bert 相似度任务训练完整版
任务
之前写了一个相似度任务的版本:bert 相似度任务训练简单版本,faiss 寻找相似 topk-CSDN博客
相似度用的是 0,1,相当于分类任务,现在我们相似度有评分,不再是 0,1 了,分数为 0-5,数字越大代表两个句子越相似,这一次的比较完整,评估,验证集,相似度模型都有了。
数据集
链接:https://pan.baidu.com/s/1B1-PKAKNoT_JwMYJx_zT1g
提取码:er1z
原始数据好几千条,我训练数据用了部分 2500 条,验证,测试 300 左右,使用 cpu 也用了好几个小时
train.py
import torch
import os
import time
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertModel, AdamW, get_cosine_schedule_with_warmup
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 设备选择
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = 'cpu'# 定义文本相似度数据集类
class TextSimilarityDataset(Dataset):def __init__(self, file_path, tokenizer, max_len=128):self.data = []with open(file_path, 'r', encoding='utf-8') as f:for line in f.readlines():text1, text2, similarity_score = line.strip().split('\t')inputs1 = tokenizer(text1, padding='max_length', truncation=True, max_length=max_len)inputs2 = tokenizer(text2, padding='max_length', truncation=True, max_length=max_len)self.data.append({'input_ids1': inputs1['input_ids'],'attention_mask1': inputs1['attention_mask'],'input_ids2': inputs2['input_ids'],'attention_mask2': inputs2['attention_mask'],'similarity_score': float(similarity_score),})def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def cosine_similarity_torch(vec1, vec2, eps=1e-8):dot_product = torch.mm(vec1, vec2.t())norm1 = torch.norm(vec1, 2, dim=1, keepdim=True)norm2 = torch.norm(vec2, 2, dim=1, keepdim=True)similarity_scores = dot_product / (norm1 * norm2.t()).clamp(min=eps)return similarity_scores# 定义模型,这里我们不仅计算两段文本的[CLS] token的点积,而是整个句向量的余弦相似度
class BertSimilarityModel(torch.nn.Module):def __init__(self, pretrained_model):super(BertSimilarityModel, self).__init__()self.bert = BertModel.from_pretrained(pretrained_model)self.dropout = torch.nn.Dropout(p=0.1) # 引入Dropout层以防止过拟合def forward(self, input_ids1, attention_mask1, input_ids2, attention_mask2):embeddings1 = self.dropout(self.bert(input_ids=input_ids1, attention_mask=attention_mask1)['last_hidden_state'])embeddings2 = self.dropout(self.bert(input_ids=input_ids2, attention_mask=attention_mask2)['last_hidden_state'])# 计算两个文本向量的余弦相似度embeddings1 = torch.mean(embeddings1, dim=1)embeddings2 = torch.mean(embeddings2, dim=1)similarity_scores = cosine_similarity_torch(embeddings1, embeddings2)# 映射到[0, 5]评分范围normalized_similarities = (similarity_scores + 1) * 2.5return normalized_similarities.unsqueeze(1)# 自定义损失函数,使用Smooth L1 Loss,更适合处理回归问题
class SmoothL1Loss(torch.nn.Module):def __init__(self):super(SmoothL1Loss, self).__init__()def forward(self, predictions, targets):diff = predictions - targetsabs_diff = torch.abs(diff)quadratic = torch.where(abs_diff < 1, 0.5 * diff ** 2, abs_diff - 0.5)return torch.mean(quadratic)def train_model(model, train_loader, val_loader, epochs=3, model_save_path='../output/bert_similarity_model.pth'):model.to(device)criterion = SmoothL1Loss() # 使用自定义的Smooth L1 Lossoptimizer = AdamW(model.parameters(), lr=5e-5) # 调整初始学习率为5e-5num_training_steps = len(train_loader) * epochsscheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=0.1*num_training_steps, num_training_steps=num_training_steps) # 使用带有warmup的余弦退火学习率调度best_val_loss = float('inf')for epoch in range(epochs):model.train()for batch in train_loader:input_ids1 = batch['input_ids1'].to(device)attention_mask1 = batch['attention_mask1'].to(device)input_ids2 = batch['input_ids2'].to(device)attention_mask2 = batch['attention_mask2'].to(device)similarity_scores = batch['similarity_score'].to(device)optimizer.zero_grad()outputs = model(input_ids1, attention_mask1, input_ids2, attention_mask2)loss = criterion(outputs, similarity_scores.unsqueeze(1))loss.backward()optimizer.step()scheduler.step()# 验证阶段model.eval()with torch.no_grad():val_loss = 0total_val_samples = 0for batch in val_loader:input_ids1 = batch['input_ids1'].to(device)attention_mask1 = batch['attention_mask1'].to(device)input_ids2 = batch['input_ids2'].to(device)attention_mask2 = batch['attention_mask2'].to(device)similarity_scores = batch['similarity_score'].to(device)val_outputs = model(input_ids1, attention_mask1, input_ids2, attention_mask2)val_loss += criterion(val_outputs, similarity_scores.unsqueeze(1)).item()total_val_samples += len(similarity_scores)val_loss /= len(val_loader)print(f'Epoch {epoch + 1}, Validation Loss: {val_loss:.4f}')if val_loss < best_val_loss:best_val_loss = val_losstorch.save(model.state_dict(), model_save_path)def collate_to_tensors(batch):'''把数据处理为模型可用的数据,不同任务可能需要修改一下,'''input_ids1 = torch.tensor([example['input_ids1'] for example in batch])attention_mask1 = torch.tensor([example['attention_mask1'] for example in batch])input_ids2 = torch.tensor([example['input_ids2'] for example in batch])attention_mask2 = torch.tensor([example['attention_mask2'] for example in batch])similarity_score = torch.tensor([example['similarity_score'] for example in batch])return {'input_ids1': input_ids1, 'attention_mask1': attention_mask1, 'input_ids2': input_ids2,'attention_mask2': attention_mask2, 'similarity_score': similarity_score}# 加载数据集和预训练模型
tokenizer = BertTokenizer.from_pretrained('../bert-base-chinese')
model = BertSimilarityModel('../bert-base-chinese')# 加载数据并创建
train_data = TextSimilarityDataset('../data/STS-B/STS-B.train - 副本.data', tokenizer)
val_data = TextSimilarityDataset('../data/STS-B/STS-B.valid - 副本.data', tokenizer)
test_data = TextSimilarityDataset('../data/STS-B/STS-B.test - 副本.data', tokenizer)train_loader = DataLoader(train_data, batch_size=32, shuffle=True, collate_fn=collate_to_tensors)
val_loader = DataLoader(val_data, batch_size=32, collate_fn=collate_to_tensors)
test_loader = DataLoader(test_data, batch_size=32, collate_fn=collate_to_tensors)optimizer = AdamW(model.parameters(), lr=2e-5)# 开始训练
train_model(model, train_loader, val_loader)# 加载最佳模型进行测试
model.load_state_dict(torch.load('../output/bert_similarity_model.pth'))
test_loss = 0
total_test_samples = 0with torch.no_grad():for batch in test_loader:input_ids1 = batch['input_ids1'].to(device)attention_mask1 = batch['attention_mask1'].to(device)input_ids2 = batch['input_ids2'].to(device)attention_mask2 = batch['attention_mask2'].to(device)similarity_scores = batch['similarity_score'].to(device)test_outputs = model(input_ids1, attention_mask1, input_ids2, attention_mask2)test_loss += torch.nn.functional.mse_loss(test_outputs, similarity_scores.unsqueeze(1)).item()total_test_samples += len(similarity_scores)test_loss /= len(test_loader)
print(f'Test Loss: {test_loss:.4f}')
predit.py
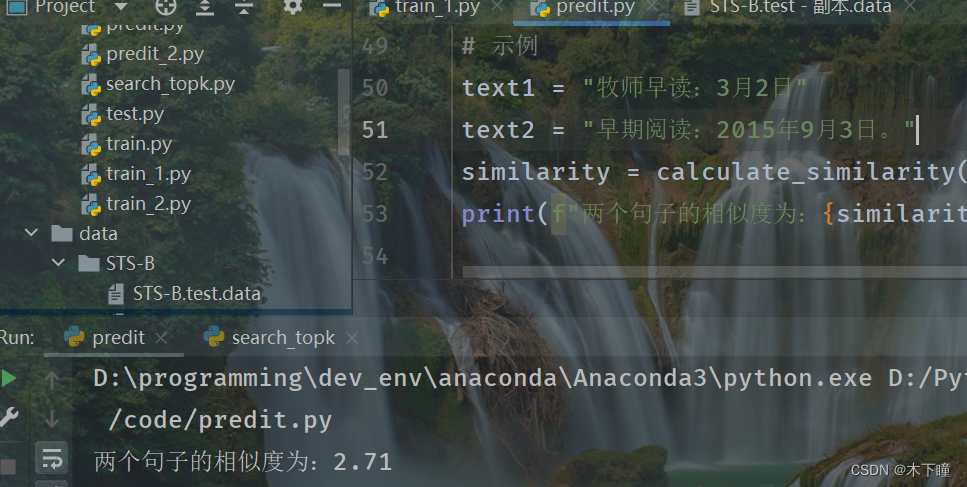
这个脚本是用来看看效果的,直接传入两个文本,使用训练好的模型来计算相似度的
import torch
from transformers import BertTokenizer, BertModeldef cosine_similarity_torch(vec1, vec2, eps=1e-8):dot_product = torch.mm(vec1, vec2.t())norm1 = torch.norm(vec1, 2, dim=1, keepdim=True)norm2 = torch.norm(vec2, 2, dim=1, keepdim=True)similarity_scores = dot_product / (norm1 * norm2.t()).clamp(min=eps)return similarity_scores# 定义模型,这里我们不仅计算两段文本的[CLS] token的点积,而是整个句向量的余弦相似度
class BertSimilarityModel(torch.nn.Module):def __init__(self, pretrained_model):super(BertSimilarityModel, self).__init__()self.bert = BertModel.from_pretrained(pretrained_model)self.dropout = torch.nn.Dropout(p=0.1) # 引入Dropout层以防止过拟合def forward(self, input_ids1, attention_mask1, input_ids2, attention_mask2):'''如果是用来预测,forward 会被禁用'''pass# 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('../bert-base-chinese')
model = BertSimilarityModel('../bert-base-chinese')
model.load_state_dict(torch.load('../output/bert_similarity_model.pth')) # 请确保路径正确
model.eval() # 设置模型为评估模式def calculate_similarity(text1, text2):# 对输入文本进行编码inputs1 = tokenizer(text1, padding='max_length', truncation=True, max_length=128, return_tensors='pt')inputs2 = tokenizer(text2, padding='max_length', truncation=True, max_length=128, return_tensors='pt')# 计算相似度with torch.no_grad():embeddings1 = model.bert(**inputs1.to('cpu'))['last_hidden_state'][:, 0]embeddings2 = model.bert(**inputs2.to('cpu'))['last_hidden_state'][:, 0]similarity_score = cosine_similarity_torch(embeddings1, embeddings2).item()# 映射到[0, 5]评分范围(假设训练时有此步骤)normalized_similarity = (similarity_score + 1) * 2.5return normalized_similarity# 示例
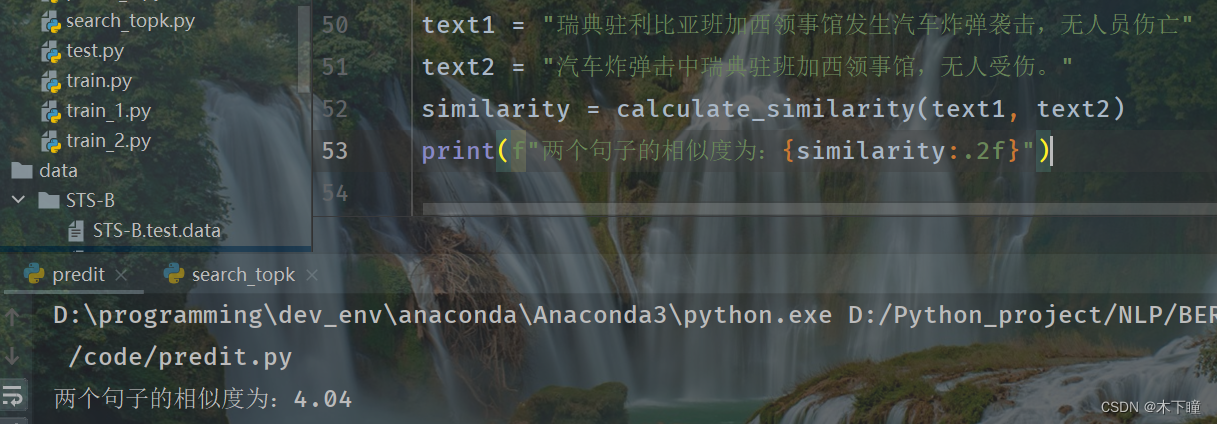
text1 = "瑞典驻利比亚班加西领事馆发生汽车炸弹袭击,无人员伤亡"
text2 = "汽车炸弹击中瑞典驻班加西领事馆,无人受伤。"
similarity = calculate_similarity(text1, text2)
print(f"两个句子的相似度为:{similarity:.2f}")
相关文章:
bert 相似度任务训练完整版
任务 之前写了一个相似度任务的版本:bert 相似度任务训练简单版本,faiss 寻找相似 topk-CSDN博客 相似度用的是 0,1,相当于分类任务,现在我们相似度有评分,不再是 0,1 了,分数为 0-5,数字越大…...

Ribbon实现Cloud负载均衡
安装Zookeeper要先安装JDK环境 解压 tar -zxvf /usr/local/develop/jdk-8u191-linux-x64.tar.gz -C /usr/local/develop 配置JAVA_HOME vim /etc/profile export JAVA_HOME/usr/local/develop/jdk1.8.0_191 export PATH$JAVA_HOME/bin:$PATH export CLASSPATH.:$JAVA_HOM…...
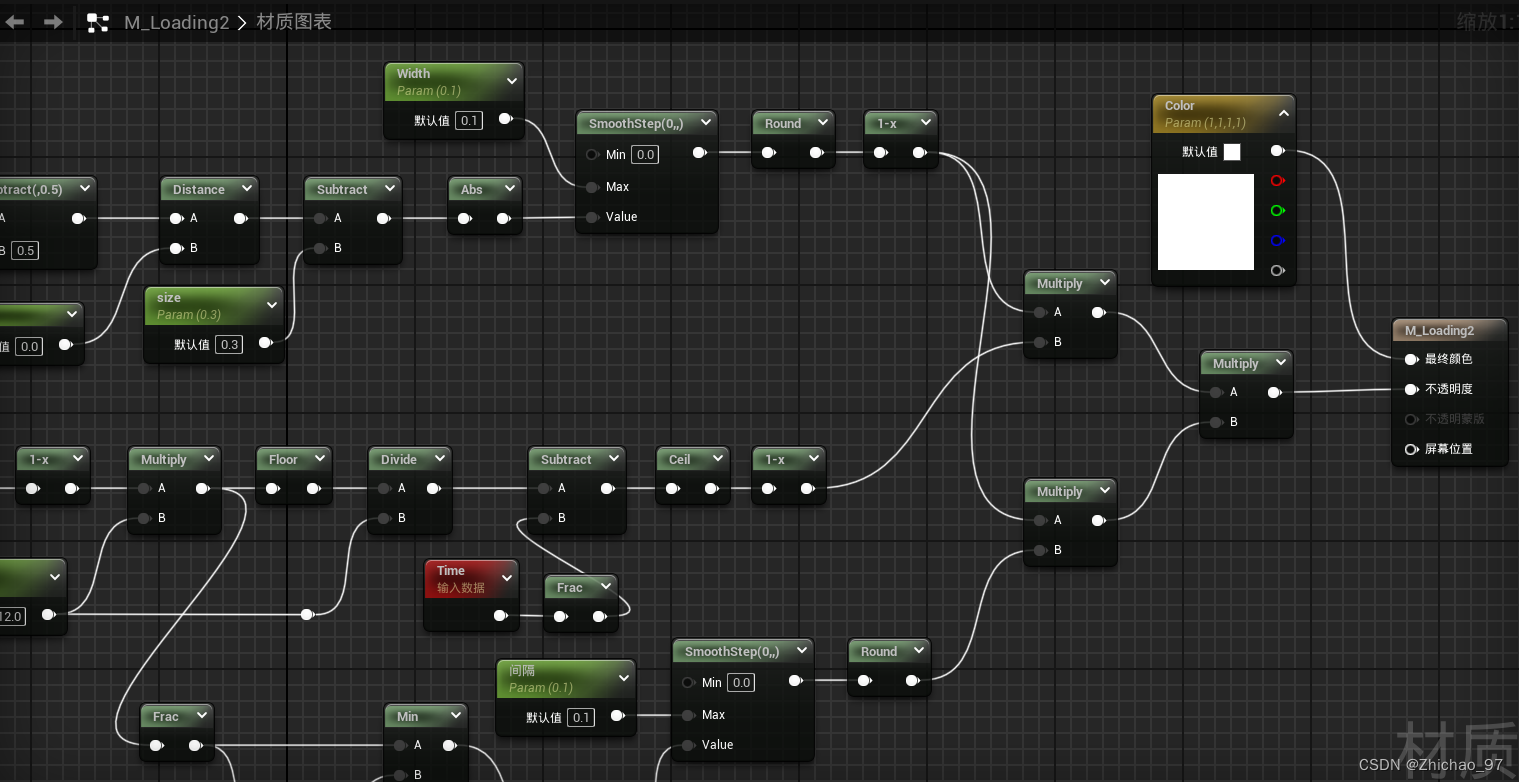
【UE 材质】制作加载图案(2)
在上一篇(【UE 材质】制作加载图案)基础上继续实现如下效果的加载图案 效果 步骤 1. 复制一份上一篇制作的材质并打开 2. 添加“Floor”节点向下取整 除相同的平铺数 此时的效果如下 删除如下节点 通过“Ceil”向上取整,参数“Tiling”默认…...

为啥要用C艹不用C?
在很多时候,有人会有这样的疑问 ——为什么要用C?C相对于C优势是什么? 最近两年一直在做Linux应用,能明显的感受到C带来到帮助以及快感 之前,我在文章里面提到环形队列 C语言,环形队列 环形队列到底是怎么回…...
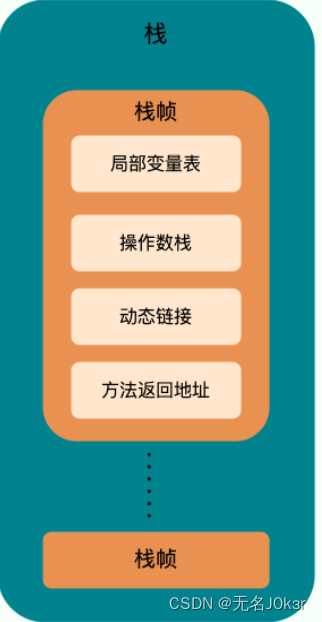
Java:JVM基础
文章目录 参考JVM内存区域程序计数器虚拟机栈本地方法栈堆方法区符号引用与直接引用运行时常量池字符串常量池直接内存 参考 JavaGuide JVM内存区域 程序计数器 程序计数器是一块较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器,各线程…...

JavaSec 基础之五大不安全组件
文章目录 不安全组件(框架)-Shiro&FastJson&Jackson&XStream&Log4jLog4jShiroJacksonFastJsonXStream 不安全组件(框架)-Shiro&FastJson&Jackson&XStream&Log4j Log4j Apache的一个开源项目,是一个基于Java的日志记录框架。 历史…...

python类的属性、方法、静态方法、静态方法类内部的调用、直接调用与实例化调用
设计者:ISDF工软未来 版本:v1.0 日期:2024/3/4 class Restaurant:餐馆类def __init__(self,restaurant_name,cuisine_type):#类的属性self.restaurant_name restaurant_nameself.cuisine_type cuisine_type# self.stregth_level 0def desc…...

haproxy集成国密ssl功能[下]
上接[haproxy集成国密ssl功能上 4. 源码修改解析 以下修改基本围绕haproxy的ssl_sock.c进行修改来展开的,为了将整个实现逻辑能够说明清楚,下述内容有部分可能就是直接摘抄haproxy的原有代码没有做任何修改,而大部分增加或者修改的内容则进行了特别的说明。 4.1 为bind指令…...
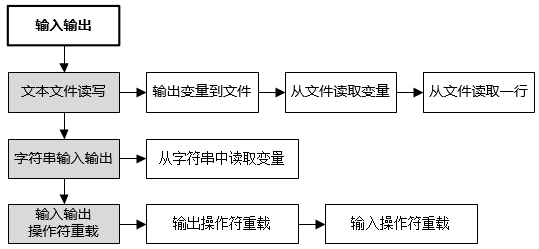
C++自学精简实践教程
一、介绍 1.1 教程特点 一篇文章从入门到就业有图有真相,有测试用例,有作业;提供框架代码,作业只需要代码填空规范开发习惯,培养设计能力 1.2 参考书 唯一参考书《C Primer 第5版》参考书下载: 蓝奏云…...

每日一题——LeetCode1572.矩阵对角线元素的和
方法一 遍历矩阵 如果矩阵中某个位置(x,y)处于对角线上,那么这个位置必定满足: xy 或 xy len-1 (len为矩阵长度) var diagonalSum function(mat) {let len mat.length;let sum 0;for (let i 0; i …...
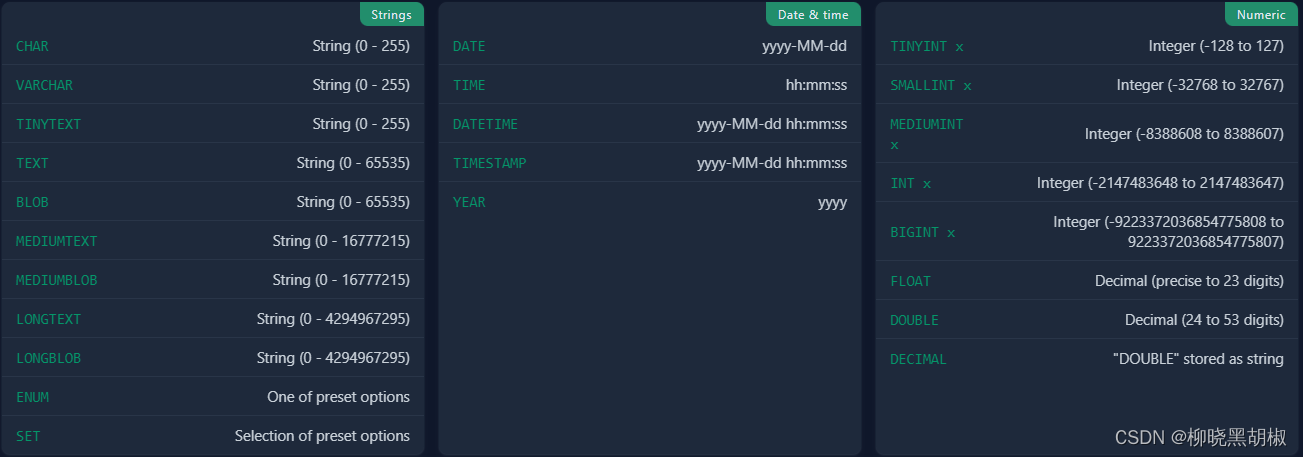
mysql 常用命令练习
管理表格从表中查询数据从多个表查询修改数据sql变量类型 管理表格 创建一个包含三列的新表 CREATE TABLE products (id INT,name VARCHAR(255) NOT NULL,price INT DEFAULT 0,PRIMARY KEY(id) // 自增 ); 从数据库中删除表 DROP TABLE product; 向表中添加新列 ALTER TAB…...

QT6 libModbus 用于ModbusTcp客户端读写服务端
虽然在以前的文章中多次描述过,那么本文使用开源库libModbus,可得到更好的性能,也可移植到各种平台。 性能:读1次和写1次约各用时2ms。 分别创建了读和写各1个连接指针,用于读100个寄存器和写100个寄存器,读写分离。 客户端&am…...
Tensor使用教程)
飞桨(PaddlePaddle)Tensor使用教程
文章目录 飞桨(PaddlePaddle)Tensor使用教程1. 安装飞桨2. 创建Tensor3. Tensor的基本属性4. Tensor的操作5. Tensor的广播机制6. Tensor与Numpy数组的转换7. 结论 飞桨(PaddlePaddle)Tensor使用教程 1. 安装飞桨 首先ÿ…...
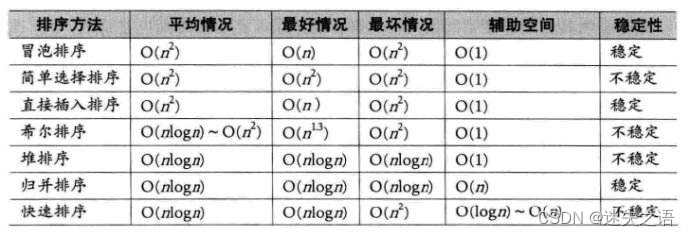
数据结构c版(3)——排序算法
本章我们来学习一下数据结构的排序算法! 目录 1.排序的概念及其运用 1.1排序的概念 1.2 常见的排序算法 2.常见排序算法的实现 2.1 插入排序 2.1.1基本思想: 2.1.2直接插入排序: 2.1.3 希尔排序( 缩小增量排序 ) 2.2 选择排序 2.2…...

《Spring Security 简易速速上手小册》第5章 高级认证技术(2024 最新版)
文章目录 5.1 OAuth2 和 OpenID Connect5.1.1 基础知识详解OAuth2OpenID Connect结合 OAuth2 和 OIDC 5.1.2 重点案例:使用 OAuth2 和 OpenID Connect 实现社交登录案例 Demo 5.1.3 拓展案例 1:访问受保护资源案例 Demo测试访问受保护资源 5.1.4 拓展案例…...

【七】【SQL】自连接
自连接初见 数据库中的自连接是一种特殊类型的SQL查询,它允许表与自身进行连接,以便查询表中与其他行相关联的行。自连接通常用于处理那些存储在同一个表中的但彼此之间具有层级或关系的数据。为了实现自连接,通常需要给表使用别名ÿ…...

C语言while 与 do...while 的区别?
一、问题 while 语句和 do...while 语句类似,都是要判断循环条件是否为真。如果为真,则执⾏循环体,否则退出循环。它们之间有什么区别呢? 二、解答 while 语句和 do..while 语句的区别在于:do..while 语句是先执⾏⼀次…...

RK3568平台开发系列讲解(基础篇)内核错误码
🚀返回专栏总目录 文章目录 一、指针的分类二、错误码三、错误码使用案例沉淀、分享、成长,让自己和他人都能有所收获!😄 一、指针的分类 二、错误码 在 Linux 内核中,所谓的错误指针已经指向了内核空间的最后一页,例如,对于一个 64 位系统来说,内核空间最后地址为 0…...
)
点云从入门到精通技术详解100篇-基于点云网络和 PSO 优化算法的手势估计(续)
目录 3 深度图像处理及转化 3.1 双目深度摄像原理及深度图的获取 3.1.1 理想化双目深度相机成像...
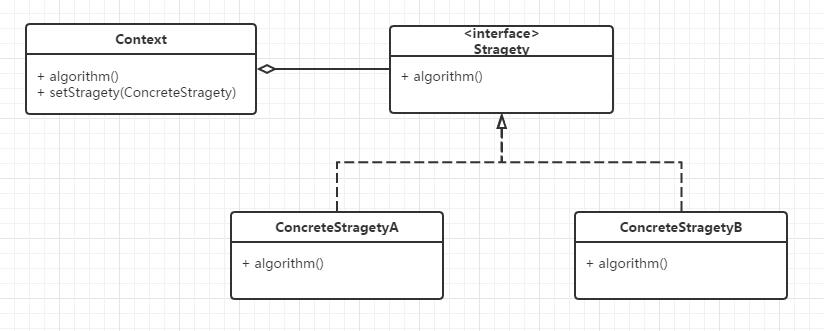
设计模式(十一)策略模式
请直接看原文:设计模式(十一)策略模式_某移动支付系统在实现账户资金转入和转出时需要进行身份验证,该系统为用户提供了-CSDN博客 ----------------------------------------------------------------------------------------------------------------…...

终极资源嗅探指南:猫抓浏览器扩展帮你轻松捕获网页媒体资源
终极资源嗅探指南:猫抓浏览器扩展帮你轻松捕获网页媒体资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在当今数字时代,…...

信息检索模型在社会科学文献结构化提取中的应用与评估
1. 项目背景与核心价值:当信息检索遇上社会科学研究在社会科学和政策评估领域,我们常常面临一个既基础又棘手的挑战:如何从堆积如山的学术论文、项目报告和评估文件中,快速、准确地找到我们真正关心的信息?是研究设计用…...

别再只盯着深度学习!用OpenCV+Python实战传统分水岭算法,5分钟搞定细胞图像分割
用OpenCVPython玩转分水岭算法:5分钟实现细胞图像精准分割在医学图像分析领域,细胞计数和分割一直是基础且关键的环节。传统深度学习方法虽然效果惊艳,但往往需要大量标注数据和计算资源。而分水岭算法这个诞生于1992年的经典方法,…...
)
自动驾驶、机器人导航都在用:实战调参卡尔曼滤波的Q和R(Python/OpenCV示例)
自动驾驶与机器人导航中的卡尔曼滤波实战:Q和R参数调优指南卡尔曼滤波在状态估计领域就像一位不知疲倦的裁判,不断在系统预测和传感器测量之间寻找平衡点。而Q(过程噪声协方差)和R(测量噪声协方差)这两个关…...

ESXi 6.7性能调优第一步:别急着装系统,先搞定主板BIOS里这4个关键设置
ESXi 6.7性能调优实战:BIOS层四大核心参数深度解析当你以为ESXi的性能瓶颈在于内存分配或存储配置时,可能忽略了最底层的硬件虚拟化支持。我曾亲眼见证一个中型企业的vSphere集群在调整BIOS参数后,虚拟机密度提升了40%,而硬件配置…...
)
车企AI Agent团队组建白皮书(附2024头部厂商组织架构图+7个核心岗位能力雷达图)
更多请点击: https://intelliparadigm.com 第一章:车企AI Agent团队组建的战略意义与行业演进 在智能网联汽车加速落地的背景下,AI Agent已从实验室概念演进为车载系统的核心决策单元——它不再仅执行预设指令,而是具备环境感知、…...

FPGA加速机器学习在粒子物理触发系统中的应用与实战
1. 项目概述:当FPGA遇上机器学习,为粒子物理装上“火眼金睛” 在大型强子对撞机(LHC)的心脏地带,每秒发生着数亿次质子对撞。每一次对撞都可能产生希格斯玻色子、顶夸克,或是我们尚未知晓的新物理现象。然而…...

ESP32嵌入式AI语音助手安全加固实战指南
1. 这不是“调个API就完事”的玩具项目,而是一次对嵌入式AI终端真实攻防边界的摸底你手头刚拿到一份标榜“ESP32本地LLM语音唤醒”的开源AI语音助手源码,烧录进开发板后,它能听懂“打开灯”“今天天气怎么样”,甚至能用合成语音回…...

UE5 GPU崩溃真相:Windows TCC超时机制与注册表调优指南
1. 为什么UE5项目一跑就GPU崩溃,而系统却说“显卡没出问题”?你刚在UE5里搭好一个带Niagara粒子Lumen全局光照的场景,点下Play,画面卡住两秒,然后整个编辑器黑屏、崩溃,任务管理器里UnrealEditor进程直接消…...

UE5.3与VS2022编译配置深度优化指南
1. 为什么UE5项目在VS2022里编译慢、报错多、改个头文件就全量重编?我第一次把团队刚升级的UE5.3项目拖进Visual Studio 2022时,整整等了17分42秒才完成首次编译——不是链接,是编译。中间还弹出6个“LNK2019未解析外部符号”、3个“C2039‘G…...