Hive总结
文章目录
- 一、Hive基本概念
- 二、Hive数据类型
- 三、DDL,DML,DQL
- 1 DDL操作
- 2 DML操作
- 3 DQL操作
- 四、分区操作和分桶操作
- 1、分区操作
- 2、分桶操作
- 五、Hive函数
- 六、文件格式和压缩格式
一、Hive基本概念
Hive是什么?
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
Hive的本质
Hive的本质是将HQL转化成MR程序。存储在HDFS上,计算使用MR引擎,运行在yarn上。
Hive架构原理
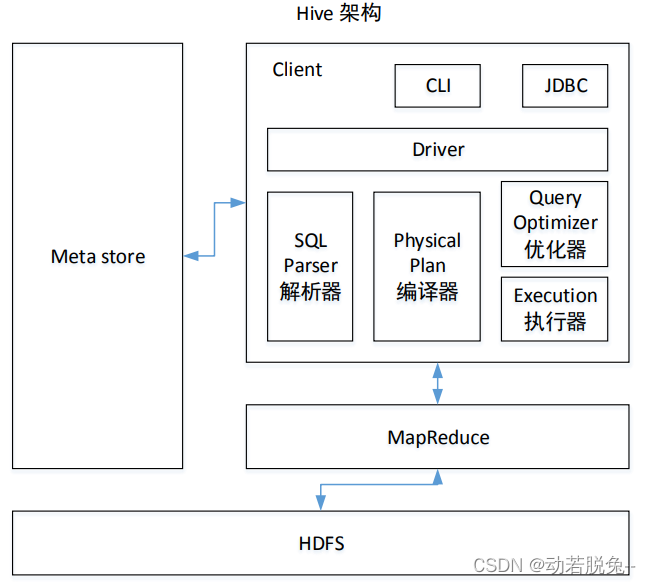 1)用户接口:Client
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、
表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3)驱动器:Driver
1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
⒉遍历AST,抽象出查询的基本组成单元QueryBlock (查询块),可以理解为最小的查询执行单元;
3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5.遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6.使用物理优化器对TaskTree进行物理优化:
7.生成最终的执行计划,提交任务到Hadoop集群运行。
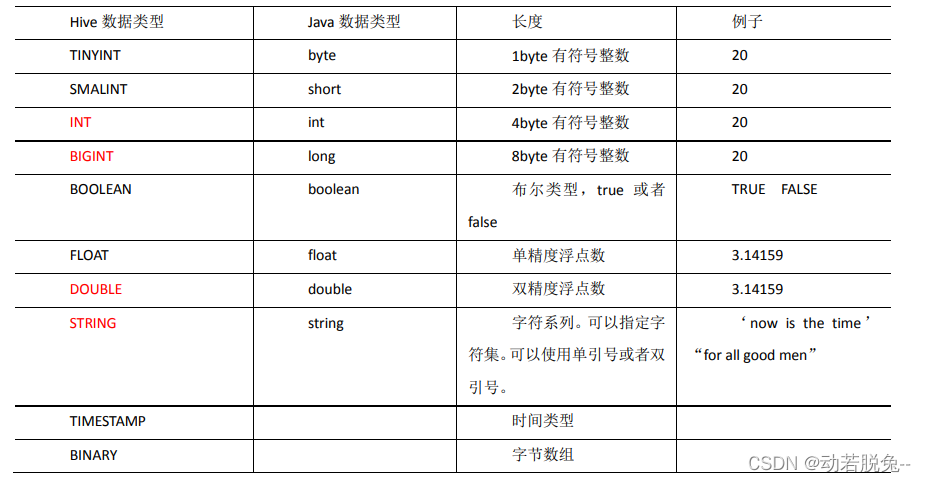
二、Hive数据类型
-
基本数据类型
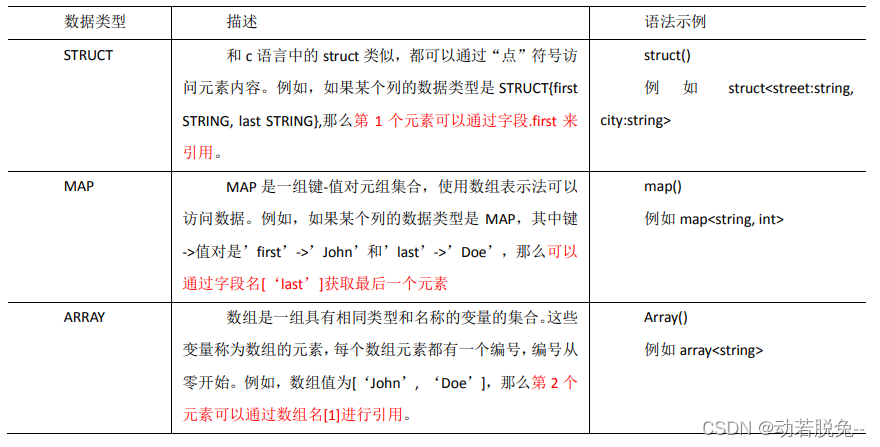
-
集合数据类型
-
类型转换
Hive默认会进行隐式类型转换
隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成INT,INT 可以转换成 BIGINT。
(2)所有整数类型、FLOAT 和 STRING 类型都可以隐式地转换成 DOUBLE。
(3)TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
(4)BOOLEAN 类型不可以转换为任何其它的类型。
三、DDL,DML,DQL
1 DDL操作
- 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)]; - 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]
2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
用户可以用 IF NOT EXISTS 选项来忽略这个异常。
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实
际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外
部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT DELIMITED [FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
row format delimited fields terminated by ‘,’ – 列分隔符
lines terminated by ‘\n’; – 行分隔符
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW
FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
(8)STORED AS 指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列
式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED
AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE 允许用户复制现有的表结构,但是不复制数据。
2 DML操作
- 向表中装载数据
hive> load data [local] inpath '数据的 path' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
具体数据导入导出操作命令参考:
http://t.csdn.cn/CBsYE
3 DQL操作
hiveSql执行顺序
from ..on .. join .. where .. group by .. having .. select .. distinct .. order by .. limit
hiveSQL书写规则
-
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT number]
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。 -
排序
-
Order By:全局排序,只有一个 Reduce
-
每个 Reduce 内部排序(Sort By)
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排
序,此时可以使用 sort by。
Sort by 为每个 reducer 产生一个排序文件。每个 Reducer 内部进行排序,对全局结果集
来说不是排序。 -
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by 类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。
对于 distribute by 进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by 的效果。 -
cluster by
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序
排序,不能指定排序规则为 ASC 或者 DESC。
四、分区操作和分桶操作
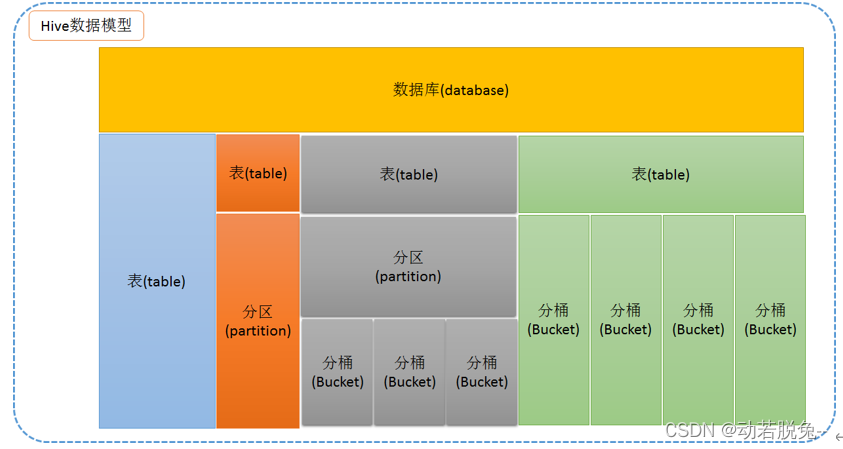
1、分区操作
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (day string)
row format delimited fields terminated by '\t';
注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列,注意:分区表加载数据时,必须指定分区
2、分桶操作
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
创建分桶表
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';注意:
(1)reduce 的个数设置为-1,让 Job 自行决定需要用多少个 reduce 或者将 reduce 的个数设置为大于等于分桶表的桶数
(2)从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题
(3)不要使用本地模式
五、Hive函数
hive窗口函数整理参考如下链接
http://t.csdn.cn/xbPnv
六、文件格式和压缩格式
文件格式
文件格式按面向的存储形式不同,分为面向行和面向列两大类文件格式。
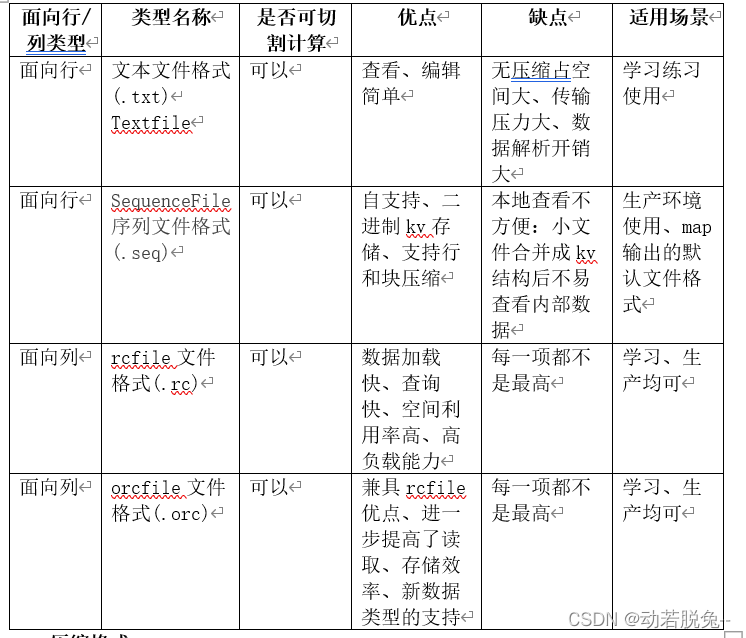 压缩格式按其可切分独立性,分成可切分和不可切分两种。
压缩格式按其可切分独立性,分成可切分和不可切分两种。

相关文章:
Hive总结
文章目录一、Hive基本概念二、Hive数据类型三、DDL,DML,DQL1 DDL操作2 DML操作3 DQL操作四、分区操作和分桶操作1、分区操作2、分桶操作五、Hive函数六、文件格式和压缩格式一、Hive基本概念 Hive是什么? Hive:由 Facebook 开源用于解决海量结构化日志的…...

docker环境下安装jenkins
前言 差点被Jenkins的插件搞麻了,又是依赖不对又是版本需要升级的,差点破口大骂了,还好忍住了,静下心来慢慢搞,终于搞通了。这里必须记录一下。 废话不多说,上来就是干,jenkins是干嘛用的&…...

Shifu基础功能:设备接入
如何修改设备接入的配置 1. 编辑edgedevice.yaml文件 接入设备前,您需要对edgedevice.yaml文件进行编辑。对于不同的协议,protocolSettings可根据协议进行进一步配置,详细配置请前往Shifu API参考。 ... connection: Ethernet address: …...
基于Java+SpringBoot+Vue+Redis+RabbitMq的鲜花商城
基于JavaSpringBootVueRedisRabbitMq的鲜花商城 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、…...
蓝桥杯真题(解码)小白入!
本来看这个题感觉很简单,不就是Ascall值换来换去嘛,其实也真的这样,但是对于小白来说,ascall根本记不住 题目说了,每个数不会重复超过9次(这见到那多了,不然根本不会写) 其次如何实现…...

并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别?
第20讲 | 并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别? 在上一讲中,我分析了 Java 并发包中的部分内容,今天我来介绍一下线程安全队列。Java 标准库提供了非常多的线程安全队列,很容易混淆。 今天我要问你的…...
分享四个前端Web3D动画库在Threejs中使用的动画库以及优缺点附地址
Threejs中可以使用以下几种动画库:Tween.js:Tween.js是一个简单的缓动库,可以用于在three.js中创建简单的动画效果。它可以控制数值、颜色、矢量等数据类型,并提供了多种缓动函数,例如线性、弹簧、强化、缓冲等等。区别…...

谷歌浏览器和火狐浏览器永久禁用缓存【一劳永逸的解决方式】
目录 前言 谷歌浏览器 方式一 方式二 火狐浏览器 前言 缓存对于开发人员来说异常的痛苦,很多莫名其妙的bug就是由缓存导致的,但当我们在网上查找禁用缓存的方式时,找到的方式大多数都是在开发者工具的面板中勾选禁用缓存的选项,但这种方式有个弊端就是需要一直打开这个…...

kibana查看日志
一、背景 kibana收集日志功能很强大,之前只是简单的使用,此次系统学习了解并分享一波 二、kibana查看日志的基本使用 1.选择查询的服务和日志文件 注意:每个应用配置了开发与生产环境,需要找到指定的应用 1.1选择对应的应用 1.…...
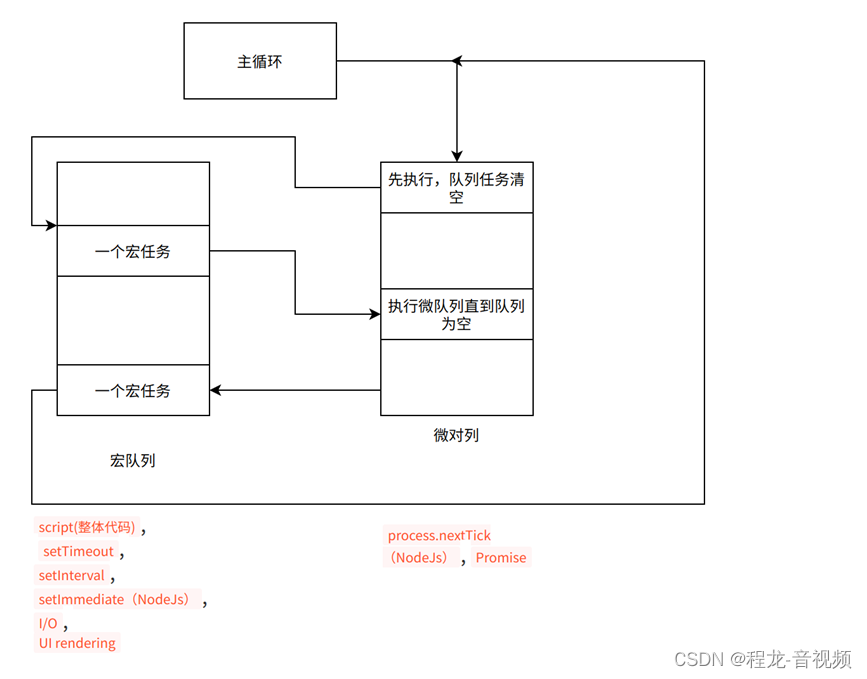
JS 异步接口调用介绍
JS 异步接口调用介绍 Js 单线程模型 JavaScript 语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。这样设计的方案主要源于其语言特性,因为 JavaScript 是浏览器脚本语言,它可以操纵 DOM ,可以渲染动画&a…...
5.深入理解HttpSecurity的设计
深入理解HttpSecurity的设计 一、HttpSecurity的应用 在前章节的介绍中我们讲解了基于配置文件的使用方式,也就是如下的使用。 也就是在配置文件中通过 security:http 等标签来定义了认证需要的相关信息,但是在SpringBoot项目中,我们慢慢脱离…...
)
opencv-python numpy常见的api接口汇总(持续更新)
前言 最近写代码总是提笔忘api,因为图像处理代码写的比较多,所以想着把一些常用的opencv的api,包括numpy的api做一个记录,后面再忘记的时候,就不用去google挨个搜索了,只需要在自己的博客中一查就全知道了…...
)
概率论小课堂:伯努利实验(正确理解随机性,理解现实概率和理想概率的偏差)
文章目录 引言I 伯努利试验1.1 伯努利分布(二项式分布)1.2 数学期望值(简称期望值)1.3 平方差(简称方差)1.4 标准差1.5 小结引言 假设买彩票中奖的概率是一百万分之一,如果要想确保成功一次,要买260万次彩票。你即使中一回大奖,花的钱要远比获得的多得多。 很多人喜…...
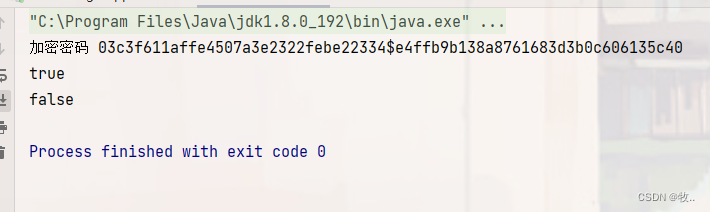
加密功能实现
文章目录1. 前言2. 密码加密1. 前言 本文 主要实现 对密码进行加密 ,因为 使用 md5 容易被穷举 (彩虹表) 而破解 ,使用 spring security 框架又太大了 (杀鸡用牛刀) 。 所以本文 就自己实现一个密码加密 . 2. 密码加密 这里我们通过 加盐是方式 来 对…...
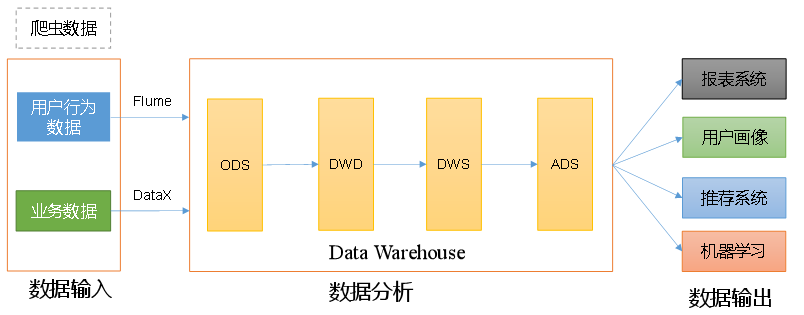
大数据项目实战之数据仓库:用户行为采集平台——第1章 数据仓库概念
第1章 数据仓库概念 数据仓库(Data Warehouse),是为企业制定决策,提供数据支持的。可以帮助企业改进业务流程、提高产品质量等。 数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等 业务数据…...
在生物制药业应用)
NTP对时服务器(NTP电子时钟)在生物制药业应用
NTP对时服务器(NTP电子时钟)在生物制药业应用 NTP对时服务器(NTP电子时钟)在生物制药业应用 8.1 系统概述 时钟系统为生物制药厂网络控制中心调度员、车场值班员及各部门工作人员提供统一的标准时间信息,也为本工程其它…...

JPA 之 QueryDSL-JPA 使用指南
Querydsl-JPA 框架(推荐) 官网:传送门 参考: JPA整合Querydsl入门篇SpringBoot环境下QueryDSL-JPA的入门及进阶 概述及依赖、插件、生成查询实体 1.Querydsl支持代码自动完成,因为是纯Java API编写查询࿰…...
如何找回回收站删除的视频?这三种方法可以试试
在使用电脑过程中,我们可能会误删重要的文件,特别是影音文件。在这样的情况下,我们可以从计算机的回收站中找回已经被删除的视频。但是有时候,我们可能会不小心清空回收站,这时候就需要一些技巧来恢复回收站删除的视频…...

FPGA_边沿监测理解
一、简易频率计设计中为什么一定要获取下降沿?gate_a:实际闸门信号gate_a_stand:将实际闸门信号打一拍之后的信号gate_a_fall_s:下降沿标志信号cnt_clk_stand: Y值,即在实际闸门信号下,标准时钟信号的周期个数cnt_clk_stand_reg:保存Y值的寄存器核心问题…...

41 42Ping-Pong操作
提高电路吞吐率的结构——Ping-Pong操作 1.Ping-Pong操作原理 作用:为了让两个不匹配的模块进行对接,并且在对接的过程中让这两个模块能够同时工作,提高数据处理的吞吐率(也称throughput效能) 常见的不匹配࿱…...
)
【限时解密】ElevenLabs未文档化的/v1/text-to-speech/{voice_id}/with-timing接口:获取逐词时间戳+音素级对齐数据(仅剩3个Beta白名单通道)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的核心能力与技术定位 ElevenLabs 是当前业界领先的 AI 语音合成平台,其英文语音生成能力建立在自研的端到端神经声学模型(如 ElevenMultilingualV2&…...

桌面自动化技能库:基于PyAutoGUI与Selenium的工程化实践
1. 项目概述:一个桌面操作员的技能库最近在GitHub上看到一个挺有意思的项目,叫Marways7/cua_desktop_operator_skill。光看这个名字,可能有点摸不着头脑,但作为一个在自动化运维和桌面支持领域摸爬滚打多年的老手,我立…...

独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力 对于独立开发者或小型工作室而言,在产品开发的早期阶段…...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

多数人支持!微软或把 Xbox 重新品牌化为 XBOX,回归最初形式
Xbox 品牌重塑:从民意调查到账号更名微软 Xbox 首席执行官阿莎夏尔马在 X(原推特)上发起民意调查,询问粉丝微软应使用 Xbox 还是 XBOX,结果多数人支持 XBOX,随后公司将其 X 账号更名。不过,Xbox…...

低多边形风出图总显廉价?揭秘Midjourney v6中--stylize、--polarize与--no纹理干扰的黄金配比公式
更多请点击: https://intelliparadigm.com 第一章:低多边形风出图的视觉认知陷阱与Midjourney v6风格断层解析 低多边形(Low-Poly)风格在AI图像生成中常被误认为“简约即可控”,实则构成一类典型的视觉认知陷阱&#…...
)
仅0.3%用户掌握的胶片叙事技巧:用Midjourney实现“过期胶卷”时间衰减效果(含Exif元数据欺骗指令集)
更多请点击: https://intelliparadigm.com 第一章:胶片叙事与数字时代的时间诗学 胶片影像的物理性——帧率、显影时长、机械快门延时——曾将时间锚定为可触摸的物质存在;而数字媒介则以纳秒级采样、无损复制与非线性剪辑,将时间…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...

量子计算解决最大独立集问题的qReduMIS算法解析
1. 量子计算与最大独立集问题概述最大独立集问题(Maximum Independent Set, MIS)是图论中的一个经典NP难问题,其目标是找到给定无向图中最大的顶点子集,使得该子集中任意两个顶点之间没有边相连。这个问题在社交网络分析、无线网络…...

深入GD32 CAN FD驱动层:从寄存器配置到ISO 15765协议栈的实战解析
深入GD32 CAN FD驱动层:从寄存器配置到ISO 15765协议栈的实战解析 在车载电子与工业控制领域,CAN FD协议正逐步取代传统CAN总线,成为高速数据传输的新标准。GD32系列MCU凭借其出色的性价比和丰富的外设资源,成为许多嵌入式开发者的…...