【数仓】flume常见配置总结,以及示例
相关文章
- 【数仓】基本概念、知识普及、核心技术
- 【数仓】数据分层概念以及相关逻辑
- 【数仓】Hadoop软件安装及使用(集群配置)
- 【数仓】Hadoop集群配置常用参数说明
- 【数仓】zookeeper软件安装及集群配置
- 【数仓】kafka软件安装及集群配置
- 【数仓】flume软件安装及配置
Flume常见配置说明
1. Source
Source是Flume体系中的第一个组件,负责从外部数据源接收数据,并将这些数据传递到Channel中。这些数据源可以是日志文件、网络端口、消息队列等。
1.1 Avro Source
type: 指定Source的类型为avro。Avro是一个数据序列化系统,Avro Source允许Flume接收通过Avro协议发送的数据。bind: 指定监听的IP地址。Flume将在这个IP地址上监听传入的数据。port: 指定监听的端口号。Flume将在这个端口上接收数据。
1.2 Exec Source
type: 指定Source类型为exec。Exec Source允许Flume通过执行外部命令来接收数据。command: 要执行的命令。这个命令的输出将被Flume捕获并传递到Channel中。例如,tail -F /var/log/syslog命令会实时读取系统的日志文件。
1.3 Kafka Source
type: 指定Source类型为org.apache.flume.source.kafka.KafkaSource。Kafka是一个分布式消息队列,Kafka Source允许Flume从Kafka主题中消费数据。kafka.bootstrap.servers: Kafka集群的地址列表。Flume将连接到这些服务器以消费数据。kafka.topics: 要消费的主题列表。Flume将从这些主题中读取数据。
1.4 NetCat Source
type: 指定Source类型为netcat。NetCat Source允许Flume通过TCP/IP网络接收数据。bind: 指定监听的IP地址。Flume将在这个IP地址上监听传入的数据。port: 指定监听的端口号。Flume将在这个端口上接收数据。
1.5 TAILDIR Source
type: 指定Source的类型为TAILDIR。TAILDIR Source是Flume中用于实时监控文件变化并采集新增数据的组件,它更加可靠和高效,能够确保数据的零丢失。positionFile: 指定用于存储文件偏移量的JSON文件的路径。这个文件记录了每个被监控文件的当前读取位置,以确保在Flume重启后能够继续从正确的位置读取数据,实现数据的连续性和完整性。filegroups: 定义要监控的文件组。每个文件组可以包含多个文件路径和通配符模式,用于匹配需要采集的文件。这提供了灵活性,允许用户根据需求指定特定的文件或目录进行监控。files: 在每个文件组内,指定具体的文件路径和通配符模式。可以使用正则表达式或简单的通配符来匹配文件名,从而精确地指定要采集的文件。channels: 指定与该Source关联的Channel的名称。这是数据流向下游组件的桥梁,确保数据能够正确地传输到指定的Channel中。
2. Channel
Channel是Flume体系中的第二个组件,负责存储从Source接收到的数据,直到Sink准备好将其发送到目标位置。Channel保证了数据的可靠性和持久性。
2.1 Memory Channel
type: 指定Channel类型为memory。Memory Channel将数据存储在内存中,具有较快的读写速度。capacity: 存储在Channel中的最大事件数。当达到这个容量时,新的数据将无法进入Channel,直到有数据被Sink消费。transactionCapacity: 每次事务中可以从Channel中取出或放入的最大事件数。这影响了数据在Channel和Sink之间的传输速度。
2.2 File Channel
type: 指定Channel类型为file。File Channel将数据存储在磁盘上,保证了数据的持久性。dataDirs: 用于存储事件数据的目录列表。数据将被分散存储在这些目录中,提高了数据的可靠性和可扩展性。checkpointDir: 用于存储Channel状态检查点的目录。检查点记录了数据的读取和写入位置,确保在Flume重启后能够恢复状态。capacity: 存储在Channel中的最大事件数。与Memory Channel类似,当达到这个容量时,新的数据将无法进入Channel。
2.3 Kafka Channel
type: 指定Channel类型为org.apache.flume.channel.kafka.KafkaChannel。Kafka Channel将数据存储在Kafka集群中,结合了Kafka的高可靠性和可扩展性。kafka.bootstrap.servers: Kafka集群的地址列表。Flume将连接到这些服务器以存储和读取数据。kafka.topic: 用于存储事件的Kafka主题。数据将被写入这个主题,并从这个主题中读取出来进行后续处理。parseAsFlumeEvent: 是否将消息解析为Flume事件。如果设置为true,则消息将被解析为Flume事件格式进行存储和传输;如果设置为false,则消息将以原始格式存储。
3. Sink
Sink是Flume体系中的最后一个组件,负责从Channel中取出数据并将其发送到目标位置。这些目标位置可以是HDFS、Kafka、数据库等。
3.1 HDFS Sink
type: 指定Sink类型为hdfs。HDFS(Hadoop Distributed FileSystem)是一个分布式文件系统,HDFS Sink将数据写入到HDFS中进行存储和分析。hdfs.path: HDFS上的目标路径。数据将被写入这个路径下的文件中。hdfs.fileType: 文件类型指定了数据的存储格式,如DataStream或SequenceFile等。不同的格式有不同的存储方式和压缩选项。hdfs.writeFormat: 写入格式指定了数据在文件中的排列方式,如Text表示按行写入文本数据,Writable表示使用Hadoop的Writable接口进行序列化后写入。hdfs.batchSize: 每个批次写入HDFS的事件数。这影响了数据写入HDFS的速度和效率。较大的批次可以减少写入操作的次数,但也会增加内存消耗和延迟。
3.2 Kafka Sink
type: 指定Sink类型为org.apache.flume.sink.kafka.KafkaSink。Kafka Sink将数据发送到Kafka集群中进行存储和处理。Kafka的高吞吐量和可扩展性使其成为大数据处理中的常用组件。kafka.bootstrap.servers: Kafka集群的地址列表。Flume将连接到这些服务器以发送数据。与Kafka Source中的配置类似,但方向相反(发送而不是接收)。kafka.topic: 目标Kafka主题。数据将被写入这个主题中进行存储和处理。与Kafka Source中的配置类似,但方向相反(写入而不是读取)。batchSize: 每个批次发送到Kafka的事件数。与HDFS Sink中的hdfs.batchSize类似,这影响了数据发送到Kafka的速度和效率。较大的批次可以减少网络传输次数,提高吞吐量;但也会增加内存消耗和延迟。需要根据实际情况进行调整以获得最佳性能。
3.3 Logger Sink
type: 指定Sink类型为logger。Logger Sink将数据记录到日志文件中,通常用于调试和测试目的。它不会将数据发送到外部系统或存储中,而是将其打印到控制台或写入到日志文件中供开发人员查看和分析。maxEventSize: 记录的最大事件大小(以字节为单位)。如果事件超过此大小,则将被截断以防止日志文件过大或控制台输出过多信息。这有助于控制日志的规模和可读性。在实际应用中,可以根据需要调整这个值以平衡日志的详细程度和存储成本。
二、配置示例
这些实例展示了如何配置Source、Channel和Sink来构建数据流的简单场景。
示例1:从日志文件采集数据到HDFS
这个示例展示了如何使用Exec Source来监控一个日志文件,通过Memory Channel传输数据,并最终将数据写入HDFS。
# Define the name of the agent
agent.sources = source1
agent.channels = channel1
agent.sinks = sink1# Configure the source
agent.sources.source1.type = exec
agent.sources.source1.command = tail -F /path/to/logfile.log# Configure the channel
agent.channels.channel1.type = memory
agent.channels.channel1.capacity = 10000# Configure the sink
agent.sinks.sink1.type = hdfs
agent.sinks.sink1.hdfs.path = hdfs://namenode:8020/flume/events/%Y-%m-%d/%H-%M-%S
agent.sinks.sink1.hdfs.fileType = DataStream
agent.sinks.sink1.hdfs.writeFormat = Text
agent.sinks.sink1.hdfs.batchSize = 1000
agent.sinks.sink1.hdfs.rollSize = 0
agent.sinks.sink1.hdfs.rollCount = 10000
agent.sinks.sink1.hdfs.rollInterval = 300# Bind the source and sink to the channel
agent.sources.source1.channels = channel1
agent.sinks.sink1.channel = channel1
示例2:从Kafka采集数据到另一个Kafka
这个示例展示了如何从Kafka的一个topic读取数据,通过Memory Channel传输,然后写入到另一个Kafka的topic。
# Define the name of the agent
agent.sources = kafkaSource
agent.channels = memoryChannel
agent.sinks = kafkaSink# Configure the Kafka source
agent.sources.kafkaSource.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafkaSource.kafka.bootstrap.servers = kafka-broker:9092
agent.sources.kafkaSource.kafka.topics = input-topic# Configure the memory channel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 10000# Configure the Kafka sink
agent.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafkaSink.kafka.bootstrap.servers = kafka-broker:9092
agent.sinks.kafkaSink.kafka.topic = output-topic
agent.sinks.kafkaSink.batchSize = 20# Bind the source and sink to the channel
agent.sources.kafkaSource.channels = memoryChannel
agent.sinks.kafkaSink.channel = memoryChannel
示例3:从Avro Source接收数据并写入HBase
这个示例展示了如何使用Avro Source接收数据,通过File Channel存储,并最终将数据写入HBase。
# Define the name of the agent
agent.sources = avroSource
agent.channels = fileChannel
agent.sinks = hbaseSink# Configure the Avro source
agent.sources.avroSource.type = avro
agent.sources.avroSource.bind = 0.0.0.0
agent.sources.avroSource.port = 10000# Configure the file channel
agent.channels.fileChannel.type = file
agent.channels.fileChannel.checkpointDir = /path/to/checkpoint/dir
agent.channels.fileChannel.dataDirs = /path/to/data/dir# Configure the HBase sink
agent.sinks.hbaseSink.type = hbase
agent.sinks.hbaseSink.table = my_table
agent.sinks.hbaseSink.columnFamily = my_column_family
agent.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
agent.sinks.hbaseSink.serializer.regex = ([^ ]*) ([^ ]*)
agent.sinks.hbaseSink.serializer.regexIgnoreOrder = false
agent.sinks.hbaseSink.serializer.colNames = key,value# Bind the source and sink to the channel
agent.sources.avroSource.channels = fileChannel
agent.sinks.hbaseSink.channel = fileChannel
请注意,以上配置示例仅供参考,并且可能需要根据您的实际环境(如服务器地址、端口号、路径、表名等)进行调整。另外,请确保您已经安装了所有必要的Flume插件,例如Kafka插件或HBase插件,以便使用相关的Source和Sink。
在配置文件中,agent是Flume中定义的一个服务单元,它可以包含一个或多个source、channel和sink。sources负责接收数据,channels负责缓存数据,sinks负责将数据发送到最终目的地。在配置文件中,你需要为每个组件指定一个唯一的名称,并使用这个名称将它们连接起来。
参考
- https://flume.apache.org/
相关文章:

【数仓】flume常见配置总结,以及示例
相关文章 【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…...

统计信息锁定
在导入成功后我要收集下这些表的信息,结果发现好几张表都没法收集,用DBMS_STATS包显示ORA-20005:object statistics are locked (stattype ALL),用Analyze命令显示ORA-38029: 对象统计信息已锁定。 解决办法很明确&a…...

光猫改为bridge模式
注意事项: 改成桥接模式后,光猫将不再拨号上网,建议提前记录自己的宽带账号,打10010申请修改自己的宽带密码。 光猫改好桥接之后,把宽带账号和密码输入到负责拨号上网的终端设备中,完成宽带PPPOE拨号设置。…...
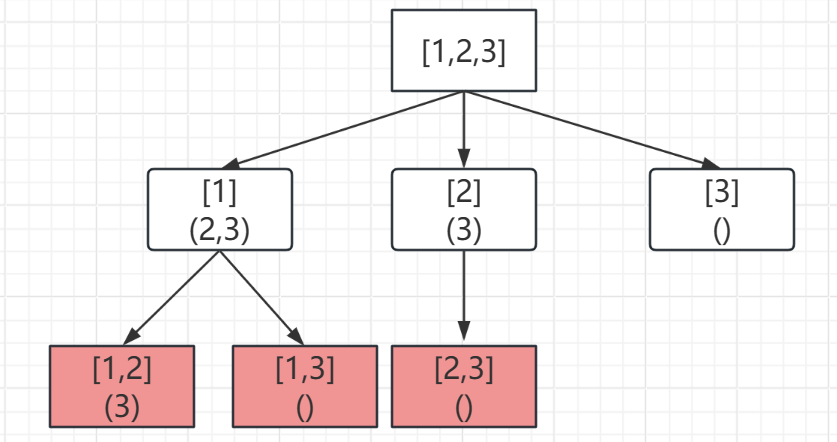
回溯算法01-组合(Java)
1.组合 题目描述 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 示例 1: 输入:n 4, k 2 输出: [[2,4],[3,4],[2,3],[1,2],[1,3],[1,4]]示例 2: 输入&#x…...
初始网络 --- 网络基础
目录 0、 前言 1、 计算机网络发展背景 1.1. 局域网(LAN) && 广域网(WAN) 2、 认识并理解协议 3、 初始网络协议 3.1. 协议分层 4、 TCP/IP 五层(或四层)模型 4.1. 简单了解TCP/IP层状体系 4.2. TCP/IP协议层状结构和计算机层状结构的关系 5、 OSI七层模型 …...

在Linux/Ubuntu/Debian中计算MD5,SHA256的方法
MD5(消息摘要算法 5)和 SHA-256(安全哈希算法 256 位)等流行的哈希算法广泛用于从任意数据生成固定大小的哈希值或校验和。 以下是这些算法及其计算方式的简要概述: MD5(消息摘要算法5)&#x…...

mybatis mysql insert 主键id为空
错误示范 java代码设置了param参数,但是sql 字段没有带上参数,例如 void insertV2(Param("historyDO") HistoryDO historyDO); <insert id"insertDuplicate" parameterType"com.test.entity.HistoryDO"keyProperty&…...

批次大小对ES写入性能影响初探
问题背景 ES使用bulk写入时每批次的大小对性能有什么影响?设置每批次多大为好? 一般来说,在Elasticsearch中,使用bulk API进行批量写入时,每批次的大小对性能有着显著的影响。具体来说,当批量请求的大小增…...

c语言十大核心用法
当然,以下是十个关于 C 语言用法的代码示例: 指针的基本用法: #include <stdio.h>int main() {int num 10;int *ptr;ptr #printf("The value of num is: %d\n", *ptr);return 0; }结构体的使用: #in…...
网页打开慢,这锅该谁背?
一、背景 工作中扯皮说不可避免且非常常见的事情. 开发与产品、开发和测试、前端和后端都会产生扯皮现象。今天要聊的一个问题就是前后端之间的扯皮问题。 网页打开太慢或者点击了某个按钮发现数据很久才显示出来,这个锅谁背? 做开发不能无凭据地胡乱甩锅, 我们…...

题目 1538: 蓝桥杯-格子位置
题目描述: 输入三个自然数N,i,j (1< i< N,1< j< N),输出在一个N*N格的棋盘中,与格子(i,j)同行、同列、同一对角线的所有格子的位置。 样例解释…...
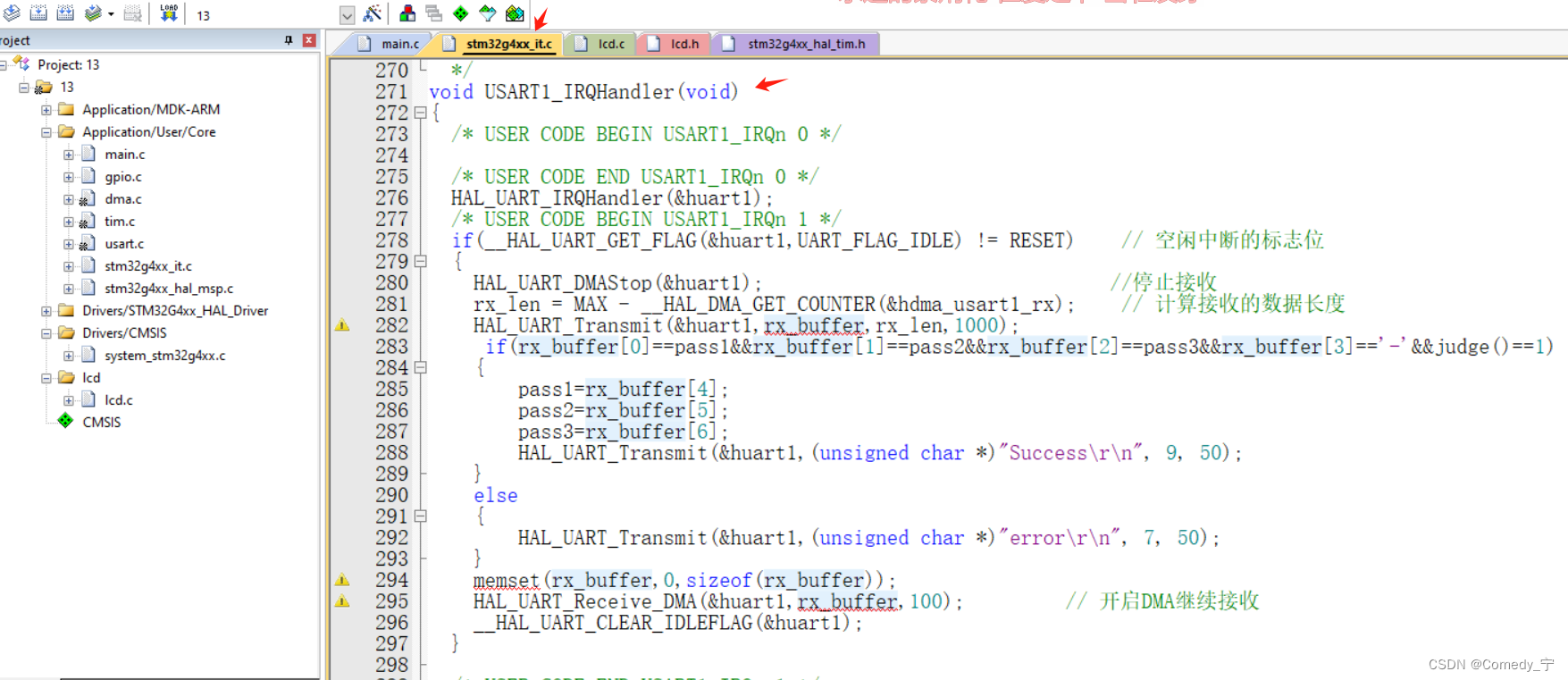
第十三届蓝桥杯嵌入式省赛程序设计详细题解
第十三届蓝桥杯嵌入式省赛题目相对于第十二届较为简单,没有那么多串口的数据处理以及判断! 第十三届省赛主要是制作一个可由串口设置密码的密码锁。本实验中,我们将用到LED模块、按键模块、串口模块、定时器的PWM模块以及官方会提供源码的LC…...

Go 语言指针
1. 什么是指针? 在 Go 语言中,指针是一种特殊的数据类型,它存储了一个变量的内存地址。指针提供了直接访问和修改变量值的能力。 2. 指针的基本操作 2.1 声明指针 在 Go 中声明指针需要使用 * 符号,例如: var p *…...

指针运算笔试题解析
题目1: int main() { int a[5] { 1, 2, 3, 4, 5 }; int* ptr (int*)(&a 1); printf("%d %d", *(a 1), *(ptr - 1)); return 0; } ptr中存放了整个数组的地址,ptr是int*类型,&a1跳到5的地址后又被强制类…...
Matlab梁单元有限元编程 | 铁木辛柯梁 | 欧拉梁 | Matlab源码 | 理论文本
专栏导读 作者简介:工学博士,高级工程师,专注于工业软件算法研究本文已收录于专栏:《有限元编程从入门到精通》本专栏旨在提供 1.以案例的形式讲解各类有限元问题的程序实现,并提供所有案例完整源码;2.单元…...
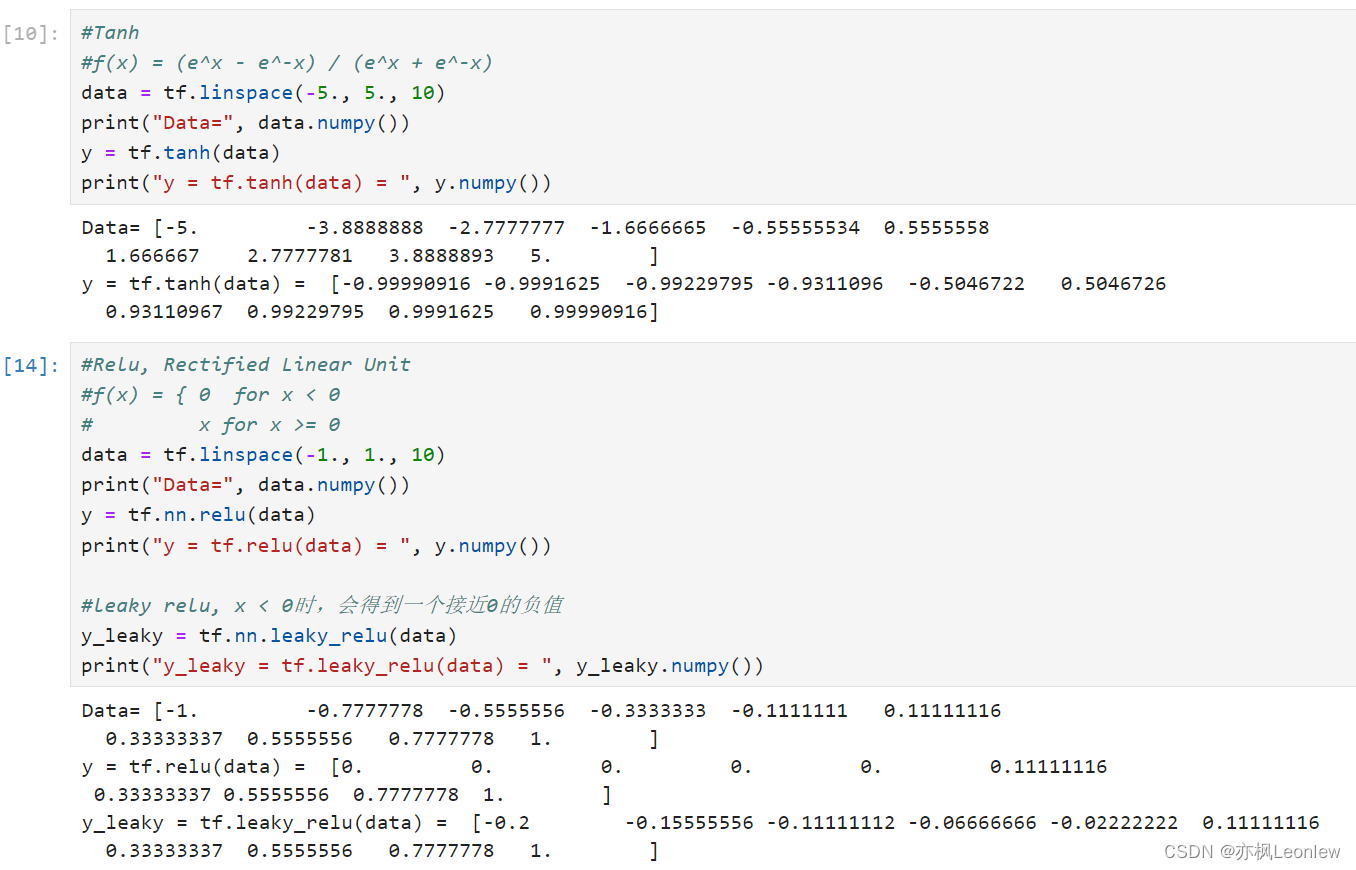
Tensorflow2.0笔记 - 常见激活函数sigmoid,tanh和relu
本笔记主要记录常见的三个激活函数sigmoid,tanh和relu,关于激活函数详细的描述,可以参考这里: 详解激活函数(Sigmoid/Tanh/ReLU/Leaky ReLu等) - 知乎 import tensorflow as tf import numpy as nptf.__ve…...
1688商品详情数据采集,工程数据采集丨店铺数据采集丨商品详情数据采集
1688是中国的一个大型B2B电子商务平台,主要用于批发和采购各种商品。对于需要从1688上获取商品详情数据、工程数据或店铺数据的用户来说,可以采用以下几种常见的方法: 官方API接口:如果1688提供了官方的API接口,那么可…...

Flutter(四):SingleChildScrollView、GridView
SingleChildScrollView、GridView 遇到的问题 以下代码会报错: class GridViewPage extends StatefulWidget {const GridViewPage({super.key});overrideState<GridViewPage> createState() > _GridViewPage(); }class _GridViewPage extends State<GridViewPage&g…...

【C++】102.二叉树的层序遍历
题目描述 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]示例 2࿱…...

Java学习笔记006——子类与父类的类型转换
在Java中,类型转换主要涉及到两种类型:向上类型转换(Upcasting)和向下类型转换(Downcasting)。 1. 向上类型转换(Upcasting): 向上类型转换是将子类的对象转换为父类类…...

别再只用箱线图了!用R语言ggplot2绘制高颜值小提琴图,让你的SCI图表更专业
科研数据可视化进阶:用R语言打造专业级小提琴图 在生物医学领域的科研论文中,数据可视化是展示研究成果的关键环节。许多研究者习惯性地使用箱线图来呈现数据分布,却忽略了这种传统方法可能掩盖的重要信息细节。当面对复杂的数据分布模式时&…...

嵌入式边缘AI论坛参会全攻略:从技术趋势到实战社交
1. 论坛核心价值与参会目标拆解“6天倒计时!”这个标题,精准地抓住了所有技术从业者在面对一个高价值行业活动时,那种既兴奋又略带紧迫感的共同心理。这不仅仅是一个简单的会议通知,它更像是一份来自同行的“战前简报”。对于嵌入…...

Cortex-M0中断与系统控制:从NVIC、SysTick到低功耗实战解析
1. 项目概述:从零开始理解Cortex-M0的中断与系统控制如果你正在接触基于ARM Cortex-M0内核的微控制器,比如STM32F0系列、NXP的LPC800系列,或者是一些国产的M0芯片,那么“中断”和“系统控制”这两个词,绝对是你绕不开的…...

最新彩虹云商城重构版 虚拟商城 在线下单 自动发货
内容目录 一、详细介绍二、效果展示1.部分代码2.效果图展示 三、学习资料下载 一、详细介绍 彩虹云商城重构版 【重构】数据面板显示样式和布局 【优化】一级分类提示,更加详细,添加对模板导航引入说明 【优化】系统概览页面 【优化】供货商商品列表显示…...

告别依赖冲突!用iframe集成file-viewer预览Word/PPT,Vue2项目也能轻松升级
告别依赖冲突!用iframe集成file-viewer预览Word/PPT,Vue2项目也能轻松升级 在Vue2项目中集成第三方文件预览组件时,开发者常常陷入依赖地狱——npm包版本冲突、构建体积膨胀、升级路径断裂等问题接踵而至。本文将揭示一种被低估的轻量级解决方…...

MRI绕组结构设计及均匀度优化算法【附算法】
✨ 长期致力于MRI、均匀度、球面谐波、目标场、主被动匀场、优化算法、超导磁体、线性规划、非线性规划研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1࿰…...

Hyper-V虚拟机文件迁移避坑指南:从C盘挪走Ubuntu,释放系统盘空间
Hyper-V虚拟机文件迁移实战:安全释放C盘空间的完整方案 当你在Windows系统上使用Hyper-V运行Ubuntu虚拟机时,是否注意到C盘空间正在被悄悄吞噬?许多技术爱好者初次接触Hyper-V时,往往直接采用默认设置,将所有虚拟机文件…...

初次接触Taotoken的新手从注册到成功发起第一次API调用的全过程记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触Taotoken的新手从注册到成功发起第一次API调用的全过程记录 作为一名刚开始接触大模型开发的工程师,我最近在寻…...

如何快速掌握JASP统计分析软件:3个高效使用技巧完整指南
如何快速掌握JASP统计分析软件:3个高效使用技巧完整指南 【免费下载链接】jasp-desktop JASP aims to be a complete statistical package for both Bayesian and Frequentist statistical methods, that is easy to use and familiar to users of SPSS 项目地址:…...

2025最权威的AI写作方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当人工智能技术于当下迅猛发展之际,对于企业来讲,核心挑战其中之一便…...