ubuntu server 18.04使用tensorflow进行ddqn训练全过程
0. 前言
需要使用ddqn完成某项任务,为了快速训练,使用带有GPU的服务器进行训练。记录下整个过程,以及遇到的坑。
1. 选择模板代码
参考代码来源
GitHub
该代码最后一次更新是Mar 24, 2020。
环境配置:
python3.8
运行安装脚本:
apt-get update
apt-get install xvfb
apt-get install python-opengl
apt-get install python3-pip
python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装python requirements
所需requirements文件
tensorflow
tensorlayer
opencv-python-headless
matplotlib
pyglet==1.5.27
gym==0.20.0
python -m pip install -r requirements -i https://pypi.tuna.tsinghua.edu.cn/simple/
运行模板代码
xvfb-run -s "-screen 0 1400x900x24" python double_DQN\ \&\ dueling_DQN.py
2. ubuntu 环境准备
本部分为踩坑记录,不需要跟着做
服务器之前有其他人用过,也可能是系统自带python,因此会有python环境,首先查看python版本
python --version
显示python命令对应的版本是2.7.17,之后查找该命令对应的符号链接文件位置。
which python
会显示python命令使用的符号链接文件
/usr/bin/python
查看该路径下还有没有其它python版本
ls -al | grep python
输出如下
lrwxrwxrwx 1 root root 9 Apr 16 2018 python -> python2.7
lrwxrwxrwx 1 root root 9 Apr 16 2018 python2 -> python2.7
-rwxr-xr-x 1 root root 3628904 Nov 29 02:51 python2.7
lrwxrwxrwx 1 root root 9 Jun 22 2018 python3 -> python3.6
-rwxr-xr-x 2 root root 4526456 Nov 25 22:10 python3.6
-rwxr-xr-x 2 root root 4526456 Nov 25 22:10 python3.6m
-rwxr-xr-x 1 root root 1018 Oct 29 2017 python3-jsondiff
-rwxr-xr-x 1 root root 3661 Oct 29 2017 python3-jsonpatch
-rwxr-xr-x 1 root root 1342 May 2 2016 python3-jsonpointer
-rwxr-xr-x 1 root root 398 Nov 16 2017 python3-jsonschema
lrwxrwxrwx 1 root root 10 Jun 22 2018 python3m -> python3.6m
发现python命令使用的是2.7,但python3可以使用3.6。因为目前有的tensorflow版本不支持2.7了,先使用3.6.
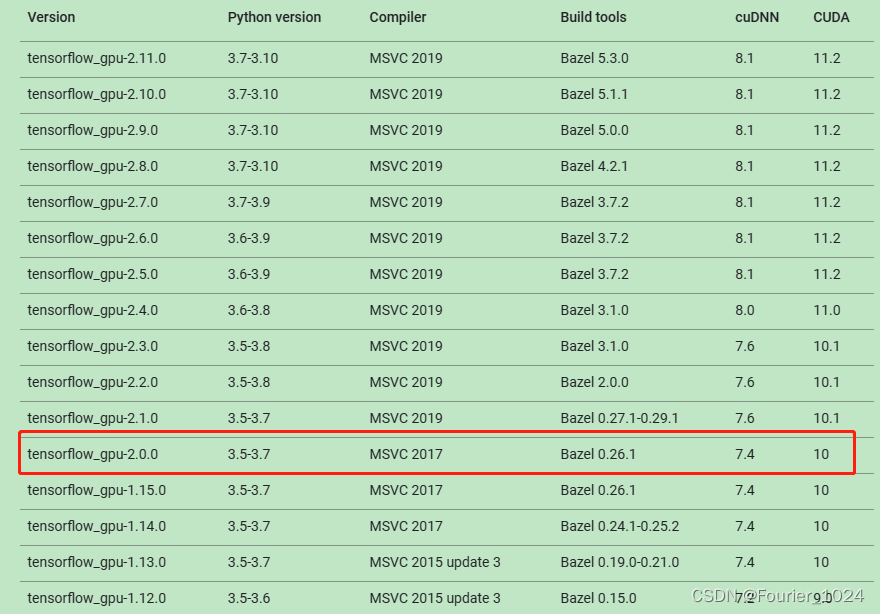
接着查看tensorflow gpu各个版本的要求:官网。如下图所示,我选择了2.0.0,发布于2019年9月30日,和代码更新时间比较近,并且支持python 3.6。
准备使用pip安装tensorflow,但pip并没有安装,使用一下命令安装pip。
apt install python3-pip
之后执行安装命令
python -m pip install tensorflow-gpu==2.0.0
比较难受的是pip源中并没有2.0.0,换了清华源也没有,输出如下
Could not find a version that satisfies the requirement tensorflow-gpu==2.0.0 (from versions: 1.13.1, 1.13.2, 1.14.0, 2.12.0)
No matching distribution found for tensorflow-gpu==2.0.0
可以看到最新的版本只有2.12.0,那只能安装最新的版本。
还需要选择python版本,至少需要python3.7。我为了之后使用方便直接把python命令的软连接接入到新安装的python3.7上。
apt install python3.7
rm -f /usr/bin/python
ln -s /usr/bin/python3.7 /usr/bin/python
python --version
最后显示版本为3.7.5,替换成功,
这时候需要更新一下pip(后面装tensorflow的时候需要安装很多相关包,如果不升级pip的话会有很多包装不上,其中一个报错是 Failed building wheel for grpcio)。
python -m pip install --upgrade pip
继续安装tensorflow-gpu。
python -m pip install tensorflow-gpu
输出如下
The "tensorflow-gpu" package has been removed!Please install "tensorflow" instead.Other than the name, the two packages have been identical
since TensorFlow 2.1, or roughly since Sep 2019. For more
information, see: pypi.org/project/tensorflow-gpu
意思是tensorflow2.1之后gpu包没得了,直接pip install tensorflow就可以。(安装速度感人,切换清华源)
python -m pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装成功!!
3. 模板代码运行
本部分为踩坑记录,不需要跟着做
将代码下载到相应文件夹之后,可以使用如下语句运行ddqn模板代码。
python double_DQN\ \&\ dueling_DQN.py
当然会报很多no module的错误,使用pip依次安装,requirements总结如下
tensorlayer
opencv-python
opencv-python-headless
matplotlib
pyglet
将上述内容写文件,之后一键安装
python -m pip install -r requirments -i https://pypi.tuna.tsinghua.edu.cn/simple/
还需要安装gym,它是一个经常用于测试强化学习的示例,目前新的版本中获取新的状态时参数数量增加了,即以下语句会报错,step函数不仅输出变多了,而且s_的输出也不太正常。因此更换为早一点的版本。
s_,r,done,_ = self.env.step(a)
我根据模板代码的时间查看了gym的tag,发现时间上和模板代码相似,再打开gym的core文件查看step函数,果然从输出数量上合适的。进行安装:
python -m pip install gym==0.20.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
报错如下:
Collecting gym==0.20.0Using cached https://pypi.tuna.tsinghua.edu.cn/packages/f1/16/a421155206e7dc41b3a79d4e9311287b88c20140d567182839775088e9ad/gym-0.20.0.tar.gz (1.6 MB)Preparing metadata (setup.py) ... errorerror: subprocess-exited-with-error× python setup.py egg_info did not run successfully.│ exit code: 1╰─> [1 lines of output]error in gym setup command: 'extras_require' must be a dictionary whose values are strings or lists of strings containing valid project/version requirement specifiers.[end of output]note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed× Encountered error while generating package metadata.
╰─> See above for output.note: This is an issue with the package mentioned above, not pip.
hint: See above for details.原因找了好久,从【参考】中找到了解决办法,更新为指定版本的setuptools:
python -m pip install --upgrade pip setuptools==57.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
运行代码
python double_DQN\ \&\ dueling_DQN.py
发现pyglet最低要求python3.8。。。重新安装python3.8,之后直接使用requirements文件一键安装到新环境。
运行过程中报错
Traceback (most recent call last):File "/usr/local/lib/python3.8/dist-packages/gym/envs/classic_control/rendering.py", line 27, in <module>from pyglet.gl import *File "/usr/local/lib/python3.8/dist-packages/pyglet/gl/__init__.py", line 47, in <module>from pyglet.gl.gl import *File "/usr/local/lib/python3.8/dist-packages/pyglet/gl/gl.py", line 7, in <module>from pyglet.gl.lib import link_GL as _link_functionFile "/usr/local/lib/python3.8/dist-packages/pyglet/gl/lib.py", line 98, in <module>from pyglet.gl.lib_glx import link_GL, link_GLXFile "/usr/local/lib/python3.8/dist-packages/pyglet/gl/lib_glx.py", line 11, in <module>gl_lib = pyglet.lib.load_library('GL')File "/usr/local/lib/python3.8/dist-packages/pyglet/lib.py", line 134, in load_libraryraise ImportError(f'Library "{names[0]}" not found.')
ImportError: Library "GL" not found.During handling of the above exception, another exception occurred:Traceback (most recent call last):File "double_DQN & dueling_DQN.py", line 195, in <module>ddqn.train(200)File "double_DQN & dueling_DQN.py", line 161, in trainif self.is_rend:self.env.render()File "/usr/local/lib/python3.8/dist-packages/gym/core.py", line 254, in renderreturn self.env.render(mode, **kwargs)File "/usr/local/lib/python3.8/dist-packages/gym/envs/classic_control/cartpole.py", line 179, in renderfrom gym.envs.classic_control import renderingFile "/usr/local/lib/python3.8/dist-packages/gym/envs/classic_control/rendering.py", line 29, in <module>raise ImportError(
ImportError: Error occurred while running `from pyglet.gl import *`HINT: make sure you have OpenGL installed. On Ubuntu, you can run 'apt-get install python-opengl'.If you're running on a server, you may need a virtual frame buffer; something like this should work:'xvfb-run -s "-screen 0 1400x900x24" python <your_script.py>'
最后说明了原因,缺少OpenGL 。并且在服务器上运行显示有点问题,就按照他给的解决方案处理。
apt-get install python-opengl
xvfb-run -s "-screen 0 1400x900x24" python double_DQN\ \&\ dueling_DQN.py
处理之后,再次报错
Traceback (most recent call last):File "double_DQN & dueling_DQN.py", line 195, in <module>ddqn.train(200)File "double_DQN & dueling_DQN.py", line 161, in trainif self.is_rend:self.env.render()File "/usr/local/lib/python3.8/dist-packages/gym/core.py", line 254, in renderreturn self.env.render(mode, **kwargs)File "/usr/local/lib/python3.8/dist-packages/gym/envs/classic_control/cartpole.py", line 229, in renderreturn self.viewer.render(return_rgb_array=mode == "rgb_array")File "/usr/local/lib/python3.8/dist-packages/gym/envs/classic_control/rendering.py", line 126, in renderself.transform.enable()File "/usr/local/lib/python3.8/dist-packages/gym/envs/classic_control/rendering.py", line 232, in enableglPushMatrix()
NameError: name 'glPushMatrix' is not defined原因是pyglet版本太高,降为1.5.27即可。
4. 安装GPU支持
根据tensorflow版本选择cuda和cudnn。
4.1 安装cuda 11.2
wget https://developer.download.nvidia.com/compute/cuda/11.2.2/local_installers/cuda_11.2.2_460.32.03_linux.run
chmod +x cuda_11.2.2_460.32.03_linux.run
sudo ./cuda_11.2.2_460.32.03_linux.run
安装完成后,需要将CUDA的路径添加到环境变量中。打开~/.bashrc文件,在文件末尾添加以下两行代码:
export PATH=/usr/local/cuda-11.2/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后运行以下命令使环境变量生效:
source ~/.bashrc
验证CUDA的安装是否成功。运行以下命令:
nvcc -V
4.2 安装cudnn 8.1
在NVIDIA官网下载。
之后上传到服务器,
tar -xzvf cudnn-11.2-linux-x64-v8.1.1.33.tgz
cp -P cuda/include/cudnn*.h /usr/local/cuda-11.2/include
cp -P cuda/lib64/libcudnn* /usr/local/cuda-11.2/lib64/
chmod a+r /usr/local/cuda-11.2/include/cudnn*.h /usr/local/cuda-11.2/lib64/libcudnn*
使用如下代码测试gpu是否正常使用
import tensorflow as tf# 显示当前GPU设备信息
print(tf.config.list_physical_devices('GPU'))# 创建一个TensorFlow的Session并在其中进行一个简单的运算
with tf.compat.v1.Session() as sess:# 创建一个TensorFlow的常量张量a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')# 创建一个TensorFlow的变量张量b = tf.Variable(tf.random.normal([3, 2], stddev=0.1), name='b')# 进行矩阵乘法运算c = tf.matmul(a, b, name='c')# 初始化所有变量sess.run(tf.compat.v1.global_variables_initializer())# 运行TensorFlow图print(sess.run(c))输出如下,可以正常使用
2023-03-05 14:43:55.699137: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F AVX512_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-05 14:43:55.861866: I tensorflow/core/util/port.cc:104] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-03-05 14:43:56.628130: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/cuda-11.2/lib64
2023-03-05 14:43:56.628241: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/cuda-11.2/lib64
2023-03-05 14:43:56.628256: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
2023-03-05 14:43:58.016301: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:58.031069: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:58.032359: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2023-03-05 14:43:58.035332: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F AVX512_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-05 14:43:58.036833: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:58.038127: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:58.039367: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:59.106971: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:59.108369: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:59.109663: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-03-05 14:43:59.110894: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1613] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 30969 MB memory: -> device: 0, name: Tesla V100S-PCIE-32GB, pci bus id: 0000:00:06.0, compute capability: 7.0
2023-03-05 14:43:59.127126: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:357] MLIR V1 optimization pass is not enabled
[[0.50951785 0.10452858][1.070737 0.27480656]]模板代码使用GPU加速感觉速度没快多少,可能是神经网络层数比较少的原因。
相关文章:
ubuntu server 18.04使用tensorflow进行ddqn训练全过程
0. 前言 需要使用ddqn完成某项任务,为了快速训练,使用带有GPU的服务器进行训练。记录下整个过程,以及遇到的坑。 1. 选择模板代码 参考代码来源 GitHub 该代码最后一次更新是Mar 24, 2020。 环境配置: python3.8 运行安装脚本…...

2023年全国最新二级建造师精选真题及答案14
百分百题库提供二级建造师考试试题、二建考试预测题、二级建造师考试真题、二建证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 二、多选题 61.已经取得下列资质的设计单位,可以直接申请相应类别施工总承包一级…...
mysql一条语句的写入原理
mysql写入原理 我们知道在mysql数据库最核心的大脑就是执行引擎; 其中的默认引擎Innodb在可靠执行和性能中做出来平衡; innodb支持在事务控制、读写效率,多用户并发,索引搜索方面都表现不俗; innodb如何进行数据写入…...
)
嵌入式Linux内核代码风格(二)
第九章:你已经把事情弄糟了 这没什么,我们都是这样。可能你的使用了很长时间Unix的朋友已经告诉你“GNU emacs”能 自动帮你格式化C源代码,而且你也注意到了,确实是这样,不过它所使用的默认值和我们 想要的相去甚远&a…...
Spring Boot @Aspect 切面编程实现访问请求日志记录
aop切面编程想必大家都不陌生了,aspect可以很方便开发人员对请求指定拦截层,一般是根据条件切入到controller控制层,做一些鉴权、分析注解、获取类名方法名参数、记录操作日志等。 在SpringBoot中使用aop首先是要导入依赖如下: …...

初学者的第一个Linux驱动
软件环境:Ubuntu20.04 Linux内核源码:3.4.39 硬件环境:GEC6818 什么是驱动?简单来说就是让硬件工作起来的程序代码。 Linux驱动模块加载有两种方式: 1、把写好的驱动代码直接编译进内核。 2、把写好的驱动代码编…...

7. 拼数
1 题目描述 拼数成绩10开启时间2021年09月24日 星期五 18:00折扣0.8折扣时间2021年11月15日 星期一 00:00允许迟交否关闭时间2021年11月23日 星期二 00:00 设有 n个正整数 a[1]…a[n],将它们联接成一排,相邻数字首尾相接,组成一个最大的整…...

Java每天15道面试题 | Redis
redis 和 和 memcached 什么区别?为什么高并发下有时单线程的 redis 比多线程的memcached 效率要高? 区别: 1.mc 可缓存图片和视频。rd 支持除 k/v 更多的数据结构; 2.rd 可以使用虚拟内存,rd 可持久化和 aof 灾难恢复࿰…...

13_pinctrl子系统
总结 pinctrl作为驱动 iomuxc节点在设备树里面 存储全部所需的引脚配置信息 iomux节点匹配pinctrl子系统 控制硬件外设的时候 要知道有哪些gpio 再看gpio有哪些服用寄存器 接着在程序配置gpio相关寄存器 这样搞效率很低 所以用iomux节点保存所有的引脚组 pinctrl驱动起来的时…...

Linux系统对于实施人员的价值
Linux系统对于实施人员的价值 随着互联网的发展,linux系统越来越突显了巨大的作用,很多互联网公司,政府企业,只要用到服务器的地方几乎都能看到linux系统的身影,可以说服务是不是在linux系统跑的代表了企业的技术水平&…...

ForkJoin 和 Stream并行流
还在用 for 循环计算两个数之间所有数的和吗?下面提供两种新方法! 1. ForkJoin 1.1 背景 要知道,在一个方法中,如果没有做特殊的处理,那么在方法开始到结束使用的都是同一个线程,无论你的业务有多复杂 那…...

逻辑优化-cofactor
1. 简介 逻辑综合中的Cofactor优化方法是一种重要的逻辑优化技术。它通过提取逻辑电路中的共同部分,从而简化电路、减小面积和延迟。该方法广泛应用于电子设计自动化(EDA)领域中的逻辑综合、等价转换和优化等方面。 Cofactor优化方法最早由…...

车道线检测CondLaneNet论文和源码解读
CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution Paper:https://arxiv.org/pdf/2105.05003.pdf code:GitHub - aliyun/conditional-lane-detection 论文解读: 一、摘要 这项工作作为车道线检测任…...

vue3的插槽slots
文章目录普通插槽Test.vueFancyButton.vue具名插槽Test.vueBaseLayout.vue作用域插槽默认插槽Test.vueBaseLayout.vue具名作用域插槽Test.vueBaseLayout.vue普通插槽 父组件使用子组件时,在子组件闭合标签中提供内容模板,插入到子组件定义的出口的地方 …...

docker学校服务器管理
docker 学校服务器管理使用docker,docker使用go语言编写。对于docker的理解,需要知道几个关键字docker, scp,images, container。 docker-码头工人scp-传输命令images/repository-镜像container-容器 docker是码头工人,scp相当…...
pv和pvc
一、PV和PVC详解当前,存储的方式和种类有很多,并且各种存储的参数也需要非常专业的技术人员才能够了解。在Kubernetes集群中,放了方便我们的使用和管理,Kubernetes提出了PV和PVC的概念,这样Kubernetes集群的管理人员就…...

k8s篇之Pod 干预与 PDB
文章目录自愿干预和非自愿干预PDBPDB 示例分离集群所有者和应用程序所有者角色如何在集群上执行中断操作自愿干预和非自愿干预 Pod 不会消失,除非有人(用户或控制器)将其销毁,或者出现了不可避免的硬件或软件系统错误。 我们把这…...
Django学习17 -- ManytoManyField
1. ManyToManyField (参考:Django Documentation Release 4.1.4) 类定义 class ManyToManyField(to, **options)使用说明 A many-to-many relationship. Requires a positional argument: the class to which the model is related, which w…...

既然有MySQL了,为什么还要有Redis?
目录专栏导读一、同样是缓存,用map不行吗?二、Redis为什么是单线程的?三、Redis真的是单线程的吗?四、Redis优缺点1、优点2、缺点五、Redis常见业务场景六、Redis常见数据类型1、String2、List3、Hash4、Set5、Zset6、BitMap7、Bi…...
RSTP基础要点(上)
RSTP基础RSTP引入背景STP所存在的问题RSTP对于STP的改进端口角色重新划分端口状态重新划分快速收敛机制:PA机制端口快速切换边缘端口的引入RSTP引入背景 STP协议虽然能够解决环路问题,但是由于网络拓扑收敛较慢,影响了用户通信质量ÿ…...

如何快速掌握LeaguePrank:英雄联盟客户端个性化修改完整指南
如何快速掌握LeaguePrank:英雄联盟客户端个性化修改完整指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟客户端中展示独特的个人风格吗?LeaguePrank是一个基于LCU API的英雄联盟客户…...

Nanbeige4.1-3B代码实例:用pipeline接口封装推理服务,支持HTTP API调用
Nanbeige4.1-3B代码实例:用pipeline接口封装推理服务,支持HTTP API调用 1. 引言 如果你正在寻找一个既小巧又强大的开源语言模型,Nanbeige4.1-3B绝对值得你花时间了解一下。这个只有30亿参数的模型,在推理、代码生成和对话任务上…...

KeyboardChatterBlocker:如何解决机械键盘的“幽灵按键“问题?
KeyboardChatterBlocker:如何解决机械键盘的"幽灵按键"问题? 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocke…...

Claude Code 常用技巧:这几个操作让我开发效率翻倍
Claude Code 常用技巧:这几个操作让我开发效率翻倍 说实话,用 Claude Code 差不多也有小半年了,从一开始"就这?"的怀疑,到现在每天开工第一件事就是把它招呼进来,中间踩了不少坑,也真…...

Java的迪米特原则介绍
01.问题思考的分析什么是迪米特原则,这个原则如何理解,如何运用到实际开发,举例说明一下?什么是高内聚松耦合,能否举例说明一下?迪米特法则。尽管它不像 SOLID、KISS、DRY 原则那样,人尽皆知&am…...

为什么高端芯片都爱用Flip Chip?对比Wire Bonding的5大优势详解
为什么高端芯片都爱用Flip Chip?对比Wire Bonding的5大优势详解 在芯片封装领域,Flip Chip(倒装芯片)技术正逐渐成为高端应用的标配。想象一下,当你手持最新款智能手机,流畅运行着复杂的AI应用时࿰…...

智慧树网课效率工具:自动化播放与倍速控制插件全解析
智慧树网课效率工具:自动化播放与倍速控制插件全解析 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 在当今在线学习环境中,智慧树作为主流教育…...

Cisco Catalyst 8000 IOS XE 17.18.2 ED - 思科 Catalyst 8000 边缘平台系列 IOS XE 系统软件
Cisco Catalyst 8000 Series Edge Platforms, IOS XE Release 17.18.2 ED 思科 Catalyst 8000 边缘平台系列 IOS XE 系统软件 请访问原文链接:https://sysin.org/blog/cisco-catalyst-8000/ 查看最新版。原创作品,转载请保留出处。 作者主页ÿ…...

SAMD21 Turbo PWM:硬件级高精度同步PWM驱动详解
1. SAMD21 Turbo PWM 库深度解析:面向嵌入式工程师的高性能PWM驱动实践指南SAMD21 Turbo PWM 是一款专为基于 ATSAMD21G 微控制器(如 Arduino Nano 33 IoT、Adafruit Itsy Bitsy M0、Trinket M0 等)设计的底层硬件加速 PWM 库。它绕过 Arduin…...

25岁后为什么老得快?你的细胞在偷偷减少
有没有发现一个扎心的事实:25岁像是一道隐形的分水岭,把青春和初老狠狠隔开。20岁的时候,通宵打游戏、追剧、赶ddl,第二天睡半天就能满血复活,脸上看不到一丝疲惫,皮肤透着原生态的光泽,哪怕偶尔…...