Day908.joinsnljdist和group问题和备库自增主键问题 -MySQL实战
join&snlj&dist和group问题和备库自增主键问题
Hi,我是阿昌,今天学习记录的是关于join&snlj&dist和group问题和备库自增主键问题的内容。
一、join 的写法
join 语句怎么优化?中,在介绍 join 执行顺序的时候,用的都是 straight_join。
两个问题:
- 如果用 left join 的话,左边的表一定是驱动表吗?
- 如果两个表的 join 包含多个条件的等值匹配,是都要写到 on 里面呢,还是只把一个条件写到 on 里面,其他条件写到 where 部分?
来构造两个表 a 和 b:
create table a(f1 int, f2 int, index(f1))engine=innodb;
create table b(f1 int, f2 int)engine=innodb;
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
表 a 和 b 都有两个字段 f1 和 f2,不同的是表 a 的字段 f1 上有索引。
然后,往两个表中都插入了 6 条记录,其中在表 a 和 b 中同时存在的数据有 4 行。
下面这两种写法的区别:
select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q1*/
select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q2*/
把这两条语句分别记为 Q1 和 Q2。
首先,需要说明的是,这两个 left join 语句的语义逻辑并不相同。
先来看一下它们的执行结果。
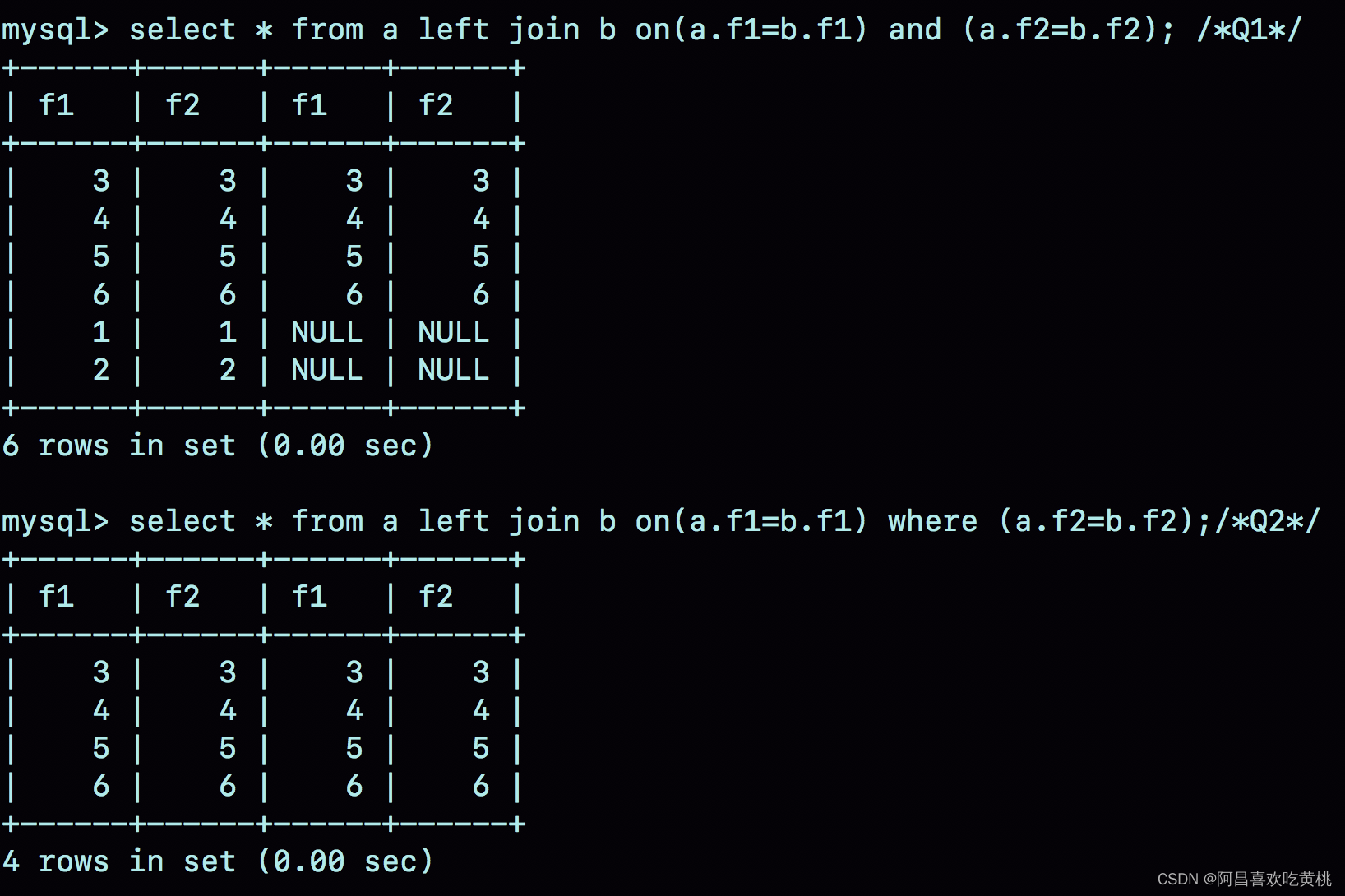
可以看到:
- 语句 Q1 返回的数据集是 6 行,表 a 中即使没有满足匹配条件的记录,查询结果中也会返回一行,并将表 b 的各个字段值填成 NULL。
- 语句 Q2 返回的是 4 行。从逻辑上可以这么理解,最后的两行,由于表 b 中没有匹配的字段,结果集里面 b.f2 的值是空,不满足 where 部分的条件判断,因此不能作为结果集的一部分。
接下来,看看实际执行这两条语句时,MySQL 是怎么做的。
先一起看看语句 Q1 的 explain 结果:

可以看到,这个结果符合预期:
- 驱动表是表 a,被驱动表是表 b;
- 由于表 b 的 f1 字段上没有索引,所以使用的是 Block Nested Loop Join(简称 BNL) 算法。
看到 BNL 算法,就应该知道这条语句的执行流程其实是这样的:
- 把表 a 的内容读入 join_buffer 中。因为是 select * ,所以字段 f1 和 f2 都被放入 join_buffer 了。
- 顺序扫描表 b,对于每一行数据,判断 join 条件(也就是 (a.f1=b.f1) and (a.f1=1))是否满足,满足条件的记录, 作为结果集的一行返回。如果语句中有 where 子句,需要先判断 where 部分满足条件后,再返回。
- 表 b 扫描完成后,对于没有被匹配的表 a 的行(在这个例子中就是 (1,1)、(2,2) 这两行),把剩余字段补上 NULL,再放入结果集中。
对应的流程图如下:
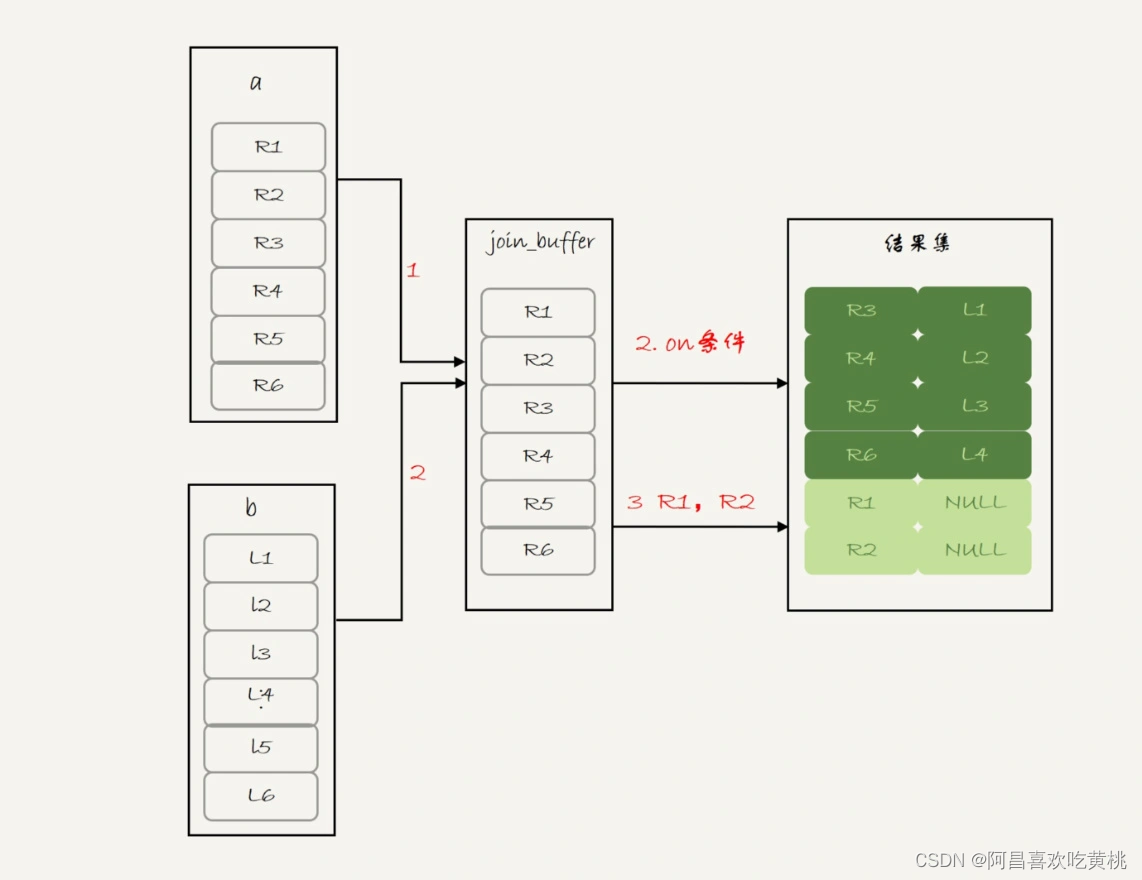
可以看到,这条语句确实是以表 a 为驱动表,而且从执行效果看,也和使用 straight_join 是一样的。
语句 Q2 的查询结果里面少了最后两行数据,是不是就是把上面流程中的步骤 3 去掉呢?
看一下语句 Q2 的 expain 结果吧。

这条语句是以表 b 为驱动表的。而如果一条 join 语句的 Extra 字段什么都没写的话,就表示使用的是 Index Nested-Loop Join(简称 NLJ)算法。
因此,语句 Q2 的执行流程是这样的:
顺序扫描表 b,每一行用 b.f1 到表 a 中去查,匹配到记录后判断 a.f2=b.f2 是否满足,满足条件的话就作为结果集的一部分返回。
那么,为什么语句 Q1 和 Q2 这两个查询的执行流程会差距这么大呢?其实,这是因为优化器基于 Q2 这个查询的语义做了优化。
一个背景知识点:在 MySQL 里,NULL 跟任何值执行等值判断和不等值判断的结果,都是 NULL。
这里包括, select NULL = NULL 的结果,也是返回 NULL。
因此,语句 Q2 里面 where a.f2=b.f2 就表示,查询结果里面不会包含 b.f2 是 NULL 的行,这样这个 left join 的语义就是“找到这两个表里面,f1、f2 对应相同的行。对于表 a 中存在,而表 b 中匹配不到的行,就放弃”。这样,这条语句虽然用的是 left join,但是语义跟 join 是一致的。
因此,优化器就把这条语句的 left join 改写成了 join,然后因为表 a 的 f1 上有索引,就把表 b 作为驱动表,这样就可以用上 NLJ 算法。
在执行 explain 之后,再执行 show warnings,就能看到这个改写的结果,如图 5 所示。

这个例子说明,即使在 SQL 语句中写成 left join,执行过程还是有可能不是从左到右连接的。也就是说,使用 left join 时,左边的表不一定是驱动表。
这样看来,如果需要 left join 的语义,就不能把被驱动表的字段放在 where 条件里面做等值判断或不等值判断,必须都写在 on 里面。
那如果是 join 语句呢?这时候,再看看这两条语句:
select * from a join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q3*/
select * from a join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q4*/
这个例子说明,即使在 SQL 语句中写成 left join,执行过程还是有可能不是从左到右连接的。也就是说,使用 left join 时,左边的表不一定是驱动表。
这样看来,如果需要 left join 的语义,就不能把被驱动表的字段放在 where 条件里面做等值判断或不等值判断,必须都写在 on 里面。
那如果是 join 语句呢?
这时候,再看看这两条语句:
select * from a join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q3*/
select * from a join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q4*/
再使用一次看 explain 和 show warnings 的方法,看看优化器是怎么做的。

可以看到,这两条语句都被改写成:
select * from a join b where (a.f1=b.f1) and (a.f2=b.f2);
执行计划自然也是一模一样的。也就是说,在这种情况下,join 将判断条件是否全部放在 on 部分就没有区别了。
二、Simple Nested Loop Join 的性能问题
join 语句使用不同的算法,对语句的性能影响会很大。在Join语句执行流程中,虽然 BNL 算法和 Simple Nested Loop Join 算法都是要判断 M*N 次(M 和 N 分别是 join 的两个表的行数),但是 Simple Nested Loop Join 算法的每轮判断都要走全表扫描,因此性能上 BNL 算法执行起来会快很多。
为了便于说明,简单描述一下这两个算法。
BNL 算法的执行逻辑是:
- 首先,将驱动表的数据全部读入内存 join_buffer 中,这里 join_buffer 是无序数组;
- 然后,顺序遍历被驱动表的所有行,每一行数据都跟 join_buffer 中的数据进行匹配,匹配成功则作为结果集的一部分返回。
Simple Nested Loop Join 算法的执行逻辑是:顺序取出驱动表中的每一行数据,到被驱动表去做全表扫描匹配,匹配成功则作为结果集的一部分返回。
Simple Nested Loop Join 算法,其实也是把数据读到内存里,然后按照匹配条件进行判断,为什么性能差距会这么大呢?
这个问题,需要用到 MySQL 中索引结构和 Buffer Pool 的相关知识点:
- 在对被驱动表做全表扫描的时候,如果数据没有在 Buffer Pool 中,就需要等待这部分数据从磁盘读入;从磁盘读入数据到内存中,会影响正常业务的 Buffer Pool 命中率,而且这个算法天然会对被驱动表的数据做多次访问,更容易将这些数据页放到 Buffer Pool 的头部;
- 即使被驱动表数据都在内存中,每次查找“下一个记录的操作”,都是类似指针操作。而 join_buffer 中是数组,遍历的成本更低。
所以说,BNL 算法的性能会更好。
三、distinct 和 group by 的性能
在内部临时表中,如果只需要去重,不需要执行聚合函数,distinct 和 group by 哪种效率高一些呢?
如果表 t 的字段 a 上没有索引,那么下面这两条语句:
select a from t group by a order by null;
select distinct a from t;
的性能是不是相同的?
首先需要说明的是,这种 group by 的写法,并不是 SQL 标准的写法。
标准的 group by 语句,是需要在 select 部分加一个聚合函数,比如:
select a,count(*) from t group by a order by null;
这条语句的逻辑是:按照字段 a 分组,计算每组的 a 出现的次数。
在这个结果里,由于做的是聚合计算,相同的 a 只出现一次。
没有了 count(*) 以后,也就是不再需要执行“计算总数”的逻辑时,第一条语句的逻辑就变成是:按照字段 a 做分组,相同的 a 的值只返回一行。而这就是 distinct 的语义,所以不需要执行聚合函数时,distinct 和 group by 这两条语句的语义和执行流程是相同的,因此执行性能也相同。
这两条语句的执行流程是下面这样的。
- 创建一个临时表,临时表有一个字段 a,并且在这个字段 a 上创建一个唯一索引;
- 遍历表 t,依次取数据插入临时表中:
- 如果发现唯一键冲突,就跳过;
- 否则插入成功;
- 遍历完成后,将临时表作为结果集返回给客户端。
四、备库自增主键问题
在[自增主键不能保证连续递增](https://blog.csdn.net/qq_43284469/article/details/129270486,在 binlog_format=statement 时,语句 A 先获取 id=1,然后语句 B 获取 id=2;接着语句 B 提交,写 binlog,然后语句 A 再写 binlog。
这时候,如果 binlog 重放,是不是会发生语句 B 的 id 为 1,而语句 A 的 id 为 2 的不一致情况呢?
首先,这个问题默认了“自增 id 的生成顺序,和 binlog 的写入顺序可能是不同的”,这个理解是正确的。
这个问题限定在 statement 格式下,也是对的。因为 row 格式的 binlog 就没有这个问题了,Write row event 里面直接写了每一行的所有字段的值。而至于为什么不会发生不一致的情况,来看一下下面的这个例子。
create table t(id int auto_increment primary key);
insert into t values(null);

可以看到,在 insert 语句之前,还有一句 SET INSERT_ID=1。这条命令的意思是,这个线程里下一次需要用到自增值的时候,不论当前表的自增值是多少,固定用 1 这个值。
这个 SET INSERT_ID 语句是固定跟在 insert 语句之前的,主库上语句 A 的 id 是 1,语句 B 的 id 是 2,但是写入 binlog 的顺序先 B 后 A,那么 binlog 就变成:
SET INSERT_ID=2;
语句B;
SET INSERT_ID=1;
语句A;
在备库上语句 B 用到的 INSERT_ID 依然是 2,跟主库相同。
因此,即使两个 INSERT 语句在主备库的执行顺序不同,自增主键字段的值也不会不一致。
相关文章:
Day908.joinsnljdist和group问题和备库自增主键问题 -MySQL实战
join&snlj&dist和group问题和备库自增主键问题 Hi,我是阿昌,今天学习记录的是关于join&snlj&dist和group问题和备库自增主键问题的内容。 一、join 的写法 join 语句怎么优化?中,在介绍 join 执行顺序的时候&am…...

算法 - 剑指Offer 丑数
题目 我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。 解题思路 这题我使用最简单方法去做, 首先我们可以获取所有2n,3n,5*n的丑数,只是我们这里暂时无法排序,并且可能…...
【ONE·C || 文件操作】
总言 C语言:文件操作。 文章目录总言1、文件是什么?为什么需要文件?1.1、为什么需要文件?1.2、文件是什么?2、文件的打开与关闭2.1、文件指针2.2、文件打开和关闭:fopen、fclose2.3、文件使用方式3、文…...
cmd窗口中java命令报错。错误:找不到或无法加载主类 java的jdk安装过程中踩过的坑
错误: 找不到或无法加载主类 HelloWorld 遇到这个问题时,我尝试过网上其他人的做法。有试过添加classpath,也有试过删除classpath。但是依然报错,这里javac可以编译通过,说明代码应该是没有问题的。只是在运行是出现了错误。我安装…...
)
Breathwork(呼吸练习)
查了下呼吸练习相关内容,做个记录。我又在油管学习啦。 喜欢在you. tube看一些self-help相关的内容。比如学习方法、拉伸、跑步、力量举、自重锻炼等等。 总是听Obi Vicent说起Breathwork,比如: My 6am Morning Routine | New Healthy Habit…...
taobao.itemprops.get( 获取标准商品类目属性 )
¥开放平台基础API不需用户授权 通过设置必要的参数,来获取商品后台标准类目属性,以及这些属性里面详细的属性值prop_values。 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 请求参数 点…...
QT配置安卓环境(保姆级教程)
目录 下载环境资源 JDK1.8 NDK SDK 安装QT 配置环境 下载环境资源 JDK1.8 介绍JDK是Java开发的核心工具,为Java开发者提供了一套完整的开发环境,包括开发工具、类库和API等,使得开发者可以高效地编写、测试和运行Java应用程序。 下载…...
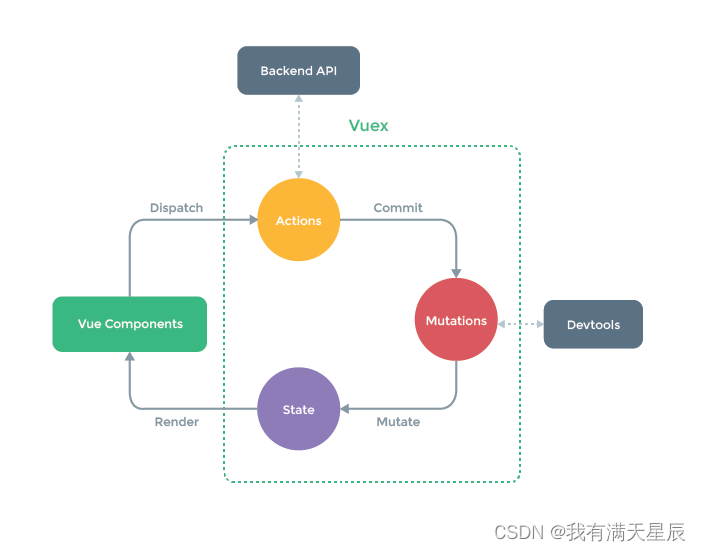
【uni-app教程】八、UniAPP Vuex 状态管理
八、UniAPP Vuex 状态管理 概念 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。 应用场景 Vue多个组件之间需要共享数据或状态。 关键规则 State:…...
)
同花顺测试面经(30min)
大概三十分钟,面试官人还挺好的 1.自我介绍 2.详细问你了自我介绍中的一个实习经历 3.对我们公司有什么了解 !!(高频) 4.对测试有什么看法,为什么选测试 5.黑盒白盒分别是什么 6.对测试左移有什么看法…...

C++-简述#ifdef、#else、#endif和#ifndef的作用
回答如下: #ifdef,#else,#endif和#ifndef都是预处理指令,用于条件编译。#ifdef:这个指令用来判断一个宏是否已经被定义过,如果已经定义过,则执行后面的代码块。#else:这个指令一般与…...

VictoriaMetrics 集群部署
官网 ## 官网 https://github.com/VictoriaMetrics/VictoriaMetrics 集群角色详解 VictoriaMetrics 集群模式。主要由 vmstorage ,vminsert,vmselect 三部分组成,这三个组件每个组件都可以单独进行扩展。其中: vmstorage 负责提供数据存储服务vminsert 是数据存…...
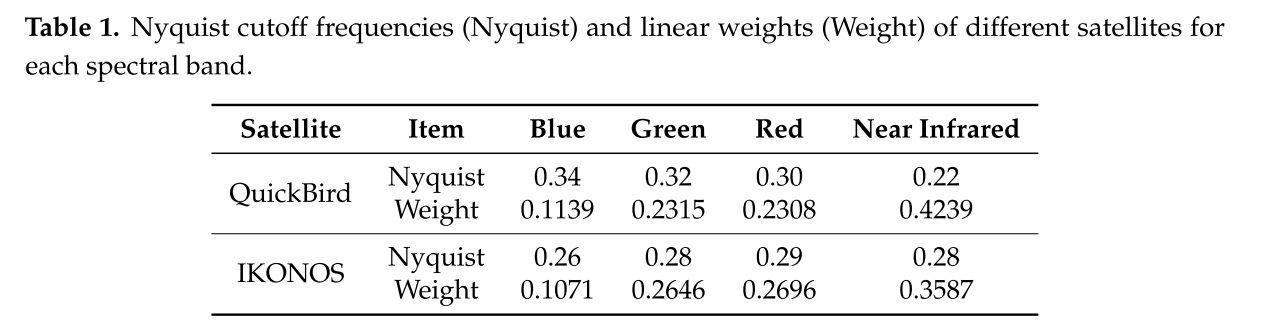
【基于感知损失的无监督泛锐化】
PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss (PercepPan:基于感知损失的无监督泛锐化) 在基于神经网络的全色锐化文献中,作为地面实况标签的高分辨率多光谱图像通常是不可用的。为了解决这个问题…...

在vercel上用streamlit部署网站
Verce和Streamlit都是非常流行的Web应用程序部署平台。以下是从零开始在Vercel上部署Streamlit应用程序的一些基本步骤。 安装 Streamlit 在本地计算机上安装Streamlit。可以轻松地通过在命令行中运行以下命令来安装: pip install streamlit为 Streamlit 应用程序…...
| 含思路)
华为OD机试题 - 斗地主(JavaScript)| 含思路
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜索引擎搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:斗地主题目输入输出描述示例一输入输出示例二输…...
-计算clock速度相关的内核API)
i.MX8MP平台开发分享(clock篇)-计算clock速度相关的内核API
专栏目录:专栏目录传送门 平台内核i.MX8MP5.15.71文章目录 clk消费者clk生产者clk_set_rateclk_round_rateclk_pll1443x_recalc_rate这一篇我们具体来看看其他驱动如何使用clock,这里以lcdif驱动为例。 IMX8MP_CLK_MEDIA_BLK_CTRL_LCDIF_PIXEL是门控时钟,名为pix,这个门控时…...
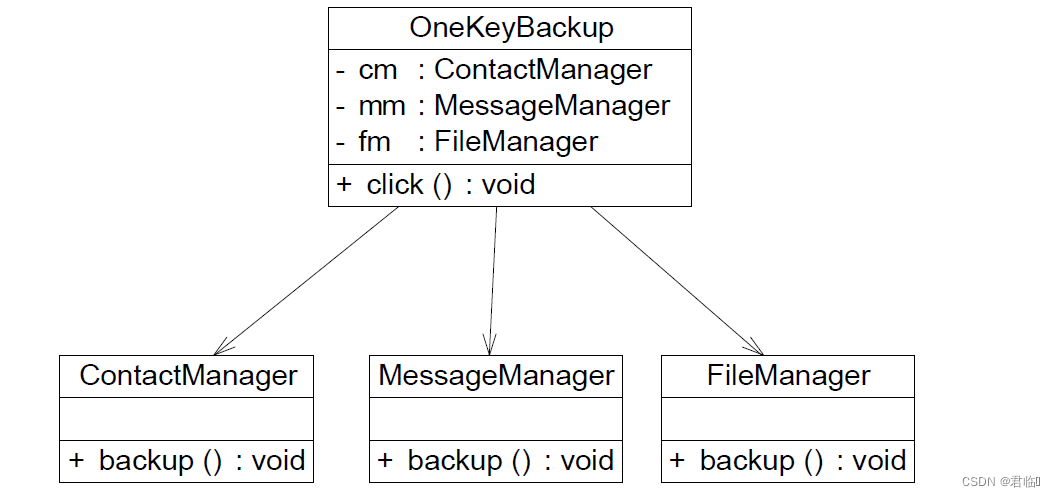
实验4 设计模式实验3
实验内容: 1. 某软件公司为新开发的智能手机控制与管理软件提供了一键备份功能,通 过该功能可以将原本存储在手机中的通信录、短信、照片、歌曲等资料一次性全 部拷贝到移动存储介质(例如MMC 卡或SD 卡)中。在实现过程中需要与多个 已有的类进行交互,例如通讯录管理类、短信…...
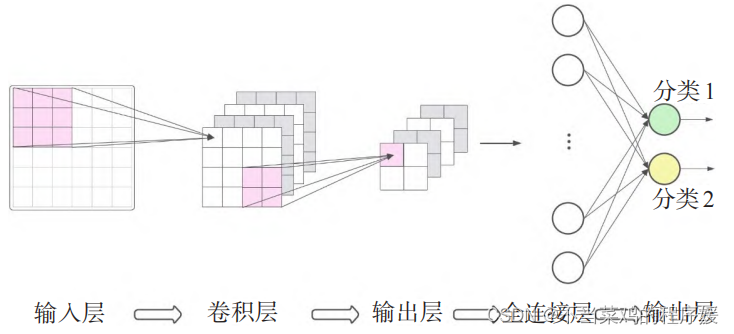
CNN基础
Tip:仅供自己学习记录,酌情参考 1. 前馈与反馈神经网络 神经网络有前馈神经网络和反馈神经网络,前向神经网络也就是前馈神经网络。 前馈型神经网络各神经元接收前一层的输入,并输出给下一层,没有反馈。节点分为两类…...
【UEFI基础】UEFI事件介绍
简述 在【UEFI基础】System Table和Architecture Protocols介绍Boot Service时提到有一部分与事件相关的接口,它们创建、触发、等待和关闭事件,来完成某些功能,本文将进一步介绍事件。 需要注意,因为Boot Service需要在DXE阶段才…...

Markdown 语法速查表
Markdown 速查表提供了所有 Markdown 语法元素的基本解释。如果你想了解某些语法元素的更多信息,请参阅更详细的基本语法和拓展语法。 #基本语法 这些是 John Gruber 的原始设计文档中列出的元素。所有 Markdown 应用程序都支持这些元素。 元素Markdown 语法标题…...
【C++】-- 类型转换
目录 前言 C语言中的类型转换 C强制类型转换 static_cast(static静止的) reinterpret_cast(reinterpret重新解释) const_cast(const常量) 总结 dynamic_cast(dynamic动态) …...

ipa 覆盖算法参数调优实战:从理论到可视化验证
1. IPA覆盖算法核心参数解析 在机器人路径规划领域,IPA覆盖算法因其高效性和适应性被广泛应用。这个算法的核心在于几个关键参数的协同作用,它们直接影响着机器人的覆盖路径质量和执行效率。让我们先来认识这些"幕后操控者": cover…...

LTE CDRX配置优化与日志解析实战
1. LTE CDRX功能基础与核心参数解析 CDRX(Connected Mode DRX)是LTE网络中终端设备在连接状态下实现节能的关键技术。想象一下你的手机就像个熬夜加班的程序员,如果一直盯着电脑屏幕(持续监听网络信号),电量…...
)
Python项目依赖管理:如何用pipreqs精准生成requirements.txt(附常见问题解决)
Python项目依赖管理实战:从pipreqs到高效协作的全链路优化 在Python项目开发中,依赖管理就像建筑的地基——它不显眼却决定了整个项目的稳定性。想象一下这样的场景:你花了三天时间调试一个诡异的问题,最后发现只是因为测试环境缺…...

企业级“衣依”服装销售平台管理系统源码|SpringBoot+Vue+MyBatis架构+MySQL数据库【完整版】
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 随着电子商务的快速发展,服装行业对高效、智能化的销售管理平台需求日益增长。传统的线下销售模式在库存管理、订单处理及客户服务等方…...

Vivado Linux版安装空间不足?手把手教你如何优化磁盘空间分配
Vivado Linux版安装空间优化实战指南:从130G到80G的瘦身方案 当你在Linux系统上第一次看到Vivado安装程序提示需要130GB以上的磁盘空间时,那种震惊感我至今记忆犹新。作为一名长期在ThinkPad X1 Carbon上工作的FPGA开发者,我深刻理解空间受限…...

终极指南:免费解锁Cursor Pro完整功能,告别AI编程限制
终极指南:免费解锁Cursor Pro完整功能,告别AI编程限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reach…...

Azure IoT Hub AMQP传输层深度解析与嵌入式实践
1. Azure IoT Hub AMQP 传输层技术深度解析Azure IoT Hub 是微软面向物联网场景构建的高可靠、可扩展云平台,其核心能力依赖于多种协议栈的协同支持。在众多通信协议中,AMQP(Advanced Message Queuing Protocol)因其固有的消息可靠…...

2026知识付费SaaS避坑指南:数据安全与系统稳定性实测,创客匠人为何值得托付?
在知识付费行业,大多数选型对比只关注“前台功能”:能不能卖课、能不能直播、有没有拼团。但真正决定生意生死的,往往是看不见的“底层能力”——数据是否安全?系统是否稳定?学员资产能否真正归你所有?过去…...

ESP32 -espidf 实战:利用AW9523实现16路PWM调光与高电流驱动
1. 为什么需要AW9523扩展芯片? ESP32作为一款功能强大的物联网芯片,其GPIO资源在实际项目中经常捉襟见肘。做过智能照明项目的朋友应该深有体会,当我们需要控制多个LED灯带时,ESP32自带的PWM通道根本不够用。我曾经在一个商业照明…...

新手福音:跳过jdk安装,在快马平台开启你的java编程第一课
作为一个Java新手,最让人头疼的往往不是学习语法本身,而是那些繁琐的环境配置。记得我刚开始学Java时,光是安装JDK就折腾了大半天,还要配置环境变量、测试安装是否成功...这些准备工作简直能把学习的热情消磨殆尽。 不过现在有了I…...