计算机设计大赛 深度学习实现语义分割算法系统 - 机器视觉
文章目录
- 1 前言
- 2 概念介绍
- 2.1 什么是图像语义分割
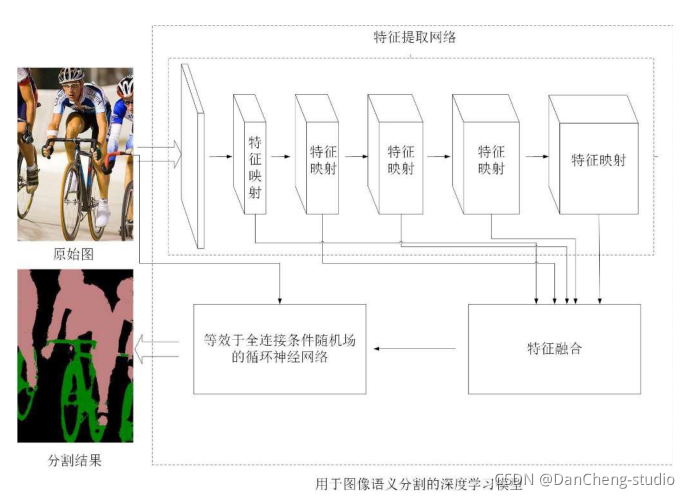
- 3 条件随机场的深度学习模型
- 3\. 1 多尺度特征融合
- 4 语义分割开发过程
- 4.1 建立
- 4.2 下载CamVid数据集
- 4.3 加载CamVid图像
- 4.4 加载CamVid像素标签图像
- 5 PyTorch 实现语义分割
- 5.1 数据集准备
- 5.2 训练基准模型
- 5.3 损失函数
- 5.4 归一化层
- 5.5 数据增强
- 5.6 实现效果
- 6 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习实现语义分割算法系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 概念介绍
2.1 什么是图像语义分割
这几年,随着深度学习理论和大规模并行计算设备快速发展,计算机视觉的诸多难点实现了质的突破,包括图像分类叫、目标检测、语义分割等等。
其中图像分类和目标检测在各种场景应用中大放光彩。目前最先进网络的准确度已经超过人类。
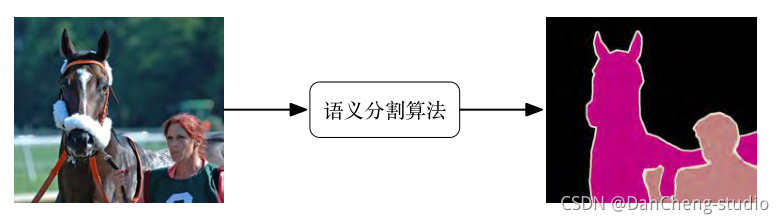
而图像语义分割是一.种语义信息更丰富的视觉识别任务,其主要任务是实现像素级别的分类。
图像语义分割示意图如下图所示。
图像语义分割技术在实际中有着非常广泛的应用,如自动驾驶、生物医学以及现实增强技术等等。
语义分割在自动驾驶的应用:

3 条件随机场的深度学习模型
整个深度学习模型框架下如图:
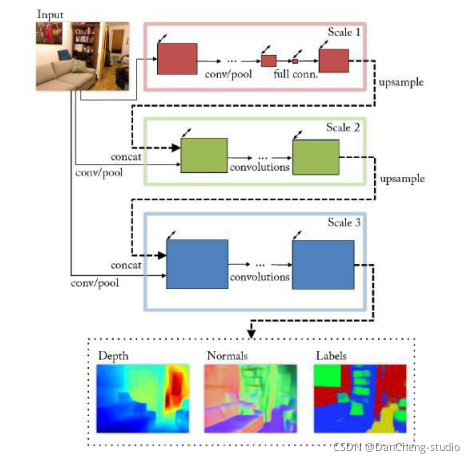
3. 1 多尺度特征融合
图像中的各类物体都以不同的形态出现, 用来观测它们的尺度也不尽相同, 不同的物体需要用合适的尺度来测量。
尺度也有很多种, 宏观上大的如“米”、“千米” 甚至“光年”; 微观上小的如“微米”、“纳米” 甚至是“飞米”。 在日常生活中,
人们也经常接触到尺度上的变换, 例如人们经常用到的电子地图上的放大与缩小、 照相机焦距的变化等,都是以不同的尺度来观察或者测量不同的物体。
当人们将一幅图像输入到计算机中时, 计算机要尝试很多不同的尺度以便得到描述图片中不同物体的最合适的尺度。
卷积神经网络中含有大量的超参数, 而且在网络中的任何一个参数, 都会对网络生成的特征映射产生影响。 当卷积神经网络的结构已经确定下来时,
网络中每一层学习到的特征映射的尺度也随之固定了下来, 拥有了在一定程度上的尺度不变性。
与此同时, 为了完成当前的任务, 网络中的这些已经设置好的超参数不能被随意更改, 所以必须要考虑融合多尺度特征的神经网络。
这种神经网络可以学习学长提供的框架不同尺度的图像特征, 获得不同尺度的预测, 进而将它们融合, 获得最后的输出。
一种多尺度特征融合网络如下所示。
4 语义分割开发过程
学长在这详细说明图像语义分割,如何进行开发和设计
语义分割网络对图像中的每个像素进行分类,从而产生按类别分割的图像。语义分割的应用包括用于自主驾驶的道路分割和用于医学诊断的癌细胞分割。有关详细信息,请参阅语义分段基础知识(计算机视觉系统工具箱)。
为了说明训练过程,学长训练SegNet ,一种设计用于语义图像分割的卷积神经网络(CNN)。用于语义分段的其他类型网络包括完全卷积网络(FCN)和U-
Net。此处显示的培训程序也可以应用于这些网络。
此示例使用剑桥大学的CamVid数据集进行培训。此数据集是包含驾驶时获得的街道视图的图像集合。该数据集为32种语义类提供了像素级标签,包括汽车,行人和道路。
4.1 建立
此示例创建具有从VGG-16网络初始化的权重的SegNet网络。要获得VGG-16,请安装适用于VGG-16网络的Deep Learning
Toolbox™模型。安装完成后,运行以下代码以验证安装是否正确。
vgg16();
下载预训练版的SegNet。预训练模型允许您运行整个示例,而无需等待培训完成。pretrainedURL = 'https: //www.mathworks.com/supportfiles/vision/data/segnetVGG16CamVid.mat ' ;
pretrainedFolder = fullfile(tempdir,'pretrainedSegNet');
pretrainedSegNet = fullfile(pretrainedFolder,'segnetVGG16CamVid.mat');
如果〜存在(pretrainedFolder,'dir')MKDIR(pretrainedFolder);disp('下载预训练的SegNet(107 MB)......');websave(pretrainedSegNet,pretrainedURL);
结束
强烈建议使用具有计算能力3.0或更高版本的支持CUDA的NVIDIA™GPU来运行此示例。使用GPU需要Parallel Computing
Toolbox™。
4.2 下载CamVid数据集
从以下URL下载CamVid数据集。
imageURL = 'http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/files/701_StillsRaw_full.zip’ ;
labelURL = 'http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/data/LabeledApproved_full.zip’ ;outputFolder = fullfile(tempdir,‘CamVid’);如果〜存在(outputFolder,‘dir’)MKDIR(outputFolder)
labelsZip = fullfile(outputFolder,'labels.zip');
imagesZip = fullfile(outputFolder,'images.zip'); disp('下载16 MB CamVid数据集标签......');
websave(labelsZip,labelURL);
unzip(labelsZip,fullfile(outputFolder,'labels'));disp('下载557 MB CamVid数据集图像......');
websave(imagesZip,imageURL);
解压缩(imagesZip,fullfile(outputFolder,'images')); 注意:数据的下载时间取决于您的Internet连接。上面使用的命令会阻止MATLAB,直到下载完成。或者,您可以使用Web浏览器首先将数据集下载到本地磁盘。要使用从Web下载的文件,请将outputFolder上面的变量更改为下载文件的位置。
4.3 加载CamVid图像
使用imageDatastore加载CamVid图像。在imageDatastore使您能够高效地装载大量收集图像的磁盘上。imgDir = fullfile(outputFolder,'images','701_StillsRaw_full');
imds = imageDatastore(imgDir);
显示其中一个图像。

4.4 加载CamVid像素标签图像
使用pixelLabelDatastore加载CamVid像素标签图像数据。A
pixelLabelDatastore将像素标签数据和标签ID封装到类名映射中。
按照原始SegNet论文[1]中使用的程序,将CamVid中的32个原始类分组为11个类。指定这些类。
class = [“Sky” “Building” “Pole” “Road” “Pavement” “Tree” “SignSymbol” “Fence” “Car” “Pedestrian” “Bicyclist” ];
要将32个类减少为11个,将原始数据集中的多个类组合在一起。例如,“Car”是“Car”,“SUVPickupTruck”,“Truck_Bus”,“Train”和“OtherMoving”的组合。使用支持函数返回分组的标签ID,该函数camvidPixelLabelIDs在本示例的末尾列出。
abelIDs = camvidPixelLabelIDs();
使用类和标签ID来创建 pixelLabelDatastore.labelDir = fullfile(outputFolder,'labels');
pxds = pixelLabelDatastore(labelDir,classes,labelIDs);
通过将其叠加在图像上来读取并显示其中一个像素标记的图像。C = readimage(pxds,1);cmap = camvidColorMap;B = labeloverlay(I,C,'ColorMap',cmap);
imshow(B)
pixelLabelColorbar(CMAP,班);

5 PyTorch 实现语义分割
学长这里给出一个具体实例 :
使用2020年ECCV Vipriors Chalange Start Code实现语义分割,并且做了一些优化,让进度更高
5.1 数据集准备
使用Cityscapes的数据集MiniCity Dataset。
将各基准类别进行输入:

从0-18计数,对各类别进行像素标记:
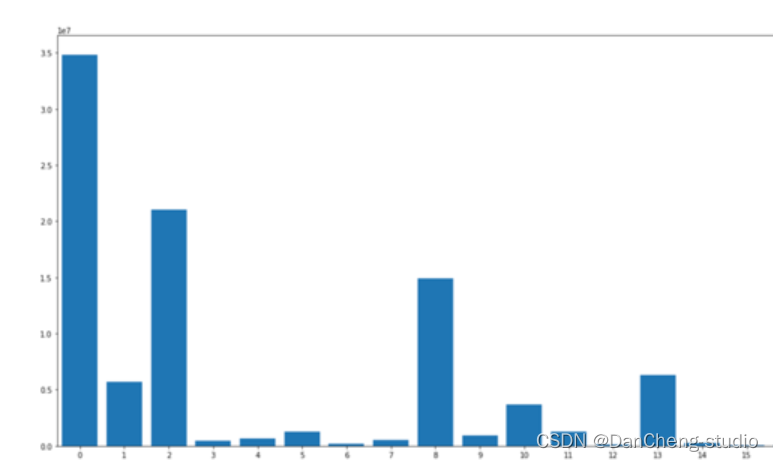
使用deeplab v3进行基线测试,结果发现次要类别的IoU特别低,这样会导致难以跟背景进行区分。
如下图中所示的墙、栅栏、公共汽车、火车等。
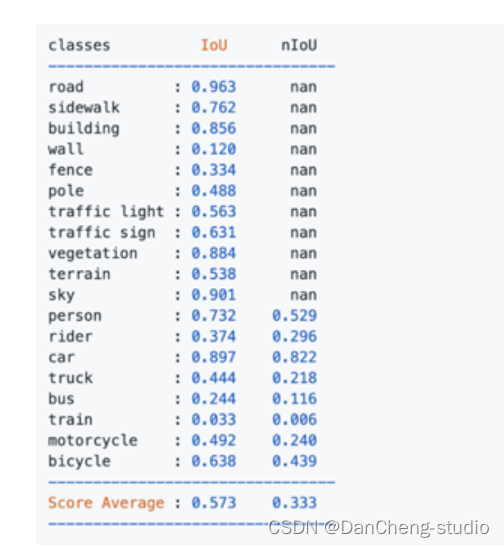
注意: 以上的结果表述数据集存在严重的类别不平衡问题。
5.2 训练基准模型
使用来自torchvision的DeepLabV3进行训练。
硬件为4个RTX 2080 Ti GPU (11GB x 4),如果只有1个GPU或较小的GPU内存,请使用较小的批处理大小(< = 8)。
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
python baseline.py --save_path baseline_run_deeplabv3_resnet101 --model DeepLabv3_resnet101 --train_size 512 1024 --test_size 512 1024 --crop_size 384 768 --batch_size 8;
5.3 损失函数
有3种损失函数可供选择,分别是:交叉熵损失函数(Cross-Entropy Loss)、类别加权交叉熵损失函数(Class-Weighted Cross
Entropy Loss)和焦点损失函数(Focal Loss)。
交叉熵损失函数,常用在大多数语义分割场景,但它有一个明显的缺点,那就是对于只用分割前景和背景的时候,当前景像素的数量远远小于背景像素的数量时,模型严重偏向背景,导致效果不好。
# Cross Entropy Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
类别加权交叉熵损失函数是在交叉熵损失函数的基础上为每一个类别添加了一个权重参数,使其在样本数量不均衡的情况下可以获得更好的效果。
# Weighted Cross Entropy Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50_wce --crop_size 576 1152 --batch_size 8 --loss weighted_ce;
焦点损失函数则更进一步,用来解决难易样本数量不平衡。
# Focal Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50_focal --crop_size 576 1152 --batch_size 8 --loss focal --focal_gamma 2.0;
5.4 归一化层
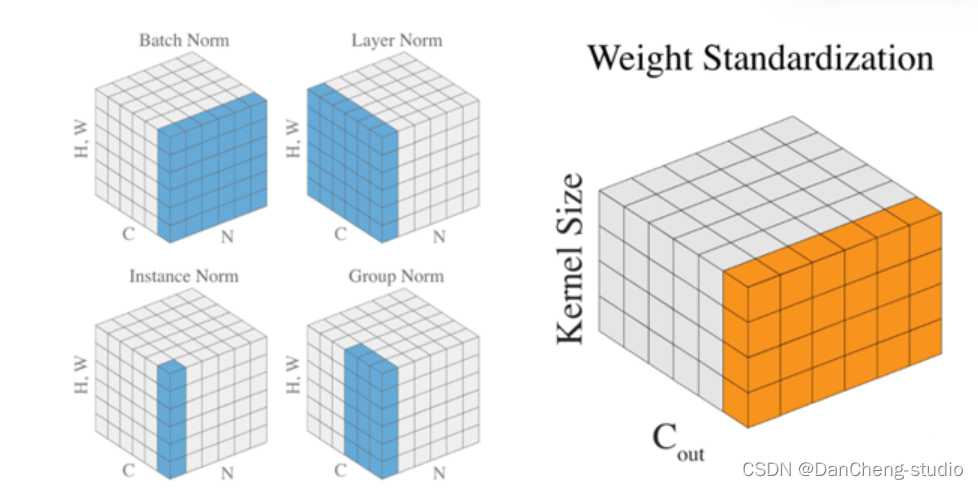
BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好。
5.5 数据增强
2种数据增强技术
- CutMix
- Copy Blob
在 Blob 存储的基础上构建,并通过Copy的方式增强了性能。
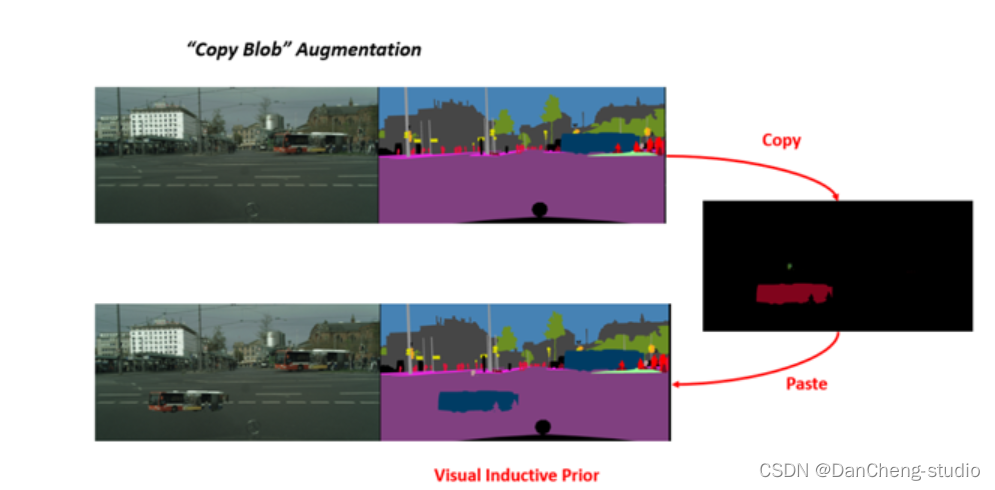
另外,如果要解决前面所提到的类别不平衡问题,则可以使用视觉归纳优先的CopyBlob进行增强。
# CopyBlob Augmentation
python baseline.py --save_path baseline_run_deeplabv3_resnet50_copyblob --crop_size 576 1152 --batch_size 8 --copyblob;
5.6 实现效果
多尺度推断
使用[0.5,0.75,1.0,1.25,1.5,1.75,2.0,2.2]进行多尺度推理。另外,使用H-Flip,同时必须使用单一批次。
# Multi-Scale Inference
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --batch_size 1 --predict --mst;
使用验证集计算度量
计算指标并将结果保存到results.txt中。
python evaluate.py --results baseline_run_deeplabv3_resnet50/results_val --batch_size 1 --predict --mst;
训练结果
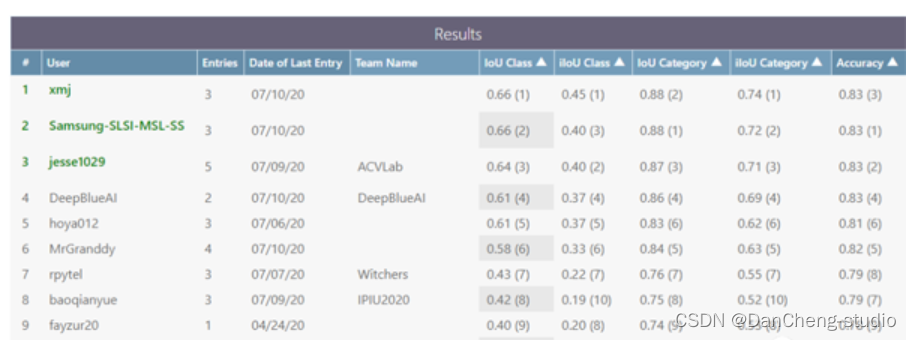
最后的单一模型结果是0.6069831962012341,
如果使用了更大的模型或者更大的网络结构,性能可能会有所提高。
另外,如果使用了各种集成模型,性能也会有所提高。
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机设计大赛 深度学习实现语义分割算法系统 - 机器视觉
文章目录 1 前言2 概念介绍2.1 什么是图像语义分割 3 条件随机场的深度学习模型3\. 1 多尺度特征融合 4 语义分割开发过程4.1 建立4.2 下载CamVid数据集4.3 加载CamVid图像4.4 加载CamVid像素标签图像 5 PyTorch 实现语义分割5.1 数据集准备5.2 训练基准模型5.3 损失函数5.4 归…...

Linux系统编程(六)高级IO
目录 1. 阻塞和非阻塞 IO 2. IO 多路转接(select、poll、epoll) 3. 存储映射 IO(mmap) 4. 文件锁(fcntl、lockf、flock) 5. 管道实例 - 池类算法 1. 阻塞和非阻塞 IO 阻塞 IO:会等待操作的…...

Python与FPGA——全局二值化
文章目录 前言一、Python全局128二、Python全局均值三、Python全局OTSU四、FPGA全局128总结 前言 为什么要进行图像二值化,rgb图像有三个通道,处理图像的计算量较大,二值化的图像极大的减少了处理图像的计算量。即便从彩色图像转成了二值化图…...

《Docker极简教程》--Docker的高级特性--Docker Compose的使用
Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。它允许开发人员通过简单的YAML文件来定义应用程序的服务、网络和卷等资源,并使用单个命令来启动、停止和管理整个应用程序的容器。以下是关于Docker Compose的一些关键信息和优势: 定义…...

tidyverse去除表格中含有NA的行
在tidyverse中,特别是使用dplyr包,去除含有NA的行可以通过filter()函数结合is.na()和any()或all()函数来实现。dplyr是tidyverse的一部分,提供了一系列用于数据操作的函数,使数据处理变得更加简单和直观。 以下是一个简单的例子&…...
开源爬虫技术在金融行业市场分析中的应用与实战解析
一、项目介绍 在当今信息技术飞速发展的时代,数据已成为企业最宝贵的资产之一。特别是在${industry}领域,海量数据的获取和分析对于企业洞察市场趋势、优化产品和服务至关重要。在这样的背景下,爬虫技术应运而生,它能够高效地从互…...

使用SMTP javamail发送邮件
一、SMTP协议 SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。SMTP协议属于TCP/IP协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。使用javamail编写发送…...

Hello C++ (c++是什么/c++怎么学/c++推荐书籍)
引言 其实C基础语法基本上已经学完,早就想开始写C的博客了,却因为其他各种事情一直没开始。原计划是想讲Linux系统虚拟机安装的,后来考虑了一下还是算了,等Linux学到一定程度再开始相关博客的写作和发表吧。今天写博客想给C开个头…...

最新的前端开发技术(2024年)
关于作者: 还是大剑师兰特:曾是美国某知名大学计算机专业研究生,现为航空航海领域高级前端工程师;CSDN知名博主,GIS领域优质创作者,深耕openlayers、leaflet、mapbox、cesium,canvas࿰…...
GCN 翻译 - 2
2 FAST APROXIMATE CONVOLUTIONS ON GRAPHS 在这一章节,我们为这种特殊的的图基础的神经网络模型f(X, A)提供理论上的支持。我们考虑一个多层的图卷积网络(GCN),它通过以下方式进行层间的传播: 这里,是无…...
HBase 的安装与部署
目录 1 启动 zookeeper2 启动 Hadoop3 HBase 的安装与部署4 HBase 高可用 1 启动 zookeeper [huweihadoop101 ~]$ bin/zk_cluster.sh start2 启动 Hadoop [huweihadoop101 ~]$ bin/hdp_cluster.sh start3 HBase 的安装与部署 (1)将 hbase-2.0.5-bin.tar.…...

236.二叉搜索树的公共祖先
236.二叉树的公共祖先 思路 看到题想的是找到两个点的各自路径利用stack保存,根据路径长度大小将两个stack的值对齐到同一层,之后同时出栈节点,若相同则找到祖先节点。但是效率不高 看了大佬代码,递归思想很难理解。 根据大佬…...
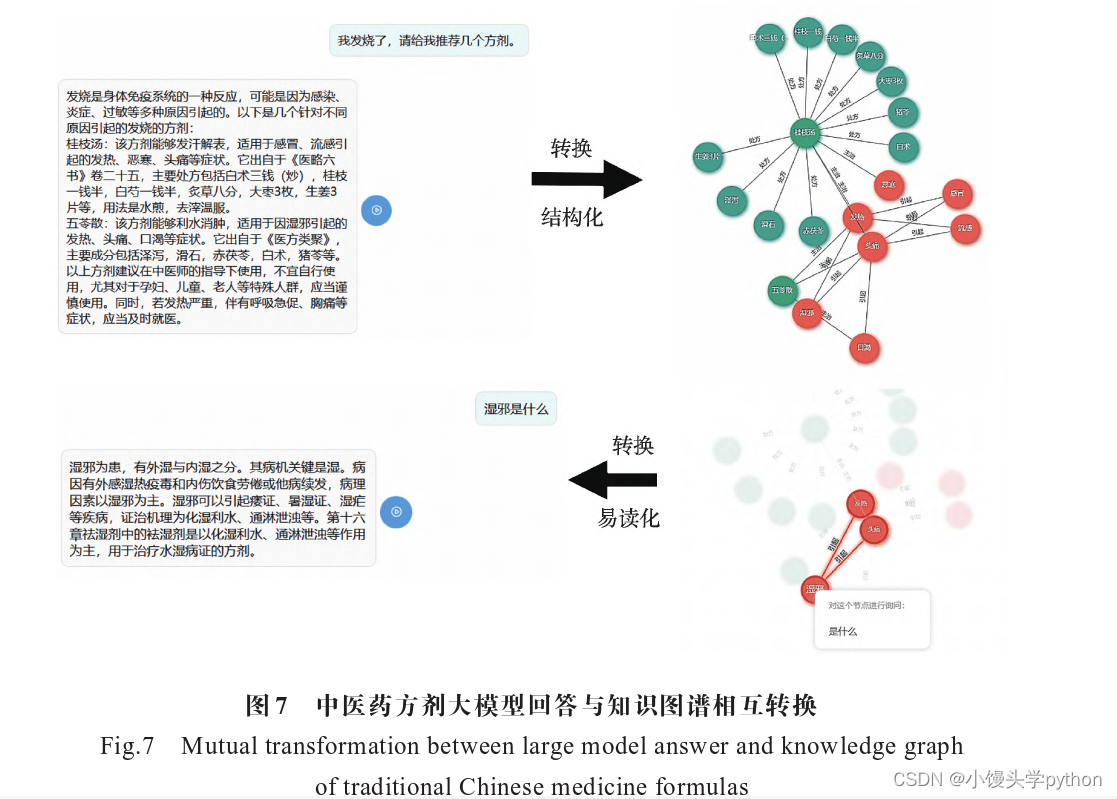
【论文精读】大语言模型融合知识图谱的问答系统研究
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
LabVIEW高精度天线自动测试系统
LabVIEW高精度天线自动测试系统 系统是一个集成了LabVIEW软件的自动化天线测试平台,提高天线性能测试的精度与效率。系统通过远程控制测试仪表,实现了数据采集、方向图绘制、参数计算等功能,特别适用于对天线辐射特性的精确测量。 在天线的…...
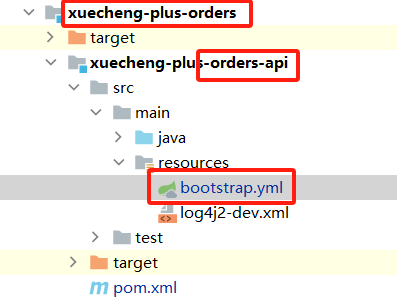
7.3 支付模块 - 创建订单、查询订单、通知
支付模块 - 创建订单、查询订单、通知 文章目录 支付模块 - 创建订单、查询订单、通知一、生成支付二维码1.1 数据模型1.1.1 订单表1.1.2 订单明细表1.1.3 支付交易记录表 1.2 执行流程1.3 Dto1.3.1 AddOrderDto 商品订单1.3.2 PayRecordDto支付交易记录扩展字段1.3.3 雪花算法…...

灵魂指针,教给(一)
欢迎来到白刘的领域 Miracle_86.-CSDN博客 系列专栏 C语言知识 先赞后看,已成习惯 创作不易,多多支持! 一、内存和地址 1.1 内存 在介绍知识之前,先来想一个生活中的小栗子: 假如把你放在一个有100间屋子的酒店…...
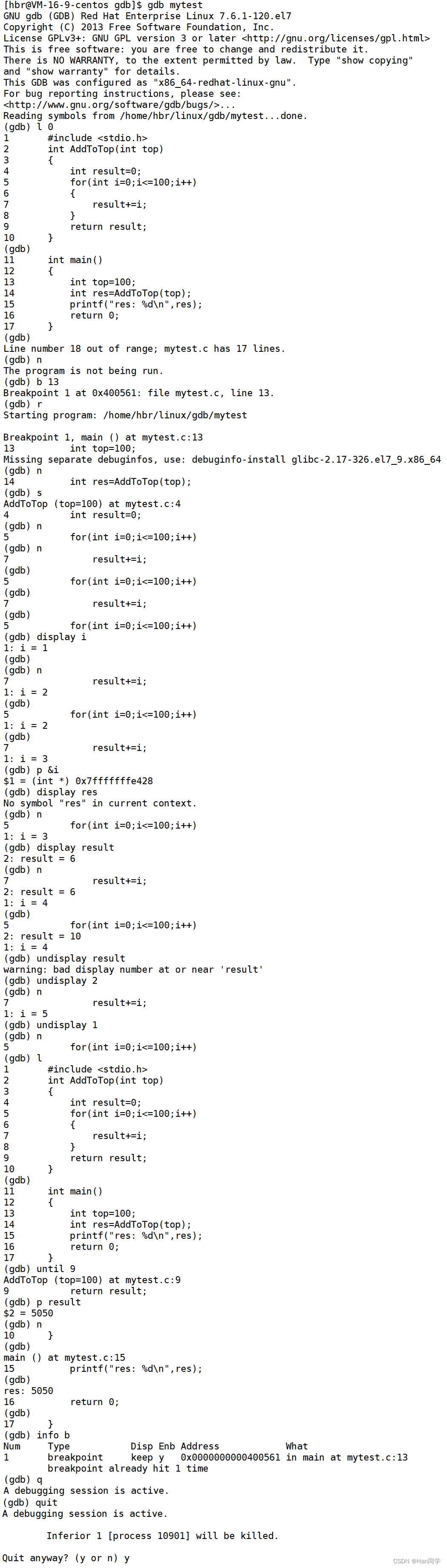
Linux 开发工具 yum、git、gdb
目录 一、yum 1、软件包 2、rzsz 3、注意事项 4、查看软件包 5、安装软件 6、卸载软件 二、git操作 1、克隆三板斧 2、第一次使用会出现以下情况: 未配置用户名和邮箱: push后弹出提示 三、gdb使用 1、背景 2、使用方法 例一:…...

Markdown
这里写自定义目录标题 欢迎使用Markdown编辑器 新的改变 功能快捷键 合理的创建标题,有助于目录的生成 如何改变文本的样式 插入链接与图片 如何插入一段漂亮的代码片 生成一个适合你的列表 创建一个表格 设定内容居中、居左、居右 SmartyPants 创建一个自定义列表 …...

【Oracle】oracle中sql给表新增字段并添加注释说明;mysql新增、修改字段
oracle中sql给表新增字段并添加注释说明 ALTER TABLE 表名 ADD 字段名 类型 COMMENT ON COLUMN 表面.字段名 IS ‘注释内容’ ALTER TABLE GROUP ADD T NUMBER(18) COMMENT ON COLUMN GROUP.T IS ‘ID’ mysql新增、修改字段、已有字段增加默认值 ALTER TABLE 表名 ADD COL…...

【汇总】pytest简易教程
pytest作为python技术栈里面主流、火热的技术,非常有必要好好学一下,因为工作和面试都能用上; 它不仅简单易用,还很强大灵活,重点掌握fixture、parametrize参数化、allure-pytest插件等,这些在后续自动化框…...

系统级开发中的夜间MVP构建与Boneyard归档实践
1. 项目概述:一个名为“Boneyard”的夜间MVP构建最近在开源社区里,我注意到一个挺有意思的项目,叫sys-fairy-eve/nightly-mvp-2026-04-05-boneyard。光看这个标题,信息量就很大,它像是一个系统构建流水线上的一个特定快…...

Vivado里写状态机总出警告?聊聊三段式、二段式的选择与那些让人头疼的Latch和Combinatorial Loop
Vivado状态机设计实战:从三段式优化到Latch消除全攻略 状态机设计中的典型痛点与EDA工具特性 第一次在Vivado中看到"Inferring Latch"警告时,我盯着综合报告发了半小时呆——明明代码逻辑完全正确,为什么工具非要"自作主张&qu…...

Win11Debloat免费工具:3步彻底清理Windows 11垃圾,性能提升51%
Win11Debloat免费工具:3步彻底清理Windows 11垃圾,性能提升51% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes …...

回声干扰导致TTS通过率暴跌41%?ElevenLabs生产环境回声抑制黄金配置,仅限内部团队使用的7项阈值标准
更多请点击: https://intelliparadigm.com 第一章:回声干扰对TTS语音质量的致命影响 回声干扰(Echo Interference)是实时TTS(Text-to-Speech)系统在语音合成与播放耦合场景中极易被忽视却极具破坏性的声学…...

【MQTT】paho.mqtt.c 库的“异步/同步模式选择、编译配置与实战” 深度解析,附嵌入式客户端开发指南
1. MQTT与paho.mqtt.c库的核心价值 在物联网设备通信领域,MQTT协议凭借其轻量级、低功耗和发布/订阅模式的优势,已经成为设备间通信的事实标准。而Eclipse Paho项目提供的paho.mqtt.c库,则是C语言开发者实现MQTT客户端功能的首选工具包。这个…...

DuckDuckGo AI本地代理服务:开源工具部署与API调用指南
1. 项目概述:一个为DuckDuckGo AI聊天功能提供本地化服务的开源工具如果你和我一样,是个重度搜索用户,同时又对AI聊天功能有高频需求,那你肯定对DuckDuckGo不陌生。作为一个主打隐私保护的搜索引擎,它最近也跟上了潮流…...

VCS仿真总失败?手把手教你用TMAX的CPV功能快速定位ATPG Pattern问题
VCS仿真总失败?TMAX的CPV功能实战指南:精准定位ATPG Pattern问题 在数字芯片验证的战场上,ATPG(自动测试模式生成)仿真是确保芯片可测试性的关键环节。但当VCS仿真器抛出"cycle mis-match"错误时,…...

SSD1306 OLED屏幕驱动全攻略:从Arduino到CircuitPython实战
1. 项目概述如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定遇到过一个问题:怎么把程序运行的状态、传感器的数据或者一些简单的交互界面直观地展示出来?用串口监视器看数据流当然可以,但不够“酷”,也不够便…...
)
二叉树‘找叶子’的三种姿势:从PTA真题到LeetCode变体(层次/先序/后序遍历对比)
二叉树‘找叶子’的三种姿势:从PTA真题到LeetCode变体(层次/先序/后序遍历对比) 在算法学习的道路上,二叉树遍历是每个程序员必须掌握的基本功。而"找叶子节点"这一看似简单的任务,却能衍生出多种解法&…...

告别Windows激活烦恼:KMS智能激活工具一站式解决方案
告别Windows激活烦恼:KMS智能激活工具一站式解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出的激活提醒而困扰吗?是否曾经因为Office办…...