[Pytorch]DataSet和DataLoader逐句详解
将自己的数据集引入Pytorch是搭建属于自己的神经网络的重要一步,这里我设计了一个简单的实验,结合这个实验代码,我将逐句教会大家如何将数据引入DataLoader。
这里以目标检测为例,一个batch中包含图片文件、先验框的框体坐标、目标类型,相对而言更加全面。大家亦可根据自己的数据结构和需求进行修改。
一、数据文件分析
标准的Voc格式是无法直接注入模型的,而如果在训练程序中进行处理即拖慢了运算速度,又难以保证数据集分割的一致性。最好是使用一个独立程序完成数据集的分割、组织、暂存。这里参考了Bubbliiiing的做法,将数据集信息暂存为txt文件。其中一条具体数据的格式如下:
../VOC2007/JPEGImages/0.jpg 166,121,336,323,0 1052,372,1371,924,1
# 文件路径(绝对路径为佳)/ # 先验框框体信息1/ # 先验框框体信息1/文件路径和框体信息之间采用空格分开;框体信息内部以逗号分开,前4个为坐标信息,最后一个为分类信息。
在随后的程序中,我们将循环读取这个文件中的数据来获取数据集信息。
二、载入数据
1.定义DataSet超参
在开始重写DataSet前,我们需要定义一些用来控制DataSet的参数。
#----自定义DataSet,继承自torch.utils.data.DataSet
class MyDataSet(Dataset):#----参数定义,输入的参数分别为数据行、输入图像尺寸,类型数def __init__(self,file_Lines,inp_Shape,num_Classes):super(MyDataSet,self).__init__()# 将局部形参变为类内的全局变量self.length = len(file_Lines) #将文件数赋值给lengthself.file_Lines = file_Linesself.inp_Shape = inp_Shapeself.num_Classes = num_Classes2.重写len函数
没什么技巧,因为我们刚刚将数据行(file_Lines)的长度赋值给了self.length,直接返回这个值就能拿到数据集的长度了。这也是设置超参数的意义所在。
def __len__(self):return self.length3.重写getitem函数
此函数每次会获取单个文件,DataLoader通过反复调用这个函数最终获取整个数据集,我们写入的,这个函数自带一个index用于控制获取的行数。
①分解数据集文件
按照我们上面解析的文件格式,我们用split函数分割index行的文本(空格分割),得到的file_item中第1个元素为文件的绝对路径,后续元素为目标先验框的信息。
def __getitem__(self, index):index = index % self.length #计算batch长度file_item = self.file_Lines[index].split() #按空格拆分文件行,其中的元素分别为:文件路径、先验框坐标(n个)file_item的值如下图所示:
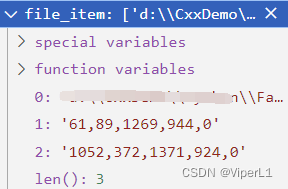
②加载图片文件
同样没什么技巧,拿到文件路径后直接打开就好了。需要注意的是神经网络的输入需要为固定的形状(图片尺寸和颜色通道数),如果图片为灰阶图则需要将其颜色通道扩充为3个(RGB图)
img = Image.open(file_item[0]) #打开图片img = cvt2RGB(img) #若图像为灰度图需要先转换为RGB图(神经网络输入为3通道)#----将图像转换为RGB----#
def cvt2RGB(img):if len(np.shape(img)) == 3 and np.shape(img)[2]==3:return img #为RGB不需要转换else:img = img.convert('RGB')return img ③拆分框体信息
同样同样没什么好说的,遍历分割file_item从1开始的元素就好了
box_info = np.array([np.array(list(map(int,box.split(',')))) for box in file_item[1:]])
#从文件中加载先验框坐标和类型(从第1个元素开始)④将图片变形
这一步也不是必须的,可以选择在开始训练之前对图片信息进行处理。但是在程序中处理需要注意一点,在改变图像的同时需要以同样的比例改变先验框的坐标。
img,new_box = self.resize_img_withBox(img,box_info,self.inp_Shape)这里给出一个无损变换大小的函数,若不指定参数则不变化。
def resize_img_withBox(self,img, box, size=[0,0]): #输入参数分别为:原图、先验框列表、变形后的图片大小iw,ih = img.sizew,h = sizenew_box=[]# 若没有指定大小则不需要变形,若指定了大小则进行变形if size!=(0,0):scale = min(w/iw,h/ih) #获取变形比例nw = int(iw*scale) #计算变形后的长宽nh = int(ih*scale)dx = (w-nw)//2dy = (h-nh)//2# 图像变形img = img.resize((nw,nh),Image.BICUBIC)new_img = Image.new('RGB',size,(128,128,128)) #创建一张灰色背景new_img.paste(img,((w-nw)//2,(h-nh)//2)) #将变形后的图片贴进背景中央# 先验框变形if len(box)>0:np.random.shuffle(box)box[:, [0,2]] = box[:, [0,2]]*nw/iw + dxbox[:, [1,3]] = box[:, [1,3]]*nh/ih + dybox[:, 0:2][box[:, 0:2]<0] = 0box[:, 2][box[:, 2]>w] = wbox[:, 3][box[:, 3]>h] = hbox_w = box[:, 2] - box[:, 0]box_h = box[:, 3] - box[:, 1]new_box = box[np.logical_and(box_w>1, box_h>1)] # discard invalid boxreturn new_img,new_box⑤变换图片的通道
标准的图片通道为RGB,而在pytorch中图片的通道为BGR,所以我们需要对通道进行调整,同时为其附加batch通道。
img = np.transpose(preprocess_input(np.array(img, dtype=np.float32)), (2, 0, 1))前面的函数是一个增强函数,会给RGB三个通道加上不同的权值,至于权值则是一个默认权值(我也不知道为什么用这个)
#----为图像加权,这是一般默认的参数----#
def preprocess_input(image):image = np.array(image,dtype = np.float32)[:, :, ::-1]mean = [0.40789655, 0.44719303, 0.47026116]std = [0.2886383, 0.27408165, 0.27809834]return (image / 255. - mean) / std⑥拆分坐标信息和分类信息
如题,将坐标信息和分类信息从先验框信息组中进行分割
# 拆分先验框坐标和类型box_data = np.zeros((len(new_box),5))if(len(box_info)>0):box_data[:len(box_info)] = box_infobox = box_data[:,:4]label = box_data[:,-1]完成上述步骤后,将得到的数据返回即可,完整的getitem函数如下:
def __getitem__(self, index):index = index % self.length #计算batch长度# 读取文件file_item = self.file_Lines[index].split() #按空格拆分文件行,其中的元素分别为:文件路径、先验框坐标(n个)img = Image.open(file_item[0]) #打开图片img = cvt2RGB(img) #若图像为灰度图需要先转换为RGB图(神经网络输入为3通道)box_info = np.array([np.array(list(map(int,box.split(',')))) for box in file_item[1:]]) #从文件中加载先验框坐标和类型(从第1个元素开始)# 对图像进行变形(含先验框变形)img,new_box = self.resize_img_withBox(img,box_info,self.inp_Shape)# 将图像进行加权#img = np.transpose(preprocess_input(np.array(img, dtype=np.float32)), (2, 0, 1))img = np.transpose(np.array(img))# 拆分先验框坐标和类型box_data = np.zeros((len(new_box),5))if(len(box_info)>0):box_data[:len(box_info)] = box_infobox = box_data[:,:4]label = box_data[:,-1]return img,box,label三、数据封包
我们在训练时肯定不能这样一个一个训练,一般情况我们训练时会将这些数据打包成一个个的patch送给迭代器,而collate_fn就是做这个的,需要注意collate_fn并不是DataSet类的成员。
这个函数使dataloader自动使用的,其中的images、bboxes、labels 将会在训练过程中用到,这里我们只要确保将数据装入对应的容器中即可。
# DataLoader中collate_fn使用
def my_collate(batch):images = []bboxes = []labels = []for img, box, label in batch:images.append(img)bboxes.append(box)labels.append(label)images = np.array(images)return images, bboxes, labels四、调用
①读取数据集文件(txt)
file_path = "数据集文件的路径"with open(file_path) as f:train_lines = f.readlines()②实例化DataSet
train_dataset = MyDataSet(train_lines,input_shape,num_classes)train_loader = DataLoader(train_dataset, shuffle = True, batch_size = 32, num_workers = 1, collate_fn=my_collate)其中num_workers是线程数;batch_size是单个batch的大小;collate_fn指向我们刚刚重写的collate_fn;shuffle表示是否打乱数据集的顺序。
③训练
当然,这里不是真的训练,我们用一个展示函数来代替训练。
print("开始打印结果")for item in train_dataset:img, box, label = itemimg = img.transpose(1,2,0)print(img.shape)im = Image.fromarray(np.uint8(img))im.show()input("按任意键继续")
这个昆虫数据集太恶心了就不给大家看了
相关文章:
[Pytorch]DataSet和DataLoader逐句详解
将自己的数据集引入Pytorch是搭建属于自己的神经网络的重要一步,这里我设计了一个简单的实验,结合这个实验代码,我将逐句教会大家如何将数据引入DataLoader。 这里以目标检测为例,一个batch中包含图片文件、先验框的框体坐标、目标…...
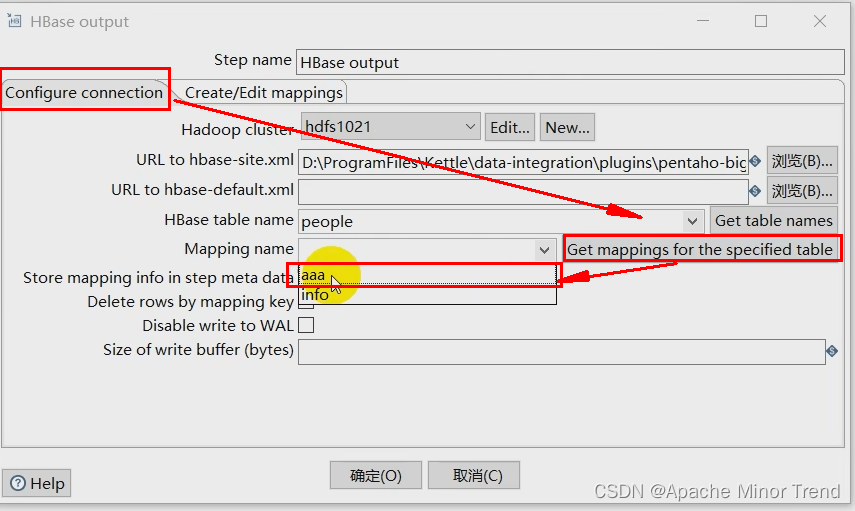
【Kettle-佛系总结】
Kettle-佛系总结Kettle-佛系总结1.kettle介绍2.kettle安装3.kettle目录介绍4.kettle核心概念1.转换2.步骤3.跳(Hop)4.元数据5.数据类型6.并行7.作业5.kettle转换1.输入控件1.csv文件输入2.文本文件输入3.Excel输入4.XML输入5.JSON输入6.表输入2.输出控件…...

JavaSE网络编程
JavaSE网络编程一、基本概念二、常用类三、使用方法1、创建服务器端Socket2、创建客户端Socket3、创建URL对象JavaSE中的网络编程模块提供了一套完整的网络编程接口,可以方便地实现各种基于网络的应用程序。本文将介绍JavaSE中网络编程模块的基本知识、常用类以及使…...

9万字“联、管、用”三位一体雪亮工程整体建设方案
本资料来源公开网络,仅供个人学习,请勿商用。部分资料内容: 1、 总体设计方案 围绕《公共安全视频监控建设联网应用”十三五”规划方案》中的总体架构和一总两分结构要求的基础上,项目将以“加强社会公共安全管理,提高…...

springboot自动装配原理
引言 springboot的自动装配是其重要特性之一,在使用中我们只需在maven中引入需要的starter,然后相应的Bean便会自动注册到容器中。例如: <dependency><groupId>org.springframework.boot</groupId><artifactId>spr…...
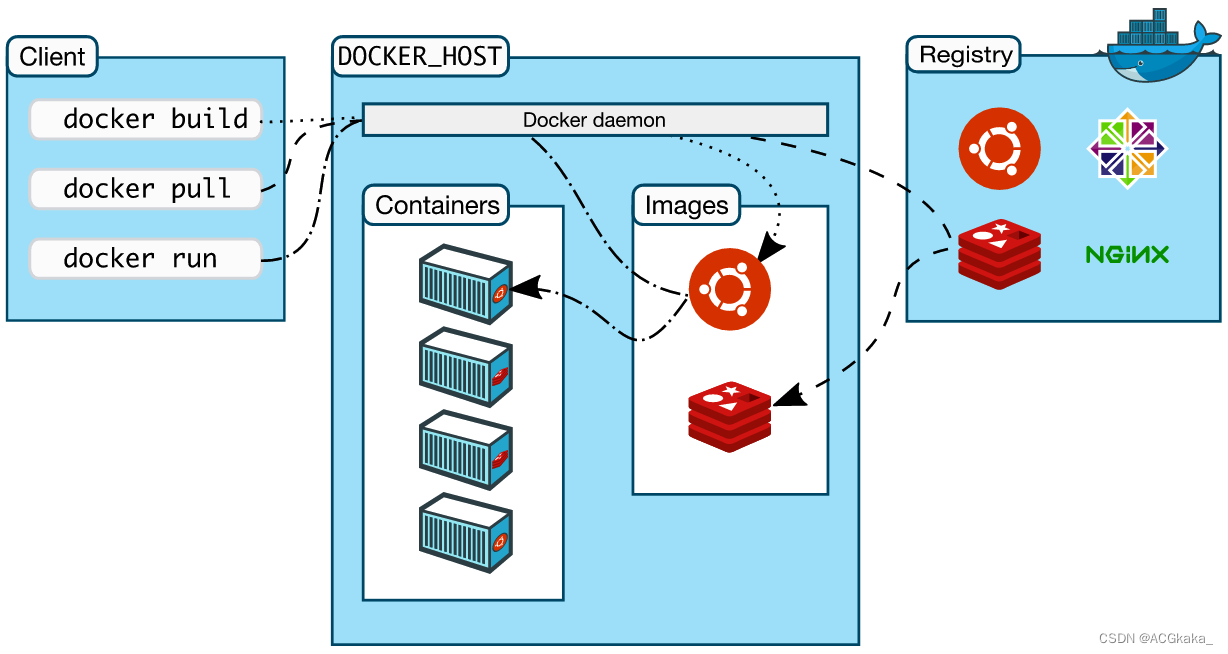
Docker学习(二十)什么是分层存储?
目录1.简介2.什么是 Union Mount?3.分层介绍1)lowerdir 层(镜像层)2)upperdir 层(容器层)3)merged 层4.工作原理1)读:2)写:3ÿ…...
Vue组件进阶(动态组件,组件缓存,组件插槽,具名插槽,作用域插槽)与自定义指令
Vue组件进阶与自定义指令一、Vue组件进阶1.1 动态组件1.2 组件缓存1.3 组件激活和非激活1.4 组件插槽1.5 具名插槽1.6 作用域插槽1.7 作用域插槽使用场景二、自定义指令2.1 自定义指令--注册2.2 自定义指令-传参一、Vue组件进阶 1.1 动态组件 多个组件使用同一个挂载点&#x…...

僵尸进程与孤儿进程
概念 在 Unix/Linux 系统中,正常情况下,子进程是通过父进程创建的,且两者的运行是相互独立的,父进程永远无法预测子进程到底什么时候结束。当一个进程调用 exit 命令结束自己的生命时,其实它并没有真正的被销毁&#…...
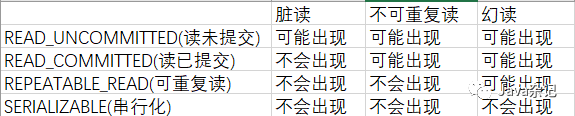
基于注解@Transactional事务基本用法
关于概念性的放在最下面,熟读几遍 在使用时候也没多关注,总是加个Transactional 初识下 一般查询 Transactional(propagation Propagation.SUPPORTS) 增删改 Transactional(propagation Propagation.REQUIRED) 当然不能这么马虎 Spring中关于事务的传播 一个个测试,事…...
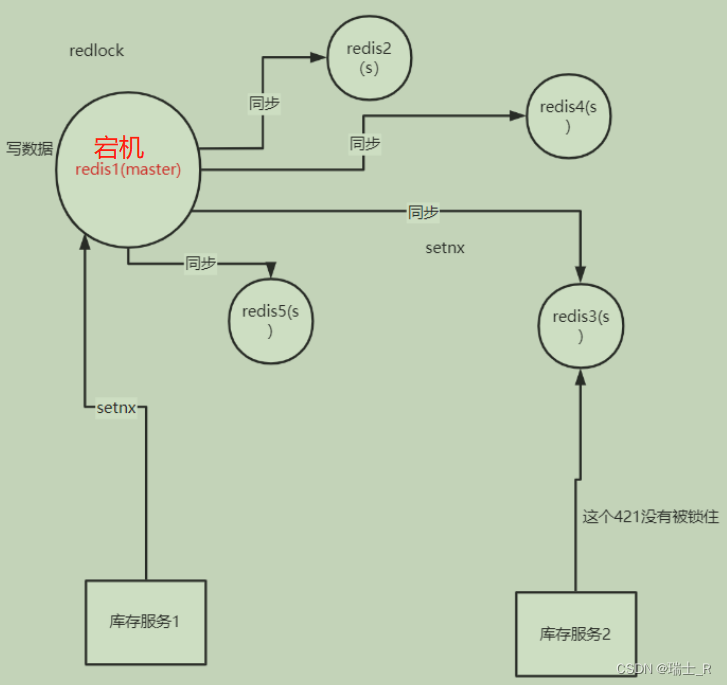
Go项目(商品微服务-2)
文章目录简介handler商品分类轮播图品牌和品牌与分类oss前端直传库存服务数据不一致redis 分布式锁小结简介 开发商品微服务 API 层类似的,将 user-web 目拷贝一份,全局替换掉 user-web修改 config 去掉不用的配置更新本地和远程 nacos 配置文件 把 pro…...
无头盔PICO-unity开发日记1(抓取、传送)
目录 可传送的地面 锚点传送 修改射线颜色(可交互/不可交互) 球、抓手组件 ||刚体(重力)组件 可传送的地面 1.地面添加组件 2.XR交互管理器添加传送提供者 3.地面设置传送提供者 4.XR交互管理器添加locomotion system 5.拖拽 完…...

Material3设计指南笔记
Material3设计指南笔记Table of Contents1. 颜色color1.1. 颜色分类1.2. 强调色accent color1.3. 中性色neutral color1.4. 辅助色additional color1.5. 调色盘tonal palettes1.6. 颜色规范2. z轴高度 elevation3. 图标 icon4. 动画 motion5. 形状 shape6. 字体1. 颜色color1.1…...

JavaWeb--会话技术
会话技术1 会话跟踪技术的概述2 Cookie2.1 Cookie的基本使用2.2 Cookie的原理分析2.3 Cookie的使用细节2.3.1 Cookie的存活时间2.3.2 Cookie存储中文3 Session3.1 Session的基本使用3.2 Session的原理分析3.3 Session的使用细节3.3.1 Session钝化与活化3.3.2 Session销毁目标 理…...

Git图解-为啥是Git?怎么装?
目录 零、学习目标 一、版本控制 1.1 团队开发问题 1.2 版本控制思想 1.2.1 版本工具 二、Git简介 2.1 简介 2.2 Git环境的搭建 三、转视频版 零、学习目标 掌握git的工作流程 熟悉git安装使用 掌握git的基本使用 掌握分支管理 掌握IDEA操作git 掌握使用git远程仓…...

HTML 框架
HTML 框架 <iframe>标签规定一个内联框架。 一个内联框架被用来在当前 HTML 文档中嵌入另一个文档。 通过使用框架,你可以在同一个浏览器窗口中显示不止一个页面。 iframe 语法: <iframe src"URL"></iframe> 该URL指向不同的…...
)
Rust特征(Trait)
特征(Trait) 特征(trait)是rust中的概念,类似于其他语言中的接口(interface)。在之前的代码中,我们也多次见过特征的使用,例如 #[derive(Debug)],它在我们定义的类型(struct)上自动…...
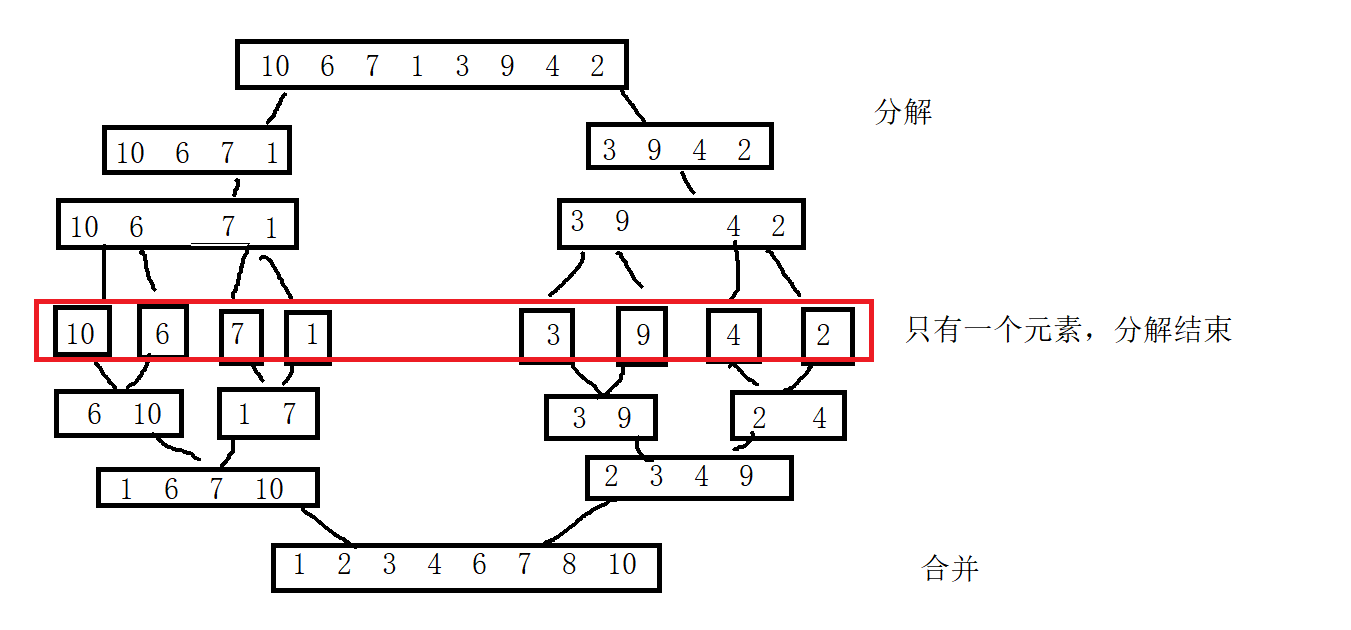
详解七大排序算法
对于排序算法,是我们在数据结构阶段,必须要牢牢掌握的一门知识体系,但是,对于排序算法,里面涉及到的思路,代码……各种时间复杂度等,都需要我们,记在脑袋瓜里面!…...
Vue+ECharts实现可视化大屏
由于项目需要一个数据大屏页面,所以今天学习了vue结合echarts的图标绘制 首先需要安装ECharts npm install echarts --save因为只是在数据大屏页面绘制图表,所以我们无需把它设置为全局变量。 可以直接在该页面引入echarts,就可以在数据大…...
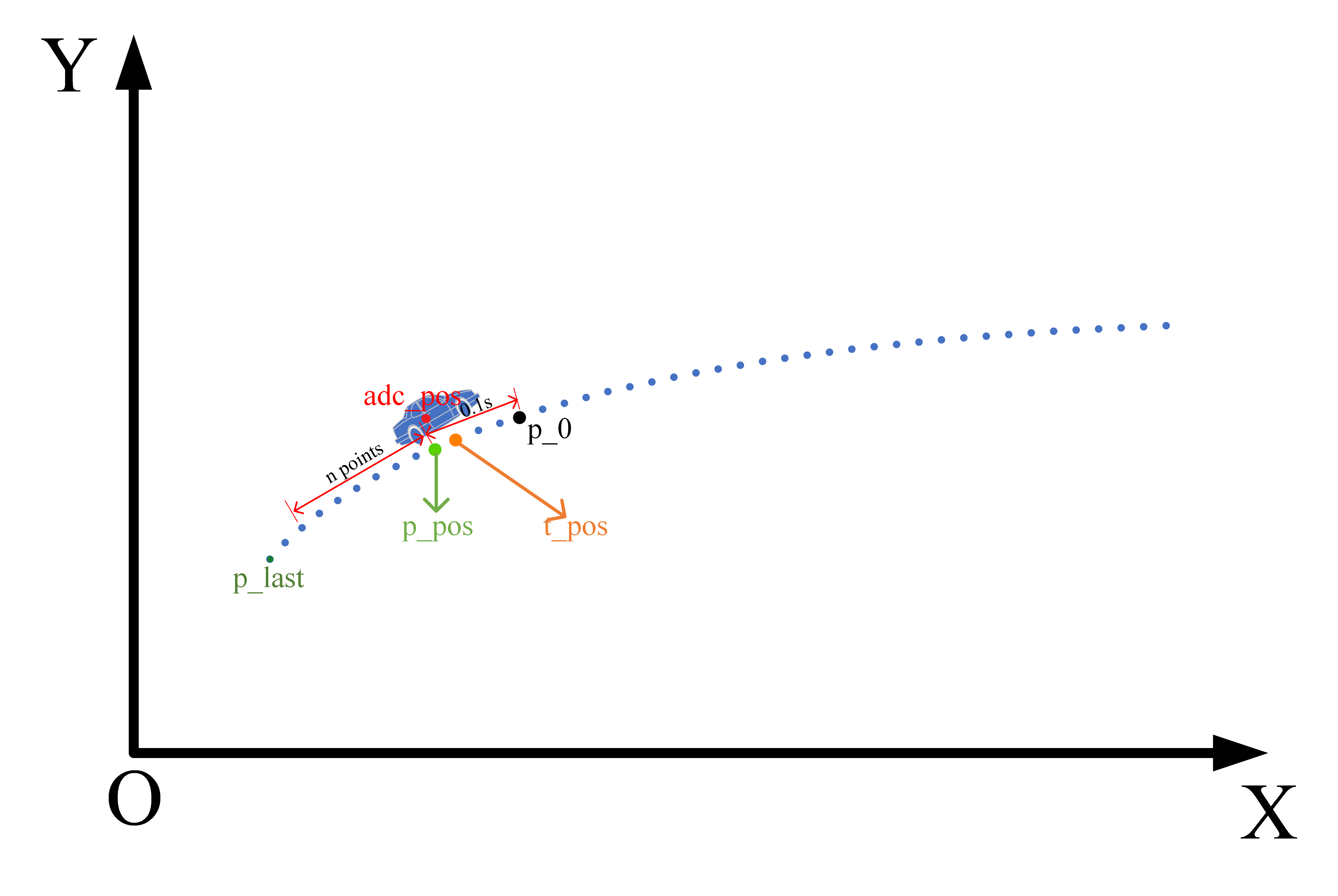
百度Apollo规划算法——轨迹拼接
百度Apollo规划算法——轨迹拼接引言轨迹拼接1、什么是轨迹拼接?2、为什么要进行轨迹拼接?3、结合Apollo代码为例理解轨迹拼接的细节。参考引言 在apollo的规划算法中,在每一帧规划开始时会调用一个轨迹拼接函数,返回一段拼接轨迹…...
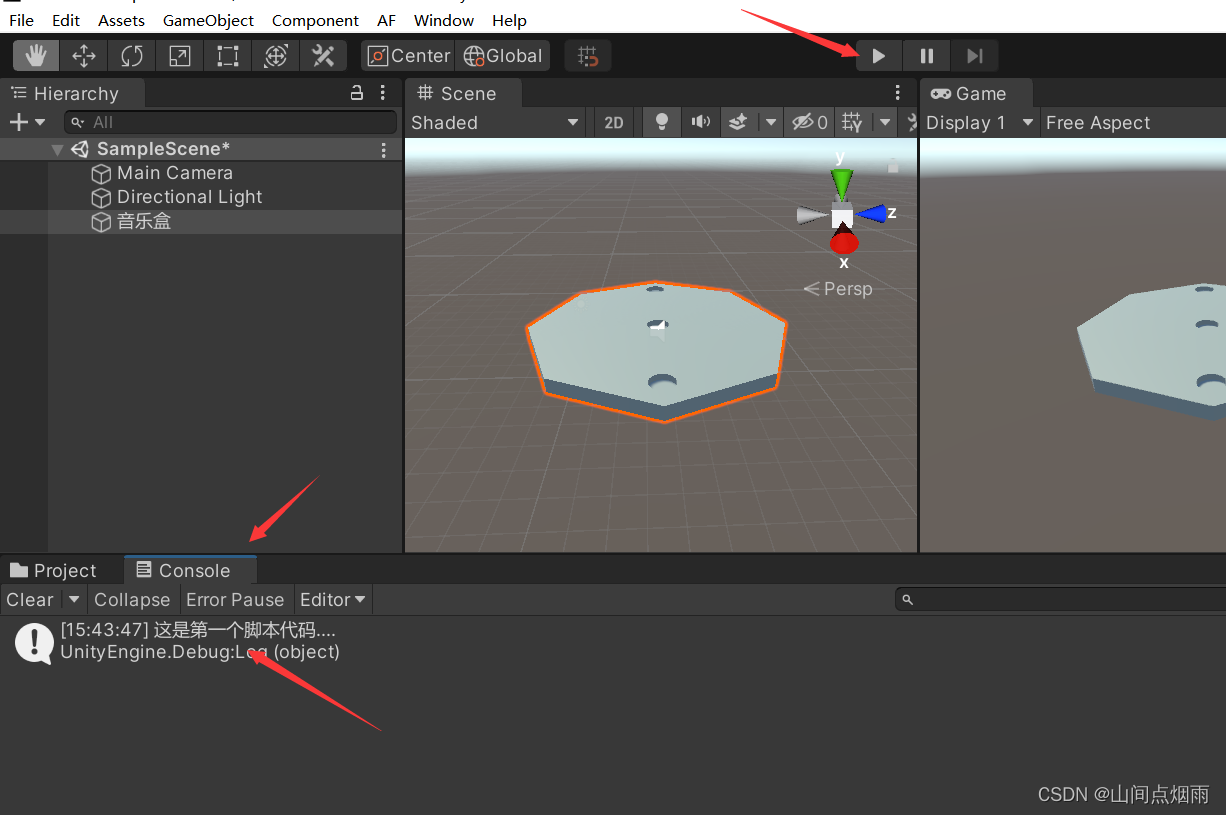
6. unity之脚本
1. 说明 当整个游戏运行起来之后,我们无法再借助鼠标来控制物体,此时可以使用脚本来更改物体的各种姿态,驱动游戏的整体运动逻辑。 2. 脚本添加 首先在Assets目录中,新创建一个Scripts文件夹,在该文件内右键鼠标选择…...
Pixel Script Temple应用场景:有声书脚本生成、儿童动画分集大纲、播客故事线设计
Pixel Script Temple应用场景:有声书脚本生成、儿童动画分集大纲、播客故事线设计 1. 产品概述 Pixel Script Temple是一款基于Qwen2.5-14B-Instruct深度微调的专业剧本创作工具,将AI推理能力与8-Bit复古美学相结合,为创作者提供沉浸式的剧…...

OpenClaw+SecGPT-14B:构建无需编程的内网资产管理系统
OpenClawSecGPT-14B:构建无需编程的内网资产管理系统 1. 为什么需要无代码内网资产管理 去年接手公司IT运维时,我发现内网设备清单还是三年前的Excel表格。每当新设备接入或旧设备淘汰,手动更新文档总会被遗忘。更麻烦的是,不同…...

Python入门:轻松掌握输入输出与数据类型,2025年ASOC SCI2区TOP,基于动态模糊系统的改进灰狼算法FGWO,深度解析+性能实测。
Python 入门:输入输出与数据类型详解 输入与输出基础 Python 的输入输出是程序与用户交互的基础。input() 函数用于接收用户输入,默认返回字符串类型。例如: user_input input("请输入内容:") print("你输入的内容…...

【数据结构与算法】第24篇:哈夫曼树与哈夫曼编码
一、基本概念1.1 带权路径长度在二叉树中:路径长度:从一个节点到另一个节点经过的边数带权路径长度(WPL):所有叶子节点的权重 路径长度 之和示例:text叶子节点:A(7), B(5), C(2), D(4)普通树:15/ \7 8/…...

MAX9814麦克风音量LED指示器嵌入式固件库
1. 项目概述MAX9814_Electret_Microphone_LED_Volume_Indicator是一个面向嵌入式音频前端采集与可视化反馈的轻量级固件库,专为 Adafruit MAX9814 电容式驻极体麦克风放大模块设计。该模块基于 Maxim(现为 Analog Devices)推出的低噪声、高增…...
✅)
计算机毕业设计:Python汽车销量数据挖掘与预测系统 Flask框架 scikit-learn 可视化 requests爬虫 AI 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...
)
氢能多能利用调度系统 -NSGA-II多目标优化,实现氢能-电能-交通多能耦合系统的24小时优化调度,包含电解制氢、可再生能源、储氢、掺氢燃气轮机、氢燃料电池和氢电动汽车等关键设备研究(Matlab)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

OFA图像描述系统实战:快速搭建图片转文字工具,避免常见权限错误
OFA图像描述系统实战:快速搭建图片转文字工具,避免常见权限错误 1. 项目介绍:让图片自己“说话”的智能工具 你有没有遇到过这样的场景?手头有一堆产品图片,需要为每张图配上文字描述,手动编写不仅耗时耗…...

mysql备份工具选择_mysqldump对InnoDB与MyISAM支持
mysqldump默认对MyISAM用表级锁、InnoDB不启用事务快照,混合引擎必须用--lock-all-tables保证一致性,且需确保REPEATABLE READ隔离级别和ROW/MIXED binlog格式。mysqldump 默认行为对 InnoDB 和 MyISAM 完全不同默认不加任何参数时,mysqldump…...

深入理解Vue的响应式原理:从Object.defineProperty到Proxy
Vue的响应式系统是其核心特性之一,它使得数据变化能够自动驱动视图更新。从Vue 2.x的Object.defineProperty到Vue 3.x的Proxy,这一演进不仅是技术实现上的突破,更体现了Vue对性能、兼容性和开发体验的深度思考。以下从技术原理、实现差异、性…...