MySQL进阶之(四)InnoDB数据存储结构之行格式
四、InnoDB数据存储结构之行格式
- 4.1 行格式的语法
- 4.2 COMPACT 行格式
- 4.2.1 记录的额外信息
- 01、变长字段长度列表
- 02、NULL 值列表
- 03、记录头信息
- 4.2.2 记录的真实数据
- 4.3 Dynamic 和 Compressed 行格式
- 4.3.1 字段的长度限制
- 4.3.2 行溢出
- 4.3.3 Dynamic 和 Compressed 行格式
- 4.4 Redundant 行格式
- 4.4.1 字段长度偏移列表
- 4.4.2 记录头信息(record header)
- 4.4.3 NULL 值处理
我们平时的数据都是以行记录为单位向表中插入数据的,这些记录在磁盘上的存放形式也被称为
行格式或者
记录格式。设计 InnoDB 存储引擎的大叔到现在为止设计了 4 中不同类型的行格式,分别是 COMPACT、REDUNDANT、DYNAMIC 和 COMPRESSED。随着时间的推移,它们可能会设计出更多的行格式,但是不管怎么变,这些行格式在原理上大体都是相同的。
——摘自《MySQL 是怎样运行的》
4.1 行格式的语法
我们可以在创建或者修改表的语句中指定记录所使用的行格式:
# 创建表时指定行格式
CREATE TABLE 表名(列的信息) ROW_FORMAT = 行格式名称
# 修改表的行格式
ALTER TABLE 表名 ROW_FORMAT = 行格式名称
4.2 COMPACT 行格式
COMPACT 表示紧凑的,在 MySQL 5.1 版本中,默认设置为 COMPACT 行格式。
一条完整的记录可以分为记录的额外信息和记录的真实数据两大部分:
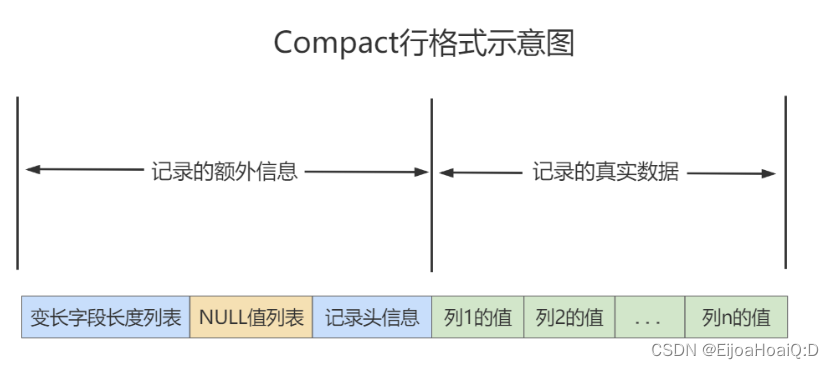
4.2.1 记录的额外信息
这部分信息时服务器为了更好地管理记录而不得不额外添加的一些信息。这些额外的信息分为三部分,分别是变长字段长度列表、NULL 值列表和记录头信息。
01、变长字段长度列表
MySQL 支持一些变长的数据类型,比如 varchar(M)、varbinary(M)、text 类型、blob 类型,这些数据类型修饰列称为变长字段,变长字段中存储多少字节的数据不是固定的,所以我们在存储真实数据的时候,需要顺便把这些数据占用的字节数也存起来。
也就是说,这些变长字段占用的存储空间分为两部分:
- 真正的数据内容;
- 该数据占用的字节数。
在 Compact 行格式中,把所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表,且各变长字段的真实数据占用的字节数按照列的顺序逆序存放。
比如,创建一张表:
create table record_test_table(col1 varchar(8),col2 varchar(8) not null,col3 vhar(8),col4 varchar(8)
) charset=ascii row_format=Compact
并向表里插入数据:
insert into record_test_table(col1, col2, col3, col4)
values
('zhangsan', 'lisi', 'wangwu', 'songhk'),
('tong', 'chen', NULL, NULL);
因为 record_test_table 表中 col1、col2、col4 列都是 varchar(8) 类型的,所以这三个列的值的长度都会被存储在记录开头处。由于使用的是 ascii 字符集,所以每个字符只需要 1 个字节来进行编码:

又因为这些长度值需要按照列的顺序逆序存放,所以最后变长字段长度列表的字节串用十六进制表示的效果就是:06 04 08。

小贴士:并不是所有记录都有这个变长字段长度列表部分,如果表中所有的列都不是变长的数据类型或者所有列的值都是 NULL 的话,就不需要有变长字段长度列表(不冗余存储,节省存储空间)了。
02、NULL 值列表
一条记录中的某些列可能存储 NULL 值,如果把这些 NULL 值都放到 “记录的真实数据” 中存储会很占地方。所以,COMPACT 行格式把一条记录中值为 NULL 的列统一管理起来,存储到 NULL 值列表中。
为什么要定义 NULL 值列表呢?
之所以要存储 NULL 值,是因为数据都是需要对齐的,如果没有标注出来 NULL 值的位置,就有可能在查询数据的时候出现混乱的情况。如果使用一个特殊符号来代替 NULL 值放到对应的位置,虽然可以达到效果,但是大量的 NULL 值列会严重浪费空间,所以干脆就直接在行数据的头部开辟出一块空间,专门用来记录该行哪些数据是非空数据,哪些是空数据。
⭐ 规定
将每个允许存储 NULL 的列对应一个二进制位,二进制位按照列的顺序逆序存放,格式如下:
- 二进制位为 1 时,代表该列的值为 NULL
- 二进制位为 0 时,代表该列的值不为 NULL
举个例子:字段 a、b、c,其中 a 是主键,在某一行中存储的数依次是 a = 1,b = null,c = 2。那么 COMPACT 行格式中的 NULL 值列表中存储的是:01。第一个 0 表示 c 的值不为 null,第二个 1 表示 b 是 null。这里需要注意以下,之所以没有 a 的值,是因为数据库会自动跳过主键,因为主键肯定是非 null 且唯一的,在 null 值列表的数据中就会自动跳过主键。
record_test_table 的两条记录的 NULL 值列表为:
# 这里是上文中插入的两条数据
insert into record_test_table(col1, col2, col3, col4)
values
('zhangsan', 'lisi', 'wangwu', 'songhk'),
('tong', 'chen', NULL, NULL);
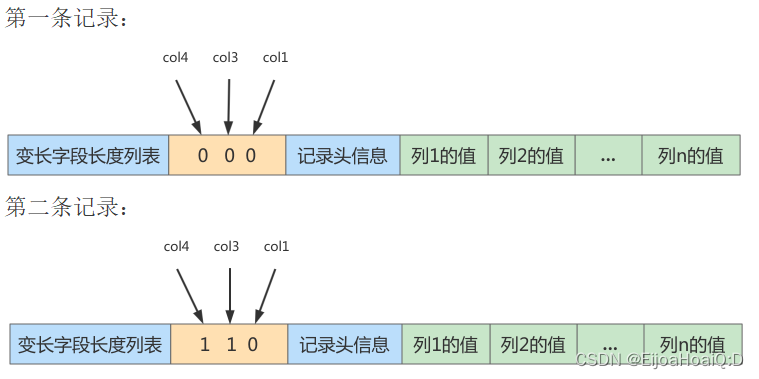
这样我们就可以回答问题了:MySQL 中的 NULL 值是怎么存储的?
答:NULL 值是由 NULL 值列表记录的,用列的二进制位逆序表示每行记录中的每一列是否为 NULL 值,0 代表不为 NULL,1 代表为 NULL 值。
假设现有一张表,其中有 4 个字段:col1、col2、col3、col4。向其插入一条记录:‘a’, NULL, NULL, ‘dd’,那么 NULL 值列表使用二进制位表示为:0 1 1 0,转化成十进制就是 06。
03、记录头信息
除了变长字段长度列表、NULL 值列表之外,还有一个记录头信息的部分,它是由固定的 5 字节组成,用于描述一些属性的。5 个字节也就是 40 个二进制位,不同的位代表不同的属性:
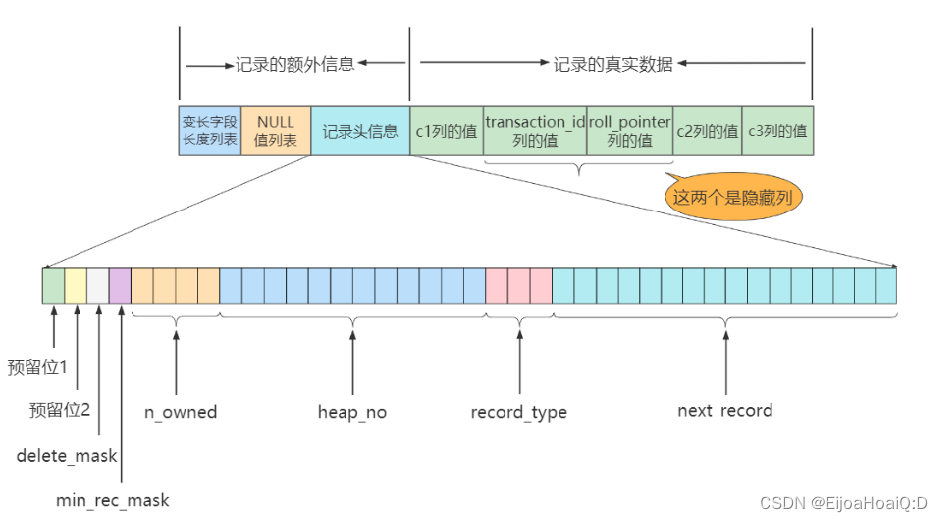
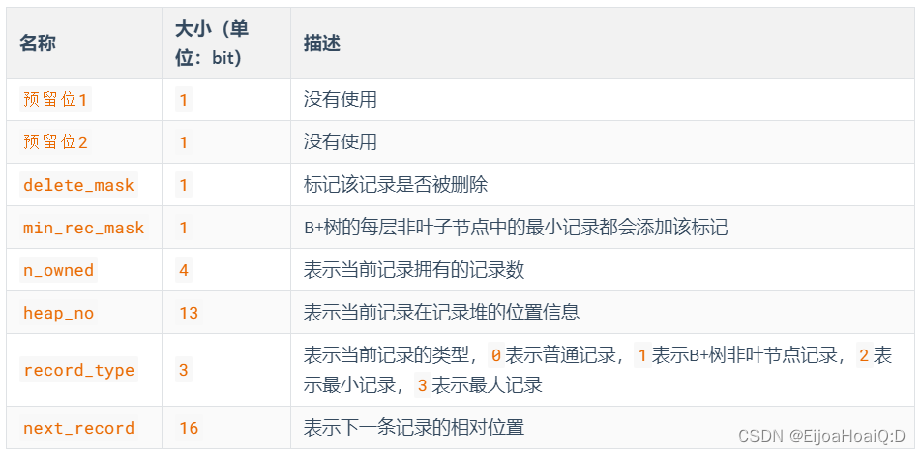
其中,重点来说几个属性。
属性一、delete_mask(删除标记)
这个属性标记着当前记录是否被删除,占用 1 个二进制位:
- 值为 0:代表记录并没有被删除
- 值为 1:代表记录被删除掉了
⭐ 被删除的记录为什么还在页中存储呢?
这些被删除的记录不会从磁盘上移除,是因为一旦移除,其他的记录还需要在磁盘上重新排列,这会带来性能消耗。
尤其是对聚簇索引的叶子节点来说,假设移除的是主键值为 1 的记录,那么整个聚簇索引的叶子节点都会因为这一条记录的删除全部重新排序,显然这样是不合适的。
所以,只是将这些删除的记录打一个删除标记,以区分正常记录和被删除的记录,所有被删除的记录会组成一个垃圾链表,它们所占用的空间被称为可重用空间,之后如果有新记录插入到表中时,可能会覆盖掉(复用)被删除的记录占用的存储空间。
这里需要注意:将 delete_flag 属性设置为 1 和将被删除的记录加入到垃圾链表中其实是分为两个阶段。
属性二、min_rec_mask(非叶子节点最小记录标记)
B+ 树的每层非叶子节点中的最小记录都会添加该标记,min_rec_mask 值为 1。如果我们自己插入的四条记录的 min_rec_mask 值都是 0,意味着它们都不是 B+ 树的非叶子节点中的最小记录。
属性三、record_type(记录类型)
这个属性表示当前记录的类型,一共有 4 种类型的记录:
- 0:普通记录
- 1:B+ 树非叶节点记录
- 2:最小记录
- 3:最大记录
再回过头来看:数据页结构和索引结构就可以理解当时的图中为什么表示的 record_type 值不一样了。
heap_no(在页中的相对位置)
这个属性表示当前记录在本页中的位置(设计 InnoDB 的大叔把记录一条一条亲密无间排列的结构称为堆,这个属性也表示在堆中的相对位置)。
其中,值为 0 和 1 的记录分别代表最小和最大记录,这两条记录并不是我们自己插入的,所以有时候也称为伪记录或虚拟记录。
n_owned(每行记录数)
页目录中会将所有的记录分成若干个组,每个组中的最后一条记录的头信息中会存储该组一共有多少条记录,来作为 n_owned 字段的值,而其他记录的 n_owned 值都是 0。
next_record(记录的相对位置)
它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。
假设第一条记录的 next_record 值为 32,意味着从第一条记录的真实数据的地址处向后找 32 个字节就是下一条记录的真实数据。
注意:下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。
并且,InnoDB 底层规定 Infimum 记录(最小记录)的下一条记录就是当前页中主键值最小的记录,而当前页中主键值最大的记录指向的下一条记录就是 Supremum 记录(最大记录)。用箭头指向代替地址偏移量来表示 next_record:
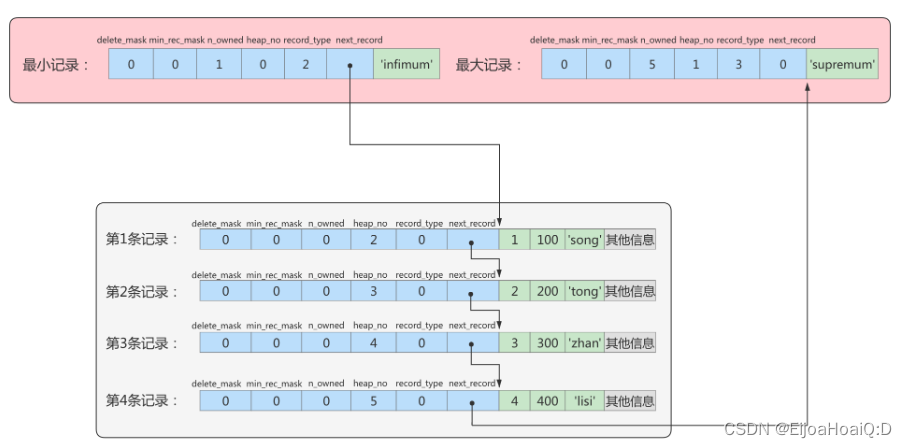
下面来分别演示一下删除一条记录的操作和增加一条记录的操作。
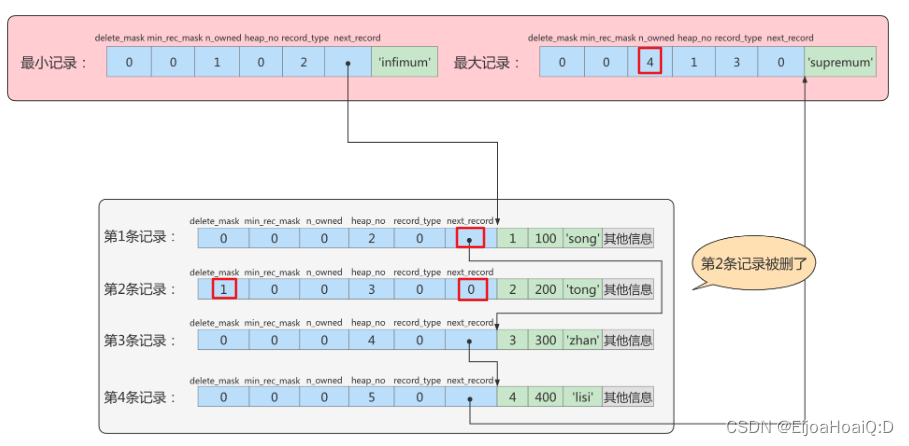
⭐ 删除一条记录的操作
根据上图所示,假设删除第 2 条记录:
# 删除主键值为2的记录
delete from page_demo where c1 = 2;
删除后,整个链表也会跟着变化:
- 把第二条记录的 delete_mask 值设置为 1,而并没有从存储空间中移除;
- 把第二条记录的 next_record 值设置为 0,意味着没有下一条记录了;
- 第一条记录的 next_record 指向第三条记录;
- 最大记录的 n_owned 值从 5 变成了 4。
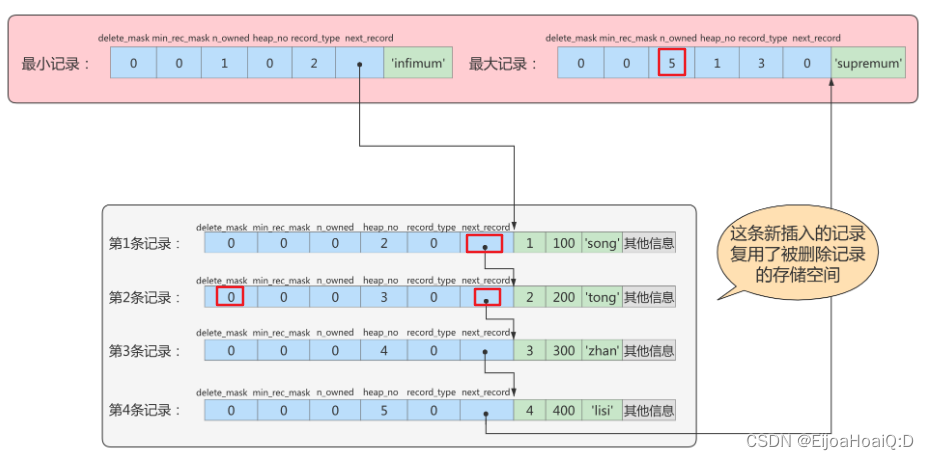
⭐ 增加一条记录的操作
在 “删除一条记录的操作” 中,主键值为 2 的记录被删除了(变成了垃圾链表),但是存储空间并没有被回收。现在要把这条数据再次插入:
# 新增主键值为2的记录
insert into page_demo values(2, 200, 'tong');
新插入的数据,因为指定了主键值为 2,所以按照聚簇索引结构这条记录会按照顺序插入原来第 2 条记录的位置,因为原来被删除的第 2 条记录并没有被真实删除,仍然占有空间,所以这次新插入的数据会复用原有的空间。链表也会发生变化:
- 第 2 条记录的 delete_mask 的值变为 0;
- 第 2 条记录的 next_record 的值变为 32;
- 第 1 条记录的 next_record 指向第 2 条记录,第 2 条记录的 next_record 指向第 3 条记录;
- 最大记录的 n_owned的值从 4 => 5。
所以,不论我们怎么对页中的记录做增删改操作,InnoDB 始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
4.2.2 记录的真实数据
记录的真实数据,除了我们自定义的列的数据之外,MySQL 会为每个记录默认地添加一些列(隐藏列):
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
| DB_ROW_ID | 否 | 6字节 | 行ID,唯一标识一条记录 |
| DB_TRX_ID | 是 | 6字节 | 事务ID |
| DB_ROLL_PTR | 是 | 7字节 | 回滚指针 |
为了方便看,就把它们都写成小写的:row_id、transaction_id、roll_pointer。
在 InnoDB 表中,InnoDB 表的主键生成策略是这样的:
- 优先使用用户自定义的主键作为主键;
- 如果用户没有定义主键,则选取一个不允许存储 NULL 值的 UNIQUE 键作为主键;
- 如果表中连不允许存储 NULL 值的 UNIQUE 键都没有定义,则会为表默认添加一个名为 row_id 的隐藏列作为主键。
举个例子:
现创建一张表 mytest:
create table mytest(col1 varchar(10),col2 varchar(10),col3 char(10),col4 varchar(10)
)engine=innodb charset=latin1 row_format=compact
并向表中插入三条数据:
insert into mytest values
('a', 'bb', 'bb', 'ccc'),
('d', 'ee', 'ee', 'fff'),
('d', NULL, NULL, 'fff');
找到存储文件 mytest.idb 的位置,用 notepad++ dakai,建议安装一个解析插件,将乱码文件解析成十进制的数据格式:
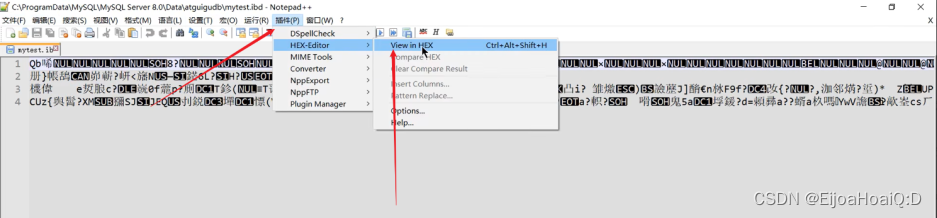

解析第一行记录如下:
由于 col3 列是定长,所以不计入变长字段长度列表中。

第二行的数据同第一行,这里就不一一列举了。
第三行的数据中有 NULL 值,所以在存储上与第一行、第二行有些差异:

至于 transaction_id 和 roll_pointer,暂时还没学到哩,等学到时候会做笔记的呀~
4.3 Dynamic 和 Compressed 行格式
4.3.1 字段的长度限制
char 与 varchar 的区别如下:

也就是说,一个 varchar 类型的字段,最大容量为 65535 个字节。
现在已经存在了一张表,分别查看 MySQL 8.0.26 版本和 MySQL 5.7.34 版本的默认字符集:
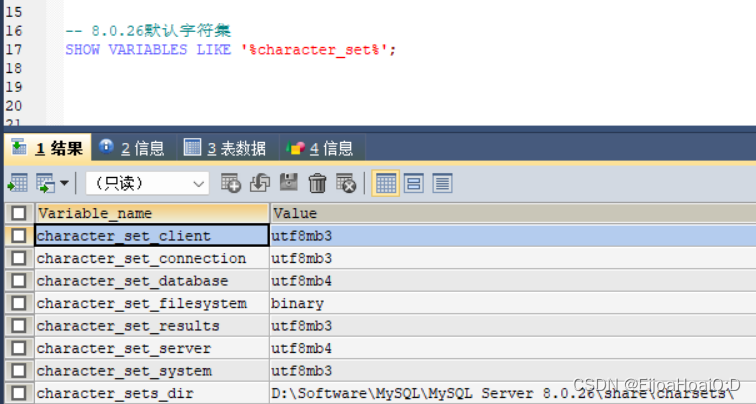
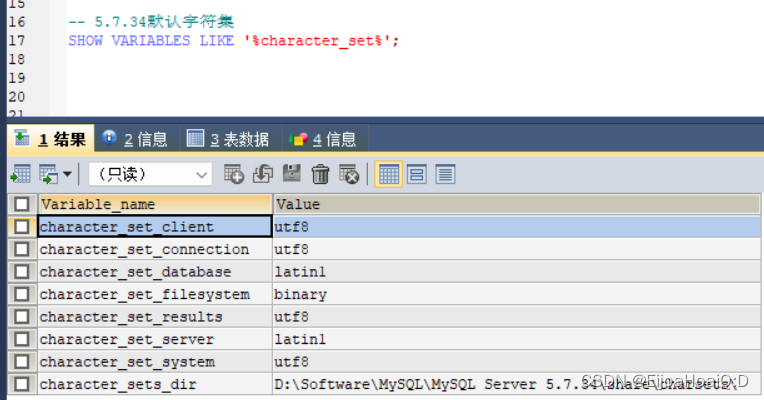
由此可见,MySQL 8.0.26 字符集默认采用 utf8mb4,MySQL 5.7.34 字符集默认采用 utf8。这两者的区别就是:
- utf8:使用 3 个字节表示字符;
- utf8mb4:使用 4 个字节表示字符,可以存储一些 emoji 表情等。
说明:统一采用 MySQL 8.0.26 版本来进行接下来的操作。
⭐ 采用默认字符集 utf8mb4
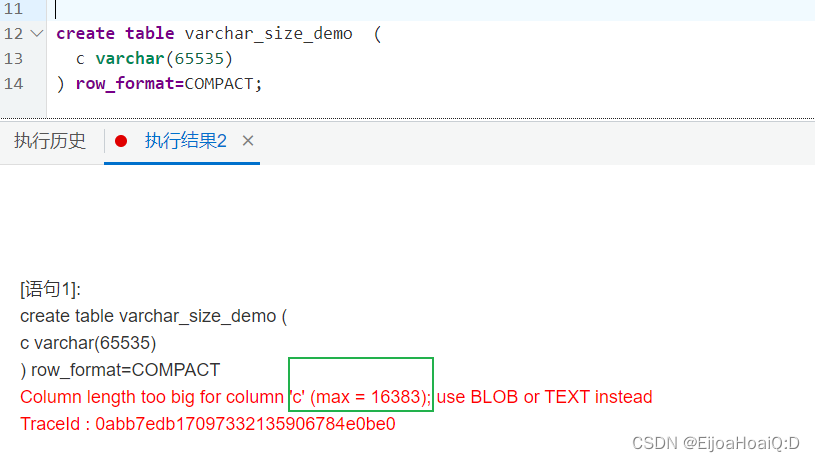
报错提示:字段长度最大不能超过 16383,因为 8.0.26 版本默认字符集为 utf8mb4,也就是说,一个字符等于 4 个字节,那么,16383 * 4 = 65532,还差 3 个字节才等于 65535。反过来,65535 除以 4 结果等于 1633.75,由于字段长度不能带小数,将其四舍五入改为 16384:
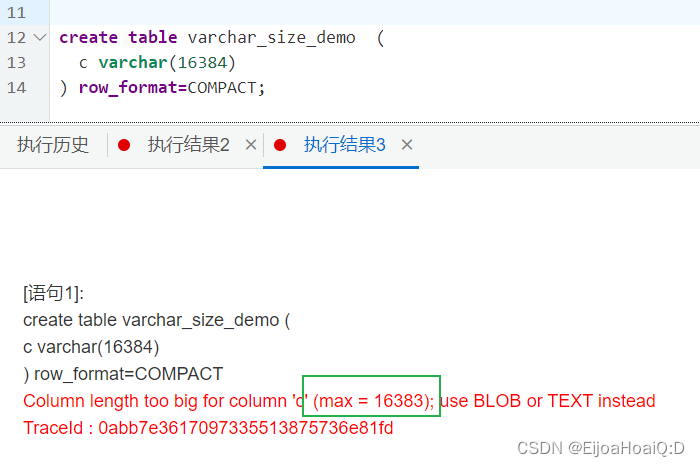
显然还是不能超过 16383 的,所以字符集 utf8mb4 允许的最大长度为 16382。
那么,那 3 个字节跑哪里了呢?
16383 * 4 = 65532,65535 - 65532 = 3。实际上,每一行记录除了存储真实数据之外,还有记录的额外信息中默认会有变长字段长度列表(2 字节)和 NULL 值列表(1 字节)。所以,如果该 varchar 类型的的列没有 NOT NULL 属性,每一行记录都会默认空出来 3 个字节:存储变长字段长度列表和 NULL 值的标识,实际最多只能存储 65532 个字节的数据。
⭐ 采用字符集 utf8
由上文可知,需要预留 3 个字节:65535 - 3 = 65532,65532 / 3 = 21844。
重复上述验证步骤:
由此可知,字符集 utf8 字段的最大长度限制为 21844。
⭐ 采用 ascii 字符集
由上述推断可知,ascii 字符集允许存储字段的最大长度为 65532。
4.3.2 行溢出
根据上文所说的单个字段的最大长度根据不同的字符集,会有不同的限制,8.0.26 默认采用 utf8mb4字符集(4 个字节表示一个字符),最大容量为 65532 字节。
而 InnoDB 中一个数据页的大小是 16 KB,16 * 1024 = 16386 个字节,也就是说,一个 varchar 的容量远远大于一个数据页的大小,这样就可能出现一个页存储不下一行记录的情况,这种情况就叫做行溢出。
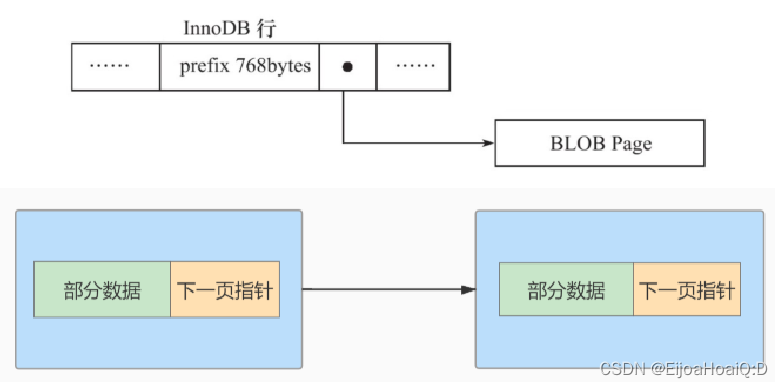
在 Compact 和 Redundant 行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的一部分数据(768 个前缀字节),把剩余的数据分散存储在其他的页中,这叫作分页存储。
然后记录的真实数据处用 20 个字节存储指向这些分散页的地址(这 20 个字节中还包括存储了分散在各个页中的真实数据占用的字节数),从而可以找到剩余数据所在的页,这称为页的扩展,如下图所示:
4.3.3 Dynamic 和 Compressed 行格式
在MySQL 8.0中,默认行格式就是 Dynamic,Dynamic、Compressed 行格式和 Compact 行格式类似,只不过在处理行溢出数据时方式不同:
-
Compact 和 Redundant 两种格式会在记录的真实数据处存储一部分数据(存放768个前缀字节)。
-
Compressed 和 Dynamic 两种行格式不会在记录的真实数据处存储列真实数据的前 768 字节,而是把所有的数据都存储到溢出页中,只在记录的真实数据处存储指向这些溢出页的地址(20 字节),实际的数据都存放在 Off Page(溢出页)中:
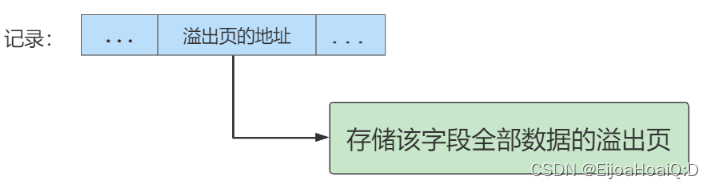
Compressed 和 Dynamic 行格式的区别:Compressed 行格式在 Dynamic 的基础上优化了一层,存储在其中的行数据会以 zlib 的算法进行压缩,因此对于 BLOB、TEXT、VARCHAR 这类大长度类型的数据能够进行非常有效的存储。
4.4 Redundant 行格式
Redundant 是 MySQL5.0 版本之前 InnoDB 的行记录存储格式,MySQL 5.0 支持 Redundant 是为了兼容之前版本的页格式。
我们可以直接修改表的行格式为 Redundant:
alter table record_test_table row_rormat=Redundant;
Redundant 行格式存储格式: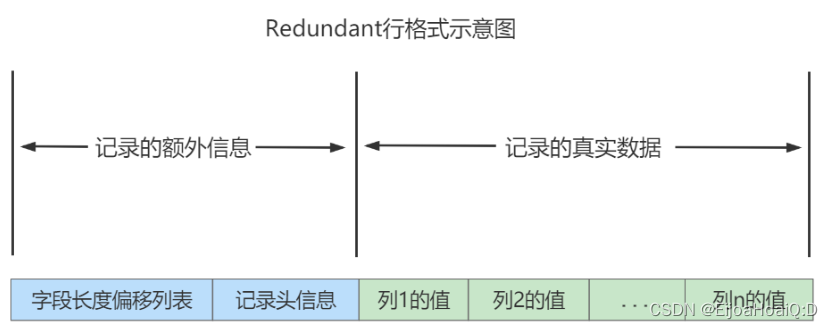
对比 Compact 行格式主要有两大处不同:
- Compact 是变长字段长度列表,Redundant 是字段长度偏移列表。
- Compact 有 NULL 值列表,Redundant 没有 NULL 值列表。
4.4.1 字段长度偏移列表
为什么说 Redundant 行格式会有冗余说法?
因为 Redundant 行格式的字段长度偏移列表会将该行记录中所有列(包括隐藏列)的长度信息都按照逆序存储起来。
偏移两个字,意味着 Redundant 行格式计算列值的长度的方式不像 Compact 行格式那么直观,它是采用两个相邻数值的差值来计算各个列值的长度。
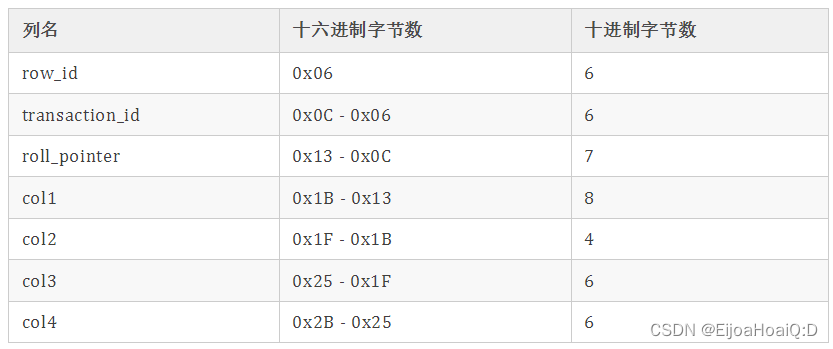
比如第一行记录的字段长度偏移列表(逆序)是:
2B 25 1F 1B 13 0C 06
因为它是按照逆序排列的,所以按照顺序排列就是:
06 0C 13 1B 1F 25 2B
可以看出有三个隐藏列和四个字段列。
按照两个相邻数值的差值来计算各个字段列值的长度的如下表所示:
4.4.2 记录头信息(record header)
不同于 Compact 行格式,Redundant 行格式中的记录头信息固定占用 6 个字节(48 位),每位的含义如下:
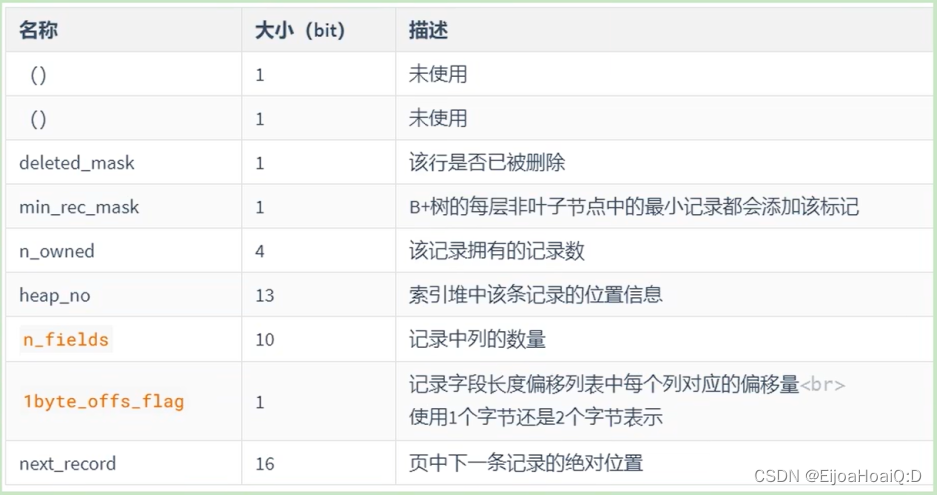
与 Compact 行格式的记录头信息对比来看,有两处不同:
- Redundant 行格式多了 n_field 和 1byte_offs_flag 这两个属性。
- Redundant 行格式没有 record_type 这个属性。
其中两个属性的含义:
-
n_field 代表一行中列的数量,占用 10 位,所以 MySQL5.0 之前的版本最多只能包含 1023 个列。
-
1byte_offs_flags 属性定义了字段长度偏移列表占用 1 个字节,还是 2 个字节(使用 127 作为分界点是因为:127 二进制表示为 01111111,第一位为 NULL 比特位,用来标记是否为 NULL)。
当记录的真实数据占用的字节数不大于 127 时,占用 1 字节;
当记录的真实数据占用的字节数大于 127,但不大于 32767 时,占用 2 字节;
当记录的真实数据大于 32767 时,这部分的数据被存放到溢出页中,使用 2 字节来存储梅格列对应的偏移量。
4.4.3 NULL 值处理
因为 Redundant 行格式没有 NULL 值列表,所以在字段长度偏移列表中对各列对应的偏移量做了一些特殊处理:将列对应的偏移量值的第一个比特位作为是否为 NULL 的依据,该比特位也可以称之为 NULL 比特位。
也就是说,在解析一条记录的某个列时,首先看一下该列对应的偏移量的 NULL 比特位是否为 1,如果为 1,那么该列的值就是 NULL,否则就不是 NULL。
相关文章:
MySQL进阶之(四)InnoDB数据存储结构之行格式
四、InnoDB数据存储结构之行格式 4.1 行格式的语法4.2 COMPACT 行格式4.2.1 记录的额外信息01、变长字段长度列表02、NULL 值列表03、记录头信息 4.2.2 记录的真实数据 4.3 Dynamic 和 Compressed 行格式4.3.1 字段的长度限制4.3.2 行溢出4.3.3 Dynamic 和 Compressed 行格式 4…...
【Qt学习笔记】(四)Qt窗口
Qt窗口 1 菜单栏1.1 创建菜单栏1.2 在菜单栏中添加菜单1.3 创建菜单项1.4 在菜单项之间添加分割线1.5 给菜单项添加槽函数1.6 给菜单项添加快捷键 2 工具栏2.1 创建工具栏2.2 设置停靠位置2.3 设置浮动属性2.4 设置移动属性2.5 添加 Action 3 状态栏3.1 状态栏的创建3.2 在状态…...
 技术应用实践)
入侵和攻击模拟 (BAS) 技术应用实践
文章目录 前言一、实施BAS的必要性二、实施BAS的关键步骤1、识别网络中的脆弱区域2、创建基线安全模型3、选择合适的BAS工具4、进行模拟攻击测试5、分析结果并改进三、BAS实施中的挑战1、组织的专业知识和能力有限2、改变传统工作流程3、安全预算不足4、难以与现有安全基础设施…...

数据结构(七)——线性表的基本操作
🧑个人简介:大家好,我是尘觉,希望我的文章可以帮助到大家,您的满意是我的动力😉 在csdn获奖荣誉: 🏆csdn城市之星2名 …...

Python 系统学习总结(基础语法+函数+数据容器+文件+异常+包+面向对象)
🔥博客主页: A_SHOWY🎥系列专栏:力扣刷题总结录 数据结构 云计算 数字图像处理 力扣每日一题_ 六天时间系统学习Python基础总结,目前不包括可视化部分,其他部分基本齐全,总结记录࿰…...

汽车碰撞与刮伤的实用维修技术,汽车的车身修复与涂装修补教学
一、教程描述 本套汽车维修技术教程,大小7.44G,共有60个文件。 二、教程目录 01-汽车车身修复教程01-安全规则(共3课时) 02-汽车车身修复教程02-汽车结构(共3课时) 03-汽车车身修复教程03-汽车修复所使…...

网络信息安全:nginx漏洞收集(升级至最新版本)
网络&信息安全:nginx漏洞收集(升级至最新版本) 一、风险详情1.1 nginx 越界写入漏洞(CVE-2022-41742)1.2 nginx 缓冲区错误漏洞(CVE-2022-41741)1.3 nginx 拒绝服务漏洞(CNVD-2018-22806) 二、nginx升级步骤 &…...
【go从入门到精通】go包,内置类型和初始化顺序
大家好,这是我给大家准备的新的一期专栏,专门讲golang,从入门到精通各种框架和中间件,工具类库,希望对go有兴趣的同学可以订阅此专栏。 go基础 。 Go文件名: 所有的go源码都是以 ".go" 结尾&…...
)
【项目实战】高并发内存池(仿tcmalloc)
【项目实战】高并发内存池(仿tcmalloc) 作者:爱写代码的刚子 时间:2024.2.12 前言: 当前项目是实现一个高并发的内存池,它的原型是google的一个开源项目tcmalloc,tcmalloc全称 Thread-Caching M…...

计算机等级考试:信息安全技术 知识点一
美国联邦政府颁布数字签名标准(Digital Signature Standard,DSS)的年份是1994美国联邦政府颁布高级加密标准(Advanced Encryption Standard,AES)的年份是2001产生认证码的函数类型通常有3类:消息加密、消息认证码和哈希函数。自主访问控制,Di…...

开展庆2024年“三八”国际妇女节系列纪念活动怎样向媒体投稿?
为了向媒体投稿,庆祝2024年“三八”国际妇女节系列纪念活动,你可以遵循以下步骤: 策划与准备: 确定纪念活动的主题和目标,例如提升女性权益、表彰女性成就、促进性别平等。 策划一系列活动,如研讨会、表彰仪式、展览、讲座等,确保内容丰富多样。 准备相关的背景资料、活动介…...

SpringBoot-集成Elasticsearch
jsoup:https://jsoup.org/ 依赖 <!--解析网页--> <dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.2</version> </dependency> <dependency><groupId>c…...

数据结构之顺序表及其实现!
目录 编辑 1. 顺序表的概念及结构 2. 接口的实现 2.1 顺序表的初始化 2.2 检查顺序表容量是否已满 2.3 顺序表的尾插 编辑 2.4 顺序表的尾删 2.5 顺序表的头插 2.6 顺序表的头删 2.7 顺序表在pos位置插入 2.8 顺序表在pos位置删除 2.9 顺序表的查找 2.10 顺…...

Vue组件间通信实践
Vue组件间通信实践 🌟 前言 欢迎来到我的小天地,这里是我记录技术点滴、分享学习心得的地方。📚 🛠️ 技能清单 编程语言:Java、C、C、Python、Go、前端技术:Jquery、Vue.js、React、uni-app、EchartsUI设…...
FISCO BCOS区块链平台上的智能合约压力测试指南
引言 在当今的分布式系统中,区块链技术因其去中心化、安全性和透明性而备受关注。随着区块链应用的不断扩展,对其性能和稳定性的要求也越来越高。因此,对区块链网络进行压力测试显得尤为重要。 目录 引言 1. 配置FISCO BCOS节点 2. 安装和…...

LabVIEW流量控制系统
LabVIEW流量控制系统 为响应水下航行体操纵舵翼环量控制技术的试验研究需求,通过LabVIEW开发了一套小量程流量控制系统。该系统能够满足特定流量控制范围及精度要求,展现了其在实验研究中的经济性、可靠性和实用性,具有良好的推广价值。 项…...

Python 爱心代码
Python爱心代码是一种用Python编程语言实现的图形化表达方式,可以通过一系列的代码来绘制出一个爱心形状。以下是一个简单的Python爱心代码示例: import turtle # 设置画布和画笔 canvas turtle.Screen() canvas.bgcolor("black") pen turt…...
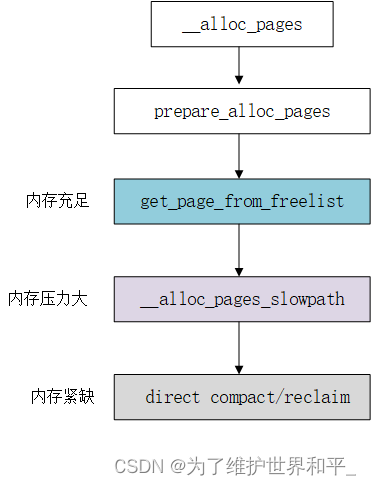
linux kernel物理内存概述(五)
目录 概述 一、快速路径分配 1、get_page_from_freelist 2、rmqueue()函数 二、慢速路径分配 1、分配流程 三、direct_compact 概述 物理内存分配步骤 1、初始化,参数初始化 2、内存充足,快速分配 get_page_from_freelist 3、内存压力大,慢速…...
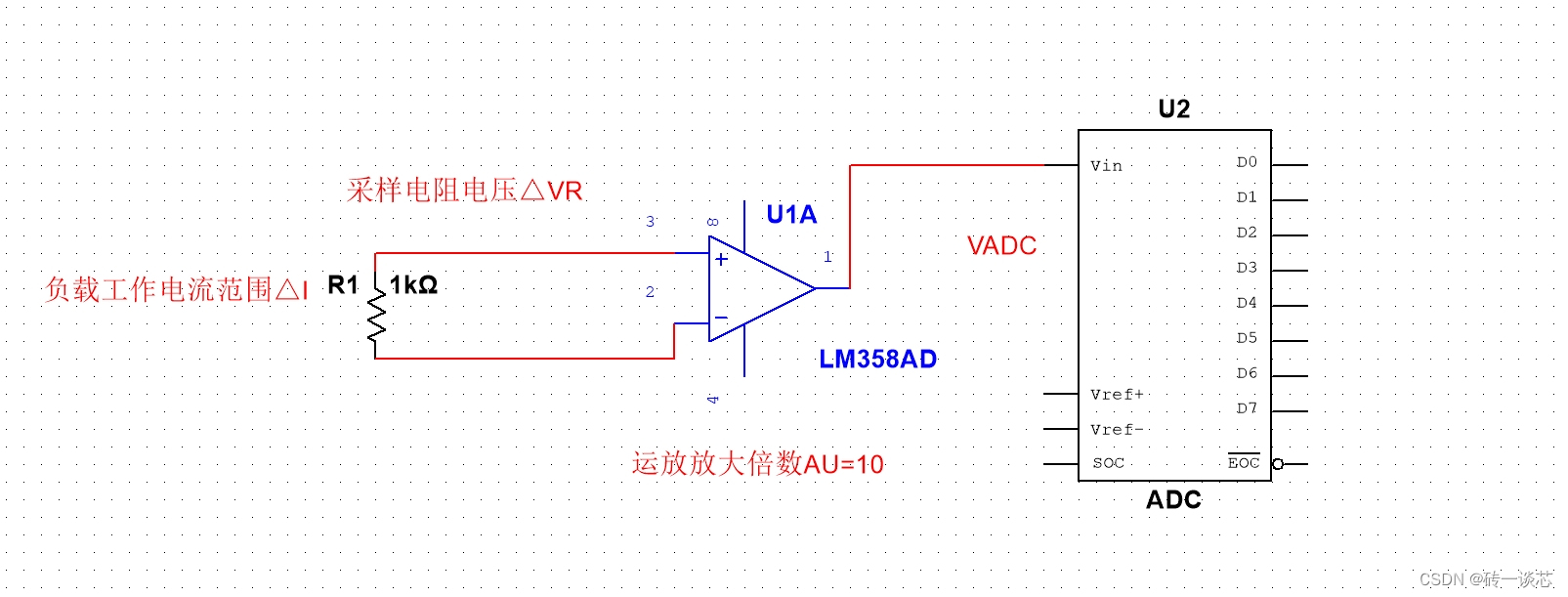
3分钟带你搞定电流采样电阻选型
大家好,我是砖一。 一,电流采样电阻的介绍 电流检测电路常用于高压短路保护、电机控制、DC/DC换流器、系统功耗管理、二次电池的电流管理、蓄电池管理等电流检测等场景。 比如,对于电机来说,电流检测电路是为了检测电流功能有比…...

代码随想录算法训练营Day52 | 300.最长递增子序列、674.最长连续递增序列、718.最长重复子数组
300.最长递增子序列 这题的重点是DP数组的定义,子序列必须以nums[i]为最后一个元素,这样dp数组中后面的元素才能与前面的元素进行对比 1、DP数组定义:dp[i]表示以nums[i]为最后一个元素的最长递增子序列长度 2、DP数组初始化:全部…...

每天节省25分钟!淘宝淘金币全自动任务脚本终极指南
每天节省25分钟!淘宝淘金币全自动任务脚本终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌…...

告别盲测!用CANoe回放功能搭建你的车载网络自动化测试环境
告别盲测!用CANoe回放功能搭建你的车载网络自动化测试环境 车载网络测试工程师们是否经常遇到这样的困境:每次路试或台架测试后,堆积如山的CAN日志只能用于临时问题排查,无法形成可复用的测试资产?当需要验证某个历史问…...

耕耘皆有回响,蓄力终会绽放
在日常的学习和生活当中,我们常常会听到这样一句话:耕耘皆有回响,蓄力终会绽放。简简单单一句话,没有华丽的辞藻,却说出了最实在的道理。不管是孩子读书求学,还是我们普通人做人做事,都离不开踏…...

Linux驱动开发:模块参数传递机制详解与工程实践
1. 项目概述:驱动安装与参数传递的“暗语”艺术在Linux驱动开发的世界里,把驱动模块加载进内核,就像给一个正在高速运转的精密机器安装一个新的零件。而“安装驱动参数传递”,就是这个安装过程中,我们与内核、与新零件…...

AI英语智能体的开发
构建一个专门用于英语学习的AI智能体(AI Agent),核心在于如何将大语言模型(LLM)的通用能力,转化为符合二语习得(SLA)理论的教学逻辑。这类智能体不仅需要“懂英语”,更需…...

Sourcetree新手指南:从零配置到高效版本控制
1. Sourcetree入门:为什么选择图形化Git工具 第一次接触版本控制时,我对着黑漆漆的命令行窗口敲git命令的手都在发抖。直到发现了Sourcetree这个神器,才真正体会到什么叫"可视化操作"。作为Atlassian公司出品的免费工具࿰…...

负载电阻从500Ω到10kΩ:用Multisim深度解读谐振放大器选择性变化的底层逻辑
负载电阻从500Ω到10kΩ:用Multisim深度解读谐振放大器选择性变化的底层逻辑 在电子电路设计中,谐振放大器是一个经典而重要的电路结构。许多工程师和爱好者都能熟练地搭建电路并进行基础测试,但当被问及"为什么负载电阻的变化会影响放大…...

为什么93%的AI法律助手查不准《数据安全法》实施细则?Perplexity这项冷启动参数设置决定成败
更多请点击: https://codechina.net 第一章:Perplexity法规查询功能的底层架构原理 Perplexity法规查询功能并非基于传统关键词匹配的搜索引擎,而是构建在多层语义理解与结构化知识协同推理的基础之上。其核心由法规知识图谱、实时语义解析引…...

Qalculate! 终极数学计算库:从新手到专家的完整指南
Qalculate! 终极数学计算库:从新手到专家的完整指南 【免费下载链接】libqalculate Qalculate! library and CLI 项目地址: https://gitcode.com/gh_mirrors/li/libqalculate Qalculate! 是一个功能强大的开源数学计算库,它提供了从简单算术到复杂…...

Perplexity学校信息检索终极手册:覆盖K12/高职/高校的12类典型场景+27个可复用Prompt模板
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索终极手册导论 在教育数字化加速演进的今天,高校师生亟需一种高效、可信且语义精准的信息获取方式。Perplexity 作为融合实时网络检索与大语言模型推理能力的智能问答平台&…...