获取PDF中的布局信息——如何获取段落
PDF解析是极其复杂的问题。不可能靠一个工具解决全部问题,尤其是五花八门,格式不统一的PDF文件。除非有钞能力。如果没有那就看看可以分为哪些问题。
提取文本内容,提取表格内容,提取图片。我认为这些应该是分开做的事情。python有一些组件,是有专长的。
问题分解以后,最重要的一个事情是,版面分析。怎么确定边界,就是哪一块是什么内容?是正文,还是表格,还是图片?
文本、图片及形状涵盖了常见的PDF元素,本文介绍利用
PyMuPDF提取这些页面元素,及其基本数据结构。本文会提供可运行的代码!
一、技术选型 PyMuPDF
PyMuPDF的Textpage对象提供的extractDICT()和extractRAWDICT()用以获取页面中的所有文本和图片(内容、位置、属性),基本数据结构如下:

看到这里,有分类,有位置信息。
二、代码演示
2.1 安装
pip install PyMuPDF2.2 demo代码
import fitz # PyMuPDFdef extract_text_blocks(pdf_path):# 打开 PDF 文件pdf_document = fitz.open(pdf_path)# 存储文本块和行块信息text_blocks = []line_blocks = []# 遍历 PDF 中的每一页for page_number in range(len(pdf_document)):page = pdf_document.load_page(page_number)# 获取文本块和行块信息blocks = page.get_text("dict")["blocks"]for b in blocks:for l in b["lines"]:line_blocks.append({"line": l["spans"],"bbox": l["bbox"],"height": l["bbox"][3] - l["bbox"][1] # 计算行块的高度})text_blocks.append({"block": b["lines"],"bbox": b["bbox"]})# 关闭 PDF 文件pdf_document.close()return text_blocks, line_blocks# 示例用法
pdf_path = "D:\\angus\\py\\困难pdf节选西藏奇正2022.pdf"
text_blocks, line_blocks = extract_text_blocks(pdf_path)# 打印提取的文本块信息
for index, block in enumerate(text_blocks):print(f"Text Block {index + 1}:")for line_index, line in enumerate(block["block"]):print(f" Line {line_index + 1}: '{line['spans']}' at position {block['bbox']}")# 打印提取的行块信息
for index, line in enumerate(line_blocks):print(f"Line {index + 1}: '{line['line']}' at position {line['bbox']}, height={line['height']}")
三、效果展示
3.1 原文PDF内容

3.2 解析后得到的结果

3.3 分析原文和结果
对比输出的结果和原文。我们可以发现,我们拿到了行的数据,也拿到了段落的数据。上述的代码中已经给我们分好了块!这样解可以区分段落了。
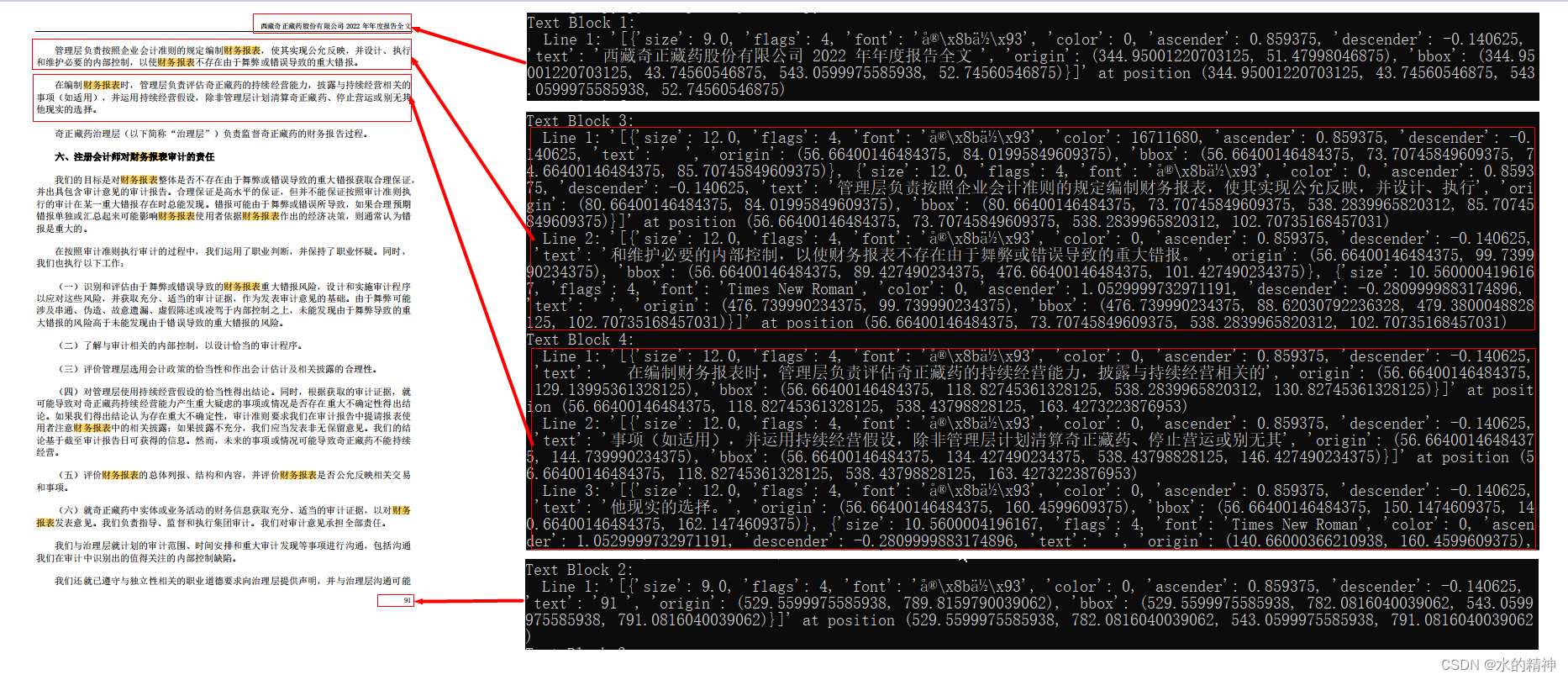
3.4 获取更多信息,包括位置

来看一个文本块:
size: 文本的大小。flags: 文本的标志。font: 字体名称。color: 字体颜色。ascender: 文本的上升高度。descender: 文本的下降高度。text: 文本内容。origin: 文本的起始位置坐标。bbox: 文本的边界框坐标,即左下角和右上角的坐标。
通过这些信息,我们可以获取到每个文本块的具体内容、大小、位置和格式等信息。这些信息对于分析和处理 PDF 文件中的文本内容非常有用。例如,你可以根据文本的大小、位置和格式来识别标题、正文和其他内容,并进行相应的处理和分析。当然,就以这个文档为例,我们可以看到的是,因为文档本身字体大小都一样,所以很难根据字体和大小获取到标题。
四、错误问题
但是也发现了问题
4.1 段落有被分开了
原文

错误的问题如下

4.2 将表格错当成了文本内容
原文表格内容如下

解析得到的内容如下
表格的一行为一个块内容,

这里调试了一版,可以去掉表格。
逻辑是:判断相邻的block,表格的特征是,当个block内的 lines的 bbox的第四位是相同的。且相邻的block的lines一定是相同的,且lines不为空。逻辑本身没有问题,就怕PDF有问题,识别出来的表格的同一行的bbox中的第四位不一样,这样会错误判断!
import fitz # PyMuPDFdef is_table_block(b1, b2):# 检查连续相邻的文本块是否具有相同的行数,并且其 bbox 的高度也相同if len(b1["lines"]) == len(b2["lines"]) and b1["bbox"][3] - b1["bbox"][1] == b2["bbox"][3] - b2["bbox"][1]:return Truereturn Falsedef extract_text_blocks(pdf_path):# 打开 PDF 文件pdf_document = fitz.open(pdf_path)# 存储文本块信息text_blocks = []line_blocks = []# 遍历 PDF 中的每一页for page_number in range(len(pdf_document)):page = pdf_document.load_page(page_number)# 获取文本块和行块信息blocks = page.get_text("dict")["blocks"]for i in range(len(blocks)):if i < len(blocks) - 1 and is_table_block(blocks[i], blocks[i+1]): # 如果是表格,则跳过continuefor l in blocks[i]["lines"]:line_blocks.append({"line": l["spans"],"bbox": l["bbox"],"height": l["bbox"][3] - l["bbox"][1] # 计算行块的高度})text_blocks.append({"block": blocks[i]["lines"],"bbox": blocks[i]["bbox"]})# 关闭 PDF 文件pdf_document.close()return text_blocks, line_blocks# 示例用法
pdf_path = "D:\\angus\\py\\困难pdf节选西藏奇正2022.pdf"
text_blocks, line_blocks = extract_text_blocks(pdf_path)# 打印提取的文本块信息
# 用于检查两个文本块中的行是否相同
def check_lines_same(block1, block2):num_lines_block1 = len(block1["block"])num_lines_block2 = len(block2["block"])return num_lines_block1 == num_lines_block2for index, block in enumerate(text_blocks):# 获取当前文本块中行的个数num_lines = len(block["block"])# 如果当前文本块是表格,则继续检查下一个文本块是否是表格if num_lines > 1 and index < len(text_blocks) - 1: # 需要多于一行,并且不是最后一个文本块next_block = text_blocks[index + 1]if check_lines_same(block, next_block):# 如果下一个文本块也是表格,则跳过,不进行打印输出continue# 如果当前文本块不是表格,则打印输出print(f"Text Block {index + 1}:")for line_index, line in enumerate(block["block"]):print(f" Line {line_index + 1}: '{line['spans']}' at position {block['bbox']}")# 打印提取的行块信息
# for index, line in enumerate(line_blocks):
# print(f"Line {index + 1}: '{line['line']}' at position {line['bbox']}, height={line['height']}")
4.3 解析丢失整行数据
测试了另外一个法律法规文件。
发现文件丢失了。原文件内容如下:

解析后的:
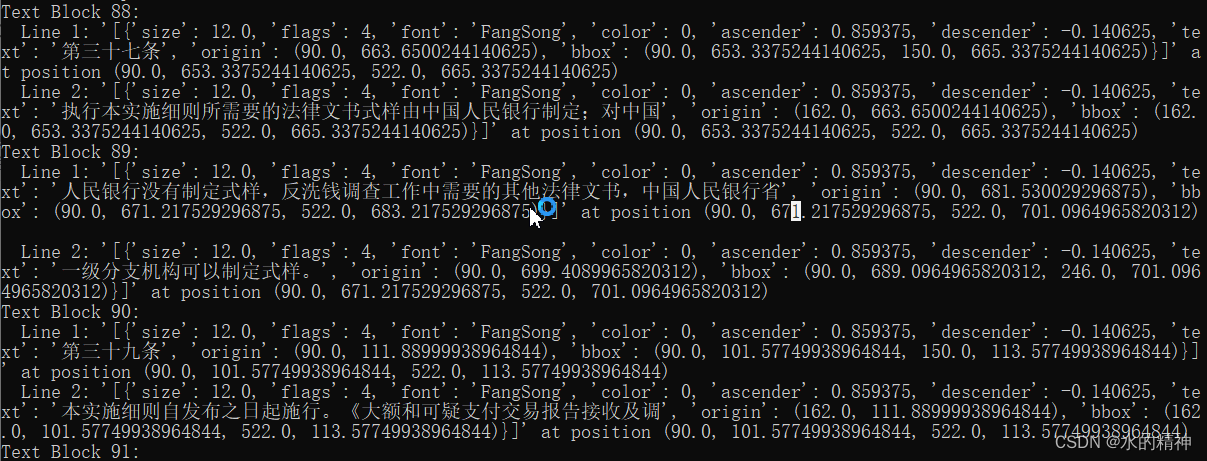
还没找到bug的原因。
五、升级版
解决了丢行的问题,因为代码bug,在判断表格的时候有问题。
解决了段落被分开的问题。解决思路是,判断两个段落之间,应该有空白分隔。如果两个块之间没有空白分隔,则为同一个段。
并将内容输出为json格式
import fitz # PyMuPDF
import jsondef is_table_block(b1, b2):# 检查连续相邻的文本块是否具有相同的行数,并且其 bbox 的高度也相同if len(b1["lines"]) == len(b2["lines"]) and b1["bbox"][3] - b1["bbox"][1] == b2["bbox"][3] - b2["bbox"][1]:return Truereturn Falsedef extract_text_blocks(pdf_path):# 打开 PDF 文件pdf_document = fitz.open(pdf_path)# 存储文本块信息text_blocks = []line_blocks = []# 遍历 PDF 中的每一页for page_number in range(len(pdf_document)):page = pdf_document.load_page(page_number)# 获取文本块和行块信息blocks = page.get_text("dict")["blocks"]# 对当前页面内的文本块按照坐标进行排序blocks.sort(key=lambda x: (x['bbox'][3], x['bbox'][0]))for i in range(len(blocks)):for l in blocks[i]["lines"]:line_blocks.append({"line": l["spans"],"bbox": l["bbox"],"height": l["bbox"][3] - l["bbox"][1], # 计算行块的高度"page_number": page_number + 1 # 记录页码信息})text_blocks.append({"block": blocks[i]["lines"],"bbox": blocks[i]["bbox"],"page_number": page_number + 1 # 记录页码信息})# 关闭 PDF 文件pdf_document.close()return text_blocks, line_blocksdef is_same_paragraph(line1, line2):# 判断相邻行是否属于同一个段落的逻辑# 这里提供一个简单的示例,你可以根据实际情况调整和扩展# 判断两行之间的垂直间距是否小于某个阈值vertical_threshold = 5 # 垂直间距阈值,根据实际情况调整if abs(line1['bbox'][3] - line2['bbox'][1]) < vertical_threshold:return Truereturn False# 示例用法pdf_path = "D:\\angus\\py\\困难pdf节选西藏奇正2022.pdf"
text_blocks, line_blocks = extract_text_blocks(pdf_path)# 用于检查两个文本块中的行是否相同
def check_lines_same(block1, block2):num_lines_block1 = len(block1["block"])num_lines_block2 = len(block2["block"])return num_lines_block1 == num_lines_block2# 收集打印的 JSON
printed_json_list = []for index, block in enumerate(text_blocks):# 获取当前文本块中行的个数num_lines = len(block["block"])# 如果当前文本块是表格,则继续检查下一个文本块是否是表格if num_lines > 1 and index < len(text_blocks) - 1: # 需要多于一行,并且不是最后一个文本块next_block = text_blocks[index + 1]if check_lines_same(block, next_block):# 如果下一个文本块也是表格,则跳过,不进行打印输出continue# 如果当前文本块不是表格,则添加到打印的 JSON 列表中block_info = {"block_index": index + 1,"page_number": block['page_number'],"lines": [line['spans'] for line in block['block']],"bbox": block['bbox']}print(block_info)printed_json_list.append(block_info)previous_json = None # 用于记录上一个非空 JSONfor printed_json in printed_json_list:# 获取 lines 的最后一个对象last_line_array = printed_json["lines"][-1]# 获取最后一个对象中的最后一个对象last_object_in_last_line = last_line_array[-1]# 获取最后一个对象中的 text 字段的值text_value = last_object_in_last_line["text"]# 输出截取到的最后一个text值#print("text字段的取值为>>>>>>>>>>>>..:", text_value)if text_value.strip() == "":# 如果 text_value 为空,则打印当前 JSONif previous_json is not None:# 合并当前 JSON 到上一个非空 JSON 上previous_json["lines"].extend(printed_json["lines"])previous_json["bbox"] = [min(previous_json["bbox"][0], printed_json["bbox"][0]),min(previous_json["bbox"][1], printed_json["bbox"][1]),max(previous_json["bbox"][2], printed_json["bbox"][2]),max(previous_json["bbox"][3], printed_json["bbox"][3])]# 更新页码信息previous_json["page_number"] = printed_json["page_number"]print(json.dumps(previous_json, ensure_ascii=False))# 重置jsonprevious_json = Noneelse:print(json.dumps(printed_json, ensure_ascii=False)) else:# 如果 text_value 不为空,则合并当前 JSON 到上一个非空 JSON 上if previous_json is not None:# 合并当前 JSON 到上一个非空 JSON 上previous_json["lines"].extend(printed_json["lines"])previous_json["bbox"] = [min(previous_json["bbox"][0], printed_json["bbox"][0]),min(previous_json["bbox"][1], printed_json["bbox"][1]),max(previous_json["bbox"][2], printed_json["bbox"][2]),max(previous_json["bbox"][3], printed_json["bbox"][3])]# 更新页码信息previous_json["page_number"] = printed_json["page_number"]else:# 如果没有上一个非空 JSON,则将当前 JSON 赋值给上一个非空 JSONprevious_json = printed_json相关文章:
获取PDF中的布局信息——如何获取段落
PDF解析是极其复杂的问题。不可能靠一个工具解决全部问题,尤其是五花八门,格式不统一的PDF文件。除非有钞能力。如果没有那就看看可以分为哪些问题。 提取文本内容,提取表格内容,提取图片。我认为这些应该是分开做的事情。python有…...

Laya2.13.3在Web条件下使用键盘控制相机移动
需求:在Laya开发时,常常没法移动相机来观察场内的环境,故制作一个移动相机的脚本来是实现此功能,目前先使用键盘后续会添加鼠标控制移动旋转等功能。 onEnable(){this.camera new Laya.Camera(0, 0.1, 100);this._tempVector3 n…...

centos系统服务器在Jenkins执行playwright UI自动化测试框架
centos系统服务器在Jenkins执行playwright UI自动化测试框架 1. centos7.9系统中安装playwright环境报错 playwright/driver/node: /lib64/libc.so.6: version `GLIBC_2.25 not found经过查找资料,playwright 仅支持Ubuntu系统,其他的Linux服务器系统不支持,为此采用docke…...

boost.redis崩溃的解决方法
使用boost.redis的协程一定要co_spawn在strand对象中。 正确的用法: boost::asio::co_spawn(boost::dasio::make_strand(ioc),XXXCoroutine(),boost::asio::detached ); 错误的用法: boost::asio::co_spawn(ioc,XXXCoroutine(),boost::asio::detache…...
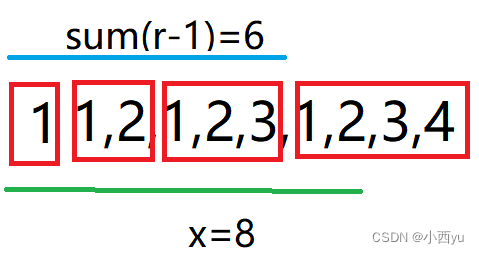
蓝桥杯——123
123 二分等差数列求和前缀和数组 题目分析 连续一段的和我们想到了前缀和,但是这里的l和r的范围为1e12,明显不能用O(n)的时间复杂度去求前缀和。那么我们开始观察序列的特点,可以按照等差数列对序列进行分块。如上图,在求前10个…...
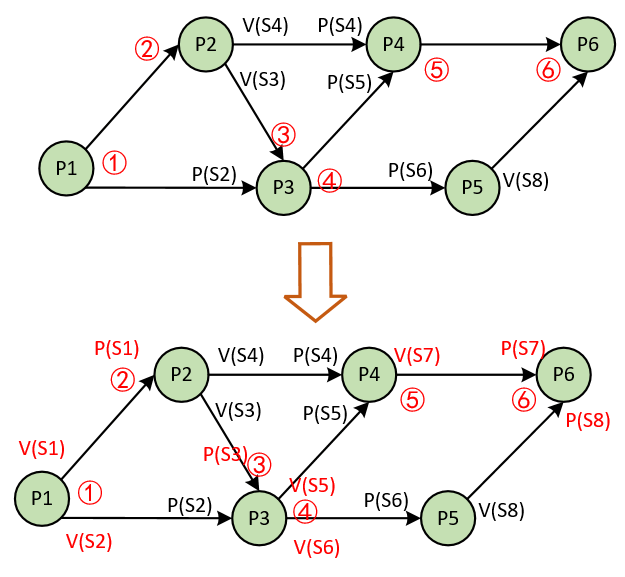
嵌入式基础知识-信号量,PV原语与前趋图
本篇来介绍信号量与PV原语的一些知识,并介绍其在前趋图上的应用分析。本篇的知识属于操作系统部分的通用知识,在嵌入式软件开发中,同样会用到这些知识。 1 信号量 信号量是最早出现的用来解决进程同步与互斥问题的机制(可以把信…...

代码遗产:探索祖传代码的历史、挑战与现代融合艺术
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua,在这里我会分享我的知识和经验。&#x…...
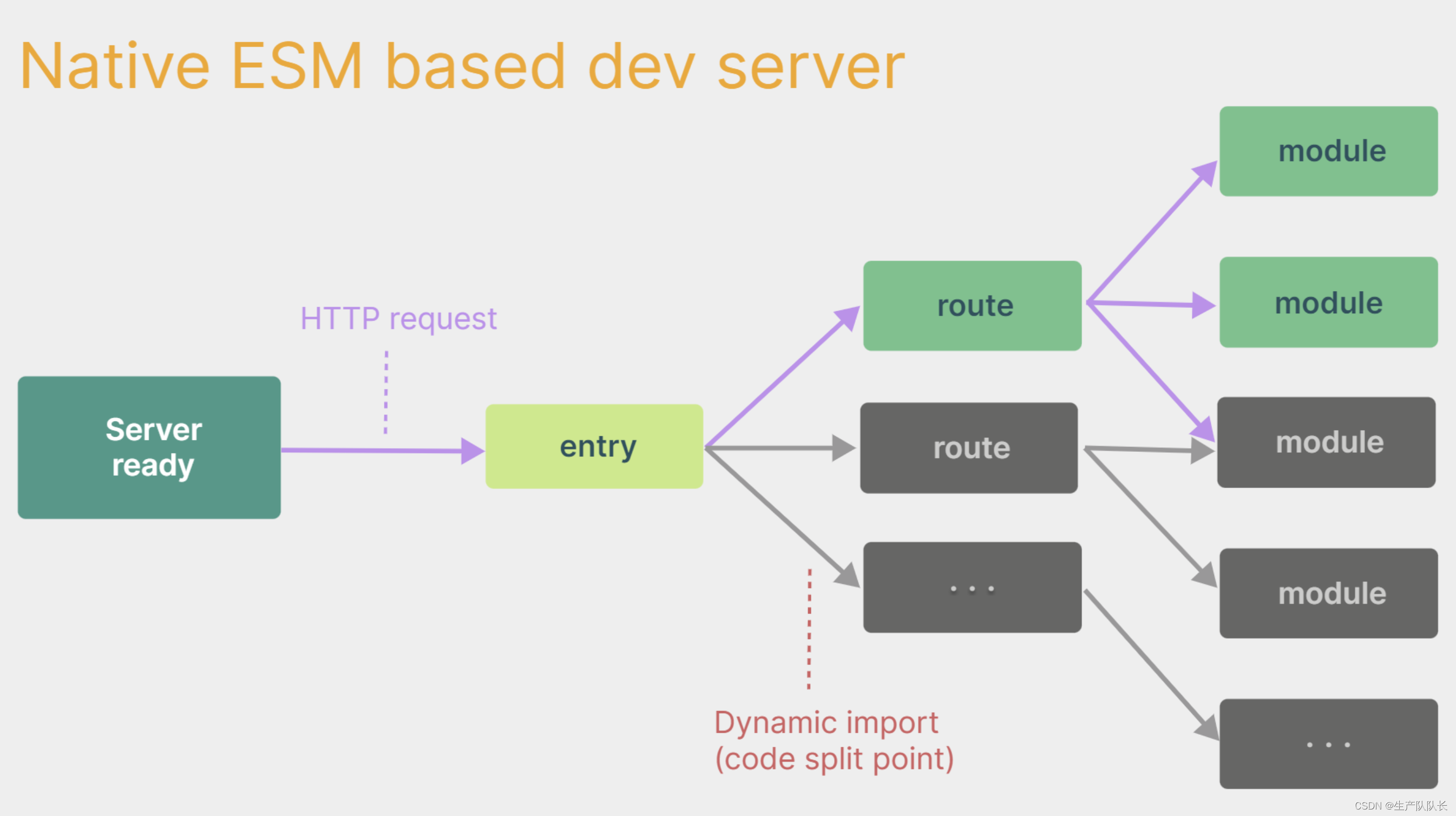
Vue3:用vite创建Vue3项目
一、简介 vite是新一代前端构建工具,官网地址:https://vitejs.cn vite的优势如下: 轻量快速的热重载(HMR),能实现极速的服务启动。对 TypeScript、JSX、CSS 等支持开箱即用。真正的按需编译,不…...
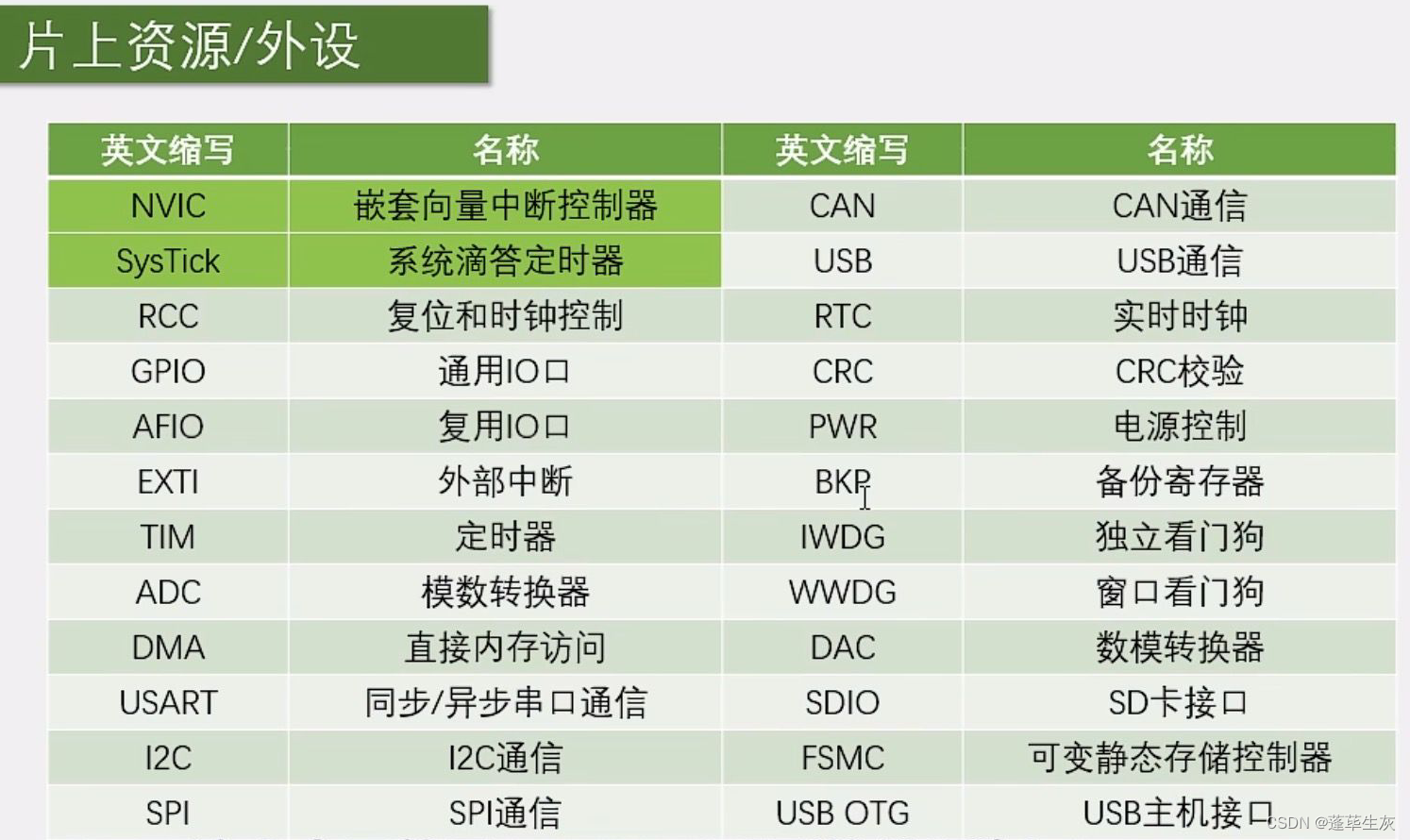
STM32 (2)
1.stm32编程模型 将C语言程序烧录到芯片中会存储在单片机的flsah存储器中,给芯片上电后,Flash中的程序会逐条进入到CPU中去执行,进而CPU去控制各种模块(即外设)去实现各种功能。 2.寄存器和寄存器编程 CPU通过控制其…...

docker部署nginx+反向代理配置/代理宿主机网段服务器
1、安装docker,并运行 2、拉取nginx镜像 docker pull nginx3、运行nginx容器,将文件拷贝至本地,并将nginx容器删除 #运行nginx容器 docker run -id --name mynginx -p 8080:80 nginx#将配置文件从容器内拷贝至本地 docker cp 容器ID:/et…...
初识Hive
官网地址为: Design - Apache Hive - Apache Software Foundation 一、架构 先来看下官网给的图: 图上显示了Hive的主要组件及其与Hadoop的交互。Hive的主要组件有: UI: 用户向系统提交查询和其他操作的用户界面。截至2011年&…...
Google发布Genie硬杠Sora:通过大量无监督视频训练最终生成可交互虚拟世界
前言 Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看似更强大:它生成的虚拟世界自主可控 第一部分 首个基础世界模型Genie 1.1 Genie是什么 Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first gener…...
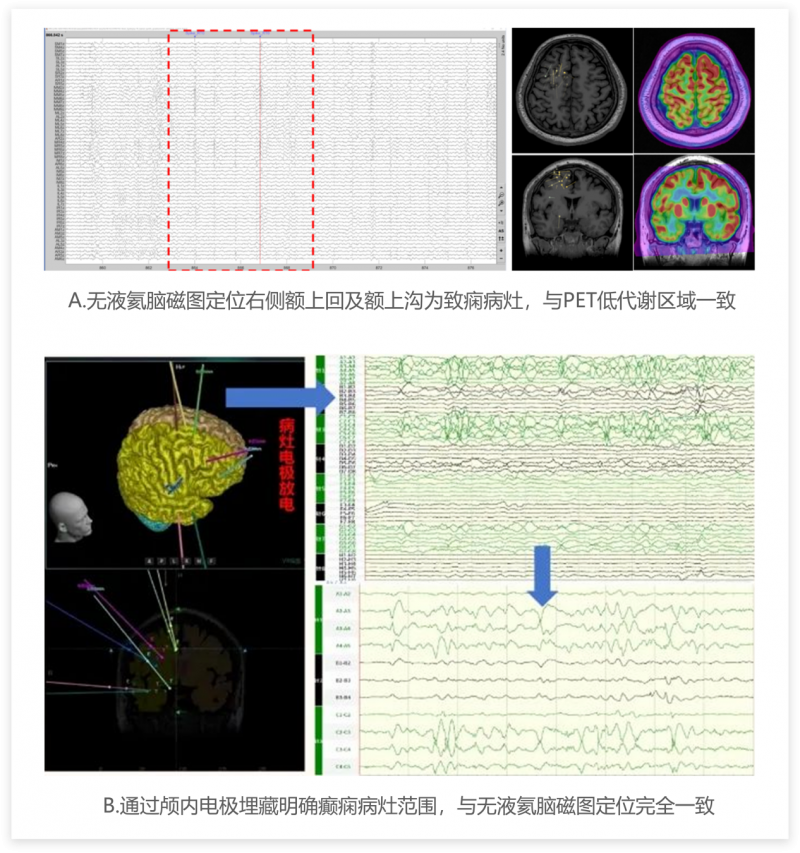
全球首台!未磁科技256通道无液氦脑磁图仪及芯片化原子磁力计正式发布
2024年2月3日,由北京未磁科技有限公司牵头的国家重点研发计划诊疗装备与生物医用材料重点专项“新型无液氦脑磁图系统研发”项目2023年度总结会暨2024年推进会顺利召开。会上发布了项目取得的重大成果——全球首台256通道无液氦脑磁图仪Marvel MEG Pro。此项重磅成果…...
配置)
openssl3.2 - exp - 内存操作(建立,写入,读取)配置
文章目录 openssl3.2 - exp - 内存操作(建立,写入,读取)配置概述笔记调试细节运行效果测试工程实现main.cppCMyOsslConfig.hCMyOsslConfig.cppEND openssl3.2 - exp - 内存操作(建立,写入,读取)配置 概述 我的应用的配置文件是落地加密的, 无法直接用openssl配置接口载入读取…...

前端食堂技术周刊第 114 期:Interop 2024、TS 5.4 RC、2 月登陆浏览器的新功能、JSR、AI SDK 3.0
美味值:🌟🌟🌟🌟🌟 口味:凉拌鸡架 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先来看下…...
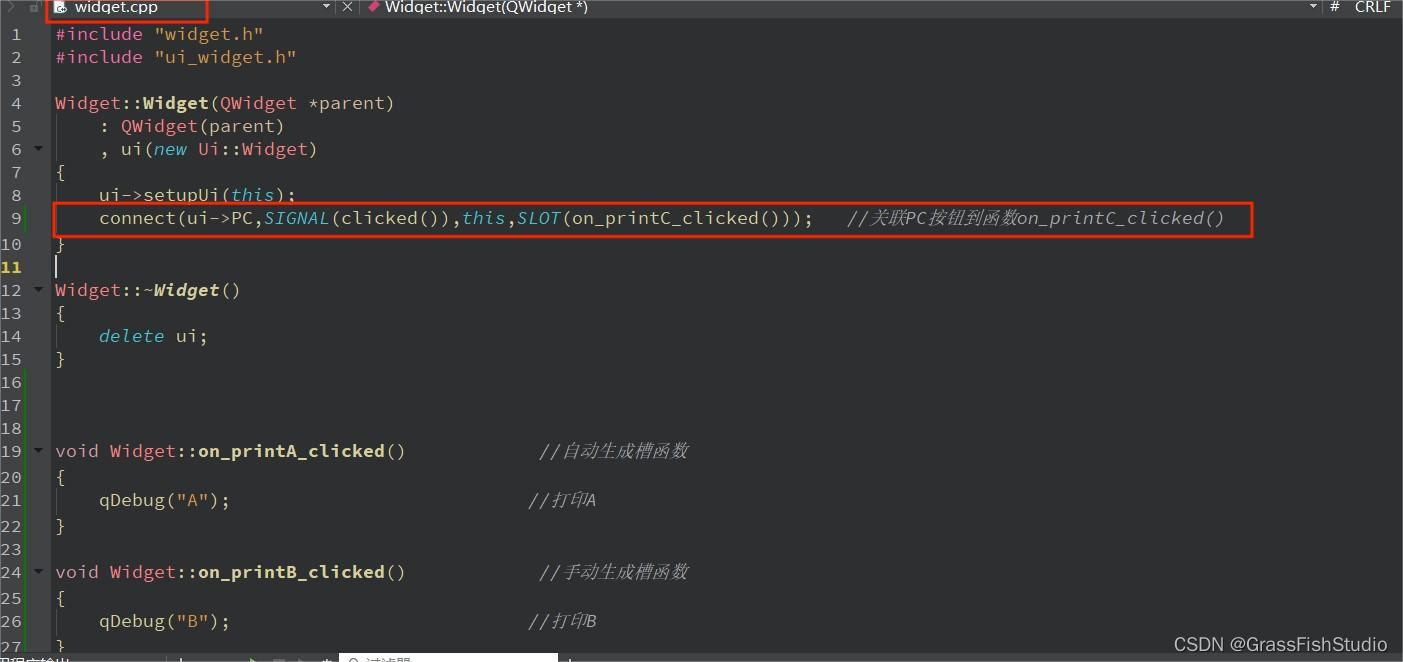
#QT(信号与槽)
1.IDE:QTCreator 2.实验:自动添加槽函数,手动添加槽函数 3.记录 (1)自动添加 a.拖拽widget.ui,放置push-button组件,并且自动生成槽函数 b.发现widget.cpp和widget.h中出现添加的槽函数,注意w…...

go 设置滚动日志
方案 通过 log/slog 实现结构化日志生成,这是go1.21中推出的新特性;通过 lumberjack 实现日志文件分割。 示例 package mainimport ("gopkg.in/natefinch/lumberjack.v2""log/slog""os""path/filepath" )fun…...

Rollup入门学习:前端开发的构建利器
在前端开发领域,构建工具对于优化项目结构和提升代码效率扮演着至关重要的角色。Rollup作为一款轻量级且功能强大的JavaScript模块打包器,近年来备受开发者青睐。本文将带你走进Rollup的世界,帮助你快速入门并掌握其核心用法。 一、Rollup简介…...
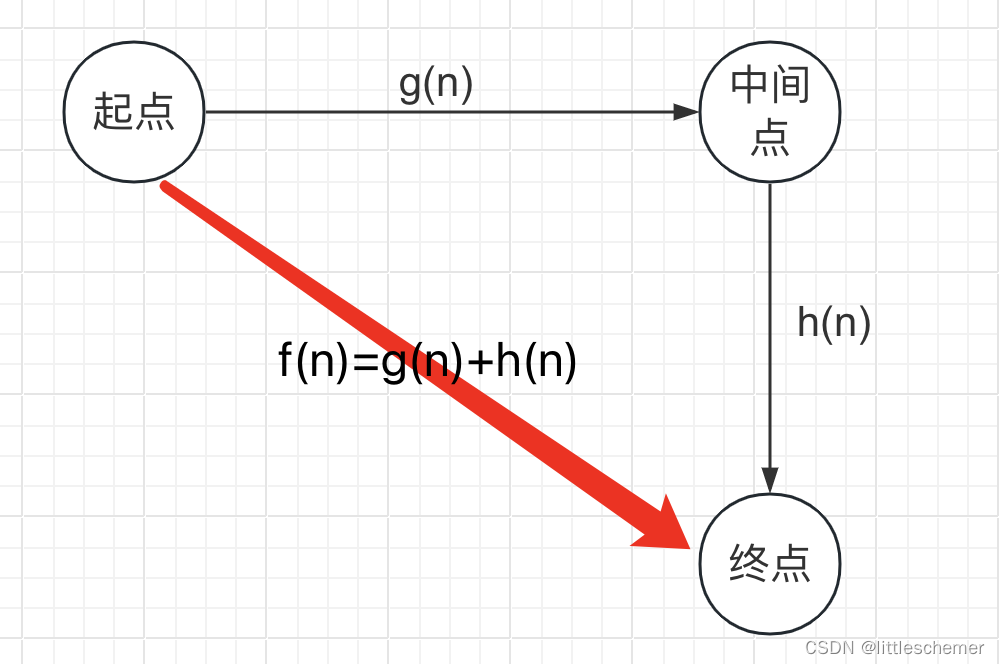
游戏寻路之A*算法(GUI演示)
一、A*算法介绍 A*算法是一种路径搜索算法,用于在图形网络中找到最短路径。它结合了Dijkstra算法和启发式搜索的思想,通过综合利用已知的最短路径和估计的最短路径来优化搜索过程。在游戏自动寻路得到广泛应用。 二、A*算法的基本思想 在图形网络中选择一个起点和终点。维护…...

软件工程顶会——ICSE '24 论文清单、摘要
1、A Comprehensive Study of Learning-based Android Malware Detectors under Challenging Environments 近年来,学习型Android恶意软件检测器不断增多。这些检测器可以分为三种类型:基于字符串、基于图像和基于图形。它们大多在理想情况下取得了良好的…...

精准监测,畅行无阻——DX-SZ3200系列在交通领域的应用
在铁路、高速及各类交通系统中,信号监测与管理的精准性和实时性至关重要。DX-SZ3200系列数字化射频实时频谱侦测接收机模块,凭借其卓越的性能和广泛的应用场景,成为了交通领域信号监测的得力助手。DX-SZ3200系列模块集成了先进的数字化射频接…...
)
摆脱论文困扰!高效论文写作全流程AI论文工具推荐(2026 最新)
论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,2026年AI论文工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖免费/付费、通用/垂直场景。一…...

【204期】异地组网一键联机工具
想和朋友异地联机打单机游戏,结果发现没有公网IP连不上?或者居家办公想访问公司局域网里的文件,搞了半天搞不定?今天聊的这类异地组网、内网穿透工具,就是专门解决这些问题的。它能把一个个单独的局域网连接起来&#…...

Unity URP中_Material Stencil属性报错的四层根因与修复
1. 这个报错不是材质没写对,而是渲染管线在“敲门问权限” 刚在Unity 2021.3 LTS项目里切完URP(Universal Render Pipeline)后打包iOS,突然弹出一行红字: Material xxx doesnt have _Stencil property 。我第一反应是…...

如何快速掌握ElegantBook:面向初学者的LaTeX书籍排版终极指南
如何快速掌握ElegantBook:面向初学者的LaTeX书籍排版终极指南 【免费下载链接】ElegantBook Elegant LaTeX Template for Books 项目地址: https://gitcode.com/gh_mirrors/el/ElegantBook ElegantBook是一款专为学术书籍排版设计的优雅LaTeX模板,…...

AI 自动剪辑不是‘一键成片’:90% 的技术团队踩在逻辑断层与工程适配陷阱里
当团队首次将「AI 自动剪辑」纳入短视频生产管线时,最典型的误判是把它当作一个黑盒触发器:导入原始素材 → 点击「智能剪辑」→ 导出成品。这种认知忽略了背后三重断裂——语音转写与气口检测的精度断层、镜头语义理解与叙事逻辑的错位、以及单机操作与…...

从Halcon助手到你的程序:手把手教你将HSmartWindow中的ROI区域‘抠’出来并用起来
从Halcon助手到C#程序:ROI区域的高效迁移与应用实战 在工业视觉开发中,ROI(Region of Interest)的交互式调整是核心痛点之一。许多开发者习惯在Halcon助手中反复调试ROI参数,却苦于无法将这些精心调整的区域无缝迁移到…...

别再傻等串口了!用STM32CubeMX+DMA实现串口收发,CPU效率直接拉满
STM32CubeMXDMA串口通信:释放CPU性能的实战指南 在嵌入式系统开发中,串口通信是最基础也最常用的外设之一。然而,传统的轮询或中断方式处理串口数据会大量占用CPU资源,这在需要同时处理电机控制、传感器数据融合等多任务的复杂系统…...

GD25Q64EWIGR、2.7-3.6V宽压供电的专业级串行闪存
内容介绍 今天我要向大家介绍的是 GigaDevice 的一款串行闪存——GD25Q64EWIGR。它能稳定提供 64M-bit(8MB)的海量存储,同时支持标准、双路和四路 SPI 高速读写,四路 I/O 数据传输速度最高可达 532Mbit/s。更难能可贵的是&…...

3步快速掌握AKShare:零基础获取金融数据的完整指南
3步快速掌握AKShare:零基础获取金融数据的完整指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/aksha…...