baidu.com")
print(driver.page_source)最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

相关文章:
Selenium浏览器自动化测试框架详解
selenium简介 介绍 Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google C…...

XGB-11:随机森林
XGBoost通常用于训练梯度提升决策树和其他梯度提升模型。随机森林使用与梯度提升决策树相同的模型表示和推断,但使用不同的训练算法。可以使用XGBoost来训练独立的随机森林,或者将随机森林作为梯度提升的基模型。这里我们专注于训练独立的随机森林。 XG…...

超平面介绍
超平面公式 (1) 超平面是指n维线性空间中维度为n-1的子空间。它可以把线性空间分割成不相交的两部分。比如二维空间中,一条直线是一维的,它把平面分成了两部分;三维空间中,一个平面是二维的,它把空间分成了两部分。(2…...
【苍穹外卖】一些开发总结
1、DTO、VO的区别 DTO:如果前端返回的实体类和对应的实体类比较较大差别 使用DTO来封装数据 后面在使用 BeanUtils.copyProperties() 将熟悉复制到对应的实体类中 VO:主要用于展示数据,例如在控制器层和视图层之间。它通常包含一些与显示相关的属性,如标题、描述等。 2…...

Python 3 中,`asynchat`异步通信
在 Python 3 中,asynchat 是基于 asyncore 的一个高层抽象模块,用于处理异步通信协议。它提供了一种简单的方式来创建自定义的异步通信协议,并处理通信中的错误和异常。 asynchat 模块主要作用是将网络数据流分割成消息或者数据包࿰…...
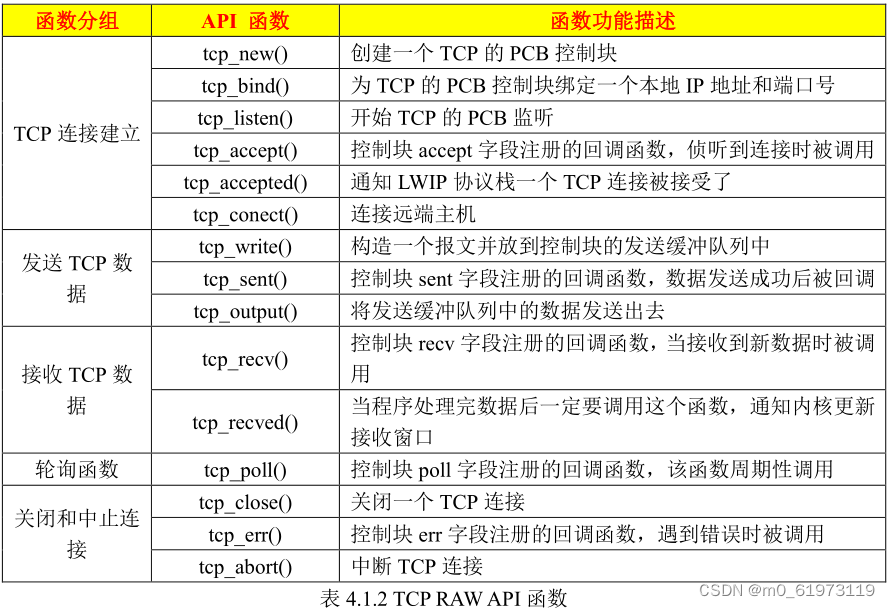
RAW 编程接口 TCP 简介
一、LWIP 中 中 RAW API 编程接口中与 TCP 相关的函数 二、LWIP TCP RAW API 函数 三、LwIP_Periodic_Handle函数 LwIP_Periodic_Handle 函数是一个必须被无限循环调用的 LwIP支持函数,一般在 main函数的无限循环中调用,主要功能是为 LwIP各个模块提供…...

Oracle EBS FA折旧回滚的分录追溯
FA模块向子分类账和总账追溯分为两部分:事务表和折旧,但是FA相关表做其实关联计划外折旧的分录会被遗漏的原因: 如果已经当月折旧,运行完成折旧后,又进行了计划外折旧,因为计划折旧时又要区分【是否进行当月…...
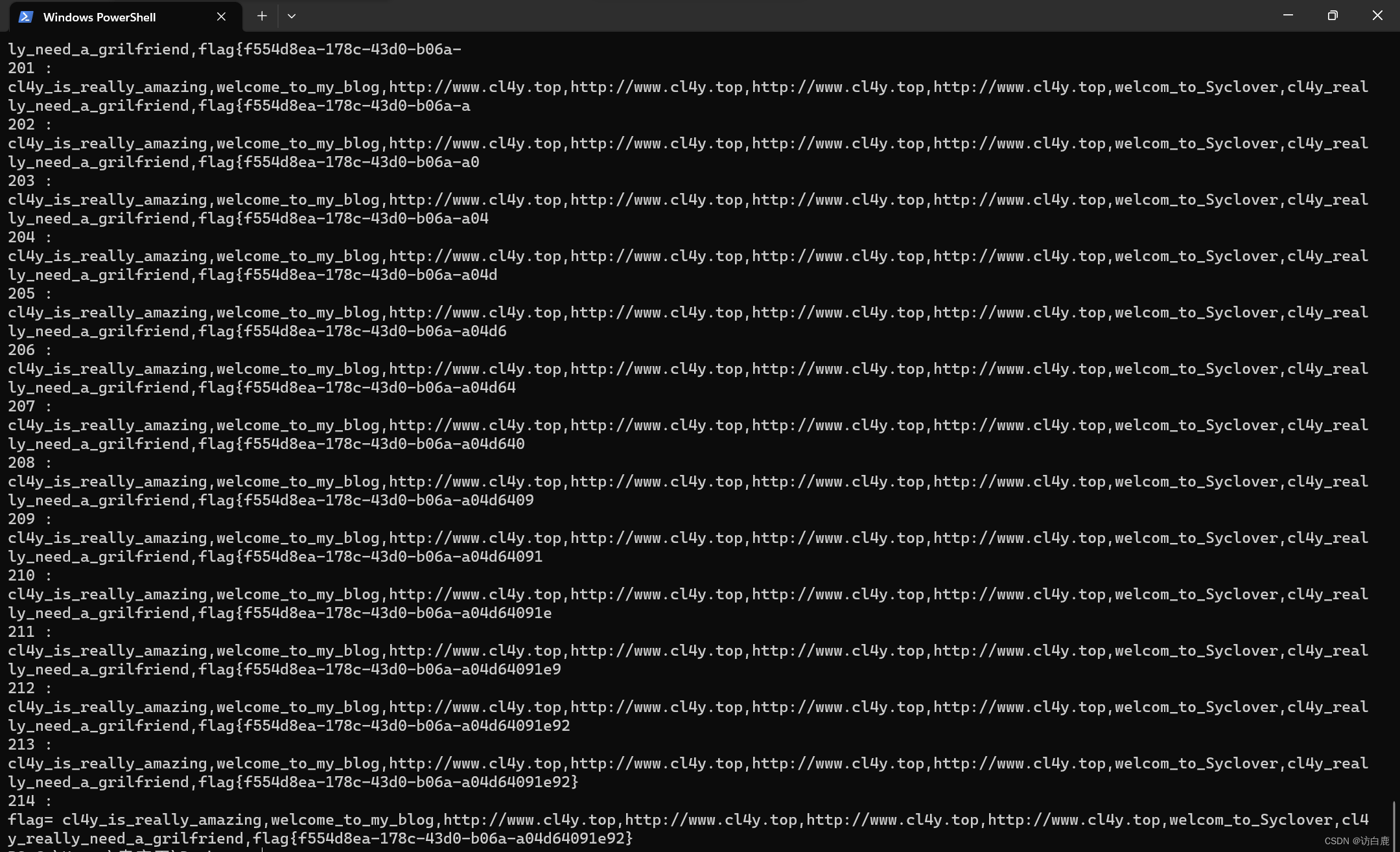
sql注入 [极客大挑战 2019]FinalSQL1
打开题目 点击1到5号的结果 1号 2号 3号 4号 5号 这里直接令传入的id6 传入id1^1^1 逻辑符号|会被检测到,而&感觉成了注释符,&之后的内容都被替换掉了。 传入id1|1 直接盲注比较慢,还需要利用二分法来编写脚本 这里利用到大佬的脚…...

持续集成,持续交付和持续部署的概念,以及GitLab CI / CD的介绍
引言:上一期我们部署好了gitlab极狐网页版,今天我们介绍一下GitLabCI / CD 目录 一、为什么要 CI / CD 方法 1、持续集成 2、持续交付 3、持续部署 二、GitLab CI / CD简介 三、GitLab CI / CD 的工作原理 4、基本CI / CD工作流程 5、首次设置 …...
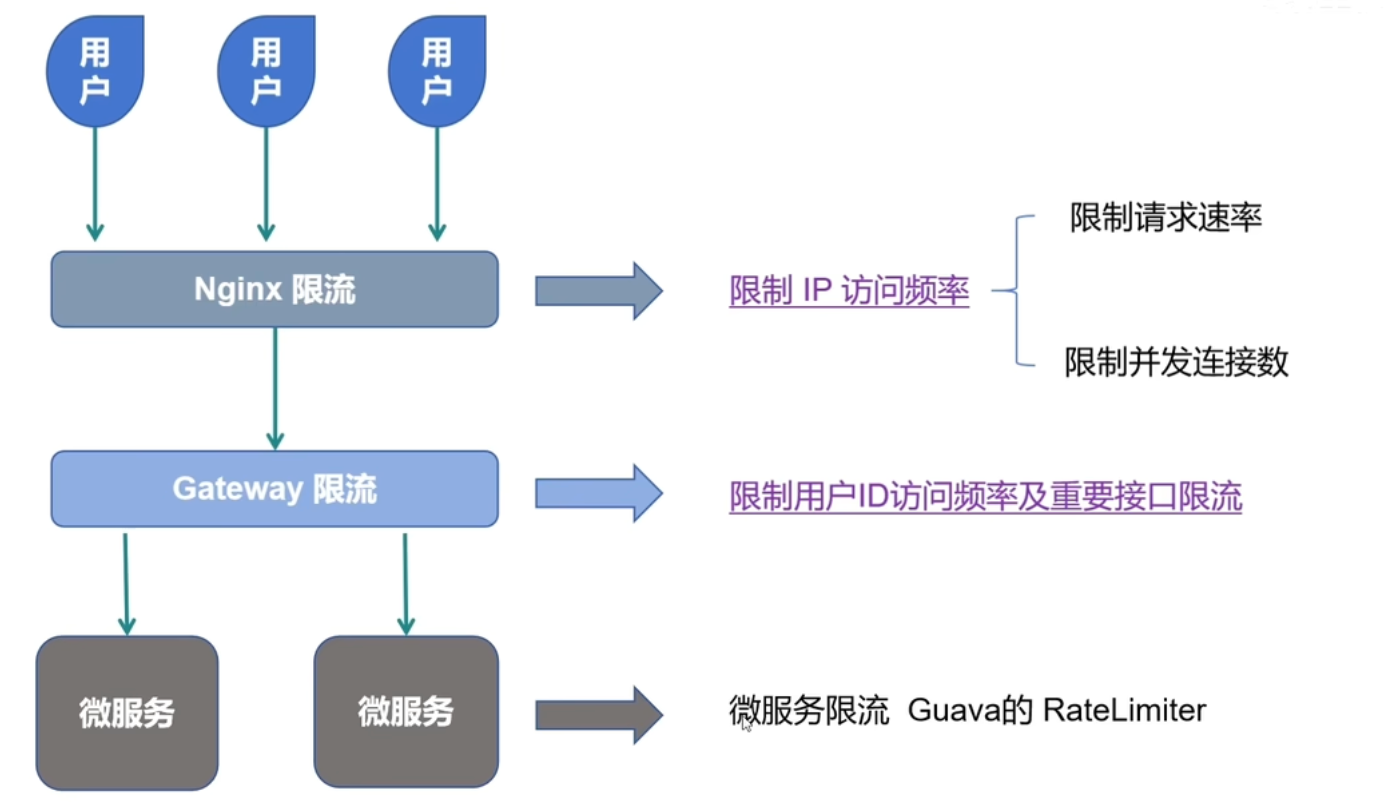
[Java 项目亮点] 三层限流设计
思路来源:bilibili 河北王校长 文章目录 面试官可能会问你能详细介绍一下Nginx的http_limit_req_module模块吗?你能解释一下如何在Nginx中配置http_limit_req_module模块吗?你知道如何调整Nginx的http_limit_req_module模块以适应不同的业务需…...
GPT-SoVITS 快速声音克隆使用案例:webui、api接口
参考: https://github.com/RVC-Boss/GPT-SoVITS 环境: Python 3.10 PyTorch 2.1.2, CUDA 12.0 安装包: 1、使用: 1)下载项目 git clone https://github.com/RVC-Boss/GPT-SoVITS.git2)下载预训练模型 https://huggingface.co/lj1995/GPT-SoVITS 下载模型文件放到GPT…...
系统功能规范)
高速自动驾驶智慧匝道(HIC)系统功能规范
智慧匝道功能规范 Highway Intelligent Change Functional Specification 文件状态: 【√】草稿 【】正式发布 【】正在修改 文件起草分工 撰写: 审核: 编制: 签名: 日期: 审核: 签名&am…...
SQL Server——建表时为字段添加注释
在 MySQL 中,新建数据库表为字段添加注释可以使用 comment 属性来实现。SQL Server 没有 comment 属性,但是可以通过执行 sys.sp_addextendedproperty 这个存储过程添加扩展属性来实现相同的功能。 这个存储过程的参数定义如下: exec sys.s…...

【明道云】导入Excel数据时的默认顺序
【背景】 明道云导入Excel过程中由于数据问题往往会有一些需要补录的地方。这种情况下就需要已上传到线上的数据和本地Excel的记录顺序完全一致才方便对比。因此需要清除如何让两者的记录顺序一致。 【分析】 经过多次排序对比,考虑到分页的影响,发现…...

几种后端开发中常用的语言。
几种后端开发中常用的语言。 C/C 语言 C 语言最初是用于系统开发工作,特别是组成操作系统的程序。由于 C 语言所产生的代码运行速度与汇编语言编写的代码运行速度几乎一样,所以采用 C 语言作为系统开发语言。目前,C 语言是最广泛使用的系统…...

Sora——探索AI视频模型的无限可能
Sora - 探索AI视频模型的无限可能 Sora作为OpenAI发布的一款AI视频模型,其探索的无限可能性表现在多个方面。首先,从技术的角度来看,Sora将文本生成图像的技术扩展到了视频领域,实现了从文字描述到视频内容的自动生成。这种技术突…...
[NCTF2019]True XML cookbook --不会编程的崽
题目的提示很明显了,就是xxe攻击,直接抓包。 <?xml version "1.0"?> <!DOCTYPE ANY [ <!ENTITY xxe SYSTEM "file:///etc/passwd" > ]> <user><username> &xxe; </username><passwor…...

Qt 应用程序中指定使用桌面版本的 OpenGL或嵌入式系统OpenGL ES的 API 进行渲染
qputenv(“QT_OPENGL”, “desktop”) 是用于在 Qt 应用程序中指定使用桌面版本的 OpenGL API 进行渲染。 具体来说,qputenv 是 Qt 提供的一个环境变量设置函数,它允许开发者在程序运行时设置环境变量。在这个例子中,环境变量 QT_OPENGL 被设…...

大数据软件,待补充
数据采集: 实时采集: Debezuim Debezuim是构建在 Apach Kafka之上,并提供Kafka连接器来监视特定的数据库管理(采集多种数据库) Canal canal 是阿里开发,用于实时采集Mysql 当中变化的数据 maxwell,flinkX,flinkCDC 离线采集&#…...

深入探索pdfplumber:从PDF中提取信息到实际项目应用【第94篇—pdfplumbe】
深入探索pdfplumber:从PDF中提取信息到实际项目应用 在数据处理和信息提取的过程中,PDF文档是一种常见的格式。然而,要从PDF中提取信息并进行进一步的分析,我们需要使用适当的工具。本文将介绍如何使用Python库中的pdfplumber库来…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

等压雨幕原理在铝合金窗的应用
等压雨幕原理在铝合金窗的应用 摘要: 针对常见的样窗水密气密不达标,首先概述等压雨幕的作用原理,然后介绍其在铝合金门窗应用中的代表性细节。可以看出,控制框扇搭接处的间隙很重要,以及密封胶条合理设计选用的重要性。而且日系推拉采用等压设计的方式很值得借鉴。 关键…...

技能工程化框架:从标准化定义到编排实战
1. 项目概述:从“技能”到“智能”的工程化桥梁在当今的软件开发领域,尤其是涉及复杂交互和自动化流程的场景,我们常常会听到“技能”这个词。它听起来很抽象,但如果你拆解过任何一款智能助手、自动化机器人或者一个大型的业务流程…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

XHS-Downloader:小红书内容采集与管理的全栈解决方案
XHS-Downloader:小红书内容采集与管理的全栈解决方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

利用OCI免费套餐构建高可用Kubernetes集群实战指南
1. 项目概述:在免费云上构建企业级K8s集群最近在技术社区里,一个名为“nce/oci-free-cloud-k8s”的项目引起了我的注意。这个标题乍一看有点“黑话”的味道,但拆解开来,它指向了一个非常具体且极具吸引力的场景:利用Or…...

JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯
JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否在使用IntelliJ IDEA、PyCharm、WebStorm等JetBrains IDE时遇到过试用期突然结束…...

CircuitPython硬件交互实战:引脚命名、模块管理与内存优化
1. 项目概述:CircuitPython硬件交互的基石 如果你刚开始接触CircuitPython,或者从Arduino转过来,可能会对如何控制板子上的某个引脚感到困惑。板子上明明印着“A0”、“D13”,但在代码里到底该怎么写? board.A0 和 …...