大模型时代企业知识全生命周期管理解决方案

©作者|Zhongmei
来源|神州问学
摘 要
越来越多的企业开始意识到数据的重要性。同时意识到,企业想保持长远的发展,还需要协调组织协作、利用现有的数据沉淀经验知识、累积数据资产。据IDC调查,目前企业结构化数据仅占到全部数据量的20%,其余80%都是以文件形式存在的非结构化和半结构化数据,这些非结构化数据每年增长率达60%。如何有效地管理和利用这些非结构化数据,成为了许多企业和组织面临的重要挑战。本文将对此展开解决方案的讨论。
结构化数据 VS 非结构化数据
大多数人所熟知的二维表格或SQL型数据库就是典型的结构化数据,因为它们有明确的、预定义的数据模型,是遵循一致顺序的数据。结构化数据有三大特征:
1)有明确的含义:数据所代表的含义是确定且已知的。比如公司的员工信息表中,第一列是id,代表员工编号。第二列是name,代表员工姓名。第五列是position,代表员工职位等等。每一列的列名明确告知了我们该列数据代表什么含义。
2)有严格、一致的顺序:结构化数据中,数据顺序是固定的。比如上面提到的员工信息表,数据顺序一定是:员工编号、姓名、性别、年纪、职位等等。每一行的顺序都是一样的。
3)有明确的数据类型:结构化数据中具有同一定义的数据符合相同的数据类型。同样用员工信息表举例,年龄这一列,数据类型一致采用整数,而不会有的用整数“20”,有的用小数“20.0”,有的用汉字“二十”,这种情况是不被允许的。
非结构化数据,相较于记录了生产、业务、交易和客户信息等的结构化数据,非结构化的信息涵盖了更为广泛的内容。它是无固定格式或规则存储的数据,没有固定的字段或标签,不易被计算机程序解析和处理。简单来说就是字段可变的数据,常见的非结构化数据包含各种办公文档、图片、视频、音频、设计文档、日志文件、机器数据等。但是,非结构化数据通常包含着大量的信息和价值,因此被越来越多的企业和组织所关注。半结构化数据为介于结构化数据与非结构化数据之间的数据,常见的半结构化数据有HTML(超文本标记语言)、XML(可扩展标记语言),广义上二者也可以认为是非结构化数据。
企业非结构化数据的痛点现状
非结构化数据具有某种特定和持续的价值,这种价值在共享、检索、分析等使用过程中得到放大,沉淀为企业知识。但上文提到的非结构化数据的特点,造成了企业管理和利用这些非结构化数据的痛点。我称之为“四失”,失存、失真、失控和失用。

1. 失存
一方面,由于企业日常经营管理和业务管理的需要,建立了功能各异的应用系统或信息化管理平台,用以支撑企业的各类管理工作。这些管理系统和平台在业务的各个环节,每天都在大量产生形式多样的非结构化文档数据,增速越来越快,体量不断增加,汇聚成海量的企业非结构化数据。数据量大、长期保存难。并且,传统的非结构化数据管理,内容对象、元数据与索引是分离存储和独立管理,难以同时灵活横向扩展,加剧海量非结构化数据的管理复杂性。
另一方面,多数企业中文档生命周期流程,即从文档生成、流转、办结到归档、保存、利用的全过程,并没有非常清晰和规范的管理流程和要求,就导致存在过多的“账外”非结构化文档数据。比如,集团制订的归档范围未将一些应归档但无法通过系统流转的文档纳入其中,部门相当一部分非结构化文档数据仍保存在个人电脑之中,导致企业文档数据资产存在着流失的风险。
2. 失真
非结构化数据往往都质量不高,必须进行数据清理才能进行组织。对于公司来说,清理和准备大量数据过程中就会看到很多失真现象。举个例子:企业业务活动中很多系统都存在着很多简称、全称以及英文名称并行使用的情况。这代表着很多不同的数据标签对应着同一事物、代表相同意义的数据使用着不同标签。再例如,如果文档管理没有设有版本支持,当使用口径不统一,相同文件会分散在不同的业务系统中,无版本控制的情况下无法确定系统中版本是否为最新,也容易造成数据失真
3. 失控
一方面,非结构化数据格式繁多。根据不同的办公场景、业务需求,非结构化数据以多种文件格式体现出来, 如Word、Excel、PPT、PDF、TXT、JPEG、MP3、MP4、压缩文件、CAD图纸等。有的散落在企业员工电脑上、硬盘里,有的存放在各业务系统中,格式和存储载体不受控制。
另一方面,,由于信息系统建设具有阶段性特征,已有的信息系统建设之初仅以单个的业务需求为目标,彼此孤立,存在着比较严重的孤岛现象。系统之间缺少横向的数据接口,且数据标准不统一,导致数据无法统一管理控制。
4. 失用
一方面,在企业业务快速发展中,面临大量信息和数据不断涌现的情况下,如何在海量数据中建立筛选机制,保证信息的准确、及时,是业界公认的难题。比如企业一些信息系统(如OA系统、ERP系统等)中文档多以表单(如办文单)的形式进行流转,需要办理的文档通常作为表单的附件,传统做法中借助表单信息或者简单的文件标题等元数据加以检索的做法是低效的,导致数据开发利用不足。
另一方面,业务涉及的数据繁杂,来源广泛,整理起来困难重重,耗时耗力。目前多数企业的数字化服务能力仍有所不足,缺乏知识数据的自动流转能力,就造成效率低,人力投入成本高。即使收集数据完成,由于非结构化数据,通常包含着丰富的信息和复杂的关联性,基于常规单一算法技术很难有效识别、表达及获取其中的隐性知识,精准描述关键信息难度大。
大模型时代企业知识管理解决方案

知识的全生命周期管理,就涉及知识提取、存储、流转、利用的全过程。在大模型时代,LLM可以类似一个人的大脑,去辅助知识的存储,理解和创造,可以解锁知识管理的新范式。
第一层是数据的整合关联。这一层中,一方面,针对企业中的不同系统,要整合不同终端数据,打破数据孤岛,对数据进行统一存储管理,实现数据的多源融合。另一方面,对于系统外不同存储格式的散落文件,为具备良好的数据处理质量,针对不同格式的文档(如Word、Excel、PPT、PDF、MP4等)都要有定制的算子,保证数据解析的精度与完整度。
第二层是知识的高效提取和存储。非结构化数据的提取和存储常见有两种,一种从中知识萃取存储进SQL或者知识图谱这种高度结构化的数据形式,这其中涉及很多的NLP算法,比如信息抽取,实体链接,知识融合等。另一种则是,经过切片和向量化嵌入(embedding),将文本或图片转化为向量存储进向量数据库。这其中会涉及文本NLP技术和图像视频处理的CV技术。这两种方式的相同点在于数据定义标准、数据架构易延展;且便于检索和查询。两者在实际应用上互相补充,为企业知识管理打下地基。
第三层是结合业务的知识验证。知识要以赋能业务为主要目标,所以知识的构建效果和后续检索使用效果都需要以业务视角进行验证。因此,需要以业务自动化和智能化为目标,面向业务应用需求,以场景为立足点,搭建指标体系,并不断迭代丰富,不断更新;确保知识质量可以支撑需求,保障知识能带来业务价值。
第四层是利用LLM智能体自动化知识利用。以大语言模型(LLM)为中心的智能体的行动框架,完美贴合T(Think)-P(Plan)-A(Action),TPA交付方法论,数据分析洞察每一个流程交由一个专家智能体就能解锁人机交互新范式,实现自动化。比如数据收集部分可以交由智能检索RAG Agent,关于检索效果提升,感兴趣可以查看我们之前的文章读懂RAG这一篇就够了,万字详述RAG的5步流程和12个优化策略, 知识图谱查询 KG Cypher Agent 以及 SQL Agent协同合作收集到数据分析所需的全部数据。而数据分析部分则可以由Data Cleansing Agent, Data Exploratory Agent, Feature Selecting Agent, Modelling Agent, Model Evaluation Agent以及 Model Selecting Agent等多智能体协作完成。洞察报告则有Insight Agent和Report Writing Agent共同协作完成。这样就可以将人力解放出来的前提下,实现辅助人类的客观分析决策、诊断洞察以及关联推荐等等功能。
第五层是运营和管理提效。数字化时代离不开的就是运维,需要保证的就是管理和运营的成本、效率和稳定性。所以一方面,进行风险控制,要对权限规划、角色职责设定、知识流转知悉范围、文档命名规范以及系统使用终端要求等等制定严谨丰富的管理规则。另一方面,运维服务工具的开发,能够减少人工操作和错误,节约人力和时间成本,提高运维团队的工作效率。同时,基于SQL&知识图谱的高度结构化数据库和向量数据库,实现的统一且易拓展的数据架构,大幅度降低更新成本。
尾语
大语言模型(LLM)的出现大幅度降低了非结构化数据的使用门槛,有助于释放海量非结构化数据中隐含的知识,赋能企业业务。所以本文提出,非结构化数据多源融合- 数据结构化&向量化 - 基于业务场景的指标体系搭建 - 数据智能体群体协作 - 知识运营&知识管理,大模型时代企业知识全生命周期高效管理五层架构。大语言模型在其中多层中作为中枢和主力军,辅佐人类,协助企业数智化。
相关文章:
大模型时代企业知识全生命周期管理解决方案
©作者|Zhongmei 来源|神州问学 摘 要 越来越多的企业开始意识到数据的重要性。同时意识到,企业想保持长远的发展,还需要协调组织协作、利用现有的数据沉淀经验知识、累积数据资产。据IDC调查,目前企业结构化数据仅占到全部数据量的20%…...
C#冒泡排序算法
冒泡排序实现原理 冒泡排序是一种简单的排序算法,其原理如下: 从待排序的数组的第一个元素开始,依次比较相邻的两个元素。 如果前面的元素大于后面的元素(升序排序),则交换这两个元素的位置,使…...

【前端寻宝之路】总结学习使用CSS的引入方式
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|MySQL| 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-BNJBIEvpN0GHNeJ1 {font-family:"trebuchet ms",verdana,arial,sans-serif;f…...

Python中输入输出函数input和print用法
# 读入一个字符串 s input() print(s)abcdef abcdef# 读入一个整数 n int(input()) print(n)5 5# 读入两个整数(空格间隔) # input()表示读入一行字符串 # split()表示以空格间隔切分出多个字符串序列,如果逗号间隔可以加参数split(,) # map()将序列每个元素转为整…...

简单认识Linux
今天带大家简单认识一下Linux,它和我们日常用的Windows有什么不同呢? Linux介绍 Linux内核&发行版 Linux内核版本 内核(kernel)是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,它提供了一个在裸设备与…...

javascript正则深入
文章目录 一、前言二、高级`API`2.1、模式匹配的用法`(x)`2.2、非捕获括号的模式匹配`(?:x)`2.3、先行断言`x(?=y)`2.4、后行断言`(?<=y)x`2.5、正向否定查找`x(?!y)`2.6、反向否定查找`(?<!y)x`2.7、字符集合和反向字符集合的用法 `[xyz] / [^xyz]`2.8、词边界和非…...

React-封装自定义Hook
1.声明函数 说明:声明一个以use打头的函数 function useToggle(){} 2.封装 说明:在函数体内封装可复用的逻辑 const [value,setValue]useState(true)const toggle()>{setValue(!value)} 3.返回 说明:把组件中用到的状态或者回调retu…...

Spark实战-基于Spark日志清洗与数据统计以及Zeppelin使用
Saprk-日志实战 一、用户行为日志 1.概念 用户每次访问网站时所有的行为日志(访问、浏览、搜索、点击)用户行为轨迹,流量日志2.原因 分析日志:网站页面访问量网站的粘性推荐3.生产渠道 (1)Nginx(2)Ajax4.日志内容 日志数据内容:1.访问的…...
Springboot中Redis的配置使用
新建 向pom.xml中添加依赖,这个可以不用标注版本号 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 配置yml文件(文件名不可以错…...
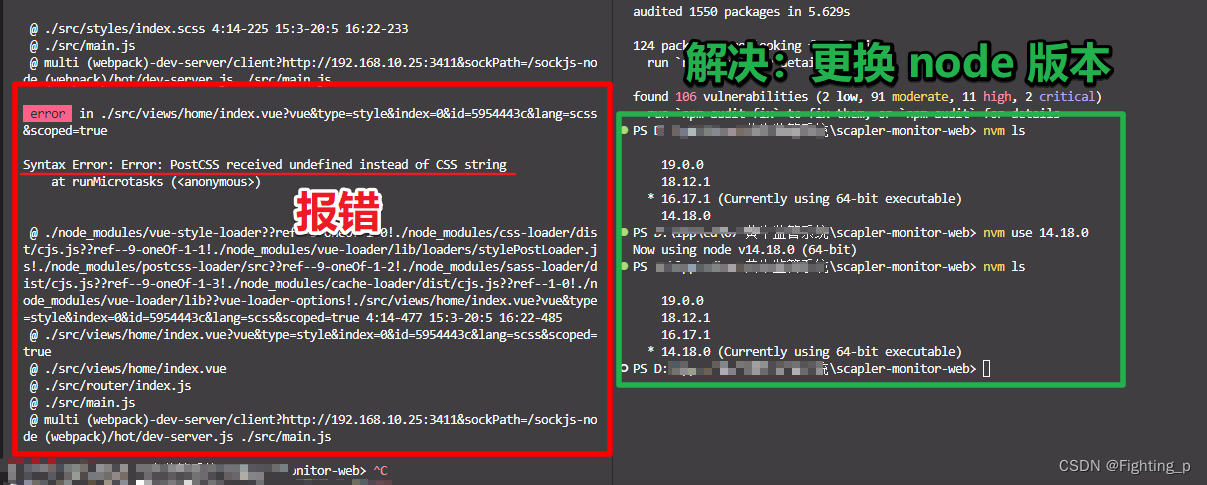
【node版本问题】运行项目报错 PostCSS received undefined instead of CSS string
最近该项目没有做任何修改,今天运行突然跑不起来报错了 PostCSS received undefined instead of CSS string 【原因】突然想起来期间有换过 node 版本为 16.17.1 【解决】将 node 版本换回之前的 14.18.0 就可以了...

Spring揭秘:BeanDefinitionRegistry应用场景及实现原理!
内容概要 BeanDefinitionRegistry接口提供了灵活且强大的Bean定义管理能力,通过该接口,开发者可以动态地注册、检索和移除Bean定义,使得Spring容器在应对复杂应用场景时更加游刃有余,增强了Spring容器的可扩展性和动态性…...
蓝桥杯(3.5)
789. 数的范围 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int n sc.nextInt();int q sc.nextInt();int[] res new int[n];for(int i0;i<n;i)res[i] sc.nextInt();while(q-- ! 0) {int…...
434G数据失窃!亚信安全发布《勒索家族和勒索事件监控报告》
最新态势快速感知 最新一周全球共监测到勒索事件90起,与上周相比数量有所增加。 lockbit3.0仍然是影响最严重的勒索家族;alphv和cactus恶意家族也是两个活动频繁的恶意家族,需要注意防范。 Change Healthcare - Optum - UnitedHealth遭受了…...
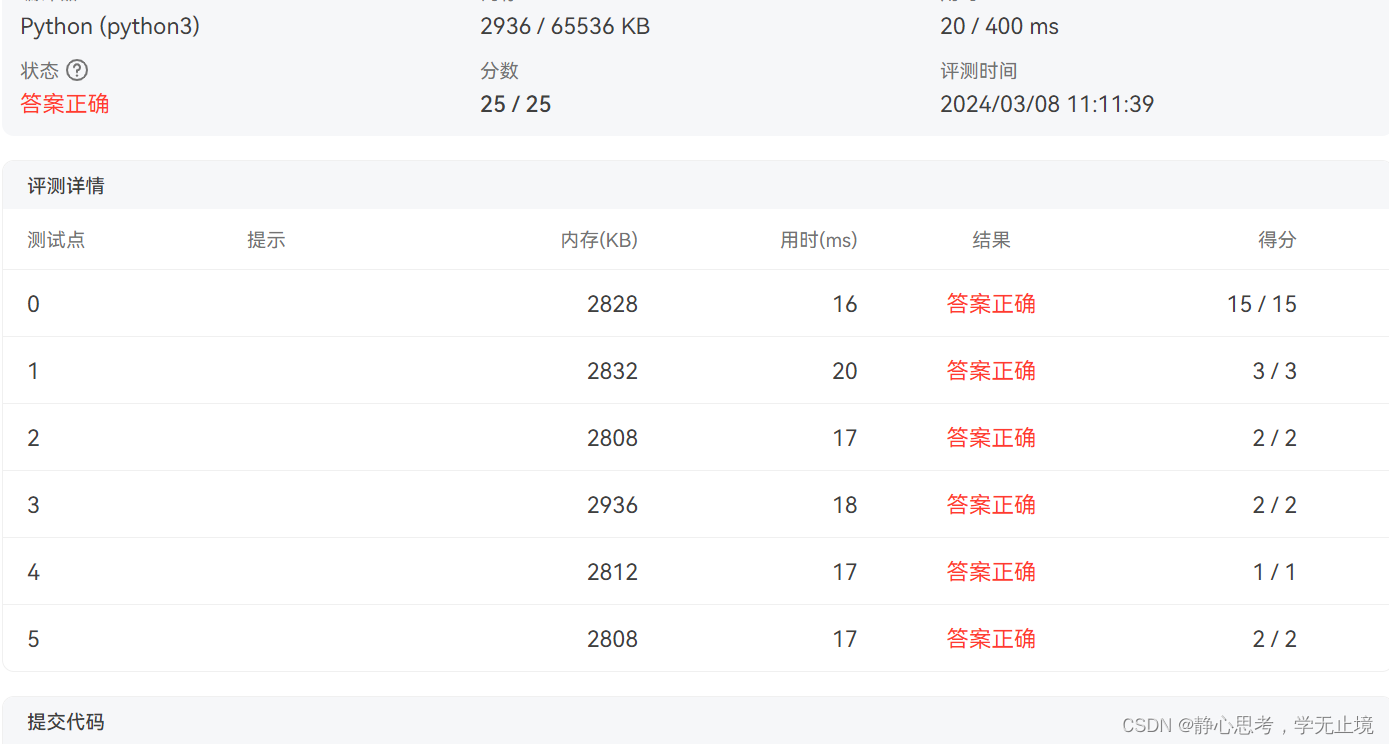
7-18 彩虹瓶(Python)
彩虹瓶的制作过程(并不)是这样的:先把一大批空瓶铺放在装填场地上,然后按照一定的顺序将每种颜色的小球均匀撒到这批瓶子里。 假设彩虹瓶里要按顺序装 N 种颜色的小球(不妨将顺序就编号为 1 到 N)。现在工…...
php使用ElasticSearch
ElasticSearch简介 Elasticsearch 是一个分布式的、开源的搜索分析引擎,支持各种数据类型,包括文本、数字、地理、结构化、非结构化。 Lucene与ElasticSearch Apache Lucene是一款高性能的、可扩展的信息检索(IR)工具库…...
wpf prism左侧抽屉式菜单
1.首先引入包MaterialDesignColors和MaterialDesignThemes 2.主页面布局 左侧菜单显示在窗体外,点击左上角菜单图标通过简单的动画呈现出来 3.左侧窗体外菜单 <Grid x:Name"GridMenu" Width"150" HorizontalAlignment"Left" Ma…...

揭秘AI新纪元:近期人工智能发展的惊人突破与未来展望
近年来,人工智能(AI)领域的发展可谓是日新月异,其强大的潜力和广阔的应用前景引发了全球范围内的关注。本文将带您领略近期AI发展的风采,一探这个神奇领域的未来展望。 首先,让我们回顾一下近期AI领域的几…...

C语言基础练习——Day01
目录 选择题 编程题 打印从1到最大的n位数 计算日期到天数转换 选择题 1、执行下面程序,正确的输出是 int x5,y7; void swap(int x, int y) {int z;zx;xy;yz; } int main() { int x3,y8; swap(int x, int y);printf("%d,%d\n",x, y);return …...

用云手机进行舆情监测有什么作用?
在信息爆炸的时代,舆情监测成为企业和政府决策的重要工具。通过结合云手机技术,舆情监测系统在品牌形象维护、市场竞争、产品研发、政府管理以及市场营销等方面发挥着关键作用,为用户提供更智能、高效的舆情解决方案。 1. 品牌形象维护与危机…...

神经网络(neural network)
在这一章中我们将进入深度学习算法,学习一些神经网络相关的知识,这些是有更加强大的作用,更加广泛的用途。 神经元和大脑(neurons and the brain): 我们对于我们的编程的进步主要来自我们对于大脑的研究,根据我们对于大脑的研究…...

OpenSees数值模拟从入门到进阶:理论、代码与实践
OpenSees数值模拟从入门到进阶:理论、代码与实践 摘要 OpenSees(Open System for Earthquake Engineering Simulation)作为开源的地震工程模拟系统,凭借其强大的非线性分析能力和开放的架构,已成为结构地震响应分析领域的重要工具。本文系统介绍OpenSees数值模拟的基本原…...

AppSpider 7.5.025 for Windows - Web 应用程序安全测试
AppSpider 7.5.025 for Windows - Web 应用程序安全测试 Rapid7 Dynamic Application Security Testing (DAST) released March 31, 2026 请访问原文链接:https://sysin.org/blog/appspider/ 查看最新版。原创作品,转载请保留出处。 作者主页…...

m4s-converter:释放B站缓存价值的格式转换利器
m4s-converter:释放B站缓存价值的格式转换利器 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 价值对比:格式转换前后的效…...

cv_resnet101_face-detection_cvpr22papermogface保姆级教程:GPU显存占用监控与自动释放策略
cv_resnet101_face-detection_cvpr22papermogface保姆级教程:GPU显存占用监控与自动释放策略 1. 引言 如果你正在使用基于ResNet101的MogFace人脸检测模型,可能会遇到一个常见问题:GPU显存占用越来越高,最终导致程序崩溃。尤其是…...

Flutter鸿蒙开发环境:从零到一,手把手解决环境配置与编译难题
1. 环境准备:搭建Flutter鸿蒙开发的基石 第一次接触Flutter鸿蒙开发时,环境配置就像盖房子的地基,看似简单却最容易踩坑。我在Windows系统上反复折腾了三天才搞定所有环境,这里把血泪经验总结成保姆级教程。首先需要明确的是&…...

告别创作瓶颈:像素剧本圣殿应用指南,打造你的专属剧本工作站
告别创作瓶颈:像素剧本圣殿应用指南,打造你的专属剧本工作站 1. 像素剧本圣殿简介 像素剧本圣殿是一款基于Qwen2.5-14B-Instruct深度微调的专业剧本创作工具。它将AI推理能力与8-Bit复古美学完美融合,为创作者提供沉浸式的剧本开发体验。 …...

从3天到30分钟:OpCore-Simplify如何重构黑苹果配置的技术民主化之路
从3天到30分钟:OpCore-Simplify如何重构黑苹果配置的技术民主化之路 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在黑苹果技术领域&…...

终极指南:快速掌握OpenNI2深度相机开发框架
终极指南:快速掌握OpenNI2深度相机开发框架 【免费下载链接】OpenNI2 项目地址: https://gitcode.com/gh_mirrors/op/OpenNI2 OpenNI2是一个功能强大的开源跨平台框架,专门用于深度相机和传感器设备的驱动开发与应用程序构建。这个完整的自然交互…...

用Python+Pandas搞定校园单车数据清洗:从‘200+’到精准分布表的保姆级教程
用PythonPandas搞定校园单车数据清洗:从‘200’到精准分布表的保姆级教程 校园单车数据清洗是数据分析实战中的经典场景。想象一下这样的情境:你拿到一份包含15个停车点、7个时间段的校园单车统计表,却发现数据里混杂着"200"这样的…...

电商客服外包怎么选|避坑指南[特殊字符]2026 商家必看
做电商绕不开客服外包,但低价陷阱、转包兼职、大促掉链、响应超时、售后甩锅真的太坑了!今天整理一套不踩雷选型攻略,全是行业干货,新手也能直接抄作业👇 🚫先避坑:这些雷区千万别碰 超低价诱惑…...