1_SQL
文章目录
- 前端复习
- SQL
- 数据库的分类
- 关系型数据库
- 非关系型数据库(NoSQL)
- 数据库的构成
- 软件架构
- MySQL内部数据组织方式
- SQL语言
- 登录数据库
- 数据库操作
- 查看库
- 创建库
- 删除库
- 修改库
- 数据库中表的操作
- 选择数据库
- 创建表
- 删除表
- 查看表
- 修改表
- 数据库中数据的操作
- 添加数据
- 查询数据
- 修改数据
- 删除数据
- 特殊关键字
- where(条件关键字)
- distinct(过滤关键字)
- limit(限制结果集关键字)
- as(取别名关键字)
- order by(排序关键字)
- group by(分组关键字)
- 聚合函数
- SQL语句的执行顺序
前端复习
- HTML
- 以标签为基础
- 主要负责页面上内容的搭建
- css
- 控制页面的样式,字体的大小,图片等等
- 主要控制样式,页面的布局
- 大
div套小div
- js
- 页面上动态内容的功能,比如点击按钮之后、完成验证码的校验等等
- html解析之后,在浏览器上以dom树的形式存在,即对dom树的增删改查
- vue
- 帮我们操作dom,我们只用操作数据,数据会自己写在页面上
- 插值表达式、v-bind/v-model/v-on/v-for
SQL
数据库的分类
关系型数据库
- 不仅可以存储数据,还可以存储数据与数据之间的关系。
常见的关系型数据库:
- Oracle
- MySQL
- MariaDB
- SQL Server
- DB2
- PostgreSQL
非关系型数据库(NoSQL)
- 对关系型数据库的补充,主要是用来做一些关系型数据库不擅长的事情。
- 关系型数据库的数据,一般是存储在磁盘上,所以速度比较慢。非关系型数据库一般是存在内存中的,所以性能比较好。
常见的非关系型数据库:
- Redis
- 最常用的非关系型数据库,数据存在内存,速度快,吞吐量高。
- Memcached
- Mongodb
- Hbase
关系型数据库和非关系型数据库的区别:
- 最本质的区别是::关系型数据库以
数据和数据之间存在的关系维护数据, 而非关系型数据库是指存储数据的时候数据和数据之间没有什么特定关系. - 在大多数时候,非关系型数据库是在传统关系型数据库基础上(其实已经基本上完全不同), 在功能上简化, 在数据存储结构上大大改变,在效率上提升, 通过减少用不到或很少用的功能,在能力弱化的同时也带来产品性能的大幅度提高。
- 但是本质上讲, 他们都是用来存储数据的. 而对于我们Java后端开发来讲, 我们在工作中基本上是以关系型数据库为主, 非关系型数据库为辅的用法.
数据库的构成
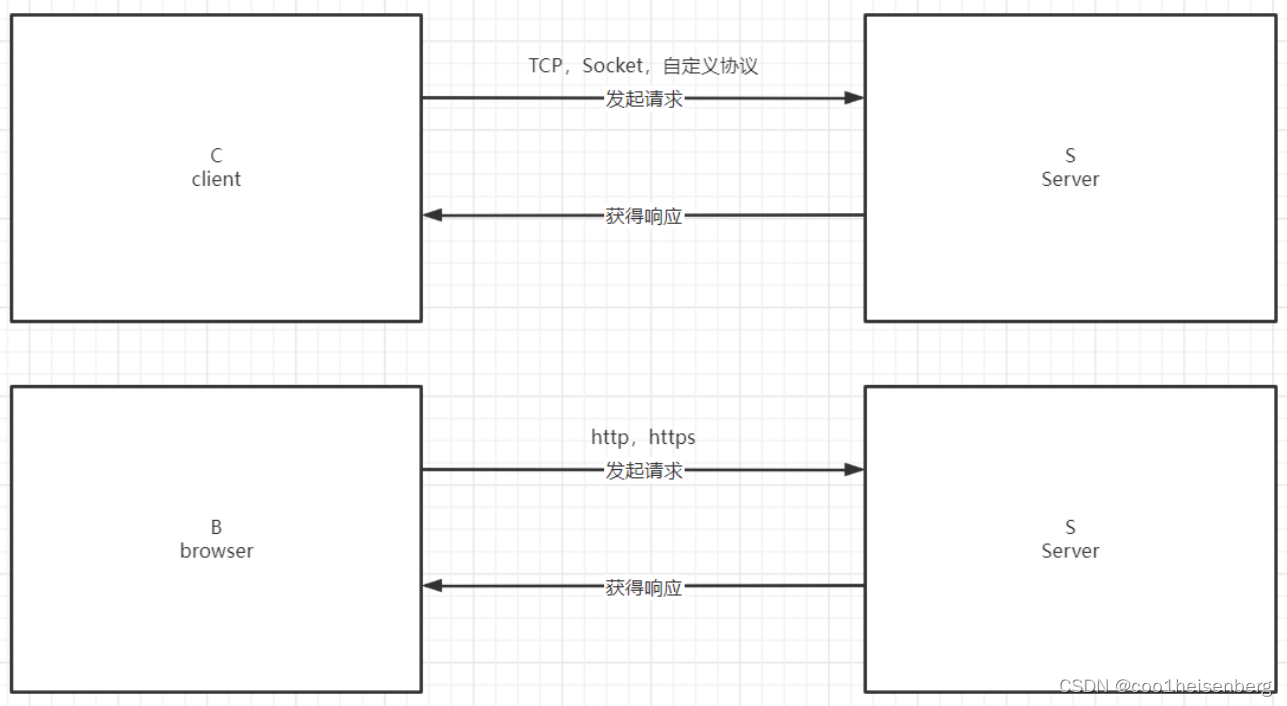
软件架构
- B/S:Browser-Server即浏览器和服务器, 即通过浏览器和服务器发起网络交互的数据请求.
- 常见的B/S架构: 淘宝、京东、拼多多、百度
- C/S:Client-Server即客户端和服务器, 即通过客户端和服务器发起网络交互的数据请求.
- 常见的C/S架构:英雄联盟、QQ、微信、数据库、手机app
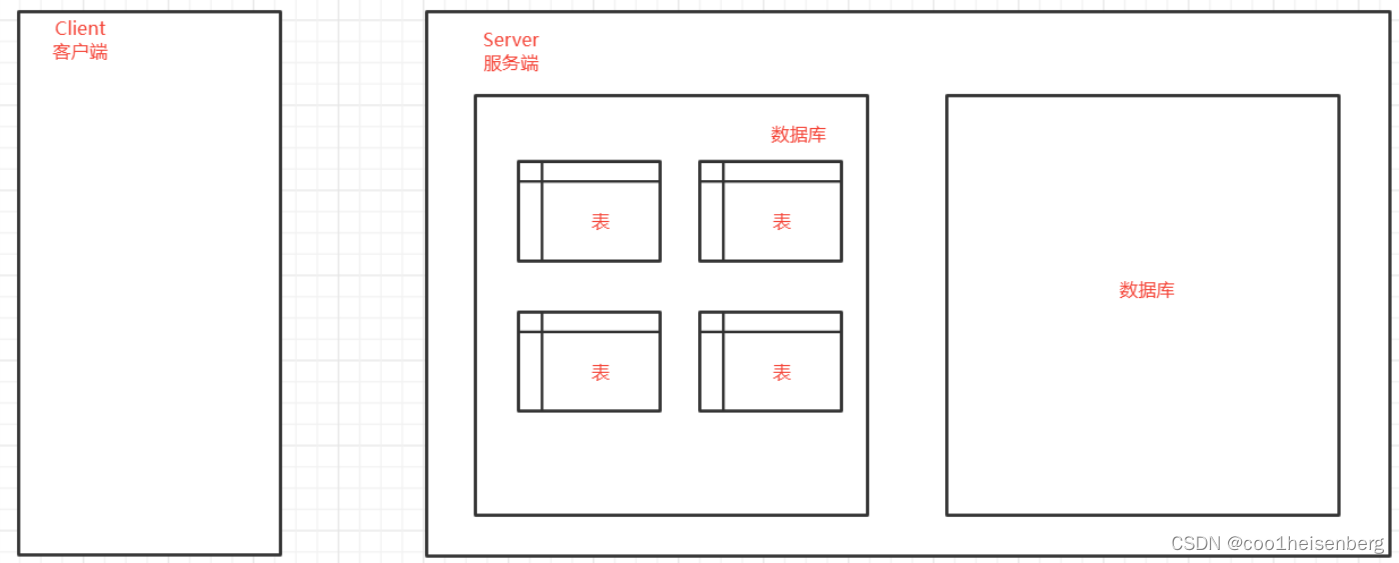
MySQL内部数据组织方式
- 数据库: 表示一份完整的数据仓库, 在这个数据仓库中分为多张不同的表。
- 表:表示某种特定类型数据的的结构化清单, 里面包含多条数据。
- 数据: 表中数据的基本单元。
SQL语言
登录数据库
$ mysql -uroot -p
输入密码(******)
数据库操作
查看库
查看所有的数据库
show databases;模糊匹配查看相关的数据库
show databases like "system%";
-- test% 表示以test开头
-- %info 表示以info结尾
-- %info% 表示info可以出现在任意位置查看当时创建数据库的命令
show create database test;
-- 查看当时创建数据库test的命令注释:
1. 第一种注释
-- <注释的内容>
-- 两个‘-’后面一定要有一个空格2. 第二种注释
#<注释的内容>
-- ‘#’后面可以不加空格3. 第三种注释
/*
<注释的内容>
*/
注意:
- 不要删除系统自带的几个数据库
information_schemamysqlperformance_schemasys
创建库
创建一个数据库
create database db_test;
-- 注意:创建一个叫 db_test 的数据库,其中注意:库名,表名,列名均不区分大小写
-- 如果要写库名为dbTest,则可以把 dbTest 写成 db_test创建一个数据库并指定字符集和指定校对规则
create database db_test character set utf8mb4 collate utf8mb4_bin;
-- mysql里面有一个字符集是utf8,但它是假的,是使用1-3个字节来存储数据,
-- 如果要使用utf8的编码,应该使用utf8mb4,utf8mb4是4个字节存储数据-- 校对规则是用来比较大小的
-- _ci(case insensitive 大小写不敏感)
-- _cs(case sensitive 大小写敏感)
-- eg:utf8mb4_bin、utf8mb4_general_ci
eg:create database db_test2 character set utf8mb4 collate utf8mb4_ci;-- 如果不指定一个字符集,则一般是默认的 latin1
-- latin1一般是不支持中文的
删除库
删除名称为db_test的数据库:
drop database db_test;
修改库
数据库中未提供改库名的操作,只提供修改字符集和校对规则。
修改指定库的字符集和校对规则:
alter database db_test character set utf8 collate utf8_bin;
数据库中表的操作
选择数据库
选择指定的数据库:
use db_test;查看当前在什么库:
select database();
创建表
- Mysql中大小写不敏感
- 不要使用数据库来存储大文件
- 设计数据库字段的时候,一定要留有一定的冗余
create table table_name(字段名 字段类型);
-- 括号里面写有哪些列,以及列类型
eg:
create table test_time(id int, date1 date, time1 timestamp);
create table test_number(id int, float1 float(4,2));
字段类型:
-
数字(整数型)
-
tinyint:1字节。 -
int: 4字节。(直接用) -
bigint: 8字节。
-
-
数字(小数)
float(M,D):4字节。浮点型M:表示最大的长度D:表示小数位最大长度
double(M,D): 8字节。浮点型(直接用)decimal (M, D),dec: 压缩的“严格”定点数M+2 个字节。定点型。- 定点型就是用字符串来存储的
- eg:
float(4, 2):表示最多存储4位,小数位数最多2位。- 如果整数位多了,比如存了
100.23,则会报错 - 如果小数位多了,比如存了
10.233,则会四舍五入,变为10.23
- 如果整数位多了,比如存了
- 如果要存储货币,需要使用
decimal定点数来存,或者是字符串
-
日期
year:年(YYYY)。time: 时分秒(HH:MM:SS)。date: 年月日(YYYY-MM-DD)。(直接用)datetime: 年月日时分秒。(YYYY-MM-DD HH:MM:SS)。- 是用字符串存的,8个字节
timestamp: 年月日时分秒。(YYYY-MM-DD HH:MM:SS)。(直接用)- 是用时间戳存的。存的是从1970-01-01到现在的毫秒数
- 2038年这个时间戳就会用完
- 使用场景:操作/更新的时间
- 写表的时候默认会写两个:
begin_time、update_time
-
字符串
char(M): 定长字符串,设置了长度。- eg:
char(M)代表最长存储M个长度,如果没有存到M个长度,会往后面添加空格。取出来的时候,会去掉空格。
- eg:
varchar(M):变长字符串,会用1-2字节来存储长度。也就是实际长度+1(2)。最大长度65535字节。(直接用)- eg:存储
'ls',则是实际占用空间加上一个字节来存储现在的长度
- eg:存储
text:文本字符串,会用2字节来存储长度。最大长度65535字节,约64K。longtext:大文本字符串。会使用4字节存储长度。最大长度2^32,约4G。
写SQL,就是一个翻译的过程:
- 需要想好你的表名
- 需要想好要存的所有的数据
- 想好类型、字段名
- 写SQL
删除表
删除名为table_name的表:
drop table table_name;
查看表
查看所有表:
show tables;查看表格结构(有哪些列):
desc table_name;
describe table_name;查看表的创建语句:
show create table table_name;
修改表
不建议工作中修改表
修改表名:
rename table old_table_name to new_table_name;
alter table old_table_name rename to new_table_name;修改表字符集 排序规则:
alter table table_name character set utf8mb4 collate utf8mb4_bin;添加列:
alter table table_name add column column_name column_type;删除列:
alter table table_name drop column column_name;修改某列的类型:
alter table table_name modify column column_name column_type;
数据库中数据的操作
添加数据
插入数据
方式1:指定需要插入的列名,values需要与之对应。
insert into table_name (column1, column2, ......) values (value1, value2, ......)方式2:不指定需要插入的列名。values,必须要写所有value,且与建表语句一一对应
insert into table_name values (value1, value2, ......)方式3:使用set方式
insert into table_name set column1=value1, column2=value2,...;可以插入多行:
insert into table_name values
(value1, value2, ......),(valuem,valuen,......),(valuem,valuen,......);
eg:
指定插入列:
-- 要在values后面写与之对应的值
-- 插入的类型一定要匹配
insert into student_test(id, name, age, address, remark)
values (1, "lihua", 20, "china", "None");不指定插入的列:
-- 插入列的顺序与创建表的时候一致
insert into student_test values (2, "zhangsan", 19, "Asia", "None");-- 插入 一条数据
insert into student_test set id=3,name="mike",age=21,address="china",remark="None";-- 还可以一次插入多行,格式就是 在前面指定的
insert into student_test(id, name, age, address, remark) values
(4, "Jack", 20, "china", "None"), (5, "Bob", 25, "china", "None");
查询数据
查询语句:
-- 关键词 select ... from
select * from table_name;-- * 代表选出所有列
-- 也可以写表中的列,多列使用, 分割
-- 比如 select id,name from students;
-- table_name 是表名
使用where关键词。where相当于是过滤器。
eg:
-- 找出name是 zs 的表记录
select * from table_name where name='ls';-- 找出年龄大于 18岁的人
select * from table_name where age > 18;
修改数据
写update语句和delete语句一定要加where条件
更新满足条件的表记录,设置列值:
update table_name set column1=value1, column2=value2 [ where 条件];
eg:
update student_test set age = 18 where id = 4;
删除数据
删除满足条件的数据:
delete from table_name [WHERE 条件];
eg:
delete from student_test where id = 5;
特殊关键字
where(条件关键字)
- 使用
where关键字并指定查询条件|表达式, 从数据表中获得满足条件的数据内容 - 在
where后面写条件,其实就是筛选出符合条件的数据select就是把这些数据筛选出来展示update只更新符合条件的delete只删除符合条件的
- 使用位置:查询语句(select)、更新语句(update)、删除语句(delete)
一些重要的SQL运算符:
- 算数运算符
- 用在
select后面表示我要选择的数据怎么计算出来的 - 用在
where后面表示筛选数据
- 用在
| 运算符 | 作用 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取余 |
- 比较和逻辑运算符
| 运算符 | 作用 | 运算符 | 作用 |
|---|---|---|---|
| = | 等于 | <=> | 等于(可比较null) |
| != | 不等于 | <> | 不等于 |
| < | 小于 | > | 大于 |
| <= | 小于等于 | >= | 大于等于 |
| between and | 在闭区间内 | like | 通配符匹配(%:通配, _占位) |
| is null | 是否为null | is not null | 是否不为null |
| in | 不在列表内 | not in | 不在列表内 |
| and | 与 | && | 与 |
| or | 或 | || | 或 |
注:
=不能用来判断null_只能匹配一次
distinct(过滤关键字)
- 获取某个列的不重复值
- 语法:
select distinct <字段名> from <表名>;- 使用
distinct对数据表中一个或多个字段重复的数据进行过滤,重复的数据只返回其一条数据给用户。
- 使用
eg:
-- 返回所有的address
select address from student_test;-- 返回不重复的 address
select distinct address from student_test;
limit(限制结果集关键字)
select <查询内容|列等> from <表名字> limit 记录数目;select <查询内容|列等> from <表名字> limit 初始位置,记录数目;select <查询内容|列等> from <表名字> limit 记录数目 offset 初始位置;
eg:
-- limit 限制了返回的最大数目
select * from student_test limit 2;-- limit offset number1, number2
-- number1:表示偏移的数量(默认是从0开始的)
-- number2:表示限制的个数
-- 从第2个开始返回,限制返回2个
select * from student_test limit 2 offset 1;
select * from student_test limit 1,2;
as(取别名关键字)
as关键字用来为表和字段指定别名as可以省略
<内容> as <别名>
eg:
select address as dizhi from student_test;
order by(排序关键字)
select <查询内容|列等> from <表名字> order by <字段名> [asc|desc];
注:
order by对查询数据结果集进行排序- 不加排序模式: 升序排序(默认)
asc: 升序排序desc: 降序排序
order by也可以按照多个列排序- 如果第一列相同,就按照第二列进行排序。如果第二列相同,则按照第三列进行排序。以此类推
eg:
select * from student_test order by age desc;select * from student_test order by age asc;
group by(分组关键字)
- 按照某个、某些字段分组
select <查询内容|列等> from <表名字> group by <字段名...>
group by后,select中只能写group by后面的列- 还可以写一些聚合函数
group_concat()函数会把每个分组的字段值都拼接显示出来having可以让我们对分组后的各组数据过滤。(一般和分组+聚合函数配合使用)round(x, d):x 指要处理的数,d 是指保留几位小数min、max、sum、avg、count
- 当
select后 既有表结构本身的字段,又有需要使用聚合函数(count()、sum()、avg()、max()、min()等)的字段,就要用到group by分组
eg:
select group_concat(name),address from student_test group by address;-->
+--------------------+---------+
| group_concat(name) | address |
+--------------------+---------+
| zhangsan | Asia |
| lihua,mike,Jack | china |
+--------------------+---------+select group_concat(name),age,address from student_test group by age having address = "china";-->
+--------------------+------+---------+
| group_concat(name) | age | address |
+--------------------+------+---------+
| lihua | 20 | china |
| mike | 21 | china |
+--------------------+------+---------+group by的特点:
group by代表分组的意思,把值相同的分到一组select后面的列,只能写group by后面的列,或者聚合函数- 如果
group by后面有多个列,会首先按照第一个列进行分组,第一个列相同,再按照第二个列进行分组 - 如果
select后面可以看出来是哪一列聚合,group by后面可以写1 2
eg:select class, count(*) from students group by class;
可以写成select class, count(*) from students group by 1; where与having的区别:where是原始数据进行过滤having是分组之后进行过滤
聚合函数
聚合函数一般用来计算列相关的指定值. 通常和分组一起使用
| 函数 | 作用 | 函数 | 作用 |
|---|---|---|---|
| count | 计数 | sum | 和 |
| avg | 平均值 | max | 最大值 |
| min | 最小值 |
count(*)与count(column_name)的区别:
count(*):纯粹计算有多少行count(column_name):计算非null的行数
SQL语句的执行顺序
- SQL语句的关键字是有顺序的,需要按照下面的顺序来写
select column_name, ... from table_name, ...
[where ...][group by ...][having ...][order by ...][limit ...](5) SELECT column_name, ...:标识出来筛选的列 (1) FROM table_name, ...:打开表 (2) [WHERE ...]:过滤 (3) [GROUP BY ...]:分组 (4) [HAVING ...]:对分组后的数据进行筛选 (6) [ORDER BY ...]:对数据进行排序(7) [Limit ...]:限制
相关文章:
1_SQL
文章目录 前端复习SQL数据库的分类关系型数据库非关系型数据库(NoSQL) 数据库的构成软件架构MySQL内部数据组织方式 SQL语言登录数据库数据库操作查看库创建库删除库修改库 数据库中表的操作选择数据库创建表删除表查看表修改表 数据库中数据的操作添加数…...
PoC免写攻略
在网络安全领域,PoC(Proof of Concept)起着重要的作用,并且在安全研究、漏洞发现和漏洞利用等方面具有重要的地位。攻击方视角下,常常需要围绕 PoC 做的大量的工作。常常需要从手动测试开始编写 PoC,再到实…...

c1-周考2
c1-第二周 9月-技能1.一个岛上有两种神奇动物,其中神奇鸟类2个头3只脚,神奇兽类3个头8只脚。游客在浓雾中看到一群动物,共看到35个头和110只脚,求可能的鸟类和兽类的只数2.构建一个长度为5的数组,并且实现下列要求3.构…...
express+mysql+vue,从零搭建一个商城管理系统7--文件上传,大文件分片上传
提示:学习express,搭建管理系统 文章目录 前言一、安装multer,fs-extra二、新建config/upload.js三、新建routes/upload.js四、修改routes下的index.js五、修改index.js六、新建上传文件test.html七、开启jwt验证token,通过login接…...
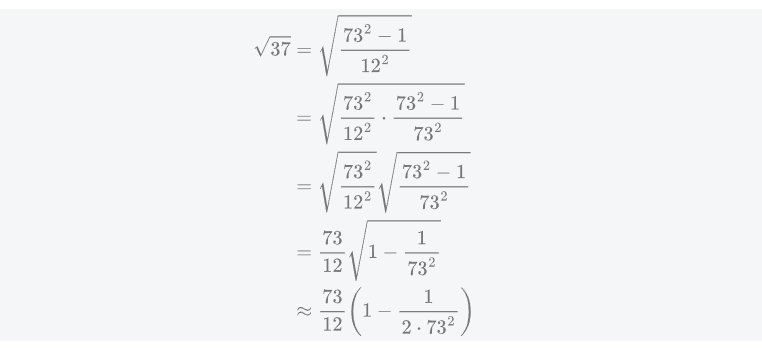
markdown的使用(Typora)
文章目录 markdown的使用(Typora)一.标题二.段落格式2.1 换行2.2 分割线2.3 字体2.4 上下标2.5 脚注2.6 改变字体颜色 三.列表3.1 无序列表3.2 有序列表3.3 列表嵌套3.4 任务列表 四.区块五.代码显示5.1 行内代码5.2 代码块 六.链接七.图片八.表格九.表情符号大纲十、流程图10.…...
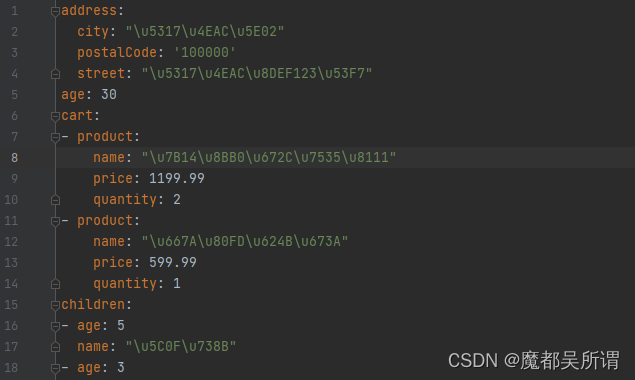
【python】json转成成yaml中文编码异常显示成:\u5317\u4EAC\u8DEF123\u53F7
姊妹篇:【python】json转成成yaml json数据 {"name": "张三","age": 30,"isMarried": false,"children": [{"name": "小王","age": 5},{"name": "小李",&qu…...

Python 实现Excel自动化办公(中)
在上一篇文章的基础上进行一些特殊的处理,这里的特殊处理主要是涉及到了日期格式数据的处理(上一篇文章大家估计也看到了日期数据的处理是不对的)以及常用的聚合数据统计处理,可以有效的实现你的常用统计要求。代码如下࿱…...

MCTS代码
这段代码的背景是玩一个游戏。游戏的参数有NUM_TURNS,在第i回合,你可以从一个整数[-2,2,3,-3]*(NUM_TURNS1-i)中进行选择。例如,在一个4回合的游戏中,在第1回合,你可以从[-8,8,12&am…...

Java 中notify 和 notifyAll 方法介绍
1. notify 方法 notify() 方法是 Java 中 Object 类的一个方法,它用来唤醒在该对象的监视器(monitor)上等待的单个线程。如果有多个线程都在该对象上等待,则会随机唤醒其中一个线程。被唤醒的线程将会尝试重新获取对象锁ÿ…...

Leetcode :杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 思路:双循环,一个是层数,一个是当前数组的生成;两侧为1,需要边界判断条件…...

MWC 2024丨美格智能CEO杜国彬出席中国联通创新成果发布会并发表主题演讲
2月26日,中国联通在MWC2024 巴塞罗那期间举办了以“算网为基,智领未来”为主题的创新成果发布会,集中展示最新的创新成果与最佳实践。 中国通信标准化协会理事长闻库、GSMA首席财务官Louise Easterbrook、中国联通副总经理梁宝俊、华为ICT销…...

个人建站前端篇(七)vite + vue3企业级项目模板
一、vite命令行创建项目 npm create vitelatest根据提示选择模板,选择vite vue3 ts即可。 二、项目连接远程仓库 git init git remote add origin https://gitee.com/niech_project/vite-vue3-template.git git pull origin master git checkout -b dev三、项目…...

centos7 安装 docker-compose
1、直接参考官方: Install Compose standalone | Docker Docs 1、安装命令 curl -SL https://github.com/docker/compose/releases/download/v2.24.6/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose 2、修改 docker-compose 执行权限 不修改执行权…...

剑指offer面试题28:对称的二叉树
#试题28:对称的二叉树 题目: 请设计一个函数判断一棵二叉树是否 轴对称 。 示例 1: 输入:root [6,7,7,8,9,9,8] 输出:true 解释:从图中可看出树是轴对称的。示例 2: 输入:root …...
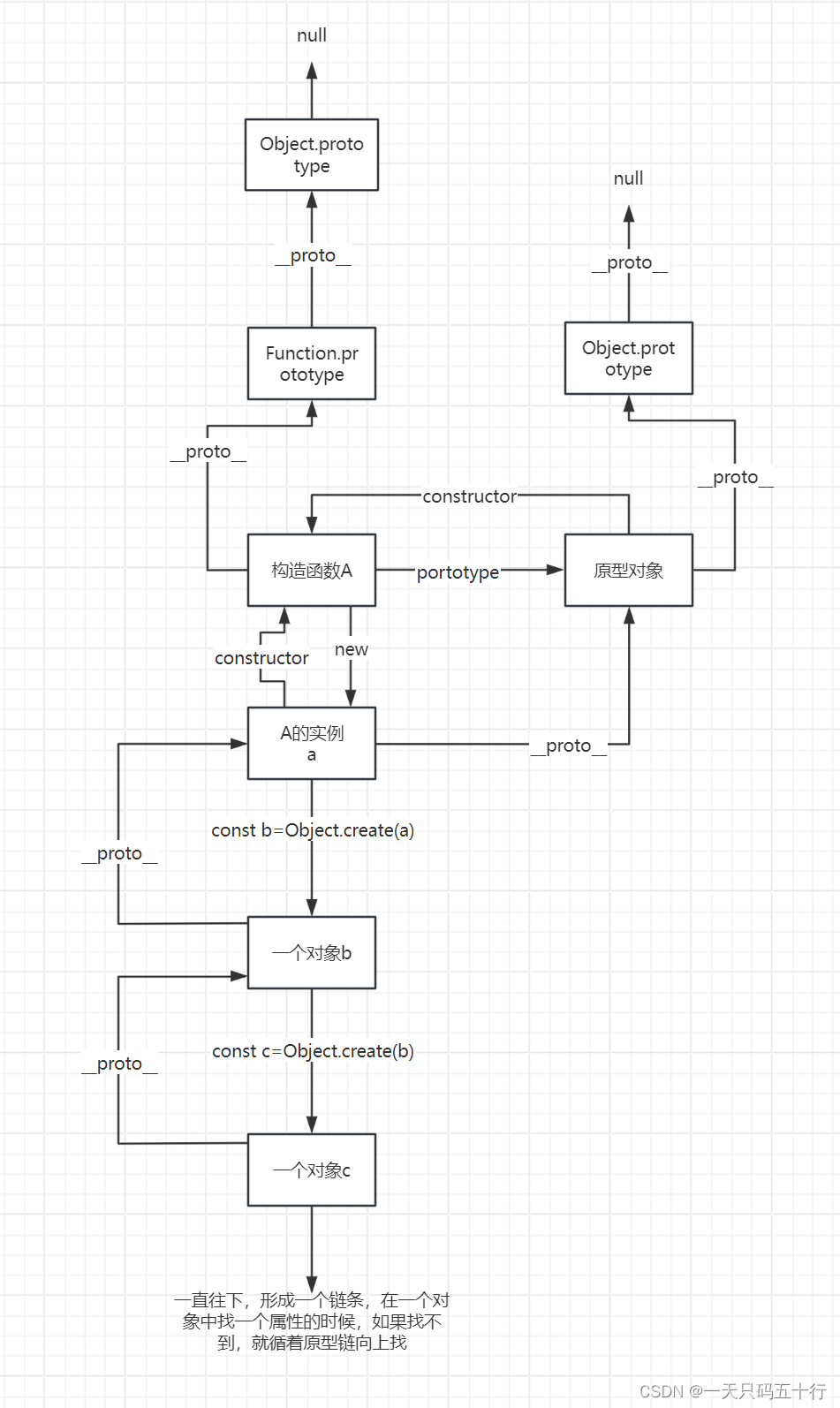
JS:原型与原型链(附带图解与代码)
一、原型 写在前面: 任何对象都有原型。 函数也是对象,所以函数也有原型。 1.什么是原型 在 JavaScript 中,对象有一个特殊的隐藏属性 [[Prototype]],它要么为 null,要么就是对另一个对象的引用,该对象…...

电子电器架构新趋势 —— 最佳着力点:域控制器
电子电器架构新趋势 —— 最佳着力点:域控制器 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师(Wechat:gongkenan2013)。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师…...
C++记录
常用快捷键: CTRL -向后定位 CTRL SHIFT -向前定位 1.注释:CTRLKC 2.取消注释:CTRLKU 11.调试(启动):F5 20.查找:CTRLF 21.替换:CTRLH 31.跳转到指定的某一行 1)方法1:组合键“CtrlG…...

ConcurrentModificationException并发修改异常
ConcurrentModificationException并发修改异常 原因分析 可以通过遍历索引也可以通过迭代器进行遍历。在我们使用迭代器进行遍历集合的时候,会获取到当前集合的迭代对象。在里面有封装了迭代器的remove方法与集合自带的remove方法,如果我们调用迭代器对…...

小程序事件处理
事件处理 一个应用仅仅只有界面展示是不够的,还需要和用户做交互,例如:响应用户的点击、获取用户输入的值等等,在小程序里边,我们就通过编写 JS 脚本文件来处理用户的操作 1. 事件绑定和事件对象 小程序中绑定事件与…...

蓝桥杯-单片机组基础6——定时计数器与外部中断混合使用(附小蜜蜂课程代码)
蓝桥杯单片机组备赛指南请查看这篇文章:戳此跳转蓝桥杯备赛指南文章 本文章针对蓝桥杯-单片机组比赛开发板所写,代码可直接在比赛开发板上使用。 型号:国信天长4T开发板(绿板),芯片:IAP15F2K6…...

Llama-3.2V-11B-cot实战教程:从安装到图文问答,全程无报错操作手册
Llama-3.2V-11B-cot实战教程:从安装到图文问答,全程无报错操作手册 1. 工具简介 Llama-3.2V-11B-cot是一款基于Meta多模态大模型开发的高性能视觉推理工具,专门针对双卡4090环境进行了深度优化。这个工具最大的特点是解决了传统大模型部署中…...

Rust的匹配中的通配符模式与剩余模式在元组解构中的组合使用技巧
Rust作为一门注重安全与性能的系统级编程语言,其模式匹配机制为开发者提供了强大的表达能力。在元组解构中,通配符模式与剩余模式的组合使用尤其值得关注,它们能显著提升代码的简洁性与灵活性。本文将深入探讨这一技巧的实用场景,…...

Unity发布京东小游戏滴
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...

量化入门-用Python筛选爆量上涨的股票酒
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-template/bl…...

软件课题测评报告这样写才专业
一份具备靠谱特性的软件课题测评报告,绝非是简单地去罗列几个功能的通过或者不通过情况,而是成为评判软件“含金量”的那块试金石。今天,我们要结合行业最新动态 ,手把手地教你写出真正具有说服力的测评报告。前几天 ,…...

PX4 EKF滤波效果不好?别只盯着Q和R,这些隐藏参数和传感器预处理同样关键
PX4 EKF滤波效果优化:超越Q/R矩阵的隐藏参数与传感器预处理全解析 当你的无人机在悬停时出现位置漂移,或是穿越机在高速机动时姿态突然发散,大多数开发者第一反应就是调整Q和R矩阵——这就像医生遇到发烧就开退烧药,却忽略了病灶本…...

DeOldify服务监控方案:Prometheus+Grafana实时跟踪GPU利用率与QPS
DeOldify服务监控方案:PrometheusGrafana实时跟踪GPU利用率与QPS 1. 监控方案概述 在实际的AI服务部署中,仅仅能够运行服务是不够的。我们需要实时了解服务的运行状态、资源使用情况以及性能指标。对于DeOldify这样的深度学习图像上色服务,…...
双输入结合HCF-Net的DASI模块,小目标检测性能显著提升!)
YOLOv11多模态融合新突破:RGB+红外线(IR)双输入结合HCF-Net的DASI模块,小目标检测性能显著提升!
1. YOLOv11多模态融合的技术突破 最近在目标检测领域,YOLOv11结合多模态输入(RGB红外)的方案引起了广泛关注。这种创新方法通过融合可见光和红外图像的优势,显著提升了小目标检测的性能。我在实际测试中发现,传统单模态…...

QTableWidget 表格组件攘
7.1 初识三维模型 7.1.1 三维模型的数据载体 随着计算机图形技术的发展,我们或多或少都会见过或者听说过三维模型。笔者始终记得小时候第一次在电视上看到三维动画《变形金刚:超能勇士》的震撼感受;而现在我们已经可以在手机上玩三维游戏《王…...

美团面试:为什么要用分布式缓存?本地缓存呢?多级缓存一致性如何保证?创
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...