RocksDB 架构
文章目录
- 1、RocksDB 摘要
- 1.1、RocksDB 特点
- 1.2、基本接口
- 1.3、编译
- 2、LSM - Tree
- 2.1、Memtable
- 2.2、WAL
- 2.3、SST
- 2.4、BlockCache
- 3、读写流程
- 3.1、读取流程
- 3.2、写入流程
- 4、LSM-Tree 放大问题
- 4.1、放大问题
- 4.2、compaction
RocksDB 是 Facebook 针对高性能磁盘开发开源的嵌入式持久化存储系统,采用了 WAL 机制和 LSM Tree 结构。RocksDB 所有类型的数据都是采用追加写,没有更新文件的操作。比较适合使用基于 Append Only 的高性能分布式文件系统。
1、RocksDB 摘要
1.1、RocksDB 特点
- 基于 LevelDB
- 嵌入式 KV 存储引擎
- 针对写密集型场景而提出的解决方案。例:日志系统、海量数据存储、海量数据分析
- 紧凑型存储。相同的数据量,更少的空间占用。
- 基于 LSM-Tree 的存储结构。
- 内存:MemTable
- 磁盘:SST | WAL
1.2、基本接口
- Open
- Get:获取 key
- Put:存放 key
- Delete:删除 key,具体在 compaction 中删除
- SingleDelete:针对从未修改过的 key,比 delete 删除快
- Merge:合并新写入的数据。带来大量的读数据请求,提前获取 Merge 的增量数据,然后进行合并。
- Iterator:通过给定的 key 批量获取符合条件的 KV 记录。
1.3、编译
# 1、RocksDB
git clone https://github.com/facebook/rocksdb.git
cd rocksdb
# 编译成调试模式
make
# 编译成发布模式
make static_lib # 压缩库 Ubuntu
# gflags
sudo apt-get install libgflags-dev
# snappy
sudo apt-get install libsnappy-dev
# zlib
sudo apt-get install zlib1g-dev
# bzip2
sudo apt-get install libbz2-dev
# lz4
sudo apt-get install liblz4-dev
# zstandard
sudo apt-get install libzstd-dev
2、LSM - Tree
RocksDB 架构基于 LSM-Tree, log structured merge tree 存储结构,其核心就是利用顺序写来提升写性能。
LSM-Tree 组成
- 内存:可写的 MemTable + 只读的 Immutable Memtable
- 磁盘:WAL + 多层级 SST
LSM-Tree VS B+ Tree
- LSM-Tree:顺序写,追加更新。问题:数据冗余,需要后台线程 compaction
- B+ Tree:随机写,就地更新。问题:磁盘随机 IO < 磁盘顺序 IO,且锁粒度大
接下来,从整体上先介绍 RocksDB 架构图,如图所示:

用户的数据需要同时写到内存中的 Memtable 数据结构和磁盘 WAL 日志。可写的 Memtable 用于快速索引查询的缓存数据,并采用了跳表数据提升查找数据的速度。定时转换成只读的 Immutable Memtable,保存到 SST 文件中(flush 磁盘操作)。在此期间,若出现服务故障,重启系统会从 WAL 中将数据通过 Redo 的方式回复到 Memtable。
为了定期 compact (合并压缩)数据,将 Immutable Memtable 分为多个层次。Level 0 层允许数据重复,文件间无序,文件内部有序;Level 1 ~ Level N 没有数据重复,跨层可能有重复,文件间是有序的。数据逐层愈冷,压缩程度愈高。SST 文件为每一层的主要存储方式。
读取数据时,先读内存 Memtable,若没有再读磁盘 SST 文件。
参考论文:Chen G J, Wiener J L, Lyer S, et al. Realtime data processing at facebook[C]. Proceedings of the 2016 International Conference on Management of Data. 2016: 1087-1098.
2.1、Memtable
Memtable 内存数据结构,其中的数据总是最新的。同时服务于读和写,写操作先插入 Memtable;读数据先查询 Memtable。当 Memtable 写满,修改为只读的 Immutable Memtable,并被新的 Memtable 替换。后台线程会该 Immutable Memtable 异步落盘(flush)到一个 SST 文件,落盘后销毁 Memtable。
Memtable 基于跳表实现。跳表是多层级有序链表,其特点是:
- 从最高层次开始跳跃查找,并记录跳跃路径,查询时间
O(logn) - 找到待插入位置后,插入节点,并随机层高
- 根据跳跃路径,构建层级链表关系

跳表应用场景
- 范围查询
- 快速有序地列出所有的节点
- 并发粒度非常低。相较红黑树加锁整棵树,只将相邻的结点操作加锁
重要参数
# 一个 memtable 的大小
write_buffer_size
# 管理 memtable 使用的总内存数
db_write_buffer_size
# 刷盘到 SST 文件的最大 memtable 数
max_write_buffer_number
复习:其他常见的层级数据结构
- 跳表:多层级有序链表
- B+ 树:叶子节点包含所有的数据,非叶子节点只包含索引 key 信息
- 时间轮:按照定时任务到期时间轻重缓急进行分层
2.2、WAL
WAL, Write Ahead Log。RocksDB 中的 DML 操作同时写入内存 Memtable 和磁盘 WAL 日志文件。当系统崩溃时,WAL 日志可以完整恢复 Memtable 中的数据,以保 WAL中的数据通过 redo 的方式恢复到 Memtable。
重要参数
# WAL 文件的最大大小
DBOptions::max_total_wal_size
# WAL 文件的删除时间
DBOptions::WAL_ttl_seconds
2.3、SST
SST, Sorted String Table,有序键值对集合,是 LSM - Tree 在磁盘中的数据结构。与 B+ Tree 就地更新不同(找到元数据所在页并修改值),LSM-Tree 直接 append 写到磁盘,再同通过合并的方式取出冗余数据。
为了加快 key 的查询速度
- 建立索引
- 布隆过滤器(Bloom Filter):判断某个字符串一定不在该集合,若该字符串存在,可能有误差。
- 原理:位图 + N 个哈希算法。key 经过 N 个哈希后,若对应的位图是 0,则 key 不存在
- 场景限制:不支持删除 key,而 SST 本身不会被修改,所以可以使用。
SST 文件格式
- Footer:程序启动位置,存储 IndexBlock 和 MetaIndexBlock 的位置
- IndexBlock:存储 DataBlock 的位置
- MetaIndexBlock:存储了过滤元数据、属性信息、压缩字典索引的位置
- DataBlock:存储有序的数据记录

引用论文:Cho M, Choi W, Park S H. A Study on WAF reduction and SST file size on RocksDB[C]. Proceedings of the Korea Information Processing Society Conference. Korea Information Processing Society, 2017: 709-712
2.4、BlockCache
背景:内核 page cache 不可定制。因此,用户可以在内存中指定 RocksDB 缓存块,传一个 Cache 对象给 RocksDB 实例。一个缓存对象可以在同一个进程的多个 RocksDB 实例之间共享。块缓存存储未压缩过的块,也可以设置块缓存去存储压缩后的块。
RocksDB 两种类型的缓存都通过分片来减轻锁冲突,容量被平均分配到每个分片,分片间不共享空间。默认情况下,每个缓存会被分成 64 个分片,每个分片至少 512 B。
默认情况下,索引和过滤块都在 BlockCache 外面存储,用户可以选择将它们缓存在 BlockCache 中;
- LRUCache:基于 LRU 算法,lru 列表 + 哈希表。
- ClockCache:基于 Clock 算法,clock 指针 + 环形列表 + 哈希表。
与 LRU 缓存比较,Clock 缓存有更好的锁粒度。LRU 缓存读取数据时,需要对所有分片加互斥锁,因为需要更新的 LRU 列表;而在 Clock 缓存上读取数据时,不需要申请该分片的互斥锁,只需要搜索并行的哈希表。只有在插入的时候需要每个分片的锁,锁粒度更小。因此,一定环境下,Clock 缓存性能更好。
3、读写流程
3.1、读取流程
- 先读内存 memtable
- 若不存在,读磁盘 SST

SST 查找流程
FindFiles。从 SST 文件中查找,如果在 L0,那么每个文件都得读,因为 L0 不保证 key 不重叠;如果在更深的层,key 保证不重叠,每层只需要读一个 SST 文件即可。L1 开始,每层可以在内存中维护一个 SST 的有序区间索引,在索引上二分查找即可。LoadIB + FB。IB, index block是 SST block 的索引;FB, filter block是一个布隆过滤器,可以快速排除 key 不在的情况,因此优先加载。SearchIB。二分查找 index block,找到对应的 blockSearchFB。用布隆过滤器过滤,如果没有,则返回;LoadDB。加载 block 到内存;SearchDB。block 中继续二分查找;ReadValue。找到 key 后读数据。若考虑 WiscKey KV 分离的情况,还需要去 vLog 中读取
3.2、写入流程
- 写入磁盘 WAL 文件
- 写入内存 memtable
- memtable 大小达到阈值后,冻结成 immutable memtable。后续的写入交给新的 memtable 和 WAL
- 后台 compaction 线程,将 immutable memtable 落盘成 level 0 的 SST,持久化后释放对应的 WAL
- 若插入新的 SST 后,当前层 Li 的总文件大小超出阈值,会从 level i 挑出一个文件和 level i + 1 层的重叠文件合并,直到所有层的大小都小于阈值。合并过程中,保证 level 1 以后各 SST 的 key 不重叠
4、LSM-Tree 放大问题
4.1、放大问题
- 读放大:描述物理读取的字节数相较于返回的字节数之比。RocksDB 读取操作需要分层依次查找,直到找到对应数据,该过程可能涉及多次 IO
- 写放大:描述磁盘上存储的数据字节数相较于数据库包含的逻辑字节数之比。所有的写入操作都是顺序写,而不是就地更新,无效数据不会马上被清理掉。
- 空间放大:描述实际写入磁盘的数据大小和程序要求写入的数据大小之比。为了减小读放大和空间放大,RocksDB 采用后台线程合并数据的方式来解决,但会造成对同一条数据多次写入磁盘
4.2、compaction
rocksdb 默认采用 leveled compaction(leveled & tiered)合并算法。compaction 操作会造成写放大,但会减少读放大,空间放大。
除 L0 外,其他层级不会出现重复数据。
- leveled:每一层只有一个文件,且每一层文件大小是上一层的 10 倍
- tiered:将文件分成拆分成大小相同的部分
将相邻层的重复数据进行合并。同时,也可以并行 compaction

相关文章:
RocksDB 架构
文章目录1、RocksDB 摘要1.1、RocksDB 特点1.2、基本接口1.3、编译2、LSM - Tree2.1、Memtable2.2、WAL2.3、SST2.4、BlockCache3、读写流程3.1、读取流程3.2、写入流程4、LSM-Tree 放大问题4.1、放大问题4.2、compactionRocksDB 是 Facebook 针对高性能磁盘开发开源的嵌入式持…...

MVVM和MVC的区别
首先,MVVM 和 MVC 都是一种设计模式MVCM(Model): 模型层。 用于处理应用程序数据逻辑的部分,模型对象负责在数据库中存取数据V (View): 视图层。 处理数据显示的部分 ,视…...

c++11 标准模板(STL)(std::unordered_map)(三)
定义于头文件 <unordered_map> template< class Key, class T, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator< std::pair<const Key, T> > > class unordered…...
OpenGL环境配置
方法一:1.下载GLFW点击GLFW跳转2.下载后解压3.下载glad,解压后4.用vs2019新建Cmake项目5.在新建的Cmake项目下建立depend文件夹在depend里放置我们下载解压的glad和glfw-3.3.8.bin.WIN646.项目中可以看到我们加进来的文件7.编写我们项目的CMakeLists.txt…...

SpringCloud之 Eureka注册中心
文章目录Eureka注册中心一、服务注册与发现1.1 依赖导入①父工程 SpringCloud 版本管理②Eureka 服务端依赖③Eureka 客户端依赖1.2 服务注册①创建 Eureka 服务端的主类②设置 Eureka 服务端的配置文件③设置 Eureka 客户端的配置文件④关闭自我保护机制1.3 服务发现①远程调用…...

Linux入门篇-用户管理
简介 linux基本的用户管理。 ⽤户的管理(切换到root) ⽤户的添加(useradd) ⽤户的删除(userdel) ⽤户的修改(usermod) ⽤户的查看(查看/etc/passwd) id⽤户组的管理(切换到root) …...
)
G. Special Permutation(构造)
1、题目 G. Special Permutation 这道题的意思是给我们从111到nnn的排列,然后我们对这个排列的顺序上进行调换,需要满足的条件是任意两个相邻元素的绝对值的差满足条件:2≤∣pi−pi1∣≤42\leq |p_i-p_{i 1}|\leq 42≤∣pi−pi1∣≤4 …...
QML动态对象管理
QML中有多种方式来动态创建和管理QML对象: Loader (加载器)Repeater(复制器)ListView,GridWiew,PethView(视图) (之后会介绍)使用加载器ÿ…...

cmake入门03 -自定义find外部库
自定义检测外部库使用pkg-config查找库搜索.pc配置文件cmake函数链接到库自定义find库检测外部库的便捷方法:使用CMake自带的find-module使用<package>Config.cmake, <package>ConfigVersion.cmake和<package>Targets.cmake。这些文件由软件商提供…...
Dubbo源码解析-——服务导出
前言 在之前我们讲过Spring和Dubbo的集成,我们在服务上标注了DubboService的注解,然后最终Dubbo会调用到ServiceBean#export方法中,本次我们就来剖析下服务导出的全流程。 一、前置回顾 由于ServiceBean实现了ApplicationListener接口&…...

vue+django+neo4j 基于知识图谱红楼梦问答系统
vuedjangoneo4j 基于知识图谱红楼梦问答系统 项目背景 知识图谱是一种以图谱形式描述客观世界中存在的各种实体、概念及其关系的技术, 广泛应用于智能搜索、自动问答和决策支持等领域. 可视分析技术可以将抽象的知识图谱映射为图形元素, 帮助用户直观地感知和分析数据, 从而提…...

2023年全国最新食品安全管理员精选真题及答案13
百分百题库提供食品安全管理员考试试题、食品安全员考试预测题、食品安全管理员考试真题、食品安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 121.关于食品召回的说法,以下表述不正确的是(&am…...

Keychron K7 Pro 轻薄矮轴机械键盘开箱体验
文章目录1. 拆箱2. 零件3. 外观4. 声音5. 特点5.1 有线 / 无线5.2 RGB背光5.3 轻薄5.4 mac / win / iphone 切换5.5 人体工程学支持5.6 扁平双射PBT键帽5.7 重新设计的稳定器5.8 扁平Gateron(佳达隆)轴体5.9 热插拔5.10 支持 QMK / VIA 改键6. 对比6.1 K7 与 K7 Pro 参数对比6.…...
加油站ai视觉识别系统 yolov7
加油站ai视觉识别系统通过yolov7网络模型深度学习,加油站ai视觉识别算法对现场画面中人员打电话抽烟等违规行为,还有现场出现明火烟雾等危险状态。除此之外,模型算法还可以对卸油时灭火器未正确摆放、人员离岗不在现场、卸油过程静电释放时间…...
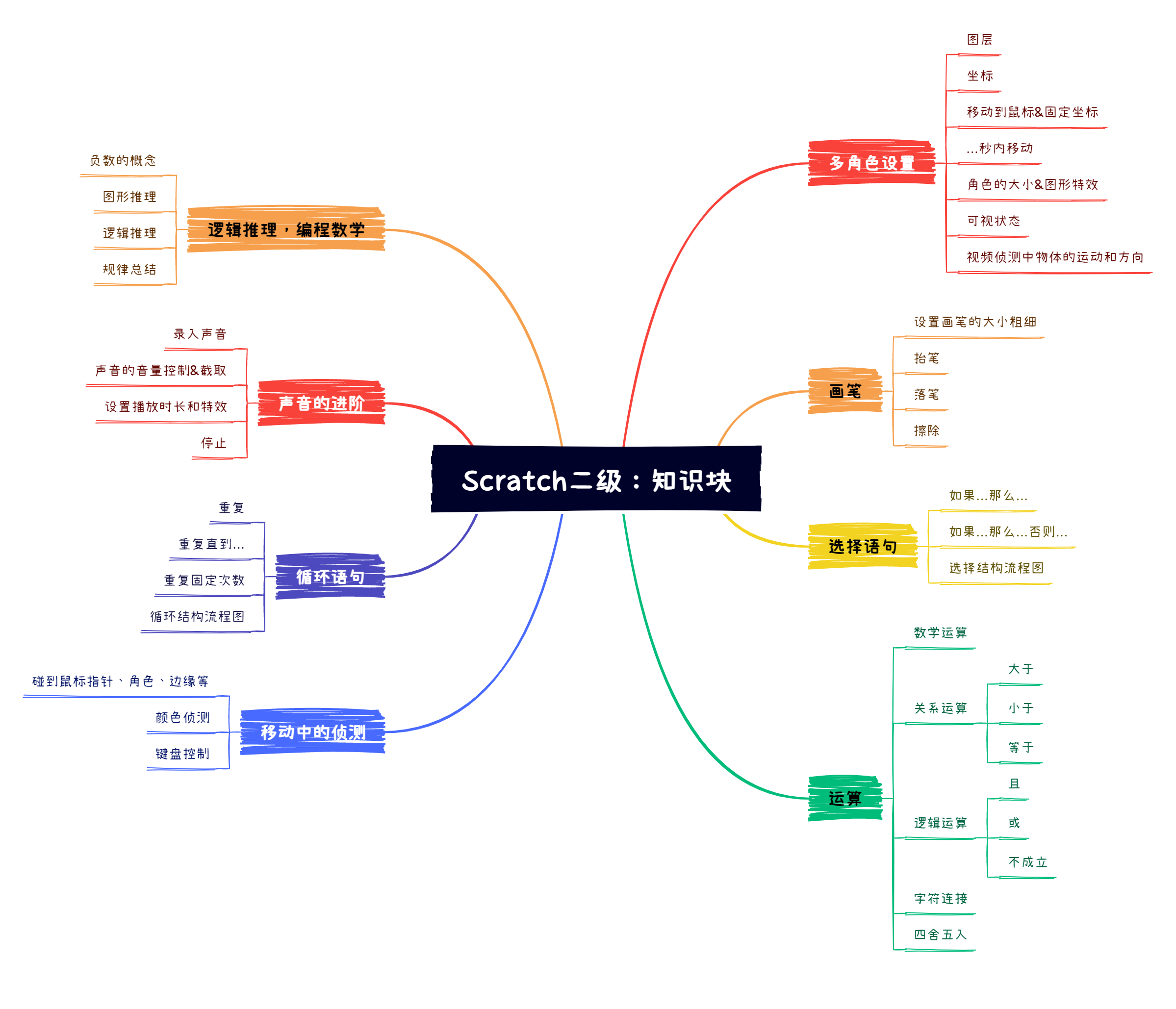
【电子学会】2022年12月图形化二级 -- 绘制风车
绘制风车 1. 准备工作 (1)隐藏默认的小猫角色; (2)选择背景:“Xy-grid”。 2. 功能实现 (1)小猫角色的初始位置为(x:0,y:0); (2)线条粗细为…...

【golang/go语言】Go语言代码实践——高复用、易扩展性代码训练
某个项目里有一段老代码写的不是很好,想着能否通过自己掌握的知识,将其改善一下。感兴趣的小伙伴可以通过了解背景和需求,自己试想下该如何实现,如果有更好的方案也欢迎留言讨论。 1. 背景及需求 (1) 背景 假设我们的下游提供了…...
[数据结构与算法(严蔚敏 C语言第二版)]第1章 绪论(学习复习笔记)
1.1 数据结构的研究内容 计算机解决问题的步骤 从具体问题抽象出数学模型设计一个解此数学模型的算法编写程序,进行测试、调试,直到解决问题 计算机解决问题的过程中寻求数学模型的实质是 分析问题,从中提取操作的对象,并找出这些…...

05_Pulsar的主要组件介绍与命令使用、名称空间、Pulsar的topic相关操作、Pulsar Topic(主题)相关操作_高级操作、
1.5.Apache Pulsar的主要组件介绍与命令使用 1.5.1.多租户模式 1.5.1.1. 什么是多租户 1.5.1.2.Pulsar多租户的相关特征_安全性(认证和授权) 1.5.1.3.Pulsar多租户的相关特性_隔离性 1.5.1.4.Pulsar多租户的相关操作 1-获取租户列表 2-创建租户 3-获取配…...

我的终端怎么莫名卡死了?shell下ctrl+s的含义
在终端下面一不小心按下了ctrl s,整个终端就锁住了,不知道原油的同学可能会以为终端卡死了,找不到原因只好关闭终端重新打开,然后下意识还不忘吐槽一句,垃圾ubuntu,动不动卡死。 事实上ctrl s在终端下是…...
【Vue】Vue的简单介绍与基本使用
一、什么是VueVue是一款用于构建用户界面的 JavaScript 框架。它基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型,帮助你高效地开发用户界面。无论是简单还是复杂的界面,Vue 都可以胜任。1.构建用户界面传统方…...

C++ 模板元编程性能优化技巧
C模板元编程性能优化技巧 在现代C开发中,模板元编程(TMP)因其编译期计算能力而备受推崇,能够在运行时实现零开销抽象。不当使用可能导致编译时间膨胀或代码可读性下降。本文将介绍几项关键优化技巧,帮助开发者高效利用…...

AI大模型系统学习路线:零基础入门人工智能,附AI大模型学习与面试资源!【非常详细】
人工智能(AI)正在重塑全球产业格局,从自动驾驶到医疗诊断,从金融风控到内容创作,AI技术已成为21世纪的核心竞争力。对于零基础学习者而言,构建系统化的学习路径至关重要。1. 明确学习动机职业转型 …...

高可用外卖返利 CPS 平台:Java 后端异步回调处理机制深度解析
高可用外卖返利 CPS 平台:Java 后端异步回调处理机制深度解析 在构建外卖返利(CPS)系统时,异步回调(Callback)机制是连接用户授权、订单同步与佣金结算的神经中枢。美团、饿了么等平台的用户授权与订单状态…...

2025_NIPS_G1: Teaching LLMs to Reason on Graphs with Reinforcement Learning
文章核心总结与创新点 核心内容 本文针对大型语言模型(LLMs)在图推理任务中表现有限的问题,提出了一种基于强化学习(RL)的方法G1。通过在大规模合成图论任务数据集Erdős上训练,G1显著提升了LLMs的图推理能力,且在未见过的任务、领域和图编码方案中表现出强泛化性,同…...

手把手教程:快速设置远程开机,看完就会
今天就给大家带来一份完整、可直接照着操作的远程开机教程,即可实现无需公网 IP、一键远程唤醒,随时随地让设备为你待命。设备支持检查确认主板支持WAKE-ON-LAN(网络唤醒)功能,局域网内需具备两台设备:目标…...

考研408计算机学科专业基础综合——操作系统复习
考研408计算机学科专业基础综合 操作系统复习 核心说明:本笔记聚焦考研408操作系统高频考点、必背知识点,贴合命题规律(选择题大题并重),剔除冗余内容,突出重难点,适配冲刺复习与基础巩固&#…...

个人学习实时数据管道框架--4 数据入湖实战
4.1 环境准备 1. 安装 Java 8+ 和 Maven 3.6+ 2. 下载项目代码:git clone <项目地址> 3. 配置环境变量:JAVA_HOME, HADOOP_HOME 4.2 配置文件 核心配置文件 application.properties: # Flink 配置 flink.job.name=VehicleSOCPipeline flink.parallelism=4 flink…...

【AI】AI安全工具:常用AI安全检测工具的使用教程
AI安全工具:常用AI安全检测工具的使用教程📝 本章学习目标:本章介绍实用工具,帮助读者掌握AI安全合规治理的工具使用。通过本章学习,你将全面掌握"AI安全工具:常用AI安全检测工具的使用教程"这一…...

GHelper完整指南:免费轻量级华硕笔记本性能控制工具终极教程
GHelper完整指南:免费轻量级华硕笔记本性能控制工具终极教程 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Str…...

S-UI配置文件加密终极指南:保护敏感信息的最佳实践 [特殊字符]
S-UI配置文件加密终极指南:保护敏感信息的最佳实践 🔒 S-UI是一款基于SagerNet/Sing-Box构建的高级Web面板,提供多协议支持和流量管理功能。在使用过程中,配置文件包含大量敏感信息,如API密钥、用户数据和服务器配置&…...