Python教程——最后一波来喽
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 1.使用__slots__
- 2. @property
- 3.多重继承
- 4.定制类
- 5.枚举类
- 6.错误处理
- 7.调试
- 8. 文档测试
- 9.单元测试
- 10. 文件读写
- 11. StringIO和BytesIO
- 12. 操作文件和目录
- 13.序列化
- 14. 多进程
- 15.多线程
- 16.ThreadLocal
- 一些常用函数
- 1.datetime
- 2.collections
- 3.struct
- 4.itertools
1.使用__slots__
class student(object):pass# 给实例绑定一个属性
s = student()
s.name = 'sb'
s.name
>>>‘sb’
# 给实例绑定方法
def set_age(self,age):self.age = agefrom types import MethodType
# 给实例绑定方法
s.set_age = MethodType(set_age,s)
# 调用实例方法
s.set_age(22)
s.age
>>>22
# 对于别的实例无效
s2 = student()
s2.set_age()
>>>
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-11-537c96074839> in <module>
----> 1 s2.set_age()AttributeError: 'student' object has no attribute 'set_age'
# 直接给class绑定方法 所有实例都可以用
def set_score(self,score):self.score = score
student.set_score = set_scores.set_score(0)
s.scores2.set_score(10)
s2.score
# 现在我们想限制实例的属性 比如只给student的实例name和age属性
# 使用__slots__ / 对继承的子类无效
class student(object):# 用tuple定义允许绑定的属性__slots__ = ('name','age')s = student()
s.name = 'sb'
s.age = 0
# 绑定其他属性
s.score = 0
>>>
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-22-f3e0e0dee7b4> in <module>
----> 1 s.score = 0AttributeError: 'student' object has no attribute 'score'
2. @property
# 绑定属性的时候,虽然方便,但是直接暴露出来,没法检查参数还可以随便改
# 通过set_score,get_score可以检查参数
class student(object):def get_score(self):return self.__scoredef set_score(self,value):if not isinstance(value,int):raise ValueError('score must be integer!')if value >100 or value < 0:raise ValueError('score must between 0-100')self.__score = value
s = student()
s.set_score(10)
s.get_score()
>>>10
# 现在觉得太麻烦了 可以用装饰器给函数动态加上功能 @property负责把一个方法变成属性调用
class student(object):@propertydef score(self):return self._score@score.setterdef score(self, value):if not isinstance(value, int):raise ValueError('score must be an integer!')if value < 0 or value > 100:raise ValueError('score must between 0 ~ 100!')self._score = values = student()
s.score = 60 # 转化为了s.set_score(60)
s.score # 转化为了s.get_score
>>>60
3.多重继承
# 子类通过继承多种父类,同时获得多个父类的功能
class Animal(object):passclass Mammal(Animal):passclass Bird(Animal):passclass Dog(Mammal):passclass Bat(Mammal):passclass Parrot(Bird):passclass Ostrich(Bird):pass
# 给动物加上功能,可以通过继承功能类
class Runnable(object):def run(self):print('running...')class Flyable(object):def fly(self):print('flying...')class Dog(Mammal,Runnable):passclass Bat(Mammal,Flyable):pass# 通过这样多重继承的方式,一个子类可以获得多个父类的功能
# MixIn
# 为了更好看出继承关系,Runnable和Flyable改为RunnableMixIn和FlyableMixIn
class Dog(Mammal,RunnableMixIn):pass
4.定制类
- 4.1 _str_
- 4.2 _iter_
- 4.3 _getitem_
- 4.4 _getattr_
- 4.5 _call_
# 4.1 __str__
# 先打印一个实例
class student(object):def __init__(self,name):self.name = nameprint(student('sb'))
# 打印出来不好看
>>>
<__main__.student object at 0x1077bba20>```python
# __str__()方法,可以打印除比较好看的自定义的字符串
class student(object):def __init__(self,name):self.name = namedef __str__(self):return 'student object (name: %s)' % self.nameprint(student('sb'))
>>>student object (name: sb)
# 不用print的时候,打印出来的实例还是不好看
s = student('sb')
s
>>><main.student at 0x1078d6630>
# 因为直接显示变量调用的不是__str__(),而是__repr__
class student(object):def __init__(self, name):self.name = namedef __str__(self):return 'student object (name=%s)' % self.name__repr__ = __str__s = student('sb')
s
>>>student object (name=sb)
# __iter__
# 想要被for循环迭代,这个类就要有__iter__(),返回一个迭代对象,for就会不断调用该调用这个迭代对象的__next__()方法拿到下一个值,直到StopIteration退出循环
class Fib(object):def __init__(self):self.a,self.b = 0,1def __iter__(self):return selfdef __next__(self):self.a,self.b = self.b,self.a + self.bif self.a > 5:raise StopIterationreturn self.afor n in Fib():print(n)
>>>1
1
2
3
5
# __getitem__
# 虽然可以用for循环了,但是想要像list一样切片
class Fib(object):def __getitem__(self, n):if isinstance(n, int): # n是索引a, b = 1, 1for x in range(n):a, b = b, a + breturn aif isinstance(n, slice): # n是切片start = n.startstop = n.stopif start is None:start = 0a, b = 1, 1L = []for x in range(stop):if x >= start:L.append(a)a, b = b, a + breturn L
f = Fib()
f[0]
f[1:3]
>>>
1
[1, 2]
# 4.4 __getattr__
# 当没有定义某些属性的时候,通过__getattr__,动态返回一个属性
class student(object):def __getattr__(self,attr):if attr == 'age':return lambda:22raise AttributeError('\'Student\' object has no attribute \'%s\'' % attr)s = student()
s.age()
>>> 22
# 4.5 __call__ 对实例本身进行调用
class student(object):def __init__(self,name):self.name = namedef __call__(self):print('Your name is %s'%self.name)s = student('sb')
s()
>>>Your name is sb
# callable()函数 判断一个对象是否可以被调用
callable(student('sb'))
>>>True
callable(max)
>>>True
callable(list)
>>>True
callable('str')
>>>False
5.枚举类
# enum实现枚举
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))for name,member in Month.__members__.items():print(name, '=>', member, ',', member.value)
Jan => Month.Jan , 1
Feb => Month.Feb , 2
Mar => Month.Mar , 3
Apr => Month.Apr , 4
May => Month.May , 5
Jun => Month.Jun , 6
Jul => Month.Jul , 7
Aug => Month.Aug , 8
Sep => Month.Sep , 9
Oct => Month.Oct , 10
Nov => Month.Nov , 11
Dec => Month.Dec , 12
# 想要更精确的控制枚举
# @unique 保障没有重复值
from enum import Enum, unique
@unique
class Weekday(Enum):Sun = 0 # Sun的value被设定为0Mon = 1Tue = 2Wed = 3Thu = 4Fri = 5Sat = 6day1 = Weekday.Mon
print(day1)
>>>Weekday.Mon
6.错误处理
- 6.1 try except finally
- 6.2 调用栈
- 6.3 记录错误
- 6.4 抛出错误
# 6.1 try机制
try:print('try...')r = 10/0print('result:',r)
except ZeroDivisionError as e:print('except:',e)
finally:print('finally...')
print('end')
>>>
try…
except: division by zero
finally…
end
# 所有的错误类型都继承自BaseException,当使用except的时候不但捕获该类型的错误,子类也一起被捕获
try:print('try...')r = 10 / int('a')print('result:', r)
except ValueError as e:print('ValueError')
except UnicodeError as e:print('UnicodeError')
# 在这里永远不会捕获到UnicodeError,因为他是ValueError的子类
>>>
try…
ValueError
# 6.2 调用栈
# 如果错误没有被捕获会一直往上抛,最后被python解释器捕获,打印错误信息,退出程序
# %%
def foo(s):return 10/int(s)def bar(s):return foo(s)*2def main():bar('0')
main()
# %%
>>>
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-1-7d9101d864ec> in <module>7 def main():8 bar('0')
----> 9 main()
# 第一部分:告诉我们第9行有问题<ipython-input-1-7d9101d864ec> in main()67 def main():
----> 8 bar('0')9 main()
# 第二部分:告诉我们上一层第8行有问题<ipython-input-1-7d9101d864ec> in bar(s)34 def bar(s):
----> 5 return foo(s)*267 def main():
# 第三部分:告诉我们上一层第5行有问题<ipython-input-1-7d9101d864ec> in foo(s)1 def foo(s):
----> 2 return 10/int(s)34 def bar(s):5 return foo(s)*2ZeroDivisionError: division by zero
# 源头:第二行出现了division by zero 的错误
# 6.3 记录错误
# 如果不捕获错误,自然可以让python解释器来打印错误堆栈,但程序也结束了!
# 既然我们可以捕获错误,就可以把错误堆栈打印出来,分析错误,同时可以持续运行
# logging模块
import logging
def foo(s):return 10/int(s)
def bar(s):return foo(s)*2def main():try:bar('0')except Exception as e:logging.exception(e)main()
print('END')
>>>
ERROR:root:division by zero
Traceback (most recent call last):File "<ipython-input-5-a6d7cf5e63df>", line 3, in mainbar('0')File "<ipython-input-4-3ddc15423656>", line 2, in barreturn foo(s)*2File "<ipython-input-3-48e50a3d2c31>", line 2, in fooreturn 10/int(s)
ZeroDivisionError: division by zero
END
# 发现打印完错误之后还会继续执行
# 还可以把错误写进日志里
# 6.4 抛出错误
# 因为错的是class,捕获错误就是捕获了一个class的实例
# 我们可以自己编写函数抛出错误class FooError(ValueError):passdef foo(s):n = int(s)if n == 0:raise FooError('invaild value: %s'%s)return 10/n
foo('0')
>>>
---------------------------------------------------------------------------
FooError Traceback (most recent call last)
<ipython-input-11-4b4551c506aa> in <module>
----> 1 foo('0')<ipython-input-10-35eddb2011fd> in foo(s)2 n = int(s)3 if n == 0:
----> 4 raise FooError('invaild value: %s'%s)5 return 10/nFooError: invaild value: 0
7.调试
- 7.1 print
- 7.2 assert
- 7.3 logging
- 7.4 pdb
# 7.1 print
# %%
def foo(s):n = int(s)print('n = %d'%n)return 10/n
# %%
def main():foo('0')
# %%
main()
>>>
# 打印出来错误是因为0
# 明显不是个好方法
n = 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-29-263240bbee7e> in <module>
----> 1 main()<ipython-input-28-e0516f232497> in main()1 def main():
----> 2 foo('0')<ipython-input-26-6a182582d57b> in foo(s)2 n = int(s)3 print('n = %d'%n)
----> 4 return 10/nZeroDivisionError: division by zero
# 7.2 assert断言
# 可以用print的地方就可以用assert# %%
def foo(s):n = int(s)# n != 0 是True,就继续下去,如果是False就'n is zero!'assert n != 0, 'n is zero!'return 10 / n
# %%
main()
>>>
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-33-263240bbee7e> in <module>
----> 1 main()<ipython-input-28-e0516f232497> in main()1 def main():
----> 2 foo('0')<ipython-input-31-daa2ab964953> in foo(s)1 def foo(s):2 n = int(s)
----> 3 assert n != 0, 'n is zero!'4 return 10 / n
# assert语句抛出AssertionError
AssertionError: n is zero!
# 7.3 logging
# 不会抛出错误/但是可以输出文件
import logging
# level分为 info/debug/warning/error
logging.basicConfig(level=logging.INFO)
s = '0'
n = int(s)
logging.info('n = %d'%n)
print(10/n)
>>>
INFO:root:n = 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-6-20413b32911f> in <module>
----> 1 print(10/n)ZeroDivisionError: division by zero
# 7.4 pdb
# 启动python的调试器pdb,让程序单步运行,可以随时查看运行状态# %%
# err.py
s = '0'
n = int(s)
print(10 / n)
# %%
# 命令行启动
python -m pdb err.py# 输入n进行单步调试
(pdb) n# 输入 p (变量名) 查看变量
(pdb) p n
(pdb) p s# 输入q结束调试
(pdb) q
# pdb.set_trace()设置断点# err.pys = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print(10 / n)# p查看变量 c继续执行
(pdb) p n
(pdb) c
8. 文档测试
# ...省略了一大堆乱七八糟的东西,当出现了xx种情况和文档匹配的时候,就会出现相应的报错
# %%
class Dict(dict):'''Simple dict but also support access as x.y style.>>> d1 = Dict()>>> d1['x'] = 100>>> d1.x100>>> d1.y = 200>>> d1['y']200>>> d2 = Dict(a=1, b=2, c='3')>>> d2.c'3'>>> d2['empty']Traceback (most recent call last):...KeyError: 'empty'>>> d2.emptyTraceback (most recent call last):...AttributeError: 'Dict' object has no attribute 'empty''''def __init__(self, **kw):super(Dict, self).__init__(**kw)# def __getattr__(self, key):# try:# return self[key]# except KeyError:# raise AttributeError(r"'Dict' object has no attribute '%s'" % key)def __setattr__(self, key, value):self[key] = valueif __name__=='__main__':import doctestdoctest.testmod()# %%
# 如果把__getattr__()注释掉,会出现这样的测试报错
**********************************************************************
File "__main__", line ?, in __main__.Dict
Failed example:d1.x
Exception raised:Traceback (most recent call last):File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/doctest.py", line 1329, in __runcompileflags, 1), test.globs)File "<doctest __main__.Dict[2]>", line 1, in <module>d1.xAttributeError: 'Dict' object has no attribute 'x'
**********************************************************************
File "__main__", line ?, in __main__.Dict
Failed example:d2.c
Exception raised:Traceback (most recent call last):File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/doctest.py", line 1329, in __runcompileflags, 1), test.globs)File "<doctest __main__.Dict[6]>", line 1, in <module>d2.cAttributeError: 'Dict' object has no attribute 'c'
**********************************************************************
1 items had failures:2 of 9 in __main__.Dict
***Test Failed*** 2 failures.9.单元测试
import unittest
# %%
class Dict(dict):def __init__(self, **kw):super().__init__(**kw)def __getattr__(self, key):try:return self[key]except KeyError:raise AttributeError(r"'Dict' object has no attribute '%s'" % key)def __setattr__(self, key, value):self[key] = value# %%
class TestDict(unittest.TestCase):def test_init(self):d = Dict(a=1, b='test')self.assertEqual(d.a, 1)self.assertEqual(d.b, 'test')self.assertTrue(isinstance(d, dict))def test_key(self):d = Dict()d['key'] = 'value'self.assertEqual(d.key, 'value')def test_attr(self):d = Dict()d.key = 'value'self.assertTrue('key' in d)self.assertEqual(d['key'], 'value')def test_keyerror(self):d = Dict()with self.assertRaises(KeyError):value = d['empty']def test_attrerror(self):d = Dict()with self.assertRaises(AttributeError):value = d.empty
# %%
# 编写测试类,都从unittest.TestCase类
# test开头的就是测试方法,
# unittest.TestCase提供了很多内置的条件判断# 运行单元测试
if __name__ == '__main__':unittest.main()
>>>
# 运行结果
----------------------------------------------------------------------
Ran 5 tests in 0.000sOK
# %%
python -m unittest xxx(文件名)>>>
# 运行结果
----------------------------------------------------------------------
Ran 5 tests in 0.000sOK# 这样可以一次批量运行很多单元测试,并且,有很多工具可以自动来运行这些单元测试。
10. 文件读写
- 10.1 读文件
- 10.2 字符编码
- 10.3 写文件
# 10.1 读文件
# open(文件名,标志符)函数
f = open('/xx/xx/xx','r')
# ‘r’表示读
# read()一次读取全部内容到内存中,返回一个str
f.read()
>>>‘Hello World’
# close()方法关闭文件,文件对象会占用操作系统资源
f.close()
# 因为文件读写的时候可能会产生IOError,为了保证close的执行,可以使用try
try:f = open('xx/xx','r')print(f.read())
finally:if f:f.close()# with语句自动调用close
with open('xx/xx','r') as f:print(f.read())
# 10.2 字符编码
# 读取非utf-8的文本文件/需要给open传递encoding参数
# 比如gbk编码的中文
f = open('xx/xx.txt','r',encoding='gbk')
f.read()
>>>‘测试’
# 当夹杂这一些非法字符的时候,可能会遇到UnicodeDecodeError,这时候就要用到error参数
f = open('xx/xx.txt','r',encoding='gbk',errors='ignore')
# 10.3 写文件
# 和读文件的区别就是把标志符换成w
f = open('xx/xx.txt','w')
11. StringIO和BytesIO
# StringIO
# 就是在内存中对String进行读写
from io import StringIO
f = StringIO()
f.write('hello')
>>>5
f.write(' ')
>>>1
f.write('world')
>>>5
print(f.getvalue())
>>>hello world
# 读取
from io import StringIO
f = StringIO('Hello\nWorld')
while True:s = f.readline()if s == '':breakprint(s.strip())
Hello
World
# BytesIO 实现在内存中二进制流的读写
from io import BytesIO
f = BytesIO()
# 写入的不是str,而是经过utf-8编码的字节流
f.write('中文'.encode('utf-8'))
>>>6
print(f.getvalue())
>>>b’\xe4\xb8\xad\xe6\x96\x87’
from io import BytesIO
f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
f.read()
>>>b’\xe4\xb8\xad\xe6\x96\x87’
12. 操作文件和目录
import os
# 操作系统类型 'posix'代表linux unix macos 'nt'就是windows
os.name
>>>‘posix’
# 具体的系统信息
os.uname()
>>>
posix.uname_result(sysname=‘Darwin’, nodename=‘LaudeMacBook-Pro.local’, release=‘19.0.0’, version=‘Darwin Kernel Version 19.0.0: Thu Oct 17 16:17:15 PDT 2019; root:xnu-6153.41.3~29/RELEASE_X86_64’, machine=‘x86_64’)
# 操作系统定义的环境变量
os.environ
# 查看当前绝对路径
os.path.abspath('.')
>>>/xxx/xxx/Day11.md
# 在某个目录下创建新的目录,首先把新目录的路径完整表示出来
os.path.join('xx/xx','new')
>>>‘xx/xx/new’
# 创建新目录
os.mkdir('xx/xx/new')# 删除目录
os.rmdir('xx/xx/new')
# 拆分路径 os.path.split()
# 后一部分一定是最后级别的目录或文件
os.path.split('xx/xx/xx.txt')
>>>(‘xx/xx’, ‘xx.txt’)
# os.path.splitext(),让你得到文件扩展名
os.path.splitext('/path/file.txt')
>>>(‘/path/file’, ‘.txt’)
# 对文件重命名
os.rename('text.txt','text.py')# 删掉文件
os.remove('test.py')
13.序列化
- 13.1 dump和dumps
- 13.2 loads
- 13.3 json
# 13.1 dump和dumps
# 在程序运行的时候,所有的变量都是在内存里
d = dict(name='Bob',age=20,score=88)# 虽然可以随时修改变量,但是一旦结束,变量占用的内存就被操作系统全部回收
# 没有存入磁盘的话,下次运行程序就会发现变量仍然没有修改
# 我们把变量从内存中变成可储存的过程叫做序列化
# 序列化后写入磁盘或通过网络存在别的机器上
# 把一个对象写入文件
import pickle
d = dict(name='Bob',age=20,score=88)
# dumps()把对象序列变成bytes,然后就可以把它写入文件
pickle.dumps(d)
>>>b’\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x03\x00\x00\x00Bobq\x02X\x03\x00\x00\x00ageq\x03K\x14X\x05\x00\x00\x00scoreq\x04KXu.’
# dump()把对象序列化后直接写入file-like-object
f = open('dump.txt','wb')
pickle.dump(d,f)
f.close()
>>>查看dump.txt里面乱七八糟的内容,就是保存的对象内部信息
# 4.2loads
# 把对象从磁盘读到内存/可以用loads()反序列化/也可以用load()方法从file-like-object反序列化出对象
f = open('dump.txt','rb')
d = pickle.load(f)
f.close()
d
>>>{‘age’: 20, ‘score’: 88, ‘name’: ‘Bob’}
# pickle只能在python内使用
# JSON表示的对象就是标准的JavaScript语言的对象
# 把python对象变成一个json
import json
d = dict(name='Bob', age=20, score=88)
json.dumps(d)
>>>‘{“name”: “Bob”, “age”: 20, “score”: 88}’
# loads()
json_str = '{"age": 20, "score": 88, "name": "Bob"}'
# 变成python对象
json.loads(json_str)
>>>{‘age’: 20, ‘score’: 88, ‘name’: ‘Bob’}
14. 多进程
- 14.1 多进程的定义
- 14.2 multiprocessing
- 14.3 subprocesses
- 14.4 子进程输入
- 14.5 进程间通信
# 14.1 多进程定义
# 普通的函数调用/调用一次/返回一次/
# fork()调用一次/返回两次/分别在父进程和子进程内返回
# 子进程永远返回0/父进程返回子进程ID/一个父进程可以fork出多个子进程
# 父进程返回子进程ID/子进程只需要调用getppid()可以获得父进程
import osprint('Process (%s) start...' % os.getppid())
# %%
pid = os.fork()
if pid == 0:print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
# %%
>>>
Process (16351) start…
I (16351) just created a child process (16378).
I am child process (16378) and my parent is 16351.
# 14.2 multiprocessing 支持多平台的多进程模块
from multiprocessing import Process
import osdef run_proc(name):print('Run child process %s (%s)' % (name,os.getpid()))# 创建一个Process的实例/用start()方法/join()方法可以等待子进程结束之后继续往下运行/通常用于进程的同步
if __name__ == '__main__':print('Parent process %s.'%os.getpid())p = Process(target=run_proc,args=('test',))print('Child process will start.')p.start()p.join()print('Child process end.')
>>>
Parent process 16351.
Child process will start.
Run child process test (16422)
Child process end.
# 14.3 Pool
# 如果需要大量子进程/可以用进程池的方式批量创建子进程
from multiprocessing import Pool
import os, time, randomdef long_time_task(name):print('Run task %s (%s)...' % (name, os.getpid()))start = time.time()time.sleep(random.random() * 3)end = time.time()print('Task %s runs %0.2f seconds.' % (name, (end - start)))if __name__=='__main__':print('Parent process %s.' % os.getpid())p = Pool(4)for i in range(5):p.apply_async(long_time_task, args=(i,))print('Waiting for all subprocesses done...')p.close()p.join()print('All subprocesses done.')
>>>
task0/1/2/3立刻执行/task4要等前面某个执行完/因为pool是默认是4
Parent process 3120.
Run task 2 (3129)…
Run task 0 (3127)…
Run task 1 (3128)…
Run task 3 (3130)…
Waiting for all subprocesses done…
Task 3 runs 0.31 seconds.
Run task 4 (3130)…
Task 4 runs 0.39 seconds.
Task 2 runs 0.82 seconds.
Task 1 runs 2.22 seconds.
Task 0 runs 2.64 seconds.
All subprocesses done.
# p=Pool(5) 可以同时跑5个进程
# Pool默认大小是cpu的核心数/如果你的cpu是8核/那么第九个子进程才会有上面的等待效果
# 有时候子进程可能会是一个外部程序/创建子程序/还需要控制子进程的输入和输出
# 1.3 subprocesses 方便启动一个子进程/控制输入和输出
import subprocessprint('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)>>>
$ nslookup www.python.org
Server: 192.168.31.1
Address: 192.168.31.1#53
Non-authoritative answer:
www.python.org canonical name = dualstack.python.map.fastly.net.
Name: dualstack.python.map.fastly.net
Address: 151.101.228.223
Exit code: 0
# 14.4 子进程输入
# 如果子进程需要输入/可以通过communicate()方法输入
import subprocessprint('$ nslookup')
p = subprocess.Popen(['nslookup'],stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
output,err=p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('utf-8'))
print('Exit code:', p.returncode)
# 相当于在命令行执行nslookup/然后手动输入
set q=mx
python.org
exit
>>>
$ nslookup
Server: 192.168.19.4
Address: 192.168.19.4#53
Non-authoritative answer:
python.org mail exchanger = 50 mail.python.org.
Authoritative answers can be found from:
mail.python.org internet address = 82.94.164.166
mail.python.org has AAAA address 2001:888:2000:d::a6
Exit code: 0
# 14.5 进程间通信
# multiprocessing模块包装了底层的机制/提供了Queue/Pipes等交流数据的方式
# 父进程创建两个子进程/一个往Queue写数据/一个往Queue读数据
from multiprocessing import Process,Queue
import os,time,random# %%
def write(q):print('Process to write: %s' % os.getpid())for value in ['A', 'B', 'C']:print('Put %s to queue...' % value)q.put(value)time.sleep(random.random())
# %%
def read(q):print('Process to read: %s' % os.getpid())while True:value = q.get(True)print('Get %s from queue.' % value)if __name__ == '__main__':# 父进程创建Queue/并且传递给各个子进程q = Queue()pw = Process(target=write,args=(q,))pr = Process(target=read,args=(q,))pw.start()pr.start()# 等待pw结束pw.join()# pr进入死循环/只能强制终止pr.terminate()
>>>
Process to read: 6466
Process to write: 6465
Put A to queue…
Get A from queue.
Put B to queue…
Get B from queue.
Put C to queue…
Get C from queue.
15.多线程
- 15.1 threading
- 15.2 Lock
- 15.3 threading.Lock
# 多个任务可以由多进程完成/也可以由一个进程的多个线程完成
# 一个进程至少一个线程
# Python的线程是真正的Posix Thread/不是模拟出来的线程
# python有两个模块:_thread/threading 大多数时候用threading
# 15.1 thread
# 启动一个线程就把一个函数传入并且创建Thread实例/然后调用start()开始执行
import time,threading# %%
def loop():print('thread %s is running...' %threading.current_thread().name)n = 0while n < 5:n = n + 1print('thread %s >>> %s' % (threading.current_thread().name,n))time.sleep(1)print('thread %s ended.' % threading.current_thread().name)
# %%
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop,name='LoopThread')
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
# %%
>>>
thread MainThread is running…
thread LoopThread is running…
thread LoopThread >>> 1
thread LoopThread >>> 2
thread LoopThread >>> 3
thread LoopThread >>> 4
thread LoopThread >>> 5
thread LoopThread ended.
thread MainThread ended.
# 15.2 Lock
# 多进程中/同一个变量/各自有一份拷贝存在于每个进程/互相不影响/
# 多线程中/所有变量都是线程共享的/多个线程同时改一个变量是风险极大的
# 改乱的例子
# %%
import time,threading# 这是你银行的存款
balance = 0def change_it(n):# 先存钱后取钱/结果应该是0global balancebalance = balance+nbalance = balance-ndef run_thread(n):for i in range(1000000):change_it(n)t1 = threading.Thread(target=run_thread,args=(5,))
t2 = threading.Thread(target=run_thread,args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
# 定义了一个共享变量balance/初始值0/启动两个线程/先存后取
# 理论结果是0
# t1/t2交替进行/只要循环次数足够多/balance的结果就不一定是0
# %%
>>>3
# 代码正常执行的时候
初始值 balance = 0t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t2: x2 = balance - 8 # x2 = 8 - 8 = 0
t2: balance = x2 # balance = 0结果 balance = 0
# t1/t2 出现的交叉执行时
初始值 balance = 0t1: x1 = balance + 5 # x1 = 0 + 5 = 5t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0t2: x2 = balance - 8 # x2 = 0 - 8 = -8
t2: balance = x2 # balance = -8结果 balance = -8
# 确保balance计算正确/就要给change_it上锁/
# 2.3 threading.Lockbalance = 0
lock = threading.Lock()def run_thread(n):for i in range(100000):# 先要获得锁lock.acquire()try:change_it(n)finally:lock.release()
-
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核。
-
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
-
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
-
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
-
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
16.ThreadLocal
# 多线程环境/每个线程都有自己的数据/一个线程使用自己局部变量比使用全局变量好/
# 因为局部变量只有线程自己能看见/全局变量要上锁
# 但是局部变量在函数调用和传递的时候很麻烦def process_student(name):std = Student(name)do_task_1(std)do_task_2(std)def do_task_1(std):do_subtask_1(std)do_subtask_2(std)def do_task_2(std):do_subtask_2(std)do_subtask_2(std)# 每个函数一层一层的调用太麻烦/全局变量也不可以/因为每个线程处理的对象不同/不能共享
# ThreadLocal
import threading# 创建全局threadLocal对象
local_school = threading.local()def process_student():# 获得当前线程关联的studentstd = local_school.studentprint('Hello, %s (in %s)' % (std, threading.current_thread().name))def process_thread(name):# 绑定ThreadLocal的student:local_school.student = nameprocess_student()t1 = threading.Thread(target=process_thread,args=('Alice',),name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
>>>
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)
- 可以理解全局变量local_school是一个dict/不但可以用local_school.student/还可以绑定其他属性
- ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接/HTTP请求/用户信息等/这样一个线程的所有调用到的处理函数都可以非常方便访问这些资源
- 一个ThreadLocal变量虽然是全局变量/每个线程都只能读写自己线程的独立副本/互不干扰/ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题
一些常用函数
1.datetime
- 1.1获得当前日期和时间
- 1.2获得指定日期和时间
- 1.3timestamp
- 1.4str转换为datetime
- 1.5本地时间转为UTC时间
- 1.6时区转换
# 1.1获得当前日期和时间
from datetime import datetime
now = datetime.now()
print(now)
print(type(now))
# datetime是模块/datetime模块包含了一个datetime类/
# 通过from datetime import datetime /导入的datetime类
# 仅导入import datetime/必须引用全名datetime.datetime
>>>
2020-01-29 19:34:03.067962
<class ‘datetime.datetime’>
# 1.2获得指定日期和时间
from datetime import datetime
dt = datetime(2020,1,20,12,12)
print(dt)
>>>2020-01-20 12:12:00
# 1.3 datetime转为timestamp
# 我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0
# 1970年以前的时间timestamp为负数,当前时间就是相对于epoch time的秒数,称为timestamp。# 相当于
timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00
# 北京时间相当于
timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00
- 可见timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)
# 1.3 timestamp
# timestamp可以直接被转化成标准时间
from datetime import datetime
t = 1429417200.0
print(datetime.fromtimestamp(t)) # 本地时间
print(datetime.utcfromtimestamp(t)) # utc时间>>>
2015-04-19 12:20:00
2015-04-19 04:20:00
# 1.4str转换为datetime
# 用户输入的日期和时间是字符串/处理的时间日期/
# datetime.strptime()
from datetime import datetime
cday = datetime.strptime('2020-1-1 19:00:00','%Y-%m-%d %H:%M:%S')
print(cday)
>>>2020-01-01 19:00:00
# 现在我们有datetime对象/把它格式化为字符串显示给用户/需要转换为str/
# strftime()
from datetime import datetime
now = datetime.now()
print(now.strftime('%a, %b %d %H:%M'))
>>>Thu, Jan 30 14:14
# 1.5datetime加减
# 对日期和时间进行加减实际就是把datetime往后或往前计算/得到新的datetime
# 加减可以直接用+-运算符/需要使用timedelta
from datetime import datetime,timedelta
now = datetime.now()
now
>>>datetime.datetime(2020, 1, 30, 14, 19, 8, 974859)now+timedelta(hours=10)
>>>datetime.datetime(2020, 1, 31, 0, 19, 8, 974859)now-timedelta(days=1)
>>>datetime.datetime(2020, 1, 29, 14, 19, 8, 974859)now+timedelta(days=2,hours=12)
>>>datetime.datetime(2020, 2, 2, 2, 19, 8, 974859)
# 1.5 本地时间转为UTC时间
# tzinfo
from datetime import datetime,timedelta,timezone
tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00
now = datetime.now()
now
>>>datetime.datetime(2020, 1, 30, 14, 34, 10, 598601)dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00
dt
>>>datetime.datetime(2020, 1, 30, 14, 34, 10, 598601, tzinfo=datetime.timezone(datetime.timedelta(seconds=28800)))
# 1.6时区转换
# 可以通过utcnow()拿到UTC时间/再转换为任意时区的时间
# 拿到UTC时间/强制设置时区UTC+0:00
utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc)
print(utc_dt)
>>>2020-01-30 06:39:29.334860+00:00# astimezone 把时区转换为北京时间
bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8)))
print(bj_dt)
>>>2020-01-30 14:39:29.334860+08:00
2.collections
- 2.1 namedtuple
- 2.2 deque
- 2.3 defaultdict
- 2.4 OrderedDict
- 2.5 ChainMap
- 2.6 counter
# 2.1 namedtuple
# 用来创建一个自定义的tuple对象/规定了tuple元素的个数/可以用属性而不是索引来引用tuple的某个元素
# 具备tuple的不变性/又可以根据属性来引用/方便
from collections import namedtuple
Point = namedtuple('Point',['x','y'])
p = Point(1,2)
p.x
>>>1p.y
>>>2isinstance(p,Point)
>>>Trueisinstance(p,tuple)
>>>True
# 2.2 deque
# deque是为了高效实现插入和删除操作的双向列表/适合于队列和栈
from collections import deque
q = deque(['a','b','c'])
q.append('x')
q.appendleft('y') # 还支持popleft()
q
>>>deque([‘y’, ‘a’, ‘b’, ‘c’, ‘x’])
# 2.3 defaultdict
# 使用dict/加入key不存在就会抛出KeyError/如果希望key不存在时/返回默认值
from collections import defaultdict
dd = defaultdict(lambda:'N/A')
dd['key1'] = 'abc'
dd['key1']
>>>'abc'dd['key2']
>>>'N/A'
# 2.4 OrderedDict
# 要保持key的顺序/可以用OrderedDict
from collections import OrderedDict
d = dict([('a',1),('b',2),('c',3)])
d
>>>{'a': 1, 'c': 3, 'b': 2}od = OrderedDict([('a',1),('b',2),('c',3)])
od
>>>OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# key会按照插入的顺序排列/不是key本身排序
od = OrderedDict()
od['z'] = 1
od['y'] = 2
od['x'] = 3
list(od.keys())
>>>[‘z’, ‘y’, ‘x’]
# 可以用来实现一个FIFO的dict/当容量超出限制/先删除最早添加的key
from collections import OrderedDictclass LastUpdatedOrderedDict(OrderedDict):def __init__(self,capacity):super(LastUpdatedOrderedDict,self).__init__self._capacity = capacitydef __setitem__(self,key,value):containsKey = 1 if key in self else 0if len(self) - containsKey >= self._capacity:last = self.popitem(last=False)print('remove:',last)if containsKey:del self[key]print('set:',(key,value))else:print('add:',(key,value))OrderedDict.__setitem__(self,key,value)
# 2.5 ChainMap
# 把一组dict穿起来并组成一个逻辑上的dict
# ChainMap本身就是dict/但是查找的时候/会按照顺序在内部的dict依次查找
# 例子:应用程序需要传入参数/参数可以通过命令行传入/可以通过环境变量传入/可以有默认参数
# 通过ChainMap实现参数的优先级查找/即先查找命令行参数/如果没有传入/再查找环境变量/如果没有就是用默认参数from collections import ChainMap
import os,argparse# 构造缺省参数
defaults = {'color':'red','user':'guest'
}# 构造命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('-u','--user')
parser.add_argument('-c','--color')
namespace = parser.parse_args()
command_line_args = {k:v for k,v in vars(namespace).items() if v}# 组合成ChainMap
combined = ChainMap(command_line_args,os.environ,defaults)print('color=%s'%combined['color'])
print('user=%s'%combined['user'])
# 没有任何参数/打印处默认参数
$ python3 use_chainmap.py
color=red
user=guest
# 传入命令行参数/优先使用命令行参数
$ python3 use_chainmap.py -u sb
color=red
user=sb
# 同时传入命令行参数和环境变量/命令行参数的优先级高
$ user=admin color=green python3 use_chainmap.py -u sb
color=green
user=sb
# 2.6 counter
from collections import Counter
c = Counter()
for ch in 'programming':c[ch] = c[ch] + 1
c
>>>Counter({'p': 1, 'r': 2, 'o': 1, 'g': 2, 'a': 1, 'm': 2, 'i': 1, 'n': 1})c.update('hello')
c
>>>Counter({'p': 1,'r': 2,'o': 2,'g': 2,'a': 1,'m': 2,'i': 1,'n': 1,'h': 1,'e': 1,'l': 2})
3.struct
- python没有专门处理字节的数据类型/但是b’str’可以表示字节/字节数组=二进制str
- c语言中/可以用struct/union处理字节/以及字节和int/float的转换
# struct模块解决bytes和其他二进制数据类型的转换
# struct的pack函数把任意数据类型变成bytes
import struct
struct.pack('>I',10240099)
>>>b’\x00\x9c@c’
- pack的第一个参数是处理指令/'>'表示字节顺序是big-endian/I表示4字节无符号整数
4.itertools
- itertools提供了非常有用的用于操作迭代对象的函数
import itertools
natuals = itertools.count(1)
for n in natuals:print(n)
# 会创建一个无限的迭代器/所以会打印出自然数序列/停不下来
# cycle()会把一个序列无限重复下去
import itertools
cs = itertools.cycle('ABC')
for c in cs:print(c)
# 同样一直重复
# repeat() 负责把一个元素无限重复下去/提供第二个参数可以限定重复次数
ns = itertools.repeat('A',2)
for n in ns:print(n)
>>>
A
A
# takewhile()根据条件判断来截取一个有限的序列
natuals = itertools.count(1)
ns = itertools.takewhile(lambda x:x <= 3,natuals)
list(ns)
>>>[1, 2, 3]
# chain()可以把一组迭代对象串联/形成一个更大的迭代器
for c in itertools.chain('ABC','XYZ'):print(c)>>>A B C X Y Z
# groupby()把迭代器中相邻的重复元素挑出来
for key,group in itertools.groupby('AAAABBCAAA'):print(key,list(group))
>>>
A [‘A’, ‘A’, ‘A’, ‘A’]
B [‘B’, ‘B’]
C [‘C’]
A [‘A’, ‘A’, ‘A’]
相关文章:

Python教程——最后一波来喽
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.使用__slots__2. property3.多重继承 4.定制类5.枚举类6.错误处理7.调试8. 文档测试9.单元测试10. 文件读写11. StringIO和BytesIO12. 操作文件和目录13.序列化14…...
)
学生管理系统(python实现)
新增学生显示学生查找学生删除学生存档到文件 约定好数据的存储格式: 约定把数据保存在和py文件同级目录中,文件名为record.txt 文件内容按照行文本的方式来表示 首先这是一个文本文件,里面包含了很多行,每一行代表一个学生 …...
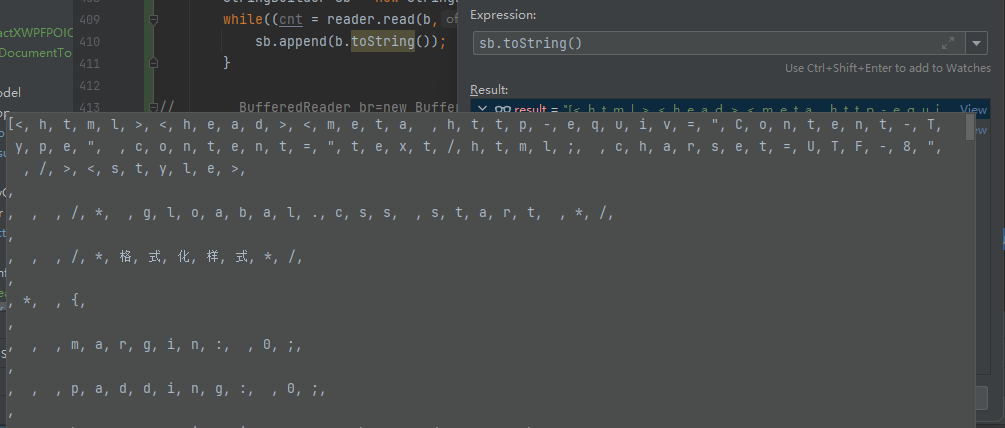
Java读取文件
读取文件为String 、访问链接直接跳转html 环境:SpringMVC 、前端jsp InputStreamReader FileInputStream fileInputStream new FileInputStream(formatFile.getHtmlpath());InputStreamReader reader new InputStreamReader(fileInputStream, StandardCharsets…...

曾桂华:车载座舱音频体验探究与思考| 演讲嘉宾公布
智能车载音频 I 分论坛将于3月27日同期举办! 我们正站在一个前所未有的科技革新的交汇点上,重塑我们出行体验的变革正在悄然发生。当人工智能的磅礴力量与车载音频相交融,智慧、便捷与未来的探索之旅正式扬帆起航。 在驾驶的旅途中࿰…...
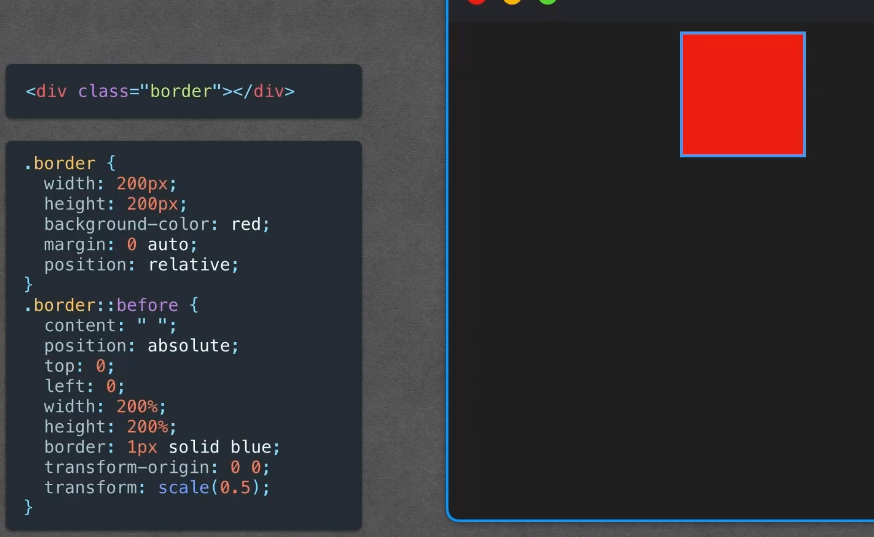
面试题HTML+CSS+网络+浏览器篇
文章目录 Css预处理sass less是什么?为什么使用他们怎么转换 less 为 css?重绘和回流是什么http 是什么?有什么特点HTTP 协议和 HTTPS 区别什么是 CSRF 攻击HTML5 新增的内容有哪些Css3 新增的特性flex VS grid清除浮动的方式有哪些ÿ…...
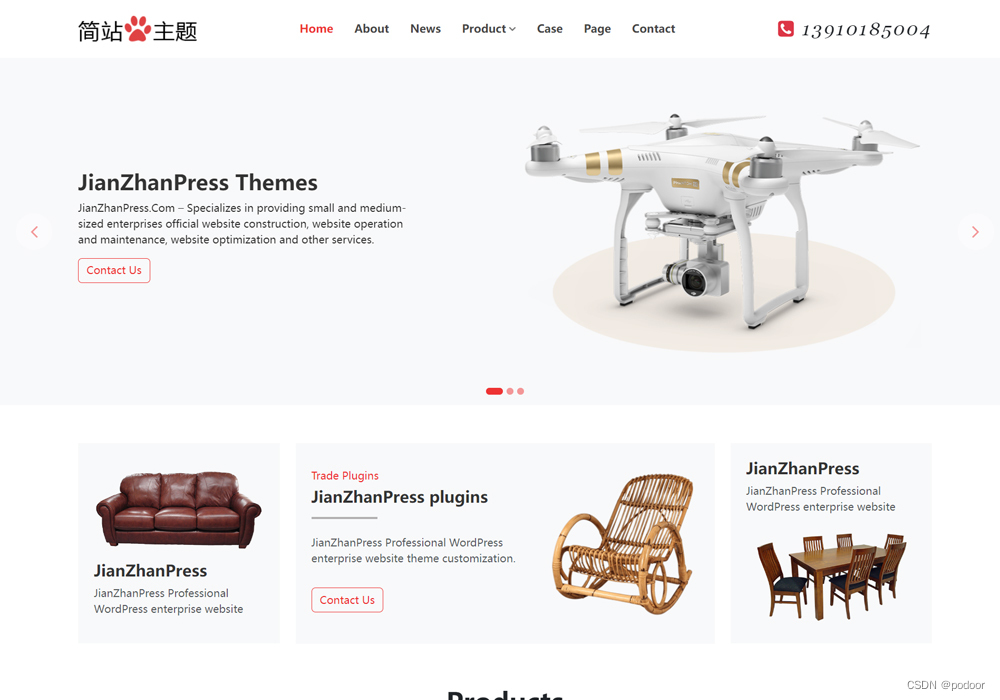
wordpress外贸独立站
WordPress外贸电商主题 简洁实用的wordpress外贸电商主题,适合做外贸跨境的电商公司官网使用。 https://www.jianzhanpress.com/?p5025 华强北面3C数码WordPress外贸模板 电脑周边、3C数码产品行业的官方网站使用,用WordPress外贸模板快速搭建外贸网…...
)
[python] 构建数据流水线(pipeline)
Plum 是一个用于构建数据流水线(pipeline)的 Python 库,它旨在简化和优化数据处理流程,使得数据流转和处理变得更加清晰、高效和可维护。下面我将更详细地介绍 Plum 的特点、功能和使用方法。 Plum 的主要特点和功能:…...

计算机网络-网络互连和互联网(五)
1.路由器技术NAT: 网络地址翻译,解决IP短缺,路由器内部和外部地址进行转换。静态地址转换:静态NAT(一对一) 静态NAT,内外一对一转换,用于web服务器,ftp服务器等固定IP的…...

【深度学习】Pytorch基础
张量 运算与操作 加减乘除 pytorch中tensor运算逐元素进行,或者一一对应计算 常用操作 典型维度为N X C X H X W,N为图像张数,C为图像通道数,HW为图高宽。 sum() 一般,指定维度,且keepdimTrue该维度上元…...

C++模拟揭秘刘谦魔术,领略数学的魅力
新的一年又开始了,大家新年好呀~。在这我想问大家一个问题,有没有同学看了联欢晚会上刘谦的魔术呢? 这个节目还挺有意思的,它最出彩的不是魔术本身,而是小尼老师“念错咒语”而导致他手里的排没有拼在一起,…...

JAVA语言编写一个方法,两个Long参数传入,使用BigDecimal类,计算相除四舍五入保留2位小数返回百分数。
在Java中,你可以使用BigDecimal类来执行精确的浮点数计算,并且可以指定结果的小数位数。以下是一个方法,它接受两个Long类型的参数,并使用BigDecimal来计算它们的商,然后将结果四舍五入到两位小数,并返回一…...

SQL教学:掌握MySQL数据操作核心技能--DML语句基本操作之“增删改查“
大家好,今天我要给大家分享的是SQL-DML语句教学。DML,即Data Manipulation Language,也就是我们常说的"增 删 改 查",是SQL语言中用于操作数据库中数据的一部分。作为MySQL新手小白,掌握DML语句对于数据库数…...
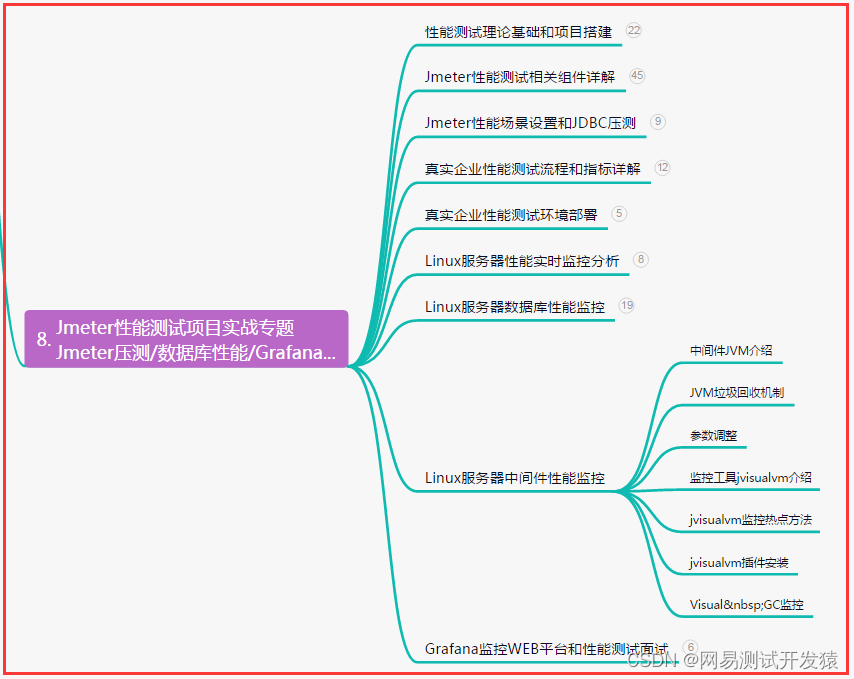
【性能测试】Jmeter性能压测-阶梯式/波浪式场景总结(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、阶梯式场景&am…...
前端面试 跨域理解
2 实现 2-1 JSONP 实现 2-2 nginx 配置 2-2 vue 开发中 webpack自带跨域 2 -3 下载CORS 插件 或 chrome浏览器配置跨域 2-4 通过iframe 如:aaa.com 中读取bbb.com的localStorage 1)在aaa.com的页面中,在页面中嵌入一个src为bbb.com的iframe&#x…...
JetBrains TeamCity 身份验证绕过漏洞复现(CVE-2024-27198)
0x01 产品简介 JetBrains TeamCity是一款由JetBrains开发的持续集成和持续交付(CI/CD)服务器。它提供了一个功能强大的平台,用于自动化构建、测试和部署软件项目。TeamCity旨在简化团队协作和软件交付流程,提高开发团队的效率和产品质量。 0x02 漏洞概述 JetBrains Team…...

设计模式—单例模式
单例模式(Singleton Pattern)是一种常用的软件设计模式,其核心思想是确保一个类仅有一个实例,并提供一个全局访问点来获取这个实例。单例模式主要用于控制资源的访问,比如配置文件的读取,数据库的连接等&am…...

Android在后台读取UVC摄像头的帧数据流并推送
Android在后台读取UVC摄像头的帧数据流并推送 添加UvcCamera依赖库 使用原版的 saki4510t/UVCCamera 在预览过程中断开可能会闪退,这里使用的是 jiangdongguo/AndroidUSBCamera 中修改的版本,下载到本地即可。 https://github.com/jiangdongguo/AndroidU…...

vue单向数据流介绍
Vue.js 的单向数据流是其核心设计原则之一,也是 Vue 响应式系统的基础。在 Vue.js 中,数据流主要是单向的,从父组件流向子组件。这种设计有助于保持组件之间的清晰通信,减少不必要的复杂性和潜在的错误。 以下是 Vue 单向数据流的…...

OpenMMlab AI实战营第四期培训
OpenMMlab AI实战营第四期培训 OpenMMlab实战营第四次课2023.2.6学习参考一、什么是目标检测1.目标检测下游视觉任务2.图像分类 v.s. 目标检测 二、目标检测实现1.滑窗 Sliding Window2.滑窗的效率问题3.改进思路(1)消除滑窗中的重复计算(2&a…...

React轻松开发平台:实现高效、多变的应用开发范本
在当今快节奏的软件开发环境中,追求高效、灵活的应用开发方式成为了开发团队的迫切需求。React低代码平台崭露头角,为开发人员提供了一种全新的开发范式,让开发过程更高效、更灵活,从而加速应用程序的开发周期和交付速度。 1. 快…...
)
告别黑白DEM!GeoServer发布地形图的样式美化实战(附完整SLD代码)
告别黑白DEM!GeoServer发布地形图的样式美化实战(附完整SLD代码) 当你在GeoServer中发布DEM数据时,是否遇到过这样的困扰:明明精心准备了高程数据,预览时却只能看到一片单调的灰度图像?这种&quo…...

Unity项目性能优化实战:除了Simplygon,还有哪些轻量级减面工具和技巧?
Unity项目性能优化实战:轻量级减面工具与技巧全解析 在Unity项目开发中,3D模型的性能优化是一个永恒的话题。当项目规模扩大、场景复杂度提升时,模型面数往往会成为性能瓶颈的首要因素。Simplygon作为业界知名的减面工具,虽然功能…...

QiMeng-TensorOp:自动生成高性能张量运算代码的框架
1. 项目概述QiMeng-TensorOp是一个革命性的张量算子自动生成框架,它能够基于硬件原语自动生成高性能的张量运算代码。在现代深度学习和大型语言模型(LLMs)中,张量运算如矩阵乘法(GEMM)和卷积(Conv)占据了90%以上的计算量。传统的手动优化方法需要数月时间…...

别再死记公式了!用Cadence仿真带你直观理解比较器的增益、失调与噪声
Cadence实战:用仿真可视化比较器的增益、失调与噪声特性 刚接触模拟电路设计时,那些复杂的公式和抽象概念总让人头疼。比较器的增益、失调电压、噪声——这些名词在教科书上看起来冰冷生硬,但当你第一次在Cadence Virtuoso中看到它们如何真实…...

远程技术面试的潜规则:摄像头角度可能影响你的录用
一、摄像头角度:被忽视的专业细节在软件测试的工作中,我们习惯用严谨的态度去排查代码里的每一个bug,用精准的测试用例去验证产品的每一项功能。但在远程技术面试这个特殊的“测试场景”里,很多人却忽略了一个看似无关紧要&#x…...

独立开发者如何利用Taotoken的透明计费规避项目超支风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的透明计费规避项目超支风险 对于独立开发者而言,项目预算的控制是决定项目能否持续、健康…...

避开DSP28335内存管理的坑:堆、栈、CMD文件配置全解析与最佳实践
DSP28335内存管理深度优化:从堆栈原理到CMD文件实战配置 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。对于基于TI C2000系列DSP28335的开发者而言,合理规划有限的内存资源不仅能提升系统性能,更能避免那些难以…...

观察使用 Taotoken Token Plan 套餐后的月度成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用 Taotoken Token Plan 套餐后的月度成本变化 对于个人开发者或小型团队而言,大模型 API 的调用成本是项目预算…...

Pure Live完整指南:3分钟掌握跨平台纯净直播聚合工具
Pure Live完整指南:3分钟掌握跨平台纯净直播聚合工具 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 在当今数字娱乐时代,直播已成为人们日常娱乐的重…...

ElevenLabs缅甸文TTS落地难题全拆解:从音素对齐失败到语调失真,3步精准修复
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs缅甸文TTS落地难题的根源认知 ElevenLabs官方API当前未原生支持缅甸文(Burmese, my-MM),其语音合成模型训练语料库中缺乏足够规模、高质量、带韵律标注的缅…...