XGboost的整理
XGboost(extreme gradient boosting):高效实现了GBDT算法并进行了算法和工程上的许多改进。
XGboost的思路:
目标:建立k个回归树,使得树群的预测尽量接近真实值(准确率)而且有尽量大的泛化能力。
目标函数:
i表示第i个样本,表示第i个样本的预测误差,误差越小越好,
表示树的复杂度的函数,越小复杂度越低,泛化能力越强
T:叶子的个数
:w的L2模平方
目标要求预测尽量小,叶子节点尽量少,节点数值尽量不极端,回归树的参数(1)选取哪个特征分裂节点(2)节点的预测值。间接解决这两个参数的方法:贪心策略+最优化(二次最优化)
(1)选取哪个特征分裂节点:最简单的是枚举,选择loss function效果最好的那个
(2)确立节点的w以及最小的loss function,采用二次函数的求最值
步骤:选择一个feature分裂,计算loss function最小值,然后再选一个feature分列,又得到一个loss function最小值,枚举完成后,找一个效果最好的,把树分裂,在分裂的时候,每次节点分裂,loss function被影响的只有这个节点的样本,因而每次分裂,计算分裂的增益只需要关注打算分裂的那个节点的样本。接下来,继续分裂,按照上述方法,形成一棵树,再形成一棵树,每次在上一次的预测基础上取最优进一步分裂/建树。
停止条件:
①当引入的分裂带来的增益小于一个阈值的时候,可以剪掉这个分裂,所以并不是每一次分裂lossfunction整体都会增加的,有点预剪枝的意思,阈值参数为正则项里叶子节点数T的系数。
②当数达到最大深度时则停止建立决策树,设置一个超参数max_depth,树太深很容易出现过拟合。
③当样本权重和小于设定阈值时则停止建树,一个叶子节点样本太少时,终止,避免过拟合。
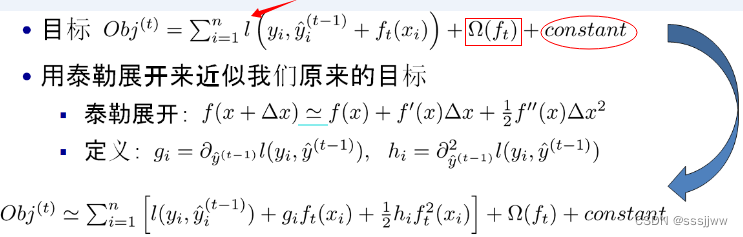
constant:常数,对于,XGboost利用泰勒展开三项,做一个近似,
表示其中一颗回归树。
XGBoost与GBDT有什么不同:
1、GBDT是机器学习算法,XGboost是该算法的工程实现
2、在使用CART作为及分类器时,XGboost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力
3、GBDT在模型训练时只是用来代价函数的一阶导数信息,XGboost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数
4、传统的GBDT采用CART作为基分类器,XGboost支持多种类型的基分类器,比如线性分类器
5、传统的GBDT在每轮迭代时使用全部的数据,XGboost则采用了与随机森林相似的策略,支持对数据进行采样
6、传统的GBDT没有设计对缺失值的处理,而XGboost能够自动学习出缺失值的处理策略。
使用xgboost库中的XGBRegressor类来创建XGboost模型
import xgboost as xgb
xgb_clf=xgb.XGBRegressor(max_depth=8,learning_rate=0.1,objective="reg:linear",eval_metric='rmse', n_estimators=3115,colsample_bytree=0.6, reg_alpha=3, reg_lambda=2, gamma=0.6,subsample=0.7, silent=1, n_jobs=-1)XGBRegressor中的参数介绍:
max_depth:树的最大深度,增加这个值可以使模型更加复杂,并提高队训练数据的拟合程度,但可能会导致过拟合。通常需要通过交叉验证来调整这个参数。
learning_rate:学习率,用于控制每次迭代更新权重时的步长。
objective:定义了学习任务和相应的损失函数,“reg:linear” 表示我们正在解决一个线性回归问题。
eval_metric:评估指标,用于在训练过程中对模型的表现进行评估,‘rmse’ 表示均方根误差(Root Mean Squared Error),它是回归问题中常用的性能指标。
n_estimators:森林中树的数量,值越大,模型越复杂,训练时间也会相应增加。通常需要通过交叉验证来调整这个参数。
colsample_bytree:构建每棵树时对特征进行采样的比例。较小的值可以减少过拟合,提高模型的泛化能力。
reg_alpha:L1正则化项的权重,增加这个值同样也可以增加模型的正则化强度。
gamma:树的叶子节点进一步分裂所需的最小损失减少量。较大值会导致模型更保守,可能会导致模型的过拟合。
subsample:用于训练每棵树的样本占整个训练集的比例。
silent:设置为1可以关闭在运行时的日志信息。
n_jobs:并行运行的作业数。
基本模型:
import pandas as pd
import xgboost as xgb
import pandas
import numpy as np# 将pandas数据框加载到DMatrix
data_train = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label_train = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data_train, label=label_train, missing=np.NaN) # 缺失值可以用构造函数中的默认值替换DMatrixdata_test = pandas.DataFrame(np.arange(12, 24).reshape((4,3)), columns=['a', 'b', 'c'])
label_test = pandas.DataFrame(np.random.randint(2, size=4))
dtest = xgb.DMatrix(data_test, label=label_test, missing=np.NaN) # 缺失值可以用构造函数中的默认值替换DMatrix# # 将CSV文件加载到DMatrix
# # label_column specifies the index of the column containing the true label
# dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
# dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# # XGBoost 中的解析器功能有限。当使用Python接口时,建议使用pandasread_csv或其他类似的实用程序而不是XGBoost的内置解析器。param = {'max_depth': 2, 'eta': 1, 'objective': 'binary:logistic'}
param['nthread'] = 4
param['eval_metric'] = ['auc', 'ams@0'] # 指定多个评估指标
# 指定验证集以观察性能
evallist = [(dtrain, 'train'), (dtest, 'eval')]# 训练
num_round = 20
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=10) # 返回最后一次迭代的模型,而不是最好的模型
# early_stopping_rounds=10作用:如果模型在10轮内没有改善,则训练将提前停止,如果设置多个指标,则最后一个指标将用于提前停止
# 训练完成后,保存模型
bst.save_model('test_xgboost/0001.model')
# 模型转储到文本文件中
bst.dump_model('test_xgboost/dump.raw.txt')
# 加载模型
bst = xgb.Booster({'nthread': 4}) # 初始化模型,将线程数设置为4
bst.load_model('test_xgboost/0001.model') # 加载模型
# 如果训练期间启动提前停止,可以从最佳迭代中获得预测
ypred = bst.predict(dtest, iteration_range=(0, bst.best_iteration + 1))
ypred = pd.DataFrame(ypred)
ypred.to_csv('test_xgboost/xgb_predict.csv', index=False)使用scikit-learn的方法
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_splitimport xgboost as xgbX, y = load_breast_cancer(return_X_y=True) # 加载数据
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=94)
# stratify=y:按目标变量分层划分,确保训练集和测试集中目标变量的比例与原始数据集相同
# random_state=94: 设置随机种子,保证每次划分的结果相同# 使用hist来构建树,并启用早期停止
early_stop = xgb.callback.EarlyStopping(rounds=2, metric_name='logloss', data_name='validation_0', save_best=True
)
clf = xgb.XGBClassifier(tree_method="hist", callbacks=[early_stop])
clf.fit(X_train, y_train, eval_set=[(X_test, y_test)])
# 保存模型
clf.save_model("test_xgboost/clf.json")https://xgboost.readthedocs.io/en/latest/python/index.html
XGBClassifier与XGBRegressor有什么区别:
目标函数:
XGBClassifier使用逻辑回归作为目标函数,用于分类任务;XGBRegressor使用平方误差 作为目标函数,用于回归任务。
评估指标:
XGBClassifier使用准确率和F1 分数 作为评估指标;XGBRegressor使用 均方误差 或 R2 分数 作为评估指标。
其他区别:
XGBClassifier支持多分类,而 XGBRegressor仅支持回归。XGBClassifier 可以使用 树 或 线性模型 作为基学习器,而 XGBRegressor 仅支持 树 作为基学习器。
相关文章:
XGboost的整理
XGboost(extreme gradient boosting):高效实现了GBDT算法并进行了算法和工程上的许多改进。 XGboost的思路: 目标:建立k个回归树,使得树群的预测尽量接近真实值(准确率)而且有尽量大的泛化能力…...

java入门基础学习导览
本篇文章会持续更新直到更新完毕,关注博主不迷路~(如果没有超链接,表示还没有更新到) 一 JAVA语言基础 二 流程控制 三 数组 字符串 与正则表达式 四 JAVA面向对象编程 五 JAVA 异常处理 六 JAVA输入输出 七 泛型与容器类 …...

网工内推 | 上市公司售前,大专以上即可,最高15K*13薪,补贴多
01 北京神州新桥科技有限公司 招聘岗位:售前工程师 职责描述: 1、完成项目的售前技术支持工作; 2、 配合销售进行新产品及解决方案的推广工作; 3、 配合销售完成用户的售前技术交流方案准备、现场技术交流、技术方案宣讲等工作…...
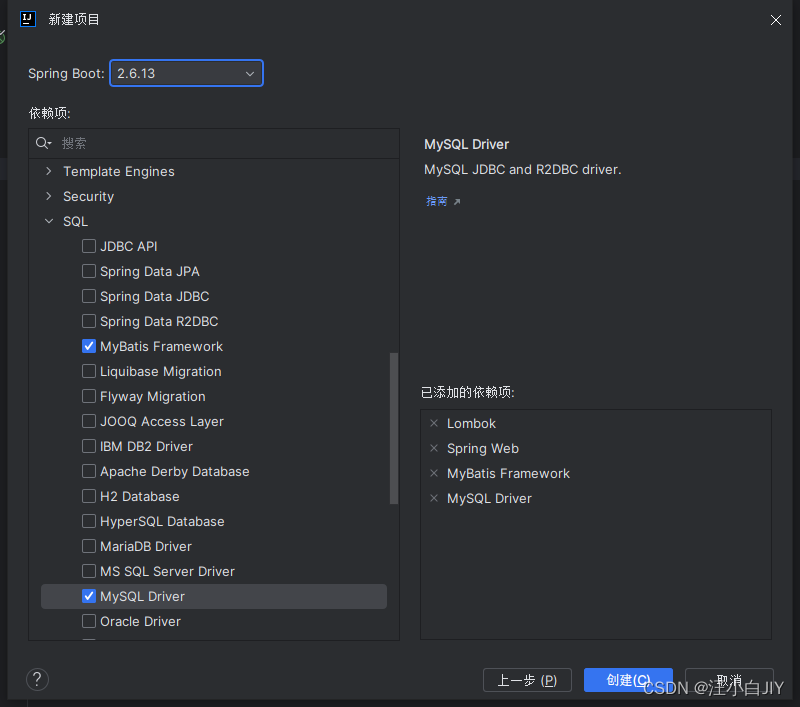
JAVA开发第一个Springboot WebApi项目
一、创建项目 1、用IDEA新建一个SpringBoot项目 注意JDK与Java版本的匹配,如果想选择jdk低版本,先要更改服务器URL:start.aliyun.com 2、添加依赖 (1)、Lombok (2)、Spring Web (3)、Mybatis Framework (4)、MySqlDriver 项目中的配置 pom.xml 如下 <?…...
基于springboot+vue的疫情管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

Qt 类的前置声明和头文件包含
1. 在头文件中引入另一个类经常有两种写法 1)前置声明 2)头文件包含 #ifndef FRMCOUPLE2_H #define FRMCOUPLE2_H#include <QWidget> //头文件包含namespace Ui { class frmcouple2; }//前置声明:QPushButton frmchkeyboard…...
Qt+FFmpeg+opengl从零制作视频播放器-1.项目介绍
1.简介 学习音视频开发,首先从做一款播放器开始是比较合理的,每一章节,我都会将源码贴在最后,此专栏你将学习到以下内容: 1)音视频的解封装、解码; 2)Qtopengl如何渲染视频&#…...

Learn OpenGL 01
OpenGL的定义 一般它被认为是一个API(Application Programming Interface, 应用程序编程接口),包含了一系列可以操作图形、图像的函数。然而,OpenGL本身并不是一个API,它仅仅是一个由Khronos组织制定并维护的规范(Specification)。 OpenGL规…...

Java开发从入门到精通(一):Java的基础语法进阶
Java大数据开发和安全开发 (一)Java注释符1.1 单行注释 //1.2 多行注释 /* */1.3 文档注释 /** */1.4 各种注释区别1.5 注释的特点1.5 注释的快捷键 (二)Java的字面量(三)Java的变量3.1 认识变量3.2 为什么…...
【C++从0到王者】第五十一站:B+树
文章目录 一、B树1.B树的概念2.B树的特性3.B树的插入的过程4.总结 二、B*树1. B*树的概念2.B*树的分裂 三、总结四、B树系列和哈希和平衡搜索树作对比五、B树的一些应用1.索引2.MySQL索引3.MyISAM2.InnoDB 一、B树 1.B树的概念 B树是B树的变形,是在B树基础上优化的…...
Spring Cloud 面试题及答案整理,最新面试题
Spring Cloud中断路器的原理及其作用是什么? Spring Cloud断路器的原理和作用基于以下几个关键点: 1、故障隔离机制: 在微服务架构中,断路器作为一种故障隔离机制,当某个服务实例出现问题时,断路器会“断…...

使用Kali搭建钓鱼网站教程
一、前言 使用kali工具一分钟制作出和目标网站一模一样的钓鱼网站。目标用户使用钓鱼网站登录自己的账号,账号密码将被自动劫持。 二、钓鱼网站的制作过程 1.在虚拟机VMvare中登录kali linux 2.准备一个目标网址 3.在kail中搜索使用工具 4.在弹出的选项中选择第一…...
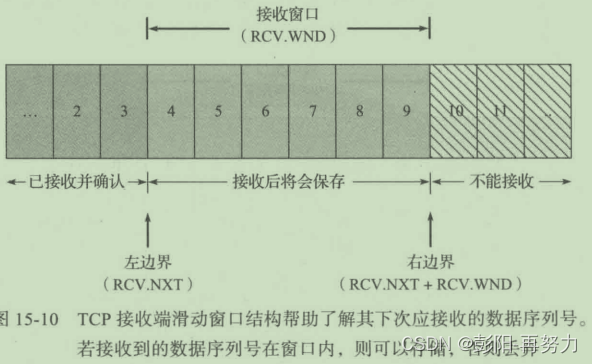
《TCP/IP详解 卷一》第15章 TCP数据流与窗口管理
目录 15.1 引言 15.2 交互式通信 15.3 延时确认 15.4 Nagle 算法 15.4.1 延时ACK与Nagle算法结合 15.4.2 禁用Nagle算法 15.5 流量控制与窗口管理 15.5.1 滑动窗口 15.5.2 零窗口与TCP持续计时器 15.5.3 糊涂窗口综合征 15.5.4 大容量缓存与自动调优 15.6 紧急机制…...

ContentType类型总结
ContentType类型总结 Content-Type是一个HTTP头部字段,用于指示资源的媒体类型(MIME类型),以及可选的字符集和编码方式。它告诉浏览器或其他客户端如何解释接收到的数据。以下是一些常见的Content-Type类型及其用途: t…...
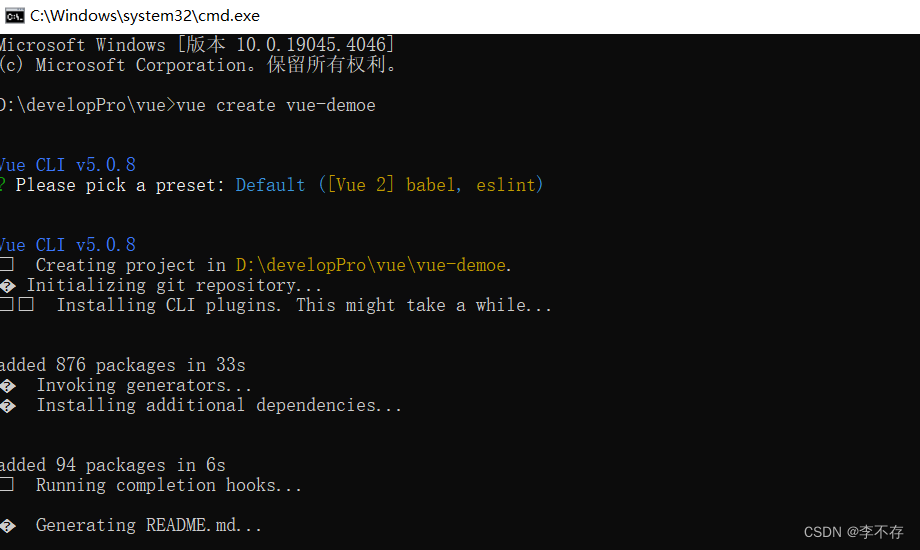
基于脚手架创建vue工程
环境要求: node.js:前端项目的运行环境 npm:javascript的包管理器 vue cli:项目脚手架 忘了自己有没有安装可以通过在黑窗口输入命令看一下 node -v npm -v 这里出现版本号就说明已经安装了 安装脚手架的命令:npm i vue/cli -g 创建vue基础工程 1.在一个没…...

【Http】OSI 和 TCP/IP,OSI,TCP/IP为什么网络要分层?
目录 OSI 和 TCP/IP OSI TCP/IP 为什么网络要分层? OSI 和 TCP/IP OSI 
STM32(5) GPIO(2)输出
1.点亮LED 1.1 推挽接法和开漏接法 要想点亮LED,有两种接法 推挽接法: 向寄存器写1,引脚输出高电平,LED点亮;向寄存器写0,引脚输出低电平,LED熄灭。 开漏接法: 向寄存器写0&…...
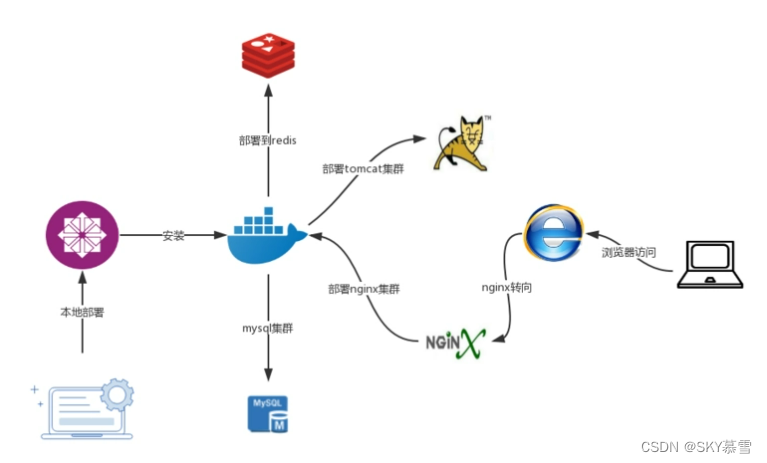
shell脚本一键部署docker
Docker介绍 Docker 是一个开源的平台,用于开发、交付和运行应用程序。它利用容器化技术,可以帮助开发人员更轻松地打包应用程序及其依赖项,并将其部署到任何环境中,无论是开发工作站、数据中心还是云中。以下是 Docker 的一些关键…...

vue2实现拖拽排序效果
1、首先下载 vuedraggable 插件 npm i -S vuedraggable2、使用方法 <template><div><div style"display: flex; justify-content: center; align-items: center"><div style"width: 120px; height: 60px; line-height: 60px; text-align…...

数据结构实验:二叉排序树
题目描述 对应给定的一个序列可以唯一确定一棵二叉排序树。然而,一棵给定的二叉排序树却可以由多种不同的序列得到。例如分别按照序列{3,1,4}和{3,4,1}插入初始为空的二叉排序树,都得到一样的结果。你的任务书对于输入的各种序列,判断它们是否…...

英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率
英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟排位赛中因为BP阶段手忙脚乱而错失先机?是否因为不了…...

自制AVR ISP批量编程器:从ZIF插座到AVRDUDE一键烧录全攻略
1. 项目概述:为什么你需要一个批量编程器?如果你玩过Arduino或者自己做过一些基于AVR单片机的小项目,那么对“烧录程序”这个步骤一定不陌生。通常,我们是用一根USB线,或者一个USBasp、USBtinyISP这样的小编程器&#…...

书成紫微动律定凤凰驯:抛开网络臆想歪论正视海棠山铁哥的大道凰标之道
——褪去网络流言,正视正统文脉网络世间众说纷纭,流言四起,诸多无根揣测、片面臆想肆意流传。 不少人未曾静心品读深意,仅凭只言片语便妄加评判,或是跟风曲解本意,或是刻意附会杂论,更有甚者凭空…...

基于Git与Zenn的内容管理方案:打造高效技术写作工作流
1. 项目概述:一个内容创作者的知识管理中枢 最近在技术社区里,看到不少朋友在讨论如何高效地管理自己的技术笔记、博客草稿和项目文档。我自己也在这个问题上摸索了很久,直到我遇到了一个名为 seiryuu1215/zenn-content 的GitHub仓库。这不…...

语音克隆从入门到商用变现,手把手教你在TikTok/播客/AI助手部署高保真克隆声,今天就能上线
更多请点击: https://kaifayun.com 第一章:语音克隆技术演进与ElevenLabs核心能力解析 语音克隆技术已从早期基于拼接的单元选择(Unit Selection)和统计参数合成(HMM-based TTS),跨越深度学习驱…...

机器人全身控制与SLAM系统核心技术解析
1. 机器人全身控制技术解析Sprout机器人采用的全身控制策略(Whole-Body Policy)通过分层控制架构实现了稳定运动与精准操作的平衡。该系统将控制分为三个主要层级:骨盆姿态控制、上肢柔顺控制和高度调节。这种分层设计使得机器人能够在保持上…...

Apex Legends压枪宏终极指南:轻松掌握自动武器检测与后坐力补偿技术
Apex Legends压枪宏终极指南:轻松掌握自动武器检测与后坐力补偿技术 【免费下载链接】Apex-NoRecoil-2021 Scripts to reduce recoil for Apex Legends. (auto weapon detection, support multiple resolutions) 项目地址: https://gitcode.com/gh_mirrors/ap/Ape…...

Netscape 浏览器:互联网时代的先驱者
Netscape 浏览器:互联网时代的先驱者 引言 自互联网诞生以来,浏览器作为连接用户与网络世界的重要工具,见证了互联网的飞速发展。在众多浏览器中,Netscape 浏览器以其创新和引领潮流的特性,成为了互联网时代的先驱者。本文将回顾 Netscape 浏览器的发展历程、技术特点及…...

基于OpenClaw与Railway的自动化部署实践:从原理到实战
1. 项目概述:一个基于OpenClaw的铁路系统自动化工具最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Mattslayga/openclaw-railway。光看这个名字,可能有点摸不着头脑,又是“OpenClaw”又是“Railway”的。简单来说&am…...

数字图像处理入门:像素、通道与卷积操作的核心原理与实践
1. 项目概述:为什么“基本知识”是数字图像处理的基石刚入行做图像处理那会儿,我犯过一个典型的“新手错误”:拿到一张图,二话不说就开始调OpenCV的函数,什么高斯模糊、边缘检测、二值化,一顿操作猛如虎&am…...