【机器学习】实验6,基于集成学习的 Amazon 用户评论质量预测
清华大学驭风计划课程链接
学堂在线 - 精品在线课程学习平台 (xuetangx.com)
代码和报告均为本人自己实现(实验满分),此次代码开源大家可以自行参考学习
有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~
一、案例简介¶
随着电商平台的兴起,以及疫情的持续影响,线上购物在我们的日常生活中扮演着越来越重要的角色。在进行线上商品挑选时,评论往往是我们十分关注的一个方面。然而目前电商网站的评论质量参差不齐,甚至有水军刷好评或者恶意差评的情况出现,严重影响了顾客的购物体验。因此,对于评论质量的预测成为电商平台越来越关注的话题,如果能自动对评论质量进行评估,就能根据预测结果避免展现低质量的评论。本案例中我们将基于集成学习的方法对 Amazon 现实场景中的评论质量进行预测。
二、作业说明
本案例中需要大家完成两种集成学习算法的实现(Bagging、AdaBoost.M1),其中基分类器要求使用 SVM 和决策树两种,因此,一共需要对比四组结果(AUC 作为评价指标):
-
Bagging + SVM
-
Bagging + 决策树
-
AdaBoost.M1 + SVM
-
AdaBoost.M1 + 决策树
注意集成学习的核心算法需要手动进行实现,基分类器可以调库。
基本要求
-
根据数据格式设计特征的表示
-
汇报不同组合下得到的 AUC
-
结合不同集成学习算法的特点分析结果之间的差异
-
(使用 sklearn 等第三方库的集成学习算法会酌情扣分)
扩展要求
-
尝试其他基分类器(如 k-NN、朴素贝叶斯)
-
分析不同特征的影响
-
分析集成学习算法参数的影响
本次数据来源于 Amazon 电商平台,包含超过 50,000 条用户在购买商品后留下的评论,各列的含义如下:
* reviewerID:用户 ID
* asin:商品 ID
* reviewText:英文评论文本
* overall:用户对商品的打分(1-5)
* votes_up:认为评论有用的点赞数(只在训练集出现)
* votes_all:该评论得到的总评价数(只在训练集出现)
* label:评论质量的 label,1 表示高质量,0 表示低质量(只在训练集出现)
评论质量的 label 来自于其他用户对评论的 votes,votes_up/votes_all ≥ 0.9 的作为高质量评论。此外测试集包含一个额外的列 ID,标识了每一个测试的样例。
三, 实验结果
在处理文本特征时候我也有尝试引入其他特征,比如评论长度,情感浓度,但是发现训练的效果反而更差,所以最终没有引入新的特征,在这里也尝试过Countvectorizer方法,最终会使得预测效果变差不少,最终使用TfidfVectorizer发现效果好很多。在这里也使用了稀疏数组的拼接方法,很适合大规模文本数据。
# 处理文本特征
vectorize_model = TfidfVectorizer(stop_words='english')
train_X = vectorize_model.fit_transform(train_df['reviewText'])
test_X = vectorize_model.transform(test_df['reviewText']) # 合并上总评分特征
train_X = scipy.sparse.hstack([train_X, train_df['overall'].values.reshape((-1, 1)) / 5])
test_X = scipy.sparse.hstack([test_X, test_df['overall'].values.reshape((-1, 1)) / 5])
train_X.shape,train_df['label'].shape((57039, 153748), (57039,))
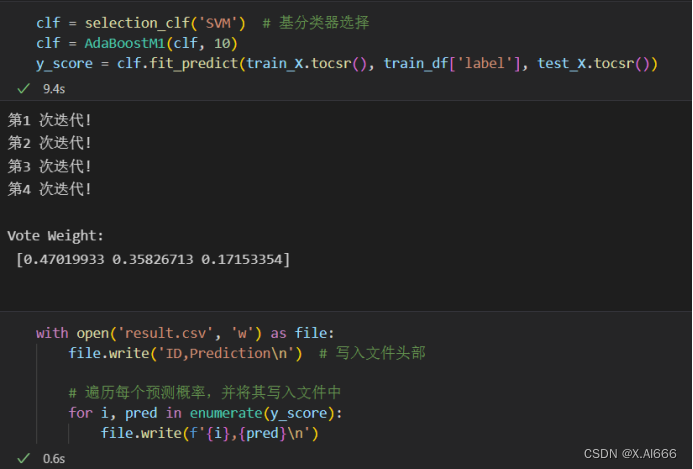
def selection_clf(base_name):clf = Noneif base_name == 'SVM':base_clf = svm.LinearSVC()clf = CalibratedClassifierCV(base_clf, cv=2, method='sigmoid')elif base_name == 'DTree':clf = DecisionTreeClassifier(max_depth=10, class_weight='balanced')return clfclass Bagging:def __init__(self, base_estimator, num_estimators):self.base_estimator = base_estimator # 基分类器对象self.num_estimators = num_estimators # Bagging 的分类器个数def fit_predict(self, X_train, y_train, X_test):num_samples = X_train.shape[0]num_features = X_train.shape[1]result = np.zeros(X_test.shape[0]) # 记录测试集的预测结果for i in range(self.num_estimators):sample_indices = np.random.choice(num_samples, size=num_samples, replace=True) # Bootstrapsample_X = X_train[sample_indices]sample_y = y_train[sample_indices]estimator = clone(self.base_estimator) # 克隆基分类器estimator.fit(sample_X, sample_y)print(f"模型 {i+1:2d} 完成!")predict_proba = estimator.predict_proba(X_test)[:, 1]result += predict_proba # 累加不同分类器的预测概率result /= self.num_estimators # 取平均(投票)return result
class AdaBoostM1(object):def __init__(self, base_estimator, num_iter):self.base_estimator = base_estimator # 基础分类器对象self.num_iter = num_iter # 迭代次数def fit_predict(self, X_train, y_train, X_test):result_lst, beta_lst = [], [] # 记录每次迭代的预测结果和投票权重num_samples = len(y_train)weights = np.ones(num_samples) # 样本权重,注意总和应为 num_samplesfor i in range(self.num_iter):self.base_estimator.fit(X_train, y_train, sample_weight=weights) # 带权重的训练print('第{:<2d}次迭代!'.format(i+1))train_predictions = self.base_estimator.predict(X_train) # 训练集预测结果misclassified = train_predictions != y_train error = np.sum(weights[misclassified]) / num_samples if error > 0.5:breakbeta = error / (1 - error)weights = weights * (1 - misclassified) * beta + weights * misclassified weights /= np.sum(weights) / num_samples # 归一化,使权重和等于 num_samplesbeta_lst.append(beta)test_predictions = self.base_estimator.predict_proba(X_test)[:, 1] # 测试集预测概率result_lst.append(test_predictions)beta_lst = np.log(1 / np.array(beta_lst))beta_lst /= np.sum(beta_lst) # 归一化投票权重print('\nVote Weight:\n', beta_lst)result = np.sum(np.array(result_lst) * beta_lst[:, None], axis=0) return resultfrom sklearn.model_selection import train_test_split
X_train, x_test, y_train, y_test = train_test_split(train_X, train_df['label'], test_size=0.14, random_state=42, shuffle=True)在训练的时候也发现bagging算法要是使用直接划分的数据集会出错,所以我用了直接切片的方法就运行成功了。通过4种组合看出,svm+adaboostm1的组合auc成绩最高,在bagging算法在此次运行中不如adaboostm1的效果好。
clf = selection_clf('SVM') # 基分类器选择
clf = Bagging(clf, 10)
y_score = clf.fit_predict(train_X.tocsr()[:50000], train_df['label'][:50000], train_X.tocsr()[50000:57039])# 计算ROC曲线和AUC
fpr, tpr, thresholds = roc_curve(train_df['label'][50000:57039], y_score)
roc_auc = auc(fpr, tpr)# 绘制ROC曲线
plt.plot(fpr, tpr, label='ROC curve (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--') # 绘制对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('SVM+Bagging')
plt.legend(loc="lower right")
plt.show()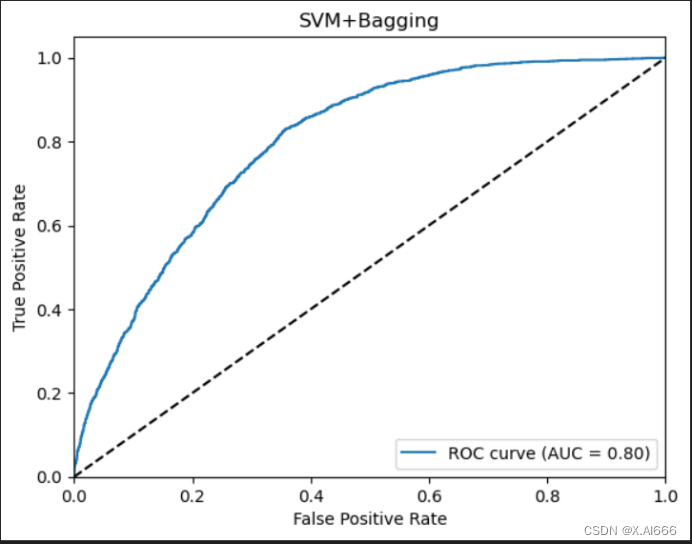
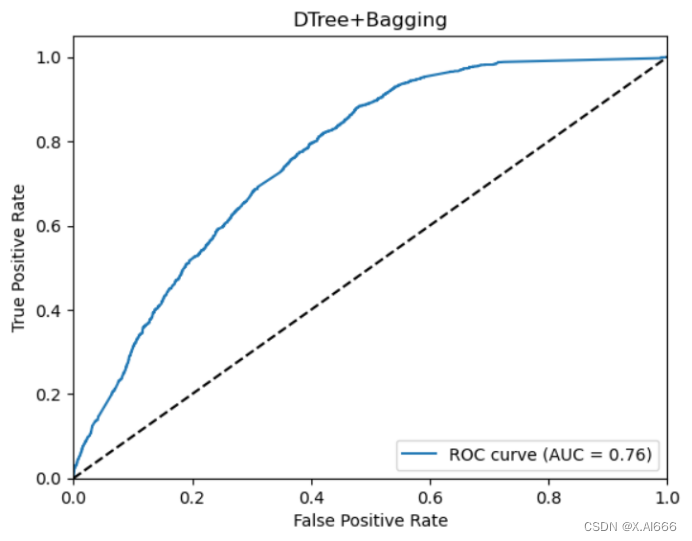

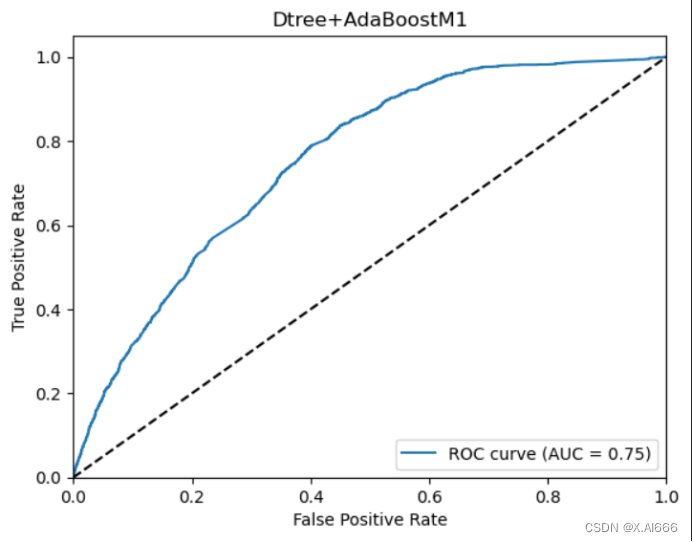
最终选择选择效果最好的svm+adaboostm1进行预测,最终写入文件。
相关文章:
【机器学习】实验6,基于集成学习的 Amazon 用户评论质量预测
清华大学驭风计划课程链接 学堂在线 - 精品在线课程学习平台 (xuetangx.com) 代码和报告均为本人自己实现(实验满分),此次代码开源大家可以自行参考学习 有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟…...
【寸铁的刷题笔记】图论、bfs、dfs
【寸铁的刷题笔记】图论、bfs、dfs 大家好 我是寸铁👊 金三银四,图论基础结合bfs、dfs是必考的知识点✨ 快跟着寸铁刷起来!面试顺利上岸👋 喜欢的小伙伴可以点点关注 💝 🌞详见如下专栏🌞 &…...

vue2 + axios + mock.js封装过程,包含mock.js获取数据时报404状态的解决记录,带图文,超详细!!!
vue axios mock.js 以下是封装的过程,记录一下 1、首先先了解什么是mock.js的用途及特点 官网地址:Mock.js (mockjs.com) 作用:生成随机数据,拦截 Ajax 请求 优势: 2、了解axios的原理及使用 官网地址:…...
对象变更记录objectlog工具(持续跟新)
文章目录 前言演示代码演示环境引入项目项目框架操作步骤 设计介绍参考仓库 前言 系统基于mybatis-plus, springboot环境 对于重要的一些数据,我们需要记录一条记录的所有版本变化过程,做到持续追踪,为后续问题追踪提供思路。下面展示预期效果…...

平衡二叉树,二叉树的路径,左叶子之和
第六章 二叉树part04 今日内容: 110.平衡二叉树 257. 二叉树的所有路径 404.左叶子之和 110.平衡二叉树 (优先掌握递归) 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为&am…...

Sodinokibi勒索病毒最新变种,解密工具更新到2.0版本
Sodinokibi勒索病毒 Sodinokibi勒索病毒又称REvil,自从2019年6月1日,GandCrab勒索病毒运营团伙宣布停止运营之后,Sodinokibi勒索病毒马上接管了GandCrab的大部分传播渠道,同时它也被称为是GandCrab勒索病毒的“接班人”ÿ…...

css 鼠标移入放大的效果
效果 HTML <div class"img-wrap"><img class"img-item" src"../assets/1.png" alt"" srcset""></div> CSS <style lang"less" scoped> .img-wrap {/* 超出隐藏 */overflow: hidden;.img-…...
Transformer模型分布式并行通信量浅析
1.数据并行DP(朴素数据并行,Zero数据并行之后补充) O ( h 2 ∗ l ) O(h^2*l) O(h2∗l) 每台机器做完自己的梯度后需要做一次All reduce操作来累积梯度,故一个batch计算发送的数据量为每层梯度大小 h 2 h^2 h2乘以层数 l l l 优点…...

PMP考试之20240304
1.一家食品公司正在使用预测型方法开发一种新产品,该产品目前正处于测试阶段。鉴于测试反馈的性质,项目经理决定使用迭代方法。在其中一个迭代结束时,颁布了与该产品有关的新法规。项目经理接下来应该做什么? A.就项目的范围提出…...

智慧城市中的公共服务创新:让城市生活更便捷
目录 一、引言 二、智慧城市公共服务创新的实践 1、智慧交通系统 2、智慧医疗服务 3、智慧教育系统 4、智慧能源管理 三、智慧城市公共服务创新的挑战 四、智慧城市公共服务创新的前景 五、结论 一、引言 随着信息技术的迅猛发展,智慧城市已成为现代城市发…...
bert 相似度任务训练完整版
任务 之前写了一个相似度任务的版本:bert 相似度任务训练简单版本,faiss 寻找相似 topk-CSDN博客 相似度用的是 0,1,相当于分类任务,现在我们相似度有评分,不再是 0,1 了,分数为 0-5,数字越大…...

Ribbon实现Cloud负载均衡
安装Zookeeper要先安装JDK环境 解压 tar -zxvf /usr/local/develop/jdk-8u191-linux-x64.tar.gz -C /usr/local/develop 配置JAVA_HOME vim /etc/profile export JAVA_HOME/usr/local/develop/jdk1.8.0_191 export PATH$JAVA_HOME/bin:$PATH export CLASSPATH.:$JAVA_HOM…...
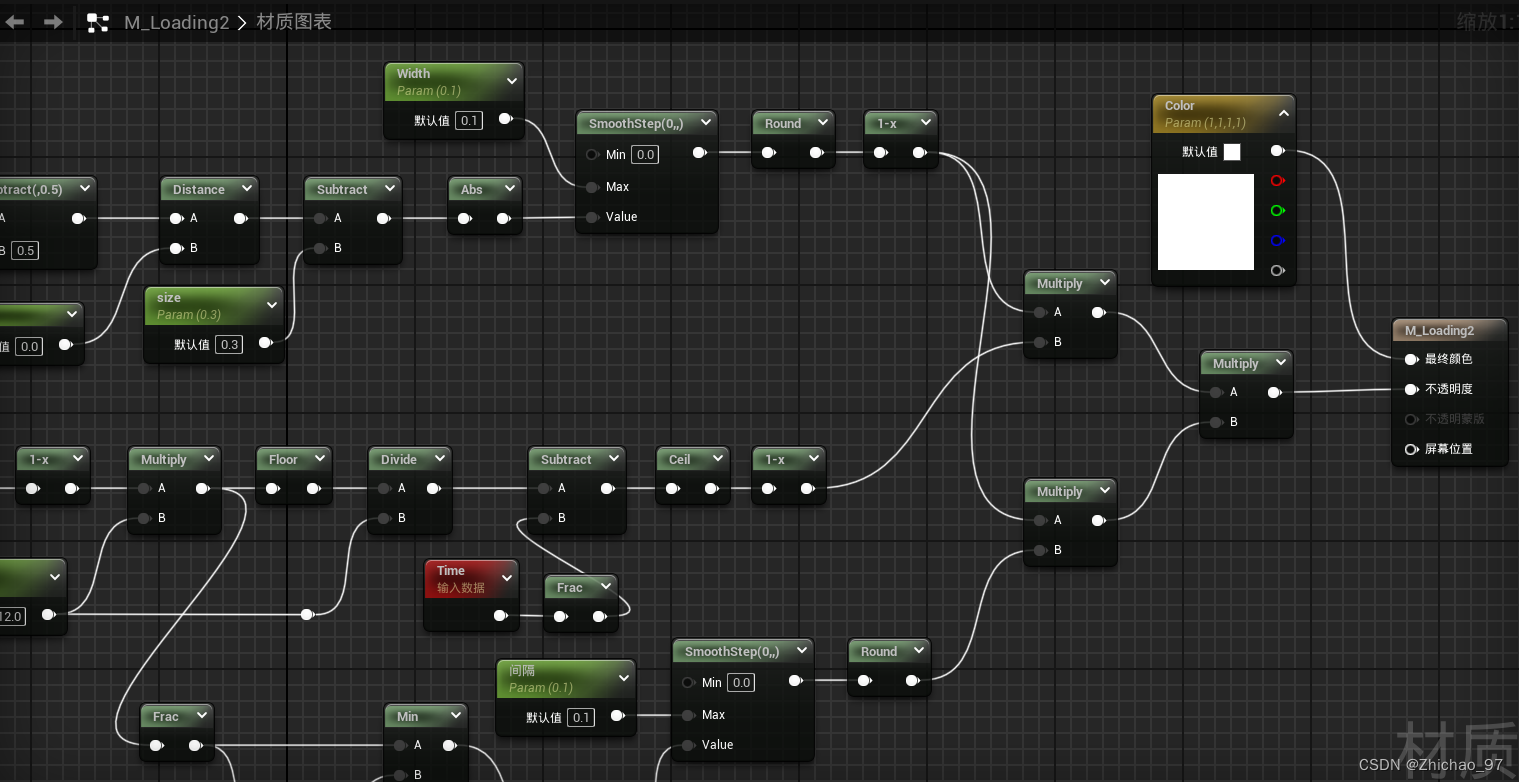
【UE 材质】制作加载图案(2)
在上一篇(【UE 材质】制作加载图案)基础上继续实现如下效果的加载图案 效果 步骤 1. 复制一份上一篇制作的材质并打开 2. 添加“Floor”节点向下取整 除相同的平铺数 此时的效果如下 删除如下节点 通过“Ceil”向上取整,参数“Tiling”默认…...

为啥要用C艹不用C?
在很多时候,有人会有这样的疑问 ——为什么要用C?C相对于C优势是什么? 最近两年一直在做Linux应用,能明显的感受到C带来到帮助以及快感 之前,我在文章里面提到环形队列 C语言,环形队列 环形队列到底是怎么回…...
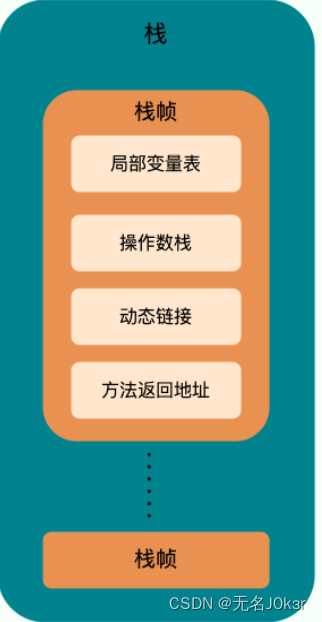
Java:JVM基础
文章目录 参考JVM内存区域程序计数器虚拟机栈本地方法栈堆方法区符号引用与直接引用运行时常量池字符串常量池直接内存 参考 JavaGuide JVM内存区域 程序计数器 程序计数器是一块较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器,各线程…...

JavaSec 基础之五大不安全组件
文章目录 不安全组件(框架)-Shiro&FastJson&Jackson&XStream&Log4jLog4jShiroJacksonFastJsonXStream 不安全组件(框架)-Shiro&FastJson&Jackson&XStream&Log4j Log4j Apache的一个开源项目,是一个基于Java的日志记录框架。 历史…...

python类的属性、方法、静态方法、静态方法类内部的调用、直接调用与实例化调用
设计者:ISDF工软未来 版本:v1.0 日期:2024/3/4 class Restaurant:餐馆类def __init__(self,restaurant_name,cuisine_type):#类的属性self.restaurant_name restaurant_nameself.cuisine_type cuisine_type# self.stregth_level 0def desc…...

haproxy集成国密ssl功能[下]
上接[haproxy集成国密ssl功能上 4. 源码修改解析 以下修改基本围绕haproxy的ssl_sock.c进行修改来展开的,为了将整个实现逻辑能够说明清楚,下述内容有部分可能就是直接摘抄haproxy的原有代码没有做任何修改,而大部分增加或者修改的内容则进行了特别的说明。 4.1 为bind指令…...
C++自学精简实践教程
一、介绍 1.1 教程特点 一篇文章从入门到就业有图有真相,有测试用例,有作业;提供框架代码,作业只需要代码填空规范开发习惯,培养设计能力 1.2 参考书 唯一参考书《C Primer 第5版》参考书下载: 蓝奏云…...

每日一题——LeetCode1572.矩阵对角线元素的和
方法一 遍历矩阵 如果矩阵中某个位置(x,y)处于对角线上,那么这个位置必定满足: xy 或 xy len-1 (len为矩阵长度) var diagonalSum function(mat) {let len mat.length;let sum 0;for (let i 0; i …...

C#基于TCP通信协议的实现示例
1. 客户端代码(TCpClient/Program.cs)该代码实现了一个基础的 TCP 客户端程序,核心逻辑是与指定 IP 和端口的 TCP 服务器建立连接,向服务器发送控制台输入的字符串数据,并接收服务器的响应数据,最后释放连接…...

Keil ULINK强制全片擦除与CRC校验实践
1. 问题现象与背景解析当使用Keil开发环境配合ULINK调试器对英飞凌C166系列微控制器进行程序烧录时,部分工程师会遇到一个看似奇怪的现象:明明在代码中设置了全片CRC校验逻辑,但实际运行时却出现校验失败。经过排查发现,ULINK默认…...

保险精算AutoML实战:超参数优化与集成学习提升模型效率
1. 项目概述:当AutoML遇上保险精算在保险行业干了十几年,我亲眼见证了精算师们从抱着厚重的费率手册和GLM(广义线性模型)公式,到如今开始尝试用Python脚本跑几个机器学习模型。但一个普遍的现象是:很多精算…...

AI Agent记忆方案大比拼:RAG、Mem0、Zep、Letta怎么选?告别选型迷茫!
本文综述了多种AI Agent记忆方案,包括RAG、Mem0、Zep、Letta、LangMem等,并分析了它们各自的适用场景和优缺点。文章指出,选择合适的记忆方案需要根据具体应用场景来确定,如RAG适合知识库检索,Mem0适合跨会话个性化&am…...
Spark Transformer:稀疏激活优化与计算效率提升
1. Spark Transformer 核心设计解析Transformer架构在自然语言处理领域展现出卓越性能,但其计算密集型特性也带来了显著的资源消耗。传统Transformer模型的前馈网络(FFN)和注意力机制采用全连接计算模式,导致FLOPs(浮点运算次数)居高不下。Spark Transfo…...

统信UOS/麒麟KOS截图快捷键失灵?别慌,试试这个后台进程清理大法
统信UOS/麒麟KOS截图快捷键失灵?三步精准定位僵尸进程早上9点,你正急着截取屏幕上的报错信息发给技术同事,却发现按下CtrlAltA后毫无反应——这不是个例。国内主流操作系统如统信UOS、麒麟KOS的用户常会遇到这类"幽灵故障"…...

Dingo-BNS:基于神经后验估计的亚秒级引力波参数推断框架
1. 项目概述:当引力波遇见神经网络引力波天文学正处在一个激动人心的时代。自2015年首次直接探测到引力波以来,我们不仅“听”到了黑洞并合的宇宙巨响,也捕捉到了双中子星并合产生的时空涟漪,开启了多信使天文学的新纪元。然而&am…...

AI赋能工程教育:构建个性化、多元化与伦理驱动的学习生态
1. 项目概述:当工程教育遇见AI,我们到底在谈论什么?最近几年,AI这个词快被说烂了。从ChatGPT的横空出世,到各类生成式AI工具的遍地开花,似乎每个行业都在讨论如何“被赋能”。工程教育这个领域也不例外&…...

基于RTK-GPS与ResNet50的自主草坪清扫机器人系统设计与实践
1. 项目概述与核心挑战在公园维护的日常工作中,草坪垃圾清理是一项既耗费人力又效率低下的重复性劳动。传统的清扫方式要么依赖人工,要么使用大型、笨重且可能损伤草皮的设备。我们团队的目标,是设计并实现一个能够自主、高效且温和地完成这项…...

根据lab1.pdf总结的知识点
第一题:简单的应用程序(Hello.java)类与主方法:Java程序入口必须是public static void main(String args[]),public表示该方法能被JVM访问,static表示无需创建对象即可调用,void表示无返回值&am…...