使用pyannote-audio实现声纹分割聚类
使用pyannote-audio实现声纹分割聚类
# GitHub地址
https://github.com/MasonYyp/audio
1 简单介绍
pyannote.audio是用Python编写的用于声纹分割聚类的开源工具包。在PyTorch机器学习基础上,不仅可以借助性能优越的预训练模型和管道实现声纹分割聚类,还可以进一步微调模型。
它的主要功能有以下几个:
- 声纹嵌入:从一段声音中提出声纹转换为向量(嵌入);
- 声纹识别:从一段声音中识别不同的人(多个人);
- 声纹活动检测:检测一段声音检测不同时间点的活动;
- 声纹重叠检测:检测一段声音中重叠交叉的部分;
- 声纹分割;将一段声音进行分割;
pyannote.audio中主要有”segmentation“、”embedding“和”speaker-diarization“三个模型,”segmentation“的主要作用是分割、”embedding“主要作用是嵌入(跟wespeaker-voxceleb-resnet34-LM作用相同),”speaker-diarization“的作用是使用管道对上面两个模型整合。
pyannote-audio的参考地址
# Huggingface地址
https://hf-mirror.com/pyannote# Github地址
https://github.com/pyannote/pyannote-audio
⚠️ 注意: pyannote.audio不同的版本有些区别;
2 使用pyannote.audio:3.1.3
2.1 安装pyannote.audio
pip install pyannote.audio==3.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
使用模型需要现在huggingface上下载模型,模型如下:
⚠️ pyannote.audio的部分模型是收到保护的,即需要在huggingface登录后,填写部分信息,同意相关协议才能下载,否则无法下载。
# 1 嵌入模型 pyannote/wespeaker-voxceleb-resnet34-LM
https://hf-mirror.com/pyannote/wespeaker-voxceleb-resnet34-LM# 2 分割模型 pyannote/segmentation-3.0
https://hf-mirror.com/pyannote/segmentation-3.0
使用huggingface-cli下载相关模型的命令:
# 注意:需要先创建Python环境# 安装huggingface-cli
pip install -U huggingface_hub# 例如下载pyannote/embedding模型
# 必须提供Hugging上的 --token hf_****
huggingface-cli download --resume-download pyannote/embedding --local-dir pyannote/embedding --local-dir-use-symlinks False --token hf_****
注意两个类
# Inference主要用于声纹嵌入
pyannote.audio import Inference# Annotation主要用于声纹分割
from pyannote.core import Annotation# Annotation中的主要方法,假设实例为;diarization
# 获取声音中说话人的标识
labels = diarization.labels()# 获取声音中全部的活动Segment(列表)
segments = list(diarization.itertracks())# 获取声音中指定说话人时间段(列表),”SPEAKER_00“为第一个说话人的标识
durations = diarization.label_timeline('SPEAKER_00')
2.2 实现声纹分割
注意:pyannote/speaker-diarization-3.1实现声纹识别特别慢,不知道是不是我的方法不对(30分钟的音频,处理了20多分钟)。⚠️ 使用单个模型很快。pyannote/speaker-diarization(版本2)较快,推荐使用pyannote/speaker-diarization(版本2)。
注意:此处加载模型和通常加载模型的思路不同,常规加载模型直接到名称即可,此处需要加载到具体的模型名称。
(1)使用python方法
# 使用 pyannote-audio-3.1.1
import timefrom pyannote.audio import Model
from pyannote.audio.pipelines import SpeakerDiarization
from pyannote.audio.pipelines.utils import PipelineModel
from pyannote.core import Annotation# 语音转向量模型
embedding: PipelineModel = Model.from_pretrained("E:/model/pyannote/pyannote-audio-3.1.1/wespeaker-voxceleb-resnet34-LM/pytorch_model.bin")
# 分割语音模型
segmentation: PipelineModel = Model.from_pretrained("E:/model/pyannote/pyannote-audio-3.1.1/segmentation-3.0/pytorch_model.bin")# 语音分离模型
speaker_diarization: SpeakerDiarization = SpeakerDiarization(segmentation=segmentation, embedding=embedding)# 初始化语音分离模型的参数
HYPER_PARAMETERS = {"clustering": {"method": "centroid","min_cluster_size": 12,"threshold": 0.7045654963945799},"segmentation":{"min_duration_off": 0.58}
}
speaker_diarization.instantiate(HYPER_PARAMETERS)start_time = time.time()# 分离语音
diarization: Annotation = speaker_diarization("E:/语音识别/数据/0-test-en.wav")# 获取说话人列表
print(diarization.labels())
# 获取活动segments列表
print(list(diarization.itertracks()))
print(diarization.label_timeline('SPEAKER_00'))ent_time = time.time()
print(ent_time - start_time)
(2)使用yml方法
# instantiate the pipeline
from pyannote.audio import Pipeline
from pyannote.core import Annotationspeaker_diarization = Pipeline.from_pretrained("E:/model/pyannote/speaker-diarization-3.1/config.yaml")# 分离语音
diarization: Annotation = speaker_diarization("E:/语音识别/数据/0-test-en.wav")print(type(diarization))
print(diarization.labels())
config.yaml
根据文件可以看出,声纹分割是将embedding和segmentation进行了组合。
version: 3.1.0pipeline:name: pyannote.audio.pipelines.SpeakerDiarizationparams:clustering: AgglomerativeClustering# embedding: pyannote/wespeaker-voxceleb-resnet34-LMembedding: E:/model/pyannote/speaker-diarization-3.1/wespeaker-voxceleb-resnet34-LM/pytorch_model.binembedding_batch_size: 32embedding_exclude_overlap: true# segmentation: pyannote/segmentation-3.0segmentation: E:/model/pyannote/speaker-diarization-3.1/segmentation-3.0/pytorch_model.binsegmentation_batch_size: 32params:clustering:method: centroidmin_cluster_size: 12threshold: 0.7045654963945799segmentation:min_duration_off: 0.0
模型目录
模型中的其他文件可以删除,只保留”pytorch_model.bin“即可。

执行结果

2.3 实现声纹识别
比较两段声音的相似度。
from pyannote.audio import Model
from pyannote.audio import Inference
from scipy.spatial.distance import cdist# 导入模型
embedding = Model.from_pretrained("E:/model/pyannote/speaker-diarization-3.1/wespeaker-voxceleb-resnet34-LM/pytorch_model.bin")# 抽取声纹
inference: Inference = Inference(embedding, window="whole")# 生成声纹,1维向量
embedding1 = inference("E:/语音识别/数据/0-test-en.wav")
embedding2 = inference("E:/语音识别/数据/0-test-en.wav")# 计算两个声纹的相似度
distance = cdist([embedding1], [embedding2], metric="cosine")
print(distance)
2.4 检测声纹活动
from pyannote.audio import Model
from pyannote.core import Annotation
from pyannote.audio.pipelines import VoiceActivityDetection# 加载模型
model = Model.from_pretrained("E:/model/pyannote/speaker-diarization-3.1/segmentation-3.0/pytorch_model.bin")# 初始化参数
activity_detection = VoiceActivityDetection(segmentation=model)
HYPER_PARAMETERS = {# remove speech regions shorter than that many seconds."min_duration_on": 1,# fill non-speech regions shorter than that many seconds."min_duration_off": 0
}
activity_detection.instantiate(HYPER_PARAMETERS)# 获取活动特征
annotation: Annotation = activity_detection("E:/语音识别/数据/0-test-en.wav")# 获取活动列表
segments = list(annotation.itertracks())
print(segments)
3 使用pyannote.audio:2.1.1
⚠️ 推荐使用此版本
3.1 安装pyannote.audio
# 安装包
pip install pyannote.audio==2.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple# 1 嵌入模型 pyannote/embedding
https://hf-mirror.com/pyannote/embedding# 2 分割模型 pyannote/segmentation
https://hf-mirror.com/pyannote/segmentation
3.2 实现声纹分割
# 使用 pyannote-audio-2.1.1
import timefrom pyannote.audio.pipelines import SpeakerDiarization
from pyannote.audio import Model
from pyannote.audio.pipelines.utils import PipelineModel
from pyannote.core import Annotation# 语音转向量模型
embedding: PipelineModel = Model.from_pretrained("E:/model/pyannote/pyannote-audio-2.1.1/embedding/pytorch_model.bin")# 分割语音模型
segmentation: PipelineModel = Model.from_pretrained("E:/model/pyannote/pyannote-audio-2.1.1/segmentation/pytorch_model.bin")# 语音分离模型
speaker_diarization: SpeakerDiarization = SpeakerDiarization(segmentation=segmentation,embedding=embedding,clustering="AgglomerativeClustering"
)HYPER_PARAMETERS = {"clustering": {"method": "centroid","min_cluster_size": 15,"threshold": 0.7153814381597874},"segmentation":{"min_duration_off": 0.5817029604921046,"threshold": 0.4442333667381752}
}speaker_diarization.instantiate(HYPER_PARAMETERS)start_time = time.time()
# vad: Annotation = pipeline("E:/语音识别/数据/0-test-en.wav")
diarization: Annotation = speaker_diarization("E:/语音识别/数据/0-test-en.wav")# 获取说话人列表
print(diarization.labels())ent_time = time.time()
print(ent_time - start_time)
3.3 其他功能
3.1.1版本的功能2.1.1都能实现,参考3.1.1版本即可。
相关文章:
使用pyannote-audio实现声纹分割聚类
使用pyannote-audio实现声纹分割聚类 # GitHub地址 https://github.com/MasonYyp/audio1 简单介绍 pyannote.audio是用Python编写的用于声纹分割聚类的开源工具包。在PyTorch机器学习基础上,不仅可以借助性能优越的预训练模型和管道实现声纹分割聚类,还…...

防御保护:防火墙内容安全
一、IAE(Intelligent Awareness Engine)引擎 二、深度检测技术(DFI和DPI) 1.DPI – 深度包检测技术 DPI主要针对完整的数据包(数据包分片,分段需要重组),之后对数据包的内容进行识别。&#x…...

uni-app webview 打开baidu.com
在uni-app中,你可以使用web-view组件来打开外部网页,比如百度首页。以下是一个简单的示例代码,展示了如何在uni-app中使用web-view组件打开百度首页: <template> <view> <web-view :src"baiduUrl">&l…...
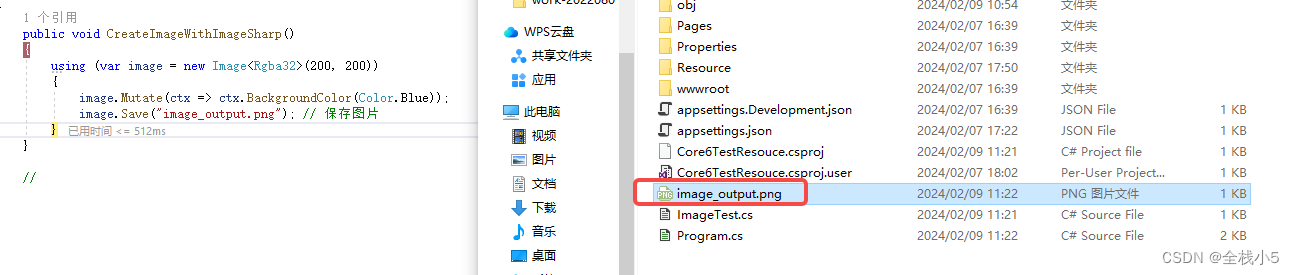
【C#】SixLabors.ImageSharp和System.Drawing两者知多少
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。…...

总是 -bash: gomobile: 命令未找到
总是 -bash: gomobile: 命令未找到 问题描述 我的项目是/Users/$user/go/src/abc.com/project 当我尝试在 /Users/GaryChan/go/src/abc.com/project/sdk 并运行: export ANDROID_HOME/Users/$user/Library/Android/sdk/ndk-bundle/gomobile bind -targetandroid abc.com/p…...

day27【LeetCode】454. 四数相加 II
day27【LeetCode】454. 四数相加 II 1.题目描述 附上题目链接:四数相加 II 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] …...
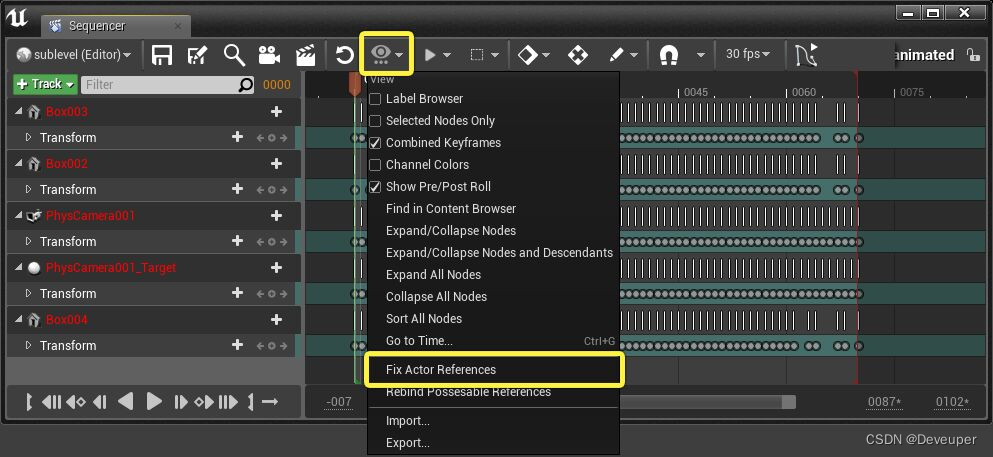
UE5 UE4 不同关卡使用Sequence动画
参考自:关于Datasmith导入流程 | 虚幻引擎文档 (unrealengine.com) 关卡中的Sequence动画序列,包含特定关卡中的Actor的引用。 将同一个Sequcen动画资源放入其他关卡,Sequence无法在新关卡中找到相同的Actor,导致报错。 Sequen…...
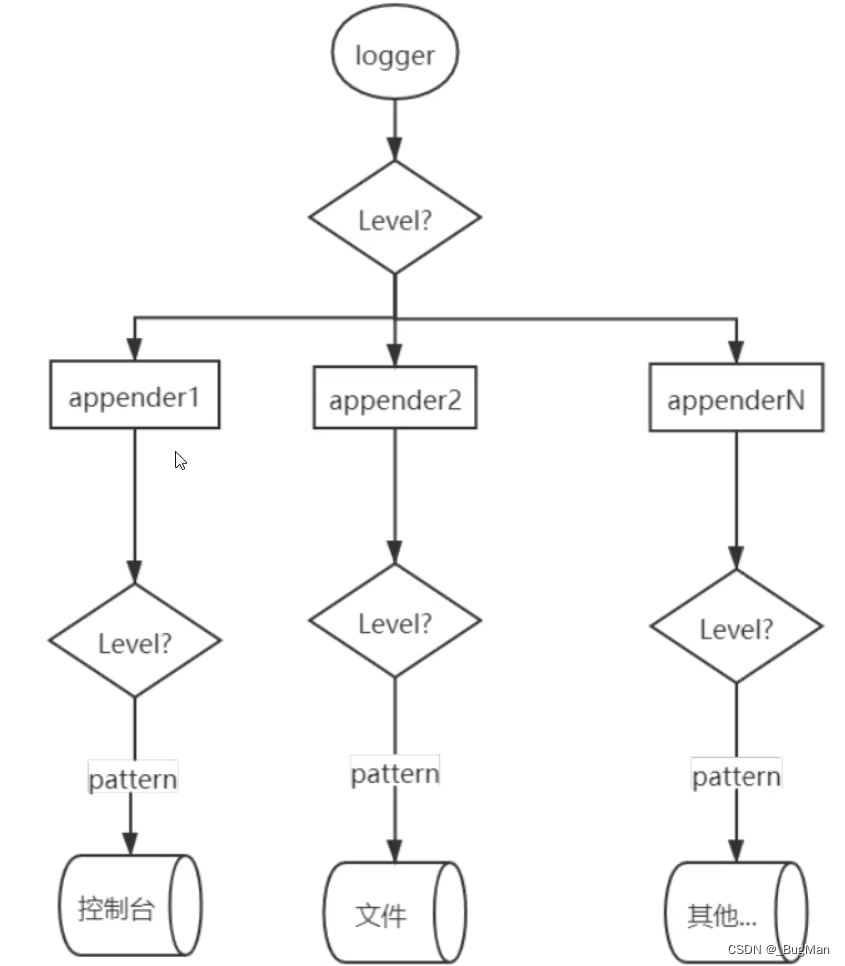
【JAVA日志】关于日志系统的架构讨论
目录 1.日志系统概述 2.环境搭建 3.应用如何推日志到MQ 4.logstash如何去MQ中取日志 5.如何兼顾分布式链路追踪 1.日志系统概述 关于日志系统,其要支撑的核心能力无非是日志的存储以及查看,最好的查看方式当然是实现可视化。目前市面上有成熟的解决…...
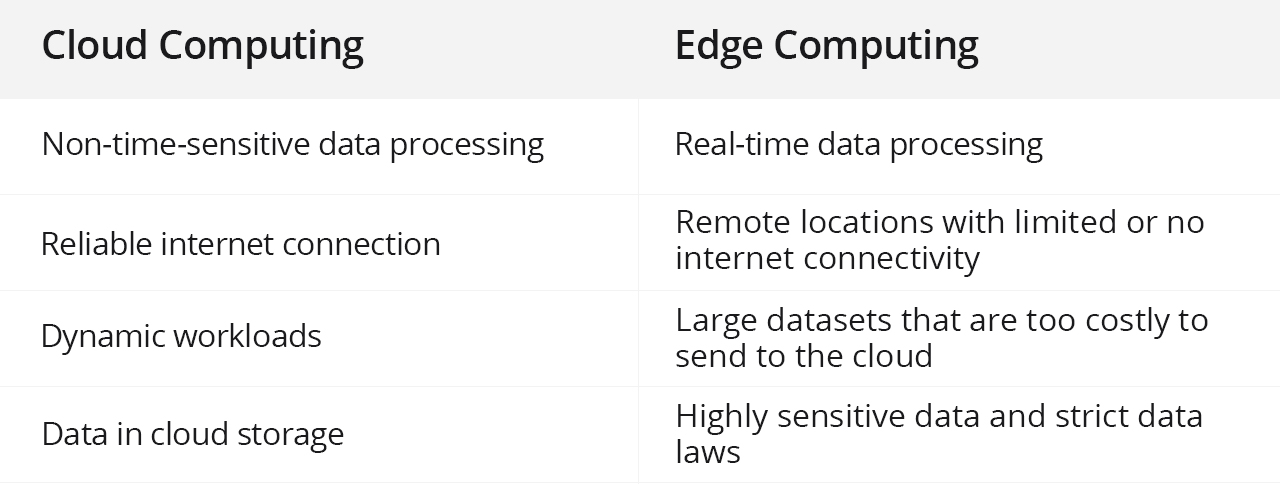
云计算与边缘计算:有何不同?
公共云计算平台可以帮助企业充分利用全球服务器来增强其私有数据中心。这使得基础设施能够扩展到任何位置,并有助于计算资源的灵活扩展。混合公共-私有云为企业计算应用程序提供了强大的灵活性、价值和安全性。 然而,随着分布在全球各地的实时人工智能应…...
02-23:边缘部分源码(源码分析篇))
「连载」边缘计算(二十)02-23:边缘部分源码(源码分析篇)
(接上篇) EdgeCore之devicetwin 前面对EdgeCore组件的edged功能模块进行了分析,本节对EdgeCore组件的另一个功能模块devicetwin进行剖析,包括devicetwin的struct调用链剖析、devicetwin的具体逻辑剖析、devicetwin的缓存机制剖析…...

Swagger接口文档管理工具
Swagger 1、Swagger1.1 swagger介绍1.2 项目集成swagger流程1.3 项目集成swagger 2、knife4j2.1 knife4j介绍2.2 项目集成knife4j 1、Swagger 1.1 swagger介绍 官网:https://swagger.io/ Swagger 是一个规范和完整的Web API框架,用于生成、描述、调用和…...

关于HTML5表单验证的方法教程
简介 HTML5表单验证是一种在客户端对用户输入进行验证的方法,可以有效地减少对于服务器端验证的依赖。通过使用HTML5表单验证,可以为用户提供实时的错误提示和更好的用户体验。本教程将介绍如何在HTML5中使用各种验证属性和技术来实现表单验证。 基本表…...
.NET生成MongoDB中的主键ObjectId
前言 因为很多场景下我们需要在创建MongoDB数据的时候提前生成好主键为了返回或者通过主键查询创建的业务,像EF中我们可以生成Guid来,本来想着要不要实现一套MongoDB中ObjectId的,结果发现网上各种各样的实现都有,不过好在阅读C#…...
BeautifulSoup+xpath+re+css简单复习+新的scrapy的学习
1.BeautifulSoupsoup BeautifulSoup(html,html.parser)all_icosoup.find(class_"DivTable") 2.xpath trs resp.xpath("//tbody[idcpdata]/tr") hong tr.xpath("./td[classchartball01 or classchartball20]/text()").extract() 这个意思是找…...

Python爬虫实战:从API获取数据
引言 在现代软件开发中,API已经成为获取数据的主要方式之一。API允许不同的软件应用程序相互通信,共享数据和功能。在本文中,我们将学习如何使用Python从API获取数据,并探讨其在实际应用中的价值。 目录 引言 二、API基础知识 …...
音频转换器哪个好?3款电脑软件+3款手机应用
在当今的数字时代,音频转换已成为许多用户日常的需求。为了帮助您找到最佳的音频转换工具,我们将介绍3款电脑软件和3款手机应用。这些工具都各有特点,能够满足不同用户的需求。 1.电脑软件篇 1.1金舟音频大师 金舟音频大师是一款多功能的音…...

惯性导航 | 运动学---运动模型
惯性导航 | 运动学---运动模型 IMU系统的运动学 IMU系统的运动学 惯性测量单元(IMU)已经非常普及了。我们在绝大多数电子设备中都能找到IMU:车辆、手机、手表、头盔,甚至足球当中都内置了IMU。它们的体积很小,安装在设…...
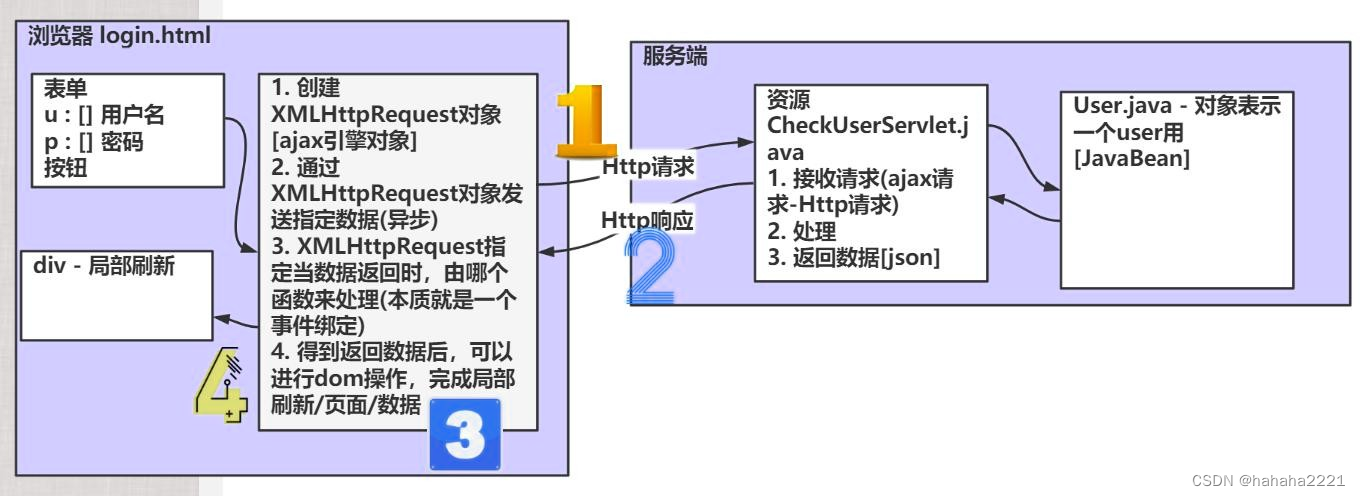
Java Web(十一)--JSON Ajax
JSON JSon在线文档: JSON 简介 JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。轻量级指的是跟xml做比较。数据交换指的是客户端和服务器之间业务数据的传递格式。 它基于 ECMAScript (W3C制定的JS规范)的一个子集,采…...
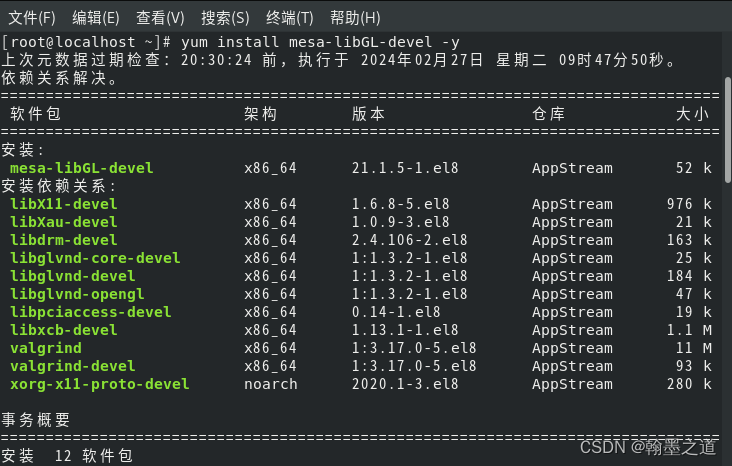
GL/gl.h: No such file or directory(CentOS8 QT5.12.12)
1.问题描述 新建的QT工程,出现如下问题: GL/gl.h: No such file or directory 2.原因分析 centos系统里面缺少opengl库 3.解决方法 运行命令: yum install mesa-libGL -devel -y...

【外设篇】-显示器
显示屏是一种电光转换工具,现在市面上的显示器都是LCD(Liquid Crystal Display,液晶显示器) 显示器参数介绍 对比度 是指画面黑与白的比值,对比度越高能使色彩表现越丰富,对比度越高,显示器的…...

如何解决暗黑破坏神2存档编辑的复杂性问题:d2s-editor可视化解决方案深度解析
如何解决暗黑破坏神2存档编辑的复杂性问题:d2s-editor可视化解决方案深度解析 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 面对暗黑破坏神2存档编辑的复杂十六进制操作和技术门槛,传统方法让普通玩家望…...

从扫地机器人到AGV:拆解双轮差速模型在CoppeliaSim中的ROS实战配置
从扫地机器人到AGV:双轮差速模型在CoppeliaSim中的ROS实战指南 当你在电商平台下单的扫地机器人完成一次完美的弓字形路径清扫时,背后是一套精密的双轮差速控制系统在发挥作用。这种看似简单的运动机制,实际上支撑着从家用清洁设备到工业AGV的…...

自然·人类行为:大语言模型如何调控人类语言网络
导语这篇发表于 Nature Human Behaviour 的研究提出了一个相当前沿、也颇具冲击力的问题:如果大语言模型(large language models, LLMs)不仅能模仿人类语言行为、预测阅读时的大脑反应,那么它是否还能进一步“反过来”帮助我们设计…...

如何快速掌握AO3镜像访问:终极完整指南
如何快速掌握AO3镜像访问:终极完整指南 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site 你是否曾经遇到过这样的困境:想要访问全球最大的同人创作平台AO3,却发现页面无法加载&#x…...

AGI自主迭代证据链首次闭环:2026奇点大会披露的172小时连续训练日志,揭示自我优化新范式
第一章:2026奇点智能技术大会:通用人工智能最新进展 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次披露了多项突破性成果,其中最引人注目的是OpenCog Foundation联合MIT AGI Lab发布的Neuro-Symbolic Fusion Engine v3.2&…...

Gemma-3-12b-it镜像免配置教程:树莓派5+USB加速棒边缘部署探索
Gemma-3-12b-it镜像免配置教程:树莓派5USB加速棒边缘部署探索 1. 环境准备与硬件要求 1.1 硬件配置清单 树莓派5:推荐8GB内存版本USB加速棒:支持CUDA的AI加速设备(如Google Coral USB Accelerator)存储设备…...

SITS2026独家解密:基于AST+图神经网络的第三代扫描引擎,如何将FP率压至0.87%并支持Rust/Go/Terraform全栈识别
第一章:SITS2026分享:AI代码安全扫描 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026大会上,多家头部安全厂商与开源社区联合发布了新一代AI驱动的代码安全扫描框架——SentryLLM,该框架深度融合大语言模型语义理解能…...

Subtitle Edit视频字幕编辑软件:开源字幕编辑软件解决时间轴调整与格式转换难题
在制作或修改视频字幕时,你是否遇到过这些问题:从网上下载的字幕与视频不同步,需要整体提前或推迟几秒;字幕文件是SRT格式,但播放器只支持ASS格式,找不到合适的转换工具;或者字幕中有错别字、时间重叠,手动检查费时费力。这些问题的核心,是需要一款专业的字幕编辑软件…...

AGI能真正“原创”吗?:基于172项实验的创造性能力量化评估白皮书
第一章:AGI能真正“原创”吗?:基于172项实验的创造性能力量化评估白皮书 2026奇点智能技术大会(https://ml-summit.org) 本白皮书首次系统性地将“原创性”解构为可测量的认知维度——语义突变率、跨域映射熵、约束下解空间覆盖率与零样本范…...

语音识别安全加固:SenseVoice-Small ONNX输入校验与异常防护
语音识别安全加固:SenseVoice-Small ONNX输入校验与异常防护 1. 项目背景与安全挑战 SenseVoice-Small ONNX语音识别工具基于FunASR开源框架开发,采用Int8量化技术实现本地高效语音识别。在实际应用中,语音识别系统面临着多种安全风险&…...