CDH6.3.1离线安装
一、从官方文档整体认识CDH
官方文档地址如下:
CDH Overview | 6.3.x | Cloudera Documentation
CDH是Apache Hadoop和相关项目中最完整、测试最全面、最受欢迎的发行版。CDH提供Hadoop的核心元素、可扩展存储和分布式计算,以及基于Web的用户界面和重要的企业功能。是唯一一个提供统一批处理、 交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。
下面是官方的组件架构图:

二、安装包下载
现在官网下载需要注册,百度网盘共享一份出来,整个过程所需的安装包都在里面了,能不能给个👍
链接: https://pan.baidu.com/s/1Qc4S93QB8krrcFmXqQwNNA 提取码: jfji
三、VMware准备三台Linux操作虚拟机
在我的博客<cdh适配国产化操作系统>中有讲到CDH支持的操作系统以及版本,有在国产化操作系统上安装的需求可以看我这一份博客,这次我们选择CDH支持的最高版本操作系统:Centos7.9

后面按照步骤和提示走就行,因为是离线安装,这里选择仅主机模式
根据做好的一台的源文件目录复制两份修改下名字,再从VMware打开就好

| 主机名 | ip | 内存 | 磁盘 | 操作系统 | 备注 |
| cdh1 | 192.168.200.131 | 3G | 30G | centos7.9 | 后面升级到了6G |
| cdh2 | 192.168.200.132 | 3G | 30G | centos7.9 | |
| cdh3 | 192.168.200.133 | 3G | 30G | centos7.9 |
如果你的资源丰富尽量磁盘和内存都给大点
四、环境准备
用SecureCRT分别连接三台服务器,方便以后批量操作(需要先关闭每台服务器上的防火墙)
选择 View>Chat Window
右键选择Send chat to all tabs
如果服务器时间不是东八区时间,需要修改/etc/localtime的软连接指向
unlink /etc/localtime
ln -s /usr/share/zoneinfo/UTC /etc/localtime
1、修改主机名
vi /etc/hostname 或 hostnamectl set-hostname 主机名
检测:hostname

2、修改域名映射
vi /etc/hosts
末尾追加
192.168.200.131 cdh1
192.168.200.132 cdh2
192.168.200.133 cdh3

3、关闭防火墙
systemctl stop firewalld
查看防火墙状态
systemctl status firewalld
永久关闭防火墙
systemctl disable firewalld.service
4、关闭selinux
vi /etc/selinux/config
SELINUX=enforcing 改为 SELINUX=disabled
5、永久关闭ipv6
vi /etc/sysctl.conf
# 禁用整个系统所有接口的IPv6,可以只简单的设置这一个参数,用来关闭所有接口的 IPv6
net.ipv6.conf.all.disable_ipv6=1
# 禁用某一个指定接口的IPv6(例如:eth0, eth1)
net.ipv6.conf.eth0.disable_ipv6=1
net.ipv6.conf.eth1.disable_ipv6=1
6、设置swap空间
临时修改
sysctl vm.swappiness=0
# 查看是否修改成功
cat /proc/sys/vm/swappiness
永久修改
echo 'vm.swappiness=0' >> /etc/sysctl.conf
# 执行以下命令,可以让修改立即生效
sysctl -p
7、关闭大页面压缩
临时生效
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
永久生效
echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
chmod +x /etc/rc.local
8、最大数限制
vi /etc/security/limits.conf
* soft nofile 65535
* hard nofile 1024999
* soft nproc 65535
* hard noroc 65535
* soft memlock unlimited
* hard memlock unlimited
如果不修改,计算数据量增大时会报 打开的文件数过多 错误 ,因为linux处处皆文件,所以也会限制socket打开的数量,当各个节点数据传输增大时就会导致整个错暴漏出来
9、操作系统内核调优-网络部分
vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 1000 65534
net.ipv4.tcp_fin_timeout=30
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_recycle=1
如果 小文件特别多,错误文件特别多(主要时受损的压缩文件) 这个时候就会报如下错:
23/11/28 17:11:58 WARN hdfs.DFSClient: Failed to connect to /10.183.243.230:9866 for block BP-1901849752-10.183.243.230-1672973682151:blk_1074692119_951295, add to deadNodes and continue.
java.net.BindException: Cannot assign requested address
“Cannot assign requested address.”是由于linux分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于TIME_WAIT状态,默认等待60s后才释放,端口才可以继续使用。在http查询中,需要发送大量的短连接,这样的高并发的场景下,就会出现端口不足,从而抛出Cannot assign requested address的异常。
查看当前linux系统的可分配端口
cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
当前系统的端口数范围为32768~60999, 所以能分配的端口数为28231。如果我的连接数达到了28231个,就会报如上错误。
1、修改端口范围
vi /etc/sysctl.conf
#1000到65534可供用户程序使用,1000以下为系统保留端口
net.ipv4.ip_local_port_range = 1000 65534
2、配置tcp端口的重用配置,提高端口的回收效率
vi /etc/sysctl.conf
#调低端口释放后的等待时间,默认为60s,修改为15~30s 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_fin_timeout=30
#修改tcp/ip协议配置, 通过配置/proc/sys/net/ipv4/tcp_tw_resue, 默认为0,修改为1,释放TIME_WAIT端口给新连接使用
net.ipv4.tcp_timestamps=1
#修改tcp/ip协议配置,快速回收socket资源,默认为0,修改为1 需要开启net.ipv4.tcp_timestamps该参数才有效果
#更不为提到却很重要的一个信息是:当tcp_tw_recycle开启时(tcp_timestamps同时开启,快速回收socket的效果达到),对于位于NAT设备后面的Client来说,是一场灾难——会导到NAT设备后面的Client连接Server不稳定(有的Client能连接server,有的Client不能连接server)。也就是说,tcp_tw_recycle这个功能,是为“内部网络”(网络环境自己可控——不存在NAT的情况)设计的,对于公网,不宜使用。
net.ipv4.tcp_tw_recycle=1
10、重启机器使以上配置生效
reboot
11、时间同步
将ntp安装包上传至三台服务器/opt/software
cd /opt/software/ntp_rpm
需要用root用户来安装
rpm -Uvh *.rpm --nodeps --force
配置:
vi /etc/ntp.conf
这里选的cdh1为master,cdh2、cdh3为slaver
master:
注释掉其他server
填写
server 127.127.1.0
fudge 127.127.1.0 stratum 8
限制从节点ip段信息,可以不配置
restrict 192.168.200.0 mask 255.255.255.0 nomodify notrap
slaver:
server 192.168.200.131
启动、查看状态命令
systemctl status ntpd
systemctl restart ntpd
设置自动启动
systemctl enable ntpd
报错:
/lib64/libcrypto.so.10: version `OPENSSL_1.0.2' not found (required by /usr/sbin/ntpd)
解决
备份原有libcrypto.so.10
mv /usr/lib64/libcrypto.so.10 /usr/lib64/libcrypto.so.10_bak
从其他服务器找到对应的so文件复制到/usr/lib64目录下
cp libcrypto.so.1.0.2k /usr/lib64/libcrypto.so.10
手动同步
ntpdate -u ip
查看同步状态
ntpdc -np
ntpstat
12、安装java
解压并重置目录
tar -xzvf jdk-8u181-linux-x64.tar.gz
mkdir /usr/java
mv jdk1.8.0_181 /usr/java
配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
刷新配置
source /etc/profile
验证:
java -version
13、安装scala
rpm安装
rpm -Uvh scala-2.11.12.rpm --nodeps --force
验证:
scala -version
14、安装mysql
选择再cdh1上安装mysql
解压并重置目录
tar -xvf mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.7.11-linux-glibc2.5-x86_64 /usr/local/mysql
创建数据目录:
mkdir -p /data/mysql
编辑my.cnf配置文件
vi /etc/my.cnf
bind-address=0.0.0.0
port=3306
user=root
basedir=/usr/local/mysql
datadir=/data/mysql
socket=/tmp/mysql.sock
[mysqld_safe]
log-error=/data/mysql/mysql.err
pid-file=/data/mysql/mysql.pid
#character config
character_set_server=utf8mb4
symbolic-links=0
explicit_defaults_for_timestamp=true
!includedir /etc/my.cnf.d
初始化
cd /usr/local/mysql/bin/
./mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql/ --datadir=/data/mysql/ --user=root --initialize

记录这个临时密码:mF/bkx<)O1G,
启动mysql,并更改root 密码
cd /usr/local/mysql/support-files
cp mysql.server mysql
mv mysql /etc/init.d/
service mysql start
登录并修改密码
/usr/local/mysql/bin/mysql -uroot -p
alter user 'root'@'localhost' identified by 'test_1234';
grant all privileges on *.* to 'root'@'localhost' identified by 'test_1234' with grant option;
flush privileges;
创建Cloudera Manager用户和Hive metastore 相关用户(注意下面的大写不能修改成小写)
create database cmf default character set utf8;
create database hive default character set utf8;
GRANT ALL PRIVILEGES ON cmf.* TO 'cmf'@'%' IDENTIFIED BY 'test_1234';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' IDENTIFIED BY 'test_1234';
flush privileges;
重命名并在固定路径放置mysql驱动包
mkdir -p /usr/share/java/
cp /opt/software/mysql-connector-java-5.1.47.jar /usr/share/java/mysql-connector-java.jar
chmod 777 -R /usr/share/java
15、离线按照CDH相关服务
解压
tar -xzvf cm6.3.1-redhat7.tar.gz
查看CDH相关安装文件
cd /opt/software/cm6.3.1/RPMS/x86_64
ls -lh

主节点(cdh1)执行:
rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm --nodeps --force
rpm -ivh cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm --nodeps --force
rpm -ivh cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm --nodeps --force
从节点(cdh2、cdh3)执行:
rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm --nodeps --force
rpm -ivh cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm --nodeps --force
agent配置修改(因为所有节点都安装了agent,因此都需要执行,cdh1是server角色的主机名)
sed -i "s/server_host=localhost/server_host=cdh1/g" /etc/cloudera-scm-agent/config.ini
server配置修改(cdh1节点)
vi /etc/cloudera-scm-server/db.properties
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=mysql主机ip或者域名:端口(127.0.0.1:3306)
com.cloudera.cmf.db.name=cmf
com.cloudera.cmf.db.user=cmf
com.cloudera.cmf.db.password=test_1234
com.cloudera.cmf.db.setupType=EXTERNAL
16、安装httpd
只需要部署一台就行,这里选择cdh1
cd /opt/software/httpd_rpm
rpm -Uvh *.rpm --nodeps --force

17、部署离线parcel源
mkdir -p /var/www/html/cdh6_parcel
cp CDH-6.3.1-1.cdh6.3.1.p0.1470567-el7.parcel /var/www/html/cdh6_parcel
cp CDH-6.3.1-1.cdh6.3.1.p0.1470567-el7.parcel.sha1 /var/www/html/cdh6_parcel
cp manifest.json /var/www/html/cdh6_parcel
启动httpd
systemctl start httpd
浏览器可以访问到
18、启动Server和Agent
Server节点执行(cdh1)
systemctl enable cloudera-scm-server
systemctl start cloudera-scm-server
查看节点状态
systemctl status cloudera-scm-server

查看日志
cd /var/log/cloudera-scm-server
tail -f cloudera-scm-server.log

出现0.0.0.0:7180即为成功
Agent执行(三台全部执行)
systemctl enable cloudera-scm-agent
systemctl start cloudera-scm-agent
查看节点状态
systemctl status cloudera-scm-agent

五、根据页面指引安装
浏览器输入网址:http://192.168.200.131:7180/cmf/login

默认用户名密码都为admin

继续

勾选接收条款,继续

我们这里选择免费版,继续(如果选择试用版,到期不续费会自动转成免费版)

继续

起个自己喜欢的名字,继续
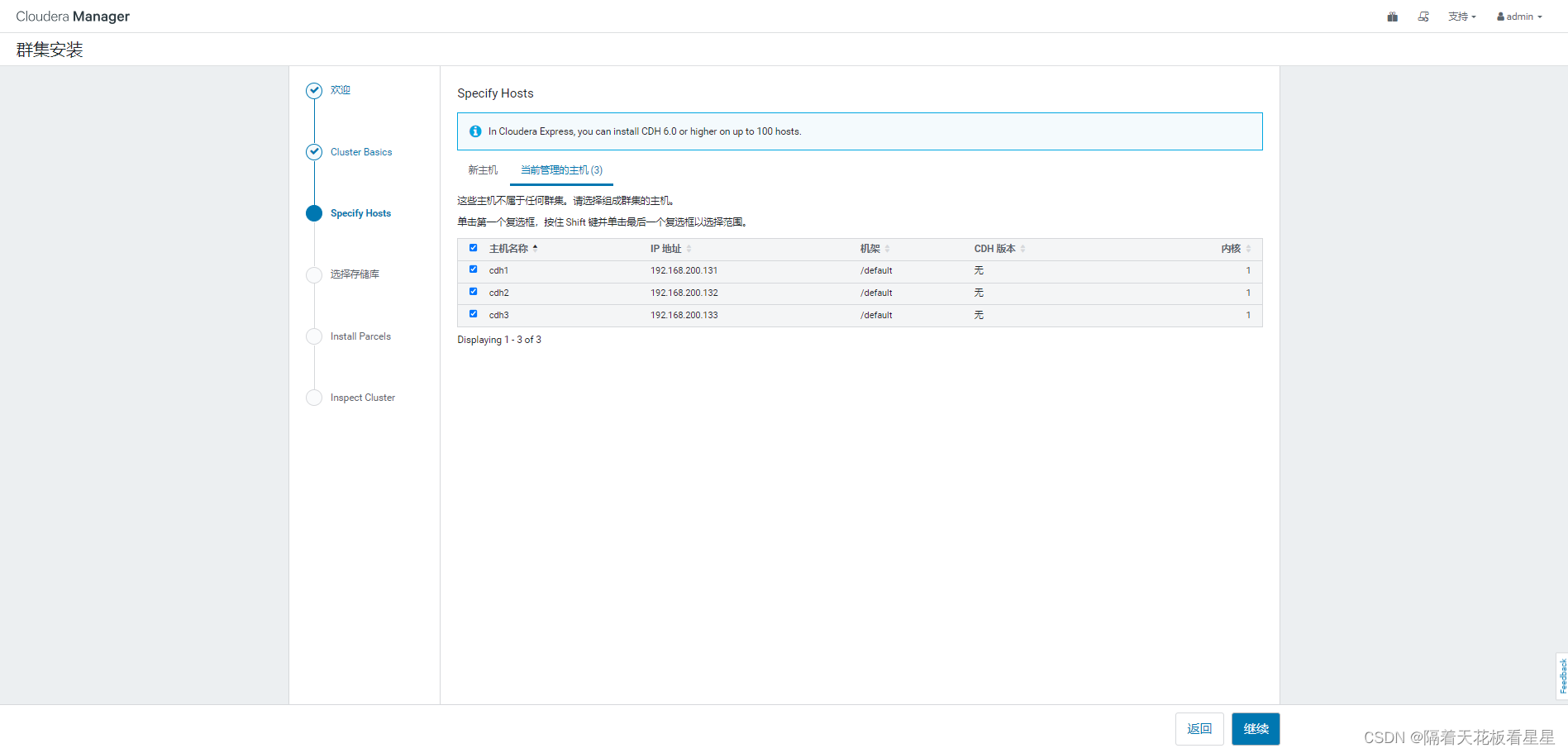
选择所有主机,继续(可以看到提示:在Cloudera Express中,您最多可以在100台主机上安装CDH 6.0或更高版本,即免费版本最多支持100台节点,对于我们学习和中小公司已经够用了)

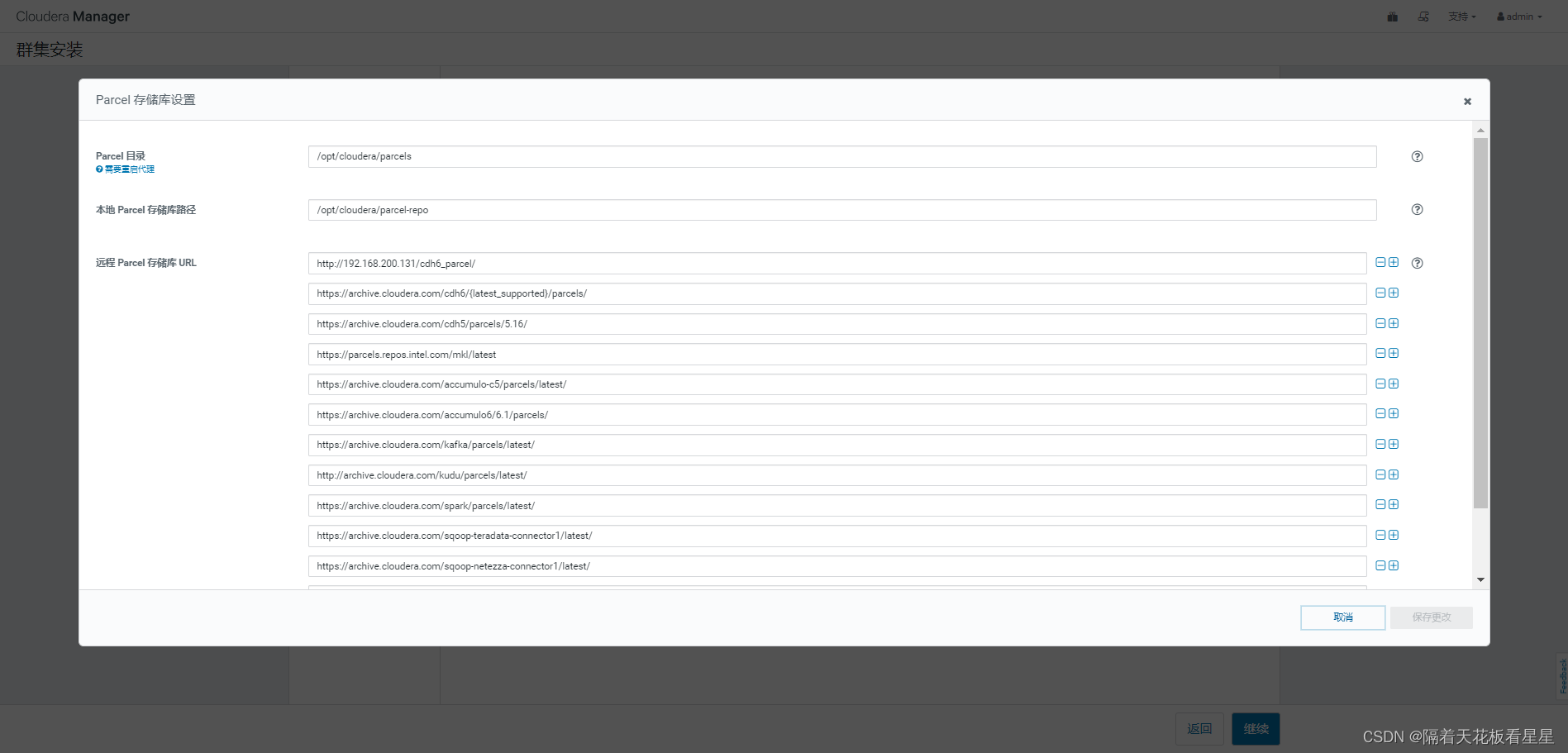
点击更多选项,把我们自己部署的离线parcel源地址填写上去(尽量写到第一行,不然可能识别不到),继续(且路径最后要夹/,不然也识别不了)
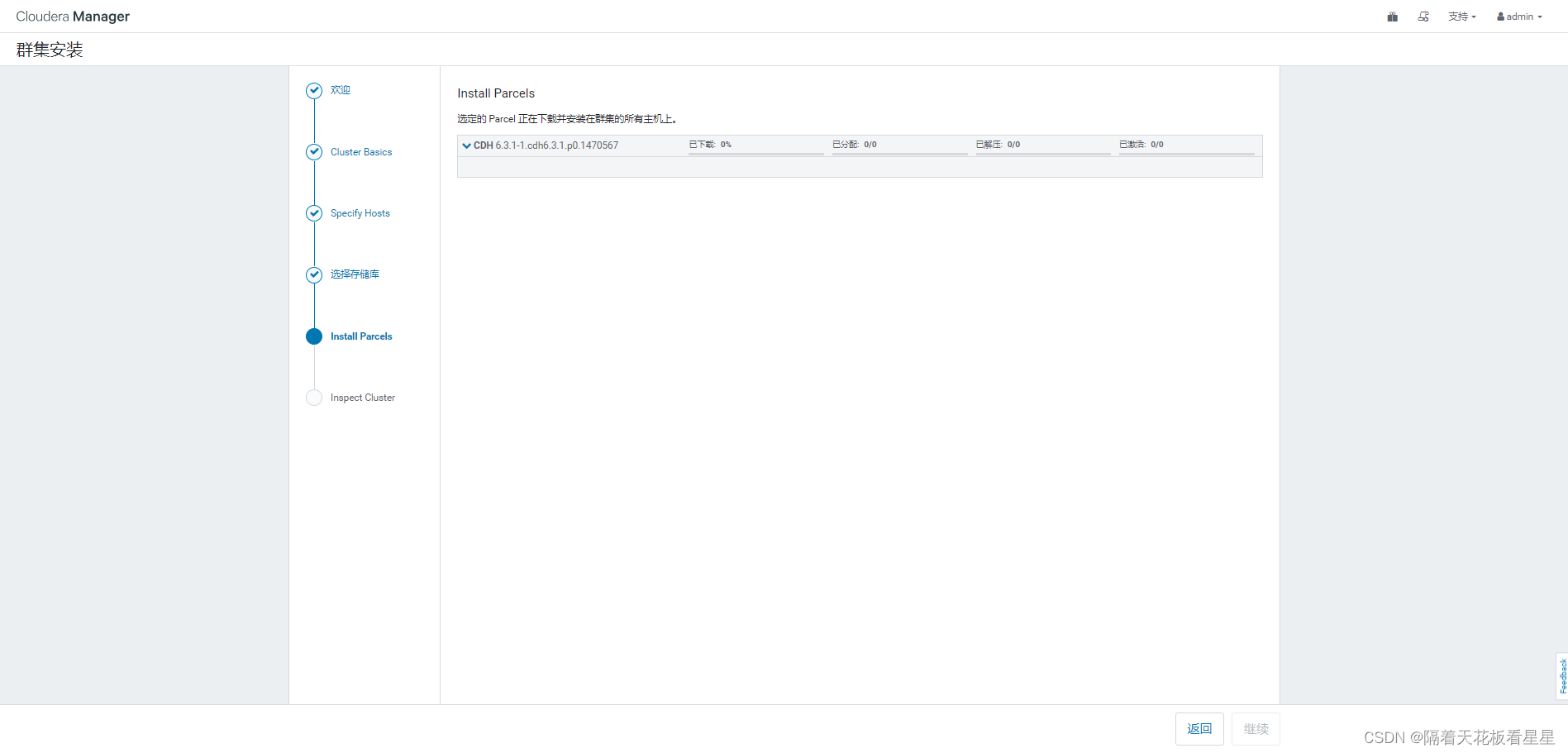
已经开始下载并往各个节点分发parce包了


全部过程走完后自动跳到下一页
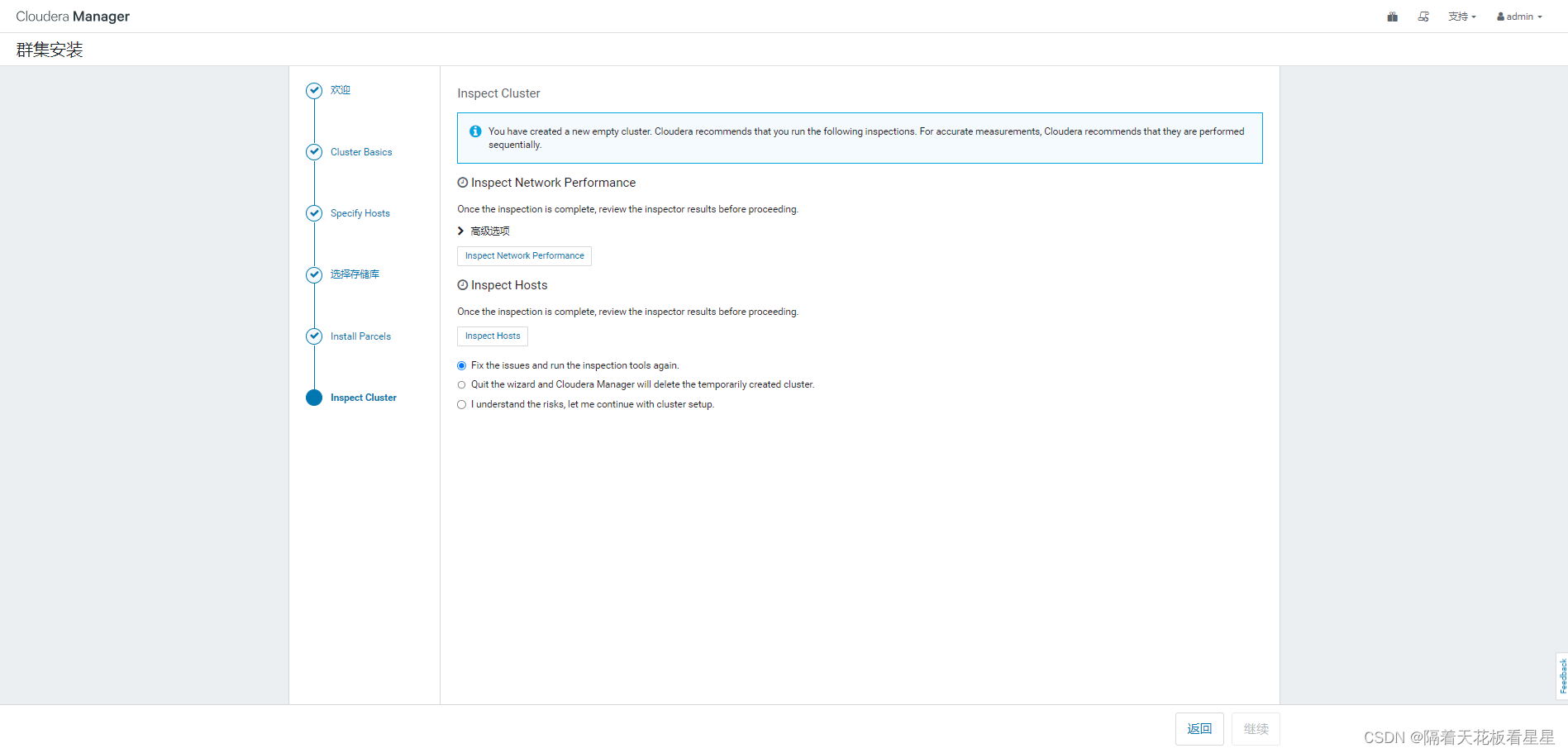

分别点击 Inspect Network Performance (检查网络性能)和 Inspect Hosts (检查主机连通性)
检查完我们勾选第3项(I understand the risks, let me continue with cluster setup.我了解风险,让我继续进行集群设置)继续,下面我们开始安装所需要的服务

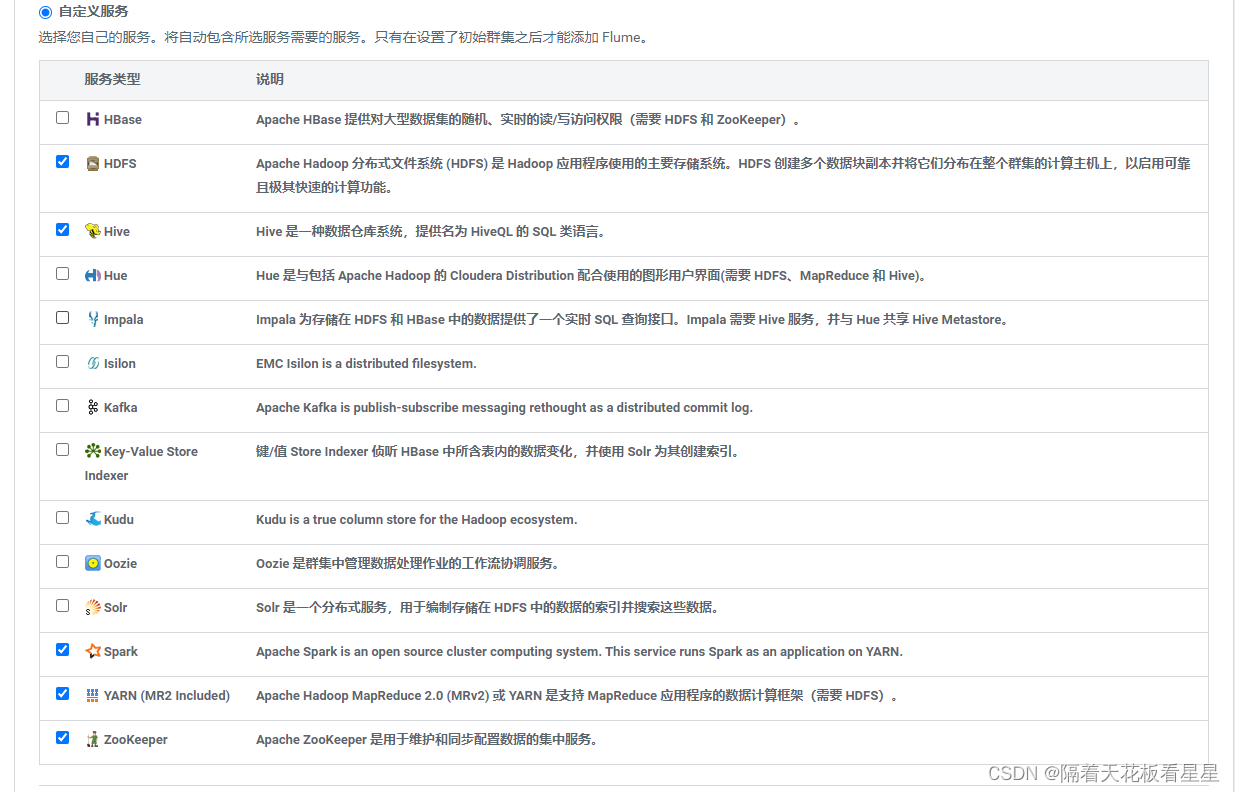
我们先选择自定义服务,以后学习一项技术我们安装一个组件(cdh这点非常好,全程界面安装,无需自己配置),继续

这里需要自己安排组件的哪些角色安装到哪些节点上,我们需要根据自己的机器性能和组件特性来合理安排,这里给出一些基本原则
1、内存最大的节点给NameNode
2、内存第二大的节点给ResourceManager
3、NameNode和secondaryNameNode不设置在同一节点
4、HiveMetastoreServer 和mysql 放在一个节点
5、Spark HistoryServer、YARN 的 JobHistory Server 和 NameNode 不放在同一节点上

填写hive、cmf在mysql中的相关信息,点击测试连接,点击继续

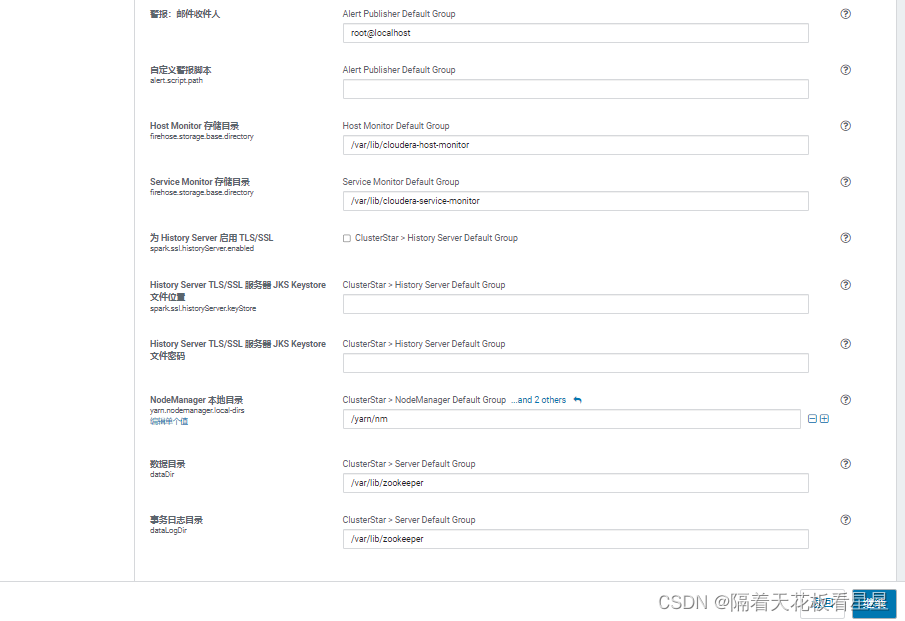
这里可以设置服务的详细配置,如果你的机器有挂载数据盘,尽量将所有数据目录指向你的数据盘,因为系统盘一般都支撑不了真实的业务,如果你公司对网络端口也有限制,需要在这里修改成符合公司网络管理的端口,继续

开始首次运行,我们静等是否报错(报错 -> 看日志 -> 解决报错)
经过重重解决,只留下了警告提示,主要原因都是虚拟机的配置太低了(磁盘不足),但是小数据量的测试还是可以的。


六、问题列举与解决
问题1:节点资源不足

安装过程中报错很正常,不要灰心,兵来将挡,水来土掩
先看下日志
[Errno 2] No such file or directory: '/var/log/zookeeper/zookeeper-cmf-zookeeper-SERVER-cdh1.log'
服务器上看了下,只有/var/log/zookeeper 目录,没有我们就创建一个试试
touch zookeeper-cmf-zookeeper-SERVER-cdh1.log
chown zookeeper:zookeeper zookeeper-cmf-zookeeper-SERVER-cdh1.log
重新运行下发现点不动了,我们进入首页看看哪个组件还报错,着重看下

Cloudera Manager Server GC cpu usage is at 10% or more of total process time.
还是节点性能问题,给cdh1的内存增加3G核数增加1个,重启看看

解决,但出现了第二个问题:时钟偏差
问题2:时钟偏差

我们手动同步下(cdh2、cdh3执行下)
ntpdate -u cdh1
静等一会儿,少了一个
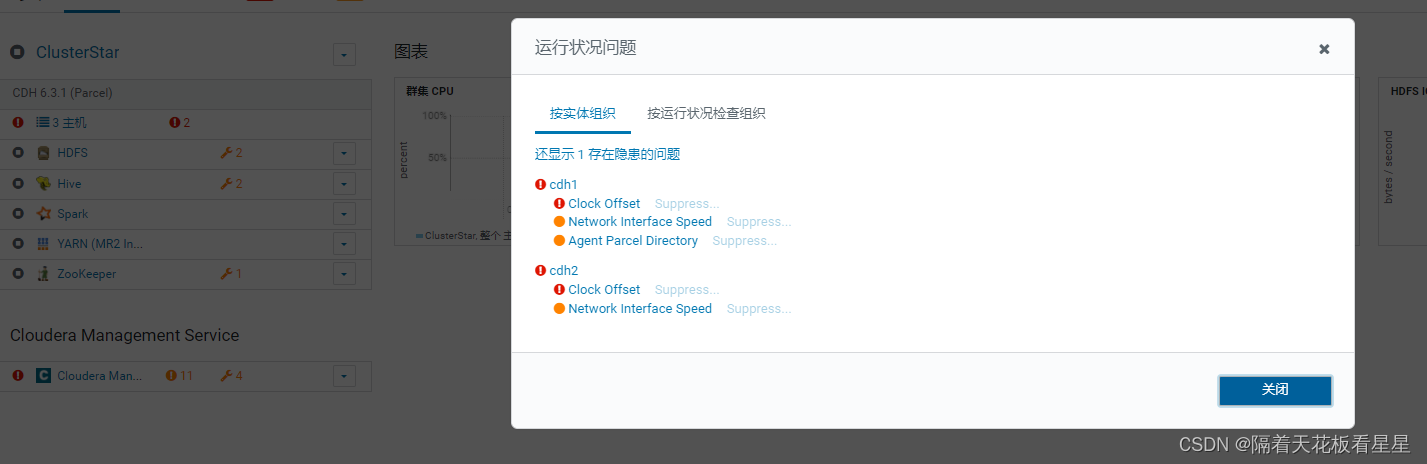
再等一会儿,就都没有了,实在不行就重启下ntp服务。最终都同步了



问题3:Yarn组件启动失败
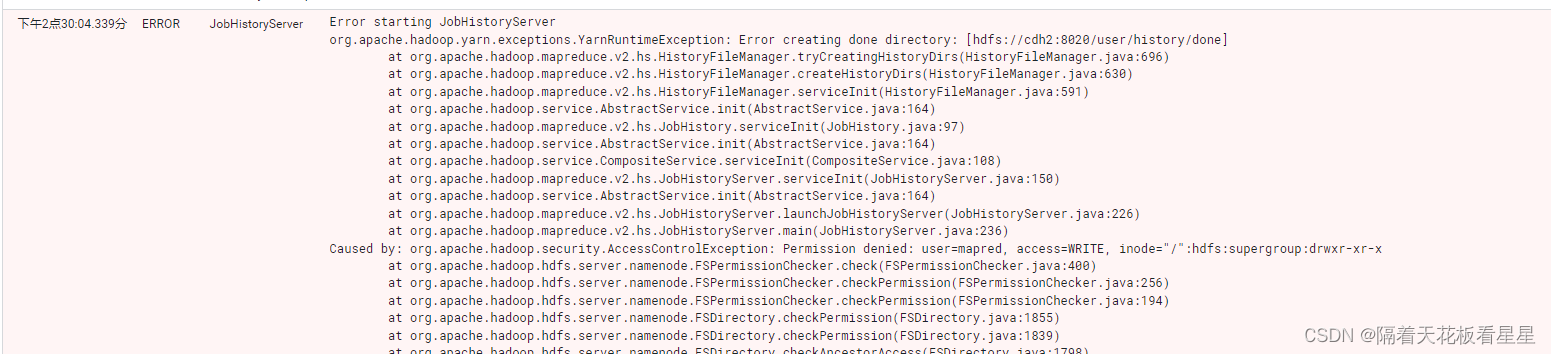
看日志是权限问题,手动创建也报权限问题
![]()
mkdir: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x
我们可以使用hdfs用户赋权下,也可以在HDFS界面上取消掉权限校验选项


问题4:Spark组件启动失败

File does not exist: hdfs://cdh2:8020/user/spark/applicationHistory
手动创建下该目录
hadoop fs -mkdir -p /user/spark/applicationHistory
问题5:Hive不能正常使用
![]()
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
需要初始化下元数据
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hive/bin/schematool -dbType mysql -initSchema

发现还是默认derby的,因此需要将hive-site.xml 中的hive元数据配置和连接数据库的驱动修改一下(为什么不在界面上改,因为我发现cm界面上是正确的,hive-site.xml中却没有相关配置,应该是最初启动是没有初始化成功,这不就导致了一致性问题吗,是不是cdh的一个bug,哈哈)
vi /etc/hive/conf.cloudera.hive/hive-site.xml
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
<description>元数据库类型指定为使用mysql</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>指定mysql的驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>指定元数据库用户</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>test_1234</value>
<description>指定元数据库密码</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://cdh1:3306/hive?createDatabaseIfNotExist=true</value>
<description>指定mysql连接串</description>
</property>
再次执行初始化,成功


界面重启hive,命令行创建成功

相关文章:
CDH6.3.1离线安装
一、从官方文档整体认识CDH 官方文档地址如下: CDH Overview | 6.3.x | Cloudera Documentation CDH是Apache Hadoop和相关项目中最完整、测试最全面、最受欢迎的发行版。CDH提供Hadoop的核心元素、可扩展存储和分布式计算,以及基于Web的用户界面和重…...

Pytorch之卷积操作
卷积是一种基本的数学操作,常用于信号处理和图像处理领域。在计算机视觉中,卷积操作是一种重要的技术,用于提取图像的特征并进行图像处理。 卷积操作基于一个卷积核(也称为滤波器或权重),它是一个小的矩阵…...

2024年春招小红书前端实习面试题分享
文章目录 导文面试重点一、方便介绍一下,你之前实习都做了什么嘛?二、 可以讲一下封装组件相关逻辑嘛?1. 为什么要封装组件?2. 封装组件的步骤3. 封装组件的原则4. 组件的复用和扩展5. 组件的维护和文档 三、项目的性能优化你有什…...
软件测试--性能测试工具JMeter
软件测试--性能测试工具JMeter 主流性能测试工具1.主流性能测试工具Loadrunner和Jmeter对比 —— 相同点2.主流性能测试工具Loadrunner和Jmeter对比 —— 不同点JMeter基本使用JMeter环境搭建1.安装JDK:2.安装Jmeter:3.注意点:JMeter功能概要1. JMeter文件目录介绍1.1 bin目…...
c++/c图的邻近矩阵表示
#include<iostream> using namespace std;#define MaxVerterNum 100 typedef char VerterType; typedef int EdgeType; typedef struct {VerterType vexs[MaxVerterNum]; // 存储顶点EdgeType edges[MaxVerterNum][MaxVerterNum]; // 存储邻接矩阵int n, e; // 顶点数和边…...

cocos-lua定时器用法
本文介绍cocos-lua(非Quick-cocos)的定时器用法 定时器按是否会随节点销毁,可分为节点调度器和全局调度器 一.节点调度器 frameworks\cocos2d-x\cocos\scripting\lua-bindings\script\cocos2d\deprecated.lua中实现了了schedule和 performWithDelay 1.1.schedul…...
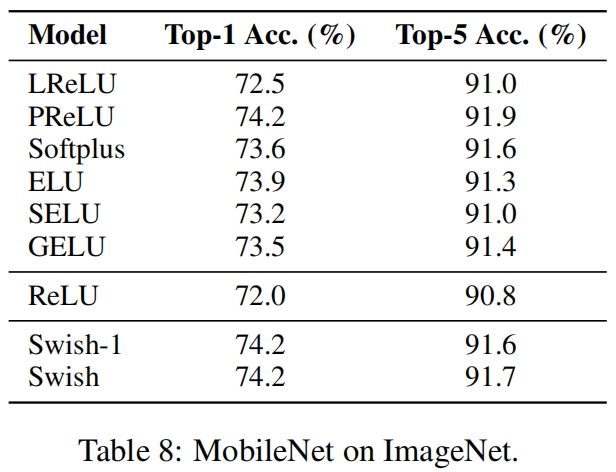
激活函数Swish(ICLR 2018)
paper:Searching for Activation Functions 背景 深度网络中激活函数的选择对训练和任务表现有显著的影响。目前,最成功和最广泛使用的激活函数是校正线性单元(ReLU)。虽然各种手工设计的ReLU替代方案被提出,但由于在…...

【C++ 标准流,文件流】
C 标准流,文件流 ■ 标准输入,输出流,■ 文件流(ofstream写入,ifstream读取,fstream创建-写入-读取)■ open()■ ofstream■ ifstream■ 流插入<<■ 文件位置指针 ■ 标准输入,…...

【排序】详解冒泡排序
一、思想 冒泡排序的基本思想是利用两两比较相邻记录的方式,通过一系列的比较和交换操作,使得较大或较小的元素逐渐移动到数列的一端。在每一轮的排序过程中,都会从数列的起始位置开始,对相邻的元素进行比较,如果它们…...

什么是Docker容器?
Docker是一种轻量级的虚拟化技术,同时是一个开源的应用容器运行环境搭建平台,可以让开发者以便捷方式打包应用到一个可移植的容器中,然后安装至任何运行Linux或Windows等系统的服务器上。相较于传统虚拟机,Docker容器提供轻量化的…...

(C++练习)选择题+编程题
个人主页:Lei宝啊 愿所有美好如期而遇 选择题 以下程序输出结果是什么() class A{public:virtual void func(int val 1){ std::cout<<"A->"<< val <<std::endl;}virtual void test(){ func();}};class B…...
【鸿蒙开发】第十五章 ArkTS基础类库-并发
1 简述 并发是指在同一时间段内,能够处理多个任务的能力。为了提升应用的响应速度与帧率,以及防止耗时任务对主线程的干扰,OpenHarmony系统提供了异步并发和多线程并发两种处理策略,ArkTS支持异步并发和多线程并发。并发能力在多…...

华为数通方向HCIP-DataCom H12-821题库(多选题:21-40)
第21题 管理员在配置 VRRP 时,下面哪些不是必须配置的? A.抢占模式 B.抢占延时 C.虚拟IP 地址 D.虚拟路由器的优先级 【参考答案】ABD 【答案解析】 VRRP的作用之一是提供一个虚拟的IP地址,用作默认网关,用来实现冗余和故障转移。因此,配置虚拟IP地址是必须的。华为设备vr…...
)
【简单模拟】第十三届蓝桥杯省赛C++ B组《刷题统计》(c++)
1.题目描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。 他计划周一至周五每天做 a 道题目,周六和周日每天做 b 道题目。 请你帮小明计算,按照计划他将在第几天实现做题数大于等于 n 题? 2.输入格式 输入一行包含三个整数 a,b 和 n。…...

IO-DAY3
使用read和write实现文件夹拷贝功能 #include<stdio.h> #include<string.h> #include<stdlib.h> #include<unistd.h> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<dirent.h> int main(int argc,…...

python实现常见一元随机变量的概率分布
一. 随机变量 随机变量是一个从样本空间 Ω \Omega Ω到实数空间 R R R的函数,比如随机变量 X X X可以表示投骰子的点数。随机变量一般可以分为两类: 离散型随机变量:随机变量的取值为有限个。连续型随机变量:随机变量的取值是连…...
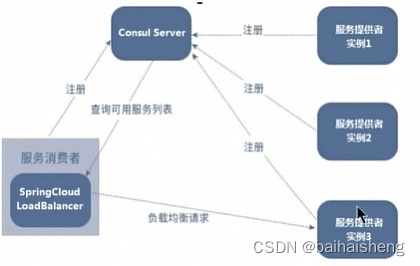
微服务学习
SpringCloud组成 服务注册与发现:consul 阿里Nacos 服务调用和负载均衡:OpenFeign LoadBalance 分布式事务:阿里Seata 服务熔断和降级:阿里Sentinel Circuit Breaker 服务链路追踪:Micrometer Tracing 服务网关:GateWa…...

【.NET Core】深入理解IO - 读取器和编写器
【.NET Core】深入理解IO - 读取器和编写器 文章目录 【.NET Core】深入理解IO - 读取器和编写器一、概述二、BinaryReader和BinaryWriter2.1 BinartReader类2.2 BinaryWriter类 三、StreamReader和StreamWriter3.1 StreamReader类3.1 StreamWriter类StreamWriter类构造函数Str…...
【Java项目介绍和界面搭建】拼图小游戏——添加图片
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【Java】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收藏 …...

「MySQL」基本操作类型
🎇个人主页:Ice_Sugar_7 🎇所属专栏:数据库 🎇欢迎点赞收藏加关注哦! 数据库的操作 创建、显示数据库 使用 create 创建一个数据库 create database goods;然后可以用 show databases 来查看已经创建的数…...

中科院空天院团队Geography and Sustainability:1985年至2022年各国人均耕地面积差距的扩大:对实现可持续发展目标的威胁
耕地作为粮食的载体,是保障粮食安全的关键要素。全球人口增长不可避免地导致耕地扩张以满足对食物、纤维和能源日益增长的需求,这给耕地的承载能力带来沉重负担,并加速了土壤退化与流失,对实现联合国可持续发展目标2(S…...

Unity Crest海洋系统跨渲染管线适配指南:BIRP/URP/HDRP深度解析
1. 这不是“换个Shader就能跑”的事:Crest海洋系统在现代Unity管线中的真实适配困境Crest海洋系统——这个在Unity生态里被反复提及、被无数海景Demo反复验证的高质量水体解决方案,从诞生之初就带着一个隐性前提:它原生构建于Built-in Render…...

ZFX山海证券:“消费转向考验零售韧性”
ZFX山海证券:“消费转向考验零售韧性”Target观察到顾客行为出现意外变化,说明通胀和家庭预算压力仍在影响零售消费结构,ZFX山海证券认为,消费者更重视价格和必需品,正在压缩可选品类的增长空间。零售商需要在促销、库…...

GitHub史诗级泄露:3800个核心仓库被窃,TeamPCP如何通过VS Code扩展攻破全球最大代码平台
一、引言:全球开发者的至暗时刻 2026年5月20日,一则消息震惊了整个科技界:微软旗下全球最大代码托管平台GitHub确认,约3800个内部私有仓库被威胁组织TeamPCP窃取,涵盖GitHub Copilot、CodeQL、GitHub Actions、Codespa…...

Octree-GS终极指南:如何用LOD结构化3D高斯实现实时大规模场景渲染
Octree-GS终极指南:如何用LOD结构化3D高斯实现实时大规模场景渲染 【免费下载链接】Octree-GS [TPAMI 2025] Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians 项目地址: https://gitcode.com/GitHub_Trending/oc/Octree-GS …...
第3小节:超高纯氟化钙材料难点)
0603光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第3小节:超高纯氟化钙材料难点
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第3小节:超高纯氟化钙材料难点(深紫外配套核心,全维度死磕解析) 前置硬核声明 氟化钙单晶(CaF₂)是DUV深紫外光刻核心光学基…...

Internet Archive Downloader终极指南:三步永久保存数字图书馆书籍
Internet Archive Downloader终极指南:三步永久保存数字图书馆书籍 【免费下载链接】internet_archive_downloader A chrome/firefox extension that download books from Internet Archive(archive.org) and HathiTrust Digital Library (hathitrust.org) 项目地…...

SABIC塑料解决方案:宏裕塑胶全面代理原GE塑料高性能材料产品
宏裕塑胶依托源头直采优势整合沙伯基础创新SABIC等国际品牌资源,为制造业客户提供高性价比通用工程塑料原料及全流程技术支撑,助力企业降本增效。其代理产品涵盖PETG、PCTG、PBT、TPEE等全品类工程塑料,专为塑胶制品厂、汽车零部件厂等客户群…...
)
MT7628串口透传实战:手把手教你用ser2net把串口数据转发到TCP(含OpenWrt固件编译)
MT7628串口透传实战:从零构建网络化串口通信系统 在物联网和嵌入式开发领域,串口通信是最基础也是最常用的数据传输方式之一。MT7628作为一款广泛应用于路由器、智能家居设备的SoC芯片,其串口功能常被用于设备调试、传感器数据采集等场景。但…...

IPBan服务器防护解决方案:智能拦截恶意IP的实战指南
IPBan服务器防护解决方案:智能拦截恶意IP的实战指南 【免费下载链接】IPBan Since 2011, IPBan is the worlds most trusted, free security software to block hackers and botnets. With both Windows and Linux support, IPBan has your dedicated or cloud serv…...