Biomod2 (下):物种分布模型建模
这里写目录标题
- 1.给出一个线性回归模型并求出因子贡献度
- 2.biomod2
- 2.1 pseudo-absences:伪不存在点(PA)
- 2.1.1 random
- 2.2.2 disk
- 2.2.3 user.defined method
- 3.使用网格划分区域
- 3.1 计算质心
- 4. 完整案例
1.给出一个线性回归模型并求出因子贡献度
##-----------------------------------------------------------------------------
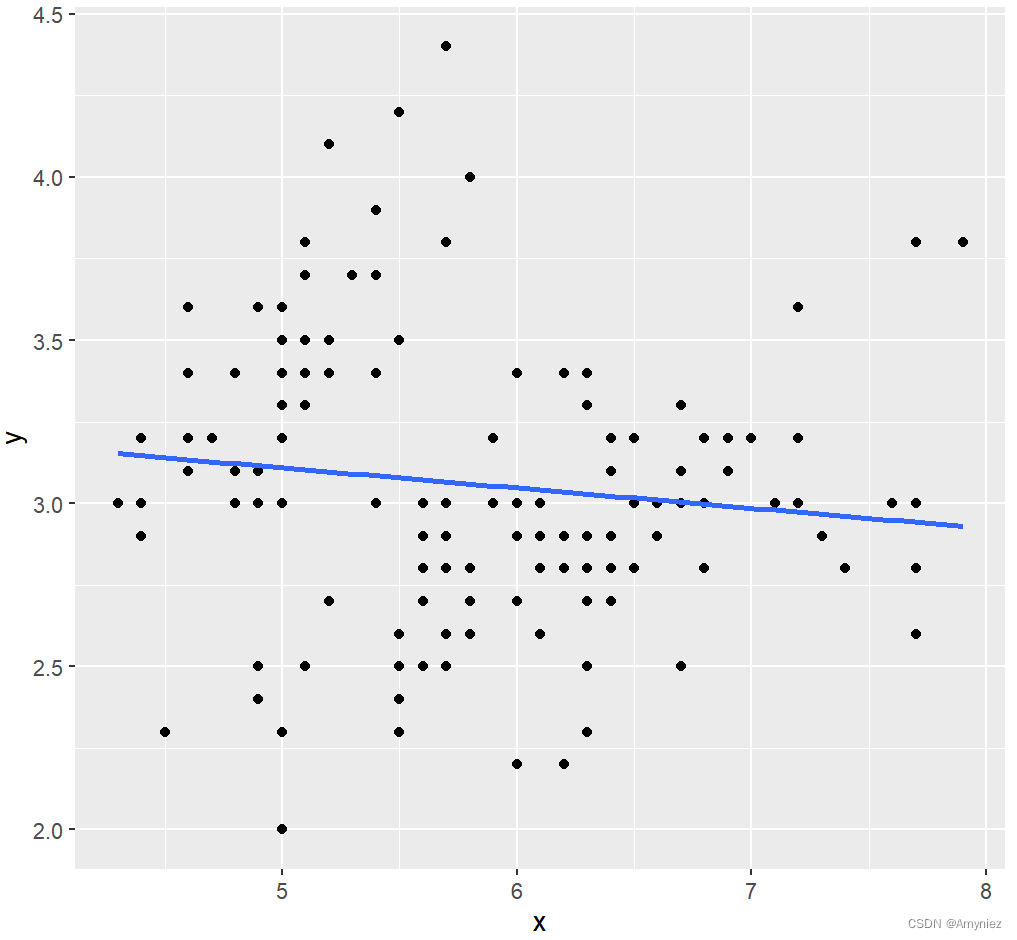
# 线性回归模型
lm_df <- data.frame(x = iris$Sepal.Length,y = iris$Sepal.Width)
lm_model <- lm(data = lm_df,y ~ x)
broom::tidy(lm_model)ggplot(data = lm_df,aes(x,y))+geom_point()+geom_smooth(method = lm, se = FALSE)# 变量重要性
install.packages("vip")
install.packages('mlbench')
library(vip)
set.seed(100)
trn <- as.data.frame(mlbench::mlbench.friedman1(500))
linmod <- lm(y ~ .^2, data = trn)
backward <- step(linmod, direction = "backward", trace = 0)
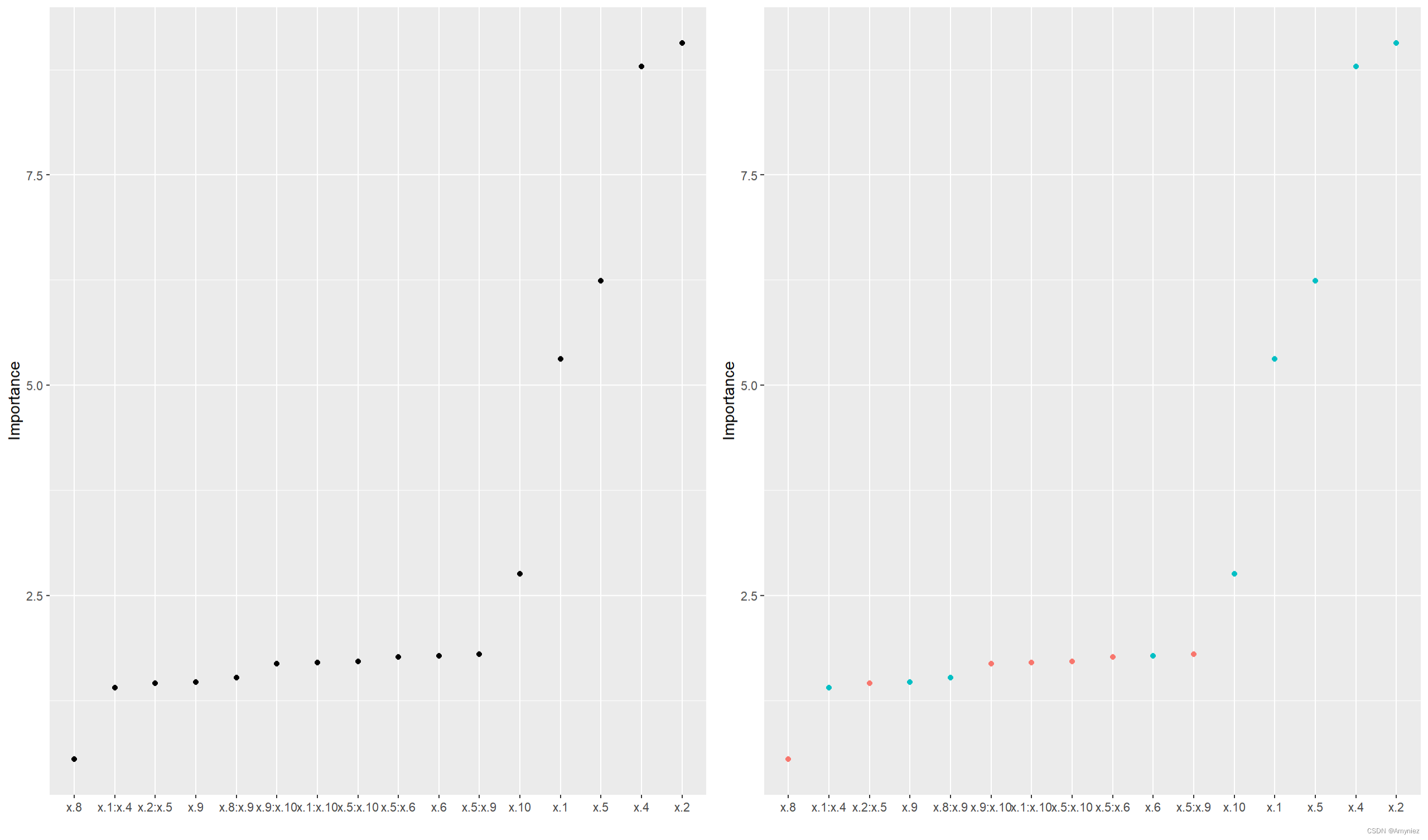
# 计算贡献度
vi(backward)# 可视化
p1 <- vip(backward, num_features = length(coef(backward)), geom = "point", horizontal = FALSE)
p2 <- vip(backward, num_features = length(coef(backward)), geom = "point", horizontal = FALSE, mapping = aes_string(color = "Sign"))
grid.arrange(p1, p2, nrow = 1)
结果展示:

图像绘制:
重要性结果展示:
2.biomod2
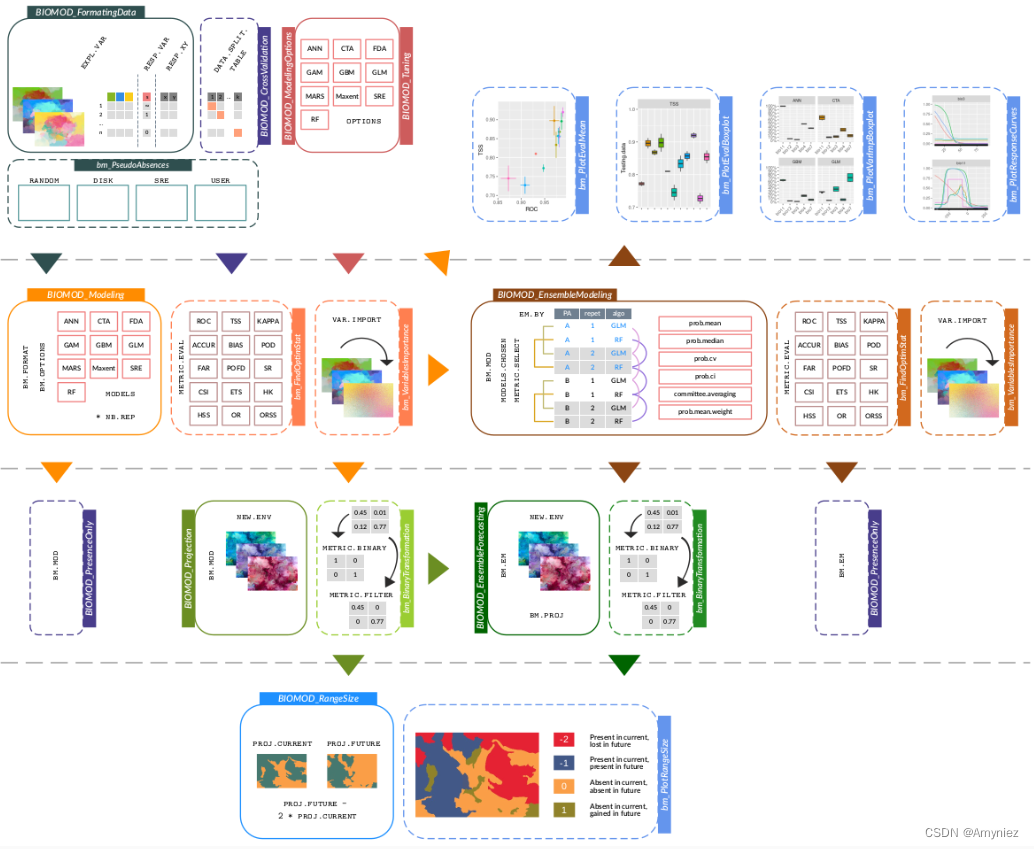
首先需要安装biomod2包:install.packages(“biomod2”)
最终生成的文件为individual_projections,该文件夹中包括.img、.xml两种数据格式,其中包括很多算法如,GLM,RF,SRE,ANN,CTA,FDA,CTA等多种模型 ,这类似于一个集成算法,集合多个模型,求取模型的平均值,以得出一个更好的模型。
##-----------------------------------------------------------------------------
# 加载成都市的适量边界图,后面会用到
library(mapchina)
cd_sf <- mapchina::china %>%dplyr::filter(Name_Perfecture == "成都市") %>%group_by(Name_Province) %>%summarise(geometry = sf::st_union(geometry)) %>%ungroup()
colnames(cd_sf) # see all variable names
plot(cd_sf)#install.packages("biomod2")
library(biomod2) ?biomod2::BIOMOD_FormatingData()
#
2.1 pseudo-absences:伪不存在点(PA)
生成PA点的四种方法:random、disk、sre、user.table
2.1.1 random
随机选择PA点
##--------------------------------------------------------------------------------
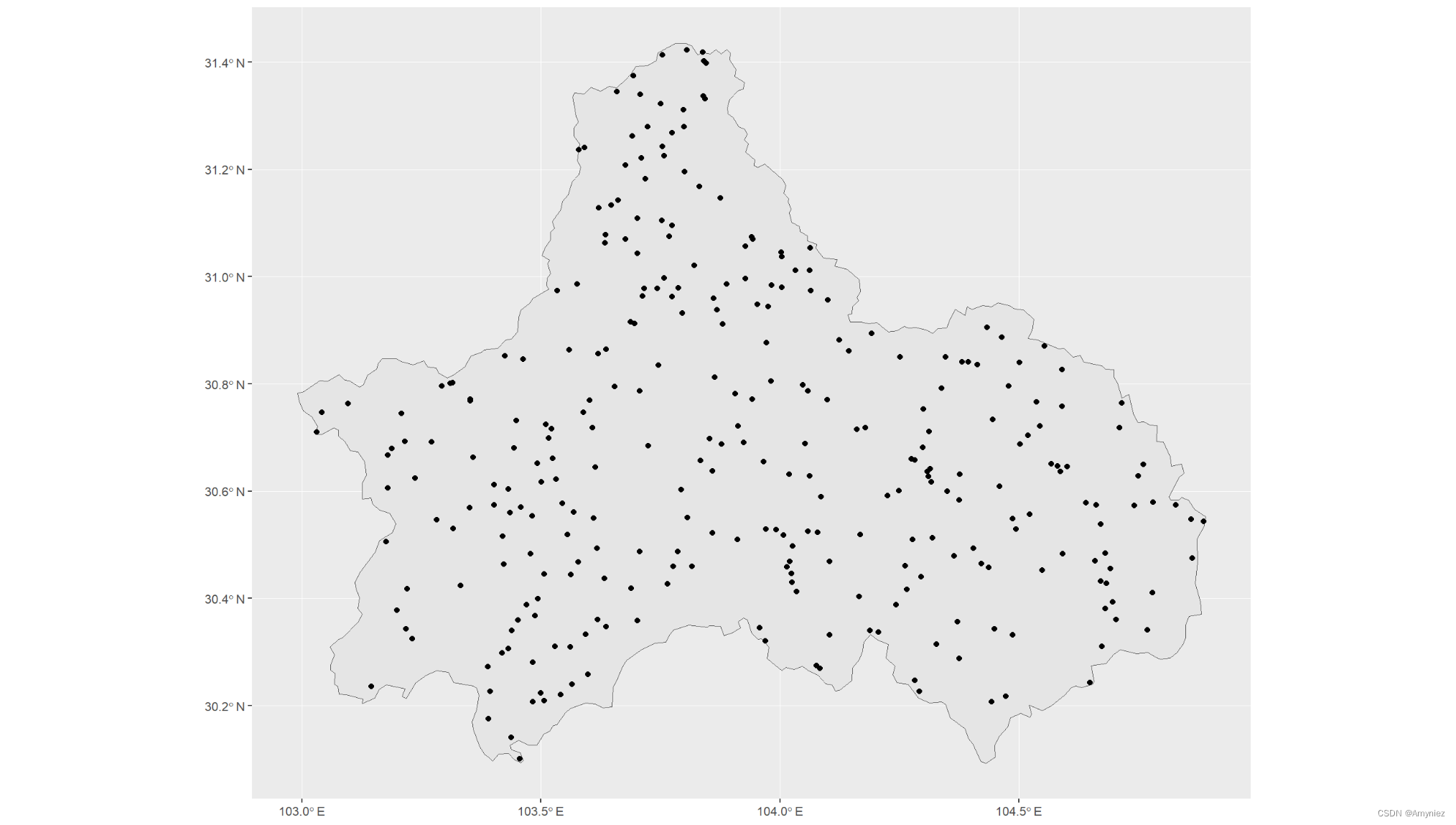
# 1.the random method : PA are randomly selected over the studied area (excluding presence points)
library(sf)
p1_random <- sf::st_sample(cd_sf,300)
ggplot()+geom_sf(data = cd_sf)+geom_sf(data = p1_random)
结果展示:
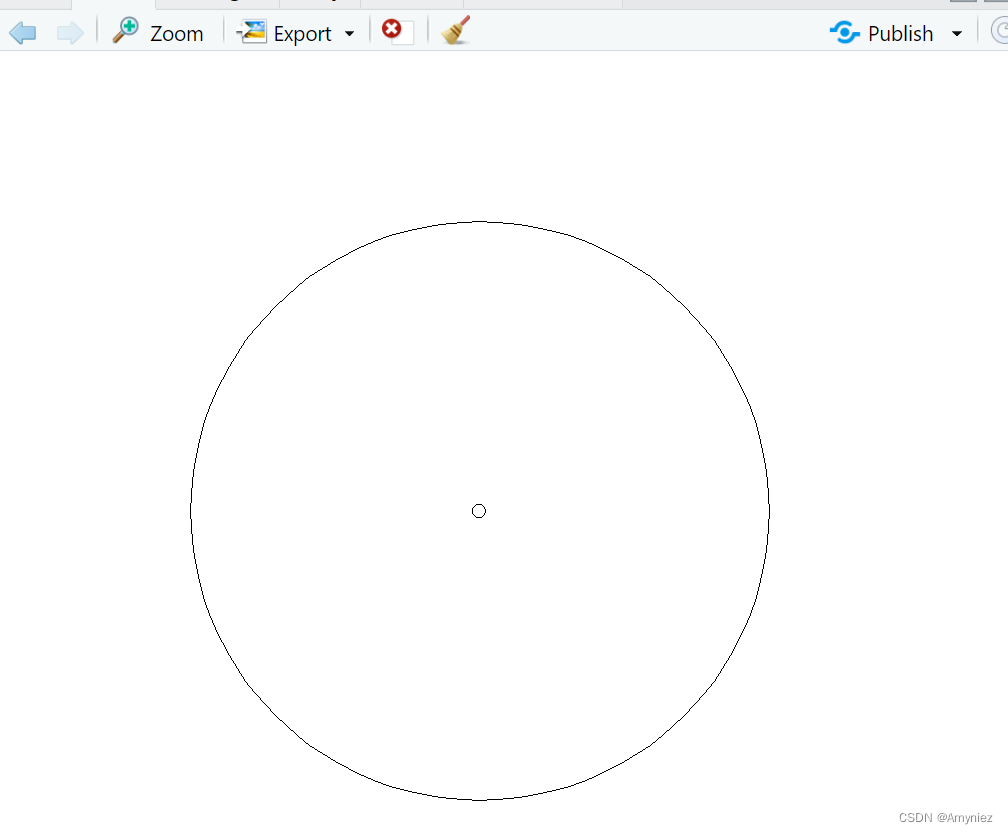
2.2.2 disk
# 2.the disk method : PA are randomly selected within circles around presence
# points defined by a minimum and a maximum distance values (defined in meters).
## Format Data with pseudo-absences : disk method
# myBiomodData.d <- BIOMOD_FormatingData(resp.var = myResp.PA,
# expl.var = myExpl,
# resp.xy = myRespXY,
# resp.name = myRespName,
# PA.nb.rep = 4,
# PA.nb.absences = 500,
# PA.strategy = 'disk',
# PA.dist.min = 5,
# PA.dist.max = 35) # 生成环形缓冲区
pts_presence <- sf::st_sample(cd_sf,300)
pts_presence

#使用生成的第一个点画圆
st_buffer(pts_presence[[1]], dist = 1) %>% plot()
plot(pts_presence[[1]],add = TRUE)
结果展示:
2.2.3 user.defined method
##-------------------------------------------------------------------------------------
#用户自定义
## Format Data with pseudo-absences : user.defined method
# myPAtable <- data.frame(PA1 = ifelse(myResp == 1, TRUE, FALSE),
# PA2 = ifelse(myResp == 1, TRUE, FALSE))
# for (i in 1:ncol(myPAtable)) myPAtable[sample(which(myPAtable[, i] == FALSE), 500), i] = TRUE
# myBiomodData.u <- BIOMOD_FormatingData(resp.var = myResp.PA,
# expl.var = myExpl,
# resp.xy = myRespXY,
# resp.name = myRespName,
# PA.strategy = 'user.defined',
# PA.user.table = myPAtable)
pts_absence <- pts_presence %>% st_as_sf() %>% mutate(id = 1:n()) %>%group_by(id) %>%nest(data = -id) %>% mutate(circle = purrr::map(.x = data,.f = function(x) {st_buffer(x = x,dist = 1)})) %>% mutate(point = purrr::map(.x = circle,.f = function(x) {st_sample(x,1)})) %>% dplyr::select(point) %>% unnest() %>% ungroup() %>% dplyr::select(-id)
pts_absence

格式转换:
# 将生成的点转换为数据框格式
#install.packages('sfheaders')
library(sfheaders)
pts_absence %>% st_as_sf() %>% sfheaders::sf_to_df() %>% dplyr::select(x,y) %>% mutate(label = "absence") %>% head()

3.使用网格划分区域
##----------------------------------------------------------------------------------
# 网格划分,形成栅格图像
cd_grid <- cd_sf %>% st_make_grid(cellsize = 0.2) %>%st_intersection(cd_sf) %>%st_cast("MULTIPOLYGON") %>%st_sf() %>%mutate(cellid = row_number())
plot(cd_grid)
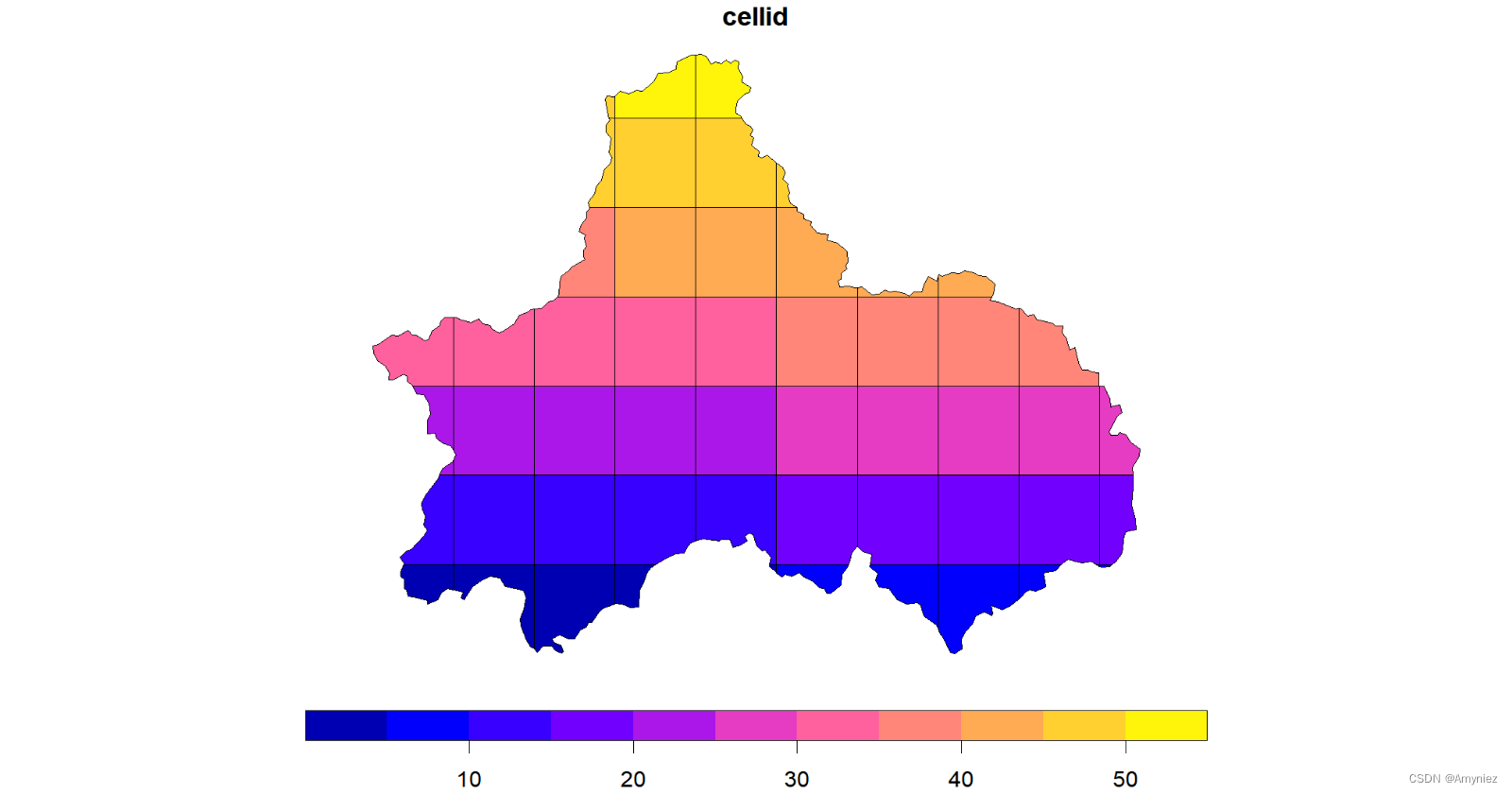
为每个网格添加标签:
#devtools::install_github("yutannihilation/ggsflabel")
ggplot(data = cd_grid)+geom_sf()+ggsflabel::geom_sf_label(aes(label = cellid))+theme_light()
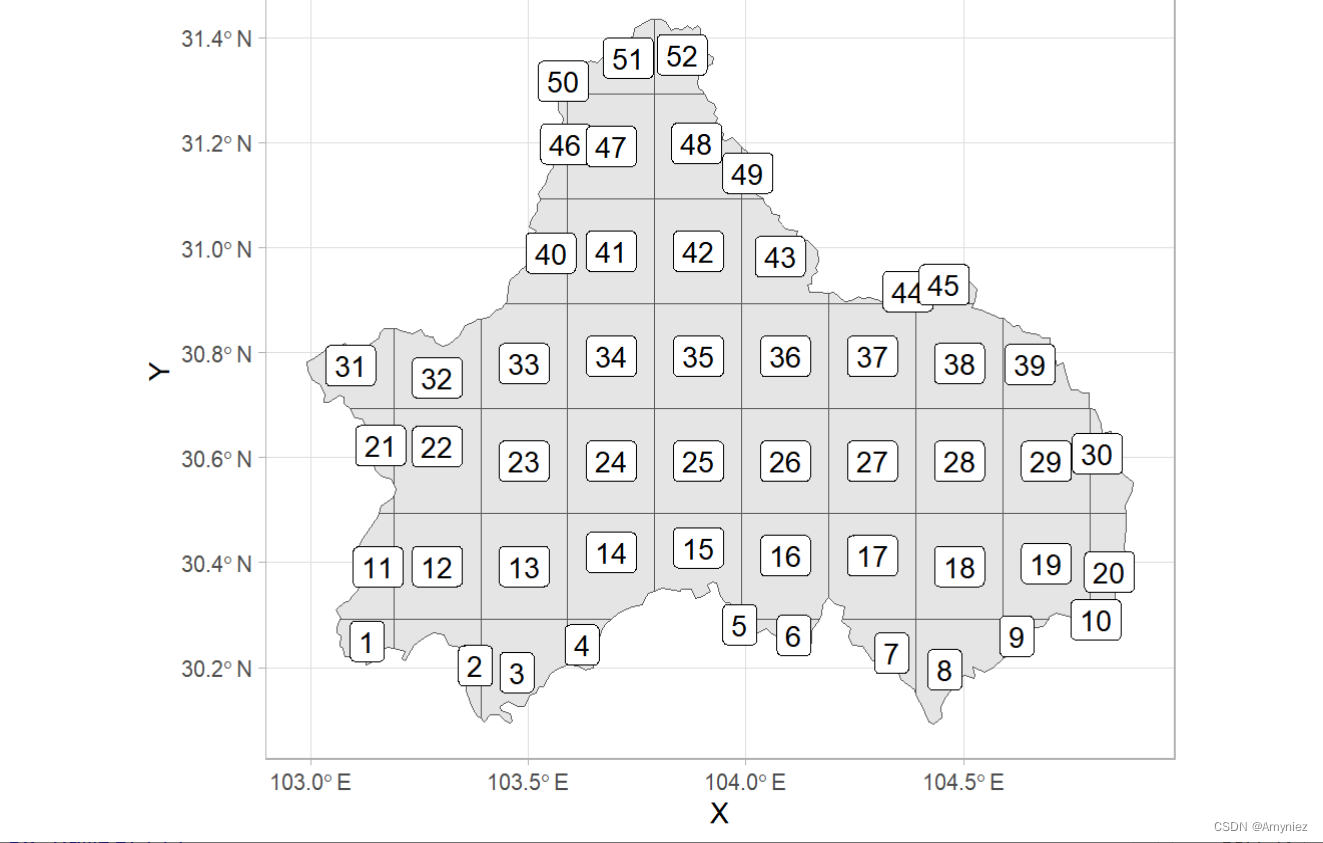
3.1 计算质心
# 计算质心
library(terra)
library(tidyterra)
library(ggplot2)bj_dem <- raster("D:/Datasets/w001001.adf")
plot(bj_dem)(sp_sf <- bj_dem %>% calc(x = .,fun = function(x) ifelse(x < 100,x,NA)) %>% # 按属性筛选rasterToPolygons() %>% st_as_sf() %>% summarise(geometry = st_union(geometry)) %>% st_make_valid())
plot(sp_sf)
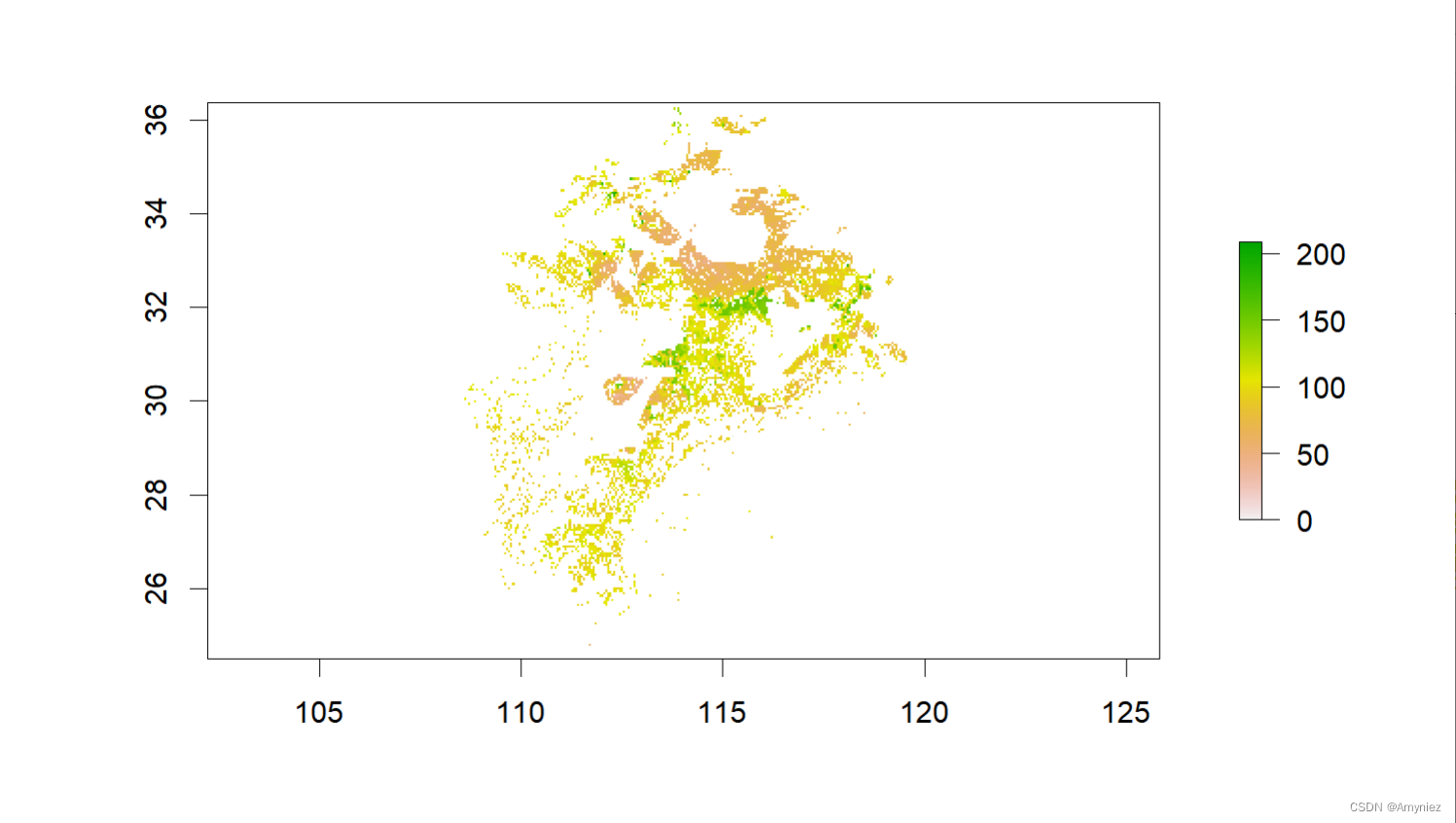

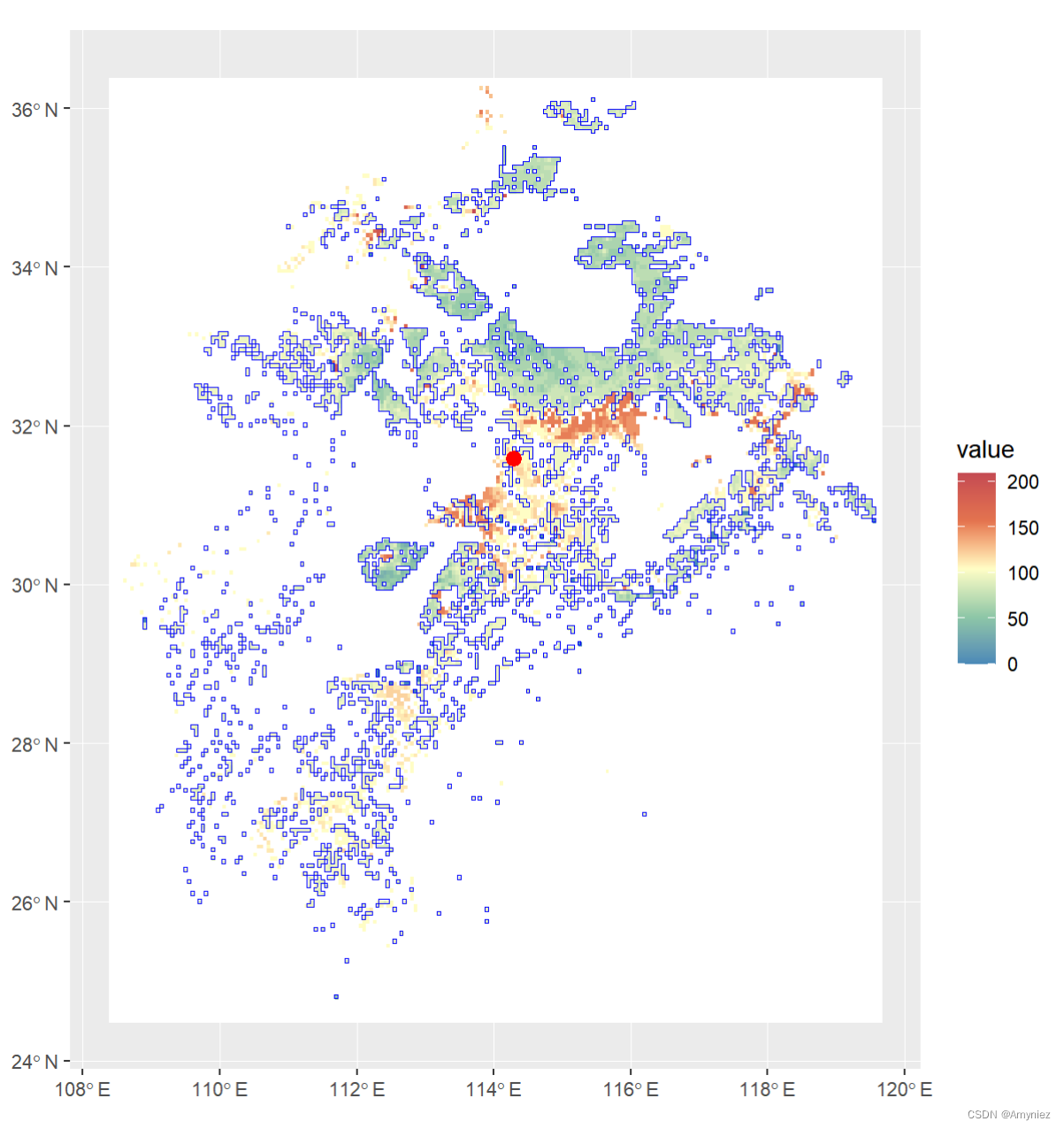
centroid <- st_centroid(sp_sf)ggplot()+geom_spatraster(data = rast(bj_dem)) +scale_fill_whitebox_c(palette = "muted",na.value = "white")+geom_sf(data = sp_sf,alpha = 0,color = "blue")+geom_sf(data = centroid,size = 3,color = "red")
4. 完整案例
# Load species occurrences (6 species available)
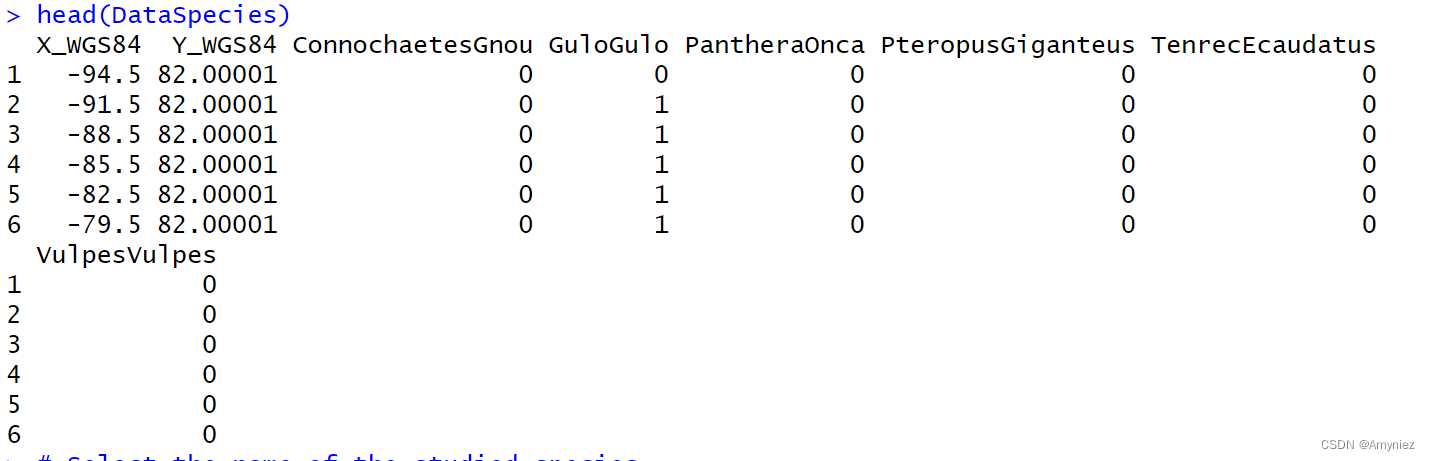
data(DataSpecies)
head(DataSpecies)# Select the name of the studied species
myRespName <- 'GuloGulo'# Get corresponding presence/absence data
myResp <- as.numeric(DataSpecies[, myRespName])# Get corresponding XY coordinates
myRespXY <- DataSpecies[, c('X_WGS84', 'Y_WGS84')]# Load environmental variables extracted from BIOCLIM (bio_3, bio_4, bio_7, bio_11 & bio_12)
data(bioclim_current)
myExpl <- terra::rast(bioclim_current)## --------------------------------------------------------------------------------
# Format Data with true absences
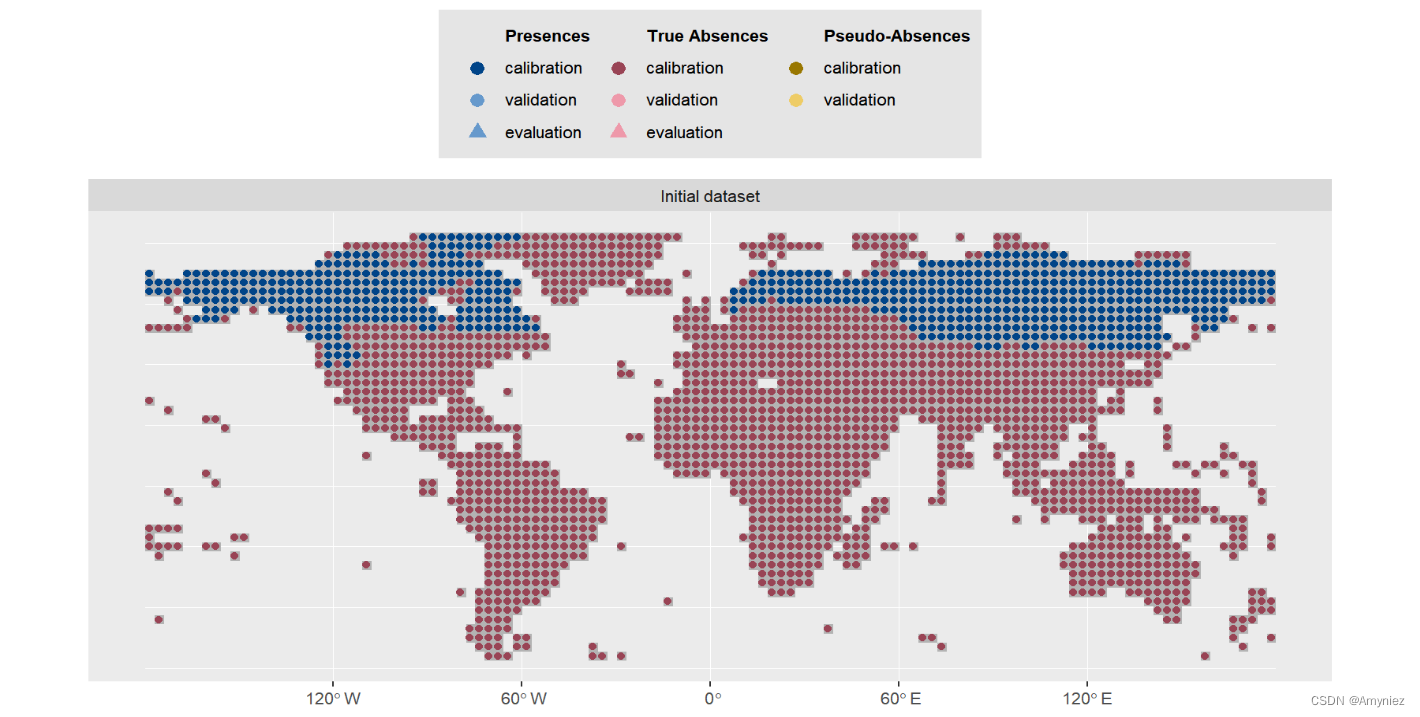
myBiomodData <- BIOMOD_FormatingData(resp.var = myResp,expl.var = myExpl,resp.xy = myRespXY,resp.name = myRespName)
myBiomodData
summary(myBiomodData)
plot(myBiomodData)
物种分布数据:
相关文章:
Biomod2 (下):物种分布模型建模
这里写目录标题1.给出一个线性回归模型并求出因子贡献度2.biomod22.1 pseudo-absences:伪不存在点(PA)2.1.1 random2.2.2 disk2.2.3 user.defined method3.使用网格划分区域3.1 计算质心4. 完整案例1.给出一个线性回归模型并求出因子贡献度 ##---------…...

Linux性能学习(2.2):内存_进程线程内存分配机制探究
文章目录1 进程内存分配探究1.1 代码1.2 试验过程2 线程内存分配探究2.1 代码2.2 试验过程3 总结参考资料:1. 嵌入式软件开发杂谈(3):Linux下内存与虚拟内存2. 嵌入式软件开发杂谈(1):Linux下最…...
BPMN2.0规范及流程引擎选型方案
BPMN2.0规范及流程引擎选型方案一、基本概念二、BPMN意义三、主要元素3.1 活动任务子流程调用活动事件子流程事务3.2 网关排他网关包容网关并行网关事件网关3.3 事件开始事件结束事件中间事件3.4 辅助泳道图注释与组数据存储四、图类型4.1 编排图4.2 会话图五、技术选型5.1 前端…...

VMware虚拟机安装Linux教程
前言 本文小新为大家带来 VMware虚拟机安装Linux教程 ,后边将为大家分享Linux系统的相关知识与操作,在此之前的第一步我们需要在我们的电脑上搭建好一个Linux系统的环境,本文的具体内容包括VMware虚拟机软件安装与Linux系统安装~ 不积跬步&a…...
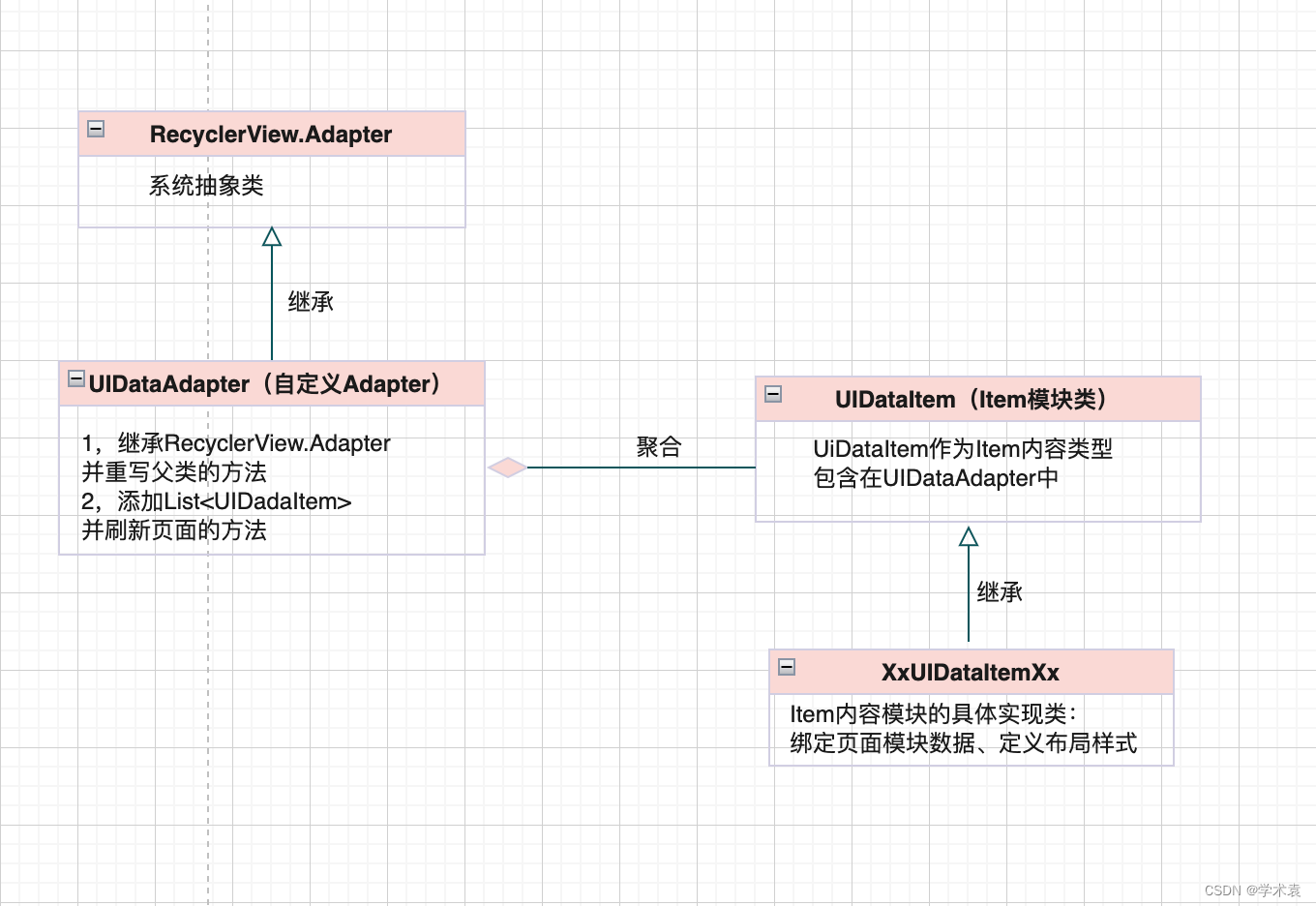
多人协作|RecyclerView列表模块新架构设计
多人协作|RecyclerView列表模块新架构设计多人协作设计图新架构设计与实现设计背景与新需求新架构设计多人协作设计图 根据产品设计,将首页列表即将展示内容区域,以模块划分成多个。令团队开发成员分别承接不同模块进行开发,且互不影响任务开…...
 整合配置文件 @Value、ConfigurationProperties)
SpringBoot (六) 整合配置文件 @Value、ConfigurationProperties
哈喽,大家好,我是有勇气的牛排(全网同名)🐮🐮🐮 有问题的小伙伴欢迎在文末评论,点赞、收藏是对我最大的支持!!!。 1 使用 Value 注解 /** Auth…...
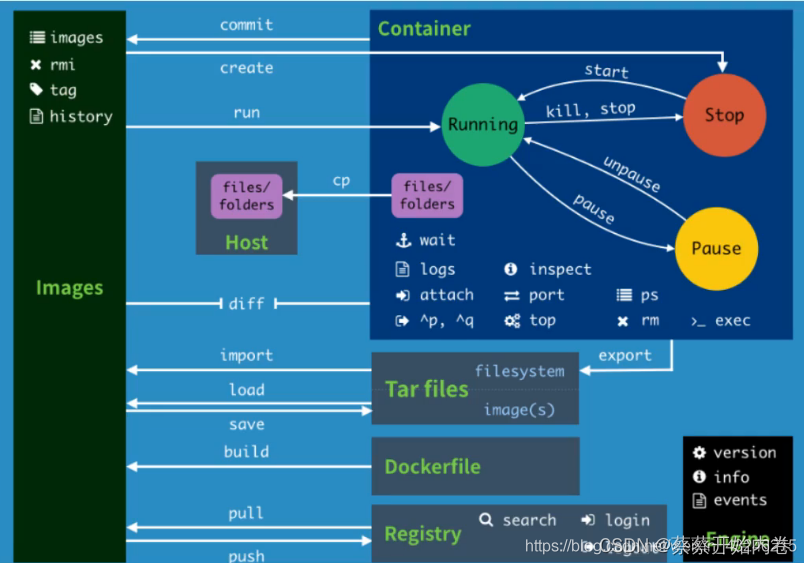
docker 入门篇
docker为什么会出现? 一款产品:开发---->运维,两套环境!应用环境,应用配置! 常见问题:我的电脑可以运行,版本更新,导致服务不可用。 环境配置十分的麻烦,…...

MapReduce的shuffle过程详解
shuffle流程概括 因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到Map节点的“环形内存缓冲区”,在写入的过程中进行分区(partition),也就是对于每个键值对来说&a…...
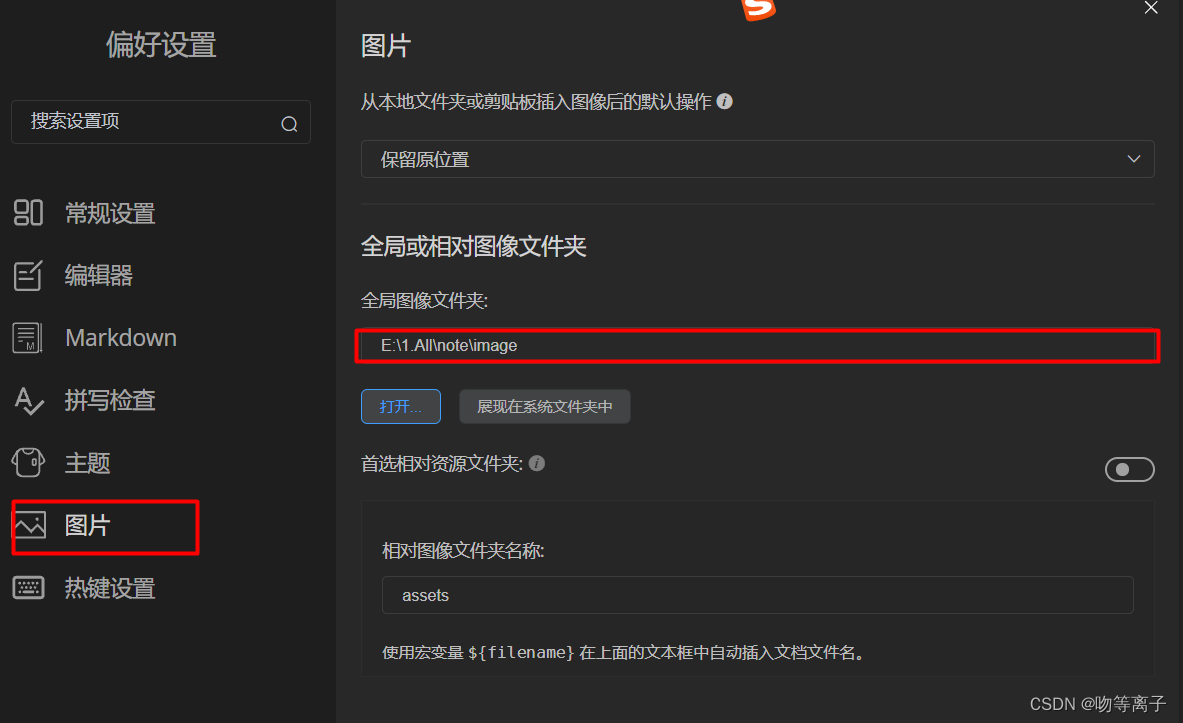
【软件使用】MarkText下载安装与汉化设置 (markdown快捷键收藏)
一、安装与汉化 对版本没要求的可以直接选择 3、免安装的汉化包 1、下载安装MarkText MaxText win64 https://github.com/marktext/marktext/releases/download/v0.17.1/marktext-setup.exe 使用迅雷可以快速下载 2. 配置中文语言包 中文包下载地址:GitHub - chi…...

LeetCode笔记:Biweekly Contest 99
LeetCode笔记:Biweekly Contest 99 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/biweekly-contest-99 1. 题目一…...

初探富文本之CRDT协同实例
初探富文本之CRDT协同实例 在前边初探富文本之CRDT协同算法一文中我们探讨了为什么需要协同、分布式的最终一致性理论、偏序集与半格的概念、为什么需要有偏序关系、如何通过数据结构避免冲突、分布式系统如何进行同步调度等等,这些属于完成协同所需要了解的基础知…...
团队死气沉沉?10种玩法激活你的项目团队拥有超强凝聚力
作为项目经理和PMO,以及管理者最头疼的是团队的氛围和凝聚力,经常会发现团队死气沉沉,默不作声,你想尽办法也不能激活团队,也很难凝聚团队。这样的项目团队你很难带领大家去打胜仗,攻克堡垒。但是如何才能避…...

Spring三级缓存核心思想
spring在启动时候,会创建bean,并给bean填充属性,这事会使用到三级缓存 private final Map<String, Object> singletonObjects new ConcurrentHashMap<>(256); //一级缓存private final Map<String, Object> earlySingleto…...

深度学习算法训练和部署流程介绍--让初学者一篇文章彻底理解算法训练和部署流程
目录 1 什么是深度学习算法 2 算法训练 2.1 训练的原理 2.2 名词解释 3 算法C部署 3.1 嵌入式终端板子部署 3.3.1 tpu npu推理 3.3.2 cpu推理 3.2 服务器部署 3.2.1 智能推理 3.2.2 CPU推理 1 什么是深度学习算法 这里不去写复杂的概念,就用通俗的话说…...
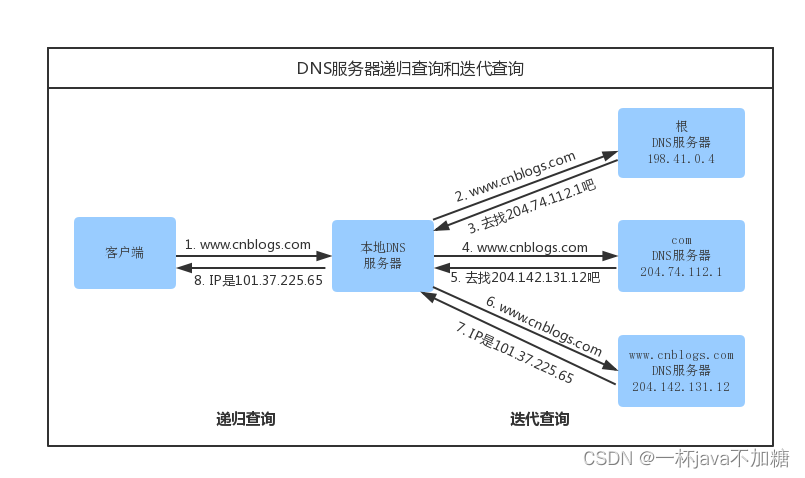
计算机网络整理
TCP与UDP 介绍 HTTP:(HyperText Transport Protocol)是超文本传输协议的缩写,它用于传送WWW方式的数据,关于HTTP协议的详细内容请参考RFC2616。HTTP协议采用了请求/响应模型。 TCP:(Transmission Contro…...
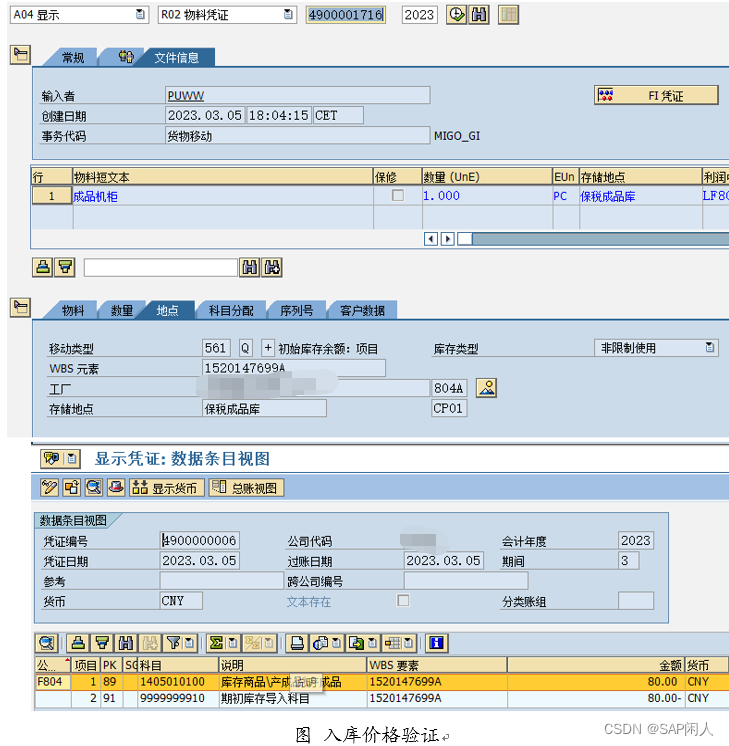
闲人闲谈PS之三十八——混合制生产下WBS-BOM价格发布增强
惯例闲话:最近中《三体》的毒很深,可能是电视剧版确实给闲人这种原著粉带来太多的感动,又一次引发了怀旧的热潮,《我的三体-罗辑传》是每天睡前必刷的视频,结尾BGM太燃了。闲人对其中一句台词感触很深——人类不感谢罗…...

Java 根类 Object
java.lang.Object 是 Java 类层次结构中的根类,所有类都直接或间接实现了此类的方法。 Object API 源码 package java.lang;public class Object {private static native void registerNatives();static {registerNatives();}public final native Class<?>…...

04_Apache Pulsar的可视化监控管理、Apache Pulsar的可视化监控部署
1.4.Apache Pulsar的可视化监控管理 1.4.1.Apache Pulsar的可视化监控部署 1.4.Apache Pulsar的可视化监控管理 1.4.1.Apache Pulsar的可视化监控部署 第一步:下载Pulsar-Manager https://archive.apache.org/dist/pulsar/pulsar-manager/pulsar-manager-0.2.0/…...

【算法】期末复盘,酒店住宿问题——勿向思想僵化前进
文章目录前言题目描述卡在哪里代码(C)前言 省流:一个人也可以住双人间,如果便宜的话。 害!尚正值青春年华,黄金岁月,小脑瓜子就已经不灵光咯。好在我在考试的最后一分钟还是成功通过了这题&am…...
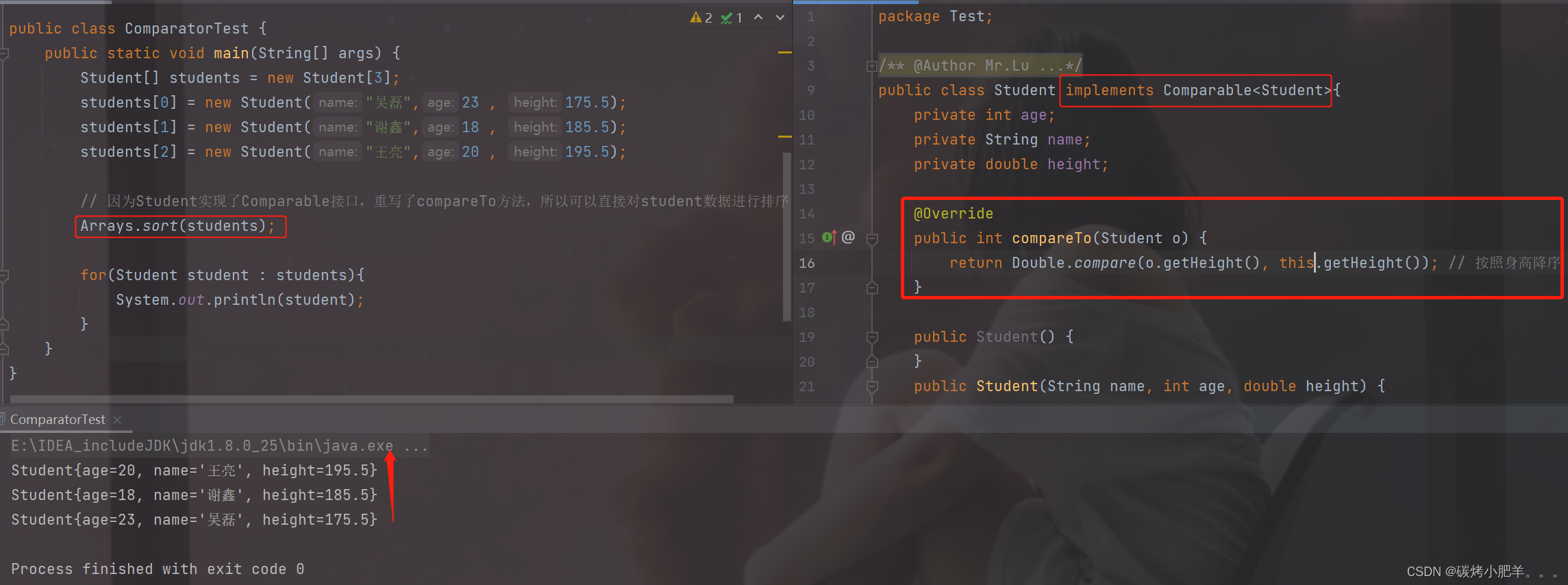
Java中的Comparator 与 Comparable详解
Comparator VS Comparable1. Comparator1.1 对一维数组进行排序1.2 对二维数组进行排序1.3 对对象数组进行排序2. Comparable3. 二者区别1. Comparator 通过源码发现Comparator是一个接口。 根据compare方法中的注释可以发现方法返回三种类型的值,正数、零、负数&a…...

新手零失败指南:基于快马ai详解android studio安装配置与第一个app运行
新手零失败指南:基于快马AI详解Android Studio安装配置与第一个APP运行 作为一个刚接触安卓开发的新手,第一次安装Android Studio时确实容易被各种概念和步骤搞晕。最近我在InsCode(快马)平台上发现他们的AI指导特别适合新手,能一步步拆解复…...

终极指南:3分钟掌握Silk v3音频转换,彻底解决微信QQ语音播放难题
终极指南:3分钟掌握Silk v3音频转换,彻底解决微信QQ语音播放难题 【免费下载链接】silk-v3-decoder [Skype Silk Codec SDK]Decode silk v3 audio files (like wechat amr, aud files, qq slk files) and convert to other format (like mp3). Batch con…...

深度解析Godot资源提取:构建专业级解包方案
深度解析Godot资源提取:构建专业级解包方案 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 在游戏开发与逆向工程领域,Godot资源提取技术已成为开发者探索游戏内部结构的核心…...

wps的VBA小tips1
在WPS/Excel的JS宏(以及VBA)里, Value2 是比 Value 更常用、更可靠的属性,主要有这几个核心原因:1. 避免格式干扰- Value 会受单元格显示格式影响:如果单元格设置了日期、货币、百分比等格式,…...

SOLOv2的‘动态’内核与‘矩阵’NMS:深入代码看它如何比SOLO快3倍
SOLOv2动态内核与矩阵NMS的工程实现奥秘 在计算机视觉领域,实例分割一直是一个极具挑战性的任务,它要求模型不仅要检测出图像中的每个对象,还要精确地描绘出每个对象的轮廓。SOLO系列算法作为这一领域的创新者,从v1到v2的演进中展…...

文本输入组件核心讲解与实战
一、文本输入类组件核心认知(一)组件整体定位TextInput、TextArea、Search是鸿蒙ArkTS核心文本输入类组件,基于统一输入底层能力封装,支持通用样式与高频事件;针对单行短文本、多行长文本、搜索专属三大场景做差异化优…...

AI如何重塑游戏公平性?让每个人都能享受射击乐趣的开源辅助方案
AI如何重塑游戏公平性?让每个人都能享受射击乐趣的开源辅助方案 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai/Aimmy …...

OpenClaw飞书机器人实战:Qwen2.5-VL-7B多模态对话配置
OpenClaw飞书机器人实战:Qwen2.5-VL-7B多模态对话配置 1. 为什么选择OpenClaw飞书Qwen2.5-VL组合 去年我们团队内部沟通量激增,每天在飞书群里有数百条消息需要处理——从产品需求讨论到技术方案评审,再到会议纪要整理。最头疼的是那些包含…...

3步解锁B站直播自由:让创作者轻松掌控推流全过程
3步解锁B站直播自由:让创作者轻松掌控推流全过程 【免费下载链接】bilibili_live_stream_code 用于在准备直播时获取第三方推流码,以便可以绕开哔哩哔哩直播姬,直接在如OBS等软件中进行直播,软件同时提供定义直播分区和标题功能 …...

如何让多设备协作更高效?揭秘QKeyMapper的跨硬件无缝解决方案
如何让多设备协作更高效?揭秘QKeyMapper的跨硬件无缝解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&…...