【基础知识】什么是 PPO(Proximal Policy Optimization,近端策略优化)
什么是 PPO(Proximal Policy Optimization,近端策略优化)
PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由John Schulman等人在2017年提出。PPO属于策略梯度方法,这类方法直接对策略(即模型的行为)进行优化,试图找到使得期望回报最大化的策略。PPO旨在改进和简化以前的策略梯度算法,如TRPO(Trust Region Policy Optimization,信任域策略优化),它通过几个关键的技术创新提高了训练的稳定性和效率。
PPO的主要特点包括:
-
裁剪的概率比率:PPO使用一个目标函数,其中包含了一个裁剪的概率比率,这个比率是旧策略和新策略产生动作概率的比值。这个比率被限制在一个范围内,防止策略在更新时做出太大的改变。
-
多次更新:在一个数据批次上可以安全地进行多次更新,这对于样本效率非常重要,尤其是在高维输入和实时学习环境中。
-
简单实现:与TRPO相比,PPO更容易实现和调整,因为它不需要复杂的数学运算来保证策略更新的安全性。
-
平衡探索与利用:PPO尝试在学习稳定性和足够的探索之间取得平衡,以避免局部最优并改进策略性能。
PPO已被广泛应用于各种强化学习场景,包括游戏、机器人控制以及自然语言处理中的序列决策问题。它是目前最流行的强化学习算法之一。
具体步骤是怎样的?
PPO算法的具体步骤是基于对策略梯度方法的改进,它主要包括以下几个关键的步骤:
-
收集数据:通过在环境中执行当前策略(policy)来收集一组交互数据。这些数据包括状态(state)、动作(action)、奖励(reward)以及可能的下一个状态。
-
计算优势估计:为了评价一个动作相对于平均水平的好坏,需要计算优势函数(advantage function)。这通常是通过某种形式的时间差分(TD)估计或者广义优势估计(GAE)来完成的。
-
优化目标函数:PPO算法使用一个特殊设计的目标函数,这个函数涉及到概率比率 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),其中 π θ \pi_\theta πθ表示新策略, π θ old \pi_{\theta_{\text{old}}} πθold表示旧策略。目标函数的形式通常为:
L ( θ ) = E ^ [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L(\theta) = \hat{\mathbb{E}}\left[\min(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)\right] L(θ)=E^[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中, A ^ t \hat{A}_t A^t是优势函数的估计, ϵ \epsilon ϵ是一个小的正数(如0.1或0.2),clip函数限制了概率比率 r t ( θ ) r_t(\theta) rt(θ)的变化范围,防止更新步骤过大。 -
更新策略:使用梯度上升方法来更新策略参数 θ \theta θ,即 θ ← θ + α ∇ θ L ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta L(\theta) θ←θ+α∇θL(θ),其中 α \alpha α是学习率。
-
重复步骤:使用新的策略参数重复以上步骤,直到满足某些停止准则,比如策略性能不再提升或者已经达到了一定的迭代次数。
PPO算法的关键之处在于它通过限制策略更新的幅度,使得学习过程更加稳定。在每次更新时,概率比率 r t ( θ ) r_t(\theta) rt(θ)被限制在 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ]范围内,防止由于单个数据点导致的极端策略更新,这有助于避免策略性能的急剧下降。同时,PPO允许在每次迭代中使用相同的数据多次进行策略更新,这提高了数据效率。
概率比率 的含义是什么?
在PPO(Proximal Policy Optimization)算法中,概率比率(probability ratio)是一个关键的概念。它表示在新策略下采取某个动作的概率与在旧策略下采取同一动作的概率之比。
具体地,如果用 π θ \pi_\theta πθ表示策略,其中 θ \theta θ是策略的参数,那么对于一个特定的状态 s s s和动作 a a a,概率比率 r t ( θ ) r_t(\theta) rt(θ)定义为:
r t ( θ ) = π θ ( a ∣ s ) π θ old ( a ∣ s ) r_t(\theta) = \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)} rt(θ)=πθold(a∣s)πθ(a∣s)
这里, π θ old \pi_{\theta_{\text{old}}} πθold是旧策略,在这个策略下,数据最初被采集;而 π θ \pi_\theta πθ是在参数 θ \theta θ下的新策略。概率比率反映了策略参数更新后动作选择概率的变化。
这个比率在PPO的目标函数中被用来权衡每个动作的重要性。当这个比率接近1时,说明新旧策略对这个动作的偏好程度相似;如果比率大于1,说明新策略相比于旧策略更倾向于选择这个动作;如果比率小于1,新策略则相对不太倾向于这个动作。
在PPO中,通过裁剪(clipping)这个比率来防止策略更新步骤过大,从而在稳定学习和鼓励探索之间寻求平衡。通过限制概率比率的变化范围,PPO算法避免了因策略更新太过激进而导致的训练不稳定,这有助于改进模型性能和收敛速度。
相关文章:
)
【基础知识】什么是 PPO(Proximal Policy Optimization,近端策略优化)
什么是 PPO(Proximal Policy Optimization,近端策略优化) PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由John Schulman等人在2017年提出。PPO属于策略梯度方法&#x…...

程序员如何选择职业赛道?
程序员如何选择职业赛道? 程序员的职业赛道就像是一座迷宫,充满了各种各样的岔路口。每个岔路口都代表着不同的方向,不同的技术领域,不同的职业发展道路。 前端开发 前端开发就像迷宫中的美丽花园,它是用户与网站或应…...
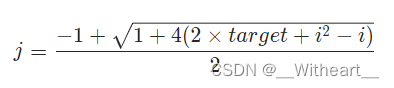
[LeetBook]【学习日记】寻找和为指定数字的连续数字
题目 文件组合 待传输文件被切分成多个部分,按照原排列顺序,每部分文件编号均为一个 正整数(至少含有两个文件)。传输要求为:连续文件编号总和为接收方指定数字 target 的所有文件。请返回所有符合该要求的文件传输组…...

阿里云中小企业扶持权益
为企业提供云资源和技术服务,助力企业开启智能时代创业新范式。阿里云推出中小企业扶持权益 上云必备,助力企业长期低成本用云 一、ECS-经济型e实例、ECS u1实例活动规则 活动时间 2023年10月31日0点0分0秒至2026年3月31日23点59分59秒 活动对象 同时满…...

2核4g服务器能支持多少人访问?并发数性能测评
2核4g服务器能支持多少人访问?支持80人同时访问,阿腾云使用阿里云2核4G5M带宽服务器,可以支撑80个左右并发用户。阿腾云以Web网站应用为例,如果视频图片媒体文件存储到对象存储OSS上,网站接入CDN,还可以支持…...

Anthropic官宣Claude3:建立大模型 推理、数学、编码和视觉等方面 新基准
文章目录 1. product2. Main2.1 核心能力2.2 打榜表现 3. My thoughtsReference Claude 3 在推理、数学、编码、多语言理解和视觉方面,全面超越GPT-4在内的所有大模型,重新树立大模型基准。 1. product https://claude.ai/ 国内暂不能使用,…...
STM32 TIM编码器接口
单片机学习! 目录 文章目录 前言 一、编码器接口简介 1.1 编码器接口作用 1.2 编码器接口工作流程 1.3 编码器接口资源分布 1.4 编码器接口输入引脚 二、正交编码器 2.1 正交编码器功能 2.2 引脚作用 2.3 如何测量方向 2.4 正交信号优势 2.5 执行逻辑 三、编码器定时…...

Jupyter Notebook的安装和使用(windows环境)
一、jupyter notebook 安装 前提条件:安装python环境 安装python环境步骤: 1.下载官方python解释器 2.安装python 3.命令行窗口敲击命令pip install jupyter 4.安装jupyter之后,直接启动命令jupyter notebook,在默认浏览器中打开jupyte…...
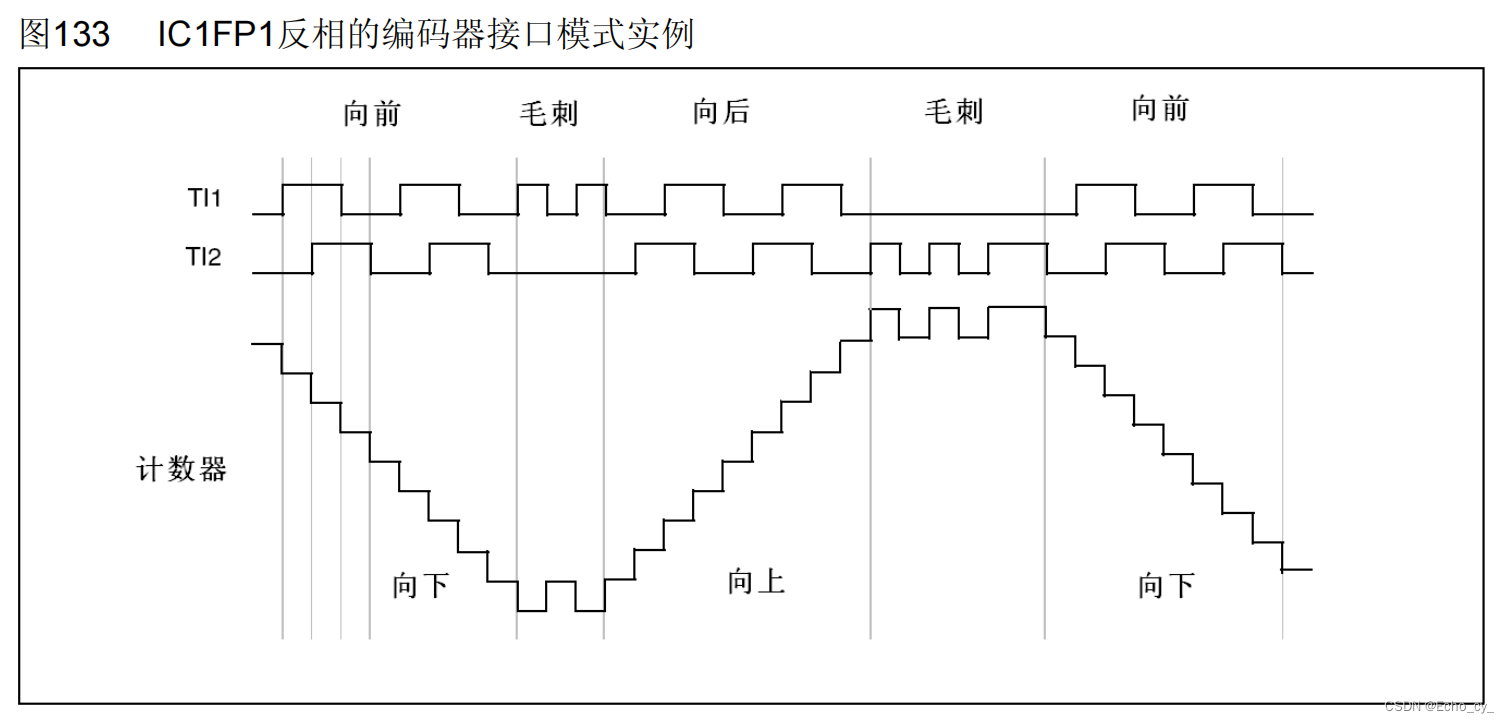
Platformview在iOS与Android上的实现方式对比
Android中早期版本Platformview的实现基于Virtual Display。VirtualDisplay方案的原理是,先将Native View绘制到虚显,然后Flutter通过从虚显输出中获取纹理并将其与自己内部的widget树进行合成,最后作为Flutter在 Android 上更大的纹理输出的…...
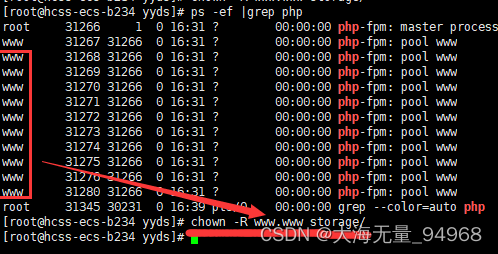
使用lnmp环境部署laravel框架需要注意的点
1,上传项目文件后,需要chmod -R 777 storage授予文件权限,不然会报错file_put_contents(/): failed to open stream: Permission denied。 如果后面还是报错没有权限的话,就执行ps -ef |grep php查询php运行用户。然后执行chown …...

AI-RAN联盟在MWC24上正式启动
AI-RAN联盟在MWC24上正式启动。它的logo是这个样的: 2月26日,AI-RAN联盟(AI-RAN Alliance)在2024年世界移动通信大会(MWC 2024)上成立。创始成员包括亚马逊云科技、Arm、DeepSig、爱立信、微软、诺基亚、美…...

Reactor详解
目录 1、快速上手 介绍 2、响应式编程 2.1. 阻塞是对资源的浪费 2.2. 异步可以解决问题吗? 2.3.1. 可编排性与可读性 2.3.2. 就像装配流水线 2.3.3. 操作符(Operators) 2.3.4. subscribe() 之前什么都不会发生 2.3.5. 背压 2.3.6. …...

实践航拍小目标检测,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下的小目标检测识别分析系统
关于无人机相关的场景在我们之前的博文也有一些比较早期的实践,感兴趣的话可以自行移步阅读即可: 《deepLabV3Plus实现无人机航拍目标分割识别系统》 《基于目标检测的无人机航拍场景下小目标检测实践》 《助力环保河道水质监测,基于yolov…...

分布式数据库中全局自增序列的实现
自增序列广泛使用于数据库的开发和设计中,用于生产唯一主键、日志流水号等唯一ID的场景。传统数据库中使用Sequence和自增列的方式实现自增序列的功能,在分布式数据库中兼容Oracle和MySQL等传统数据库语法,也是基于Sequence和自增列的方式实现…...
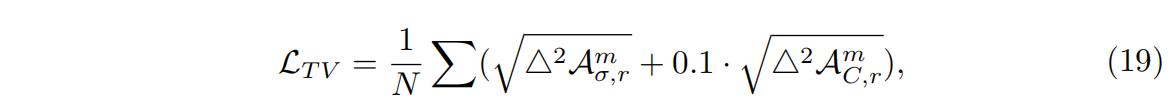
【论文阅读】TensoRF: Tensorial Radiance Fields 张量辐射场
发表于ECCV2022. 论文地址:https://arxiv.org/abs/2203.09517 源码地址:https://github.com/apchenstu/TensoRF 项目地址:https://apchenstu.github.io/TensoRF/ 摘要 本文提出了TensoRF,一种建模和重建辐射场的新方法。不同于Ne…...

深入了解 Android 中的 FrameLayout 布局
FrameLayout 是 Android 中常用的布局之一,它允许子视图堆叠在一起,可以在不同位置放置子视图。在这篇博客中,我们将详细介绍 FrameLayout 的属性及其作用。 <FrameLayout xmlns:android"http://schemas.android.com/apk/res/androi…...
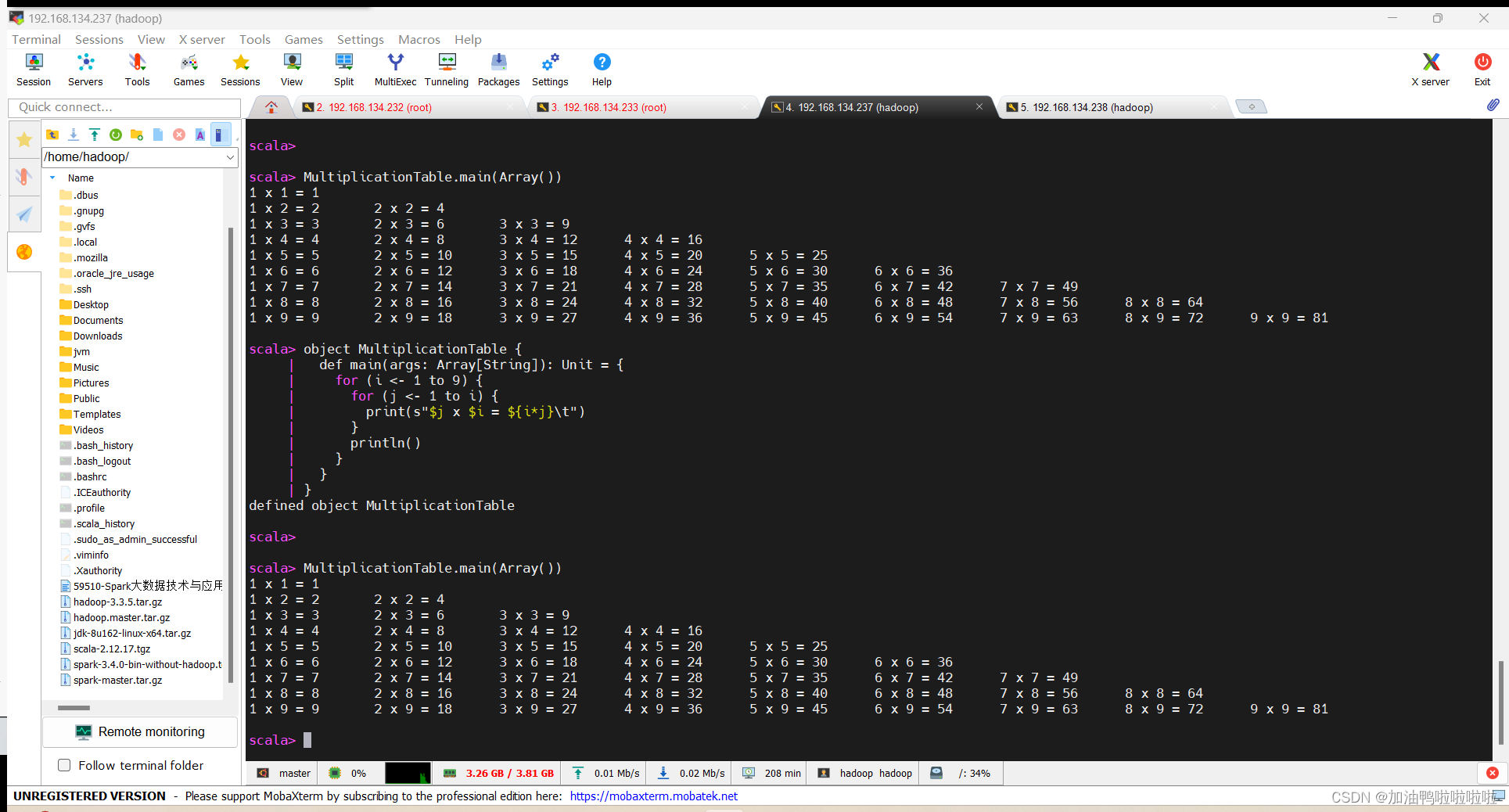
高级大数据技术 实验一 scala编程
高级大数据技术 实验一 scala编程 写的不是很好,大家多见谅! 1. 计算水仙花数 实验目标; (1) 掌握scala的数组,列表,映射的定义与使用 (2) 掌握scala的基本编程 实验说明 …...

使用Fabric创建的canvas画布背景图片,自适应画布宽高
之前的文章写过vue2使用fabric实现简单画图demo,完成批阅功能;但是功能不完善,对于很大的图片就只能显示一部分出来,不符合我们的需求。这就需要改进,对我们设置的背景图进行自适应。 有问题的canvas画布背景 修改后的…...
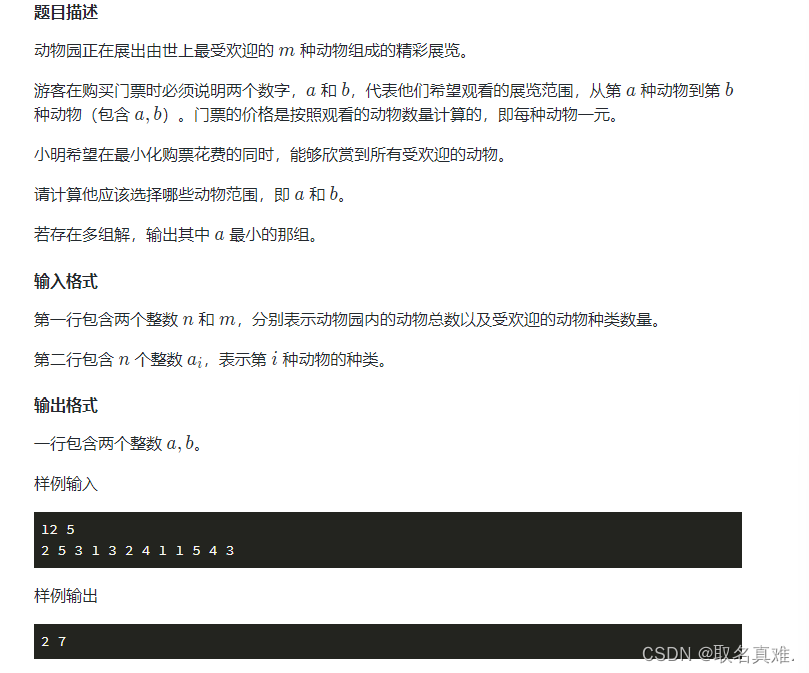
枚举与尺取法(蓝桥杯 c++ 模板 题目 代码 注解)
目录 组合型枚举(排列组合模板()): 排列型枚举(全排列)模板: 题目一(公平抽签 排列组合): 编辑 代码: 题目二(座次问题 全排…...

11、电源管理入门之Regulator驱动
目录 1. Regulator驱动是什么? 2. Regulator框架介绍 2.1 regulator consumer 2.2 regulator core 2.3 regulator driver 3. DTS配置文件及初始化 4. 运行时调用 5. Consumer API 5.1 Consumer Regulator Access (static & dynamic drivers) 5.2 Regulator Outp…...

网关连接ModbusRTU串行设备故障排查
客户在使用我们串行网关时常常遇到串行侧网络通讯问题,但是又无从下手,不知道如何排查。根据客户常见问题,进行了以下总结。即便是不连接我们网关,对于ModbusRTU串行设备在通讯故障时,都可以按照以下步骤来排查和解决。…...

【MATLAB】红外图像增强与目标检测实现
【MATLAB】红外图像增强与目标检测实现 摘要:红外成像技术可全天候、无源感知目标热辐射信息,不受光照、雾霾、黑夜环境限制,广泛应用于安防监控、军事侦察、设备故障巡检、森林防火等领域。但受红外传感器噪声、大气衰减、环境杂波干扰影响,原始红外图像普遍存在对比度低…...
)
OpenClaw 自动处理核心逻辑(流程图+关键配置清单)
OpenClaw 自动处理核心逻辑(流程图关键配置清单) 说明:流程图可直接复制到支持Mermaid的工具(如Typora、Mermaid Live Editor)生成可视化图表;配置清单可直接用于部署、优化,适配所有自动处理场…...

抖音批量下载工具:免费无水印下载完整指南
抖音批量下载工具:免费无水印下载完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量…...

在自动化工作流中集成大模型,利用Taotoken统一API调用与管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化工作流中集成大模型,利用Taotoken统一API调用与管理 将大模型能力集成到自动化工作流中,例如CI/CD…...

SAP 和 Legacy 系统之间的平面文件集成,GUI_DOWNLOAD 的实战设计
很多 SAP 项目里,系统集成并不总是从 API、RFC、OData 或 Event Mesh 开始。相当多的老系统仍然依赖一个最朴素的接口形态,固定格式的文本文件。财务共享平台要一份物料清单,仓储系统要一份当天新增物料,历史的生产执行系统只认 .txt 或 .csv,这时 ABAP 报表把 SAP 表里的…...

9. Python 文件与输入输出 深度解析
Python 文件与输入输出 深度解析 目录 Python I/O 概述文件对象与基本操作 2.1 打开文件:open 与模式2.2 读取数据2.3 写入数据2.4 使用 with 自动管理文件 文件指针与随机访问路径操作:os、os.path 与 pathlib 4.1 os 模块与 os.path 基础4.2 现代路径…...

使用TaotokenCLI工具一键配置开发环境与模型密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境与模型密钥 在接入大模型进行开发时,手动配置API密钥、Base URL和模型ID是常见的…...

魔改frida-server实现反检测:从行为消除到可检测性归零
1. 为什么魔改frida-server比写检测绕过代码更根本?在Android逆向与安全测试一线干了十多年,我见过太多团队把精力耗在“检测逻辑对抗”上:写一堆Java层的isFridaPresent()、Native层的checkFridaPort()、甚至用ptrace自检父进程——结果呢&a…...

全周期陪伴式服务成行业趋势,墨石教育以 “录取即终点” 定义管理类联考服务新标准
随着考研培训行业从流量竞争转向服务竞争,《人民日报》《新华网》多次倡导 **“全周期、结果导向”的教育服务模式。管理类联考作为系统性工程,从择校、笔试、面试到调剂,任何环节缺失都可能导致落榜。墨石教育率先打破 “重授课、轻服务” 的…...