【数据库系列】MQSQL历史数据分区
互联网行业企业都倾向于mysql数据库,虽说mysql单表能支持亿级别的数据量,加上索引优化下查询速度,勉强能使用,但是对于追求性能和效率的互联网企业,这是远远不够的。Mysql数据库单表数据量到达500万左右,达到性能最佳点,可是对于需要亿级别的业务来说,500万是远远不够的。既然数据放在一个位置不行,那我们就把数据拆分放到多个位置。如果寻找数据位置的时间成本忽略不计的话,那么在亿级别的数据量里面查询数据的时间成本就相当于从单张表力查询数据的时间成本一样。这就是分库分表的最初思想。
对表进行分区,是为了能最大限度的提高数据库的IO能力,分区能让数据库将同一张表中的数据放在不同的磁盘下,提高数据库IO能力,类似多核多线程的思想。因此分区能提高单标的高并发能力。
range分区
range方式创建分区语句如下:
#根据表结构中的时间字段来作为分区键,如下的year()方法,或者to_char()方法create table table_range(id int(11),amt int(11) unsigned not null,created_on datetime)partition by range(year(created_on))(partition p2018 values less than (2018),partition p2019 values less than (2019),partition p2020 values less than (2020)partition pdefault values less than maxvalue #MAXVALUE 表示最大的可能的整数值);#或者使用id作为范围分区create table table_range(id int(11),amt int(11) unsigned not null,created_on datetime)partition by range(id)(partition p10000 values less than (10000),partition p20000 values less than (20000),partition p30000 values less than (30000)partition pdefault values less than maxvalue #MAXVALUE 表示最大的可能的整数值);范围分区
所有范围区间不能重叠。
查询条件里包括分区键,免全表扫描,分区表查询都应该注意这个。
分区键一般是时间或是唯一的索引值,一般都会在每条数据上计算并保存分区字段。
实例
假如我们现在有一张大表需要做分区:
过程应该如下建新表–>备份–>停机-》删原表–>改名〉恢复
CREATE TABLE `t_send_message_send2` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`plan_id` bigint(20) DEFAULT NULL,`job_uuid` varchar(36) DEFAULT NULL,`send_port` varchar(16) DEFAULT NULL,`mobile` varchar(16) DEFAULT NULL,`content` varchar(200) DEFAULT NULL,`product_code` varchar(16) DEFAULT 'HELP',`fake` bit(1) DEFAULT b'0',`date_push` datetime NOT NULL,`activity_id` bigint(20) DEFAULT '0',PRIMARY KEY (`id`,`date_push`),KEY `mobile` (`mobile`),KEY `date_push` (`date_push`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE COLUMNS(date_push)
(PARTITION p2016 VALUES LESS THAN ('2017-01-01') ENGINE = InnoDB,PARTITION p2017 VALUES LESS THAN ('2018-01-01') ENGINE = InnoDB,PARTITION p2018 VALUES LESS THAN ('2019-01-01') ENGINE = InnoDB,PARTITION p2019 VALUES LESS THAN ('2020-01-01') ENGINE = InnoDB,PARTITION p2020 VALUES LESS THAN ('2021-01-01') ENGINE = InnoDB);②备份
备份的方式有两类:
a、在线备份
数据一直在数据库中不离线。(最好的方式是把备库拉出来做,做分区。再做主备切换)
insert into t_send_message_send2 (select * from t_send_message_send);b、离线备份
数据先导出到本地,再从本地导回数据库。这种需要先停机,时间较长
③删原表
drop table t_send_message_send;注意:删原表前一定要确认数据备份完成,且完整。
后面再做增量同步,保证数据不丢失。
rename table t_send_message_send to t_send_message_send_bak;④改名
rename table t_send_message_send2 to t_send_message_send;附:
1、查询表分区情况
select partition_name part,partition_expression expr,partition_description descr,table_rows from information_schema.partitions where table_schema = schema() and table_name='t_send_message_send';
1
2、查询表分区数据
select * from t_send_message_send partition(p2020);
mysql分区表对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成。
实现分区的代码实际上是对一组底层表的句柄对象的封装。mysql在创建表时使用PARTITIONBY子句定义每个分区存放的数据。
在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询就无须扫描所有分区——只需要查询包含需要数据的分区就可以了。
分区的一个主要目的是将数据按照一个较粗的粒度分在不同的表中,这样做可以将相关的数据放在一起,另外,如果想一次批量删除整个分区的数据也会变得很方便。
a),mysql 的分表是真正的分表,一张表分成很多表后,
每一个小表都是完正的一张表,都对应三个文件, 一个.MYD 数据文件,.MYI 索引文件,.frm 表结构文件。
在下面的场景中,分区可以起到非常大的作用:
1.表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他均是历史数据。
2.分区表的数据更容易维护。例如想批量删除大量数据可以使用清除整个分区的方式。另外,还可以对一个独立分区进行优化、检查、修复等操作。
3.分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。
4.可以使用分区表来避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问,ext3文件系统的inode锁竞争等。
5.如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果非常好。
分区表本身也有一些限制,下面是其中比较重要的几点:
1.一个表最多只能有1024个分区。
2.在mysql5.1中,分区表达式必须是整数,或者是返回整数的表达式。在mysql5.5中,某些场景中可以直接使用列进行分区。
3.如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来。
4.分区表中无法使用外键约束。
分区表上的操作按照下面的操作逻辑进行:
select查询
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据。
insert操作
当写入一条记录时,分区层先打开并锁住所有的底层表,然后确定哪个分区接收这条记录,再将记录写入对应底层表。
delete操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作。
update操作
当更新一条记录时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据在哪个分区,最后对底层进行写入操作,并对原数据所在的底层表进行删除操作。
虽然每个操作都有“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的。如果存储引擎能够自己实现行级锁,例如innoDb,则会在分区层释放对应表锁。这个加锁和解锁过程与普通InnoDB上的查询类似。
mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,
一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,
在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。
如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去
reate table employees (
id int not null primary key,
first_name varchar(30),
last_name varchar(30))
partition by range(id)(
partition p0 values less than (11),
partition p1 values less than (21),
partition p2 values less than (31),
partition p3 values less than (41)
);
insert into employees values(1,'Vincent','Chen');
insert into employees values(6,'Victor','Chen');
insert into employees values(11,'Grace','Li');
insert into employees values(16,'San','Zhang');2)explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。

查询到这条数据,是从p1里面找到的。

找不到,所以不是从哪个分区找到的。

查询条件不是分区建立的条件,所以走所有分区。
我们增加分区条件id

阿里不建议分区,而是分表:
因此,如果要使用分区表,就不要创建太多分区。我见过一个用户做了按天分区策略,然后预先创建了10年的分区。这种情况下,访问分区表的性能自然是不好的。这里有两个问题:
分区并不是越细越好 单表或单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都已是小表
分区不要提前预留太多,在使用之前预先创建即可 比如,如果是按月分区,每年年底时再把下一年度的12个新分区创建上即可。对于没有数据的历史分区,及时drop
分区表的其他问题,比如查询需要跨多个分区取数据,查询性能就会比较慢,基本上就不是分区表本身的问题,而是数据量或说使用方式问题。 如果你的团队已经维护了成熟的分库分表中间件,用业务分表,对业务开发同学没有额外的复杂性,对DBA也更直观,自然更好。
相关文章:
【数据库系列】MQSQL历史数据分区
互联网行业企业都倾向于mysql数据库,虽说mysql单表能支持亿级别的数据量,加上索引优化下查询速度,勉强能使用,但是对于追求性能和效率的互联网企业,这是远远不够的。Mysql数据库单表数据量到达500万左右,达…...

MyBatis常用的俩种分页方式
1、使用 limit 实现分页 select * from xxx limit m,n # m 表示从第几条数据开始,默认从0开始 # n 表示查询几条数据 select * from xxx limit 2,3 # 从索引为2的数据开始,往后查询三个。2、3、4 (1) 创建分页对象,用来封装分页的数据 PS…...
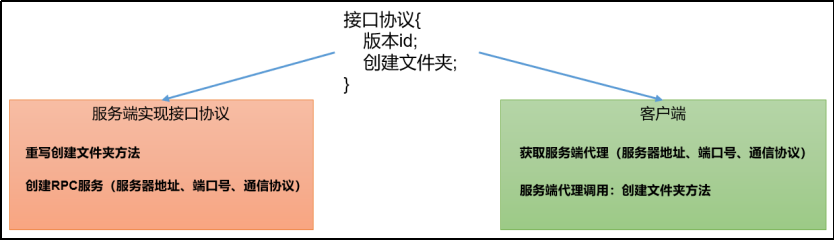
RPC通信原理解析
一、什么是RPC框架? RPC,全称为Remote Procedure Call,即远程过程调用,是一种计算机通信协议。 比如现在有两台机器:A机器和B机器,并且分别部署了应用A和应用B。假设此时位于A机器上的A应用想要调用位于B机…...

【蓝桥杯集训·周赛】AcWing 第93场周赛
文章目录第一题 AcWing 4867. 整除数一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解第二题 AcWing 4868. 数字替换一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解第三题 AcWing 4869. 异或值一、题目1、原题…...
蓝桥杯-刷题统计
蓝桥杯-刷题统计1、问题描述2、解题思路3、代码实现3.1 方案一:累加方法(超时)3.2 方案二1、问题描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a 道题目, 周六和周日每天做 b 道题目。请你帮小明计算, 按照计划他将在 第几天实现做题数…...

Linux入门教程||Linux Shell 变量|| Shell 传递参数
Shell 变量 定义变量时,变量名不加美元符号($,PHP语言中变量需要),如: your_name"w3cschool.cn"注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一…...
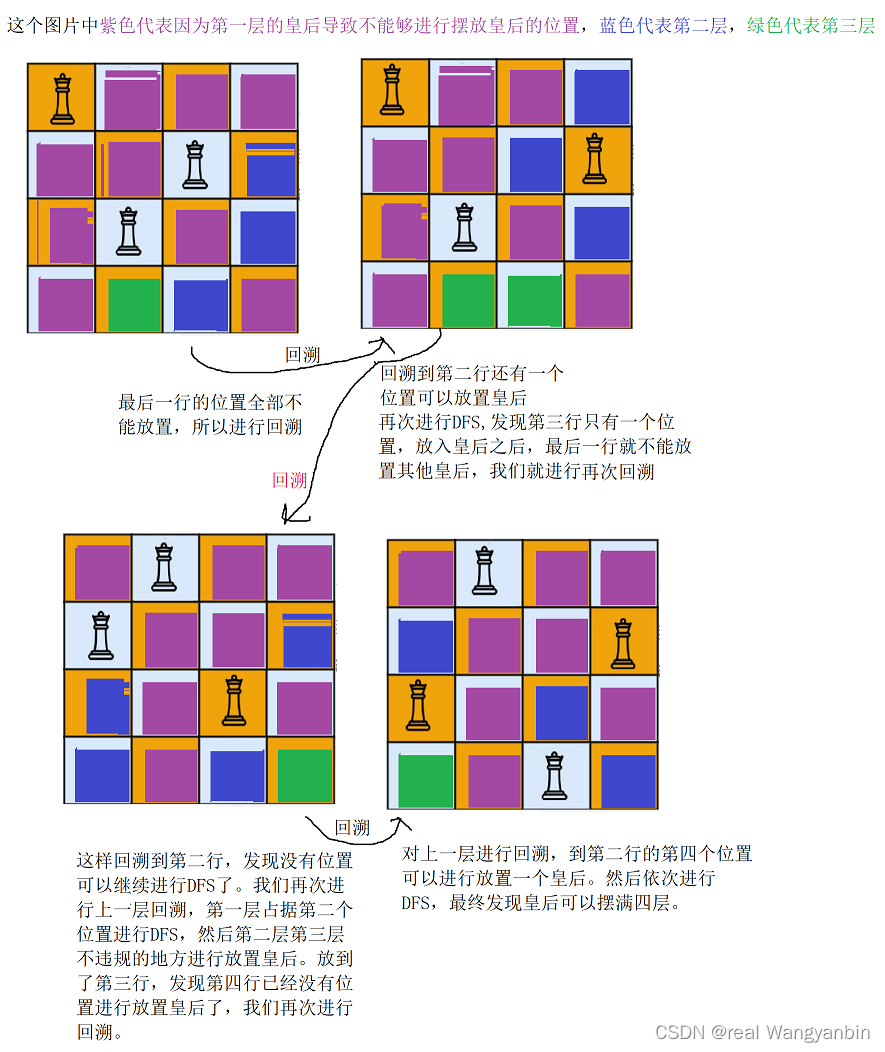
[算法和数据结构]--回溯算法之DFS初识
回溯算法——DFSDFS介绍(Depth First Search)DFS经典题目1. 员工的重要性2. 图像渲染3.被围绕的区域4.岛屿数量5. 电话号码的字母组合6.数字组合7. 活字印刷8. N皇后DFS介绍(Depth First Search) 回溯法(back tracking)(探索与回溯法&#x…...
【LeetCode每日一题】——680.验证回文串 II
文章目录一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【解题思路】七【题目提示】八【时间频度】九【代码实现】十【提交结果】一【题目类别】 贪心算法 二【题目难度】 简单 三【题目编号】 680.验证回文串 II 四【题目描述】 给你一个字…...

【C语言进阶:指针的进阶】你真分得清sizeof和strlen?
本章重点内容: 字符指针指针数组数组指针数组传参和指针传参函数指针函数指针数组指向函数指针数组的指针回调函数指针和数组面试题的解析这篇博客 FLASH 将带大家一起来练习一些容易让人凌乱的题目,通过这些题目来进一步加深和巩固对数组,指…...
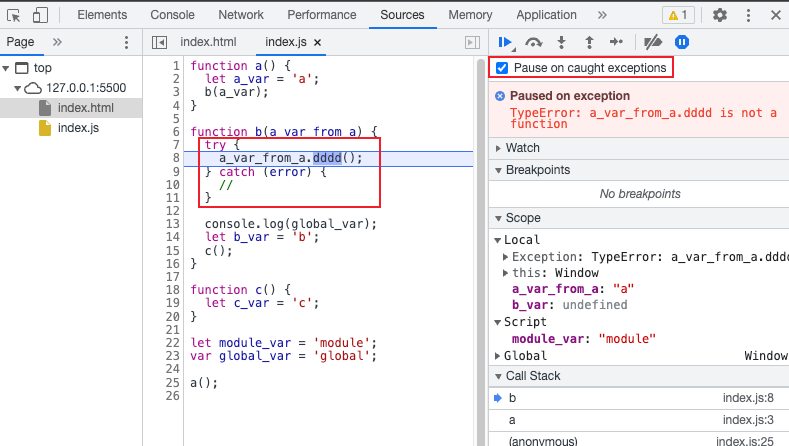
【前端必看】极大提高开发效率的网页 JS 调试技巧
大家好,我是前端西瓜哥。本文讲解如何使用浏览器提供的工具进行 JS 代码的断点调试。 debugger 在代码中需要打断点的地方,加上 debugger,表示一个断点。浏览器代码执行到该位置时,会停下来,进入调试模式。 示例代码…...

【春招面经】视源股份前端一面
前言 本次主要记录一下视源股份CVTE前端一面 (3.3下午4点15) 文章目录前言本次主要记录一下视源股份CVTE前端一面 (3.3下午4点15)问题总结介绍一下项目的来源以及做这个项目的初衷一直监听滚动,有没有对性能产生影响&a…...
插件化开发入门
一、背景顾名思义,插件化开发就是将某个功能代码封装为一个插件模块,通过插件中心的配置来下载、激活、禁用、或者卸载,主程序无需再次重启即可获取新的功能,从而实现快速集成。当然,实现这样的效果,必须遵…...

tftp、nfs 服务器环境搭建
目录 一、认识 tftp、nfs 1、什么是 tftp? 2、什么是 nfs? 3、tftp 和 nfs 的区别 二、tftp的安装 1、安装 tftp 服务端 2、配置 tftp 3、启动 tftp 服务 三、nfs 的安装 1、安装 nfs 服务端 2、配置 nfs 3、启动 nfs 服务 一、认识 tftp、…...
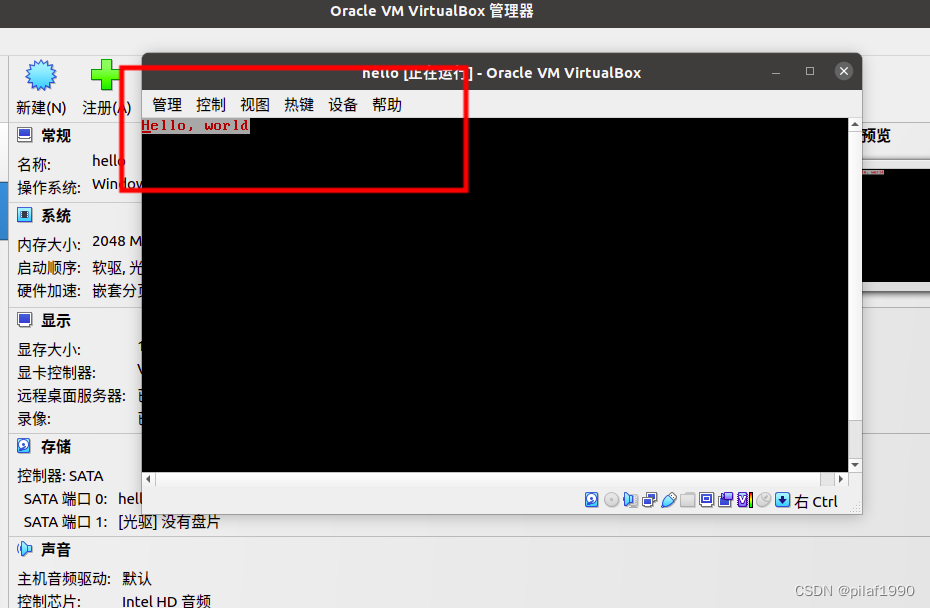
汇编系列03-不借助操作系统输出Hello World
每天进步一点点,加油! 上一节,我们通过汇编指令,借助操作系统的系统调用实现了向标准输出打印Hello world。这一节我们打算绕过操作系统,直接在显示屏幕上打印Hello world。 计算机的启动过程 当我们给计算机加电启…...

TPU编程竞赛系列|算能赛道冠军SO-FAST团队获第十届CCF BDCI总决赛特等奖!
近日,第十届中国计算机学会(CCF)大数据与计算智能大赛总决赛暨颁奖典礼在苏州顺利落幕,算能赛道的冠军队伍SO-FAST从2万余支队伍中脱颖而出,获得了所有赛道综合评比特等奖! 本届CCF大赛吸引了来自全国的2万…...
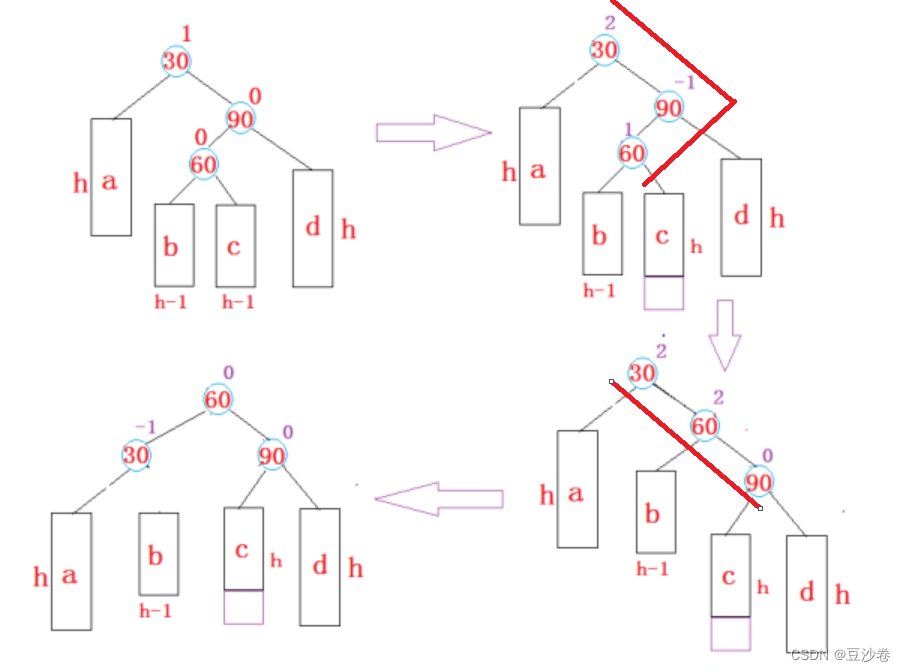
【C++】AVL树,平衡二叉树详细解析
文章目录前言1.AVL树的概念2.AVL树节点的定义3.AVL树的插入4.AVL树的旋转左单旋右单旋左右双旋右左双旋AVL树的验证AVL树的删除AVL树的性能前言 前面对map/multimap/set/multiset进行了简单的介绍,在其文档介绍中发现,这几个容器有个共同点是࿱…...
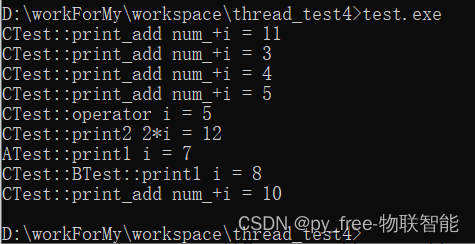
C/C++开发,无可避免的多线程(篇四).线程与函数的奇妙碰撞
一、函数、函数指针及函数对象 1.1 函数 函数(function)是把一个语句序列(函数体, function body)关联到一个名字和零或更多个函数形参(function parameter)的列表的 C 实体,可以通过返回或者抛…...

elisp简单实例: taglist
从vim 转到emacs 下,一直为缺少vim 中的tablist 插件而感到失落. 从网上得到的一个emacs中的taglist, 它的功能很简陋,而且没有任何说明, 把它做为elisp的简单实例,供初学者入门倒不错,我给它加了很多注释,帮助理解, 说实话,感觉这百行代码还是挺有深度的,慢慢体会,调试才会有收…...
-认知服务(3))
Azure AI基础到实战(C#2022)-认知服务(3)
目录 OpenFileDialog 类上一节代码的API剖析ComputerVisionClientExtensions.ReadAsync MethodReadHeaders ClassReadHeaders.OperationLocation Property探索ReadHeaders加上调试代码可用于 Azure 认知服务的身份验证标头使用单服务订阅密钥进行身份验证使用多服务订阅密钥进行…...
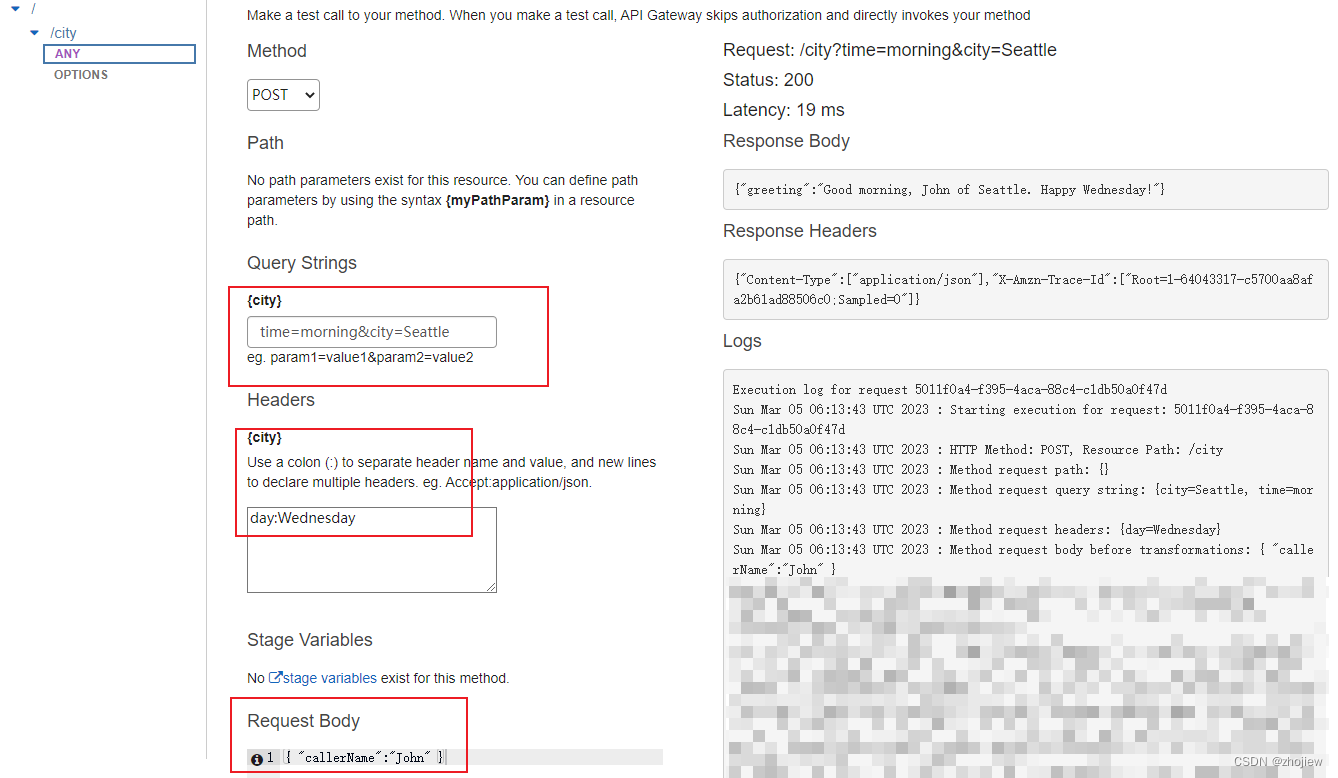
aws apigateway 使用restapi集成lambda
参考资料 代理集成,https://docs.aws.amazon.com/zh_cn/apigateway/latest/developerguide/api-gateway-create-api-as-simple-proxy-for-lambda.html非代理集成,https://docs.aws.amazon.com/zh_cn/apigateway/latest/developerguide/getting-started-…...

电-热-气综合能源系统协同优化Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...

利用快马平台快速生成基于jdk17的spring boot应用原型
最近在尝试用JDK17搭建一个Spring Boot项目原型时,发现从环境配置到基础代码编写要花不少时间。正好试用了InsCode(快马)平台,发现它能快速生成可运行的项目骨架,特别适合需要快速验证想法的场景。这里记录下具体操作和体验: 项目…...

【MicroPython编程-ESP32篇:设备驱动】-PCF8591数据采集驱动
PCF8591数据采集驱动 文章目录 PCF8591数据采集驱动 1、PCF8591介绍 2、软件准备 3、硬件准备与接线 4、程序实现 4.1 PCF8591驱动实现 4.2 主程序 1、PCF8591介绍 PCF8591 是一款单片集成、独立电源、低功耗、8 位 CMOS 数据采集设备。 PCF8591 具有四个模拟输入、一个模拟输…...

用PyQt5打造GUI应用:PyCharm中QtDesigner和PyUic的高效工作流配置
PyCharm专业版中PyQt5高效开发:QtDesigner与PyUic深度整合指南 在Python GUI开发领域,PyQt5凭借其强大的功能和跨平台特性,已成为众多开发者的首选工具。然而,许多中级开发者在实际项目中常遇到工作流断裂的问题——设计界面与代码…...

Honey Select 2本地化增强补丁:技术实现与模块化架构深度解析
Honey Select 2本地化增强补丁:技术实现与模块化架构深度解析 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch作为Honey Select 2游戏社…...

让旧款Mac重获新生:OpenCore Legacy Patcher完整指南
让旧款Mac重获新生:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果官方抛弃的旧款Mac&#…...

如何快速解决腾讯游戏卡顿问题:ACE-Guard资源限制器完整指南
如何快速解决腾讯游戏卡顿问题:ACE-Guard资源限制器完整指南 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩腾讯游戏时遇到过电脑…...

突破网盘下载限制:八大平台直链获取的高效方案
突破网盘下载限制:八大平台直链获取的高效方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

AI时代下的AOSP构建:从“效率黑洞”到“分钟级交付”,企业级构建如何破局?
近年来,AI模型训练与大型软件构建的复杂度持续攀升,企业级操作系统的多分支、多产品构建正成为工程团队的“效率黑洞”。在 Android 平台,AOSP 构建尤为突出:全量构建耗时长、增量改动触发大规模重建、CI 队列冗长、资源消耗高等问…...
)
冥想第一千八百三十八天(1838)
1.周四,4.2号,今天项目上特别忙,下班后带着溪溪桐桐一起去锦和公园的大土坡上玩了一圈。 2.感谢父母,感谢朋友,感谢家人,感谢不断进步的自己。...