ElasticSearch搜索引擎使用指南
一、ES数据基础类型
1、数据类型
字符串
主要包括: text和keyword两种类型,keyword代表精确值不会参与分词,text类型的字符串会参与分词处理
数值
包括: long, integer, short, byte, double, float
布尔值
boolean
时间
date
数组
数组类型不需要专门定义,只要插入的字段值是json数组就行
GEO类型
主要涉及地理信息检索、多边形区域的表达
2、text&keyword使用注意
text类型,支持全文搜索,因为text涉及分词,所以可以配置使用什么分词器,尤其涉及中文分词。
实际项目中,如果不需要模糊搜索的字符类型,可以选择keyword类型,例如:手机号、email、微信的openid等等,如果选text类型,可能会出现搜出一大堆相似的数据,而且不是精确的数据。
二、query语法
query子句主要用于编写查询条件,类似于SQL中的where语句。
query子句主要用于编写类似SQL的where语句,支持布尔查询(and/or)、IN、全文搜索、模糊匹配、范围查询(大于/小于)。
其中:text类型字段支持分词,可以使用模糊查询。keyword类型只能做等值查询,不能进行分词。
1、match类like匹配
1.1 match匹配单个字段
使用match实现全文搜索。类似于SQL中的like操作。
简单使用的语法:
GET /{索引名}/_search
{"query": {"match": {"{FIELD}": "{TEXT}"}}
}说明:
{FIELD} - 就是我们需要匹配的字段名
{TEXT} - 就是我们需要匹配的内容
例子:
GET /article/_search
{"query": {"match" : {"title" : "ES教程"}}
}article索引中,title字段匹配“ES教程”的所有文档。
如果title字段的数据类型是text类型,搜索关键词会进行分词处理。
等价SQL(假设"ES教程"没有进行分词):
select * from article where title like '%ES教程%'1.2 multi_match多字段匹配
例子:
GET /article/_search
{"query": {"multi_match": {"query": "斯柯达前轮制动器","fields":["doc_title","doc_content"]}}
}等价SQL:
select * from article where doc_title like '%<斯柯达前轮制动器的分词>%' or doc_content like '%<斯柯达前轮制动器的分词>%'因为 斯柯达前轮制动器的分词 会有很多,所以实际上也会有很多的like,而不仅仅是上面的两个like。
1.3 multi_phrase顺序匹配
match_phrase查询是ES中一种用于精确匹配短语的查询方式,可以确保查询字符串中的关键词按照给定的顺序在文档中连续出现。
说明:检索词还是进行分词的,分词后的各个单词的顺序在 被检索的文中是一样的。
例子:
GET /article/_search
{"query": {"match_phrase": {"doc_content": "制动器装配"}}
}搜索结果:

1.4 operator的布尔操作
指定分词匹配的布尔规则,默认情况下operator为or,即分词中有一个匹配即可。
当operator为and时,需要文档匹配所有的分词。
例子:
GET demo_idx/_search
{"query": {"match": {"content": {"query": "simple rest apis distributed nature","operator": "and"}}}
}1.5 结合operator、boost及match_phrase的查询
我们希望精确匹配在搜索结果中排名较高,但也希望看到结果中相关性较低的文档,此时使用should子句来组合OR、AND和match短语查询。布尔查询中的should子句采用更好匹配的方法,因此每个子句的得分将为每个文档的最终_score做出贡献。
GET demo_idx/_search
{"query": {"bool": {"should": [{"match": {"content": {"query": "simple rest apis distributed nature"}}},{"match": {"content": {"query": "simple rest apis distributed nature","operator": "and"}}},{"match_phrase": {"content": {"query": "simple rest apis distributed nature","boost": 2}}}]}}
}2、term精确匹配单个字段
使用term实现精确匹配。
如果想要类似SQL语句中的等值匹配,不需要进行分词处理,例如:订单号、手机号、时间字段,不需要分值处理,只要精确匹配。
语法:
GET /{索引名}/_search
{"query": {"term": {"{FIELD}": "{VALUE}"}}
}{FIELD} - 就是我们需要匹配的字段名
{VALUE} - 就是我们需要匹配的内容,除了TEXT类型字段以外的任意类型。
例子:
GET /order_v2/_search
{"query": {"term": {"order_no": "202003131209120999"}}
}搜索订单号order_no = "202003131209120999"的文档。
类似SQL语句:
select * from order_v2 where order_no = "202003131209120999"3、terms实现SQL的in语句
如果我们要实现SQL中的in语句,一个字段包含给定数组中的任意一个值就匹配。
语法:
GET /order_v2/_search
{"query": {"terms": {"{FIELD}": ["{VALUE1}","{VALUE2}"]}}
}说明:
{FIELD} - 就是我们需要匹配的字段名
{VALUE1}, {VALUE2} … {VALUE N} - 就是我们需要匹配的内容,除了TEXT类型字段以外的任意类型。
例子:
GET /order_v2/_search
{"query": {"terms": {"shop_id": [123,100,300]}}
}搜索order_v2索引中,shop_id字段,只要包含[123,100,300]其中一个值,就算匹配。
类似SQL语句:
select * from order_v2 where shop_id in (123,100,300)4、range范围查询
通过range实现范围查询,类似SQL语句中的>, >=, <, <=表达式。
语法:
GET /{索引名}/_search
{"query": {"range": {"{FIELD}": {"gte": 10, "lte": 20}}}
}参数说明:
{FIELD} - 字段名
gte范围参数 - 等价于>=
lte范围参数 - 等价于 <=
范围参数可以只写一个,例如:仅保留 “gte”: 10, 则代表 FIELD字段 >= 10
范围参数如下:
gt - 大于 ( > )
gte - 大于且等于 ( >= )
lt - 小于 ( < )
lte - 小于且等于 ( <= )例子:
GET /order_v2/_search
{"query": {"range": {"shop_id": {"gte": 10,"lte": 200}}}
}查询order_v2索引中,shop_id >= 10 且 shop_id <= 200的文档。类似SQL:
select * from order_v2 where shop_id >= 10 and shop_id <= 2005、bool组合查询
前面的例子都是设置单个字段的查询条件,如果想要编写类似SQL的Where语句组合多个字段的查询条件,可以使用bool语句。
5.1 bool查询基本语法结构
语法:
GET /{索引名}/_search
{"query": {"bool": { // bool查询"must": [], // must条件,类似SQL中的and, 代表必须匹配条件"must_not": [], // must_not条件,跟must相反,必须不匹配条件"should": [] // should条件,类似SQL中or, 代表匹配其中一个条件}}
}
must、must_not和should条件的参数都是一个数组,意味着他们都支持设置多个条件。
同时,前面介绍的单个字段的匹配语句,都可以用在bool查询语句中进行组合。
5.2 must条件
类似SQL的and,代表必须匹配的条件。
语法:
GET /{索引名}/_search
{"query": {"bool": {"must": [{匹配条件1},{匹配条件2},...可以有N个匹配条件...]}}
}
例子:
GET /order_v2/_search
{"query": {"bool": {"must": [{"term": {"order_no": "202003131209120999"}},{"term": {"shop_id": 123}}]}}
}
这里的Must条件,使用了term精确匹配,等价SQL:
select * from order_v2 where order_no="202003131209120999" and shop_id=1235.3 must_not条件
跟must的作用相反,语法类似。
5.4 should条件
类似SQL中的 or, 只要匹配其中一个条件即可。
语法:
GET /{索引名}/_search{"query": {"bool": {"should": [{匹配条件1},{匹配条件2},…可以有N个匹配条件…]}}}例子:
GET /order_v2/_search
{"query": {"bool": {"should": [{"term": {"order_no": "202003131209120999"}},{"term": {"order_no": "22222222222222222"}}]}}
}等价SQL:
select * from order_v2 where order_no="202003131209120999" or order_no="22222222222222222"5.5 bool综合例子
GET /order_v2/_search
{"query": {"bool": {"should": [{"bool": {"must": [{"term": {"order_no": "2020031312091209991"}},{"range": {"shop_id": {"gte": 10,"lte": 200}}}]}},{"terms": {"tag": [1,2,3,4,5,12]}}]}}
}等价SQL:
select * from order_v2 where (order_no='202003131209120999' and (shop_id>=10 and shop_id<=200)) or tag in (1,2,3,4,5)
6、wildcard通配符查询
wildcard 关键字: 通配符查询 ? 用来匹配一个任意字符 * 用来匹配多个任意字符。
例子:
GET /xizi/emp/_search{"query": {"wildcard": {"name": {"value": "xi*"}}}}7、fuzzy模糊查询
fuzzy 模糊查询,最大模糊错误必须在0-2之间
搜索关键词长度为 2 不允许存在模糊 0
搜索关键词长度为3-5 允许一次模糊 0 1
搜索关键词长度大于5 允许最大2模糊
例子:
GET /xizi/emp/_search{"query": {"fuzzy": {"name":"xizi"}}}8、额外限制条件
8.1 _source指定返回字段
例子1:
get lib3/user/_search
{"_source":["name","age"],"query":{"match": {"interests": "changge"}}
结果只返回索引中name和age字段信息
例子2:
get lib3/user/_search
{"query":{"match_all": {}},"_source":{"includes": "addr*","excludes": ["name","bir*"]}
}显示要的字段、去除不需要的字段、可以使用通配符*。
8.2 boost查询的权重
boost值控制每个查询子句的相对权重,该值默认为1。
boost参数被用来增加一个子句的相对权重(当boost大于1时),或者减小相对权重(当boost介于0到1时),但是增加或者减小不是线性的。换言之,boost设为2并不会让最终的_score加倍。
例子:
GET/_search{"query": {"bool": {"must": {"match": {"content": {"query": "full text search","operator": "and"}}},"should": [{"match": {"content": {"query": "Elasticsearch","boost": 3}}},{"match": {"content": {"query": "Lucene","boost": 2}}}]}}
}8.3 min_similarity设置匹配的最小相似度
8.4 highlight高亮搜索结果
例子:
get data_info/_search
{"_source":["doc_title","doc_content"],"query": {"match": {"doc_content": "斯柯达前轮制动器"}},"highlight":{"fields":{"doc_content":{}}}
}返回结果:

8.5 size指定返回条数
ES默认返回10条结果。
例子:
get data_info/_search
{"query": {"match": {"doc_content": "斯柯达前轮制动器"}},"size": 2
}结果中只有2条信息。
8.6 from分页查询
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果。
例子:
get data_info/_search
{"query": {"match": {"doc_content": "斯柯达前轮制动器"}},"size": 2,"from": 3
}8.7 sort指定字段排序
使用该属性会让得分失效。
例子:
GET /db_idx4/_search
{"query":{"match_all":{}},"sort":[{"age":"desc"}]
}
8.8 explain查看分数计算详情
ES提供了一个解释性API和一个解释性查询参数以了解如何计算分数。
例子:
GET /db_idx4/_search
{"explain": true,"query": {"match_phrase": {"doc_content": "制动器装配"}}
}结果示例:

三、全文搜索
1、概念
平时我们使用SQL like语句搜索一些文本、字符串是否包含指定的关键词,如果两篇文章都包含我们的关键词,那么具体哪篇文章内容的相关度更高?这个SQL的like语句是做不到的,更别说like语句的性能问题了。
ES通过分词、相关度计算可以解决这个问题,ES内置了一些相关度算法,大致上意思是:如果一个关键词在一篇文章出现的频率高,并且在其他文章中出现少,那说明这个关键词与这篇文章的相关度很高。
ES对于text类型的字段,在插入数据的时候,会进行分词处理,然后根据分词的结果索引文档,当我们搜索text类型字段的时候,也会先对搜索关键词进行分词处理、然后根据分词的结果去搜索。
2、文档评分计算
2.1 默认评分影响因素
ES使用的默认评分算法是BM25,决定文档得分的3个主要因素:
- 字词频率(TF):搜索字词在我们正在搜索的文档中的字段中出现的次数越多,则该文档越相关
- 反向文档频率(IDF):在我们要搜索的字段中包含搜索词的文档越多,该词的重要性就越低
- 字段长度:如果文档在非常短的字段(即,只有几个单词)中包含搜索词,则比文档在较长的字段(即,包含很多单词)中包含搜索词更相关
2.2 使用function_score和script_score定制搜索结果分数
function_score和script_score是很耗资源的,所以实际使用时只需要计算一组经过过滤的文档的分数。
script_score定制的例子:
GET best_games/_search
{"_source": ["name","critic_score","user_score"],"query": {"script_score": {"query": {"match": {"name": "Final Fantasy"}},"script": {"source": "_score * (doc['user_score'].value*10+doc['critic_score'].value)/2/100"}}}
}具体细节参考:Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数-CSDN博客
3、分词效果测试
语法:
GET /_analyze
{"text": "需要分词的内容","analyzer": "分词器"
}例子:
GET http://xx.elasticsearch.aliyuncs.com:9200/_analyze
{"text":"上海大学","analyzer": "standard"
}使用standard分词器,对"上海大学"进行分词,下面是输出结果:
{"tokens": [{"token": "上","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "海","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "大","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2},{"token": "学","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 3}]
}token就是分解出来的关键词。
四、难点剖析
1、filter与must的区别
同样是按条件匹配,filter不统计相关度,must统计相关度。就是filter不计算score分数值,而must是计算的。所以must比filter计算更复杂、更耗时。
具体参考:Elasticsearch Query: filter与must的区别_elasticsearch must 和filter的区别-CSDN博客
相关文章:
ElasticSearch搜索引擎使用指南
一、ES数据基础类型 1、数据类型 字符串 主要包括: text和keyword两种类型,keyword代表精确值不会参与分词,text类型的字符串会参与分词处理 数值 包括: long, integer, short, byte, double, float 布尔值 boolean 时间 date 数组 数组类型不…...

mysql与oracle的区别
一、并发性并发性是oltp数据库最重要的特性,但并发涉及到资源的获取、共享与锁定。mysql:mysql以表级锁为主,对资源锁定的粒度很大,如果一个session对一个表加锁时间过长,会让其他session无法更新此表中的数据。虽然InnoDB引擎的表…...

JVM相关面试题及常用命令参数
JVM常用命令和参数 常用命令: jps:查看进程及其相关信息 jmap:用来生成dump文件和查看堆相关的各类信息的命令 jstat:查看jvm运行时的状态信息 jstack:查看jvm线程快照的命令 jinfo:查看jvm参数和动态修改…...

Material UI 5 学习01-按钮组件
Material UI 5 学习01-按钮组件 一、安装Material UI二、 组件1、Button组件1、基础按钮2、variant属性3、禁用按钮4、可跳转的按钮5、disableElevation属性6、按钮的点击事件onClick 2、Button按钮的颜色和尺寸1、Button按钮的颜色2、按钮自定义颜色3、Button按钮的尺寸 3、图…...

解决移除数字问题的两种方法:暴力法和使用栈
题目 给你一个以字符串表示的非负整数 num 和一个整数 k ,移除这个数中的 k 位数字,使得剩下的数字最小。请你以字符串形式返回这个最小的数字 示例 1 : 输入:num "1432219", k 3 输出:"1219"…...

高校宣讲会管理系统|基于Springboot的高校宣讲会管理系统设计与实现(源码+数据库+文档)
高校宣讲会管理系统目录 目录 基于Springboot的高校宣讲会管理系统设计与实现 一、前言 二、系统功能设计 1、学生信息管理 2、企业信息管理 3、宣讲会管理 4、公告信息管理 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 …...

6_怎么看原理图之协议类接口之LCD笔记
首先想一想再前几篇文章讲的协议类的前提 1、双方约定好通信的协议 2、双方满足一定的时序要求 以上第二点又有一些要求: 1)弄清2440在这个通信协议中,能设置哪些时序的值,这些值的含义是什么——2440手册 2)弄清楚这…...
SpringCloud Alibaba 学习
一:SpringCloud Alibaba介绍 Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服 务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。 依托 Spring Cloud Alibaba&…...

【ros2 control 机器人驱动开发】双关节多控制器机器人学习-example 4
【ros2 control 机器人驱动开发】双关节多控制器机器人学习-example 4 文章目录 前言一、创建controller相关二、测试运行测试forward_position_controller总结前言 本篇文章在上篇文章的基础上主要讲解双轴机器人驱动怎么编写机器人外部/内部(扭矩、压力)传感器数据反馈1,…...

Leetcode 3071. Minimum Operations to Write the Letter Y on a Grid
Leetcode 3071. Minimum Operations to Write the Letter Y on a Grid 1. 解题思路2. 代码实现 题目链接:3071. Minimum Operations to Write the Letter Y on a Grid 1. 解题思路 这一题思路上也是比较直接的,就是首先找到这个Y字符,然后…...

随想录算法训练营第五十一天|309.最佳买卖股票时机含冷冻期、714.买卖股票的最佳时机含手续费
309.最佳买卖股票时机含冷冻期 public class Solution {public int MaxProfit(int[] prices) {if(prices.Length<2){return 0;}int [,]dpnew int[prices.Length,4];dp[0,0]-prices[0];for(int i1;i<prices.Length;i){dp[i,0]Math.Max(dp[i-1,0],Math.Max(dp[i-1,3]-pric…...
【语言学习】std::transform函数
阅读llvm的这个提交时,发现了其中使用了一个函数std::transform(原文对其进行了一层封装) 如果不理解std::transform的三个参数的关系,就会对第三个参数的lambda表达式理解不了。其实,第三个参数的作用是提供给了一种…...
Java开发面试准备,轻松搞定SpringBoot数据校验
程序员:给多少工资,干多少事 我们不是经常会看到一个关于西游记的“悖论”吗: 为什么孙悟空初期大闹天宫的时候那么厉害?因为他自己当老板,打一群天庭的打工仔。 为什么取经路上又变得不行了?作为一个打工…...
信呼OA普通用户权限getshell方法
0x01 前言 信呼OA是一款开源的OA系统,面向社会免费提供学习研究使用,采用PHP语言编写,搭建简单方便,在中小企业中具有较大的客户使用量。从公开的资产治理平台中匹配到目前互联中有超过1W的客户使用案例。 信呼OA目前最新的版本是…...
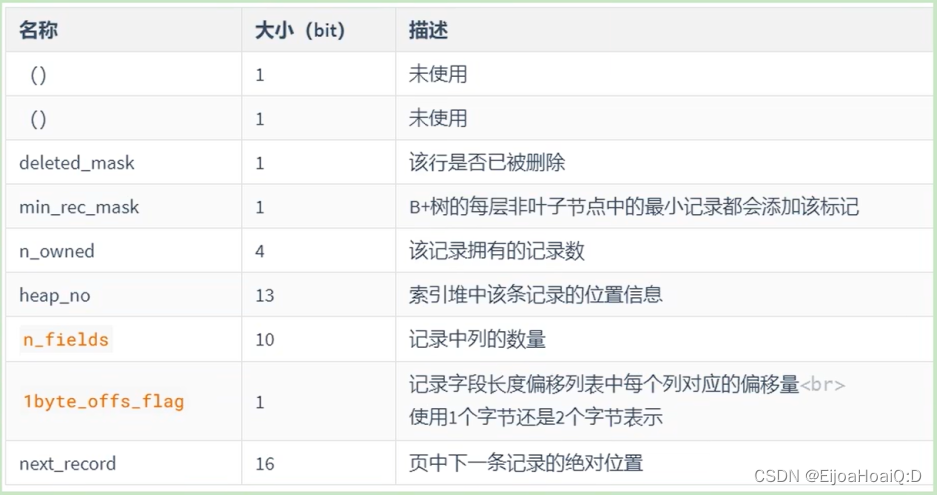
MySQL进阶之(四)InnoDB数据存储结构之行格式
四、InnoDB数据存储结构之行格式 4.1 行格式的语法4.2 COMPACT 行格式4.2.1 记录的额外信息01、变长字段长度列表02、NULL 值列表03、记录头信息 4.2.2 记录的真实数据 4.3 Dynamic 和 Compressed 行格式4.3.1 字段的长度限制4.3.2 行溢出4.3.3 Dynamic 和 Compressed 行格式 4…...
【Qt学习笔记】(四)Qt窗口
Qt窗口 1 菜单栏1.1 创建菜单栏1.2 在菜单栏中添加菜单1.3 创建菜单项1.4 在菜单项之间添加分割线1.5 给菜单项添加槽函数1.6 给菜单项添加快捷键 2 工具栏2.1 创建工具栏2.2 设置停靠位置2.3 设置浮动属性2.4 设置移动属性2.5 添加 Action 3 状态栏3.1 状态栏的创建3.2 在状态…...
 技术应用实践)
入侵和攻击模拟 (BAS) 技术应用实践
文章目录 前言一、实施BAS的必要性二、实施BAS的关键步骤1、识别网络中的脆弱区域2、创建基线安全模型3、选择合适的BAS工具4、进行模拟攻击测试5、分析结果并改进三、BAS实施中的挑战1、组织的专业知识和能力有限2、改变传统工作流程3、安全预算不足4、难以与现有安全基础设施…...

数据结构(七)——线性表的基本操作
🧑个人简介:大家好,我是尘觉,希望我的文章可以帮助到大家,您的满意是我的动力😉 在csdn获奖荣誉: 🏆csdn城市之星2名 …...

Python 系统学习总结(基础语法+函数+数据容器+文件+异常+包+面向对象)
🔥博客主页: A_SHOWY🎥系列专栏:力扣刷题总结录 数据结构 云计算 数字图像处理 力扣每日一题_ 六天时间系统学习Python基础总结,目前不包括可视化部分,其他部分基本齐全,总结记录࿰…...

汽车碰撞与刮伤的实用维修技术,汽车的车身修复与涂装修补教学
一、教程描述 本套汽车维修技术教程,大小7.44G,共有60个文件。 二、教程目录 01-汽车车身修复教程01-安全规则(共3课时) 02-汽车车身修复教程02-汽车结构(共3课时) 03-汽车车身修复教程03-汽车修复所使…...
)
PTA数据结构天梯赛L2-001:手把手教你用Dijkstra算法搞定双权值最短路径(附C语言完整代码)
PTA数据结构天梯赛L2-001:双权值最短路径的Dijkstra算法实战解析 在算法竞赛和数据结构课程中,图论问题一直是考察重点和难点。面对PTA天梯赛L2-001这类需要同时考虑时间和距离两个权值的最短路径问题,传统的单权值Dijkstra算法需要经过巧妙…...
)
不只是模拟器:用Android-x86把你的旧笔记本变成安卓平板(附VirtWifi联网指南)
旧笔记本重生计划:用Android-x86打造高性能安卓工作站 你是否有一台闲置多年的旧笔记本,性能早已跟不上现代操作系统的需求,却又舍不得丢弃?别急着让它沦为电子垃圾,通过Android-x86项目,这些老设备完全可以…...

OPNsense安装选UFS还是ZFS?从硬件选择到文件系统性能的完整决策指南
OPNsense安装选UFS还是ZFS?从硬件选择到文件系统性能的完整决策指南 在部署OPNsense防火墙时,文件系统选择往往被忽视,却直接影响系统性能、数据安全和运维效率。UFS和ZFS的抉择不仅关乎安装时的选项勾选,更关系到长期运行的稳定性…...

CATCCOS核心组件深度解析:从Host到Device的分层架构设计原理
CATCCOS核心组件深度解析:从Host到Device的分层架构设计原理 【免费下载链接】catccos CATCCOS昇腾计算-通信融合算子模板库,是一个聚焦于提供高性能计算通信融合类算子基础模板的代码库。 项目地址: https://gitcode.com/cann/catccos CATCCOS昇…...

AI服务先看工作流
很多人买 AI 服务时,还是按买会员的方式看:哪个模型名气大,哪个月费便宜,哪个 Token 多。这个习惯很自然,但它很容易把钱花在用不起来的地方。 最近几个问题放在手边看,会发现同一个提醒。手机店卖不动新机…...

Vibe Coding 工具选型决策树:5 类项目场景对应 7 种组合配置方案
1. 项目概述:为什么“选对组合”比“选对单个工具”更重要 大多数人第一次听说 vibe coding,是在看到某位工程师用 Cursor 写完一个 Vue3 表单组件只花了 90 秒,或者用 Claude Code 在 VS Code 里补全了整套 Express 路由逻辑后脱口而出的那句“这哪是写代码,这是调 API”…...

Windows终极HEIC预览方案:免费解锁苹果照片缩略图
Windows终极HEIC预览方案:免费解锁苹果照片缩略图 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPhone拍摄的…...

你的TP53基因在哪个数据库?一文搞懂Ensembl ID、Entrez ID、UniProt ID在生信分析中的实战选择
你的TP53基因在哪个数据库?一文搞懂Ensembl ID、Entrez ID、UniProt ID在生信分析中的实战选择 在基因组学研究中,一个基因就像一位国际旅行者,每到一个国家(数据库)就会获得一个新的护照号码(基因ID&#…...

工业 DC-DC 标准封装设计探讨 钡特电源 DB2-12D15D 与金升阳 A1215D-2WR3 工业模块电源盘点
在工业控制与嵌入式系统设计中,12V 输入转 15V 输出的 2W 隔离供电方案,是模拟电路、信号调理模块的核心供电选择。伴随国内电子制造技术持续突破,国产直流电源模块在标准化封装、电气性能稳定性上不断贴合行业通用规范,成为推动国…...

从零到告警:用Prometheus+SNMP监控华为交换机,并配置Grafana看板与告警规则
从零构建华为交换机智能监控体系:PrometheusSNMP实战指南 当机房里的华为交换机突然宕机时,运维团队往往要面对业务部门的连环追问。传统的人工巡检方式就像用体温计量火山喷发——既滞后又无力。本文将手把手带您搭建从数据采集到告警响应的完整监控闭环…...