【Elasticsearch查询】精确查询
文章目录
- 复合查询
- constant_score query
- bool query
- dis_max query
- function_score query
- boosting query
- 单层嵌套
- 双层嵌套
- 词项查询
- term query(词项查询)
- 数字的精确查询
- 文本的精确查询
- 查询优化
- terms query(多词项查询)
- terms_set query
- range query (范围查询)
- exists query (存在查询)
- null_value
- prefix query (前缀查询)
- wildcard query (通配符查询)
- regexp query (正则查询)
- fuzzy query (模糊查询)
- type query (类型查询)
- ids query(ID查询)
复合查询
复合查询封装了其他复合查询或子查询,可以组合它们的结果和分数,改变它们的行为,或者从查询切换到过滤上下文。
constant_score query
包装另一个查询,但在筛选器上下文中执行它的查询。给所有匹配的文档相同的“常量”_score。
GET /_search
{"query": {"constant_score" : {"filter" : {"term" : { "user" : "kimchy"}},"boost" : 1.2}}
}
bool query
用于组合多个子查询或复合查询子句的默认查询,如must、should、must_not或filter子句。must和should子句的分数组合在一起——匹配的子句越多越好——而must_not和filter子句则在过滤器上下文中执行。
POST _search
{"query": {"bool" : {"must" : {"term" : { "user" : "kimchy" }},"filter": {"term" : { "tag" : "tech" }},"must_not" : {"range" : {"age" : { "gte" : 10, "lte" : 20 }}},"should" : [{ "term" : { "tag" : "wow" } },{ "term" : { "tag" : "elasticsearch" } }],"minimum_should_match" : 1,"boost" : 1.0}}
}
dis_max query
接受多个查询并返回与任何查询子句匹配的任何文档的查询。bool查询组合来自所有匹配查询的分数,而dis_max查询使用单个最佳匹配查询子句的分数。
GET /_search
{"query": {"dis_max" : {"tie_breaker" : 0.7,"boost" : 1.2,"queries" : [{"term" : { "age" : 34 }},{"term" : { "age" : 35 }}]}}
}
function_score query
使用函数修改主查询返回的分数,以考虑流行度、近似性、距离或脚本实现的自定义算法等因素。
要使用function_score,用户必须定义一个查询和一个或多个函数,这些函数为查询返回的每个文档计算一个新分数。
GET /_search
{"query": {"function_score": {"query": { "match_all": {} },"boost": "5","random_score": {}, "boost_mode":"multiply"}}
}
boosting query
返回与正查询匹配的文档,但减少与负查询匹配的文档的分数。
boosting查询可用于有效地降级与给定查询匹配的结果。与bool查询中的“NOT”子句不同,它仍然选择包含不需要的词语的文档,但会降低它们的总体得分。
GET /_search
{"query": {"boosting" : {"positive" : {"term" : {"field1" : "value1"}},"negative" : {"term" : {"field2" : "value2"}},"negative_boost" : 0.2}}
}
单层嵌套
组成部分
{"bool" : {"must" : [],"should" : [],"must_not" : [],}
}
must : 所有的语句都 必须(must) 匹配,与 AND 等价。
must_not : 所有的语句都 不能(must not) 匹配,与 NOT 等价。
should : 至少有一个语句要匹配,与 OR 等价。
GET /my_store/_doc/_search
{"query": {"bool": {"should": [{"term": {"price": 20}},{"term": {"productID": "XHDK-A-1293-#fJ3"}}],"must_not": {"term": {"price": 30}}}}
}
双层嵌套
GET /my_store/_doc/_search
{"query": {"bool": {"should": [{"term": {"productID": "KDKE-B-9947-#kL5"}},{"bool": {"must": [{"term": {"productID": "JODL-X-1937-#pV7"}},{"term": {"price": 30}}]}}]}}
}词项查询
全文查询将在执行之前对查询字符串进行分词,而词项级查询将对存储在反向索引中的精确词项进行操作,并且执行前对只对具有normalizer属性的keyword字段词项进行规范化。
这些查询通常用于数字、日期和枚举等结构化数据,而不是全文字段。或者,它们允许您在分析过程之前创建低级查询。
term query(词项查询)
查找包含在指定字段中确切指定的词项的文档。
词项查询查找包含倒排索引中指定的精确词项的文档。例如:
POST _search
{"query": {"term" : { "user" : "Kimchy" } }
}
在用户字段的倒排索引中查找包含确切的术语Kimchy的文档。
权重:boost
Why doesn’t the term query match my document?
字符串字段可以是text类型(作为全文处理,如电子邮件的正文)或keyword类型(作为精确值处理,如电子邮件地址或邮政编码)。精确值(如数字、日期和关键字)将字段中指定的精确值添加到反向索引中,以使它们可搜索。
但是,对text 字段进行分析。这意味着它们的值首先通过分析器生成一个词项列表,然后将其添加到反向索引中。
分析文本有很多方法:默认的standard analyzer会去掉大多数标点符号,将文本分解为单个单词,并将它们小写。例如,standard的分析器会将字符串“Quick Brown Fox!”分词为[quick, brown, fox].。
这个分析过程使得在一个大块段落中搜索单个单词成为可能。
词项查询在字段的倒索引中查找确切的词项—它不知道关于字段的分析器的任何信息。这使得它在keyword 字段、数字或日期字段中查找值非常有用。在查询全文文本字段时,使用match查询,它理解如何分析字段。
为了演示,请尝试下面的示例。首先,创建一个索引,指定字段映射,索引一个文档:
PUT my_index
{"mappings": {"_doc": {"properties": {"full_text": {"type": "text" },"exact_value": {"type": "keyword" }}}}
}PUT my_index/_doc/1
{"full_text": "Quick Foxes!", "exact_value": "Quick Foxes!"
}
现在,比较term查询和match查询的结果:
GET my_index/_search
{"query": {"term": {"exact_value": "Quick Foxes!" }}
}GET my_index/_search
{"query": {"term": {"full_text": "Quick Foxes!" }}
}GET my_index/_search
{"query": {"term": {"full_text": "foxes" }}
}GET my_index/_search
{"query": {"match": {"full_text": "Quick Foxes!" }}
}
数字的精确查询
非评分模式查询数字
GET /my_store/products/_search
{"query" : {"constant_score" : { "filter" : {"term" : { "price" : 20}}}}
}
文本的精确查询
1、text字段可设置为无需分析的
"properties" : {"productID" : {"type" : "string","index" : "not_analyzed" }}
2、直接设置为KeyWord类型,可通过非评分模式和布尔查询实现精确匹配
查询优化
理论上非评分查询 先于 评分查询执行。非评分查询任务旨在降低那些将对评分查询计算带来更高成本的文档数量,从而达到快速搜索的目的。
terms query(多词项查询)
查找包含指定字段中指定的任何确切词项的文档。
筛选具有与所提供的任何词项(未分析)匹配的字段的文档。例如:
GET /_search
{"query": {"terms" : { "user" : ["kimchy", "elasticsearch"]}}
}
terms_set query
返回与至少一个或多个提供的词项匹配的任何文档。这些词项没有被分析,因此必须精确匹配。必须匹配的词的数量在每个文档中都是不同的,或者由最小应匹配字段控制,或者在每个文档中计算最小应匹配脚本。
控制必须匹配的必需词汇的数量的字段必须是一个数字字段:
PUT /my-index
{"mappings": {"_doc": {"properties": {"required_matches": {"type": "long"}}}}
}PUT /my-index/_doc/1?refresh
{"codes": ["ghi", "jkl"],"required_matches": 2
}PUT /my-index/_doc/2?refresh
{"codes": ["def", "ghi"],"required_matches": 2
}GET /my-index/_search
{"query": {"terms_set": {"codes" : {"terms" : ["abc", "def", "ghi"],"minimum_should_match_field": "required_matches"}}}
}
range query (范围查询)
查找指定字段中包含指定范围内的值(日期、数字或字符串)的文档。
GET _search
{"query": {"range" : {"age" : {"gte" : 10,"lte" : 20,"boost" : 2.0}}}
}
符号:
gt gte lt lte
查询过去一个小时内的所有文档
"range" : {"timestamp" : {"gt" : "now-1h"}
}
某一段时间
"range" : {"timestamp" : {"gt" : "2020-01-01 00:00:00","lt" : "2020-01-01 00:00:00||+1M" }
}
exists query (存在查询)
返回原始字段中至少有一个非空值的文档:
GET /_search
{"query": {"exists" : { "field" : "user" }}
}
不会被匹配到的情况:
{ "user": null }
{ "user": [] }
{ "user": [null] }
{ "foo": "bar" }
null_value
如果字段映射包含null_value设置,则显式的空值将被指定的null_value替换。例如,如果用户字段映射如下:
PUT /example
{"mappings": {"_doc": {"properties": {"user": {"type": "keyword","null_value": "_null_"}}}}
}
然后显式的空值将被索引为字符串null,当搜寻非空文档时,null值依然可以被搜索到
{ "user": null }
{ "user": [null] }
返回字段为空的文档:
GET /_search
{"query": {"bool": {"must_not": {"exists": {"field": "user"}}}}
}
prefix query (前缀查询)
查找指定字段中包含以指定的确切前缀开头的词项的文档。
GET /_search
{ "query": {"prefix" : { "user" : "ki" }}
}
权重:boost
wildcard query (通配符查询)
查找指定字段中包含与指定模式匹配的词项的文档,其中模式支持单字符通配符(?)和多字符通配符(*)
GET /_search
{"query": {"wildcard" : { "user" : "ki*y" }}
}
regexp query (正则查询)
查找指定字段中包含与指定的正则表达式匹配的词项的文档。
注意:regexp查询的性能在很大程度上取决于所选的正则表达式。与使用lookaround正则表达式一样,匹配像.*这样的所有内容会非常慢。如果可能,您应该尝试在正则表达式开始之前使用一个长前缀。像.*?+会大大降低性能。
GET /_search
{"query": {"regexp":{"name.first": "s.*y"}}
}
fuzzy query (模糊查询)
查找指定字段中包含与指定词项有模糊相似之词项的文档。模糊查询使用基于Levenshtein编辑距离的相似性。
模糊查询生成在模糊性中指定的最大编辑距离内的匹配词项,然后检查词项字典,以找出这些生成的词项中哪些确实存在于索引中。最后一个查询使用最多max_expansions匹配的词项。
GET /_search
{"query": {"fuzzy" : { "user" : "ki" }}
}
高级查询:
GET /_search
{"query": {"fuzzy" : {"user" : {"value": "ki","boost": 1.0,"fuzziness": 2,"prefix_length": 0,"max_expansions": 100}}}
}
type query (类型查询)
筛选与所提供的文档/映射类型匹配的文档。
GET /_search
{"query": {"type" : {"value" : "_doc"}}
}
ids query(ID查询)
查找具有指定类型和id的文档。
GET /_search
{"query": {"ids" : {"type" : "_doc","values" : ["1", "4", "100"]}}
}
相关文章:

【Elasticsearch查询】精确查询
文章目录 复合查询constant_score querybool querydis_max queryfunction_score queryboosting query单层嵌套双层嵌套 词项查询term query(词项查询)数字的精确查询文本的精确查询查询优化 terms query(多词项查询)terms_set que…...
小狐狸chat2.7.2免授权修复版可用版
小狐狸chat2.7.2免授权修复版可用版 在网络上面找了好几个版本不能使用,今天发布这个仔细测试正常使用 主要功能:独立版无限多开支持分销会员充值自己APP打包小程序万能创作MJ绘图多个国内接口 国外很火的ChatGPT,这是一种基于人工智能技术…...
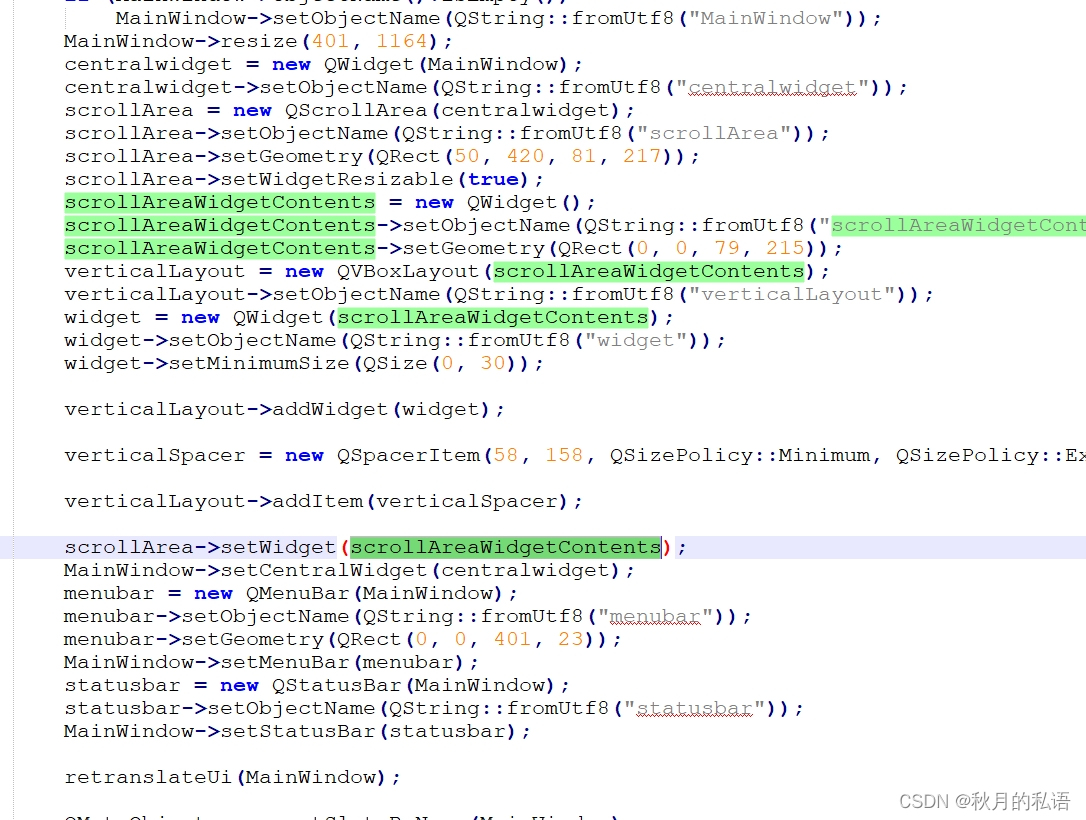
通过QScrollArea寻找最后一个弹簧并且设置弹簧大小
项目原因,最近需要通过QScrollArea寻找其中最后一个弹簧并且设置大小和策略,因为无法直接调用UI指针,所以只能用代码寻找。 直接上代码: if (m_scrollArea){int iScrollWidth m_labelSelectedTitle->width();m_scrollArea-&g…...

為什麼使用海外動態代理IP進行網路爬蟲?
網路爬蟲作為獲取網路數據的重要工具,其重要性不言而喻。但隨著網站反爬策略的日益嚴格,爬蟲任務變得愈發困難,不過海外動態代理IP可以很好地解決這一問題。本文將詳細闡釋動態代理IP在爬蟲中的應用,以及如何使用動態代理IP提升爬…...

LeetCode 热题100 刷题笔记
一:哈希表 一般哈希表都是用来快速判断一个元素是否出现集合里。 直白来讲其实数组就是一张哈希表,哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素。 1.两数之和 题目链接:. - 力扣(LeetCode…...

veridata安装
GoldenGate Veridata是GoldenGate中用于比较数据库间数据同步效果的一个对比软件。Veridata基于Web,支持大据量的数据对比,能够在不停止数据同步的情况下就可以比较数据。 1、安装veridata前我们都会先安装 middleware infrastructure 这时我们会添加几个…...
面试笔记系列三之spring基础知识点整理及常见面试题
目录 如何实现一个IOC容器? 说说你对Spring 的理解? 你觉得Spring的核心是什么? 说一下使用spring的优势? Spring是如何简化开发的? IOC 运行时序 prepareRefresh() 初始化上下文环境 obtainFreshBeanFactory() 创建并…...

面试笔记系列四之SpringBoot+SpringCloud+计算机网络基础知识点整理及常见面试题
目录 Spring Boot 什么是 Spring Boot? Spring Boot 有哪些优点? SpringBootApplication注解 Spring Boot 的启动流程 Spring Boot属性加载顺序 springboot自动配置原理是什么?(*) 如何理解springboot中的start…...

Kernel[Device Tree] - 1. 设备树的由来
内核代码中,arch文件夹下,是各个架构相关的代码,arm也在里面。 arm子文件夹下,有mach-xxx的目录,就是针对各个芯片类型的,比如mach-imx就是imx系列的芯片。 再里面就是具体的芯片或SOC,比如ma…...

第十四天-网络爬虫基础
目录 1.什么是爬虫 2.网络协议 OSI七层参考模型 TCP/IP模型 1.应用层 2.传输层 3.网络层 3.HTTP协议 1.介绍 2.http版本: 3.请求格式 4.请求方法 5.HTTP响应 状态码: 6.http如何连接 4.Python requests模块 1.安装 2.使用get/post 3.响…...

Linux系统安装
Linux系统安装 安装包链接 链接:https://pan.baidu.com/s/1FdP7TH90UvKUQuiL2yeGCA 提取码:c49n安装包内容 虚拟机执行文件 详细安装教程 虚拟机密钥 Ubuntu 安装步骤 先点击虚拟机的.EXE文件安装,打开安装教程,有详细的说明。...
springboot-基础-thymeleaf配置+YAML语法
备份笔记。所有代码都是2019年测试通过的,如有问题请自行搜索解决! 目录 配置thymeleafthymeleaf举例参数设置yaml基础知识YAML语法报错:Expecting a Mapping node but got 其他语法 spring boot不推荐使用jsp。thymeleaf是一个XML/XHTML/HTM…...
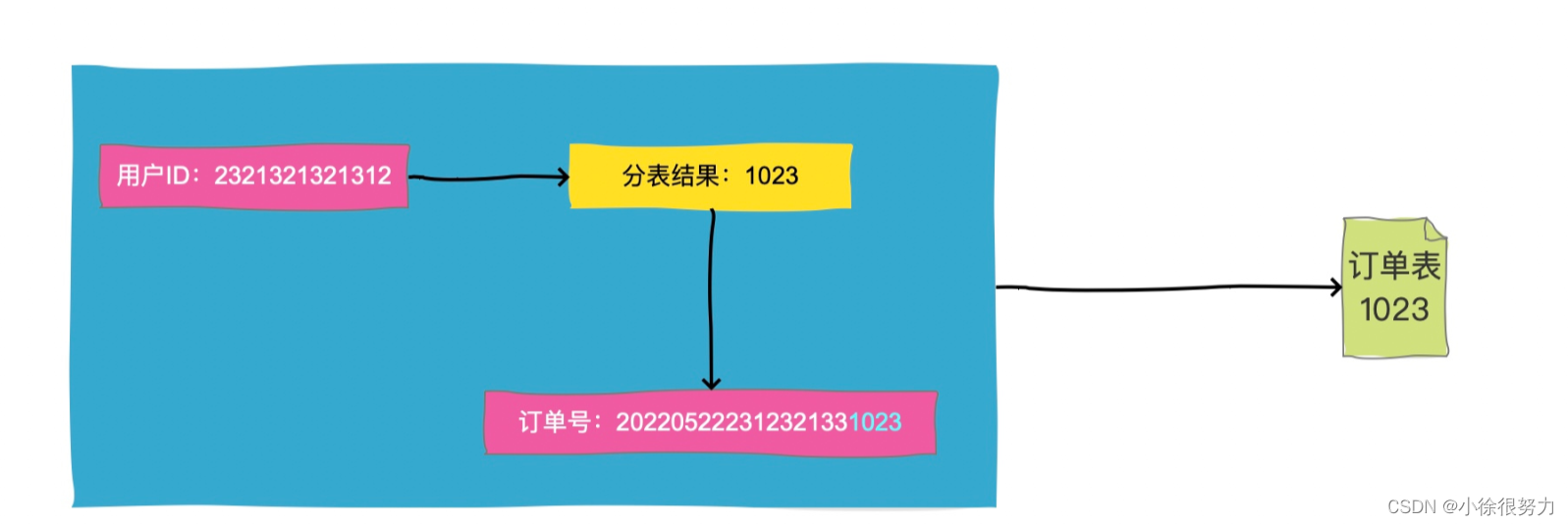
深入理解分库、分表、分库分表
前言 分库分表,是企业里面比较常见的针对高并发、数据量大的场景下的一种技术优化方案,所谓"分库分表",根本就不是一件事儿,而是三件事儿,他们要解决的问题也都不一样,这三个事儿分别是"只…...

Oracle中序列
1. Sequence 定义 在Oracle中可以用SEQUENCE生成自增字段。Sequence序列是Oracle中用于生成数字序列的对象,可以创建一个唯一的数字作为主键。 2. 为什么要用 Sequence 你可能有疑问为什么要使用序列? 不能使用一个存储主键的表并每次递增吗…...
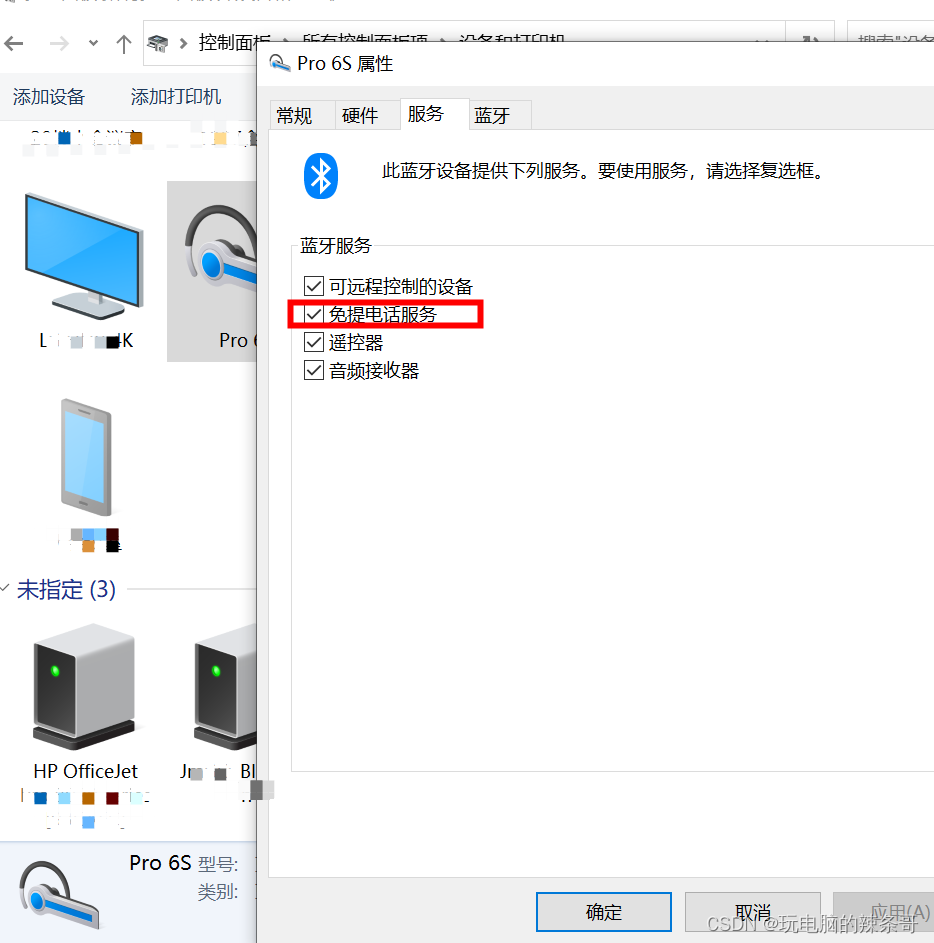
蓝牙耳机和笔记本电脑配对连接上了,播放设备里没有显示蓝牙耳机这个设备,选不了输出设备
环境: WIN10 杂牌蓝牙耳机6s 问题描述: 蓝牙耳机和笔记本电脑配对连接上了,播放设备里没有显示蓝牙耳机这个设备,选不了输出设备 解决方案: 1.打开设备和打印机,找到这个设备 2.选中这个设备&#…...

Cadence Allegro PCB设计88问解析(三十四) 之 Allegro 中 DDR等长处理
一个学习信号完整性仿真的layout工程师 在进行PCB设计时 ,会遇到一些单端的信号要做等长处理,比如DDR的数据线,交换机之间的数据线之类的。这时需要我们建立match group,来做等长。下面简单介绍在Allegro中怎么做等长:…...
>)
向爬虫而生---Redis 探究篇2<redis集群(1)>
前言: 经常会遇到这样的事,redis运行一段时间以后,就会出现迟钝和卡壳! 这时候,说明已经到了瓶颈期了,需要用到redis集群了! 那么,弄明白集群的几个概念是必要的,我用案例来讲,,, 正文: 当需要处理大量数据或提供高可用性和性能时,Redis集群是一种常见的解决方案。…...

[云原生] 二进制安装K8S(上)搭建单机matser、etcd集群和node节点
一、单机matser预部署设计 目前Kubernetes最新版本是v1.25,但大部分公司一般不会使用最新版本。 目前公司使用比较多的:老版本是v1.15,因为v1.16改变了很多API接口版本,国内目前使用比较多的是v1.18、v1.20。 组件部署ÿ…...
)
乘积尾零(蓝桥杯)
文章目录 乘积尾零题目描述代码 乘积尾零 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 如下的 10 行数据,每行有 10 个整数,请你求出它们的乘积的末尾有多少个零? 5650 454…...

项目解决方案: 实时视频拼接方案介绍
目 录 1、实时视频拼接概述 2、适用场景 3、系统介绍 3.1拼接形式 3.1.1横向拼接 3.1.2纵向拼接 3.2前端选择 3.2.1前端类型 3.2.2推荐配置 3.3后端选择 3.3.1录像回放 3.3.2客户端展示 4、拼接方案介绍 4.1基于4K摄像机的拼接方案 4.1.1系统架构…...

【TensorRT】—— 动态Batch推理实战:从模型导出到trtexec性能深度解析
1. 动态Batch推理的核心价值与应用场景 想象一下你正在开发一个智能视频分析系统,白天需要处理大量实时监控画面(高并发小batch),深夜则要批量处理历史录像(低并发大batch)。如果每次都要为不同batch size重…...

从‘心跳’到‘急停’:图解CANopen CIA 402状态机,让你的电机控制逻辑不再混乱
从‘心跳’到‘急停’:图解CANopen CIA 402状态机,让你的电机控制逻辑不再混乱 在工业自动化领域,电机控制的稳定性和可靠性直接影响着整个系统的性能。CANopen协议作为工业通信的主流标准之一,其CIA 402子协议专门为电机控制定义…...
|类与对象基础(封装、构造 / 析构函数,面试必考))
C++ 从 0 入门(三)|类与对象基础(封装、构造 / 析构函数,面试必考)
大家好,我是网域小星球。 本篇是 C 面向对象的核心开篇,也是 C 面试重中之重 —— 类与对象基础。面试官几乎都会问封装、构造函数、析构函数的用法,甚至让手撕代码。本篇全程聚焦面试考点,不冗余、只讲核心,代码 VS2…...

JBoltAI工业数智化SOP:助力“人工智能+”工业新发展
在“人工智能”工业浪潮席卷而来的当下,工业领域的数智化转型成为必然趋势。JBoltAI工业数智化SOP产品,凭借其独特的功能架构,为工业企业的标准化作业流程管理带来了新的思路与解决方案。清晰架构,高效管理SOP内容JBoltAI工业数智…...

如何用roop-unleashed快速制作高质量AI换脸视频:完整入门指南
如何用roop-unleashed快速制作高质量AI换脸视频:完整入门指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要在几分钟内制作出专业级AI换脸…...

STM32LL库实战入门:从零搭建高效开发环境
1. 为什么选择STM32 LL库开发? 第一次接触STM32 LL库的开发者可能会有疑问:已经有了HAL库和标准库,为什么还要学习LL库?这个问题要从嵌入式开发的效率需求说起。我在实际项目中遇到过这样的情况:使用STM32F030芯片做电…...

AD20封装库疑难杂症:从“Footprint Not Found”到ECO一键修复
1. 当AD20大喊"Footprint Not Found"时,到底发生了什么? 每次看到AD20弹出"Footprint Not Found"的红色警告框,我都忍不住想吐槽:明明封装库就在那里,为什么软件就是找不到?这个问题困…...

5分钟上手LogcatReader:安卓设备日志查看神器
5分钟上手LogcatReader:安卓设备日志查看神器 【免费下载链接】LogcatReader A simple app for viewing logcat logs on an android device. 项目地址: https://gitcode.com/gh_mirrors/lo/LogcatReader 还在为复杂的ADB命令而烦恼吗?LogcatReade…...

别再搞混了!Verilog里数组、向量和存储器的赋值与读写,新手避坑指南
Verilog数据存储结构深度解析:从位操作到存储器建模实战 刚接触Verilog的工程师常会被其灵活的数据存储结构所困扰——什么时候用向量?什么时候用数组?存储器又该如何正确建模?这些看似基础的概念一旦混淆,就会在仿真和…...

5分钟搞定!Android Studio中文界面完整汉化终极指南
5分钟搞定!Android Studio中文界面完整汉化终极指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android St…...