扩展学习|大数据分析的现状和分类
文献来源:[1] Mohamed A , Najafabadi M K , Wah Y B ,et al.The state of the art and taxonomy of big data analytics: view from new big data framework[J].Artificial Intelligence Review: An International Science and Engineering Journal, 2020(2):53.
下载链接:https://pan.baidu.com/s/1WOU6JctBhv93MslHMA-WyQ 提取码:1ck4
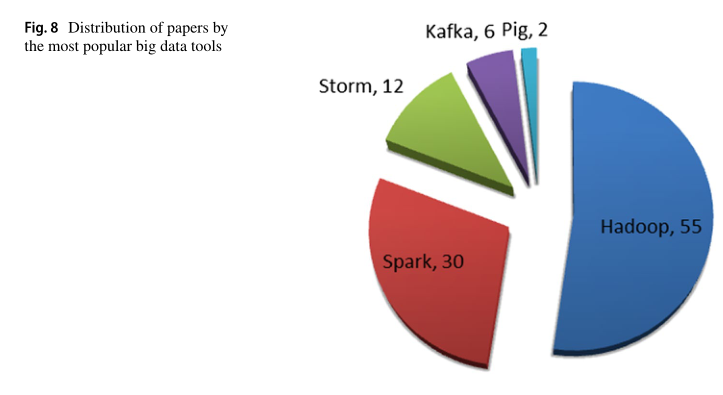
本文不仅提供了主要大数据技术的全球视图,还提供了三类流行的大数据工具,即批处理、流处理和混合处理工具。在批处理中,随着时间的推移收集一组数据或一批信息,然后将其输入分析系统进行处理。在大数据流计算下,处理是实时完成的,数据被逐块输入分析工具。批处理是先存储后计算的模型,其里程碑是Google在2003年开发的MapReduce框架;流处理是直通计算的模型,其里程碑是在2010年开发的Yahoo。 但大数据批量计算无法支持大数据流计算。流处理的特点是:(1)大容量是指连续数据的到达量超出了单个机器的能力;(2)在多阶段计算过程中,输入数据流产生输出流时,延时较低。第三代大数据工具被称为混合处理,由于其批处理和流处理的能力,它可能是有利的。
一、从五个“V”理解大数据的定义

大数据的五大方面:(1)多样性是指数据类型和来源的不同形式,如活动事件的文本信息;关于道路上的车辆交通和计划中的活动(例如,音乐活动、体育赛事)的交通数据集。(2) Velocity表示数据输入和输出的速度。它指的是数据的动态性、数据生成的频率以及实时生成结果的必要性。(3)大数据量关注的是达到兆字节或千兆字节、太字节甚至拍字节级别的数据集的大小。(4)真实性(Veracity)是指在数据来源可靠的情况下,数据可以被信任的程度。例如,当从传感器接收数据时,某些设备可能会受到损害。(5)价值对应于组织从处理大数据中可以获得的潜在见解,指的是潜在价值大或价值密度极低。
二、基于大数据生活的各个方面的分类方法

三、大数据计算的工具即批处理工具、流处理工具和混合处理工具。
大多数批处理数据分析平台都是基于Apache Hadoop的,如Dryad和Mahout。流数据分析平台的例子是Storm和S4用于实时应用程序。混合处理工具利用批处理和流处理的优势来计算大量数据。
(一)批处理
批处理模型,并将数据湖的文件转换为准备用于分析用例的批处理视图。它负责调度和执行批处理迭代算法,如排序、搜索、索引或更复杂的算法,如PageRank、贝叶斯分类或遗传算法。批处理主要由MapReduce编程模型表示。它的缺点体现在两个方面。一方面,在处理大量批处理数据时,通常需要将多个作业链接起来,以便将更复杂的处理作为单个作业执行。另一方面,Map到Reduce阶段的中间结果物理地存储在硬盘中,完全降低了Velocity(就响应时间而言)。
·Hadoop/MapReduce
Apache Hadoop是批处理框架的一个众所周知的例子,它支持在商用硬件集群上分布式存储和处理大型数据集。它是一个基于java的开源框架,被Facebook、Yahoo!Twitter存储和处理大数据工作负载。实际上,Hadoop由两个组件组成:(1)Hadoop分布式文件系统(HDFS),其中数据存储在集群的节点之间是分布式的;(2) Hadoop MapReduce引擎,它将数据处理分配到它所在的节点。
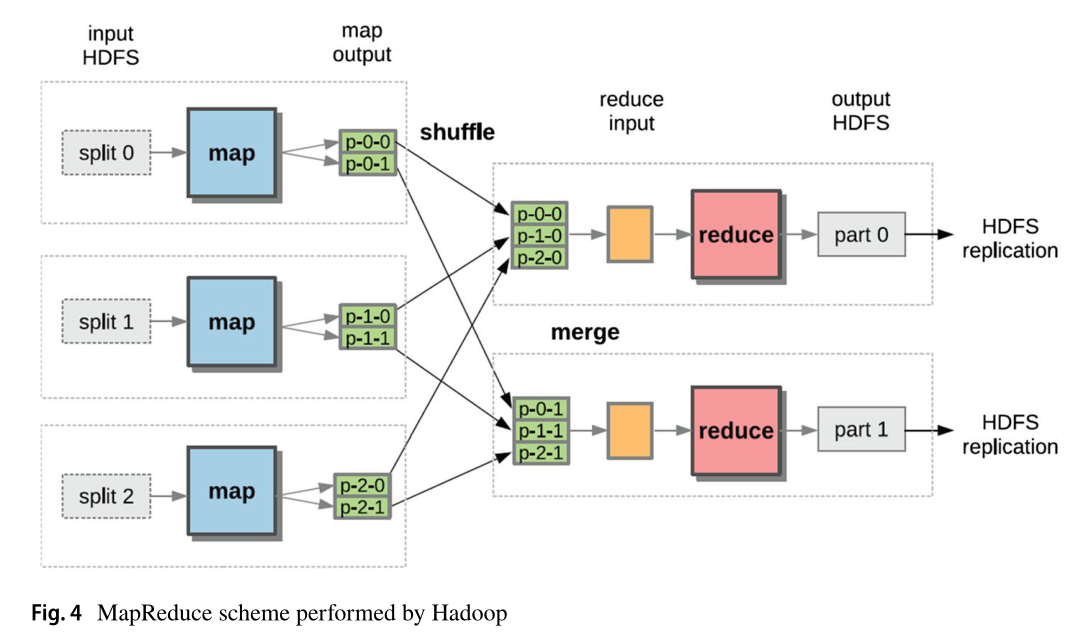
Hadoop是MapReduce编程模型的开源实现,用于处理大型数据集,这些数据集可以结构化为数据库,也可以非结构化为文件系统,通过在由一个主节点和多个工作节点组成的节点集群上使用并行和分布式算法。主节点接受输入,将输入分成更小的子问题,并将这些子问题分发给工作节点。工作节点可以依次执行此过程,从而形成多级树结构。在处理完较小的子问题后,工作节点将答案传递回主节点。然后,主节点收集所有子问题的答案,并将这些答案以某种方式组合起来,以形成问题的答案输出主节点最初试图解决(Elkano等人2017;Kranjc et al . 2017)。Hadoop也是Apache Mahout2的基础框架,它有机器学习算法来支持降维、推荐挖掘、频繁项集挖掘、分类和聚类。Mahout的第一个版本实现了构建在Hadoop框架上的算法,但最近的Mahout版本包括了在Spark上运行的新实现,例如Spark-item相似性的实现使新一代的共现推荐能够使用用户点击流和上下文来进行推荐。然而,Hadoop为大数据应用提供了认证、负载均衡、高可用性、灵活访问、可扩展性、可调复制、容错和安全性,包括金融分析、机器学习、自然语言处理、遗传算法、模拟和信号处理等。由于Hadoop中某些组件缺乏可扩展性等问题,导致出现了带有Yet Another Resource Negotiator (YARN)的Hadoop第二版。YARN是一个资源管理框架,它在MapReduce中拆分了作业跟踪器和任务跟踪器的职责,从而可以在共享公共集群资源管理的同时并行运行多个应用程序。新引擎中的Hadoop集群可以扩展到更大的配置,并同时支持迭代处理、流处理、图形处理和一般集群计算。Hadoop执行的MapReduce总体方案概述如图4所示。在第一步中,输入数据被分割成片段,片段由map函数以(key, value)格式读取。map的输出被划分为不同的片段(图4中的p-x-x)。Shuffle步骤重新分配map函数产生的片段,使所有属于同一行为(key)的数据都位于同一节点上。然后,将reduce步骤用作组合器并在map输出上运行。相应的reducer对它们的输入进行处理,合并生成最终结果,并将结果发送到HDFS。
(二)流处理
并行处理大量数据对Hadoop来说不是问题。它是一种通用的划分机制,用于在不同的机器上分配累积的工作负载。此外,Hadoop是为批处理而设计的。Hadoop是一个多用途引擎,但由于其延迟,它不是一个实时和高性能的引擎。在一些流数据应用中,如日志文件处理、机器对机器、传感工业和远程信息处理需要实时响应来处理大量流数据。因此,有必要对流处理进行实时分析。流数据需要实时分析,因为大数据具有高速、大容量和复杂的数据类型。在涉及实时处理的应用中,Map/Reduce框架在时间维度和高速度方面存在挑战。
流处理平台如Storm、S4、Splunk和Apache Kafka已经被开发为第二代数据流处理平台,用于实时分析数据(Wang and Belhassena 2017;Ferranti et al . 2017)。实时处理是指连续的数据处理高度需要极低的响应延迟。这是由于在处理的时间维度上累积的数据量很小。
一般来说,大数据可能是在分散的环境中收集和存储的,而不是在一个数据中心。通常,在Map/Reduce框架中,Reduce阶段只在Map阶段之后才开始工作。因此,Map阶段生成的所有中间数据都保存在磁盘中,然后提交给reducer进行下一阶段的处理。这些都对处理造成了很大的阻碍。Hadoop的高延迟特性使得它几乎不可能进行实时分析。
Storm3是实时分析中最受认可的数据流处理程序之一,它专注于可靠的消息处理。Storm是一个免费的开源分布式流处理环境,用于开发和运行处理持续数据流的分布式程序。因此,可以说Storm是一个开源的、通用的、分布式的、可扩展的、部分容错的平台,可以可靠地处理无界的数据流进行实时处理。开发Storm的一个优点是,它允许开发人员专注于使用稳定的分布式进程,同时将分布式/并行处理的复杂性和技术挑战(如构建复杂的恢复机制)委托给框架。
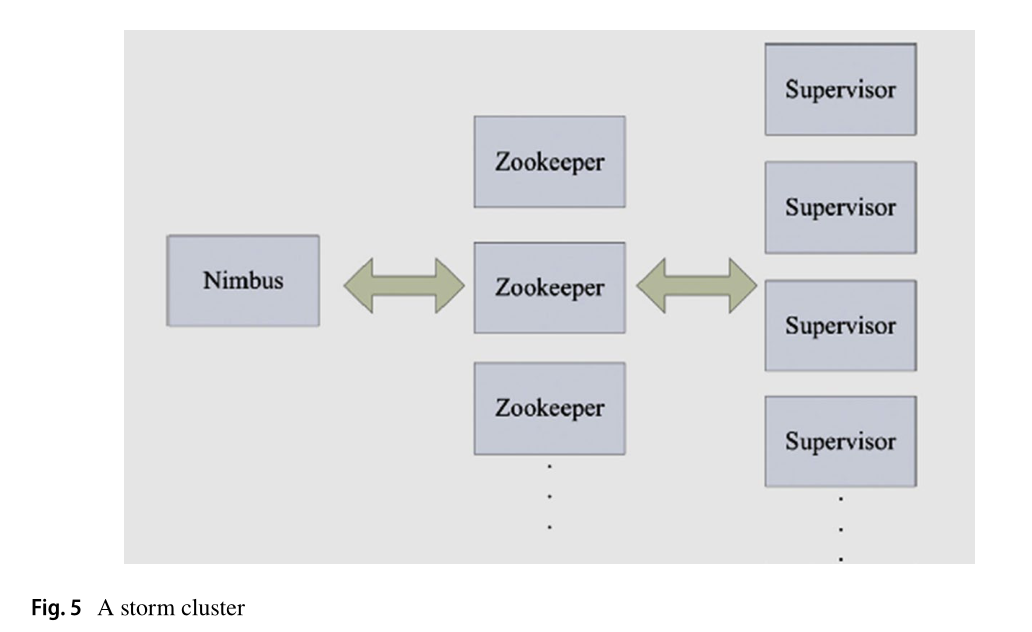
首先,Nimbus在Storm中分发代码来执行并行处理,将任务委托给Supervisor,并处理错误。其次,Supervisor执行初始化工作流程的角色,以处理为处理多方面事件而创建的拓扑。
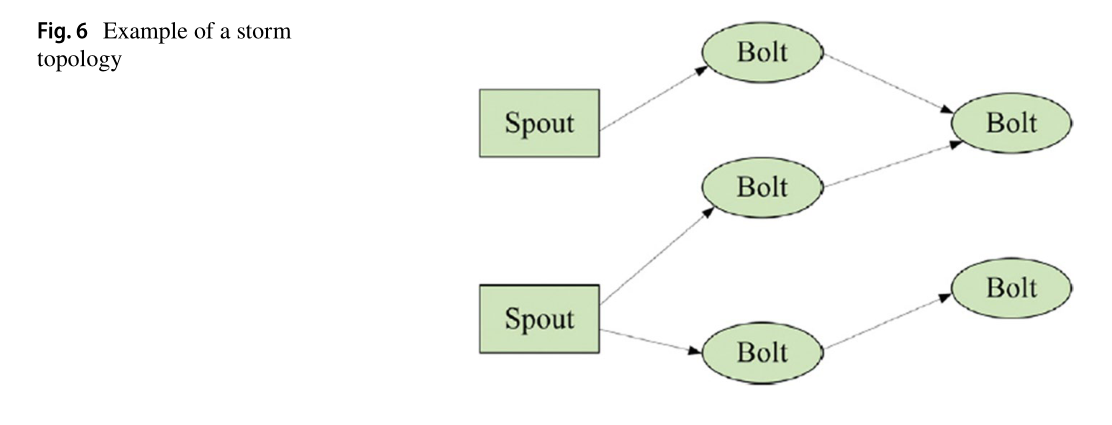
拓扑节点分为Spout和Bolt两类,如图6所示,Spout充当事件接收器,从多个来源收集流数据或事件,并将数据传递给多个Bolt。然后,螺栓执行单元逻辑事件处理器的角色,例如过滤、收集和连接事件处理网络上的事件流。最后,Zookeeper作为分布式应用程序的协调服务,负责同步节点,作为分布式协调器协调系统,并将Nimbus和supervisor的所有情况记录在本地磁盘上。它支持一个针对错误的复苏装置,以确保框架是容错的。Storm的主要抽象结构是拓扑结构。它是描述每个消息经过的处理节点的顶层抽象。拓扑表示为一个图,其中节点是处理组件,而边表示在它们之间发送的消息。拓扑节点分为喷孔节点和螺栓节点。喷出节点是拓扑的入口点,也是要处理的初始消息的来源。
Bolt节点是实际的处理单元,它接收传入的文本,对其进行处理,并将其传递到拓扑中的下一个阶段。拓扑中一个节点的几个实例可以允许实际的并行处理。
(三)混合处理
混合处理使得第三代大数据平台成为可能,因为这是大数据应用的许多领域所必需的。该范例综合了基于Lambda架构的批处理和流处理范例。Lambda架构是一种数据处理架构,旨在通过利用批处理和流处理方法来处理大量数据。这种范式的高级体系结构包含三个层。批处理层管理存储在分布式系统中不可更改的主数据集。服务层加载并公开数据存储中批处理层的视图以供查询,而速度层只处理低延迟的新数据。最后,将批处理视图与实时视图相结合,合并完整的结果。
四、大数据分析技术的分类框架
大数据分析中使用的技术广泛分为以下六类:机器学习/数据挖掘技术、云计算、语义网络分析/web挖掘、可视化技术、数学和统计技术以及优化技术。
(一)机器学习/数据挖掘技术(深度学习/人工神经网络)
数据挖掘和机器学习技术是一组人工智能技术,一旦设计的算法从经验数据中学习行为,就可以从数据中提取隐藏的知识和有价值的信息(模式)。算法包括支持向量机、聚类分析、分类、关联规则学习和回归。
传统的数据挖掘技术在分析数据时效率高,但在处理大数据时效率和可扩展性不高,因此需要基于大数据架构的新技术来管理和分析大数据。数据速率快速增长,因此k-means、模糊c-means、分层聚类、分层聚类、CLARANS、平衡迭代约简和聚类等大型应用应扩展到数据聚类的未来使用,使其能够应对巨大的工作负载;否则,这些算法将不再适用于未来(Najafabadi et al . 2017a, b;Wang and Belhassena 2017;Wang等人2017a, b).并行编程模型,如Hadoop和Map/Reduce可以扩展数据挖掘和机器学习技术,用于挖掘和并行处理大数据集。例如,人工神经网络(artificial neural network, ANN)作为图像分析、自适应控制、模式识别等的基础算法,在大数据的学习过程中存在时间和内存消耗的问题。神经网络需要更多的隐藏层和节点来获得更高的性能。
然而,由于人工神经网络学习过程的复杂性,它的性能会比大数据差,并且会造成额外的时间消耗。因此,人工神经网络在并行和分布式设置下得到了改进,以减少内存和时间消耗(Fonseca and Cabral 2017;Rahman et al. 2016)。深度学习技术是利用人工神经网络从复杂数据集中提取信息和从数据中发现相关性的常用技术之一。它通过学习多个层次的表示和抽象来理解不同类型的数据,如图像、文本和声音。深度学习在模式识别、文本挖掘、图像分析、自适应控制、基因组医学等大数据应用中发挥了重要作用。大多数大数据分析技术都是基于深度学习方法,利用分类优化、统计估计和控制理论来解决大数据分析问题。
神经网络在学习大规模数据集的过程中,由于需要更多的隐藏层和节点来产生更高的准确率,因此需要更大的内存。人们普遍认为,大数据的神经处理导致了非常大的网络。事实上,这个过程中的主要挑战之一是记忆限制和训练时间,这越来越棘手。此外,传统的训练算法也表现不佳。因此,可以采用一些采样方法来减少数据的大小,并以并行和分布式的方式扩展神经网络。深度学习在新类型的推荐中也显示出其效率,例如将项目映射到联合潜在空间的跨领域推荐系统,以及社会信任集成学习模型(Iqbal et al. 2017;Najafabadi等2017a, b;Najafabadi and Mahrin 2016)。
因此,为了挖掘大规模数据,有必要重新设计MapReduce框架上的机器学习和数据挖掘算法。Mahout和Spark MLlib是两个开源项目,它们解决可伸缩性问题,并支持许多算法,包括回归、分类、协同过滤、聚类和降维。因为它们提供了一个分布式环境,在这个环境中算法可以处理大型数据集。
(二)云计算技术
云计算正在成为高效数据处理的关键资源,它已成为最近计算信息时代的主要转变,它承诺为大规模和复杂的企业应用程序提供合理和动态的计算架构。它是一种重要的革命性模型,提供面向服务的计算,并从客户机或用户抽象出配备软件的硬件基础设施。云计算在大数据应用中的主要目标是挖掘大量的数据,并为未来的行动提取有用的信息或知识。云计算是一种用于大数据分析的并行分布式计算系统。云计算服务确认用户对信息共享的请求,然后根据数据做出最佳决策,并将信息无冗余地传递给其他用户。云计算的概念主要流行于三个方面:(1)软件即服务(SaaS),(2)平台即服务(PaaS)和(3)基础设施即服务(IaaS)。简而言之,SaaS为用户提供对应用程序的不间断访问。PaaS帮助用户开发、运行和管理应用程序。IaaS为用户提供访问可配置计算资源池的权限,如网络、存储和服务器。云提供商拥有并运营云服务。为单个组织运行的云服务称为私有云,为公共使用运行的云服务称为公共云。随着大数据和云计算时代的到来,世界各地广泛部署了大量的数据中心,全球数据中心的电力需求迅速增长。2013年,数据中心能耗占全球总能耗的0.5%。据估计,到2020年,数据中心的能耗将会增加(将占到1%)。这种巨大的能源消耗不仅增加了其运行成本,而且对环境产生了负面影响。最理想的方法之一是利用可再生能源来减少温室气体排放并摊销数据中心的能源成本。
(三)语义网络分析/Web挖掘
语义网络分析涉及Web挖掘、自然语言处理(NLP)和文本分析等领域。语义网络分析是一种用于从大型网络存储库中确定模式的技术。语义网络分析揭示了网站上未识别的知识,用户可以使用它来进行数据分析。该技术有助于评估特定网站的有效性。为了解决NLP中复杂的任务,特别是与语义分析相关的任务,我们需要语言的形式表示,即语义语言。NLP是一种计算机程序理解人类语言的能力。NLP是一门科学学科让机器可以使用自然语言。NLP承担了从文档中提取关系、识别文档中的句子边界、搜索和检索文档等任务。NLP是通过在非结构化文本中建立结构以进行进一步分析来促进文本分析的方法。文本分析是指从文本源中挖掘有用的信息。它是一个总括性术语,描述了从使用元信息(如文本中提到的人物和地点)注释文本源到关于文档的各种模型(例如,文本聚类、情感分析和分类)的任务。在自然语言处理研究中,处理海量文本数据已成为一个重要课题。由于大多数数字信息以新闻文章或网页等非结构化数据的形式存在,跨文档共同引用解析、事件检测或计算文本相似度等NLP任务经常需要在规定的时间框架内处理数百万个文档。
语义网络分析有助于从网络内容中挖掘有用信息。网站内容包括音频、视频、文本和图像。万维网上许多不断扩展的信息源(如超文本文档)的异构性和缺乏结构使得Internet和万维网的自动发现、组织、搜索和索引工具(例如,Alta Vista、Lycos、WebCrawler和Meta Crawler)对用户来说很舒服。然而,这些工具既没有提供结构化信息,也没有对文档进行分类、过滤或解释。
因此,这促使研究人员开发更智能的信息检索工具(例如,智能网络代理),并扩展数据库和数据挖掘技术,以提供组织网络上可用的半结构化数据的方法。基于代理的语义网络分析方法涉及开发复杂的人工智能系统,该系统可以代表特定用户自主或半自主地识别和组织web/网络信息。
一些web挖掘技术通过图论来检测网站的节点和连接结构。例如,从网站内的超链接中提取模式和分析树状结构来描述XML或HTML标记。
(四)可视化技术
可视化技术被用来理解数据,并通过创建表格、图像和图表来解释它们。例如,Facebook正在使用一种可视化技术,通过直观的显示方式来操纵和组织其数据库中的数据。由于数据本身的复杂性,大数据可视化并不像传统的小数据可视化那样容易。传统可视化技术的扩展主要集中在大规模数据上,通过特征提取和几何建模在呈现实际数据之前减小数据的大小,使数据具有意义。为了更接近和直观地解释数据,许多研究人员采用并行方式进行批模型软件渲染,以获得最高的数据分辨率。在处理大数据时,数据表示和选择合适的数据表示是非常重要的。科学家们已经意识到,计算机的图形化潜力和利用大数据的可视化策略将成为数据分析师最大的资源。正如Wang等人所述,数据可视化方面的创新表明,一个好的用户界面价值1000 pb。
(五)统计学
统计学是在大数据研究中出现的基于特定基础数学来收集、组织和分析数据的数学技术的集合。从技术的角度来看,通过利用目标之间的相互关系和因果关系以及样本的数值描述的推导,支持数据管理和分析阶段的决策。然而,传统的统计技术往往不能很好地适应海量数据的管理,并行统计、统计学习和统计计算等新方法应运而生。特别是统计技术的规模化和并行实现,可以提高处理海量数据的能力。例如,沃尔玛商店通过使用与机器学习相关的统计技术,利用交易数据中的模式,来支持其涉及广告活动和定价策略的决策。Batarseh和Latif(2016)提出了统计回归模型,该模型与数据集的大小和用于估计相对于输入变量单调的函数的过程数量呈线性关系。
(六)优化技术
在生物学、物理学、经济学和工程学等多学科领域,优化技术已成为解决定量问题的有效技术。不同的计算策略,如粒子群优化、遗传算法、调度算法、蜂群、进化规划、量子退火和模拟退火,由于其定量实现的性质和它们表现出的并行性,可以有效地解决全局优化问题。然而,它们具有较高的内存成本和时间消耗,并且需要在实时环境下通过协作式协同进化算法进行扩展,以处理大数据应用。这些计算策略还与优化问题中的数据约简和并行性相结合。该领域的另一个热门话题是实时优化,其能力已经在智能交通系统和无线传感器网络等许多大数据应用中的决策问题中得到了证明。
五、大数据工具的优缺点对比。
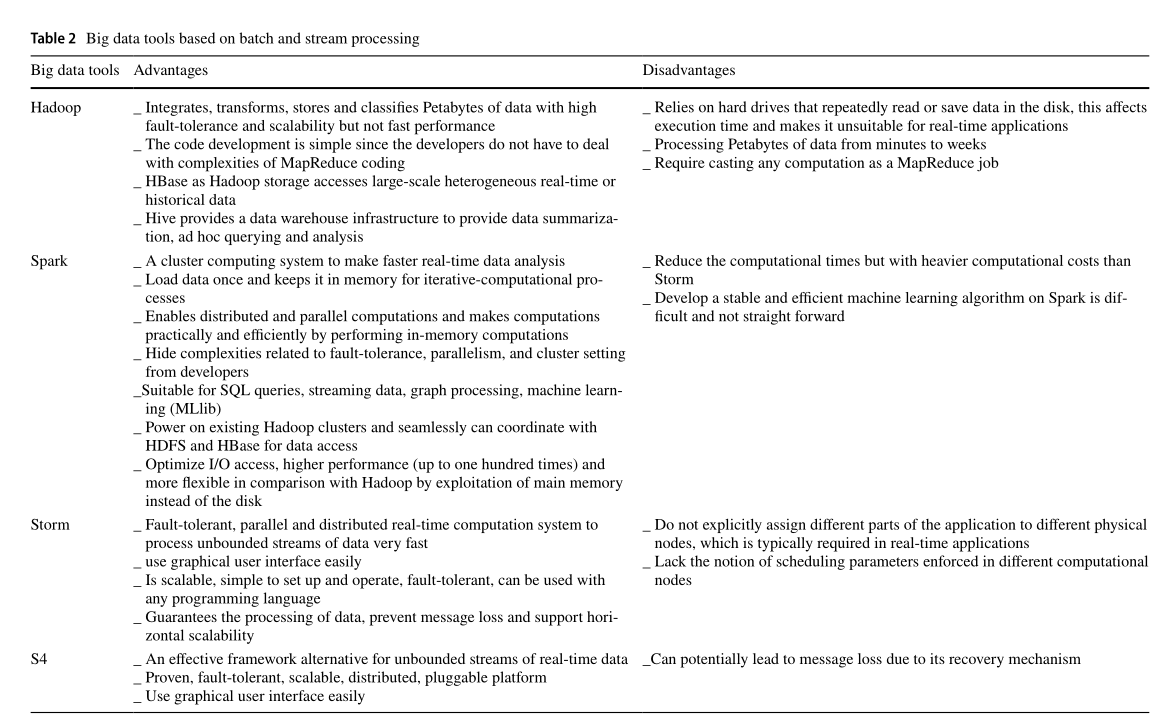
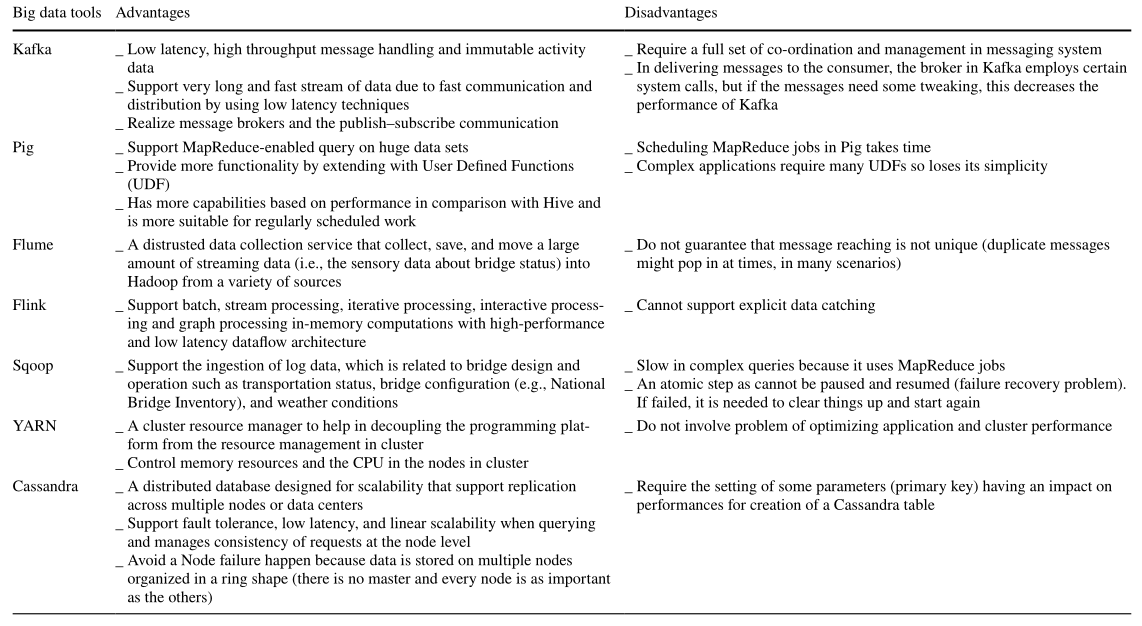
相关文章:
扩展学习|大数据分析的现状和分类
文献来源:[1] Mohamed A , Najafabadi M K , Wah Y B ,et al.The state of the art and taxonomy of big data analytics: view from new big data framework[J].Artificial Intelligence Review: An International Science and Engineering Journal, 2020(2):53. 下…...
java学习笔记-初级
完整笔记下载链接:https://download.csdn.net/download/qq_48257021/88800766?spm1001.2014.3001.5503 一、变量 1.双标签 <!-- 外部js script 双标签 --><script srcmy.js></script> 在新文件my.js里面写: 2.字符串定义ÿ…...

使用axios 封装大文件上传,支持断点续传的功能
使用 Axios 实现断点续传、重试、暂停、开始和上传进度功能 简介 在许多应用程序中,我们经常需要上传大文件。但是,由于网络连接不稳定或其他原因,上传过程可能会中断。为了解决这个问题,我们可以使用断点续传功能。断点续传允许…...

在python中,设置json支持中文字符串
# 省略以上环节 ... # 假设json格式如下 system_info_dict {uptime: uptime.split(".")[0],cpu_usage: cpu_usage,memory_usage: memory_usage,disk_usage: disk_usage,battery_percentage: battery_percentage,battery_status: batteryStatus }# 设置json支持中文字…...

qnx du统计目录大小单位
在qnx上使用du命令统计目录大小时,发现统计数值与实际大小不一样。 比如目录下有个已知1gb大小的问题,但du统计出来的值跟1gb差太多了 # ls -al total 2097169 drwxrwxrwx 2 root root 4096 Jan 01 00:21 . drwxrwxrwx 6 root …...

测试人员如何向开发人员准确清晰地描述问题?
测试人员向开发人员准确清晰地描述问题可以采取以下方法: 提供详细的背景和上下文信息:描述问题发生的环境、前提条件和操作步骤,让开发人员能够了解问题出现的场景。明确问题的症状和表现:清楚地说明问题的具体表现,…...
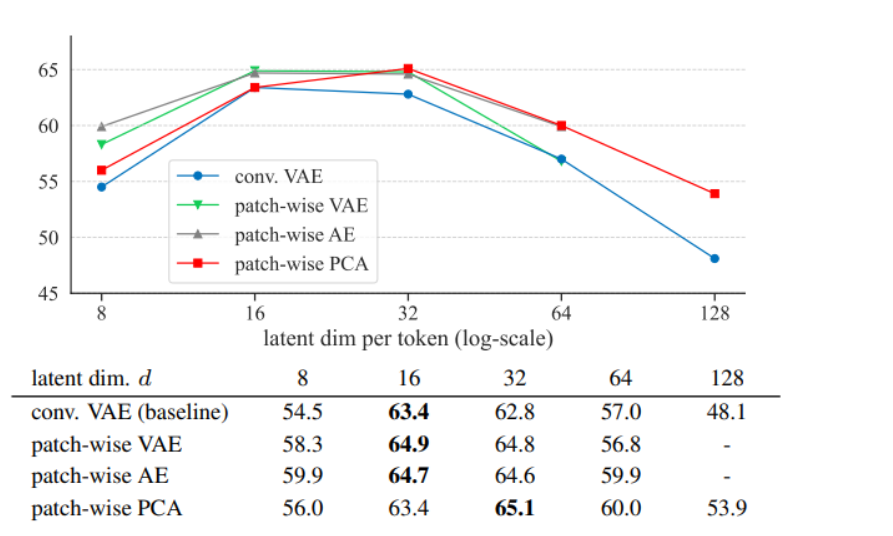
何恺明新作 l-DAE:解构扩散模型
何恺明新作 l-DAE:解构扩散模型 提出背景扩散模型步骤如何在不影响数据表征能力的同时简化模型?如何进一步推动模型向经典DAE靠拢?如何去除对生成任务设计的DDM中不适用于自监督学习的部分?如何改进DDM以专注于清晰图像表示的学习…...

【数学建模获奖经验】2023第八届数维杯数学建模:华中科技大学本科组创新奖获奖分享
2024年第九届数维杯大学生数学建模挑战赛将于:2024年5月10日08:00-5月13日09:00举行,近期同学们都开始陆续进入了备赛阶段,今天我们就一起来看看上一届优秀的创新奖选手都有什么获奖感言吧~希望能帮到更多热爱数学建模的同学。据说点赞的大佬…...
Kubernetes(k8s第二部分)
资源清单相当于剧本 什么是资源: k8s中所有的内容都抽象为资源,资源实例化后,叫做对象。 1.K8S中的资源 集群资源分类 名称空间级别: kubeadm k8s kube-system kubectl get pod -n default 工作负载型资源,&a…...

mac新环境
1、maven 设置阿里云镜像 打开Maven的settings.xml文件。找到<mirrors>标签,如果没有,可以手动添加。在<mirrors>标签内部添加以下内容: <mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorO…...

神经网络基础知识:LeNet的搭建-训练-预测
1.参考视频: 2.1 pytorch官方demo(Lenet)_哔哩哔哩_bilibili 2.总结: (1)LeNet网络就是 我最开始用来预测mnist数据集的那个网络,简单的2个conv2个maxpool3个linear层 (2)up主整理的train.py…...
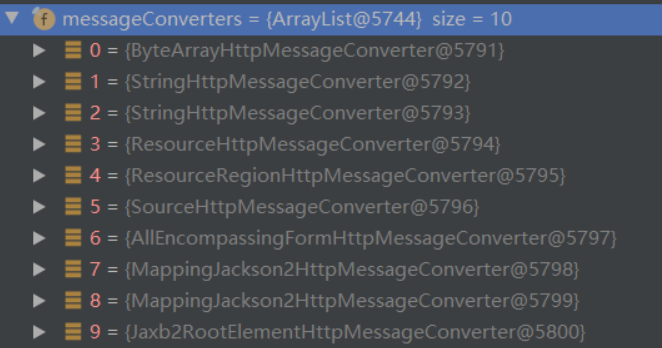
SpringMVC 学习(七)之报文信息转换器 HttpMessageConverter
目录 1 HttpMessageConverter 介绍 2 RequestBody 注解 3 ResponseBody 注解 4 RequestEntity 5 ResponseEntity 6 RestController 注解 1 HttpMessageConverter 介绍 HttpMessageConverter 报文信息转换器,将请求报文(如JSON、XML、HTML等&#x…...

浅谈密码学
文章目录 每日一句正能量前言什么是密码学对称加密简述加密语法Kerckhoffs原则常用的加密算法现代密码学的原则威胁模型(按强度增加的顺序) 密码学的应用领域后记 每日一句正能量 人生在世,谁也不能做到让任何人都喜欢,所以没必要…...
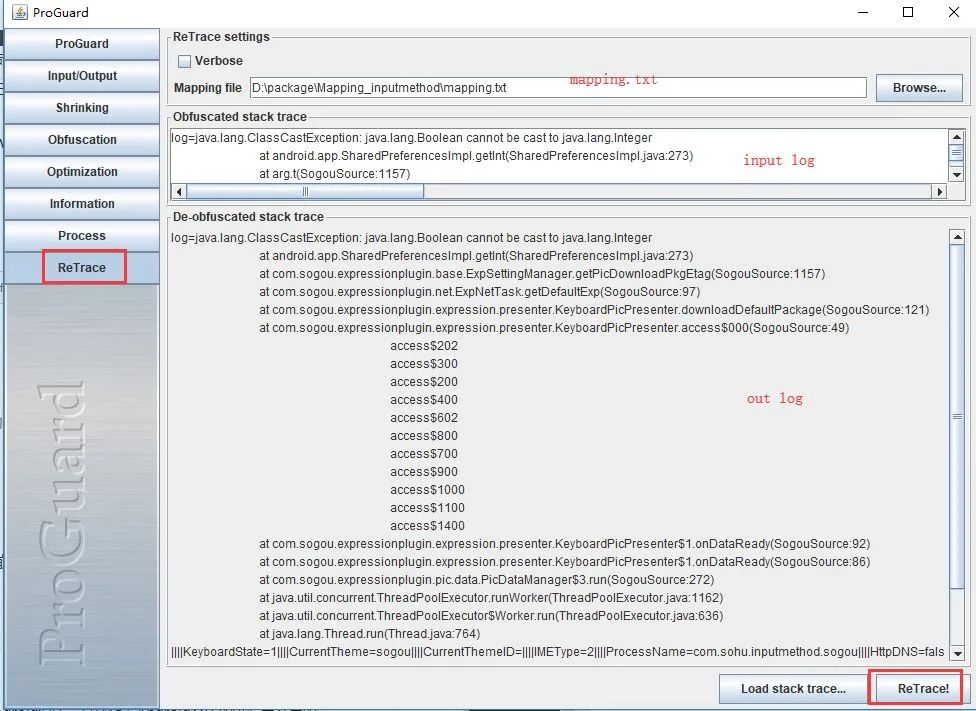
Android 混淆是啥玩意儿?
什么是混淆 Android混淆,是伴随着Android系统的流行而产生的一种Android APP保护技术,用于保护APP不被破解和逆向分析。简单的说,就是将原本正常的项目文件,对其类、方法、字段,重新命名a,b,c…之类的字母,…...
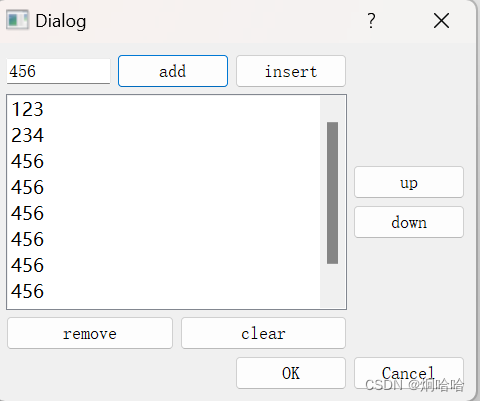
【嵌入式——QT】QListWidget
QListWidget类提供了一个基于项的列表小部件,QListWidgetItem是列表中的项,该篇文章中涉及到的功能有添加列表项,插入列表项,删除列表项,清空列表,向上移动列表项,向下移动列表项。 常用API a…...

爬虫入门到精通_基础篇5(PyQuery库_PyQuery说明,初始化,基本CSS选择器,查找元素,遍历,获取信息,DOM操作)
1 PyQuery说明: PyQuery是python中一个强大而又灵活的网页解析库,如果你觉得正则写起来太麻烦,又觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法那么,PyQuery就是你绝佳的选择。 安装 pip3 install pyquery2 …...

用冒泡排序模拟C语言中的内置快排函数qsort!
目录 编辑 1.回调函数的介绍 2. 回调函数实现转移表 3. 冒泡排序的实现 4. qsort的介绍和使用 5. qsort的模拟实现 6. 完结散花 悟已往之不谏,知来者犹可追 创作不易,宝子们!如果这篇文章对你们有帮助的话,别忘了给个免…...

智慧公厕:打造智慧城市环境卫生新标杆
随着科技的不断发展和城市化进程的加速推进,智慧城市建设已经成为各地政府和企业关注的焦点。而作为智慧城市环境卫生管理的基础设施,智慧公厕的建设和发展也备受重视,被誉为智慧城市的新标杆。本文以智慧公厕源头厂家广州中期科技有限公司&a…...

【学习版】Microsoft Office 2021安装破解教程
本文转载自知乎:https://zhuanlan.zhihu.com/p/655653158 由本人二次整理修改 用到的软件为:Office Tool Plus,下载链接:Office Tool Plus 官方网站 - 一键部署 Office (landian.vip) 下载页面:(随机找个站…...
基于java Springboot实现课程评分系统设计和实现
基于java Springboot实现课程评分系统设计和实现 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获取源…...

IndexTTS2 V23情感语音合成保姆级教程:一键启动WebUI界面
IndexTTS2 V23情感语音合成保姆级教程:一键启动WebUI界面 1. 从零开始:为什么你需要这个情感语音工具 想象一下,你正在为一个有声书项目寻找配音,或者想为你的视频内容配上更生动、更有感染力的旁白。传统的语音合成工具听起来总…...

Qwen3-ForcedAligner-0.6B中小企业应用:低成本构建自有字幕工厂全流程
Qwen3-ForcedAligner-0.6B中小企业应用:低成本构建自有字幕工厂全流程 1. 为什么中小企业需要自己的字幕工厂 在视频内容爆发的时代,字幕已经成为提升用户体验的关键要素。无论是企业宣传视频、在线课程、产品演示还是社交媒体内容,精准的字…...

大模型---RLHF
目录 1.RLHF的定义 2.LLM的RLHF 3.奖励模型 4.RLHF的主要问题与局限 5.“非显式RL”方法 (1)DPO (2)RRHF 后续有更深入学习,再继续补充: 1.RLHF的定义 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)的核心思想就是先让人告诉模型…...

开源大模型Phi-4-mini-reasoning横向评测:性能、成本与易用性深度分析
开源大模型Phi-4-mini-reasoning横向评测:性能、成本与易用性深度分析 1. 评测背景与模型概览 在开源大模型生态快速发展的当下,Phi-4-mini-reasoning作为一款轻量级推理模型引起了开发者社区的广泛关注。这款由微软研究院开源的模型,定位在…...

零基础也能玩转!QWEN-AUDIO智能语音合成系统5分钟快速部署教程
零基础也能玩转!QWEN-AUDIO智能语音合成系统5分钟快速部署教程 想不想让电脑开口说话,而且声音还能像真人一样有感情?今天,我就带你用5分钟时间,把一个专业的智能语音合成系统搬到你自己的电脑上。不需要懂代码&#…...

RTX 4090D 24G大模型推理免配置镜像:PyTorch 2.8 + CUDA 12.4保姆级教程
RTX 4090D 24G大模型推理免配置镜像:PyTorch 2.8 CUDA 12.4保姆级教程 1. 开箱即用的深度学习环境 如果你正在寻找一个免配置、开箱即用的深度学习环境,这个基于RTX 4090D 24GB显卡优化的PyTorch 2.8镜像就是为你准备的。想象一下,不用再花…...

Qwen3-TTS-Tokenizer-12Hz实际项目:语音标注平台音频token化存储与检索优化
Qwen3-TTS-Tokenizer-12Hz实际项目:语音标注平台音频token化存储与检索优化 如果你正在开发一个语音标注平台,或者管理着海量的语音数据,那你一定遇到过这些头疼的问题:音频文件太大,存储成本高得吓人;想找…...

翻译工具太单调?试试像素语言·跨维传送门:一键部署,开箱即用
翻译工具太单调?试试像素语言跨维传送门:一键部署,开箱即用 1. 产品概述 像素语言跨维传送门(Pixel Language Portal)是一款基于腾讯混元MT-7B核心引擎构建的高端翻译终端。与传统翻译工具不同,它采用16-…...

Notepad++效率倍增:集成Phi-4-mini-reasoning的代码片段智能生成
Notepad效率倍增:集成Phi-4-mini-reasoning的代码片段智能生成 1. 为什么Notepad需要AI加持? 作为一款轻量级代码编辑器,Notepad凭借其快速启动和简洁界面赢得了全球开发者的喜爱。但面对日益复杂的开发需求,传统编辑器在智能辅…...

Ollama部署DeepSeek-R1:解决数学编程问题的智能助手
Ollama部署DeepSeek-R1:解决数学编程问题的智能助手 1. 引言:为什么你需要一个数学和编程助手 如果你经常需要解决数学问题、编写代码或者处理复杂的逻辑推理,可能会遇到这样的困扰:面对一个复杂的方程,需要反复推导…...