PostgreSQL内存上下文系统设计概述
PostgreSQL内存上下文系统设计概述
原文:src/backend/utils/mmgr/README
背景
我们在“内存上下文”中进行大部分内存分配,通常是AllocSets由src/backend/utils/mmgr/aset.c实现。在没有大量开销的情况下成功进行内存管理的关键是定义一组具有适当生命周期的有用上下文。
内存上下文的基本操作是:
-
创建一个上下文
-
在上下文中分配一块内存(相当于标准C库的malloc())
-
删除一个上下文(包括释放其中分配的所有内存)
-
重置上下文(释放上下文中分配的所有内存,但不释放上下文对象本身)
-
查询分配给上下文的内存总量(上下文从中分配块的原始内存;而不是块本身)
给定先前从上下文分配的一块内存,可以释放它或重新分配更大或更小的内存(对应于标准C库的free()和realloc()进程)。这些操作将内存返回到块最初分配的同一上下文或从该上下文中获取更多内存。
始终存在由CurrentMemoryContext全局变量表示的“当前”上下文。palloc()在该上下文中隐式分配空间。MemoryContextSwitchTo()操作选择一个新的当前上下文并返回之前的上下文,以便调用者可以在退出之前恢复之前的上下文)。
与普通使用malloc/free相比,内存上下文的主要优点是可以轻松释放内存上下文的全部内容,而无需请求释放其中的每个单独块。这比按块记录更快、更可靠。我们利用在事务结束时进行清理:通过重置事务的所有活动上下文或缩短生命周期,我们可以回收所有瞬态内存。类似地,我们可以在每个查询结束时或在查询期间处理每个元组之后进行清理。
关于pallocAPI与标准C库的一些注意事项
palloc及其其它pg内存分配函数的行为与标准C库的malloc及其它内存分配函数类似,但也有一些故意的差异。以下是一些澄清行为的注释。
-
如果内存不足,palloc和repalloc通过elog退出(错误)。它们从不返回NULL,并且测试这样的结果没有必要也没有用。通过palloc_extended(),可以使用MCXT_ALLOC_NO_OOM标志覆盖该行为。
-
palloc(0)是明确有效的操作。它不返回NULL指针,而是返回一个不能使用任何字节的有效块。然而该块稍后可能会被重新分配得更大;它也可以被释放而不会出现错误。类似地,repalloc允许重新分配到零大小。
-
pfree和repalloc不接受NULL指针(故意这样设计的)。
当前内存上下文(TheCurrentMemoryContext)
CurrentMemoryContext的基本概念。如果没有它,copyObject进程将需要传递上下文,返回引用传递数据类型的函数执行进程也是如此。同样,对于在内部临时分配空间但不将其返回给调用者的进程?我们当然不希望系统中的每个调用都因“这里是用于您可能想要执行的任何临时内存分配的上下文”而变得混乱。
不过这种推理的结果是,如果可能的话CurrentMemoryContext通常应该指向短生命周期上下文。在查询执行期间,它通常指向一个在每个元组之后重置的上下文。只有在“非常”受限的代码中,它才应该指向具有大于事务生命周期的上下文,因为这样做会带来永久内存泄漏的风险。
pfree/repalloc不依赖于CurrentMemoryContext
pfree()和repalloc()可以应用于任何块,无论它是否属于CurrentMemoryContext——无论如何该块的所属上下文都将被调用来处理操作。
“父”和“子”上下文(“Parent” and “Child” Contexts)
如果所有上下文都是独立的,那么就很难跟踪它们,尤其是在错误情况下。这是通过创建“父”和“子”上下文树来解决的。创建内存上下文时,可以将新上下文指定为某个现有上下文的子上下文。一个上下文可以有多个子级,但只能有一个父级。通过这种方式,上下文形成了一个森林(不一定是一棵树,因为可能有多个顶级上下文;尽管在当前实践中只有一个顶级上下文,即TopMemoryContext)。
删除上下文也会删除其所有直接和间接子级。重置上下文时,删除子上下文几乎总是更有用,因此MemoryContextReset()意味着,如果您确实想要一个空上下文树,则需要调用MemoryContextResetOnly()加上MemoryContextResetChildren()。
这些功能使我们能够管理大量上下文,而不必担心某些上下文会被泄露;我们只需要跟踪我们将在事务结束时删除的一个顶级上下文,并确保我们创建的任何短期上下文都是该上下文的后代。由于树可以有多个级别,因此我们可以轻松处理存储的嵌套生命周期,例如每个事务、每个语句、每个扫描、每个元组。仅部分重叠的存储生命周期可以通过从上下文林的不同树进行分配来处理(下一节中有一些示例)。
为了方便起见,我们还提供“重置/删除给定上下文的所有子级,但不重置或删除该上下文本身”之类的操作。
内存上下文重置/删除回调
Postgres9.5中引入的一项功能允许使用内存上下文来管理更多资源,而不仅仅是普通的分配内存。这是通过为内存上下文注册“重置回调函数”来完成的。这样的函数将在下次重置或删除上下文之前调用一次。它可用于放弃在某种意义上与上下文中分配的对象关联的资源。可能的用例包括
- 关闭与元组排序对象关联的打开文件;
- 释放长期缓存对象的引用计数,这些对象由正在重置的上下文中的某个对象持有;
- 释放与某些palloc对象关联的malloc管理的内存。
最后一种情况仅代表Postgres代码的不良编程实践;最好在目标上下文或某个子上下文中使用palloc进行所有分配。然而,对于与非Postgres库交互的代码来说,它很可能派上用场。
可以为内存上下文建立任意数量的重置回调;它们以与注册相反的顺序调用。此外,如果重置或删除上下文树,则附加到子上下文的回调会在附加到父上下文的回调之前调用。
此API要求调用者提供MemoryContextCallback内存块来保存回调的状态。通常,应将其分配在逻辑附加的同一上下文中,以便在使用后自动释放。要求调用者提供此内存的原因是,在大多数使用场景中,调用者将在目标上下文中创建一些更大的结构,并且可以通过包含以下内容来“免费”创建MemoryContextCallback结构,而无需单独的palloc()调用它在这个更大的结构中。
实践中的内存上下文
全局已知的上下文
有一些众所周知的上下文通常是通过全局变量引用的。在任何时刻,系统都可能包含许多附加上下文,但所有其他上下文应该是这些上下文之一的直接或间接子级,以确保它们在发生错误时不会泄漏。
-
TopMemoryContext—这是上下文树的实际顶层;所有其他上下文都是该上下文的直接或间接子上下文。这里的分配本质上与“malloc”相同,因为这个上下文永远不会被重置或删除。这是为了那些应该永远存在的东西,或者是为了控制模块将在适当的时间删除的东西。一个例子是fd.c的打开文件表。除非确实必要,否则请避免在此处分配内容,尤其是避免使用指向此处的CurrentMemoryContext来运行。
-
PostmasterContext—这是postmaster的正常工作上下文。后端启动后删除PostmasterContext释放postmaster启动时使用的不需要的内存副本。请注意,在非EXEC_BACKEND版本中,postmaster的pg_hba.conf和pg_ident.conf数据副本在后端进程的身份验证期间直接使用;因此,在完成之前后端无法删除PostmasterContext。(postmaster只有TopMemoryContext、PostmasterContext和ErrorContext—其余的顶级上下文在启动期间在每个后端中设置。)
-
CacheMemoryContext—relcache、catcache和相关模块的永久存储。它也永远不会被重置或删除,因此没有必要将其与TopMemoryContext区分开来。但为了调试目的而保持这种区别是值得的。(注意:CacheMemoryContext的子上下文的生命周期较短。例如,子上下文是保存与relcache条目关联的辅助存储的最佳位置;这样我们就可以轻松地释放规则解析树等,而不必依赖于构造freeObject()的可靠版本。)
-
MessageContext—此上下文保存来自前端的当前命令消息,以及仅需要与当前消息一样长的任何派生存储(例如,在简单查询模式下,解析树和计划树可以存在于此)。在PostgresMain外循环的每个循环的顶部,将重置此上下文,并删除所有子级。这与每个事务和每个门户上下文分开,因为查询字符串可能需要比任何单个事务或门户生存更长或更短的时间。
-
TopTransactionContext—这保存了直到顶级事务结束为止的所有内容。在每个顶级事务周期结束时,此上下文将被重置,并删除其所有子上下文。在大多数情况下,您不想直接在此处分配内容,而是在CurTransactionContext中;这里真正属于的是显式存在的控制信息,用于管理跨多个子事务的状态。注意:出现错误时不会立即清除此上下文;其内容将一直存在,直到事务块通过COMMIT/ROLLBACK退出。
-
CurTransactionContext——它保存必须存活到当前事务结束的数据,特别是在顶级事务提交时需要的数据。当我们处于顶级事务中时,这与TopTransactionContext相同,但在子事务中它指向子上下文。重要的是要理解,如果子事务中止,则其CurTransactionContext在完成中止处理后将被丢弃;但已提交的子事务CurTransactionContext一直保留到顶级提交(当然,除非子事务的中间级别之一中止)。这确保了我们不会将失败的子事务中的数据保留超过必要的时间。由于这种行为,您必须在子事务中止期间小心地进行正确清理——子事务的状态必须与上层事务中保存的任何指针或列表解除链接,否则您将有悬空指针,导致顶级提交时崩溃。这里保存的数据的一个示例是挂起的NOTIFY消息,这些消息在顶级提交时发送,但前提是生成的子事务没有中止。
-
PortalContext—这实际上不是一个单独的上下文,而是一个指向当前活动执行门户的每个门户上下文的全局变量。如果需要分配与当前门户执行所需时间一样长的存储空间,则可以使用此方法。
-
ErrorContext—这个永久上下文被切换到错误恢复处理,然后在恢复完成时重置。我们安排始终有几KB的可用内存。这样,即使后端内存不足,我们也可以确保有一些内存可用于错误恢复。这允许将内存不足视为正常错误情况,而不是致命错误。
预备语句和执行平台(portal)的上下文
预备语句对象具有关联的私有上下文,其中存储查询的解析树和计划树。由于这些树对于执行器来说是只读的,因此预备语句可以多次重复使用,而无需进一步复制这些树。
execution-portal(执行平台)对象具有一个私有上下文,当execution-portal处于活动状态时,该上下文由PortalContext引用。对于由DECLARE CURSOR创建的平台,此私有上下文包含查询解析和计划树(没有其他对象可以容纳它们)。从预备语句创建的平台仅引用准备好语句树,不需要在其私有上下文中分配任何存储。
逻辑复制工作线程上下文
ApplyContext——在应用工作的整个生命周期内永久存在。此处也可以使用TopMemoryContext,但为了简化内存使用分析,我们启动不同的上下文。
ApplyMessageContext—在处理每个逻辑复制协议消息后重置的短期上下文。
执行期间的瞬态上下文
创建预备语句时,解析树和计划树将构建在MessageContext子级的临时上下文中(以便在出错时它将自动消失)。成功后,完成的计划将被复制到预备语句的私有上下文中,并释放临时上下文;这允许规划器在执行开始之前恢复临时空间。(在简单查询模式下,不需要额外的复制步骤,因此规划器临时空间会一直保留到查询结束。)
顶级执行程序进程以及大多数“计划节点”执行代码通常将在由ExecutorStart创建并由ExecutorEnd销毁的上下文中运行;此上下文还保存在ExecutorStart期间构建的“计划状态”树。这些进程中分配的大部分内存旨在一直存在到查询结束。执行器的顶级上下文是PortalContext的子级,即代表查询执行的平台上下文。
执行器中的主要内存管理考虑因素是表达式求值(无论是用于质量测试还是用于目标列表条目的计算)都不能发生内存泄漏。为此,执行器中创建的每个ExprContext(表达式求值上下文)都有一个与之关联的私有内存上下文,并且在计算该ExprContext中的表达式时,我们会切换到该上下文。拥有ExprContext的计划节点负责在不再需要表达式求值结果时将私有上下文重置为空。通常,重置是在计划节点中每个元组获取周期开始时完成的。
请注意,此设计为每个计划节点提供了自己的表达式评估内存上下文。这对于正确处理嵌套连接是必要的,因为外部计划节点可能需要保留它在从内部节点获取下一个元组时计算出的表达式结果——但内部节点可能会在返回之前执行许多元组循环和许多表达式。内部节点必须能够在每个外部元组循环中多次重置其自己的表达式上下文。幸运的是内存上下文足够便宜为每个计划节点提供一个内存上下文不是问题。
在查询生命周期上下文中运行索引访问和排序的一个问题是,这些操作会调用特定的数据类型比较函数,并且如果比较器泄漏任何内存,那么该内存将不会在查询结束之前恢复。比较器函数都返回bool或int32,因此它们的结果数据没有问题,但可能存在内部临时数据泄漏的问题。特别是,对支持TOAST的数据类型进行操作的比较器函数需要小心,不要泄漏其输入的detoast版本。这很烦人,但使比较器符合要求比修复索引和排序进程容易得多,所以这就是7.1所做的事情。这仍然是btree和哈希索引中的情况,因此btree和哈希支持函数仍然需要不泄漏内存。大多数其他索引AM已被修改为在短期上下文中运行opclass支持函数,因此内存泄漏没有问题;鉴于它们的支持职能往往要复杂得多,这是必要的。
有一些特殊情况,例如聚合函数。nodeAgg.c需要记住从一个元组循环到下一个元组循环的聚合转换函数的评估结果,因此它不能在循环中丢弃元组状态。处理这个问题的最简单方法是在聚合节点中拥有两个元组上下文,并在它们之间进行ping-pong操作,以便在每个元组中,一个是当前活动分配上下文,另一个上一循环时上下文。
切换CurrentMemoryContext的执行程序进程可能需要在返回之前将数据复制到调用者的当前内存上下文中。然而我们已经最大限度地减少了这种需要,因为按照惯例,在执行周期的“开始”而不是结束时重置每个元组上下文。根据该规则,执行节点可以返回一个在其每个元组上下文中分配的元组,并且该元组将保持良好状态,直到该节点被调用另一个元组或被告知结束执行。这与表扫描级别的按引用传递值的情况类似,因为扫描节点可以返回指向磁盘缓冲区中的元组的直接指针,而该元组只能保证在那么长时间内保持良好状态。
复制数据的一个更常见的原因是将结果从每个元组上下文传输到每个查询上下文;例如,Unique节点将在其每个查询上下文中保存最后一个不同的元组值,需要复制步骤。
允许多种类型上下文的机制
为了有效地允许不同的分配模式并进行实验,我们允许具有不同分配策略但相似外部行为的不同类型的内存上下文。为了处理这个问题,内存分配函数是通过函数指针访问的,并且我们要求所有上下文类型都遵守此处给出的约定。
MemoryContextData(请参阅memnodes.h)。此结构体标识上下文的确切类型,并包含不同类型的MemoryContext之间通用的信息,例如父上下文和子上下文以及上下文的名称。
这本质上是一个抽象超类,其行为由“methods”指针决定,即它的虚函数表(struct MemoryContextMethods)。特定的内存上下文类型将使用将这些字段作为其第一个字段的派生结构。特定类型的所有上下文都将具有指向相同的函数指针静态表的方法指针。
虽然从上下文分配和重置等操作将相关的MemoryContext作为参数,但像free和realloc这样的操作则更加棘手。为了实现这些工作,我们要求所有内存上下文类型生成分配的块,这些块立即没有任何填充,前面是指向相应MemoryContext的指针。
如果某种类型的分配器需要有关其块的附加信息(例如分配的大小),则该信息又可以先于MemoryContext。这意味着内存上下文机制隐含的唯一开销是指向其上下文的指针,因此我们不会对上下文类型设计者产生太多限制。
鉴于此,像pfree这样的进程通过类似的操作确定它们相应的上下文(尽管通常封装在GetMemoryChunkContext()中)
MemoryContext context = *(MemoryContext*) (((char *) pointer) - sizeof(void *));
#然后调用上下文对应的方法
context->methods->free_p(pointer);
aset.c行为的更多控制
默认情况下,aset.c始终在上下文中第一次分配时分配8K块,并为每个连续的块请求将该大小加倍。对于可能保存“大量”数据的上下文来说,这是一个很好的行为。但是,如果系统中有数十个甚至数百个较小的上下文,我们就需要能够更好地进行微调。
上下文的创建者能够指定初始块大小和最大块大小。选择较小的值可以防止在预计不会容纳太多内容的上下文中浪费空间(一个例子是relcache的每个关系上下文)。
此外,还可以指定最小上下文大小,以防由于某种原因应与附加块的初始大小不同。aset.c上下文将始终包含至少一个大小为minContextSize的块(如果已指定),否则为initBlockSize。
我们预计每个元组上下文将被频繁重置,并且通常不会为每个元组周期分配太多空间。为了使这种使用模式更便宜,在重置期间不会将上下文中分配的第一个块返回给malloc(),而只是清除。这可以避免malloc抖动。
替代内存上下文实现
aset.c是我们默认的通用实现,在大多数情况下工作正常。我们还有两个针对特殊用例优化的实现,与aset.c相比(或两者)提供更好的性能或更低的内存使用量。
-
slab.c(SlabContext)是为固定长度的块的分配而设计的,不允许分配不同大小的块。
-
generation.c(GenerationContext)专为将块分配到具有相似生命周期的组中或大致按FIFO顺序分配的情况而设计。
两个内存上下文都旨在将内存释放回操作系统(与aset.c不同,它将释放的块保留在freelist中,并且仅在重置/删除时返回内存)。
这些内存上下文最初是为ReorderBuffer开发的,但只要分配模式匹配,就可能在其他地方有用。
内存核算
基本内存上下文操作之一是确定上下文(及其子上下文)中使用的内存量。我们有多个地方实现了自己的临时内存核算,这是为了提供统一的方法。临时计算解决方案适用于对分配有严格控制的地方,或者当很容易确定分配块的大小时(例如,仅使用元组的地方)。
内存上下文中内置计算是透明的,并且对所有分配都透明地工作,只要它们最终位于正确的内存上下文子树中。
例如,考虑聚合函数-聚合状态通常由从转换函数分配的任意结构表示,因此临时计算不太可能起作用。然而,内置的计算功能可以很好地处理这种情况。
为了最大限度地减少开销,会计是在块级别完成的,而不是针对单个分配块。
记账是惰性的——分配(或释放)块后,仅更新拥有该块的上下文。这意味着当查询给定上下文中的内存使用情况时,我们必须递归地遍历所有子上下文。这意味着内存核算不适用于内存上下文过多(在相关子树中)的情况。
个人对内存上下文的总结
内存上下文就是控制已分配内存的生命周期,例如以下代码
oldcxt = MemoryContextSwitchTo(TopMemoryContext);
object = palloc(1024*1024*8);
MemoryContextSwitchTo(oldcxt);
object是分配在TopMemoryContext,生命周期为PostgreSQL服务启动至停止.
同时pg fork进程时,object也会复制一个至新的进程.例如当有新连接pg创建进程时也会复制.
相关文章:

PostgreSQL内存上下文系统设计概述
PostgreSQL内存上下文系统设计概述 原文:src/backend/utils/mmgr/README 背景 我们在“内存上下文”中进行大部分内存分配,通常是AllocSets由src/backend/utils/mmgr/aset.c实现。在没有大量开销的情况下成功进行内存管理的关键是定义一组具有适当生命周期的有用…...

C++ 网络编程学习二
C 网络编程学习二 asio异步写操作asio异步读操作asio 异步echo服务端asio异步服务器中存在的隐患 asio异步写操作 async_write_some是异步写的函数:传入buffer和回调函数以及参数以后,发送后会调用回调函数。 void Session::WriteToSocketErr(const st…...

SpringMVC 学习(四)之获取请求参数
目录 1 通过 HttpServletRequest 获取请求参数 2 通过控制器方法的形参获取请求参数 3 通过 POJO 获取请求参数(重点) 1 通过 HttpServletRequest 获取请求参数 public String handler1(HttpServletRequest request) <form action"${pageCont…...
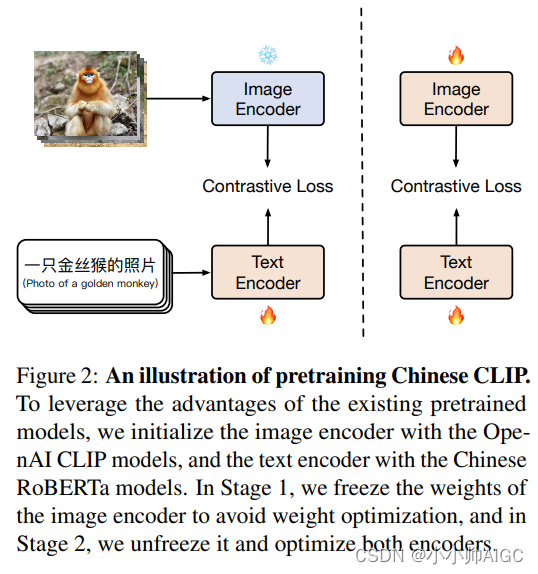
多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读
我之前一直在使用CLIP/Chinese-CLIP,但并未进行过系统的疏导。这次正好可以详细解释一下。相比于CLIP模型,Chinese-CLIP更适合我们的应用和微调,因为原始的CLIP模型只支持英文,对于我们的中文应用来说不够友好。Chinese-CLIP很好地…...

Git本地分支关联远程分支
Git本地分支关联远程分支 本地分支相关操作 查看本地分支 git branch新建本地分支 git branch name切换本地分支 git checkout name新建本地分支并切换到该分支 git checkout -b name #或 git branch name删除本地分支 git branch -d name git branch -D name #强制删除远程分…...

[FT]chatglm2微调
1.准备工作 显卡一张:A卡,H卡都可以,微调需要一张,大概显存得30~40G吧环境安装: 尽量在虚拟环境安装:参见,https://blog.csdn.net/u010212101/article/details/103351853环境安装参见ÿ…...
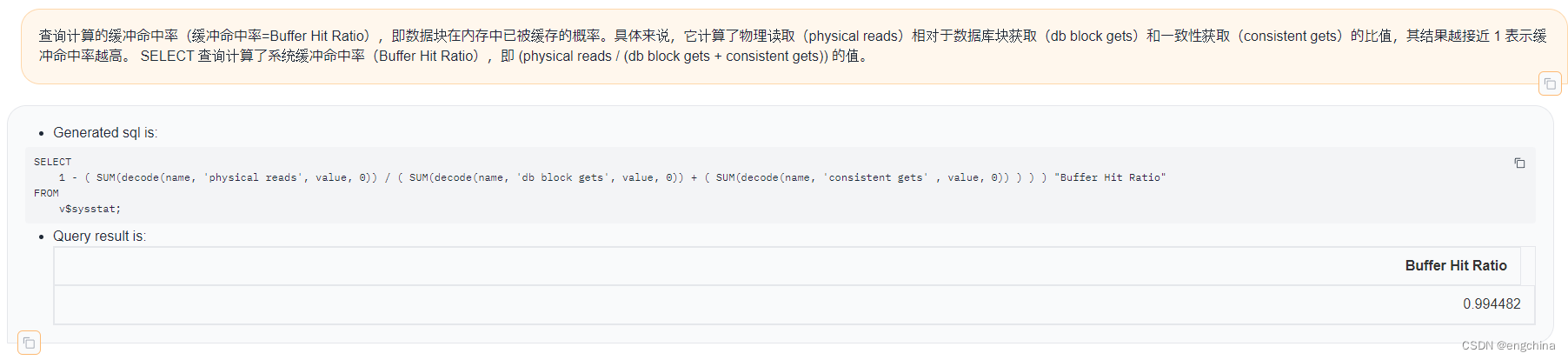
AI赋能Oracle DBA:以自然语言与Oracle数据库互动
DBA AI助手:以自然语言与Oracle数据库互动 0. 引言1. AI赋能Oracle DBA的优势2. AI如何与Oracle数据库交互3. 自然语言查询的一些示例4. 未来展望 0. 引言 传统的Oracle数据库管理 (DBA) 依赖于人工操作,包括编写复杂的SQL语句、分析性能指标和解决各种…...

Django学习记录04——靓号管理整合
1.靓号表 1.1 表结构 1.2 靓号表的构造 class PrettyNum(models.Model): 靓号表 mobile models.CharField(verbose_name"手机号", max_length11)# default 默认值# null true,blank true 允许为空price models.IntegerField(verbose_name"价…...
AD9226 65M采样 模数转换
目录 AD9220_ReadTEST AD9220_ReadModule AD9226_TEST_tb 自己再写个 260M的时钟,四分频来提供65M的时钟。 用 vivado 写的 AD9226_ReadTEST module AD9226_ReadTEST( input clk, input rstn,output clk_driver, //模块时钟管脚 input [12:0]IO_data, //模块数…...

远程控制桌面,让电脑办公更简单
随着科技的不断发展,远程办公已经成为了越来得越多企业和个人的选择。远程控制电脑办公,仅需1款软件即可轻松get! 1.绿虫电脑管理软件 是一款功能强大的办公电脑管理软件,仅需安装在被控端电脑,主控端通过网页登录后…...

猫头虎分享已解决Bug || 网络连接问题:NetworkError: Failed to fetch
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

Layer1 明星项目 Partisia Blockchain 何以打造互操作、可创新的数字经济网络
我们的目标是创建一个以用户为中心的全新数字经济网络:在去信任化和公平透明的环境下,所有的隐私数据都能够得到天然保障,企业、用户等各角色的协作与共享将会更顺利地进行。 —— Partisia Blockchain 团队 作为一个以 Web3 安全为技术方向的…...

用CSS制作弧形卡片的三种创意方法!
在平时开发中,有时候会碰到下面这种“弧形”样式,主要分为“内凹”和“外凸”两种类型,如下 该如何实现呢?或者想一下,有哪些 CSS 属性和“弧形”有关?下面介绍 3 种方式,一起看看吧 一、borde…...

守护健康之光 —— 小脑萎缩患者的生活指南
生活中,我们或许会遇到一些特殊的挑战,而面对这些挑战时,了解和掌握正确的应对策略至关重要。今天,我们要聊一聊一个较为少见却不容忽视的话题——小脑萎缩。这不仅是患者的战役,也是家人和社会共同的关怀课题。下面&a…...

CSS选择器:让样式精确命中目标
CSS选择器:让样式精确命中目标 在网页开发中,CSS选择器是一种强大的工具,它可以帮助我们精确地定位HTML元素,以便为它们应用样式。在这篇博客中,我们将探讨一些常见的CSS选择器,了解它们的功能和使用方法。…...

前端不传被删记录的id怎么删除记录,或子表如何删除记录
1.删除主表相关子表所有记录 2.再保存一次前端传来的记录 3.如果子表是通过先生成空记录,再put修改模式,可以在执行1和2两步后再拿模板集合和当前现有子表集合套两个for循环对比判断,count记录模板记录和子表记录每次循环重合次数ÿ…...

axios的基本特性用法
1. axios的基本特性 axios 是一个基于Promise用于浏览器和node.js的HTTP客户端。 它具有以下特征: 支持浏览器和node.js支持promiseAPI自动转换JSON数据能拦截请求和响应请求转换请求数据和响应数据(请求是可以加密,在返回时也可进行解密&…...
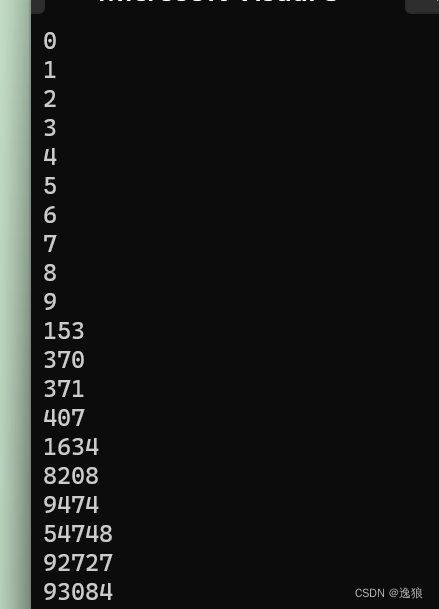
打印水仙花数---c语言刷题
欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎指出~ 题述 求出0~100000之间的所有“水仙花数”并输出。 “水仙花数”是指一个n位数,其各位数字的n次方之和确好等于该数本身,如:153&#…...
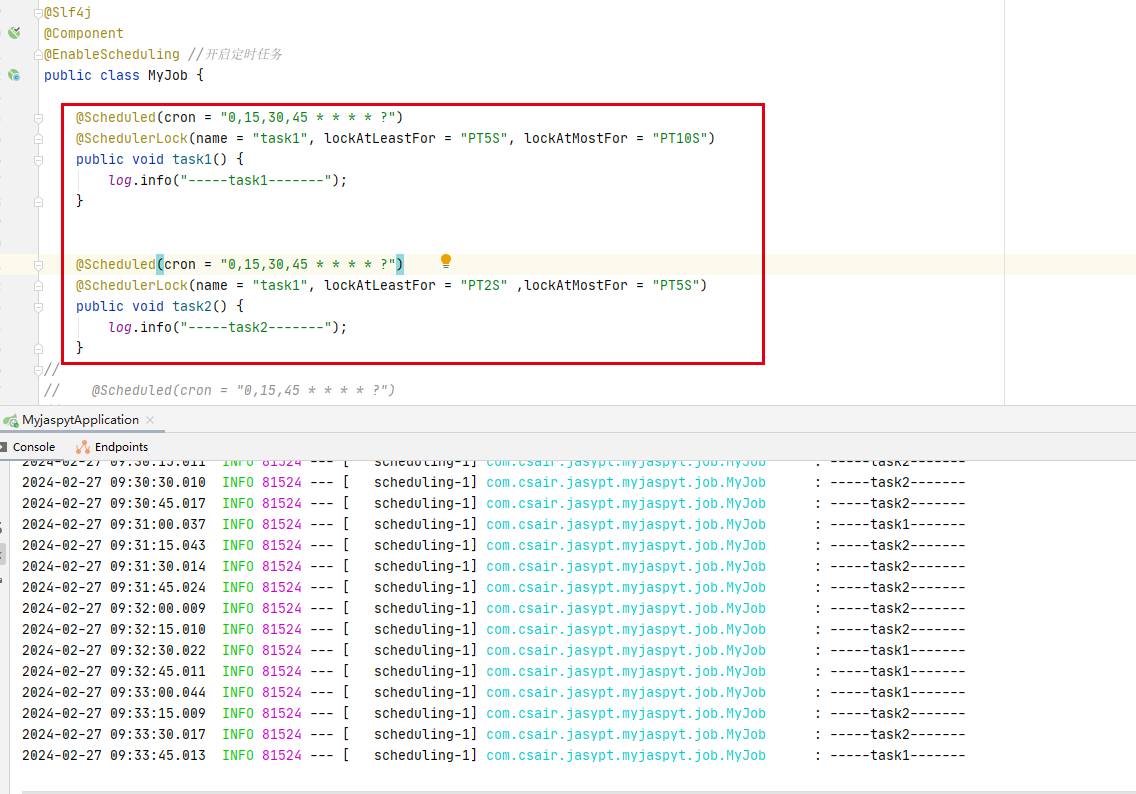
springboot基础(82):分布式定时任务解决方案shedlock
文章目录 前言简介shedlock dbSchedulerLock注解说明 shedlock redis遇到的问题1.配置shedlock不生效2.报错net/javacrumbs/shedlock/core/LockProvider shedlock升级高版本同名定时任务 前言 多节点或者多服务器拥有相同的定时任务,这种情况下,不同节…...

【Golang】Gorm乐观锁optimisticlock的使用
在数据库操作中,为了保证数据的一致性和完整性,常常需要采取一些措施来防止并发操作导致的数据冲突。悲观锁和乐观锁是两种常见的并发控制机制。 悲观锁(Pessimistic Lock) 悲观锁的基本假设是,数据在并发访问时很可能…...

5分钟搞定中科蓝讯SDK编译:用CodeBlocks快速验证RV32-Toolchain环境配置
5分钟搞定中科蓝讯SDK编译:用CodeBlocks快速验证RV32-Toolchain环境配置 对于嵌入式开发者来说,搭建一个稳定可靠的开发环境往往是项目开发的第一步。中科蓝讯基于RISC-V架构的蓝牙芯片方案,以其高性价比和低功耗特性,在TWS耳机、…...

BetterNCM-Installer:如何一键解锁网易云音乐PC版的完整插件生态
BetterNCM-Installer:如何一键解锁网易云音乐PC版的完整插件生态 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 厌倦了网易云音乐PC版功能单一,想要体验更丰富…...

ChemCrow化学智能工具:3步快速掌握AI化学研究助手
ChemCrow化学智能工具:3步快速掌握AI化学研究助手 【免费下载链接】chemcrow-public Chemcrow 项目地址: https://gitcode.com/gh_mirrors/ch/chemcrow-public ChemCrow是一个基于Langchain构建的开源化学智能工具包,专为化学研究人员和爱好者设计…...

植物大战僵尸终极修改方案:PVZ Toolkit如何让经典游戏焕发新生
植物大战僵尸终极修改方案:PVZ Toolkit如何让经典游戏焕发新生 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 在植物大战僵尸这款经典塔防游戏发布十多年后,许多玩家仍在寻…...

三月七小助手:5步配置《崩坏:星穹铁道》自动化工具的完整指南
三月七小助手:5步配置《崩坏:星穹铁道》自动化工具的完整指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 厌倦了《崩坏:星穹铁…...

从洗发水销量预测看LSTM过拟合:Keras中Dropout与recurrent_dropout的调参避坑指南
LSTM时间序列预测实战:洗发水销量预测中的Dropout调参艺术 1. 时间序列预测的挑战与LSTM优势 时间序列数据预测一直是机器学习领域最具挑战性的任务之一。与传统的表格数据不同,时间序列数据具有明显的时间依赖性,前后观测值之间存在复杂的非…...

别再搞混了!UE5角色移动时,GetActorForwardVector和GetControlRotation到底该用哪个?
UE5角色移动方向选择指南:GetActorForwardVector与GetControlRotation的实战解析 在虚幻引擎5的角色移动开发中,方向控制是最基础却最容易出错的环节之一。许多开发者都经历过角色莫名转圈、移动抖动或朝向异常的困扰——这些问题往往源于对GetActorForw…...

如何高效提取SWF资源:JPEXS Free Flash Decompiler终极指南
如何高效提取SWF资源:JPEXS Free Flash Decompiler终极指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 还在为无法从SWF文件中提取图像和音频而烦恼吗?面对那…...

Vivado 中 Xilinx DDR4 MIG 的实战配置与性能调优
1. DDR4 MIG IP核基础配置 在Vivado中配置DDR4 MIG(Memory Interface Generator)IP核是搭建高速存储系统的第一步。我最近在一个数据采集项目中就遇到了这个需求,当时需要处理每秒超过5GB的传感器数据流。下面分享我的实战经验,帮…...

SteamCleaner终极指南:3步快速释放游戏缓存,轻松回收硬盘空间
SteamCleaner终极指南:3步快速释放游戏缓存,轻松回收硬盘空间 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://…...