Elasticsearch:基于 Langchain 的 Elasticsearch Agent 对文档的搜索

在今天的文章中,我们将重点介绍如何使用 LangChain 提供的基础设施在 Python 中构建 Elasticsearch agent。 该 agent 应允许用户以自然语言询问有关 Elasticsearch 集群中数据的问题。
Elasticsearch 是一个强大的搜索引擎,支持词法和向量搜索。 ElasticSearch 可以在 RAG(检索增强生成)的上下文中使用,但这不是我们在本故事中的主题。 因此,我们不会使用 Elasticsearch 检索文档来创建注入提示中的上下文。 相反,我们在 agent 的上下文中使用 Elasticsearch,即我们正在构建一个 agent,它以自然语言与 Elasticsearch 进行通信,并执行搜索和聚合查询并解释这些查询。
为了方便大家学习,我们需要克隆如下的两个代码仓库:
- GitHub - liu-xiao-guo/elasticsearch-agent: ElasticSearch agent based on ElasticSearch, LangChain and ChatGPT 4
- GitHub - liu-xiao-guo/elasticsearch-agent-chainlit: Provides a simple UI for the ElasticSearch LangChain Agent
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

我们记下上面的 elastic 用户密码以及 fingerprint 的值。它们将在下面的配置中进行使用。
构建代理的秘诀
Elasticsearch agent
如果我们从如何编译 agent 的角度来看,我们将拥有以下成分:
- LLM(大型语言模型):你可以使用使用 ChatGPT 4 8K 模型。 我们也尝试过ChatGPT 3.5 16K模型,但结果不是很好。
- 4 个 自制 agent 工具:
- elastic list indices:获取所有可用 Elasticsearch 索引的工具
- elastic index show details:获取单个Elasticsearch索引信息的工具
- elastic index show data:用于从 Elasticsearch 索引获取条目列表的工具,有助于找出可用的数据。
- elastic search tool:该工具对 Elastisearch 索引执行特定查询并返回所有命中或聚合结果
- Specialised prompting:我们使用了一些特殊的指令来让 agent 正常工作。 提示指示代理首先获取索引的名称,然后获取索引字段名称。 没有内存相关指令的主要 prompt 是:
f"""Make sure that you query first the indices in the ElasticSearch database.Make sure that after querying the indices you query the field names. Then answer this question:{question}"""我们首先使用如下的命令来克隆 elasticsearch-agent 的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-agent然后我们在当前的目录下创建一个叫做 .env 的文件:
.env
OPENAI_API_KEY=YourOpenAiKey
OPENAI_MODEL=gpt-4-0613
# OPENAI_MODEL=gpt-3.5-turbo-16k-0613
REQUEST_TIMEOUT=300
LANGCHAIN_CACHE=false
CHATGPT_STREAMING=false
LLM_VERBOSE=true# Elastic Search related
ELASTIC_SERVER=https://127.0.0.1:9200
ELASTIC_USER=elastic
ELASTIC_PASSWORD=q2rqAIphl-fx9ndQ36CO
CERT_FINGERPRINT=bce66ed55097f255fc8e4420bdadafc8d609cc8027038c2dd09d805668f3459e
ELASTIC_VERIFY_CERTIFICATES=trueELASTIC_INDEX_DATA_FROM=0
ELASTIC_INDEX_DATA_SIZE=5
ELASTIC_INDEX_DATA_MAX_SIZE=50LANGCHAIN_VERBOSE=true
AGGS_LIMIT=200
TOKEN_LIMIT=6000
MAX_SEARCH_RETRIES = 100在上面,你需要根据自己的 Elasticsearch 配置来配置:
- OPENAI_API_KEY:你需要申请自己的 OpenAI key
- ELASTIC_SERVER:Elasticsearch 的终端地址
- ELASTIC_USER:超级用户的账号名称。你也可以使用自己创建的其它账号
- ELASTIC_PASSWORD:超级用户 elastic 的密码
- CERT_FINGERPRINT:这个是 Elasticsearch 的证书的 fingerprint。可以在 Elasticsearch 启动的画面中找到
在当前的目录下,我们使用如下的命令来进行打包及安装:
python3 -m venv .venv
source .venv/bin/activate$ pwd
/Users/liuxg/python/elasticsearch-agent
$ python3 -m venv .venv
$ source .venv/bin/activate我们然后安装 peorty:
pip3 install poetry接下来,我们使用如下的命令来进行打包并安装:
rm poetry.lock
poetry install(.venv) $ rm poetry.lock
(.venv) $ poetry install
Updating dependencies
Resolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/a7/94/ace0fdea5241a27d13543ee117cbc65868e82213fb31a8eb7fe9ff23f313/numpy-1.26.4-cp310-cp310-macosx_10_9_x86_64.wResolving dependencies... Downloading https://files.pythonhosted.org/packages/12/f6/0232cc0c617Resolving dependencies... (22.7s)Package operations: 0 installs, 23 updates, 0 removals• Updating typing-extensions (4.8.0 -> 4.9.0)• Updating certifi (2023.7.22 -> 2024.2.2)• Updating charset-normalizer (3.3.0 -> 3.3.2)• Updating frozenlist (1.4.0 -> 1.4.1)• Updating idna (3.4 -> 3.6)• Updating multidict (6.0.4 -> 6.0.5)• Updating pydantic-core (2.10.1 -> 2.16.2)• Updating urllib3 (1.26.17 -> 2.2.1)• Updating attrs (23.1.0 -> 23.2.0)• Updating marshmallow (3.20.1 -> 3.20.2)• Updating pydantic (2.4.2 -> 2.6.1)• Updating yarl (1.9.2 -> 1.9.4)• Updating aiohttp (3.8.6 -> 3.9.3)• Updating dataclasses-json (0.6.1 -> 0.6.4)• Updating elastic-transport (8.4.1 -> 8.12.0)• Updating langsmith (0.0.43 -> 0.0.92)• Updating numpy (1.25.2 -> 1.26.4)• Updating regex (2023.10.3 -> 2023.12.25)• Updating sqlalchemy (2.0.21 -> 2.0.27)• Updating tqdm (4.66.1 -> 4.66.2)• Updating elasticsearch (8.10.0 -> 8.12.1)• Updating python-dotenv (1.0.0 -> 1.0.1)• Updating tiktoken (0.5.1 -> 0.5.2)Writing lock fileInstalling the current project: elasticsearch-agent (0.1.7)我们使用如下的命令来进行构建:
poetry build(.venv) $ poetry build
Building elasticsearch-agent (0.1.7)- Building sdist- Built elasticsearch_agent-0.1.7.tar.gz- Building wheel- Built elasticsearch_agent-0.1.7-py3-none-any.whl
(.venv) $ ls 我们可以通过如下的命令来进行检查是否已经生成安装文件:
(.venv) $ pwd
/Users/liuxg/python/elasticsearch-agent
(.venv) $ ls
README.md dist elasticsearch_agent pyproject.toml
datasets docs poetry.lock
(.venv) $ ls dist/
elasticsearch_agent-0.1.7-py3-none-any.whl elasticsearch_agent-0.1.7.tar.gzelasticsearch-agent-chainlit
我们在另外一个 terminal 中使用如下的命令来克隆代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-agent-chainlit此功能中使用的 prompt 最多包含用户之前的 5 个问题。 这是一种仅通过问题来记忆的简单尝试。 它还包含从 Elasticsearch 获取每个问题的索引和详细信息的说明。
我们使用同样的方法来创建虚拟环境:
python3 -m venv .venv
source .venv/bin/activate我们在当前的目录下创建一个和上面 elasticsearch-agent 项目中一样的 .env 文件:
.env
OPENAI_API_KEY=YourOpenAIkey
OPENAI_MODEL=gpt-4-0613
# OPENAI_MODEL=gpt-3.5-turbo-16k-0613
REQUEST_TIMEOUT=300
LANGCHAIN_CACHE=false
CHATGPT_STREAMING=false
LLM_VERBOSE=true# Elastic Search related
ELASTIC_SERVER=https://127.0.0.1:9200
ELASTIC_USER=elastic
ELASTIC_PASSWORD=q2rqAIphl-fx9ndQ36CO
CERT_FINGERPRINT=bce66ed55097f255fc8e4420bdadafc8d609cc8027038c2dd09d805668f3459e
ELASTIC_VERIFY_CERTIFICATES=trueELASTIC_INDEX_DATA_FROM=0
ELASTIC_INDEX_DATA_SIZE=5
ELASTIC_INDEX_DATA_MAX_SIZE=50LANGCHAIN_VERBOSE=true
AGGS_LIMIT=200
TOKEN_LIMIT=6000
MAX_SEARCH_RETRIES = 100
QUESTIONS_TO_KEEP=5但是我们需要额外添加 QUESTIONS_TO_KEEP=5。
在进行安装之前,我们需要根据上一步所生成的安装包的位置来修改 pyproject.toml 文件:
pyproject.toml
[tool.poetry]
name = "elasticsearch-chainlit"
version = "0.1.0"
description = "Provides a simple UI for the ElasticSearch LangChain Agent."
authors = ["Gil Fernandes <gil.fernandes@onepointltd.com>"]
readme = "README.md"[tool.poetry.dependencies]
python = "^3.11"
chainlit = "^0.7.2"
elasticsearch-agent = {path = "../elasticsearch-agent/dist/elasticsearch_agent-0.1.7-py3-none-any.whl", develop = true}[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"我们需要修改 elasticsearch-agent 的值。
我们使用如下的命令来运行上面的代码:
poetry install(.venv) $ pwd
/Users/liuxg/python/elasticsearch-agent-chainlit
(.venv) $ poetry install
Installing dependencies from lock fileNo dependencies to install or updateInstalling the current project: elasticsearch-chainlit (0.1.0)我们可以通过如下的命令来查看所安装的包:
(.venv) $ pip3 list | grep elasticsearch
elasticsearch 8.12.1
elasticsearch-agent 0.1.7
elasticsearch-chainlit 0.1.0 /Users/liuxg/python/elasticsearch-agent-chainlit接下来,我们使用如下的命令来运行:
chainlit run ./elasticsearch_chainlit/ui/agent_chainlit.py 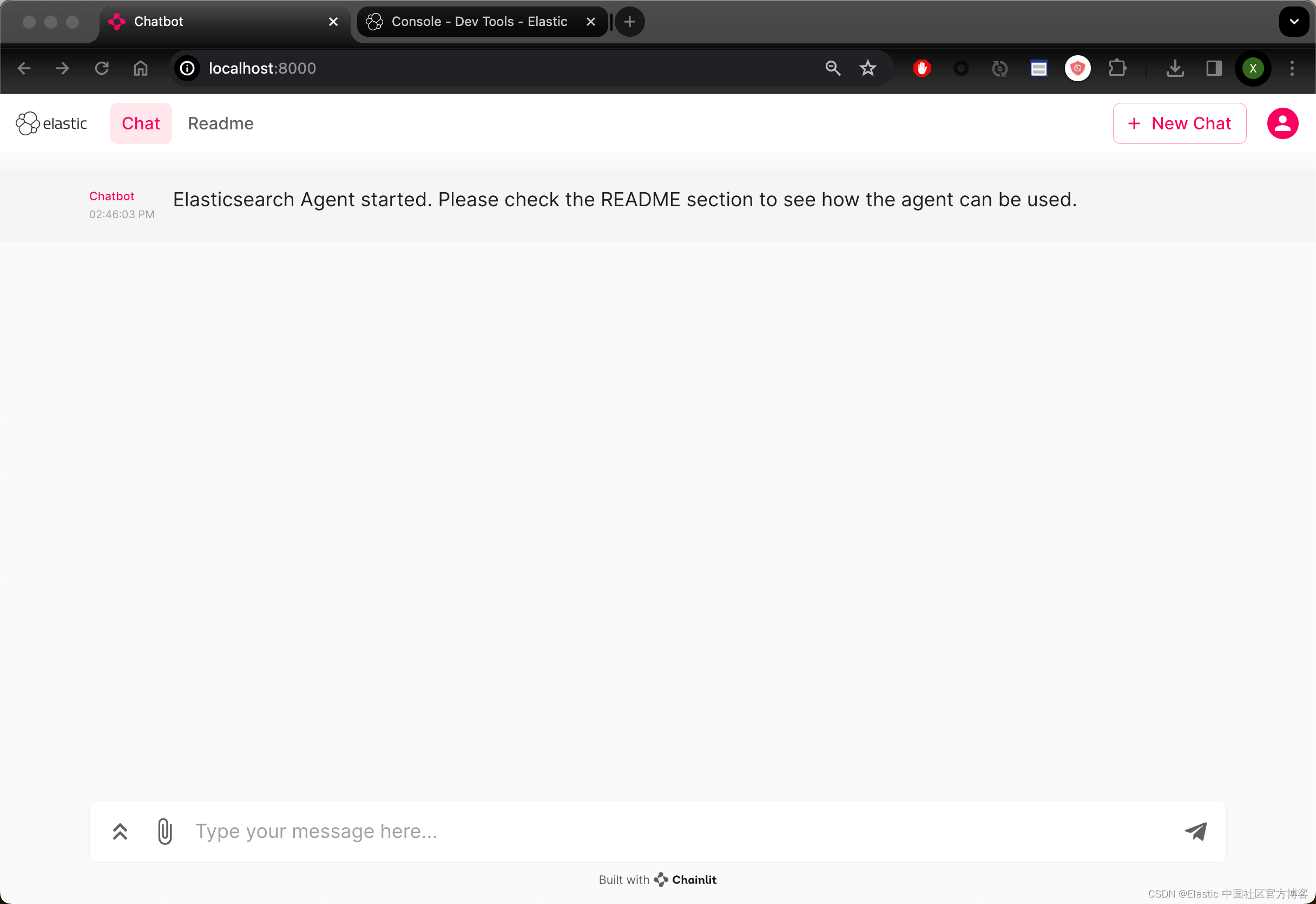
上面是我们能看到的界面。在运行代码时,一定要确保 chainlit 出于最新的版本。在早期的版本中,question 是一个 dict 类型的数据而不是 str:
elasticsearch_chainlit/ui/agent_chainlit.py

Agent 工作流程
Elasticsearch agent 工作流程
工作流程有两部分:
设置 — 执行三个步骤:
- 初始化工具
- 设置 LLM 模型
- 设置 agent,包括提示
执行流程 — 以下是工作流程步骤:
- 用户提出问题
- LLM 分析问题
- 网关:决定使用哪个工具。 在某些情况下,可能没有任何工具可以完成该任务。
- 网关案例 1:找到工具 — 执行工具并接收其观察结果。 在我们的例子中,这是一个 JSON 响应。
- 网关案例 2:未找到工具 — 工作流程以错误消息结束。
- 如果找到工具:该工具的观察结果将发送回 LLM。
- 网关:决定使用哪个工具,或者是否找不到工具并且流程终止,或者我们是否有最终答案。 如果决定使用该工具,我们将再次循环执行相同的步骤。
执行流程是循环的,直到找到最终答案。 这意味着对于一个问题,agent 可以访问多个工具,甚至多次访问同一个工具。
通常,工作流程会在与 LLM 交互 15 次并出现错误后停止。
工具列表:
- 列表索引工具:此工具列出 Elasticsearch 索引,通常在 agent 每次回答任何问题时调用。 该工具接收分隔符作为输入,并输出由它分隔的索引列表。
- 索引详细信息工具:该工具列出特定索引的别名、映射和设置。 它接收 Elasticsearch 索引名称作为输入。
- 索引数据工具:该工具用于从 Elasticsearch 索引中获取条目列表,有助于找出可用的数据。 根据我的测试,这是 ChatGPT 使用最少的工具。
- 索引搜索工具:此工具是搜索工具,需要输入索引、查询以及查询的起始位置和长度。 它解析查询并尝试确定查询是搜索还是聚合查询,并根据返回结果(如果是搜索)或聚合(如果是聚合查询)。 但它也试图避免响应的 token 大小超过某个阈值,因此可能会重试查询。 这是这个工具的主要方法。在此文件中,你可以找到输入模型(SearchToolInput)和该工具的运行方法(elastic_search):
展示
首先,我们使用 ChatGPT 来生成一个样本文档。

PUT /people
{"mappings": {"properties": {"name": {"type": "text"},"description": {"type": "text"},"sex": {"type": "keyword"},"age": {"type": "integer"},"address": {"type": "text"}}}
}POST /_bulk
{ "index" : { "_index" : "people", "_id" : "1" } }
{ "name" : "John Doe", "description" : "A software developer", "sex" : "Male", "age" : 30, "address" : "123 Elm Street, Springfield" }
{ "index" : { "_index" : "people", "_id" : "2" } }
{ "name" : "Jane Smith", "description" : "A project manager", "sex" : "Female", "age" : 28, "address" : "456 Maple Avenue, Anytown" }
{ "index" : { "_index" : "people", "_id" : "3" } }
{ "name" : "Alice Johnson", "description" : "A graphic designer", "sex" : "Female", "age" : 26, "address" : "789 Oak Lane, Metropolis" }
{ "index" : { "_index" : "people", "_id" : "4" } }
{ "name" : "Bob Brown", "description" : "A marketing specialist", "sex" : "Male", "age" : 32, "address" : "321 Pine Street, Gotham" }
{ "index" : { "_index" : "people", "_id" : "5" } }
{ "name" : "Charlie Davis", "description" : "An IT analyst", "sex" : "Male", "age" : 29, "address" : "654 Cedar Blvd, Star City" }
{ "index" : { "_index" : "people", "_id" : "6" } }
{ "name" : "Diana Prince", "description" : "A diplomat", "sex" : "Female", "age" : 35, "address" : "987 Birch Road, Themyscira" }
{ "index" : { "_index" : "people", "_id" : "7" } }
{ "name" : "Evan Wright", "description" : "A journalist", "sex" : "Male", "age" : 27, "address" : "213 Willow Lane, Central City" }
{ "index" : { "_index" : "people", "_id" : "8" } }
{ "name" : "Fiona Gallagher", "description" : "A nurse", "sex" : "Female", "age" : 31, "address" : "546 Spruce Street, South Side" }
{ "index" : { "_index" : "people", "_id" : "9" } }
{ "name" : "George King", "description" : "A teacher", "sex" : "Male", "age" : 34, "address" : "879 Elm St, Smallville" }
{ "index" : { "_index" : "people", "_id" : "10" } }
{ "name" : "Helen Parr", "description" : "A full-time superhero", "sex" : "Female", "age" : 37, "address" : "123 Metro Avenue, Metroville" } 
这样我们就创建了一个叫做 people 的索引。我们现在以这个索引为例来进行展示:
what are the indices in the cluster?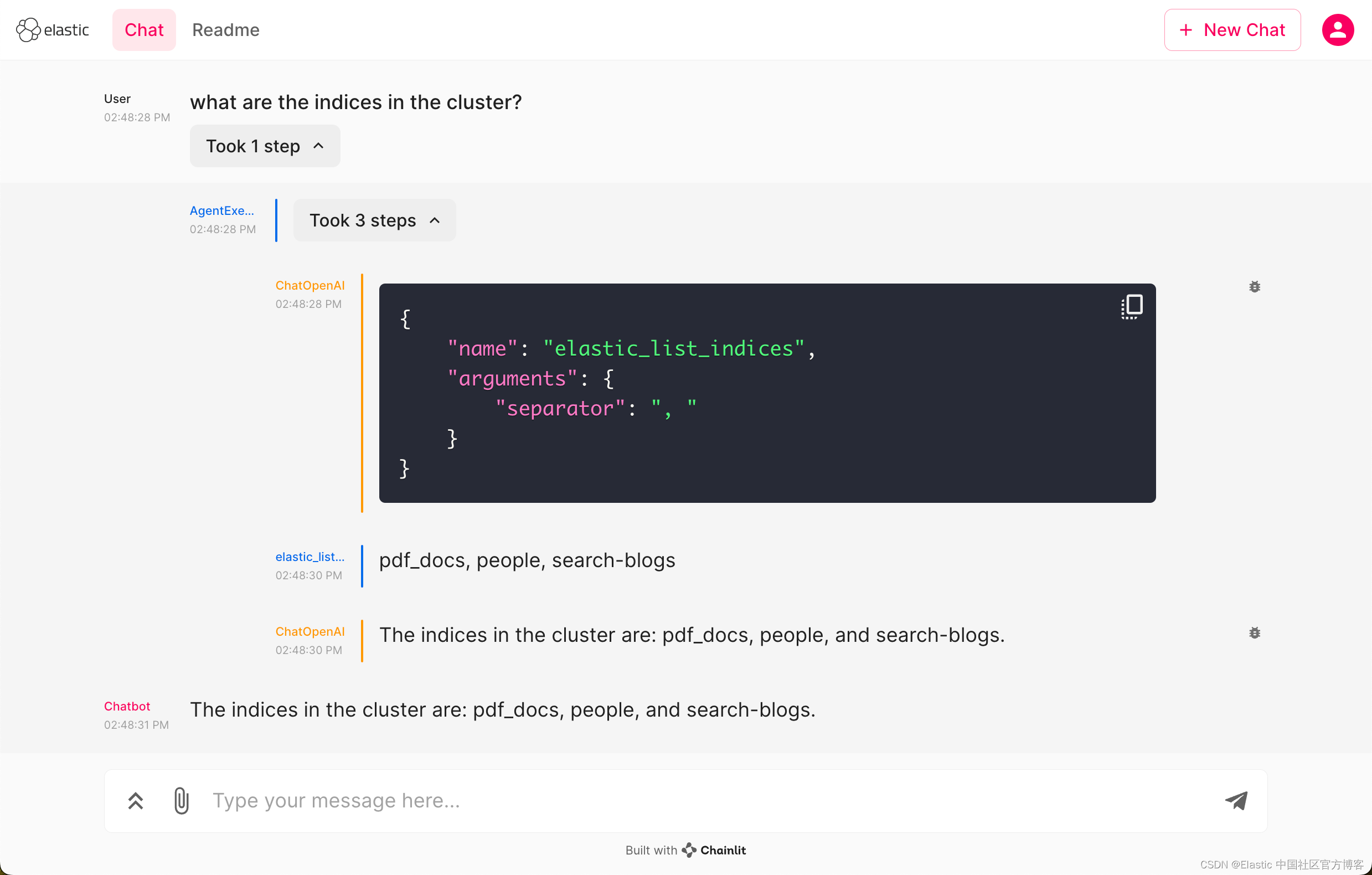
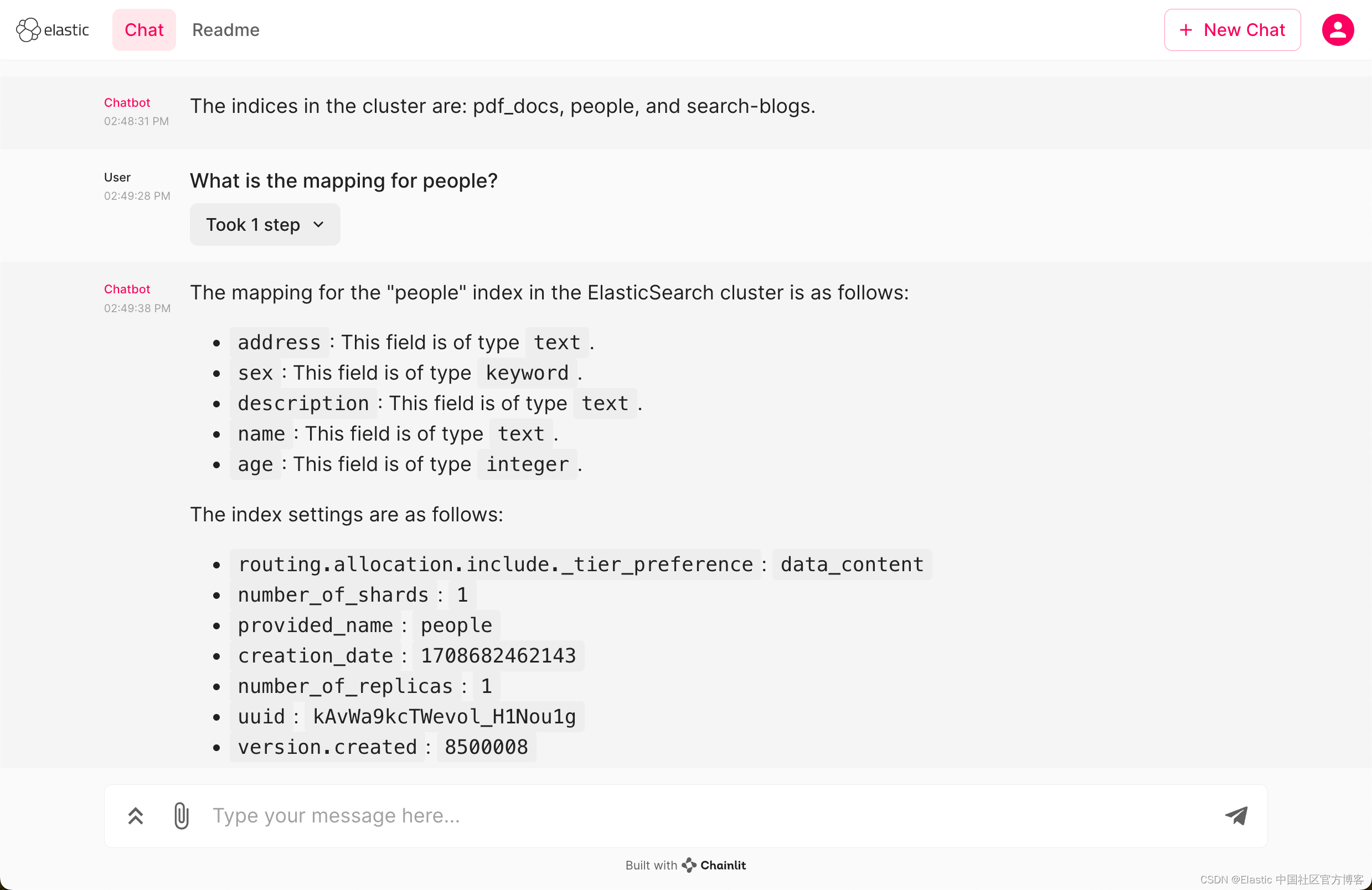
How many documents are there in the index people?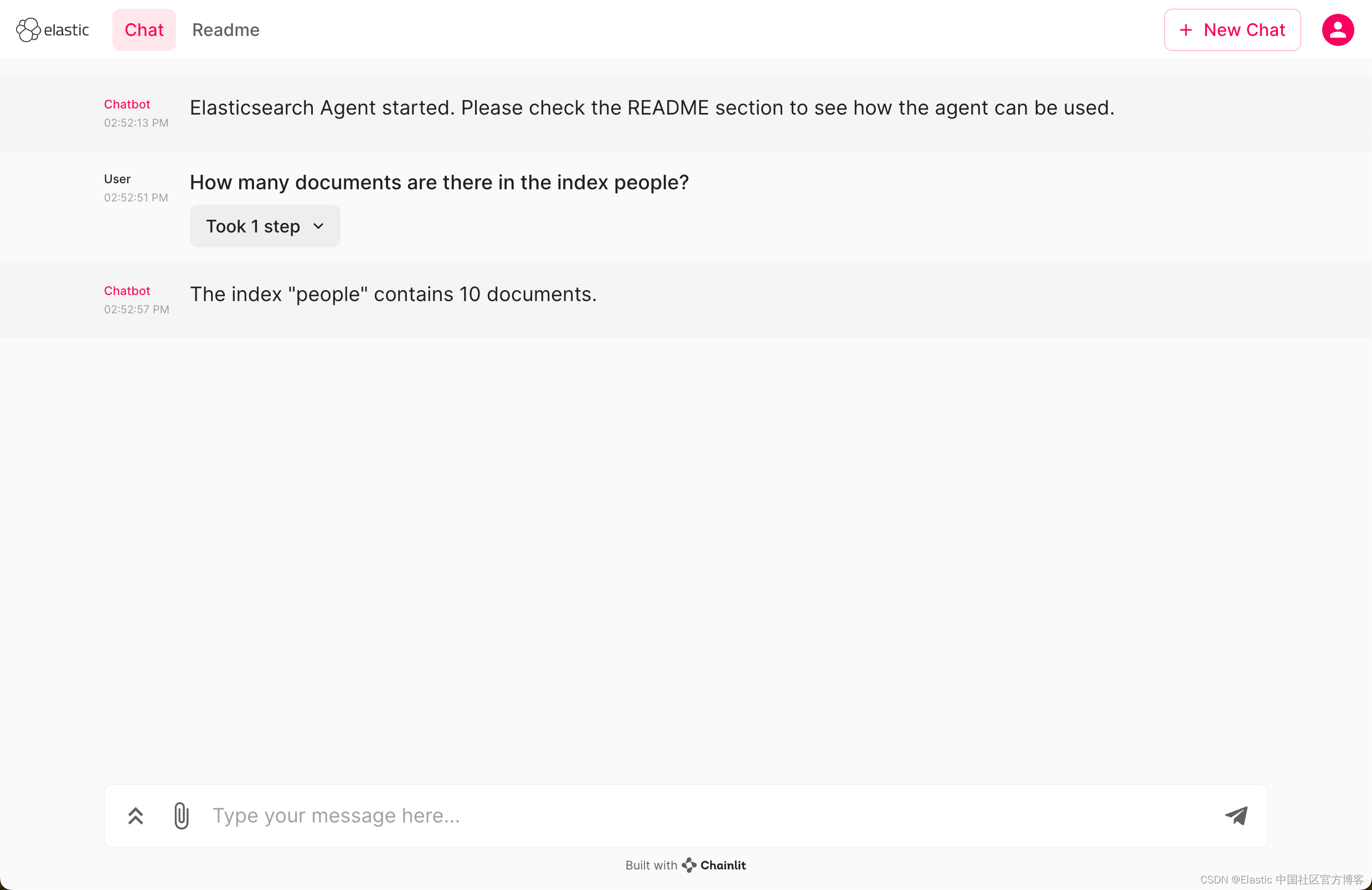
Which document has the biggest age? 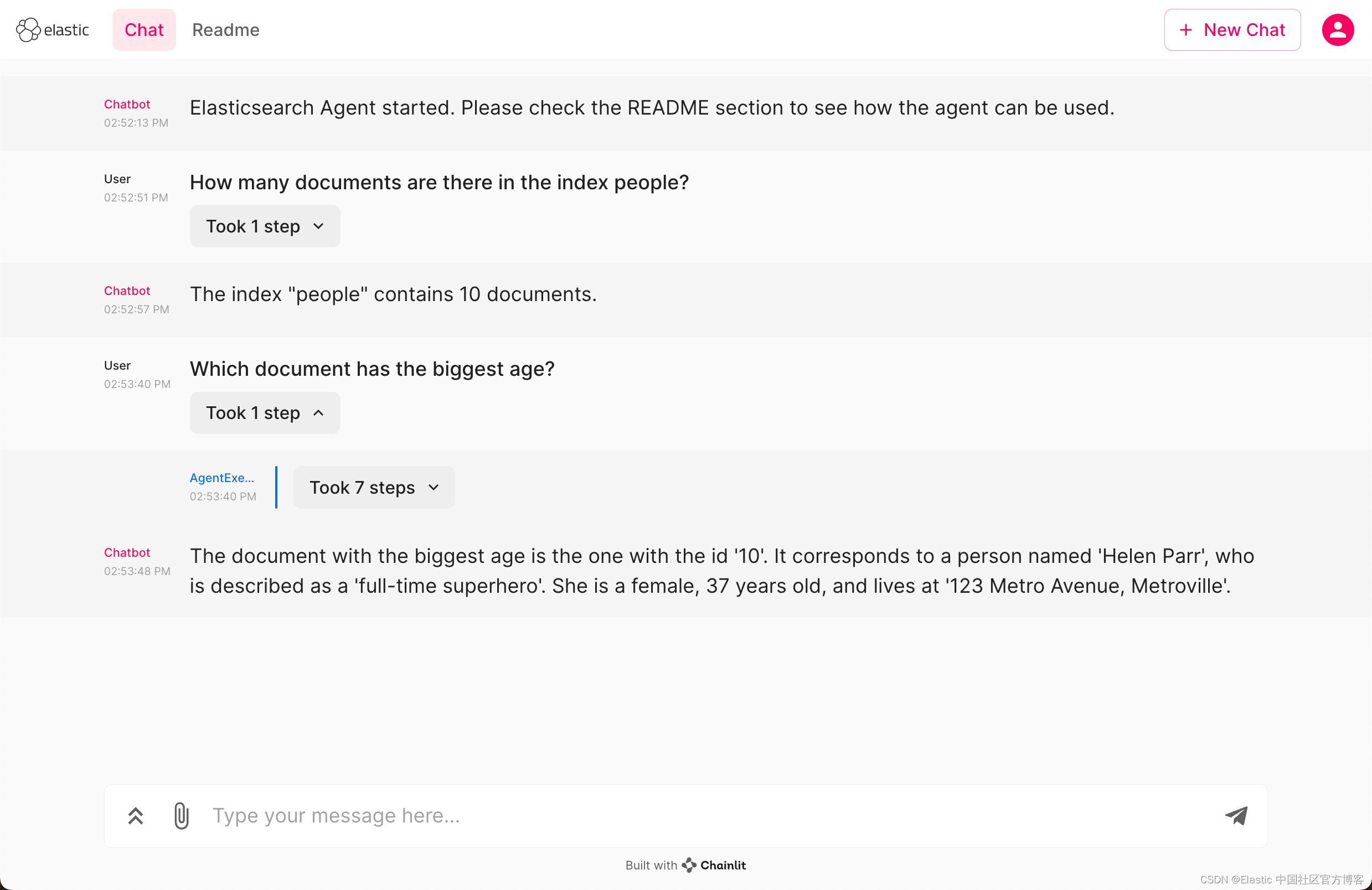
让我们针对索引 people 做一个聚合:
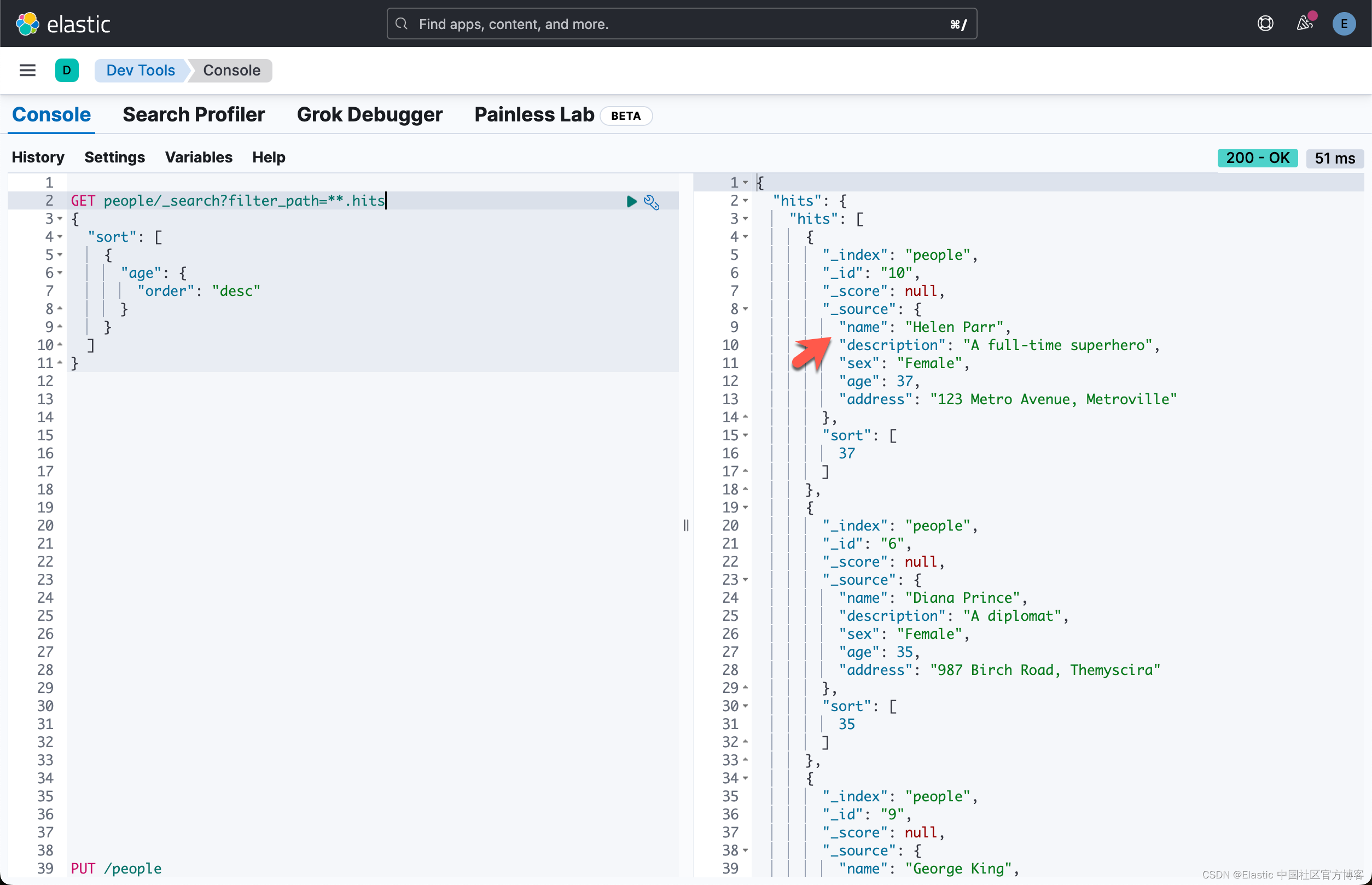
很显然我们的结果是非常正确的。
How many males and females in the index people? 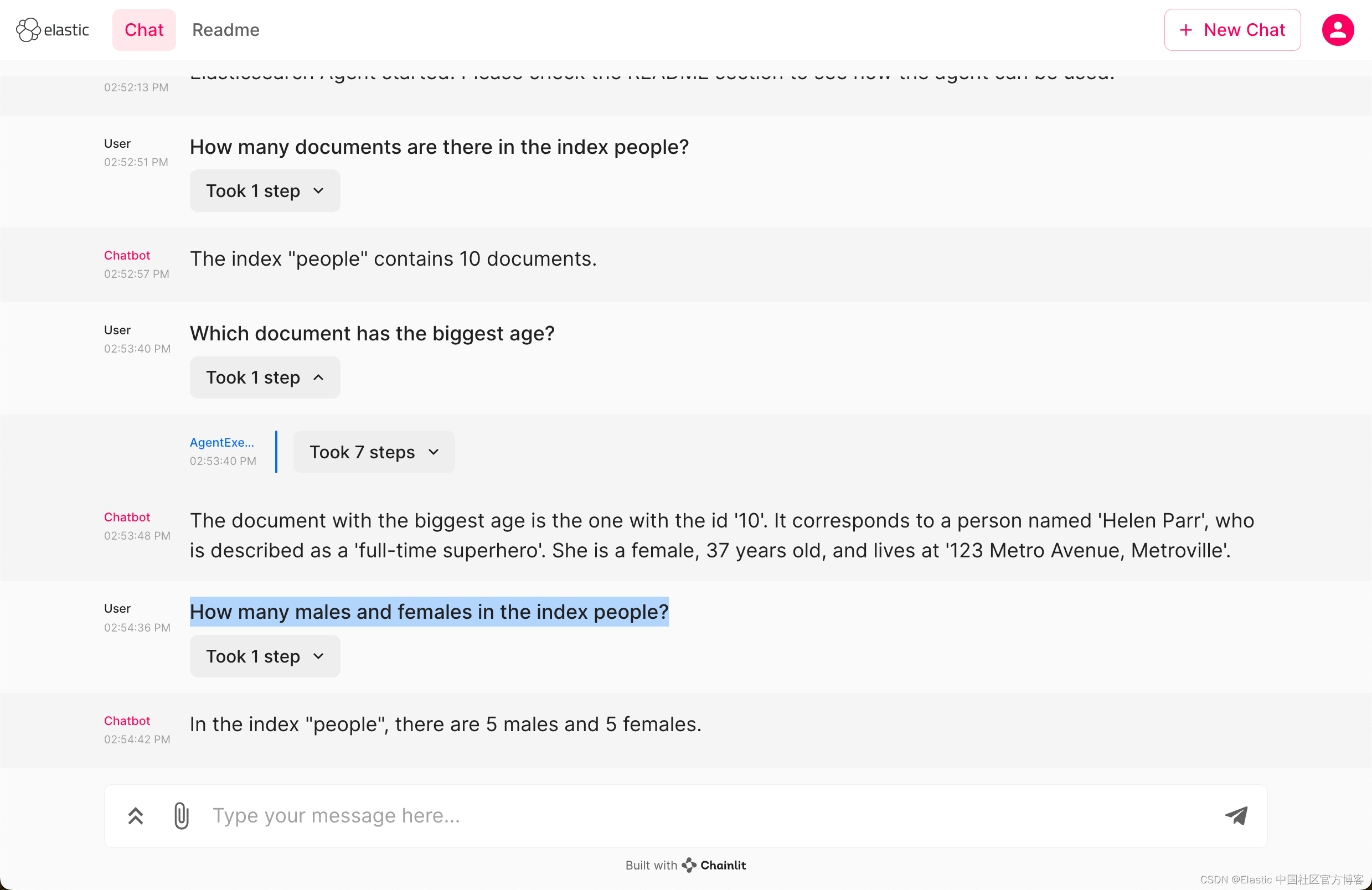

很显然它是对的。
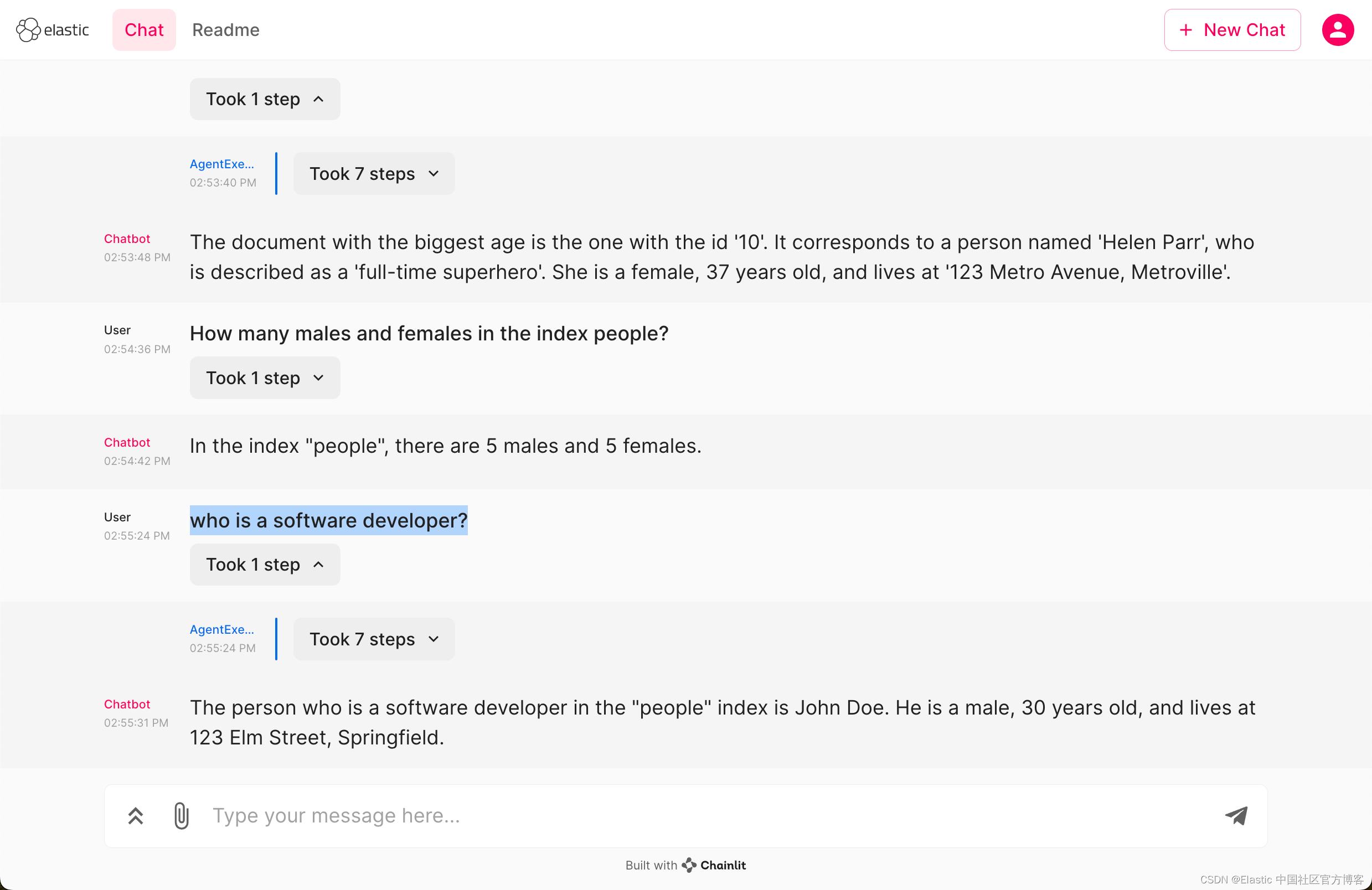

who lives in Metropolis? 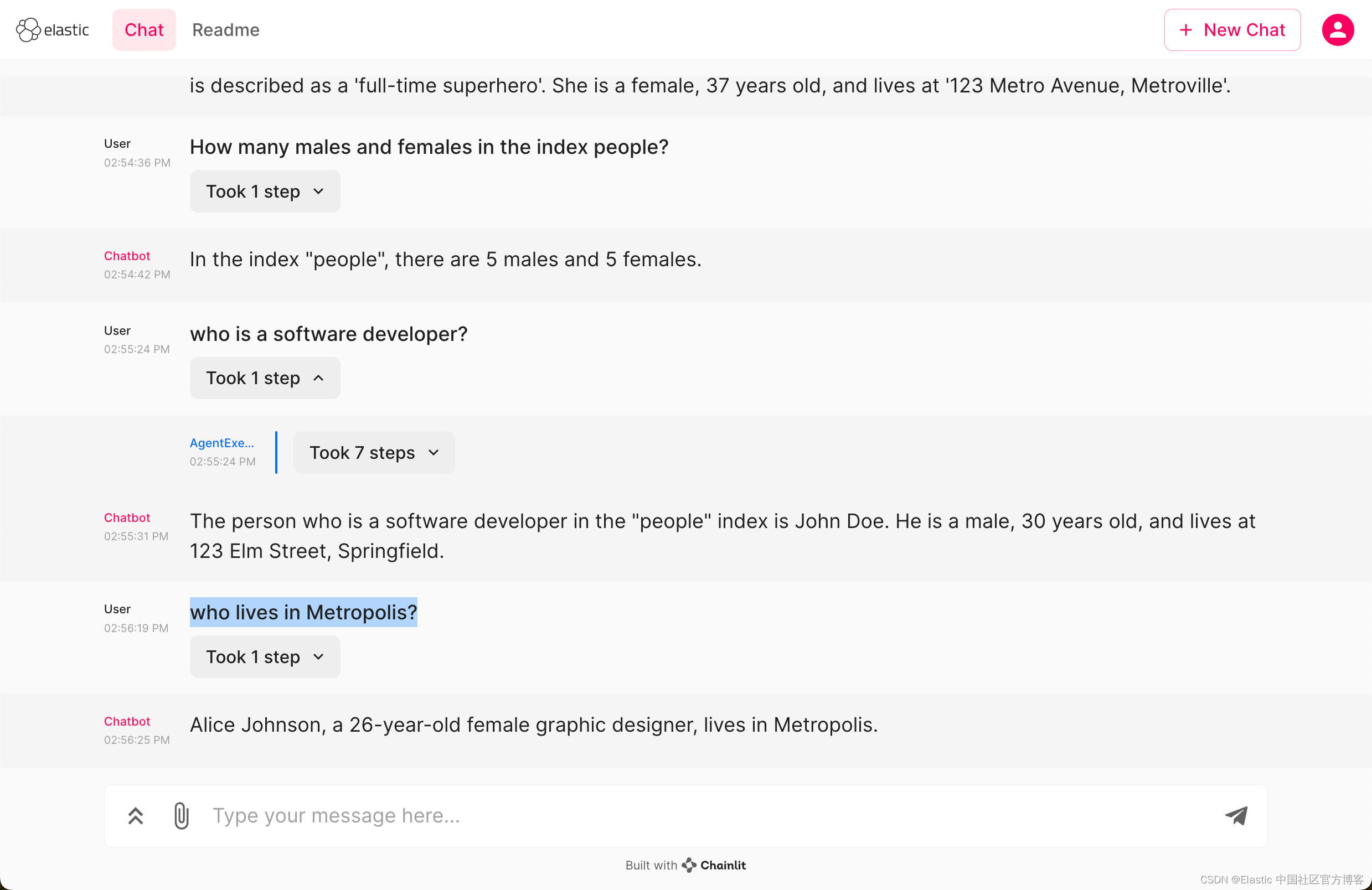
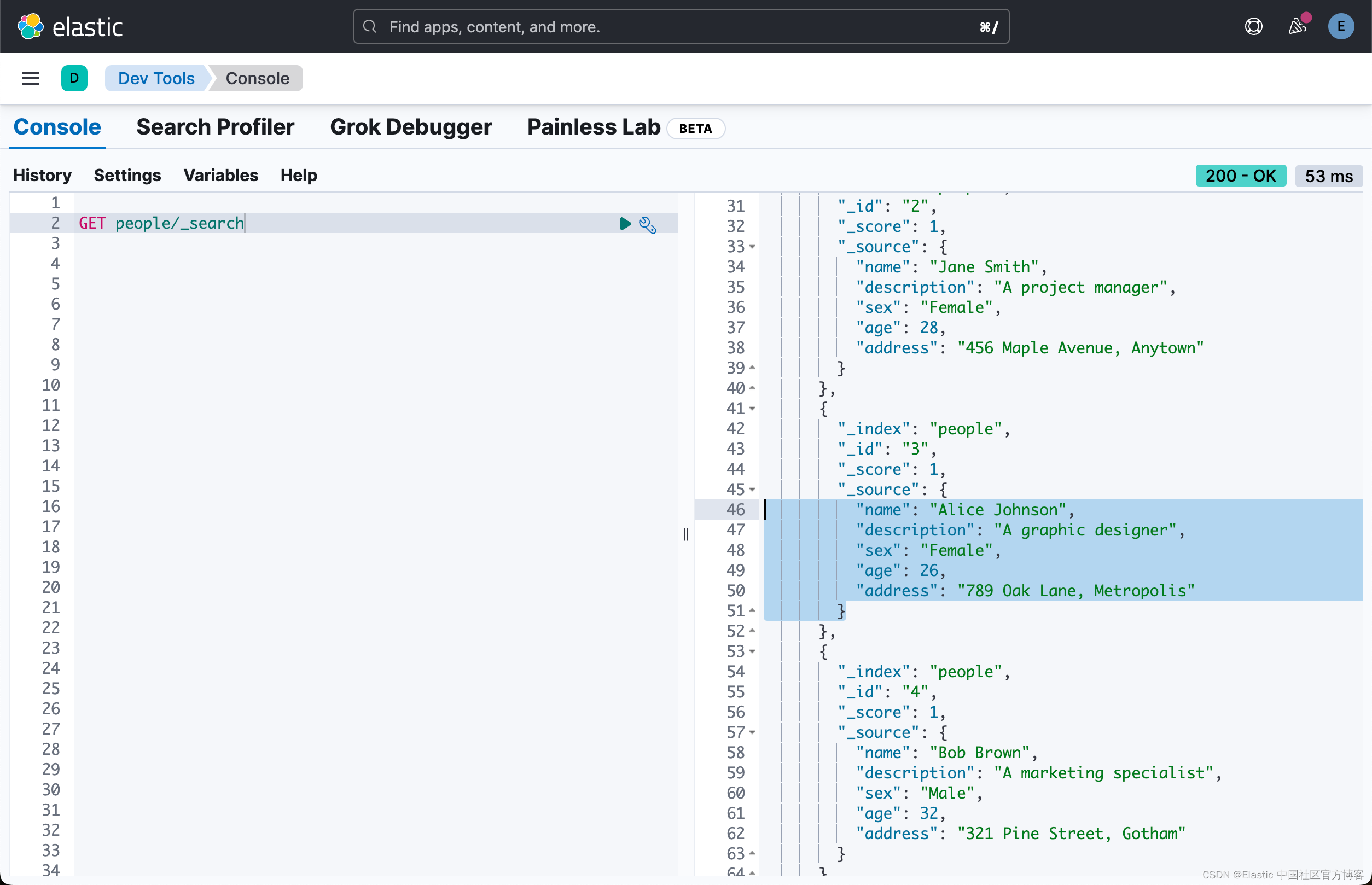
最后,让我们试一下中文的搜索:
哪一个文档的年龄最大? 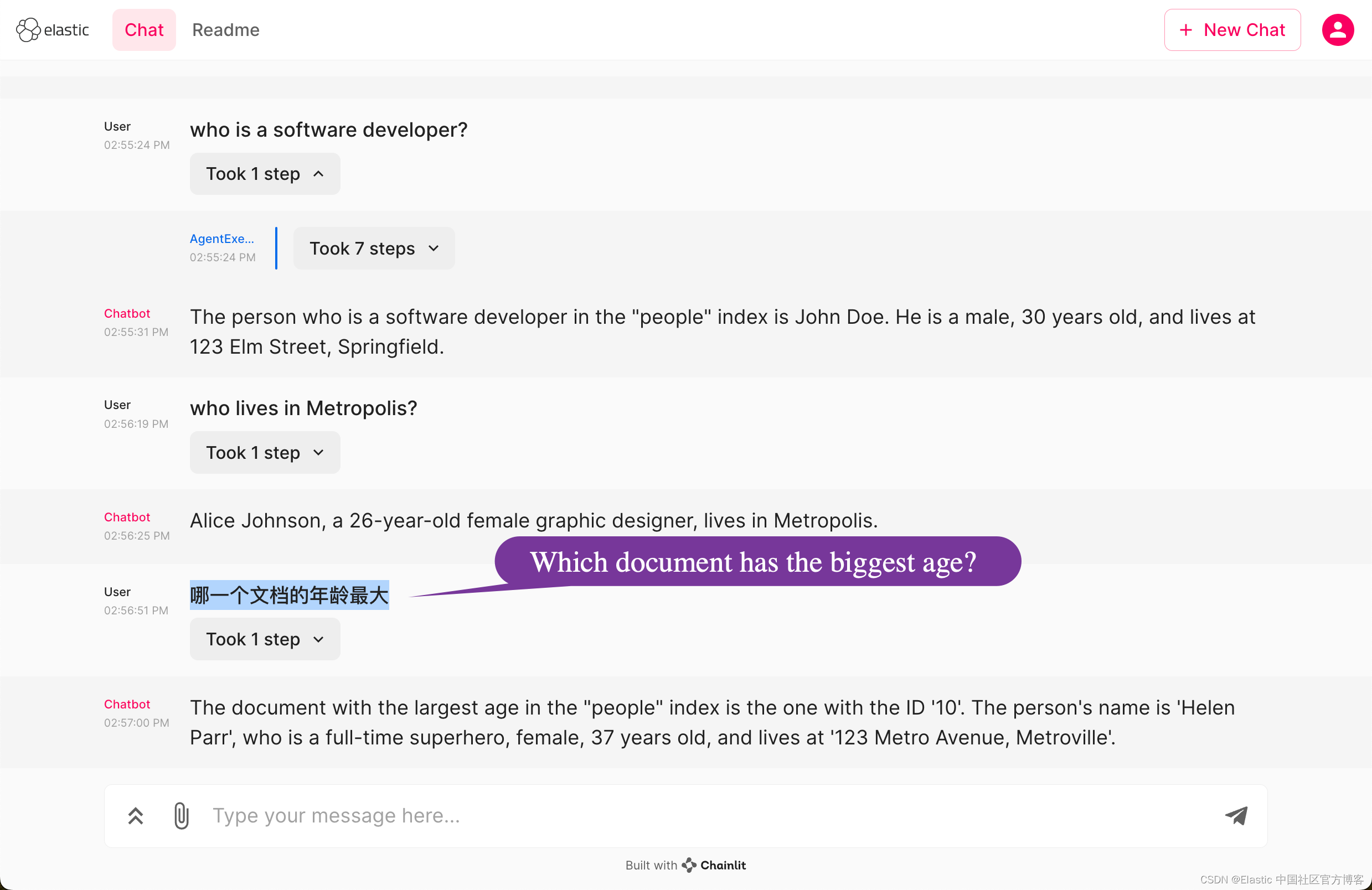
我们还可以做任何其他的尝试。它可以充分了解我的需求,并做出正确的搜索。
Happy exploration :)
相关文章:
Elasticsearch:基于 Langchain 的 Elasticsearch Agent 对文档的搜索
在今天的文章中,我们将重点介绍如何使用 LangChain 提供的基础设施在 Python 中构建 Elasticsearch agent。 该 agent 应允许用户以自然语言询问有关 Elasticsearch 集群中数据的问题。 Elasticsearch 是一个强大的搜索引擎,支持词法和向量搜索。 Elast…...
学习python的第7天,她不再开放她的听歌榜单
我下午登录上小号,打开聊天消息看到了她的回复,我很开心兴奋,可是她不再开放她的听歌榜单了,我感觉得到,我要失恋了。 “因为当年电视上看没有王菲版本的” “行”。 “那你以后还会开放听歌榜单吗?”我…...

多维时序 | Matlab实现CPO-BiTCN-BiGRU冠豪猪优化时间卷积神经网络双向门控循环单元多变量时间序列预测模型
多维时序 | Matlab实现CPO-BiTCN-BiGRU冠豪猪优化时间卷积神经网络双向门控循环单元多变量时间序列预测模型 目录 多维时序 | Matlab实现CPO-BiTCN-BiGRU冠豪猪优化时间卷积神经网络双向门控循环单元多变量时间序列预测模型预测效果基本介绍程序设计参考资料 预测效果 基本介绍…...
低代码与大语言模型的探索实践
低代码系列文章: 可视化拖拽组件库一些技术要点原理分析可视化拖拽组件库一些技术要点原理分析(二)可视化拖拽组件库一些技术要点原理分析(三)可视化拖拽组件库一些技术要点原理分析(四)低代码…...
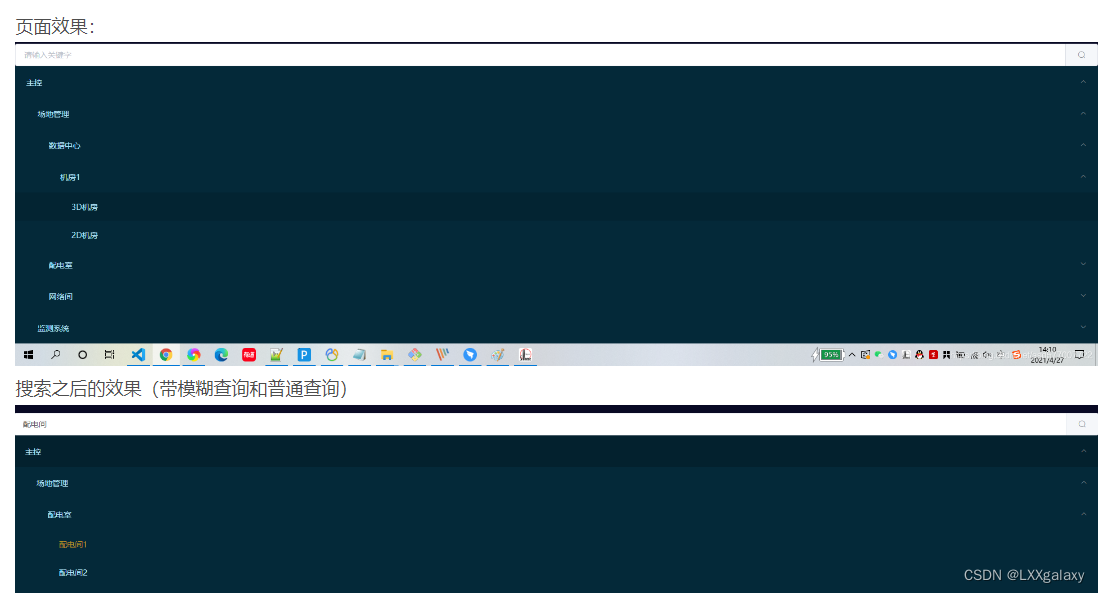
element导航菜单el-menu添加搜索功能
element导航菜单-侧栏,自带的功能没有搜索或者模糊查询。 找了找资料 找到一个比较可行的,记录一下: //index.vue的代码 <div style"overflow:auto"><el-menu :default-active"$route.path":default-openeds&…...

浅析SpringBoot框架常见未授权访问漏洞
文章目录 前言Swagger未授权访问RESTful API 设计风格swagger-ui 未授权访问swagger 接口批量探测 Springboot Actuator未授权访问数据利用未授权访问防御手段漏洞自动化检测工具 CVE-2022-22947 RCE漏洞原理分析与复现漏洞自动化利用工具 其他常见未授权访问Druid未授权访问漏…...

PostgreSQL内存上下文系统设计概述
PostgreSQL内存上下文系统设计概述 原文:src/backend/utils/mmgr/README 背景 我们在“内存上下文”中进行大部分内存分配,通常是AllocSets由src/backend/utils/mmgr/aset.c实现。在没有大量开销的情况下成功进行内存管理的关键是定义一组具有适当生命周期的有用…...

C++ 网络编程学习二
C 网络编程学习二 asio异步写操作asio异步读操作asio 异步echo服务端asio异步服务器中存在的隐患 asio异步写操作 async_write_some是异步写的函数:传入buffer和回调函数以及参数以后,发送后会调用回调函数。 void Session::WriteToSocketErr(const st…...

SpringMVC 学习(四)之获取请求参数
目录 1 通过 HttpServletRequest 获取请求参数 2 通过控制器方法的形参获取请求参数 3 通过 POJO 获取请求参数(重点) 1 通过 HttpServletRequest 获取请求参数 public String handler1(HttpServletRequest request) <form action"${pageCont…...
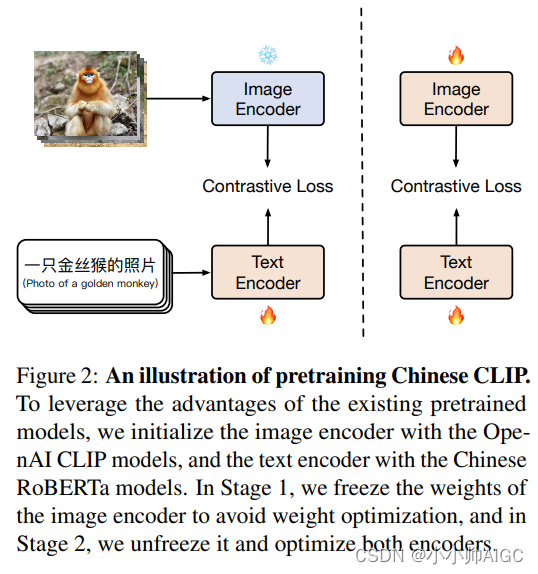
多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读
我之前一直在使用CLIP/Chinese-CLIP,但并未进行过系统的疏导。这次正好可以详细解释一下。相比于CLIP模型,Chinese-CLIP更适合我们的应用和微调,因为原始的CLIP模型只支持英文,对于我们的中文应用来说不够友好。Chinese-CLIP很好地…...

Git本地分支关联远程分支
Git本地分支关联远程分支 本地分支相关操作 查看本地分支 git branch新建本地分支 git branch name切换本地分支 git checkout name新建本地分支并切换到该分支 git checkout -b name #或 git branch name删除本地分支 git branch -d name git branch -D name #强制删除远程分…...

[FT]chatglm2微调
1.准备工作 显卡一张:A卡,H卡都可以,微调需要一张,大概显存得30~40G吧环境安装: 尽量在虚拟环境安装:参见,https://blog.csdn.net/u010212101/article/details/103351853环境安装参见ÿ…...
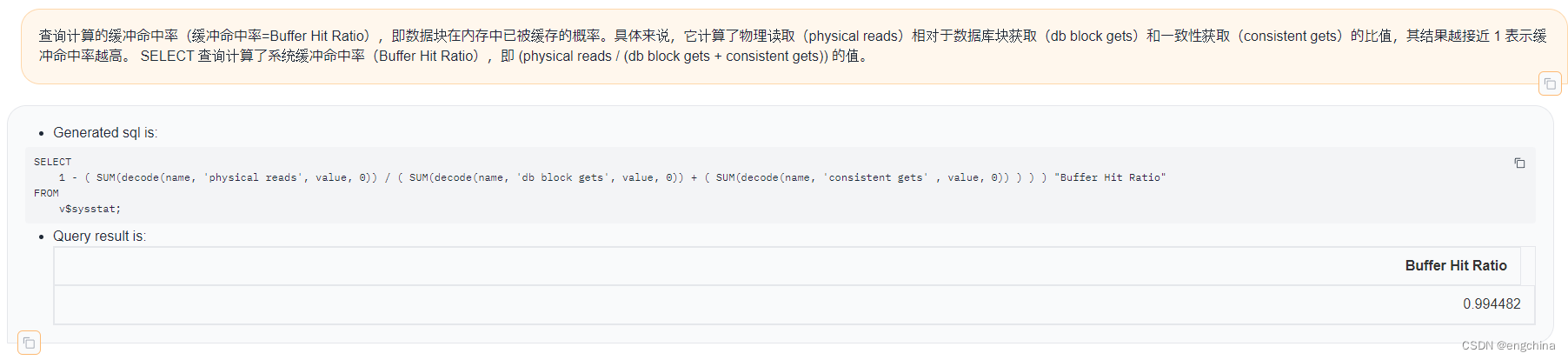
AI赋能Oracle DBA:以自然语言与Oracle数据库互动
DBA AI助手:以自然语言与Oracle数据库互动 0. 引言1. AI赋能Oracle DBA的优势2. AI如何与Oracle数据库交互3. 自然语言查询的一些示例4. 未来展望 0. 引言 传统的Oracle数据库管理 (DBA) 依赖于人工操作,包括编写复杂的SQL语句、分析性能指标和解决各种…...

Django学习记录04——靓号管理整合
1.靓号表 1.1 表结构 1.2 靓号表的构造 class PrettyNum(models.Model): 靓号表 mobile models.CharField(verbose_name"手机号", max_length11)# default 默认值# null true,blank true 允许为空price models.IntegerField(verbose_name"价…...
AD9226 65M采样 模数转换
目录 AD9220_ReadTEST AD9220_ReadModule AD9226_TEST_tb 自己再写个 260M的时钟,四分频来提供65M的时钟。 用 vivado 写的 AD9226_ReadTEST module AD9226_ReadTEST( input clk, input rstn,output clk_driver, //模块时钟管脚 input [12:0]IO_data, //模块数…...

远程控制桌面,让电脑办公更简单
随着科技的不断发展,远程办公已经成为了越来得越多企业和个人的选择。远程控制电脑办公,仅需1款软件即可轻松get! 1.绿虫电脑管理软件 是一款功能强大的办公电脑管理软件,仅需安装在被控端电脑,主控端通过网页登录后…...

猫头虎分享已解决Bug || 网络连接问题:NetworkError: Failed to fetch
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

Layer1 明星项目 Partisia Blockchain 何以打造互操作、可创新的数字经济网络
我们的目标是创建一个以用户为中心的全新数字经济网络:在去信任化和公平透明的环境下,所有的隐私数据都能够得到天然保障,企业、用户等各角色的协作与共享将会更顺利地进行。 —— Partisia Blockchain 团队 作为一个以 Web3 安全为技术方向的…...

用CSS制作弧形卡片的三种创意方法!
在平时开发中,有时候会碰到下面这种“弧形”样式,主要分为“内凹”和“外凸”两种类型,如下 该如何实现呢?或者想一下,有哪些 CSS 属性和“弧形”有关?下面介绍 3 种方式,一起看看吧 一、borde…...

守护健康之光 —— 小脑萎缩患者的生活指南
生活中,我们或许会遇到一些特殊的挑战,而面对这些挑战时,了解和掌握正确的应对策略至关重要。今天,我们要聊一聊一个较为少见却不容忽视的话题——小脑萎缩。这不仅是患者的战役,也是家人和社会共同的关怀课题。下面&a…...

QrazyBox终极指南:3分钟快速修复损坏二维码的完整教程
QrazyBox终极指南:3分钟快速修复损坏二维码的完整教程 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否遇到过打印模糊的二维码无法扫描?或者手机拍摄的付款码因为…...
 保姆级排查与修复指南(含代理设置详解))
Git克隆又报错?GnuTLS recv error (-110) 保姆级排查与修复指南(含代理设置详解)
Git克隆报错GnuTLS recv error (-110)全流程诊断手册:从网络配置到TLS深度解析 当你正专注地克隆一个Git仓库,突然终端抛出GnuTLS recv error (-110): The TLS connection was non-properly terminated——这个看似晦涩的错误背后,可能隐藏着…...

Python零基础到精通教程,高级特性教程
本文聚焦 Python 最实用、最能简化代码、提升效率的高级特性,避开晦涩理论,全是工作 / 面试高频用法,学完能直接写出简洁、优雅、高性能的 Python 代码。适合有 Python 基础,想进阶代码水平的学习者,每个特性都配可直接…...

Visual Syslog Server:Windows平台最完整的Syslog监控解决方案终极指南
Visual Syslog Server:Windows平台最完整的Syslog监控解决方案终极指南 【免费下载链接】visualsyslog Syslog Server for Windows with a graphical user interface 项目地址: https://gitcode.com/gh_mirrors/vi/visualsyslog 在复杂的IT环境中,…...
)
从QMessageBox到MyMessageBox:一个Qt弹窗的‘整容’与‘进化’全记录(支持Qt5/Qt6)
从QMessageBox到MyMessageBox:一个Qt弹窗的‘整容’与‘进化’全记录 在商业软件开发中,用户体验往往决定了产品的成败。当我们的产品经理拿着竞品分析报告走进会议室,指着那些精致的弹窗说"为什么我们的提示框这么丑"时࿰…...
)
S32K开发环境全攻略:基于S32 Design Studio和SDK的快速上手教程(含Arduino评估板)
S32K开发环境实战指南:从零构建智能车控系统 第一次拿到S32K开发板时,我盯着那排Arduino兼容的接口发呆了十分钟——这个汽车级MCU竟然能用面包板快速验证创意。NXP官方提供的工具链比想象中友好得多,但隐藏的坑也不少。本文将带你用S32 Desi…...

WenQuanYi Micro Hei字体实战指南:从安装到深度优化的全流程解决方案
WenQuanYi Micro Hei字体实战指南:从安装到深度优化的全流程解决方案 【免费下载链接】fonts-wqy-microhei Debian package for WenQuanYi Micro Hei (mirror of https://anonscm.debian.org/git/pkg-fonts/fonts-wqy-microhei.git) 项目地址: https://gitcode.co…...

避坑指南:解决平头哥CDK编译RVB2601示例工程时‘缺少chippack’的几种方法
平头哥RVB2601开发实战:CDK环境配置与依赖缺失问题深度解析 第一次接触平头哥RVB2601开发板的开发者,往往会被其强大的IoT能力和丰富的生态资源所吸引。但当他们满怀热情地下载示例代码,双击.cdkproj文件准备大展拳脚时,却可能遭遇…...

DIY智能家居控制面板:用ESP8266和TM1629A打造低成本数码管时钟/温湿度显示器
DIY智能家居控制面板:用ESP8266和TM1629A打造低成本数码管时钟/温湿度显示器 周末在家捣鼓电子元件时,突然想到能不能用闲置的数码管做个既实用又酷炫的桌面小工具。于是就有了这个项目——一个不到百元成本的智能显示面板,既能精准报时又能监…...

告别卡顿!Android布局优化实战:用<include>、<merge>和ViewStub提升App流畅度
Android布局优化三剑客:用 、 和ViewStub打造丝滑体验 每次打开电商App时,那些瞬间加载出来的商品瀑布流是否让你感到惊艳?反观自己开发的App,却在滑动时频频卡顿,甚至出现令人尴尬的白屏。这种性能差距往往源于对Andr…...