初识Hive
官网地址为:
Design - Apache Hive - Apache Software Foundation
一、架构
先来看下官网给的图:
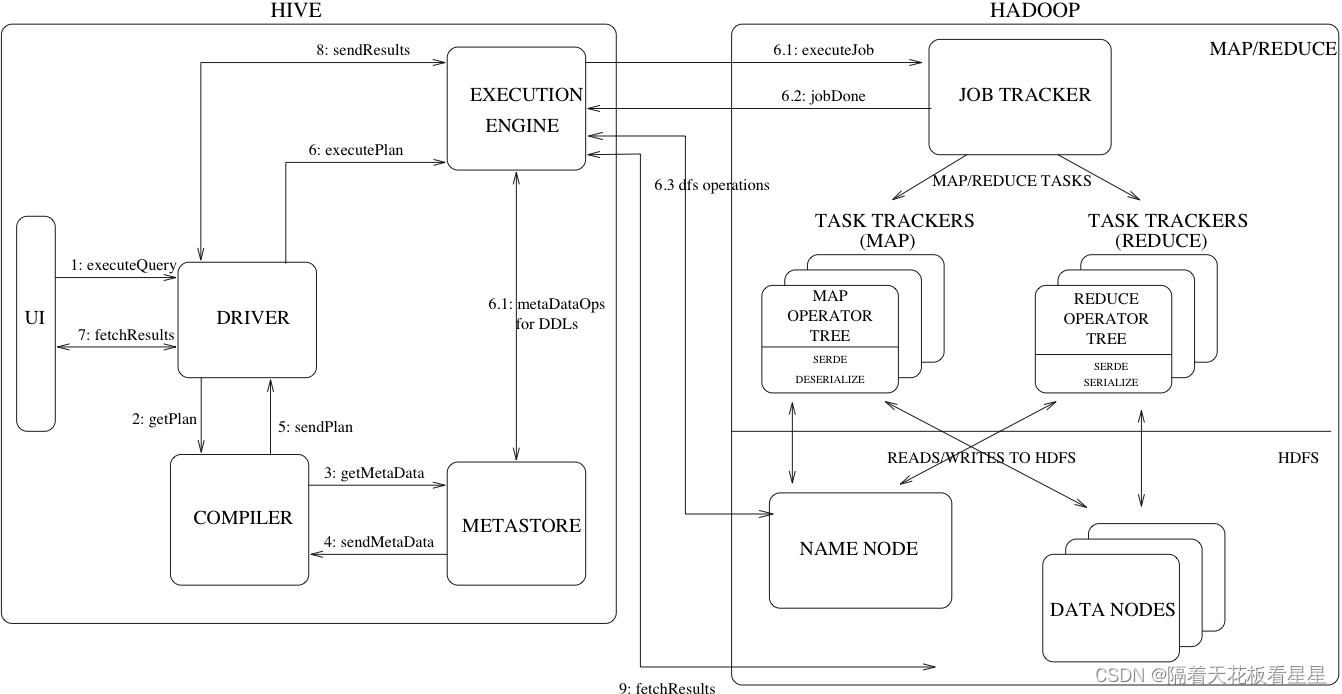
图上显示了Hive的主要组件及其与Hadoop的交互。Hive的主要组件有:
UI:
用户向系统提交查询和其他操作的用户界面。截至2011年,该系统具有命令行界面,并且正在开发基于web的GUI。
Driver:
驱动程序,接收查询的组件。该组件实现了会话句柄的概念,并提供了基于JDBC/ODBC接口建模的执行和获取API。
Compiler:
编译器, 该组件解析查询,对不同的查询块和查询表达式进行语义分析,并最终借助从元存储中查找的表和分区元数据生成执行计划。
Metastore:
元数据存储,存储仓库中各种表和分区的所有结构信息的组件,包括列和列类型信息、读写数据所需的序列化程序和反序列化程序以及存储数据的相应HDFS文件。
Execution Engine:
执行引擎,执行编译器创建的执行计划的组件。该计划是一个分阶段的DAG。执行引擎管理计划的这些不同阶段之间的依赖关系,并在适当的系统组件上执行这些阶段。
此外图中还展示了一个典型的查询是如何在系统中流动的,
1、UI调用驱动程序的执行接口
2、驱动程序为查询创建会话句柄,并将查询发送给编译器以生成执行计划
3、4、编译器从元存储中获取必要的元数据
5、利用元数据对查询树中的表达式进行类型检查,并根据查询谓词修剪分区。编译器生成计划,计划是阶段的DAG,每个阶段要么是Map/Reduce作业,要么是元数据操作,要么是HDFS上的操作。对于Map/Reduce阶段,计划包含map运算符树(在MapTask上执行的运算符树)和reduce运算符树(用于需要ReduceTask的操作)。
6、6.1、6.2、6.3:执行引擎将这些阶段提交给适当的组件,如果是元数据操作(DDL)就直接提交给元数据,如果是数据操作(DML)就解析成任务提交给Hadoop,当然也可以输入命令直接操作HDFS上的数据
在每个任务 (mapper/reducer) 中,与表或中间输出相关联的解串器用于从HDFS文件中读取行,并且这些行通过相关联的运算符树传递。一旦生成输出,就会通过序列化程序将其写入临时HDFS文件(如果操作不需要reduce,则会在map中发生这种情况)。临时文件用于为计划的后续映射/还原阶段提供数据。对于DML操作,最终的临时文件将移动到表的位置。此方案用于确保不读取脏数据(文件重命名是HDFS中的原子操作)。
7、8、9:对于查询,执行引擎直接从HDFS读取临时文件的内容,作为来自驱动程序的获取调用的一部分
二、数据模型
Hive中的数据被组织为:
Tables(表):
这些类似于关系数据库中的表。表可以进行筛选、投影、联接和联合。此外,表的所有数据都存储在HDFS中的一个目录中。Hive还支持外部表的概念,其中可以通过向表创建DDL提供适当的位置,在HDFS中预先存在的文件或目录上创建表。表中的行被组织成类型列,类似于关系数据库。
Partitions(分区):
每个表可以有一个或多个分区键,用于确定数据的存储方式,例如,具有日期分区列dt的表T具有存储在HDFS中的<Table location>/dt=<date>目录中的特定日期的数据文件。分区允许系统根据查询谓词修剪要检查的数据,例如,对T中满足谓词T的行感兴趣的查询。dt=“2008-09-01”只需查看HDFS中<table location>/dt=2008-09-01/目录中的文件。
Buckets(桶):
每个分区中的数据又可以基于表中的列的哈希被划分为桶。每个bucket都作为一个文件存储在分区目录中。Bucketing允许系统有效地评估依赖于数据样本的查询(这些查询使用表上的sample子句)。
下面我们来创建一个有桶的分区表,并给些示例数据,看看它在HDFS上是怎么存储的
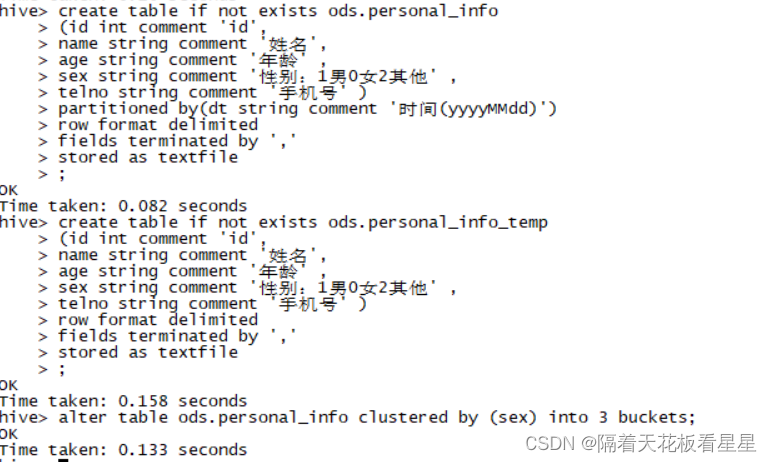
#创建分区表
create table if not exists ods.personal_info
(id int comment 'id',
name string comment '姓名',
age string comment '年龄' ,
sex string comment '性别:1男0女2其他' ,
telno string comment '手机号' )
partitioned by(dt string comment '时间(yyyyMMdd)')
row format delimited
fields terminated by ','
stored as textfile
;
#创建中间表
#因为分桶表不能直接将文件数据load到表中,需要先load到中间表再insert到分桶表
create table if not exists ods.personal_info_temp
(id int comment 'id',
name string comment '姓名',
age string comment '年龄' ,
sex string comment '性别:1男0女2其他' ,
telno string comment '手机号' )
row format delimited
fields terminated by ','
stored as textfile
;
#通过alter table语句将该表设置为有桶的分区表,并指定桶的数量
alter table ods.personal_info clustered by (sex) into 3 buckets;
开始做数据
vi personal_info_test.txt
1,张三,23,1,187xxxx0001
2,王五,56,1,187xxxx0002
3,李四,18,1,187xxxx0003
4,刘七,36,0,187xxxx0004
5,牛八,42,1,187xxxx0005
6,吴九,23,1,187xxxx0006
7,孙十,28,0,187xxxx0007
8,钱十一,29,1,187xxxx0008
9,周十二,30,1,187xxxx0009
10,郑十三,31,1,187xxxx0010
11,冯十四,26,1,187xxxx0011
12,陈十五,23,0,187xxxx0012
13,姜十六,24,1,187xxxx0013
14,韩十七,35,1,187xxxx0014
15,路十八,42,0,187xxxx0015
16,杨十九,38,1,187xxxx0016
17,朱二十,31,1,187xxxx0017
18,秦二十一,27,2,187xxxx0018
19,何二十二,28,2,187xxxx0019
20,金二十三,29,2,187xxxx0010
加载数据到表中
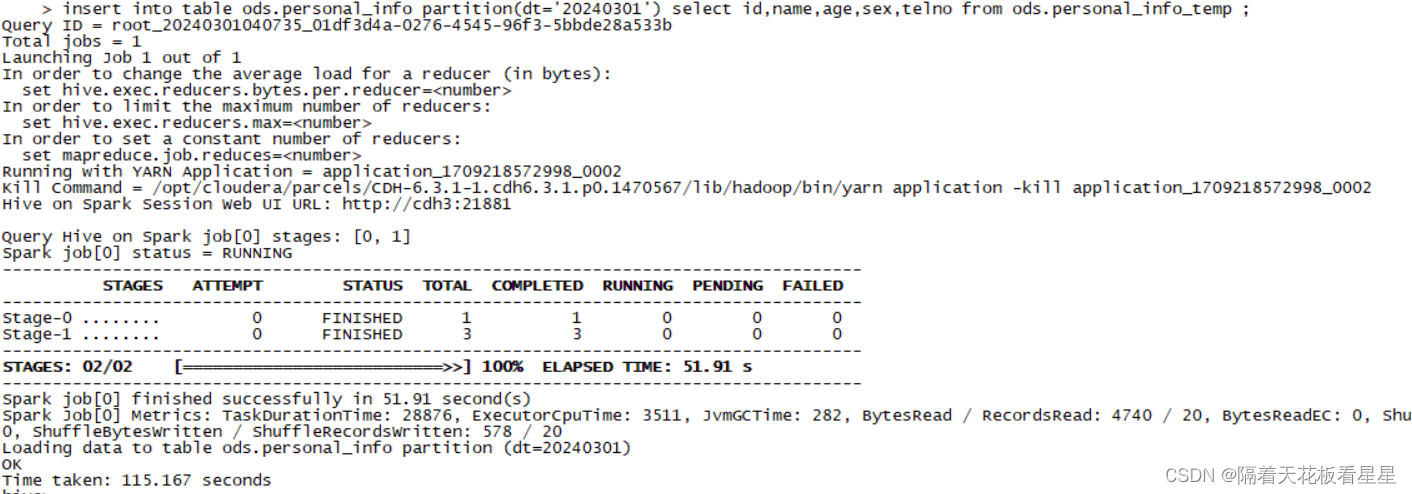
#load数据到中间临时表
load data local inpath '/opt/test/personal_info_test.txt' into table ods.personal_info_temp;
#采用spark引擎
set hive.execution.engine=spark;
#insert数据到目标表
insert into table ods.personal_info partition(dt='20240301') select id,name,age,sex,telno from ods.personal_info_temp ;

下面我们来看看表在HDFS上的存储方式
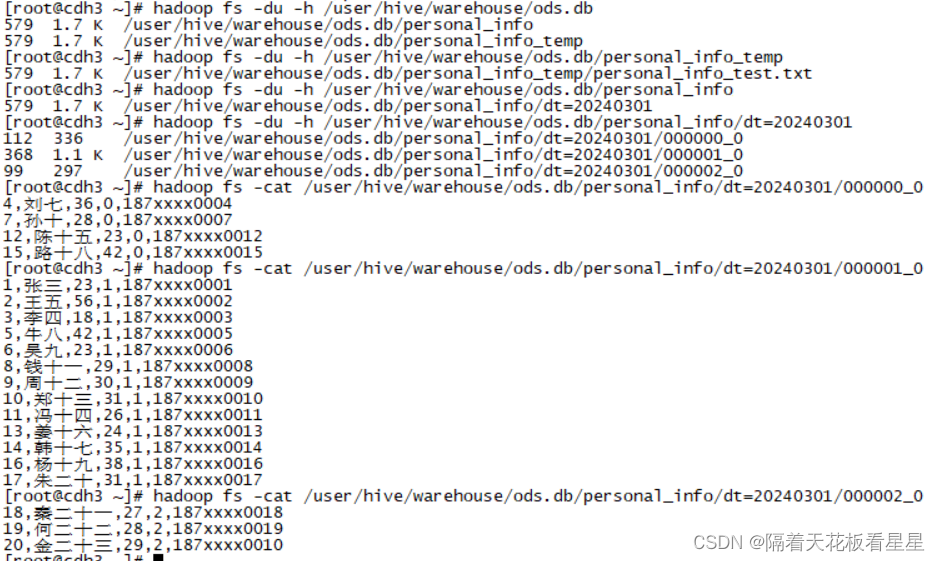
从图中可以看出:
1、关注数据的分区和存储:每个分区实际上对应HDFS下的一个文件夹,这个文件夹中保存了这个分区的数据。再进行查询时可以避免全局扫描,提升性能。而且方便对历史数据进行管理,灵活的按照策略进行删除和备份
2、考虑数据的分布以及查询效率:分桶是将数据划分为若干个存储文件,并规定存储文件的数量,分桶可以将数据分成更小的存储单元,提高了数据统计和聚合的效率。分桶后更容易实现均衡负载。分发到多个节点中,提高了查询效率
除了基元列类型(整数、浮点数、泛型字符串、日期和布尔值)外,Hive还支持 arrays 和 maps 。此外,用户可以通过编程方式从任何基元、集合或其他用户定义的类型中组合自己的类型。类型系统与SerDe(Seralization/Desolialization)和对象检查器接口紧密相连。用户可以通过实现自己的对象检查器来创建自己的类型,并且使用这些对象检查器可以创建自己的SerDes来将数据序列化和反序列化为HDFS文件)。当涉及到理解其他数据格式和更丰富的类型时,这两个接口提供了必要的钩子来扩展Hive的功能。内置对象检查器(如ListObjectInspector、StructObjectInspecter和MapObjectInspect)提供了必要的基元,以便以可扩展的方式组成更丰富的类型。对于maps 和 arrays ,提供了有用的内置函数,如大小和索引运算符。虚线表示法用于导航嵌套类型,例如a.b.c=1查看类型a的字段b的字段c,并将其与1进行比较。
三、元数据存储
1、动机
元数据存储提供了数据仓库的两个重要但经常被忽视的功能:数据抽象和数据发现。如果没有Hive中提供的数据抽象,用户必须在查询的同时提供有关数据格式、提取器和加载器的信息。在配置单元中,这些信息是在创建表的过程中提供的,每次引用表时都会重复使用。这与传统的仓储系统非常相似。第二个功能是数据发现,使用户能够发现和探索仓库中的相关和特定数据。可以使用此元数据构建其他工具,以公开并可能增强有关数据及其可用性的信息。Hive通过提供与Hive查询处理系统紧密集成的元数据存储库来实现这两个功能,从而使数据和元数据同步。
2、元数据对象
数据库:是表的命名空间。当你没有指定数据库时,默认会指向 default
表:表的元数据包含列、所有者、存储和SerDe信息的列表。它还可以包含任何用户提供的键和值数据。存储信息包括基础数据的位置、文件输入和输出格式以及桶信息。SerDe元数据包括序列化器和反序列化器的实现类以及实现所需的任何支持信息。所有这些信息都可以在创建表的过程中提供。
分区:每个分区都可以有自己的列以及SerDe和存储信息。这有助于在不影响旧分区的情况下更改架构
3、元数据存储架构
元存储是具有数据库或文件支持存储的对象存储。数据库支持的存储是使用名为DataNucleus的对象关系映射(ORM)解决方案实现的。将其存储在关系数据库中的主要动机是元数据的可查询性。使用单独的数据存储来存储元数据而不是使用HDFS的一些缺点是同步和可伸缩性问题。此外,由于缺乏对文件的随机更新,因此没有明确的方法在HDFS之上实现对象存储。这一点,再加上关系性存储的可查询性优势,因此选择元数据存储在关系型数据库中。
元数据存储可以配置为以两种方式使用:远程和嵌入式。在远程模式下,元商店是一项节俭服务。此模式对非Java客户端非常有用。在嵌入式模式下,Hive客户端使用JDBC直接连接到底层元存储。这种模式很有用,因为它避免了另一个需要维护和监控的系统。这两种模式可以共存。
4、元数据存储接口
元数据存储提供了一个Thrift接口来操作和查询配置单元元数据。Thrift提供许多流行语言的绑定。第三方工具可以使用此接口将Hive元数据集成到其他业务元数据存储库中。
四、Hive查询语言
HiveQL是Hive的一种类似SQL的查询语言。它主要模仿SQL语法来创建表、将数据加载到表和查询表。HiveQL还允许用户嵌入他们的自定义map reduce脚本。这些脚本可以使用简单的基于行的流式接口以任何语言编写——从标准输入读取行,并将行写入标准输出。这种灵活性是以将行从字符串转换为字符串所造成的性能损失为代价的。然而,我们已经看到,用户并不介意这样做,因为他们可以用自己选择的语言实现脚本。HiveQL独有的另一个功能是多表插入。在此构造中,用户可以使用单个HiveQL查询对同一输入数据执行多个查询。Hive优化了这些查询以共享输入数据的扫描,从而将这些查询的吞吐量提高了几个数量级。
五、编译
1、语法解析器
将查询字符串转换为解析树表示形式
2、语义分析器
将解析树转换为内部查询表示,它仍然是基于块的,而不是运算符树。作为此步骤的一部分,将验证列名,并执行诸如*之类的展开。在此阶段还将执行类型检查和任何隐式类型转换。如果所考虑的表是分区表(这是常见的情况),则会收集该表的所有表达式,以便稍后使用它们来修剪不需要的分区。如果查询已指定采样,则也会收集采样以供以后使用。
3、逻辑计划生成器
将内部查询表示形式转换为逻辑计划,该计划由运算符树组成。有些运算符是关系代数运算符,如“filter”、“join”等。但有些运算符是Hive特定的,稍后用于将此计划转换为一系列MapReduce作业。一个这样的运算符是出现在MapReduce边界处的reduceLink运算符。这一步骤还包括优化器来转换计划以提高性能——其中一些转换包括:将一系列连接转换为单个多路连接,通过执行组的映射侧部分聚合,分两个阶段执行组,以避免在分组密钥存在偏斜数据的情况下,单个reducer 可能成为瓶颈的情况。每个运算符都包括一个描述符,该描述符是一个可串行化的对象
4、查询计划生成器
将逻辑计划转换为一系列MapReduce任务。操作符树被递归遍历,分解为一系列MapReduce可序列化任务,这些任务稍后可以提交到Hadoop分布式文件系统的MapReduce框架。reduceLink操作符是MapReduce边界,其描述符包含reduce键。reduceLink描述符中的缩小键用作贴图缩小边界中的缩小密钥。如果查询指定了该计划,则该计划由所需的样本/分区组成。该计划将被序列化并写入文件。
六、优化器
优化器将执行更多的计划转换。优化器是一个不断发展的组件。截至2011年,它是基于规则的,并执行以下操作:列修剪和谓词下推。然而,基础设施已经到位,包括其他优化(如Map端连接)的工作正在进行中。
优化器可以增强为基于成本的优化。输出表的排序特性也可以保留下来,并在以后用于生成更好的计划。可以对小样本数据进行查询,以猜测数据分布,从而可以用于生成更好的计划。
七、Hive API
提供API可以使自己的应用程序或框架与Hive生态系统集成。
API可以分为两个类别:基于操作的API和基于查询的API。
1、基于查询的API
基于查询的API允许提交和执行HQL的某些子集。API客户端通常需要解析和解释任何返回值,因为返回类型的范围通常非常广泛。此类API的实现通常针对Hive的“查询语言”子系统,该子系统解析查询并根据需要执行查询。考虑到大多数基于查询的API共享类似的执行路径,通过API提交的任何操作都可能具有与通过Hive CLI提交的等效HQL类似的结果。基于查询的API通常用于构建动态创建Hive API操作或HQL等效结果很重要的流程。这种类型的API的缺点包括:缺乏编译时检查,在更高抽象级别上工作可能效率低下,以及可能容易受到类似SQL-injection的攻击。
2、基于操作的API
基于操作的API公开了许多范围严格的方法,每个方法都实现了一个非常特定的配置单元操作。这样的方法通常接受并返回适合于其各自操作的强类型值。操作的实现通常针对Hive内非常特定的层或子系统,因此在使用中可能是高效的。然而,操作的结果可能与等效HQL的结果不同,因为在每种情况下都可能调用不同的代码路径。基于操作的API用于构建需要以重复的、声明性的方式进行交互的进程,并提供更大程度的编译时检查。
相关文章:
初识Hive
官网地址为: Design - Apache Hive - Apache Software Foundation 一、架构 先来看下官网给的图: 图上显示了Hive的主要组件及其与Hadoop的交互。Hive的主要组件有: UI: 用户向系统提交查询和其他操作的用户界面。截至2011年&…...
Google发布Genie硬杠Sora:通过大量无监督视频训练最终生成可交互虚拟世界
前言 Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看似更强大:它生成的虚拟世界自主可控 第一部分 首个基础世界模型Genie 1.1 Genie是什么 Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first gener…...
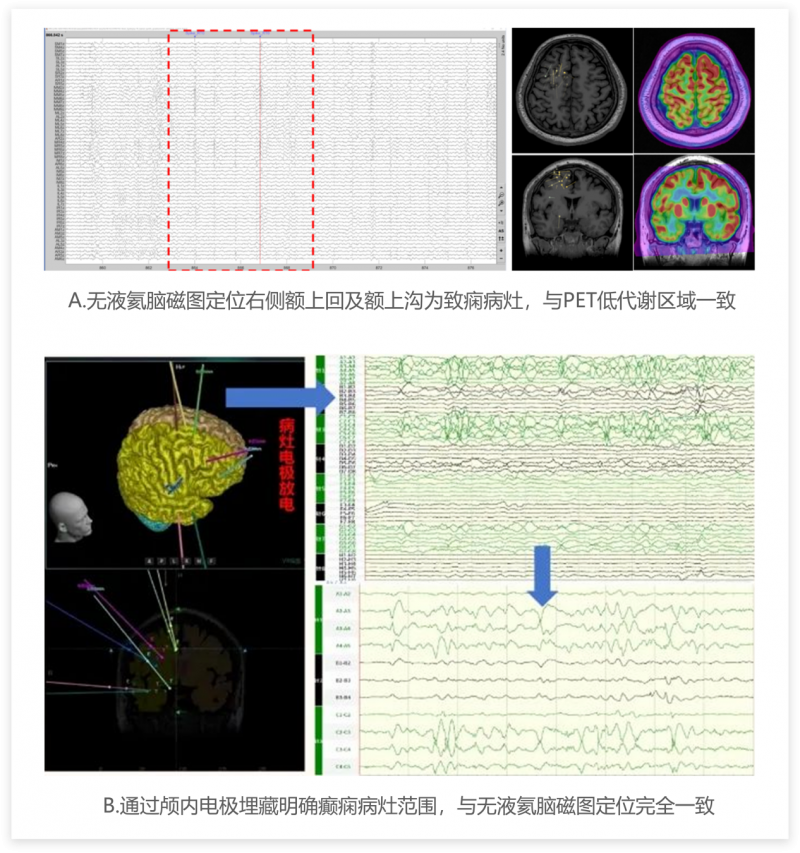
全球首台!未磁科技256通道无液氦脑磁图仪及芯片化原子磁力计正式发布
2024年2月3日,由北京未磁科技有限公司牵头的国家重点研发计划诊疗装备与生物医用材料重点专项“新型无液氦脑磁图系统研发”项目2023年度总结会暨2024年推进会顺利召开。会上发布了项目取得的重大成果——全球首台256通道无液氦脑磁图仪Marvel MEG Pro。此项重磅成果…...
配置)
openssl3.2 - exp - 内存操作(建立,写入,读取)配置
文章目录 openssl3.2 - exp - 内存操作(建立,写入,读取)配置概述笔记调试细节运行效果测试工程实现main.cppCMyOsslConfig.hCMyOsslConfig.cppEND openssl3.2 - exp - 内存操作(建立,写入,读取)配置 概述 我的应用的配置文件是落地加密的, 无法直接用openssl配置接口载入读取…...

前端食堂技术周刊第 114 期:Interop 2024、TS 5.4 RC、2 月登陆浏览器的新功能、JSR、AI SDK 3.0
美味值:🌟🌟🌟🌟🌟 口味:凉拌鸡架 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先来看下…...
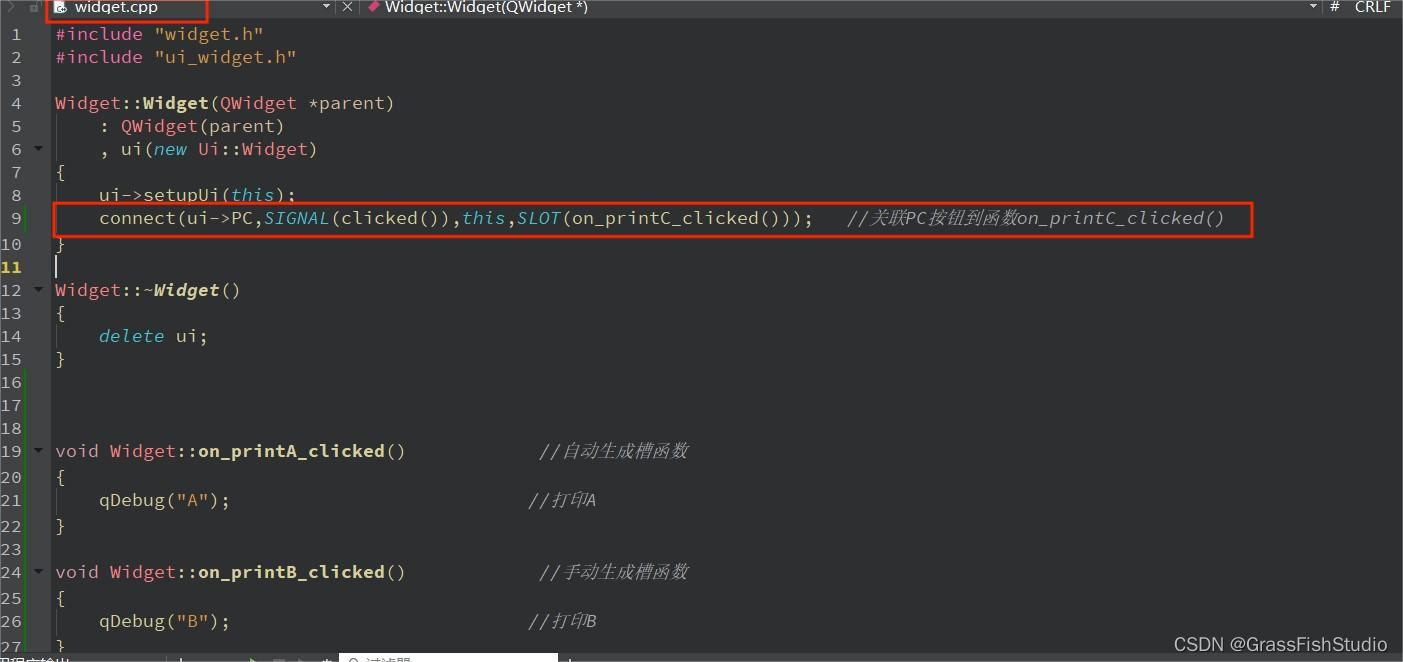
#QT(信号与槽)
1.IDE:QTCreator 2.实验:自动添加槽函数,手动添加槽函数 3.记录 (1)自动添加 a.拖拽widget.ui,放置push-button组件,并且自动生成槽函数 b.发现widget.cpp和widget.h中出现添加的槽函数,注意w…...

go 设置滚动日志
方案 通过 log/slog 实现结构化日志生成,这是go1.21中推出的新特性;通过 lumberjack 实现日志文件分割。 示例 package mainimport ("gopkg.in/natefinch/lumberjack.v2""log/slog""os""path/filepath" )fun…...

Rollup入门学习:前端开发的构建利器
在前端开发领域,构建工具对于优化项目结构和提升代码效率扮演着至关重要的角色。Rollup作为一款轻量级且功能强大的JavaScript模块打包器,近年来备受开发者青睐。本文将带你走进Rollup的世界,帮助你快速入门并掌握其核心用法。 一、Rollup简介…...
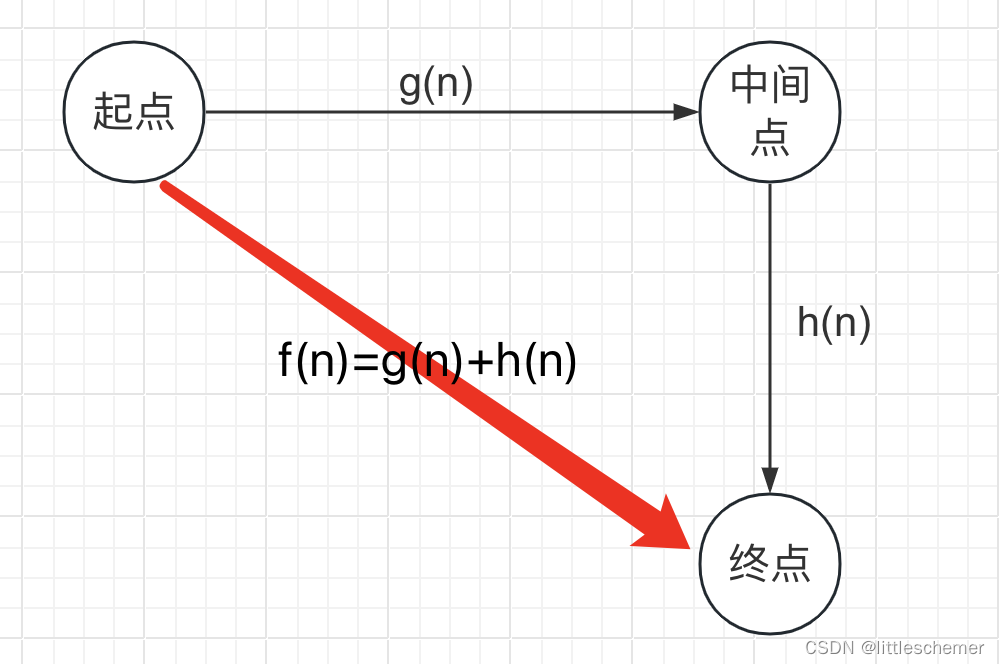
游戏寻路之A*算法(GUI演示)
一、A*算法介绍 A*算法是一种路径搜索算法,用于在图形网络中找到最短路径。它结合了Dijkstra算法和启发式搜索的思想,通过综合利用已知的最短路径和估计的最短路径来优化搜索过程。在游戏自动寻路得到广泛应用。 二、A*算法的基本思想 在图形网络中选择一个起点和终点。维护…...

软件工程顶会——ICSE '24 论文清单、摘要
1、A Comprehensive Study of Learning-based Android Malware Detectors under Challenging Environments 近年来,学习型Android恶意软件检测器不断增多。这些检测器可以分为三种类型:基于字符串、基于图像和基于图形。它们大多在理想情况下取得了良好的…...

Vue点击复制到剪切板
一、Vue2写法 安装 (官网地址) npm install --save vue-clipboard2 使用 //main.js import VueClipboard from vue-clipboard2 Vue.use(VueClipboard)//页面使用 <button type"button"v-clipboard:copy"message"v-clipboard:su…...
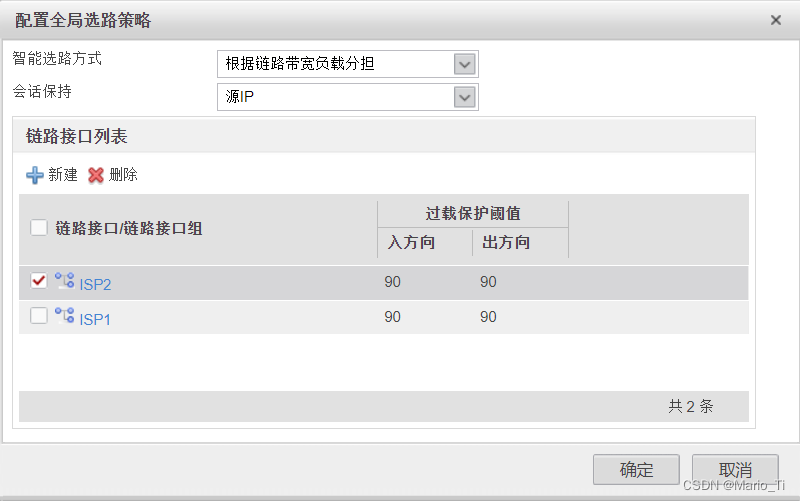
链路负载均衡之DNS透明代理
一、DNS透明代理 一般来说,企业的客户端上都只能配置一个运营商的DNS服务器地址,DNS服务器通常会将域名解析成自己所在ISP内的Web服务器地址,这将导致内网用户的上网流量都集中在一个ISP的链路上转发,最终可能会造成链路拥塞&…...

2024大语言模型LLM基础|语义搜索Semantic_Search全解
目录 语义搜索Semantic_Search代码详解 为甚麽用Pinecone做向量索引?优点是什么? 有哪些常见向量索引方法? Pinecone做向量索引怎么用? 向量索引全解:含原理解析: 语义搜索Semantic_Search代码详解 1…...

vue中使用echarts实现人体动态图
最近一直处于开发大屏的项目,在开发中遇到了一个小知识点,在大屏中如何实现人体动态图。然后看了下echarts官方文档,根据文档中的示例调整出来自己想要的效果。 根据文档上发现 series 中 type 类型设置为 象形柱形图,象形柱图是…...

结构化思维助力Prompt创作:专业化技术讲解和实践案例
结构化思维助力Prompt创作:专业化技术讲解和实践案例 最早接触 Prompt engineering 时, 学到的 Prompt 技巧都是: 你是一个 XX 角色… 你是一个有着 X 年经验的 XX 角色… 你会 XX, 不要 YY.. 对于你不会的东西, 不要瞎说!…对比什么技巧都不用, 直接像使用搜索引…...
(三))
【0272】postgres内核分配 MyBackendId 实现原理(MyBackendId、MyProc、shmInvalBuffer)(三)
相关文章: 【0255】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(一) 【0256】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(二) 第一个backend process前,shmInvalBuffer的值情况 (gdb) p *shmInvalBuffer $153 = {minMsgNum =...

AUKFUKF的MATLAB程序,含源码
adaptive UKF与UKF效果对比 只有一个m文件,直接拖到MATLAB上面就能运行并输出结果了 部分结果 程序源码 % adaptive UKF与UKF效果对比 % author:Evand % 作者联系方式:evandjiang@qq.com(除前期达成一致外,付费咨询) % date: 2023-11-07 % Ver1 clear;clc;close all; %%…...
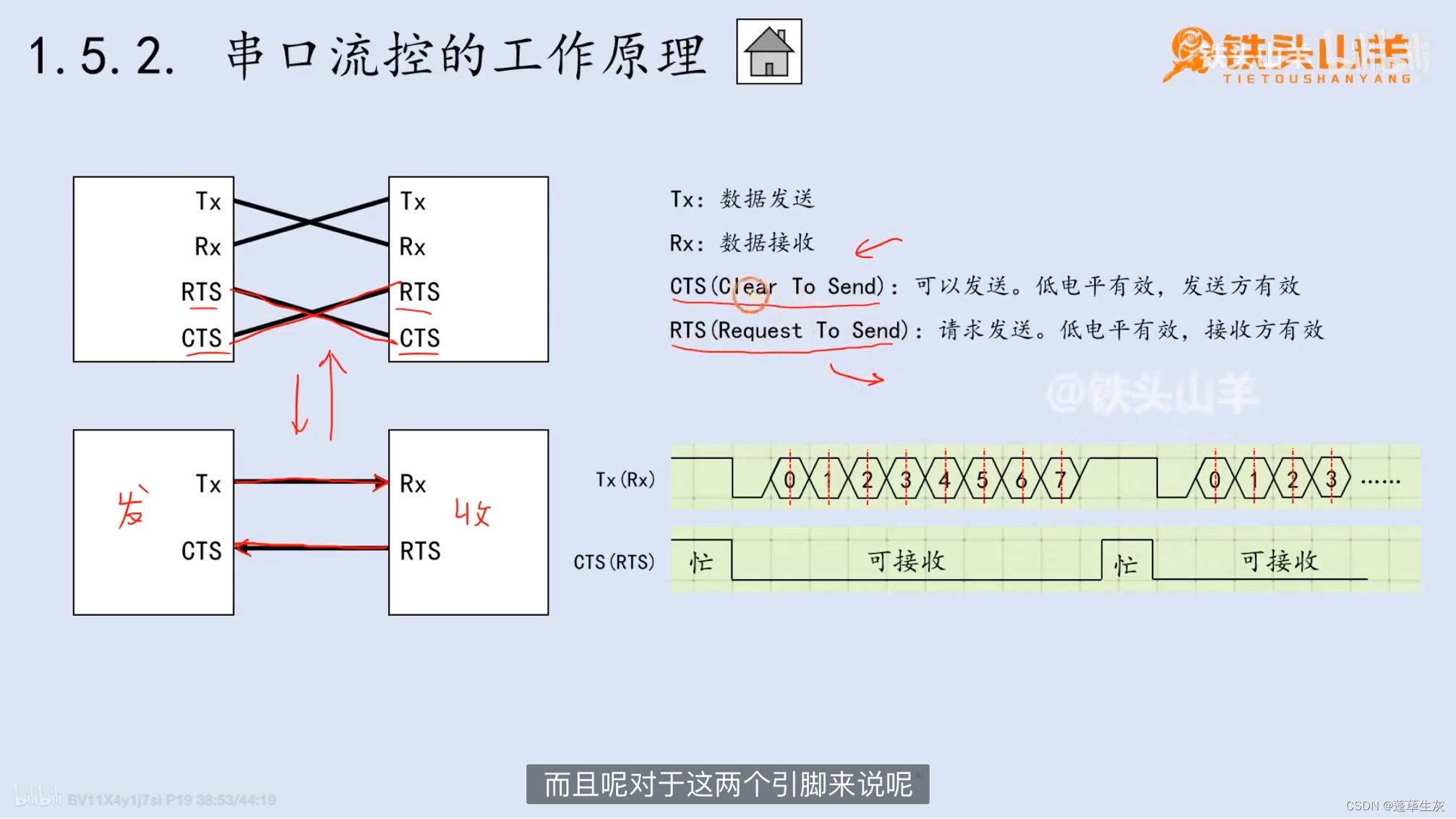
STM32(13)串口
串口的数据帧 1.空闲 2.起始位 3.数据位 4.校验位(可有可无) 为了验证数据传输是否出错而设立的比特位 1和4传输方式比较常见 校验规则: 根据1的个数,校验位会自己补0或1 5.停止位 例子: 同步通信 异步通信 波特率 …...
)
Element(Java后端入门篇)
Element(Java后端入门篇) Element:是饿了么公司前端开发团队提供的一套基于Vue的网站组件库,用于快速构建网页组件:组成网页的部件,例如超链接、按钮、图片、表格等等~ Element快速入门 引入Element的css、js文件和V…...
qt5和gstreamer开发环境安装配置
构建KDE虚拟机环境 1、安装virtualBox 2、导入镜像 配置QtCreator开发环境 https://blog.csdn.net/weixin_45824067/article/details/131970558(安装的是qt6) https://blog.csdn.net/m0_70849943/article/details/132472950 (安装的qt版本为5.14.2&…...

520遇见AI:猛犸AI智能体训练增长营第15期深圳圆满落幕
一束玫瑰,一场关于未来的对话。 2026年5月20日,猛犸AI智能体训练增长营第15期在深圳南山正式开课。课程伊始,GEO理论奠基人罗小军为每一位到场的100余名学员送上了一束玫瑰花——这一天恰逢520,这束花,是猛犸AI送给每一…...

通过curl命令快速测试Taotoken平台API连通性与模型列表
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken平台API连通性与模型列表 基础教程类,本文面向需要快速验证环境或进行排错的开发者&…...
)
【顶级EI复现】考虑用户行为基于扩散模型的电动汽车充电场景生成( Python + PyTorch代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

UVA12822 Extraordinarily large LED 题解
UVA12822 Extraordinarily large LED 题目描述 Link: https://uva.onlinejudge.org/index.php?optioncom_onlinejudge&Itemid8&category861&pageshow_problem&problem4687 PDF 输入格式 输出格式 输入输出样例 #1 输入 #1 START 09:00:00 SCORE 09:01:05…...

机器学习博士生存指南:问题定义、三维技术栈与认知带宽管理
1. 这不是“读博指南”,而是一份机器学习方向博士生的生存手记 我带过7届硕士、指导过4位博士,自己也从MIT CSAIL实验室的PhD candidate一路走到现在,在工业界和学术界都完整跑过ML方向的闭环——从ICML投稿被拒5次到最终以共同作者身份参与N…...

【Go i18n】TOML语言包
一、VS Code 必备的 TOML 插件1. Even Better TOML(核心高亮与语法检查 👑)搜索关键字:Even Better TOML为什么要装:它是目前全网公认第一的 TOML 插件。装上它之后,你的 .toml 文件不仅会变得色彩斑斓&…...

Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案
Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans 你是否曾经在设计网页或应用时,…...
Translumo:实时屏幕翻译工具的完整实战指南
Translumo:实时屏幕翻译工具的完整实战指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外语游戏…...

Godot开源RPG框架选型与状态契约构建指南
1. 这不是又一个“Godot入门教程”,而是一套可落地的RPG世界构建方法论 你有没有试过打开Godot,新建一个项目,拖进几个精灵,写两行 move_and_slide() ,然后卡在“接下来该做什么”上?我做过——整整三年前…...

SaaS系统数据范围权限设计:从RBAC/ABAC到高性能实现
1. 项目概述:当数据安全遇上规模化增长在构建和运营一个面向多租户的大型SaaS(软件即服务)系统时,数据安全与隔离是悬在每一位架构师和开发者头上的“达摩克利斯之剑”。这不仅仅是技术问题,更是商业信任的基石。想象一…...