机器学习-面经(part8、贝叶斯和其他知识点)
机器学习面经其他系列
机器学习面经系列的其他部分如下所示:
机器学习-面经(part1)-初步说明
机器学习-面经(part2)-交叉验证、超参数优化、评价指标等内容
机器学习-面经(part3)-正则化、特征工程面试问题与解答合集
机器学习-面经(part4)-决策树共5000字的面试问题与解答
机器学习-面经(part5)-KNN以及SVM等共二十多个问题及解答
机器学习-面经(part6)-集成学习(万字解答)
机器学习-面经(part7、无监督学习)
12 概率模型
12.1 朴素贝叶斯
是一个生成模型,其次它通过学习已知样本,计算出联合概率,再求条件概率。
原理:基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的待分类项X,通过学习到的模型计算后验概率分布,即:在此项出现的条件下各个目标类别出现的概率,将后验概率最大的类作为X所属的类别。
前提假设:
- 特征之间相互独立
- 每个特征同等重要
贝叶斯定理的公式表达式如下所示:
![]()
12.1.1为什么朴素贝叶斯如此“朴素”?
在计算条件概率分布P(X=x∣Y=Ck)时,NB引入了一个很强的条件独立假设,即,当Y确定时,X的各个特征分量取值之间相互独立,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。
利用贝叶斯定理求解联合概率P(XY)时,需要计算条件概率P(X|Y)。在计算P(X|Y)时,朴素贝叶斯做了一个很强的条件独立假设(当Y确定时,X的各个分量取值之间相互独立),即P(X1=x1,X2=x2,…Xj=xj|Y=yk) = P(X1=x1|Y=yk)P(X2=x2|Y=yk)…*P(Xj=xj|Y=yk)。 多个特征全是独立的,需要分别相乘
12.1.2 朴素贝叶斯的优缺点?

12.1.3 为什么引入条件独立性假设?
1、朴素贝叶斯法对条件概率分布做了条件独立性的假设,由于这是一个较强的假设,朴素贝叶斯也由此得名!这一假设使得朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率
2、同时为了避免贝叶斯定理求解时面临的组合爆炸、样本稀疏问。
12.1.4 在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
采用贝叶斯估计。即引入λ,当λ=1时,就是普通的极大似然估计;λ=1时称为拉普拉斯平滑。拉普拉斯平滑法是朴素贝叶斯中处理零概率问题的一种修正方式。在进行分类的时候,可能会出现某个属性在训练集中没有与某个类同时出现过的情况,如果直接基于朴素贝叶斯分类器的表达式进行计算的话就会出现零概率现象。为了避免其他属性所携带的信息被训练集中未出现过的属性值“抹去”,所以才使用拉普拉斯估计器进行修正。具体的方法是:在分子上加1,对于先验概率,在分母上加上训练集中label的类别数;对于特征i 在label下的条件概率,则在分母上加上第i个属性可能的取值数(特征 i 的unique())
12.1.5 为什么属性独立性假设在实际情况中很难成立,但NB仍能取得较好效果?
使用分类器之前,首先做的第一步往往是特征选择,目的就是为了排除特征之间的共线性、选择相对较为独立的特征;对于与分类任务来说,只要各类别的条件概率排序正确,无需精准概率值就可以导致正确分类;
如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算复杂度的同时不会对性能产生负面影响。
12.1.6 如何对贝叶斯网络进行采样?
- 没有观测变量:采用祖先采样,核心思想是根据有向图的顺序,先对祖先节点进行采样,只有当某个节点的父节点都已经完成采样,才对该节点进行采样。
- 只对非观测变量采样,但是最终得到的样本需要赋一个重要性权值,这种采样方法称作似然加权采样;
- 还可以用MCMC采样法来进行采样
12.2 朴素贝叶斯 vs LR

详细来讲,前者是生成式模型,后者是判别式模型,二者的区别就是生成式模型与判别式模型的区别。
- 首先,Navie Bayes通过已知样本求得先验概率P(Y), 及条件概率P(X|Y), 对于给定的实例,计算联合概率,进而求出后验概率。它尝试去找到底这个数据是怎么生成的(产生的),然后再进行分类。哪个类别最有可能产生这个信号,就属于那个类别。
- 优点:样本容量增加时,收敛更快;隐变量存在时也可适用。
- 缺点:时间长;需要样本多;浪费计算资源
- 相比之下,Logistic回归不关心样本中类别的比例及类别下出现特征的概率,它直接给出预测模型的式子。设每个特征都有一个权重,训练样本数据更新权重w,得出最终表达式。虽然他是算条件概率,但是根据极大似然对数估计,直接写出目标概率函数,并变成对数损失函数,使用SGD算法去优化求解。
- 优点:直接预测往往准确率更高;简化问题;可以反应数据的分布情况,类别的差异特征;适用于较多类别的识别。
- 缺点:收敛慢;不适用于有隐变量的情况
12.3 先验概率和后验概率
先验概率是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现. 就是根据以往的经验或者现有数据的分析所得到的概率。如,随机扔一枚硬币,则p(正面) = p(反面) = 1/2,这是我们根据已知的知识所知道的信息,即p(正面) = 1/2为先验概率。
后验概率是指依据得到"结果"信息所计算出的最有可能是那种事件发生,如贝叶斯公式中的,是"执果寻因"问题中的"因"。后验概率是基于新的信息,修正原来的先验概率后所获得的更接近实际情况的概率估计。
先验概率和后验概率是相对的。如果以后还有新的信息引入,更新了现在所谓的后验概率,得到了新的概率值,那么这个新的概率值被称为后验概率。
数学表达式为p(A|B), 即A在B发生的条件下发生的概率。以误喝牛奶的例子为例,现在知道了你今天拉肚子了(B),算一下你早上误喝了一瓶过期了的牛奶(A)的概率, 即P(A|B),这就是后验概率,后验概率是有果求因(知道结果推出原因)
12.4 生成模式和判别模式的区别(常见):
- 生成模式:由数据学得联合概率分布,求出条件概率分布P(Y|X)的预测模型;比较在乎数据是怎么生成的
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
- 判别模式:由数据学得决策函数或条件概率分布作为预测模型,要关注在数据的差异分布上,而不是生成
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
12.5 为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍能取得较好的效果?
首先独立性假设在实际中不存在,确实会导致朴素贝叶斯不如一些其他算法,但是就算法本身而言,朴素贝叶斯也会有不错的分类效果,原因是:
- 分类问题看中的是类别的条件概率的排序,而不是具体的概率值,所以这里面对精准概率值的计算是有一定的容错的。
- 如果特征属性之间的依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响。
12.6 朴素贝叶斯可以做多分类吗?
可以,朴素贝叶斯是选出各个分类类别后验概率最大的作为最终分类
12.7 朴素贝叶斯中概率计算的下溢问题如何解决?
在朴素贝叶斯的计算过程中,需要对特定分类中各个特征出现的概率进行连乘,小数相乘,越乘越小,这样就造成下溢出。在程序中,在相应小数位置进行四舍五入,计算结果可能就变成0了。
为了解决这个问题,对乘积结果取自然对数。将小数的乘法操作转化为取对数后的加法操作,规避了变为0的风险同时并不影响分类结果。
12.8 朴素贝叶斯分类器对异常值和缺失值敏感吗?
回想朴素贝叶斯的计算过程,它在推理的时候,输入的某个特征组合,他们的特征值在训练的时候在贝叶斯公式中都是基于频数进行统计的。
所以一个值的异常(变成了别的数),只是贝叶斯公式里的计算概率的分子或者分母发生微小的变化,整体结果影响不大,就算微微影响最终概率值的获得,由于分类问题只关注概率的排序而不关注概率的值,所以影响不大,保留异常值还可以提高模型的泛化性能。
缺失值也是一样,如果一个数据实例缺失了一个属性的数值,在建模的时将被忽略,不影响类条件概率的计算,在预测时,计算数据实例是否属于某类的概率时也将忽略缺失属性,不影响最终结果。
12.9. 朴素贝叶斯中有没有超参数可以调?
朴素贝叶斯是没有超参数可以调的,所以它不需要调参,朴素贝叶斯是根据训练集进行分类,分类出来的结果基本上就是确定了的,拉普拉斯估计器不是朴素贝叶斯中的参数,不能通过拉普拉斯估计器来对朴素贝叶斯调参。
12.10 朴素贝叶斯有哪三个模型?
- 多项式模型 对应于离散变量,其中离散变量指的是category型变量,也就是类别变量,比如性别;连续变量一般是数字型变量,比如年龄,身高,体重。
- 高斯模型 对应于连续变量(每一维服从正态分布)
- 伯努利模型 文本分类 (特征只能是0或者1)
12.11 朴素贝叶斯是高方差还是低方差模型?
朴素贝叶斯是低方差模型。(误差 = 偏差 + 方差)
对于复杂模型来说,由于复杂模型充分拟合了部分数据,使得它们的偏差变小,但由于对部分数据过分拟合,这就导致预测的方差会变大。
因为朴素贝叶斯假设了各个属性之间是相互的,算是一个简单的模型。对于简单的模型来说,则恰恰相反,简单模型的偏差会更大,相对的,方差就会较小。
12.12 朴素贝叶斯有什么优缺点?
优点
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据和异常数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快。
- 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,当数据量超出内存时,我们可以一批批的去增量训练(朴素贝叶斯在训练过程中只需要计算各个类的概率和各个属性的类条件概率,这些概率值可以快速地根据增量数据进行更新,无需重新全量计算)。
缺点
- 对训练数据的依赖性很强,如果训练数据误差较大,那么预测出来的效果就会不佳
- 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。 但是在实际中,因为朴素贝叶斯“朴素,”的特点,导致在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
- 需要知道先验概率,且先验概率很多时候是基于假设或者已有的训练数据所得的,这在某些时候可能会因为假设先验概率的原因出现分类决策上的错误。
什么是深度学习?深度学习的训练过程是什么?
无监督预训练+有监督微调(fine-tune)
过程:(1)自下而上非监督学习特征 (2)自顶向下有监督微调
深度学习与机器学习有什么区别?
机器学习在训练模型之前,需要手动设置特征,即需要做特征工程;
深度学习可自动提取特征;所以深度学习自动提取的特征比机器学习手动设置的特征鲁棒性更好;
13. 机器学习
13.1 你是怎么理解偏差和方差的平衡的?
偏差是真实值和预测值之间的偏离程度;方差是预测值得分散程度,即越分散,方差越大;
- 偏差是模型输出值与真实值的误差,也就是模型的精准度
- 方差是预测值与模型输出期望的的误差,即模型的稳定性,也就是数据的集中性的一个指标
13.2 给你一个有1000列和1百万行的训练数据集,这个数据集是基于分类问题的。经理要求你来降低该数据集的维度以减少模型计算时间,但你的机器内存有限。你会怎么做?
处理方法:
1.由于我们的RAM很小,首先要关闭机器上正在运行的其他程序,包括网页浏览器等,以确保大部分内存可以使用。
2.随机采样数据集: 可以创建一个较小的数据集,比如有1000个变量和30万行,然后做计算。
3.为了降低维度,可以把数值变量和分类变量分开,同时删掉相关联的变量。对于数值变量,将使用相关性分析;对于分类变量,可以用卡方检验(统计学)。
4.另外,还可以使用PCA,并挑选可以解释在数据集中有最大偏差的成分。
5.利用在线学习算法,如VowpalWabbit。
6.利用 SGD 建立线性模型也很有帮助。
13.3 给你一个数据集,这个数据集有缺失值,且这些缺失值分布在离中值有1个标准偏差的范围内。百分之多少的数据不会受到影响?为什么?
约有32%的数据将不受缺失值的影响。由于数据分布在中位数附近,先假设这是一个正态分布。在一个正态分布中,约有68%的数据位于跟平均数(或众数、中位数)1个标准差范围内,那么剩下的约32%的数据是不受影响的。
13.4 模型受到低偏差和高方差问题时,应该使用哪种算法来解决问题呢?
可以使用bagging算法(随机森林)。低偏差意味着模型的预测值接近实际值,即该模型有足够的灵活性,以模仿训练数据的分布。
bagging算法把数据集分成重复随机取样形成的子集。然后这些样本利用单个学习算法生成一组模型。接着,利用投票(分类)或平均(回归)把模型预测结合在一起。
另外,为了应对大方差,我们可以:
1.使用正则化技术,惩罚更高的模型系数,从而降低了模型的复杂性。
2.使用可变重要性图表中的前n个特征。可以用于当一个算法在数据集中的
所有变量里很难寻找到有意义信号的时候。
13.5 怎么理解偏差方差的平衡的?
偏差误差在量化平均水平之上,预测值跟实际值相差多远时有用。
高偏差误差意味着我们的模型表现不太好,因为没有抓到重要的趋势。
而另一方面,方差量化了在同一个观察上进行的预测是如何彼此不同的。
高方差模型会过度拟合你的训练集,而在训练集以外的数据上表现很差。
13.6 协方差和相关性有什么区别?
相关性是协方差的标准化格式。协方差本身很难做比较。如:计算工资($)和年龄(岁)的协方差,因为这两个变量有不同的度量,所以会得到不能做比较的不同的协方差。
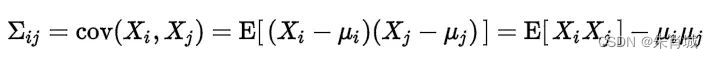
为了解决这个问题,通过计算相关性来得到一个介于-1和1之间的值,就可以忽略它们各自不同的度量。
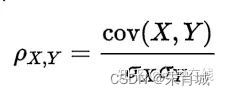
13.7 把分类变量当成连续型变量会更得到一个更好的预测模型吗?
只有在分类变量在本质上是有序的情况下才可以被当做连续型变量来处理。
“买了这个的客户,也买了......”亚马逊的建议是哪种算法的结果?
13.8 机器学习中分类器指的是什么?
指输入离散或连续特征值的向量,并输出单个离散值或者类型的系统。
对统计这一块了解吗?p值是什么?
当原假设为真时所得到的样本观察结果或更极端结果出现的概率;
如果P值很小,说明bai原假设情况的发生的概率很小;
如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。
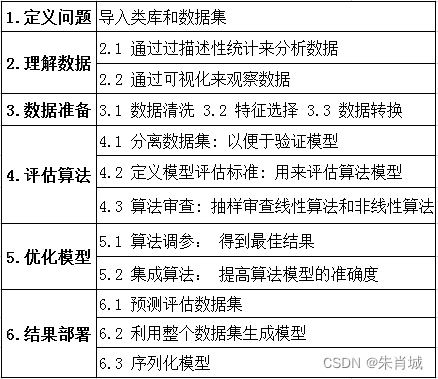
13.9 请简要说说一个完整机器学习项目的流程?
相关文章:
机器学习-面经(part8、贝叶斯和其他知识点)
机器学习面经其他系列 机器学习面经系列的其他部分如下所示: 机器学习-面经(part1)-初步说明 机器学习-面经(part2)-交叉验证、超参数优化、评价指标等内容 机器学习-面经(part3)-正则化、特征工程面试问题与解答合集机器学习-面经(part4)-决策树共5000字的面试问…...
)
图数据库 之 Neo4j - 应用场景3 - 知识图谱(8)
背景 知识图谱的复杂性:知识图谱通常包含大量的实体、关系和属性,以及它们之间的复杂关联。传统的关系型数据库在处理这种复杂性时可能面临性能和灵活性的挑战。 图数据库的优势:图数据库是一种专门用于存储和处理图结构数据的数据库。它们使用节点和边来表示实体和关系,并…...

redis 性能优化三
前言 如果Redis 没有执行大量的慢查询,同时也没有删除大量的过期的keys,那么我们该怎么办呢?那么我们是不是就应该关注影响性能的其他机制了,也就是文件系统和操作系统了。 Redis 会把数据持久化到磁盘,这个过程依赖文件系统来完…...

Python用Tkinter实现圆的半径 面积 周长 知一求二程序
Python用Tkinter实现圆的半径 面积 周长 知一求二程序 import tkinter as tk from tkinter import messagebox from tkinter import *app tk.Tk() app.title(圆的半径 面积 周长 知一求二程序) app.geometry(425x125)label1 tk.Label(app, text"半径") label2 tk.…...

电源环路补偿的目标是避免产生正反馈
在一般的认识中,进行电源环路设计的目的是保证电源输出端的电压稳定,在误差信号传入系统时,系统进行负反馈调节,矫正干扰信号带来的误差量。 那么,为什么要设置成这样,不稳定会有什么后果等等,…...

SSM+MySQL替换探索 openGauss对比postgresql12
SSM 介绍 SSM(SpringSpringMVCMyBatis)框架集由 Spring、MyBatis 两个开源框架整合而成(SpringMVC 是 Spring 中的部分内容),常作为数据源较简单的 web 项目的框架。 Spring Spring 就像是整个项目中装配 bean 的大…...
XGboost的整理
XGboost(extreme gradient boosting):高效实现了GBDT算法并进行了算法和工程上的许多改进。 XGboost的思路: 目标:建立k个回归树,使得树群的预测尽量接近真实值(准确率)而且有尽量大的泛化能力…...

java入门基础学习导览
本篇文章会持续更新直到更新完毕,关注博主不迷路~(如果没有超链接,表示还没有更新到) 一 JAVA语言基础 二 流程控制 三 数组 字符串 与正则表达式 四 JAVA面向对象编程 五 JAVA 异常处理 六 JAVA输入输出 七 泛型与容器类 …...

网工内推 | 上市公司售前,大专以上即可,最高15K*13薪,补贴多
01 北京神州新桥科技有限公司 招聘岗位:售前工程师 职责描述: 1、完成项目的售前技术支持工作; 2、 配合销售进行新产品及解决方案的推广工作; 3、 配合销售完成用户的售前技术交流方案准备、现场技术交流、技术方案宣讲等工作…...
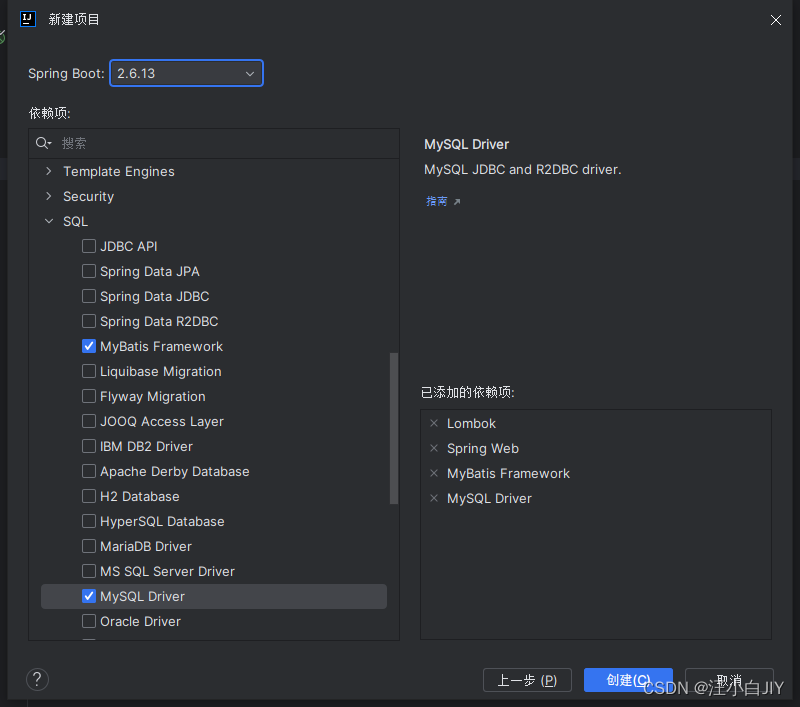
JAVA开发第一个Springboot WebApi项目
一、创建项目 1、用IDEA新建一个SpringBoot项目 注意JDK与Java版本的匹配,如果想选择jdk低版本,先要更改服务器URL:start.aliyun.com 2、添加依赖 (1)、Lombok (2)、Spring Web (3)、Mybatis Framework (4)、MySqlDriver 项目中的配置 pom.xml 如下 <?…...
基于springboot+vue的疫情管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

Qt 类的前置声明和头文件包含
1. 在头文件中引入另一个类经常有两种写法 1)前置声明 2)头文件包含 #ifndef FRMCOUPLE2_H #define FRMCOUPLE2_H#include <QWidget> //头文件包含namespace Ui { class frmcouple2; }//前置声明:QPushButton frmchkeyboard…...
Qt+FFmpeg+opengl从零制作视频播放器-1.项目介绍
1.简介 学习音视频开发,首先从做一款播放器开始是比较合理的,每一章节,我都会将源码贴在最后,此专栏你将学习到以下内容: 1)音视频的解封装、解码; 2)Qtopengl如何渲染视频&#…...

Learn OpenGL 01
OpenGL的定义 一般它被认为是一个API(Application Programming Interface, 应用程序编程接口),包含了一系列可以操作图形、图像的函数。然而,OpenGL本身并不是一个API,它仅仅是一个由Khronos组织制定并维护的规范(Specification)。 OpenGL规…...

Java开发从入门到精通(一):Java的基础语法进阶
Java大数据开发和安全开发 (一)Java注释符1.1 单行注释 //1.2 多行注释 /* */1.3 文档注释 /** */1.4 各种注释区别1.5 注释的特点1.5 注释的快捷键 (二)Java的字面量(三)Java的变量3.1 认识变量3.2 为什么…...
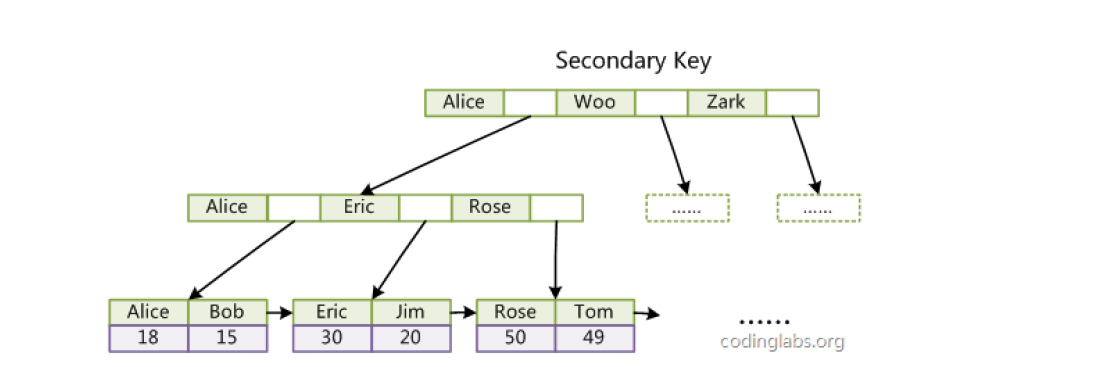
【C++从0到王者】第五十一站:B+树
文章目录 一、B树1.B树的概念2.B树的特性3.B树的插入的过程4.总结 二、B*树1. B*树的概念2.B*树的分裂 三、总结四、B树系列和哈希和平衡搜索树作对比五、B树的一些应用1.索引2.MySQL索引3.MyISAM2.InnoDB 一、B树 1.B树的概念 B树是B树的变形,是在B树基础上优化的…...
Spring Cloud 面试题及答案整理,最新面试题
Spring Cloud中断路器的原理及其作用是什么? Spring Cloud断路器的原理和作用基于以下几个关键点: 1、故障隔离机制: 在微服务架构中,断路器作为一种故障隔离机制,当某个服务实例出现问题时,断路器会“断…...

使用Kali搭建钓鱼网站教程
一、前言 使用kali工具一分钟制作出和目标网站一模一样的钓鱼网站。目标用户使用钓鱼网站登录自己的账号,账号密码将被自动劫持。 二、钓鱼网站的制作过程 1.在虚拟机VMvare中登录kali linux 2.准备一个目标网址 3.在kail中搜索使用工具 4.在弹出的选项中选择第一…...
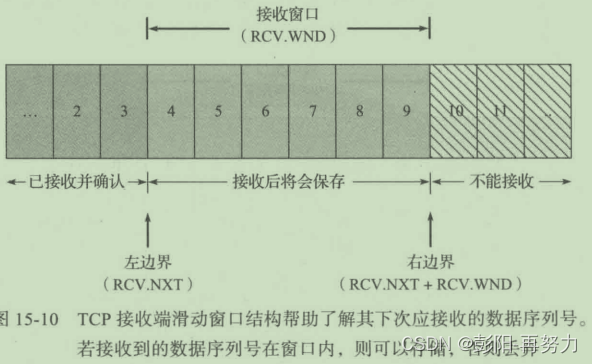
《TCP/IP详解 卷一》第15章 TCP数据流与窗口管理
目录 15.1 引言 15.2 交互式通信 15.3 延时确认 15.4 Nagle 算法 15.4.1 延时ACK与Nagle算法结合 15.4.2 禁用Nagle算法 15.5 流量控制与窗口管理 15.5.1 滑动窗口 15.5.2 零窗口与TCP持续计时器 15.5.3 糊涂窗口综合征 15.5.4 大容量缓存与自动调优 15.6 紧急机制…...

ContentType类型总结
ContentType类型总结 Content-Type是一个HTTP头部字段,用于指示资源的媒体类型(MIME类型),以及可选的字符集和编码方式。它告诉浏览器或其他客户端如何解释接收到的数据。以下是一些常见的Content-Type类型及其用途: t…...
)
Comsol光学仿真连续域束缚态BIC,te,tm模式耦合,透射光谱远场偏振矢量(导出数据计算)
Comsol光学仿真连续域束缚态BIC,te,tm模式耦合,透射光谱远场偏振矢量(导出数据计算),所见即所得 【手指在键盘上停顿三秒】这周在实验室搞COMSOL光学仿真差点被边界条件逼疯,连续域束缚态(BIC)…...

打造手游PC级操控:QtScrcpy键鼠映射完全指南
打造手游PC级操控:QtScrcpy键鼠映射完全指南 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy 手机…...

雷电模拟器装Magisk后,自带的文件管理器为啥打不开/data?用MT管理器一招搞定
雷电模拟器Magisk环境下文件管理器的权限困局与实战解决方案 当你在雷电模拟器中成功安装Magisk后,可能会遇到一个令人困惑的现象:原本可以自由访问系统目录的自带文件管理器,突然对/data和/system等关键路径"视而不见"。这并非模拟…...

OpenOCD入门到精通:第23章 添加新的 JTAG 适配器驱动
第23章 添加新的 JTAG 适配器驱动 导读摘要:OpenOCD 支持 40 余种调试适配器,每种适配器背后都有一个遵循统一接口规范的驱动程序。本章从 adapter_driver 结构体出发,逐一解析其回调函数语义,介绍 libusb/HIDAPI 通信层封装,并通过一个完整的简易驱动实现示例,帮助读者掌…...

【极限压测】从99.9%全红到5%安全线!2026最新横评5款硬核降AI工具
说真的,作为在知乎摸爬滚打好几年的博主,我太理解大家临近交稿时的那种绝望了。眼看着论文初稿要交,结果降ai检测一出来,竟然是红彤彤的99%?!那一刻,我感觉脑袋真的“嗡”的一声。好不容易熬夜码…...
的注册表锁定机制与长期试用方案)
深度技术解析:IDM激活脚本(IAS)的注册表锁定机制与长期试用方案
深度技术解析:IDM激活脚本(IAS)的注册表锁定机制与长期试用方案 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Dow…...

智能提取视频转文档:自动化工具提升内容处理效率
智能提取视频转文档:自动化工具提升内容处理效率 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 在数字化学习与办公场景中,视频内容提取已成为知识管理的重要…...

Windows Defender Remover:彻底移除Windows安全组件的终极解决方案
Windows Defender Remover:彻底移除Windows安全组件的终极解决方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh…...
)
基于三菱PLC与MCGS组态的农田智能灌溉系统说明(两万字)
基于三菱PLC农田灌溉 包含说明一万 和MCGS组态农田智能灌溉系统说明一万前阵子回豫东老家帮我叔打理那三亩秋月梨果园,那浇地给我整得怀疑人生——三伏天顶着三十七八度的太阳,扛着铁锹跑遍地头开电磁阀,中午热得头晕就算了,晚上还…...

Node.js 轻量级数据库 NeDB 实战指南:从入门到精通
1. 为什么你需要了解NeDB 如果你正在寻找一个轻量级的Node.js数据库解决方案,NeDB绝对值得你花时间研究。作为一个嵌入式数据库,它不需要单独运行数据库服务,数据可以直接存储在内存或磁盘文件中。我在多个小型项目中使用过NeDB,最…...