一文搞懂 什么是CPU上下文?为什么要切换?如何减少切换?
最近经常有小伙伴问到的一些问题,比较集中的是关于CPU切换.
实际用C/C++,go开发,你会特别注意内存和CPU的使用情况,那些对于CPU使用情况特别关注,或者性能特别关注的朋友可以看看这篇文章,相信看完结尾的示例,能对你优化CPU资源使用有帮助。
我们都知道CPU上下文切换,会增加系统负载。那什么是CPU上下文,为什么要切换?
什么是CPU切换
我们都知道,Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
根据任务的不同,CPU的上下文切换可以分为不同的场景,也就是进程上下文切换、线程上下文切换、中断上下文切换。
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
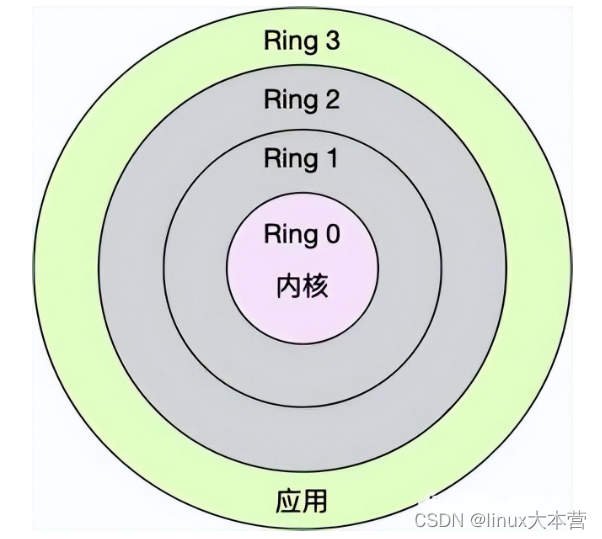
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
那么,系统调用的过程有没有发生 CPU 上下文的切换呢?答案自然是肯定的。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU 寄存器需要恢复原来用户保存的状态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
- 进程上下文切换,是指从一个进程切换到另一个进程运行。
- 而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
那么,进程上下文切换跟系统调用又有什么区别呢?
首先,你需要知道,进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。

根据测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是上一节中我们所讲的,导致平均负载升高的一个重要因素。
另外,我们知道, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
知道了进程上下文切换潜在的性能问题后,我们再来看,究竟什么时候会切换进程上下文。
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
相关视频推荐
Linux操作系统:进程与CPU的故事
360度无死角讲解进程管理,调度器的5种实现
2023年最新技术图谱,c++后端的8个技术维度,助力你快速成为大牛
免费学习地址:C/C++Linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
那么,进程在什么时候才会被调度到 CPU 上运行呢?
最容易想到的一个时机,就是进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。其实还有很多其他场景,也会触发进程调度,在这里我给你逐个梳理下。
其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
最后一个,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
了解这几个场景是非常有必要的,因为一旦出现上下文切换的性能问题,它们就是幕后凶手。
线程上下文切换
说完了进程的上下文切换,我们再来看看线程相关的问题。
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
到这里你应该也发现了,虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
进程/线程CPU的亲缘性
何为CPU的亲和性
CPU的亲和性,进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性,进程迁移的频率小就意味着产生的负载小。亲和性一词是从affinity翻译来的,实际可以称为CPU绑定。
在多核运行的机器上,每个CPU本身自己会有缓存,在缓存中存着进程使用的数据,而没有绑定CPU的话,进程可能会被操作系统调度到其他CPU上,如此CPU cache(高速缓冲存储器)命中率就低了,也就是说调到的CPU缓存区没有这类数据,要先把内存或硬盘的数据载入缓存。而当缓存区绑定CPU后,程序就会一直在指定的CPU执行,不会被操作系统调度到其他CPU,性能上会有一定的提高。
另外一种使用CPU绑定考虑的是将关键的进程隔离开,对于部分实时进程调度优先级提高,可以将其绑定到一个指定CPU核上,可以保证实时进程的调度,也可以避免其他CPU上进程被该实时进程干扰。
我们可以手动地为其分配CPU核,而不会过多的占用同一个CPU,所以设置CPU亲和性可以使某些程序提高性能。
CPU亲缘性可以分为两大类:软亲缘性和硬亲缘性。
Linux 内核进程调度器天生就具有被称为 CPU 软亲缘性(soft affinity) 的特性,这意味着进程通常不会在处理器之间频繁迁移。这种状态正是我们希望的,因为进程迁移的频率小就意味着产生的负载小。但不代表不会进行小范围的迁移。
CPU 硬亲缘性是指通过Linux提供的相关CPU亲缘性设置接口,显示的指定某个进程固定的某个处理器上运行。本文所提到的CPU亲缘性主要是指硬亲缘性。
使用CPU亲缘性的好处
目前主流的服务器配置都是SMP架构,在SMP的环境下,每个CPU本身自己会有缓存,缓存着进程使用的信息,而进程可能会被kernel调度到其他CPU上(即所谓的core migration),如此,CPU cache命中率就低了。设置CPU亲缘性,程序就会一直在指定的cpu运行,防止进程在多SMP的环境下的core migration,从而避免因切换带来的CPU的L1/L2 cache失效。从而进一步提高应用程序的性能。
Linux CPU亲缘性的使用
我们有两种办法指定程序运行的CPU亲缘性。
- 通过Linux提供的taskset工具指定进程运行的CPU。
- 方式二,glibc本身也为我们提供了这样的接口,借来的内容主要为大家讲解如何通过编程的方式设置进程的CPU亲缘性。
绑定进程到cpu核上运行
- 查看cpu有几个核
使用cat /proc/cpuinfo查看cpu信息
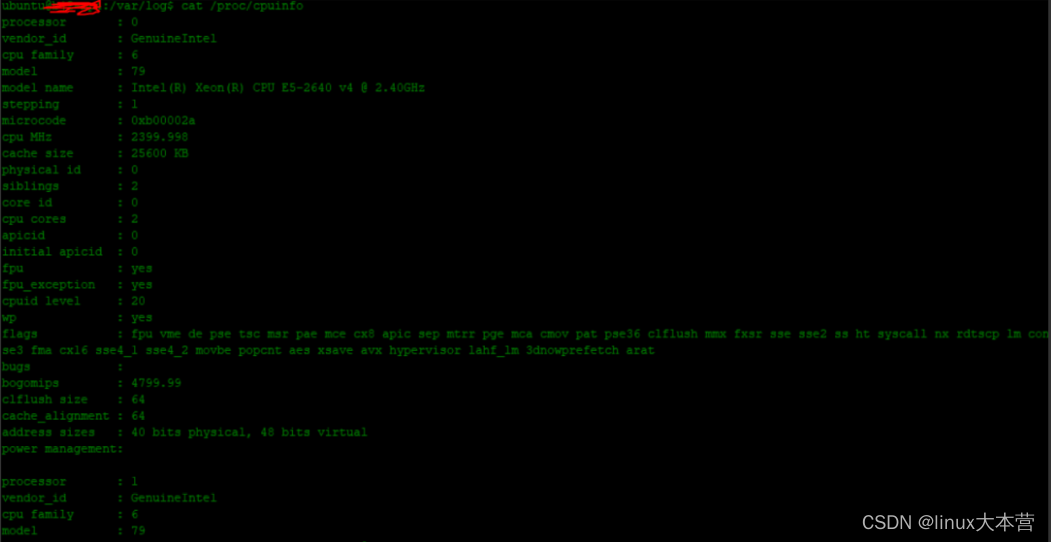
如下两个信息:
- processor,指明第几个cpu处理器
- cpu cores,指明每个处理器的核心数
也可以使用系统调用sysconf获取cpu核心数:
#include <unistd.h>
int sysconf(_SC_NPROCESSORS_CONF);/* 返回系统可以使用的核数,但是其值会包括系统中禁用的核的数目,因 此该值并不代表当前系统中可用的核数 */
int sysconf(_SC_NPROCESSORS_ONLN);/* 返回值真正的代表了系统当前可用的核数 */
/* 以下两个函数与上述类似 */
#include <sys/sysinfo.h>
int get_nprocs_conf (void);/* 可用核数 */
int get_nprocs (void);/* 真正的反映了当前可用核数 */使用taskset指令
- 获取进程pid
- 查看进程当前运行在哪个cpu上

显示的十进制数字3转换为2进制为最低两个是1,每个1对应一个cpu,这里的f表示的是随机分配的。
指定进程运行在cpu1上

注意,cpu的标号是从0开始的,所以cpu1表示第二个cpu(第一个cpu的标号是0)。
至此,就把应用程序绑定到了cpu1上运行,查看如下:

使用sched_setaffinity系统调用
sched_setaffinity可以将某个进程绑定到一个特定的CPU。
#define _GNU_SOURCE /* See feature_test_macros(7) */#include <sched.h>/* 设置进程号为pid的进程运行在mask所设定的CPU上 * 第二个参数cpusetsize是mask所指定的数的长度 * 通常设定为sizeof(cpu_set_t)* 如果pid的值为0,则表示指定的是当前进程 */int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);/* 获得pid所指示的进程的CPU位掩码,并将该掩码返回到mask所指向的结构中 */- 实例
#include<stdlib.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/sysinfo.h>
#include<unistd.h>
#define __USE_GNU
#include<sched.h>
#include<ctype.h>
#include<string.h>
#include<pthread.h>
#define THREAD_MAX_NUM 200 //1个CPU内的最多进程数
int num=0; //cpu中核数
void* threadFun(void* arg) //arg 传递线程标号(自己定义)
{cpu_set_t mask; //CPU核的集合cpu_set_t get; //获取在集合中的CPUint *a = (int *)arg; int i;printf("the thread is:%d\n",*a); //显示是第几个线程CPU_ZERO(&mask); //置空CPU_SET(*a,&mask); //设置亲和力值if (sched_setaffinity(0, sizeof(mask), &mask) == -1)//设置线程CPU亲和力{printf("warning: could not set CPU affinity, continuing...\n");}CPU_ZERO(&get);if (sched_getaffinity(0, sizeof(get), &get) == -1)//获取线程CPU亲和力{printf("warning: cound not get thread affinity, continuing...\n");}for (i = 0; i < num; i++){if (CPU_ISSET(i, &get))//判断线程与哪个CPU有亲和力{printf("this thread %d is running processor : %d\n", i,i);}}return NULL;
}
int main(int argc, char* argv[])
{int tid[THREAD_MAX_NUM];int i;pthread_t thread[THREAD_MAX_NUM];num = sysconf(_SC_NPROCESSORS_CONF); //获取核数if (num > THREAD_MAX_NUM) {printf("num of cores[%d] is bigger than THREAD_MAX_NUM[%d]!\n", num, THREAD_MAX_NUM);return -1;}printf("system has %i processor(s). \n", num);for(i=0;i<num;i++){tid[i] = i; //每个线程必须有个tid[i]pthread_create(&thread[i],NULL,threadFun,(void*)&tid[i]);}for(i=0; i< num; i++){pthread_join(thread[i],NULL);//等待所有的线程结束,线程为死循环所以CTRL+C结束}return 0;
}- 绑定线程到cpu核上运行
绑定线程到cpu核上使用pthread_setaffinity_np函数,其原型定义如下:
#define _GNU_SOURCE /* See feature_test_macros(7) */#include <pthread.h>int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize,const cpu_set_t *cpuset);int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset);Compile and link with -pthread.- 各参数的意义与sched_setaffinity相似。
- 实例
#define _GNU_SOURCE
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#define handle_error_en(en, msg) \do { errno = en; perror(msg); exit(EXIT_FAILURE); } while (0)
int
main(int argc, char *argv[])
{int s, j;cpu_set_t cpuset;pthread_t thread;thread = pthread_self();/* Set affinity mask to include CPUs 0 to 7 */CPU_ZERO(&cpuset);for (j = 0; j < 8; j++)CPU_SET(j, &cpuset);s = pthread_setaffinity_np(thread, sizeof(cpu_set_t), &cpuset);if (s != 0)handle_error_en(s, "pthread_setaffinity_np");/* Check the actual affinity mask assigned to the thread */s = pthread_getaffinity_np(thread, sizeof(cpu_set_t), &cpuset);if (s != 0)handle_error_en(s, "pthread_getaffinity_np");printf("Set returned by pthread_getaffinity_np() contained:\n");for (j = 0; j < CPU_SETSIZE; j++)if (CPU_ISSET(j, &cpuset))printf(" CPU %d\n", j);exit(EXIT_SUCCESS);
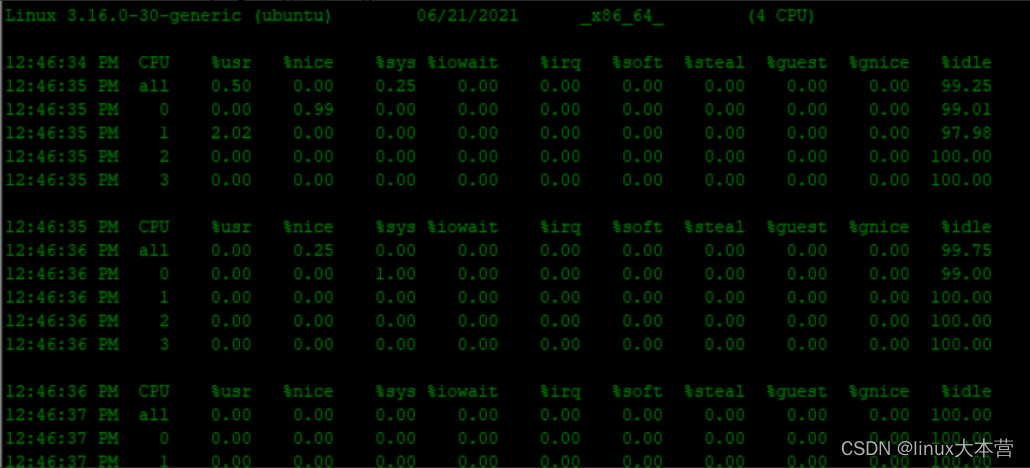
}- 通过亲缘性绑定,你可以用mpstat -P ALL 1 查看各个CPU core的使用情况,具体参数这里不做过多解释(相信你可以通过英文单词就可以理解各个参数的含义)。
结语
既然你知道了如何通过CPU资源绑定来减少CPU切换带来的性能问题,你有么有想过这又会带来什么问题吗?他的优缺点是什么?
相关文章:
一文搞懂 什么是CPU上下文?为什么要切换?如何减少切换?
最近经常有小伙伴问到的一些问题,比较集中的是关于CPU切换. 实际用C/C,go开发,你会特别注意内存和CPU的使用情况,那些对于CPU使用情况特别关注,或者性能特别关注的朋友可以看看这篇文章,相信看完结尾的示例…...
【Python】Python学习笔记(二)基本输入输出
Python娘来源:https://next.rikunabi.com/tech/docs/ct_s03600.jsp?p002412 目录print()函数不进行自动换行的print()函数打印输出多个字符串只进行换行input()函数使用format方法格式化字符串字符串与数值转换字符串转换为数值数值转换为字符串总结参考资料print(…...

LeetCode刷题系列 -- 724. 寻找数组的中心下标
给你一个整数数组 nums ,请计算数组的 中心下标 。数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于…...

Linux编辑器vim
本文已收录至《Linux知识与编程》专栏! 作者:ARMCSKGT 演示环境:CentOS 7 目录 前言 正文 vim常用方式 进入vim 退出vim vim基本模式及模式功能 命令模式 插入模式 底行模式 替换模式 视图模式 配置vim 自己配置vim 自动化配置…...

基于“python+”潮汐、风驱动循环、风暴潮等海洋水动力模拟
查看原文>>>基于“python”潮汐、风驱动循环、风暴潮等海洋水动力模拟ADCIRC是新一代海洋水动力计算模型,它采用了非结构三角形网格广义波动连续方程的设计,在提高计算精确度的同时还减小了计算时间。被广泛应用于:模拟潮汐和风驱动…...
《Terraform 101 从入门到实践》 第二章 Providers插件管理
《Terraform 101 从入门到实践》这本小册在南瓜慢说官方网站和GitHub两个地方同步更新,书中的示例代码也是放在GitHub上,方便大家参考查看。 不怕出身低,行行出状元。 插件 Terraform可以对多种平台的多种资源进行管理,这个是通过…...
)
03- pandas 数据库可视化 (机器学习)
pandas库的亮点: 一个快速、高效的DataFrame对象,用于数据操作和综合索引;用于在内存数据结构和不同格式之间读写数据的工具:CSV和文本文件、Microsoft Excel、SQL数据库和快速HDF 5格式;智能数据对齐和丢失数据的综合处理&#…...
Spring为什么这么火 之 Bean的6种作用域和Bean的生命周期
1、Bean的作用域 1.1、什么是作用域? 限定程序中变量的可用范围叫做作用域,或者说在源代码中定义变量的某个区域就叫做作用域 1.2、Bean的6种作用域 singleton:单例作用域prototype:原型作用域【多例作用域】request࿱…...

【CSS面试题】2023前端最新版css模块,高频15问
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的CSS面试题 目录 一、CSS必备面试题 1.CSS3新特性 2.CSS实现元素两个盒子垂…...

SpringCloud-Netflix学习笔记10——Hystrix实现服务熔断
一、概述 1、分布式系统面临的问题 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败! 2、服务雪崩 多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B 和微服务C又…...
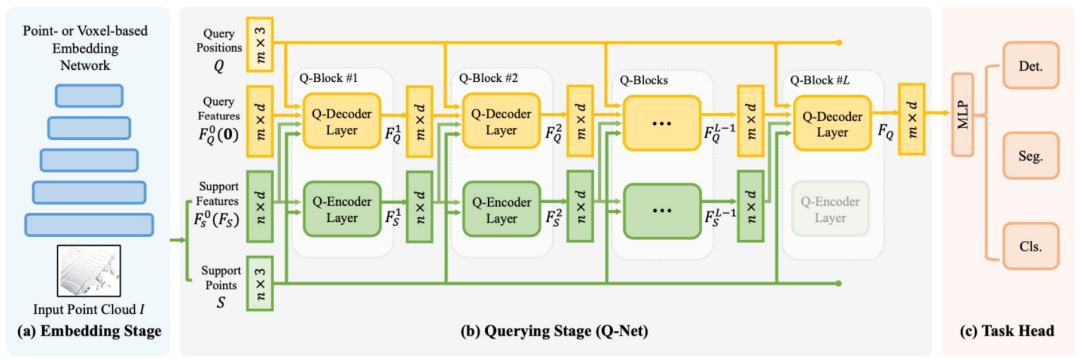
精华文稿|迈向统一的点云三维物体检测框架
分享嘉宾 | 杨泽同 文稿整理 | William 嘉宾介绍 Introduction 3D检测是在三维世界中去定位和分类不同的物体,与传统2D检测的区别在于它有一个深度信息。目前,大部分的工作是倾向于用点云去做三维检测,点云实际上是通过传感器去扫描出来的一…...
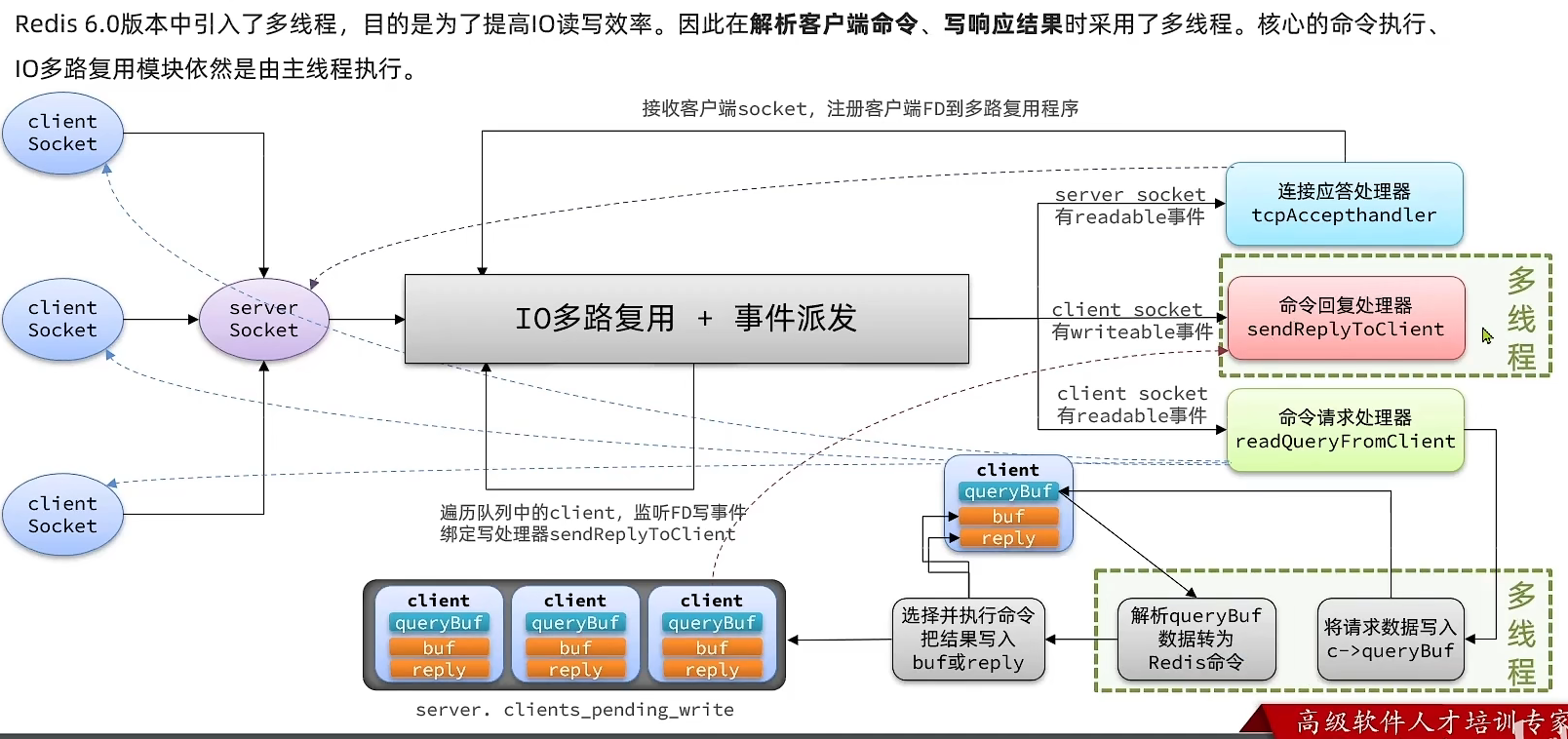
面试题:Redis网络模型
1 用户空间和内核空间以Centos 7 linux操作系统为例。计算机系统被内核操控, 内核被应用操控。为了避免用户应用导致冲突甚至内核崩溃,用户应用与内核是分离的进程的寻址空间会划分为两部分:内核空间、用户空间。用户空间只能执行受限的命令(Rin3&#x…...
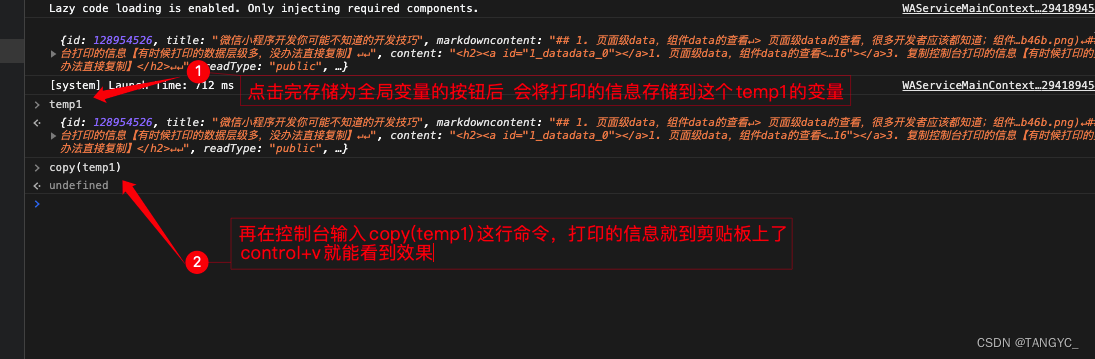
微信小程序开发你可能不知道的开发技巧
1. 页面级data,组件data的查看 页面级data的查看,很多开发者应该都知道;组件级的数据查看我是开发了大半年才发现的; 页面级的data查看: 组件的data查看: 2. 放大模拟器【调整一些UI细节】 效果&#x…...
STM32开发(8)----CubeMX配置串口通讯(中断方式和DMA方式)
CubeMX配置串口通讯(中断方式和DMA方式)前言一、中断方式1.CubeMX配置2.代码实现3.实验结果二、DMA方式1.CubeMX配置2.代码实现3.实验结果总结前言 本章继续介绍使用STM32CubeMX对串口进行配置的方法,串口通讯有三种方式:轮询&am…...

7.1 微服务-SpringCloud(二)
目录 前言 7.1.5 Hystrix 7.1.5.1 什么是Hystrix 7.1.5.2 雪崩问题 7.1.5.3 线程隔离,服务降级 7.1.5.4 搭建 7.1.5.4.1 引入依赖 7.1.5.4.2 开启熔断 7.1.5.4.3 编写降级逻辑 1.局部降级逻辑 2.全局降级逻辑 7.1.5.4.4 设置超时 7.1.5.5 服务熔断 7.…...

Spring的AOP开发-基于xml配置的AOP
Spring的AOP开发-基于xml配置的AOP xml方式AOP快速入门 通过配置文件的方式解决以下问题 配置哪些包、哪些类、哪些方法需要被增强配置目标方法要被哪些通知方法所增强,在目标方法执行之前还是之后执行增强 配置方式的设计、配置文件(注解),Spring已…...

JAVA的垃圾收集器与内存分配策略【一篇文章直接看懂】
内存动态分配和垃圾收集技术是JAVA和C之间最大的区别之一 垃圾收集(Garbage Collection,GC)只办三件事: 哪些内存需要回收什么时候回收如何回收 对于对象回收的方法 引用计数法: 每处引用时1,引用失效…...

NLP学习——信息抽取
信息抽取 自动从半结构或无结构的文本中抽取出结构化信息的任务。常见的信息抽取任务有三类:实体抽取、关系抽取、事件抽取。 1、实体抽取 从一段文本中抽取出文本内容并识别为预定义的类别。 实体抽取任务中的复杂问题: 重复嵌套,原文中…...
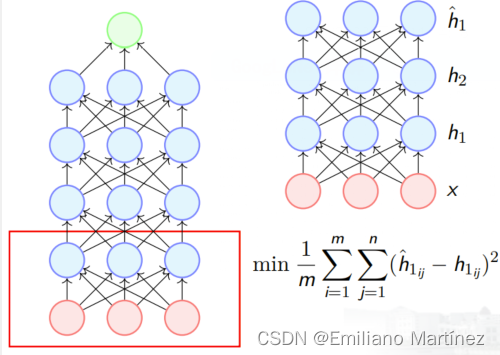
【深度学习基础7】预训练、激活函数、权重初始化、块归一化
一、Unsupervised Pre-training 得益于 Hinton and Salakhutdinov 在 2006 年的开创性工作— 无监督预训(unsupervised pre-training);在《Reducing the dimensionality of data with neural networks.》这篇论文中,他们在 RBMs 中引入无监督预训练,下面我们将在Autoenco…...

MetaMQ
文章目录MetaMQMetaMQ 的优势在于:MetaMQ 的劣势也有:MetaMQ MetaMQ 是一个基于以太坊的可扩展分布式消息队列(MQ)系统,它可以支持大规模的分布式应用程序。MetaMQ 是一个开放源代码项目,它支持企业级应用程…...

从‘不好用的CE’到‘好用的OD’:一次逆向实战中的工具选择与思路转换
逆向工程实战:从工具局限到思维跃迁的破解之道 当那个MFC程序弹出第一个窗口时,我习惯性地打开了Cheat Engine——这个在游戏修改领域堪称神器的工具。但十分钟后,面对毫无进展的扫描结果和不断跳出的错误提示,我突然意识到&#…...

MCA Selector终极指南:Minecraft世界区块管理的核心技术解析与实战应用
MCA Selector终极指南:Minecraft世界区块管理的核心技术解析与实战应用 【免费下载链接】mcaselector A tool to select chunks from Minecraft worlds for deletion or export. 项目地址: https://gitcode.com/gh_mirrors/mc/mcaselector MCA Selector是一款…...

从干扰三要素到实战:辐射发射的工程化抑制与诊断方法
1. 项目概述:从一道周五小测题聊起辐射发射那天在EE Times上翻到一篇2014年的老文章,标题叫“Friday Quiz: Radiated Emissions”,作者是Martin Rowe。文章开头就抛出了一个非常基础,但又直击电磁兼容(EMC)…...

LLM训练实战:8个编程谜题带你掌握分布式训练核心技术
1. 项目概述与核心价值如果你对大型语言模型(LLM)的训练过程感到好奇,或者你听说过“千卡集群”、“万亿参数”这些词,但总觉得它们离自己很遥远,那么这个名为“LLM Training Puzzles”的项目,就是为你量身…...

终极指南:NoSQL数据库大全awesome-bigdata - 文档型数据库实战入门 [特殊字符]
终极指南:NoSQL数据库大全awesome-bigdata - 文档型数据库实战入门 🚀 【免费下载链接】awesome-bigdata A curated list of awesome big data frameworks, ressources and other awesomeness. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-b…...

Redis++完全指南:C++开发者的终极Redis客户端解决方案
Redis完全指南:C开发者的终极Redis客户端解决方案 【免费下载链接】redis-plus-plus Redis client written in C 项目地址: https://gitcode.com/gh_mirrors/re/redis-plus-plus Redis是一款专为C开发者打造的高性能Redis客户端,它提供了简洁易用…...

【ElevenLabs商业增长实战手册】:20年AI语音赛道老兵亲授从0到月营收$2M的7个关键跃迁节点
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs商业增长的核心范式迁移 传统AI语音服务商长期依赖“API调用量时长计费”模型,而ElevenLabs正系统性重构价值交付逻辑——从卖计算资源转向卖情感可信度与品牌声纹资产。这一迁移…...

半导体技术评估:如何判断新技术从概念到产品的“露点”
1. 开篇:从“露点”看半导体行业的虚实迷雾 大家好,我是Don Scansen。在半导体行业摸爬滚打了二十多年,从设计、验证到失效分析,几乎把产业链的各个环节都趟了一遍。今天,我想借这个新开的专栏,和大家聊聊一…...

D2DX:让《暗黑破坏神2》在现代电脑上完美运行的终极方案
D2DX:让《暗黑破坏神2》在现代电脑上完美运行的终极方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为《…...

别再手动调阈值了!OpenCV实战:用Otsu和自适应阈值搞定光照不均的图片分割
智能图像分割实战:Otsu与自适应阈值技术解决光照不均难题 在工业质检、医疗影像分析、自动驾驶等场景中,图像分割的准确性直接影响最终结果。但现实世界的光照条件往往复杂多变——同一张图片可能同时存在过曝和欠曝区域,传统全局阈值方法在…...