mysql 性能调优参数配置文件
###########################################################################
## my.cnf for MySQL 8.0.x #
## 本配置参考 https://imysql.com/my-cnf-wizard.html #
## 注意: #
## (1)本配置假设物理服务器内存为 16G,总表数量在300之内,中小型企业业务 #
## (2)请根据实际情况作调整部分参数 #
## (3)本人不对这些建议结果负相应责任 #
###########################################################################
###########################################################################
##客户端参数配置
###########################################################################
[client]
port = 3306
socket =/var/lib/mysql/mysqld.sock
[mysql]
#prompt="\u@mysqldb \R:\m:\s [\d]> "
#关闭自动补全sql命令功能
no-auto-rehash
###########################################################################
##服务端参数配置
###########################################################################
[mysqld]
port = 3306
datadir = /var/lib/mysql
socket = /var/lib/mysql/mysqld.sock
log-error = /var/lib/mysql/error.log
pid-file = /var/lib/mysql/mysqld.pid
#只能用IP地址检查客户端的登录,不用主机名
skip_name_resolve = 1
#若你的MySQL数据库主要运行在境外,请务必根据实际情况调整本参数
default_time_zone = "+8:00"
#数据库默认字符集, 主流字符集支持一些特殊表情符号(特殊表情符占用4个字节)
character-set-server = utf8mb4
#数据库字符集对应一些排序等规则,注意要和character-set-server对应
collation-server = utf8mb4_general_ci
#设置client连接mysql时的字符集,防止乱码
init_connect='SET NAMES utf8mb4'
#是否对sql语句大小写敏感,1表示不敏感
lower_case_table_names = 1
# 执行sql的模式,规定了sql的安全等级, 暂时屏蔽,my.cnf文件中配置报错
#sql_mode = STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#事务隔离级别,默认为可重复读,mysql默认可重复读级别(此级别下可能参数很多间隙锁,影响性能)
transaction_isolation = READ-COMMITTED
#TIMESTAMP如果没有显示声明NOT NULL,允许NULL值
explicit_defaults_for_timestamp = true
#它控制着mysqld进程能使用的最大文件描述(FD)符数量。
#需要注意的是这个变量的值并不一定是你设定的值,mysqld会在系统允许的情况下尽量获取更多的FD数量
open_files_limit = 65535
#最大连接数
max_connections = 300
#最大错误连接数
max_connect_errors = 600
#在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中
#官方建议 back_log = 50 + (max_connections / 5),封顶数为65535,默认值= max_connections
back_log = 110
# The number of open tables for all threads
# For example, for 200 concurrent running connections, specify a table cache size of at least 200 * N,
# where N is the maximum number of tables per join in any of the queries which you execute.
table_open_cache = 600
# The number of table definitions that can be stored in the definition cache
# MIN(400 + table_open_cache / 2, 2000)
table_definition_cache = 700
# 为了减少会话之间的争用,可以将opentables缓存划分为table_open_cache/table_open_cache_instances个小缓存
table_open_cache_instances = 64
# 每个线程的堆栈大小 如果线程堆栈太小,则会限制执行复杂SQL语句
thread_stack = 512K
# 禁止外部系统锁
external-locking = FALSE
#SQL数据包发送的大小,如果有BLOB对象建议修改成1G
max_allowed_packet = 128M
#order by 或group by 时用到
#建议先调整为4M,后期观察调整
sort_buffer_size = 4M
#inner left right join时用到
#建议先调整为4M,后期观察调整
join_buffer_size = 4M
# How many threads the server should cache for reuse.
# 如果您的服务器每秒达到数百个连接,则通常应将thread_cache_size设置得足够高,以便大多数新连接使用缓存线程
# default value = 8 + ( max_connections / 100) 上限为100
thread_cache_size = 20
#MySQL连接闲置超过一定时间后(单位:秒)将会被强行关闭
#MySQL默认的wait_timeout 值为8个小时, interactive_timeout参数需要同时配置才能生效
interactive_timeout = 1800
wait_timeout = 1800
#Metadata Lock最大时长(秒), 一般用于控制 alter操作的最大时长sine mysql5.6
#执行 DML操作时除了增加innodb事务锁外还增加Metadata Lock,其他alter(DDL)session将阻塞
lock_wait_timeout = 3600
#内部内存临时表的最大值。
#比如大数据量的group by ,order by时可能用到临时表,
#超过了这个值将写入磁盘,系统IO压力增大
tmp_table_size = 64M
max_heap_table_size = 64M
#--###########################-- 慢SQL日志记录 开始 --##########################################
#是否启用慢查询日志,1为启用,0为禁用
slow_query_log = 1
#记录系统时区
log_timestamps = SYSTEM
#指定慢查询日志文件的路径和名字
slow_query_log_file = /var/lib/mysql/slow.log
#慢查询执行的秒数,必须达到此值可被记录
long_query_time = 5
#将没有使用索引的语句记录到慢查询日志
log_queries_not_using_indexes = 0
#设定每分钟记录到日志的未使用索引的语句数目,超过这个数目后只记录语句数量和花费的总时间
log_throttle_queries_not_using_indexes = 60
#对于查询扫描行数小于此参数的SQL,将不会记录到慢查询日志中
min_examined_row_limit = 5000
#记录执行缓慢的管理SQL,如alter table,analyze table, check table, create index, drop index, optimize table, repair table等。
log_slow_admin_statements = 0
#作为从库时生效, 从库复制中如何有慢sql也将被记录
#对于ROW格式binlog,不管执行时间有没有超过阈值,都不会写入到从库的慢查询日志
log_slow_slave_statements = 1
#--###########################-- 慢SQL日志记录 结束 --##########################################
#--###########################-- Bin-Log设置 开始 --############################################
server-id = 110
#开启bin log 功能
log-bin=mysql-bin
#binlog 记录内容的方式,记录被操作的每一行
binlog_format = ROW
#对于binlog_format = ROW模式时,FULL模式可以用于误操作后的flashBack。
#如果设置为MINIMAL,则会减少记录日志的内容,只记录受影响的列,但对于部分update无法flashBack
binlog_row_image = FULL
#bin log日志保存的天数
#如果 binlog_expire_logs_seconds 选项也存在则 expire_logs_days 选项无效
#expire_logs_days 已经被标注为过期参数
#expire_logs_days = 7
binlog_expire_logs_seconds = 1209600
#master status and connection information输出到表mysql.slave_master_info中
master_info_repository = TABLE
#the slave's position in the relay logs输出到表mysql.slave_relay_log_info中
relay_log_info_repository = TABLE
#作为从库时生效, 想进行级联复制,则需要此参数
log_slave_updates
#作为从库时生效, 中继日志relay-log可以自我修复
relay_log_recovery = 1
#作为从库时生效, 主从复制时忽略的错误
#如果在备份过程中执行ddl操作,从机需要从主机的备份恢复时可能会异常,从而导致从机同步数据失败
#如果对数据完整性要求不是很严格,那么这个选项确实可以减轻维护的成本
slave_skip_errors = ddl_exist_errors
#####RedoLog日志 和 binlog日志的写磁盘频率设置 BEGIN ###################################
# RedoLog日志(用于增删改事务操作) + binlog日志(用于归档,主从复制)
# 为什么会有两份日志呢?
# 因为最开始MySQL没有 InnoDB 引擎,自带MyISAM引擎没有 crash-safe能力,binlog日志只用于归档
# InnoDB 引擎是另一个公司以插件形式引入MySQL的,采用RedoLog日志来实现 crash-safe 能力
# redo log 的写入(即事务操作)拆成两阶段提交(2PC):prepare阶段 和 commit阶段
#(事务步骤1) 执行commit命令,InnoDB redo log 写盘,然后告知Mysql执行器:[你可以写binlog了,且一并提交事务],事务进入 prepare 状态
#(事务步骤2) 如果前面 prepare 成功,Mysql执行器生成 binlog 并且将binlog日志写盘
#(事务步骤3) 如果binlog写盘成功,Mysql执行器一并调用InnoDB引擎的提交事务接口,事务进入 commit 状态,操作完成,事务结束
#参数设置成 1,每次事务都直接持久化到磁盘
#参数设置成 0,mysqld进程的崩溃会导致上一秒钟所有事务数据的丢失。
#参数设置成 2,只有在操作系统崩溃或者系统掉电的情况下,上一秒钟所有事务数据才可能丢失。
#即便都设置为1,服务崩溃或者服务器主机crash,Mysql也可能丢失但最多一个事务
#控制 redolog 写磁盘频率 默认为1
innodb_flush_log_at_trx_commit = 1
#控制 binlog 写磁盘频率
sync_binlog = 1
#####RedoLog日志 和 binlog日志的写磁盘频率设置 END #####################################
#一般数据库中没什么大的事务,设成1~2M,默认32kb
binlog_cache_size = 4M
#binlog 能够使用的最大cache 内存大小
max_binlog_cache_size = 2G
#单个binlog 文件大小 默认值是1GB
max_binlog_size = 1G
#开启GTID复制模式
gtid_mode = on
#强制gtid一致性,开启后对于create table ... select ...或 CREATE TEMPORARY TABLE 将不被支持
enforce_gtid_consistency = 1
#解决部分无主键表导致的从库复制延迟问题
#其基本思路是对于在一个ROWS EVENT中的所有前镜像收集起来,
#然后在一次扫描全表时,判断HASH中的每一条记录进行更新
#该参数已经被标注为过期参数
#slave-rows-search-algorithms = 'INDEX_SCAN,HASH_SCAN'
# default value is CRC32
#binlog_checksum = 1
# default value is ON
#relay-log-purge = 1
#--###########################-- Bin-Log设置 结束 --##########################################
#--###########################-- 可能用到的MyISAM性能设置 开始 --#############################
#对MyISAM表起作用,但是内部的临时磁盘表是MyISAM表,也要使用该值。
#可以使用检查状态值 created_tmp_disk_tables 得知详情
key_buffer_size = 15M
#对MyISAM表起作用,但是内部的临时磁盘表是MyISAM表,也要使用该值,
#例如大表order by、缓存嵌套查询、大容量插入分区。
read_buffer_size = 8M
#对MyISAM表起作用 读取优化
read_rnd_buffer_size = 4M
#对MyISAM表起作用 插入优化
bulk_insert_buffer_size = 64M
#--###########################-- 可能用到的MyISAM性能设置 开始 --################################
#--###########################-- innodb性能设置 开始 --##########################################
# Defines the maximum number of threads permitted inside of InnoDB.
# A value of 0 (the default) is interpreted as infinite concurrency (no limit)
innodb_thread_concurrency = 0
#一般设置物理存储的 60% ~ 70%
innodb_buffer_pool_size = 8G
#当缓冲池大小大于1GB时,将innodb_buffer_pool_instances设置为大于1的值,可以提高繁忙服务器的可伸缩性
innodb_buffer_pool_instances = 4
#默认启用。指定在MySQL服务器启动时,InnoDB缓冲池通过加载之前保存的相同页面自动预热。 通常与innodb_buffer_pool_dump_at_shutdown结合使用
innodb_buffer_pool_load_at_startup = 1
#默认启用。指定在MySQL服务器关闭时是否记录在InnoDB缓冲池中缓存的页面,以便在下次重新启动时缩短预热过程
innodb_buffer_pool_dump_at_shutdown = 1
# Defines the name, size, and attributes of InnoDB system tablespace data files
innodb_data_file_path = ibdata1:1G:autoextend
#InnoDB用于写入磁盘日志文件的缓冲区大小(以字节为单位)。默认值为16MB
innodb_log_buffer_size = 32M
#InnoDB日志文件组数量
innodb_log_files_in_group = 3
#InnoDB日志文件组中每一个文件的大小
innodb_log_file_size = 2G
#是否开启在线回收(收缩)undo log日志文件,支持动态设置,默认开启
innodb_undo_log_truncate = 1
#当超过这个阀值(默认是1G),会触发truncate回收(收缩)动作,truncate后空间缩小到10M
innodb_max_undo_log_size = 4G
#The path where InnoDB creates undo tablespaces
#没有配置则在数据文件目录下
#innodb_undo_directory = /var/lib/mysql/undolog
#用于设定创建的undo表空间的个数
#已经弃用了,只能手动添加undo表空间
#The innodb_undo_tablespaces variable is deprecated and is no longer configurable as of MySQL 8.0.14
#innodb_undo_tablespaces = 95
#提高刷新脏页数量和合并插入数量,改善磁盘I/O处理能力
#根据您的服务器IOPS能力适当调整
#一般配普通SSD盘的话,可以调整到 10000 - 20000
#配置高端PCIe SSD卡的话,则可以调整的更高,比如 50000 - 80000
innodb_io_capacity = 4000
innodb_io_capacity_max = 8000
#如果打开参数innodb_flush_sync, checkpoint时,flush操作将由page cleaner线程来完成,此时page cleaner会忽略io capacity的限制,进入激烈刷脏
innodb_flush_sync = 0
innodb_flush_neighbors = 0
#CPU多核处理能力设置,假设CPU是4颗8核的,设置如下
#读多,写少可以设成 2:6的比例
innodb_write_io_threads = 8
innodb_read_io_threads = 8
innodb_purge_threads = 4
innodb_page_cleaners = 4
innodb_open_files = 65535
innodb_max_dirty_pages_pct = 50
#该参数针对unix、linux,window上直接注释该参数.默认值为 NULL
#O_DIRECT减少操作系统级别VFS的缓存和Innodb本身的buffer缓存之间的冲突
innodb_flush_method = O_DIRECT
innodb_lru_scan_depth = 4000
innodb_checksum_algorithm = crc32
#为了获取被锁定的资源最大等待时间,默认50秒,超过该时间会报如下错误:
# ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
innodb_lock_wait_timeout = 20
#默认OFF,如果事务因为加锁超时,会回滚上一条语句执行的操作。如果设置ON,则整个事务都会回滚
innodb_rollback_on_timeout = 1
#强所有发生的死锁错误信息记录到 error.log中,之前通过命令行只能查看最近一次死锁信息
innodb_print_all_deadlocks = 1
#在创建InnoDB索引时用于指定对数据排序的排序缓冲区的大小
innodb_sort_buffer_size = 67108864
#控制着在向有auto_increment 列的表插入数据时,相关锁的行为,默认为2
#0:traditonal (每次都会产生表锁)
#1:consecutive (mysql的默认模式,会产生一个轻量锁,simple insert会获得批量的锁,保证连续插入)
#2:interleaved (不会锁表,来一个处理一个,并发最高)
innodb_autoinc_lock_mode = 1
#表示每个表都有自已独立的表空间
innodb_file_per_table = 1
#指定Online DDL执行期间产生临时日志文件的最大大小,单位字节,默认大小为128MB。
#日志文件记录的是表在DDL期间的数据插入、更新和删除信息(DML操作),一旦日志文件超过该参数指定值时,
#DDL执行就会失败并回滚所有未提交的当前DML操作,所以,当执行DDL期间有大量DML操作时可以提高该参数值,
#但同时也会增加DDL执行完成时应用日志时锁定表的时间
innodb_online_alter_log_max_size = 4G
#--###########################-- innodb性能设置 结束 --##########################################
相关文章:

mysql 性能调优参数配置文件
########################################################################### ## my.cnf for MySQL 8.0.x # ## 本配置参考 https://imysql.com/my-cnf-wizard.html # ## 注意: …...

windows右键新建文件没有txt文本文档怎么办?
我碰到此问题,按照以下方法改了注册表, 重启之后就正常了(没有注销,只是单纯重启)。以下方法来自AI: 如果在注册表的 .txt 路径下没有找到 ShellNew 键,你可以尝试手动创建这个键和所需的值来恢…...

已读不回,我又玻璃心了
最近有点上火,3个询盘给我整我无语了,难道我还没修炼到家?玻璃心又出来作祟了? 客户A急火火的发我一个文件,需求内容ios客户端调整,让我按照需求给找个人处理下,我收到后抓紧时间摇人࿰…...
)
面试经典150题(105-107)
leetcode 150道题 计划花两个月时候刷完之未完成后转,今天(第2天)完成了3道(105-107)150 105.(191. 位1的个数)题目描述: 编写一个函数,输入是一个无符号整数(以二进制串的形式&am…...
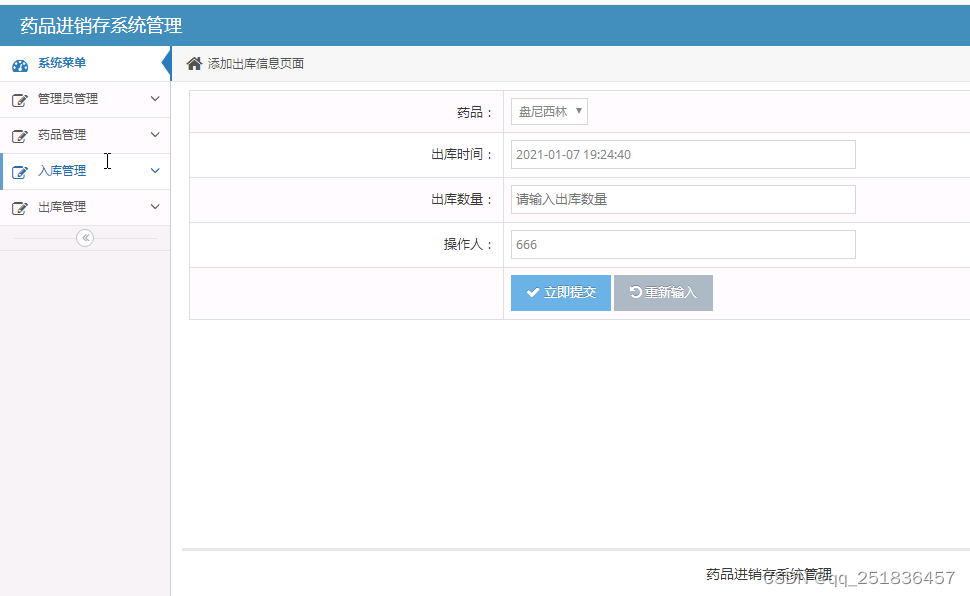
javaWebssh药品进销存信息管理系统myeclipse开发mysql数据库MVC模式java编程计算机网页设计
一、源码特点 java ssh药品进销存信息管理系统是一套完善的web设计系统(系统采用ssh框架进行设计开发),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOM…...
计算机设计大赛 深度学习实现语义分割算法系统 - 机器视觉
文章目录 1 前言2 概念介绍2.1 什么是图像语义分割 3 条件随机场的深度学习模型3\. 1 多尺度特征融合 4 语义分割开发过程4.1 建立4.2 下载CamVid数据集4.3 加载CamVid图像4.4 加载CamVid像素标签图像 5 PyTorch 实现语义分割5.1 数据集准备5.2 训练基准模型5.3 损失函数5.4 归…...

Linux系统编程(六)高级IO
目录 1. 阻塞和非阻塞 IO 2. IO 多路转接(select、poll、epoll) 3. 存储映射 IO(mmap) 4. 文件锁(fcntl、lockf、flock) 5. 管道实例 - 池类算法 1. 阻塞和非阻塞 IO 阻塞 IO:会等待操作的…...

Python与FPGA——全局二值化
文章目录 前言一、Python全局128二、Python全局均值三、Python全局OTSU四、FPGA全局128总结 前言 为什么要进行图像二值化,rgb图像有三个通道,处理图像的计算量较大,二值化的图像极大的减少了处理图像的计算量。即便从彩色图像转成了二值化图…...

《Docker极简教程》--Docker的高级特性--Docker Compose的使用
Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。它允许开发人员通过简单的YAML文件来定义应用程序的服务、网络和卷等资源,并使用单个命令来启动、停止和管理整个应用程序的容器。以下是关于Docker Compose的一些关键信息和优势: 定义…...

tidyverse去除表格中含有NA的行
在tidyverse中,特别是使用dplyr包,去除含有NA的行可以通过filter()函数结合is.na()和any()或all()函数来实现。dplyr是tidyverse的一部分,提供了一系列用于数据操作的函数,使数据处理变得更加简单和直观。 以下是一个简单的例子&…...
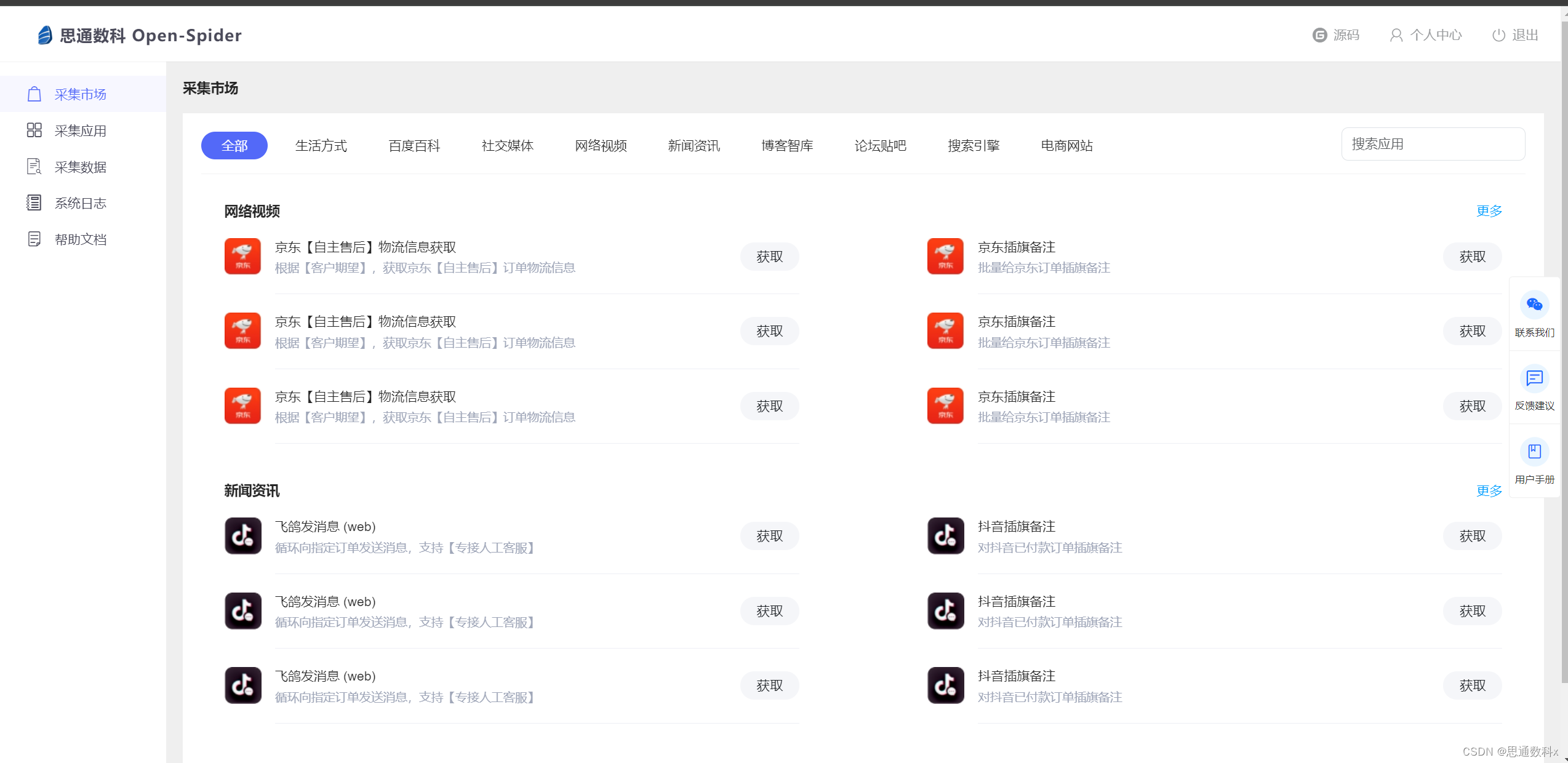
开源爬虫技术在金融行业市场分析中的应用与实战解析
一、项目介绍 在当今信息技术飞速发展的时代,数据已成为企业最宝贵的资产之一。特别是在${industry}领域,海量数据的获取和分析对于企业洞察市场趋势、优化产品和服务至关重要。在这样的背景下,爬虫技术应运而生,它能够高效地从互…...

使用SMTP javamail发送邮件
一、SMTP协议 SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。SMTP协议属于TCP/IP协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。使用javamail编写发送…...

Hello C++ (c++是什么/c++怎么学/c++推荐书籍)
引言 其实C基础语法基本上已经学完,早就想开始写C的博客了,却因为其他各种事情一直没开始。原计划是想讲Linux系统虚拟机安装的,后来考虑了一下还是算了,等Linux学到一定程度再开始相关博客的写作和发表吧。今天写博客想给C开个头…...

最新的前端开发技术(2024年)
关于作者: 还是大剑师兰特:曾是美国某知名大学计算机专业研究生,现为航空航海领域高级前端工程师;CSDN知名博主,GIS领域优质创作者,深耕openlayers、leaflet、mapbox、cesium,canvas࿰…...
GCN 翻译 - 2
2 FAST APROXIMATE CONVOLUTIONS ON GRAPHS 在这一章节,我们为这种特殊的的图基础的神经网络模型f(X, A)提供理论上的支持。我们考虑一个多层的图卷积网络(GCN),它通过以下方式进行层间的传播: 这里,是无…...
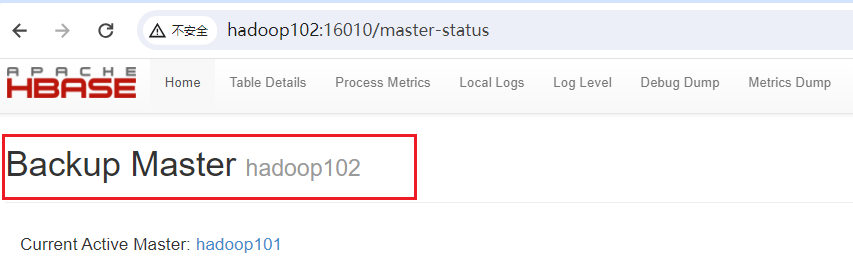
HBase 的安装与部署
目录 1 启动 zookeeper2 启动 Hadoop3 HBase 的安装与部署4 HBase 高可用 1 启动 zookeeper [huweihadoop101 ~]$ bin/zk_cluster.sh start2 启动 Hadoop [huweihadoop101 ~]$ bin/hdp_cluster.sh start3 HBase 的安装与部署 (1)将 hbase-2.0.5-bin.tar.…...

236.二叉搜索树的公共祖先
236.二叉树的公共祖先 思路 看到题想的是找到两个点的各自路径利用stack保存,根据路径长度大小将两个stack的值对齐到同一层,之后同时出栈节点,若相同则找到祖先节点。但是效率不高 看了大佬代码,递归思想很难理解。 根据大佬…...
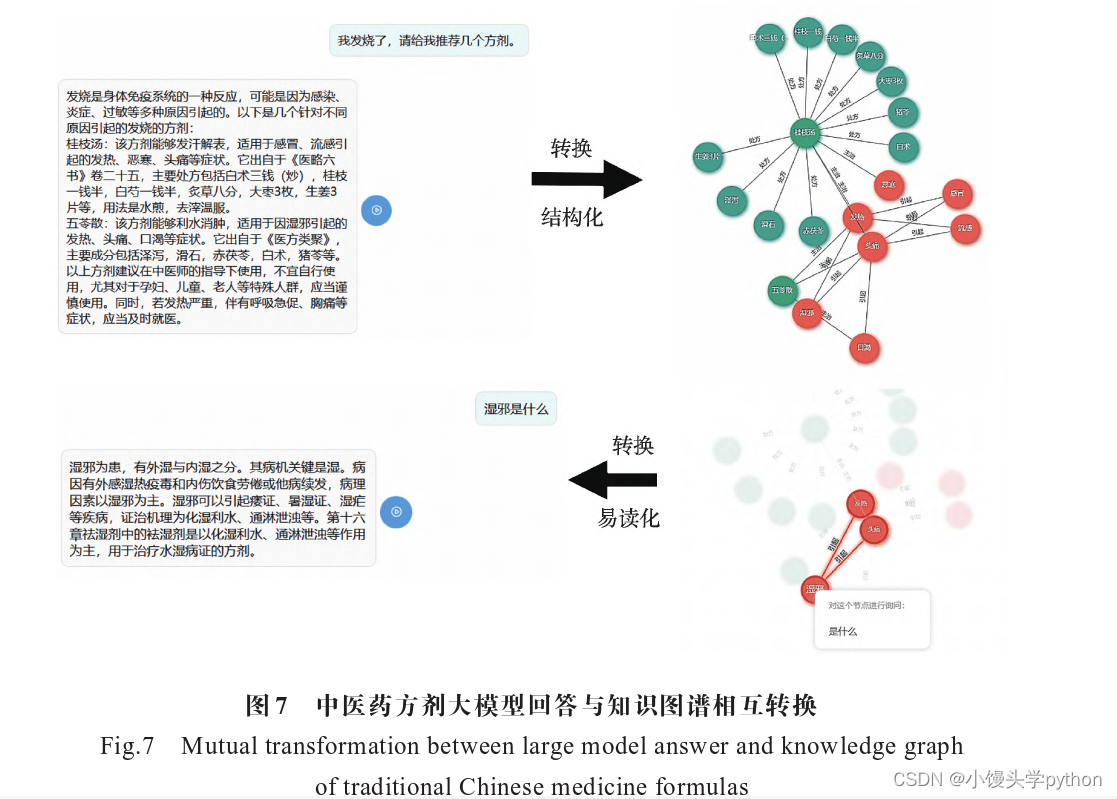
【论文精读】大语言模型融合知识图谱的问答系统研究
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
LabVIEW高精度天线自动测试系统
LabVIEW高精度天线自动测试系统 系统是一个集成了LabVIEW软件的自动化天线测试平台,提高天线性能测试的精度与效率。系统通过远程控制测试仪表,实现了数据采集、方向图绘制、参数计算等功能,特别适用于对天线辐射特性的精确测量。 在天线的…...
7.3 支付模块 - 创建订单、查询订单、通知
支付模块 - 创建订单、查询订单、通知 文章目录 支付模块 - 创建订单、查询订单、通知一、生成支付二维码1.1 数据模型1.1.1 订单表1.1.2 订单明细表1.1.3 支付交易记录表 1.2 执行流程1.3 Dto1.3.1 AddOrderDto 商品订单1.3.2 PayRecordDto支付交易记录扩展字段1.3.3 雪花算法…...

利用coze使用无代码平台搭建图片识别机器人
利用coze使用无代码平台搭建图片识别机器人 无代码平台允许用户通过可视化界面快速创建聊天机器人,无需编程基础。例如,扣子(Coze) 是一个由字节跳动开发的智能体应用开发平台,支持集成多种大语言模型(如 …...

开源自动化工具用例集:从网页监控到GUI自动化的实践指南
1. 项目概述:一个中文开源“利爪”用例集最近在整理一些自动化脚本和工具链时,我一直在思考一个问题:一个真正好用的、能解决实际问题的自动化工具,它的价值边界到底在哪里?是仅仅完成一个预设的、简单的任务ÿ…...

Unity 5.6移动VR开发与单通道渲染优化指南
1. Unity 5.6移动VR开发环境配置1.1 Daydream原生支持解析Unity 5.6首次实现了对Daydream平台的原生支持,这标志着移动VR开发进入新阶段。与传统的插件式集成不同,原生支持直接内置于引擎核心,带来三个显著优势:性能提升ÿ…...

单例模式深度解析:从基础实现到生产级避坑指南
1. 单例模式:为什么它既是基石又是“坑”在软件开发的江湖里,单例模式(Singleton Pattern)的名号,几乎无人不知。它被写进教科书,是设计模式中最容易理解、也最常被提及的模式之一。但有趣的是,…...

FPGA实战:用Z80与8051软核构建可运行BASIC的复古计算机
1. 项目概述:在FPGA上复活经典8位计算机如果你和我一样,对上世纪七八十年代那些经典的8位计算机架构——比如Zilog Z80和Intel 8051——抱有浓厚的兴趣,同时又对现代FPGA技术着迷,那么这个项目绝对会让你兴奋。它不是一个简单的仿…...

Equalizer APO:Windows系统音频均衡终极指南,免费打造专业级音效体验
Equalizer APO:Windows系统音频均衡终极指南,免费打造专业级音效体验 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 想要彻底提升Windows电脑的音频质量吗?Equalize…...

RISC-V RT-Thread Smart用户态应用编译与QEMU运行实战指南
1. 项目概述:从内核到应用的完整RISC-V生态体验最近在折腾RT-Thread Smart(简称RTT-Smart)这个微内核实时操作系统,目标平台是qemu模拟的64位RISC-V虚拟机(qemu-virt64-riscv)。整个过程的核心,…...

靠谱的openai claudecode AI中转站
各位大神开发都用那些模型?最近用Trae的模型一下就降智,切换到apikeyfun.com 用了ops4.7和gpt5.5简直是降维打击,速度快,还不错!...

DLT Viewer:面向汽车电子系统的分布式日志诊断与实时监控技术方案
DLT Viewer:面向汽车电子系统的分布式日志诊断与实时监控技术方案 【免费下载链接】dlt-viewer Diagnostic Log and Trace viewing program 项目地址: https://gitcode.com/gh_mirrors/dl/dlt-viewer DLT Viewer是一款基于COVESA标准的专业诊断日志分析工具&…...

从省级技术中心认证,看嵌入式企业如何以系统工程能力赋能开发者
1. 从“省级企业技术中心”认定,看一家嵌入式企业的硬核实力最近,在河北省发改委公布的2023年省级企业技术中心认定名单里,我看到了一个熟悉的名字——保定飞凌嵌入式技术有限公司。对于圈内人来说,“飞凌嵌入式”这个名字并不陌生…...