Hive SQL 开发指南(三)优化及常见异常
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指南,帮助您高效地编写 Hive SQL 查询。
本系列分为
Hive SQL 开发指南(一)数据类型及函数
Hive SQL 开发指南(二)使用(DDL、DML,DQL)
Hive SQL 开发指南(三)优化及常见异常
一、执行日志
在使用Hive进行数据查询和处理时,执行日志是一个重要的组成部分,它帮助开发者和管理员理解SQL执行的细节、性能瓶颈以及可能出现的错误。
1. 开启和查看执行日志
- Hive CLI(命令行界面):在Hive CLI中执行SQL时,可以直接在控制台输出中看到日志信息。
- Beeline:使用Beeline连接Hive时,也可以设置不同的日志级别来查看执行过程中的详细信息。
- HiveServer2日志:如果通过HiveServer2服务执行SQL,可以在HiveServer2的日志文件中找到执行日志。
- YARN日志:对于提交到YARN上运行的Hive作业,可以通过YARN的ResourceManager界面或使用yarn logs -applicationId <应用ID>命令来查看详细的执行日志。
2. 日志级别
Hive支持不同的日志级别,这些级别从详细到简洁依次为:DEBUG、INFO、WARN、ERROR。在调试SQL性能问题或错误时,DEBUG或INFO级别的日志通常最为有用,但它们会产生大量的输出。在生产环境中,通常使用WARN或ERROR级别以减少日志文件的大小。
3. 配置日志级别
日志级别可以通过多种方式配置:
- 在Hive CLI或Beeline中临时设置:可以在启动Hive CLI或Beeline时通过--hiveconf hive.root.logger=INFO,console这样的参数来设置日志级别。
- 修改Hive配置文件:在hive-site.xml中设置hive.root.logger属性来全局改变日志级别。
二、提前过滤数据
尽量尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。
select ... from A
join B
on A.key = B.key
where A.userid>10and B.userid<10and A.dt='20220417'and B.dt='20220417';
-- 应该改写为:
select .... from (select .... from Awhere dt='202200417'and userid>10) a
join ( select .... from Bwhere dt='202200417'and userid < 10 ) b
on a.key = b.key;三、慎用Map Join
慎重使用mapjoin,一般行数小于2000行,大小小于25M(扩容后可以适当放大)的表才能使用,小表要注意放在join的左边。否则会引起磁盘和内存的大量消耗
四、禁止使用笛卡尔积
笛卡尔积只有1个reduce任务,会导致计算超慢,甚至可能计算不出来或者导致节点挂掉。
五、列修剪和分区修剪
在读数据的时候,只读取查询中需要用到的列,而忽略其他列。例如,对于查询:
SELECT a,b FROM T WHERE e < 10;其中,T 包含 5 个列 (a,b,c,d,e),列 c,d 将会被忽略,只会读取a, b, e 列
这个选项参数默认为真: hive.optimize.cp = true
在查询的过程中减少不必要的分区。例如,对于下列查询:
SELECT * FROM (SELECT c1, COUNT(1)FROM T GROUP BY c1) subqWHERE subq.prtn = 100;SELECT * FROM T1 JOIN(SELECT * FROM T2) subq ON (T1.c1=subq.c2)WHERE subq.prtn = 100;会在子查询中就考虑 subq.prtn = 100 条件,从而减少读入的分区数目。
此选项参数默认为真:hive.optimize.pruner=true
六、explain的使用
explain命令对于我们优化查询语句很重要,针对某些查询语句,我们可以通过它查看各个执行计划,针对耗时的地方,优化之。
语法
EXPLAIN [ EXTENDED | FORMATTED | DEPENDENCY | LOGICAL | AUTHORIZATION | VECTORIZATION | ANALYZE ] query
七、union all 改写成join
当需要把几个数据集的结果合并时,能使用join的话就不要使用union all。因为使用union all时通常需要加入大量的0,这会导致中间结果膨胀,增加系统负担。
八、数据膨胀导致reduce任务数不合理
数据膨胀很多时候也会导致reduce任务个数过少。reduce数目是否合理,可以从任务的mr监控页面发现端倪。请注意job监控页面的一个参数:
Reduce shuffle bytes reduce任务读取字节数
一般情况下,reduce任务的个数应大致等于上面这个参数的大小(请换算成GB),如果该参数大小是reduce任务数的数倍,那就意味着reduce任务数不合理。
解决方法:
通过设置reduce任务数提高并行度来加速执行:
set mapred.reduce.tasks=N; //执行语句之前
set mapred.reduce.tasks=-1; //执行语句之后恢复原状
注意:请合理设置N的大小,最好设置为上述参数的大小。不要超过999!
九、合并小文件
文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的结果文件来消除这样的影响:
- hive.merge.mapfiles = true是否和并 Map 输出文件,默认为 True
- hive.merge.mapredfiles = false是否合并 Reduce 输出文件,默认为 False
- hive.merge.size.per.task = 256*1000*1000合并文件的大小
十、合理设置reduce个数
1)某些情况下,job运行过程中reduce个数太少,导致任务执行太慢,默认reduce的个数由下面配置控制:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)
2)调整reduce个数方法一
调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
3)调整reduce个数方法二(一般这样设置就可以了)
set mapred.reduce.tasks = 15;
4)reduce个数并不是越多越好
同map一样,启动和初始化reduce也会消耗时间和资源;另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
5)什么情况下只有一个reduce
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务
其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
a)没有group by的汇总,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 写成 select count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04';
b)用了Order by
c)有笛卡尔积
十一、排序优化
Order by 实现全局排序,一个reduce实现,效率低,所以order by过程中尽量limit来限制输出条数
Sort by 实现部分有序,单个reduce输出的结果是有序的,效率高,通常和DISTRIBUTE BY关键字一起使用(DISTRIBUTE BY关键字 可以指定map 到 reduce端的分发key)
CLUSTER BY col1 等价于DISTRIBUTE BY col1 SORT BY col1
十二、动态分区
在hive中,有时候会希望根据输入的key,把结果自动输出到不同的目录中,这可以通过动态分区来实现,就是把每一个key当作一个分区。
如果要启动动态分区,则需要进行下面的设置
1、首先需要在hive语句中设置允许动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
2、在动态分区有可能很大的情况下,还需要其他的调整
hive.exec.dynamic.partitions.pernode 参数指的是每个节点上能够生成的最大分区,这个在最坏情况下应该是跟最大分区一样的值
hive.exec.dynamic.partitions.partitions 参数指的是总共的最大的动态分区数
hive.exec.max.created.files 参数指的是能够创建的最多文件数(分区一多,文件必然就多了...)
3、最后要注意的是select语句中要把distribute的key也select出来
4、适当设置reduce个数 mapred.reduce.tasks
十三、数据倾斜
数据倾斜的外在表现是执行时间超长。查看任务的监控页面可以发现,除了一个或几个任务外,其他reduce任务都执行的很快。这种情况下,只有一个解释:数据倾斜。
在做Shuffle阶段的优化过程中,遇到了数据倾斜的问题,造成了对一些情况下优化效果不明显。主要是因为在Job完成后的所得到的Counters是整个Job的总和,优化是基于这些Counters得出的平均值,而由于数据倾斜的原因造成map处理数据量的差异过大,使得这些平均值能代表的价值降低。Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。规避错误来更好的运行比解决错误更高效。在查看了一些资料后,总结如下。
数据倾斜原因
操作
| 关键词 | 情形 | 后果 |
| Join | 其中一个表较小, 但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| 大表与大表,但是分桶的判断字段0值或空值过多 | 这些空值都由一个reduce处理,灰常慢 | |
| group by | group by 维度过小, 某值的数量过多 | 处理某值的reduce灰常耗时 |
| Count Distinct | 某特殊值过多 | 处理此特殊值的reduce耗时 |
原因
a)、key分布不均匀
b)、业务数据本身的特性
c)、建表时考虑不周
d)、某些SQL语句本身就有数据倾斜
表现
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
数据倾斜的解决方案
参数调节
a) hive.map.aggr = true
Map 端部分聚合,相当于Combiner
b) hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
SQL语句调整
a) 如何Join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
b) 大小表Join:
使用map join让小的维度表(1000条以下的记录条数) 先进内存。在map端完成reduce.
c) 大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
d) count distinct大量相同特殊值
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
e) group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。
f)特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
典型的业务场景
空值产生的数据倾斜
场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题。
解决方法1: user_id为空的不参与关联
select * from log ajoin users bon a.user_id is not nulland a.user_id = b.user_idunion all
select * from log awhere a.user_id is null;解决方法2 :赋与空值分新的key值
select *from log aleft outer join users bon case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;结论:方法2比方法1效率更好,不但io少了,而且作业数也少了。解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 。这个优化适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
不同数据类型关联产生数据倾斜
场景:用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。
解决方法:把数字类型转换成字符串类型
select * from users aleft outer join logs bon a.usr_id = cast(b.user_id as string)3.3) 小表不小不大,怎么用 map join 解决倾斜问题
使用 map join 解决小表(记录数少)关联大表的数据倾斜问题,这个方法使用的频率非常高,但如果小表很大,大到map join会出现bug或异常,这时就需要特别的处理。 以下例子:
select * from log aleft outer join users bon a.user_id = b.user_id;users 表有 600w+ 的记录,把 users 分发到所有的 map 上也是个不小的开销,而且 map join 不支持这么大的小表。如果用普通的 join,又会碰到数据倾斜的问题。
解决方法:
select /*+mapjoin(x)*/* from log aleft outer join (select /*+mapjoin(c)*/d.*from ( select distinct user_id from log ) cjoin users don c.user_id = d.user_id) xon a.user_id = b.user_id;假如,log里user_id有上百万个,这就又回到原来map join问题。所幸,每日的会员uv不会太多,有交易的会员不会太多,有点击的会员不会太多,有佣金的会员不会太多等等。所以这个方法能解决很多场景下的数据倾斜问题。
总结
使map的输出数据更均匀的分布到reduce中去,是我们的最终目标。由于Hash算法的局限性,按key Hash会或多或少的造成数据倾斜。大量经验表明数据倾斜的原因是人为的建表疏忽或业务逻辑可以规避的。在此给出较为通用的步骤:
1、采样log表,哪些user_id比较倾斜,得到一个结果表tmp1。由于对计算框架来说,所有的数据过来,他都是不知道数据分布情况的,所以采样是并不可少的。
2、数据的分布符合社会学统计规则,贫富不均。倾斜的key不会太多,就像一个社会的富人不多,奇特的人不多一样。所以tmp1记录数会很少。把tmp1和users做map join生成tmp2,把tmp2读到distribute file cache。这是一个map过程。
3、map读入users和log,假如记录来自log,则检查user_id是否在tmp2里,如果是,输出到本地文件a,否则生成<user_id,value>的key,value对,假如记录来自member,生成<user_id,value>的key,value对,进入reduce阶段。
4、最终把a文件,把Stage3 reduce阶段输出的文件合并起写到hdfs。
如果确认业务需要这样倾斜的逻辑,考虑以下的优化方案:
1、对于join,在判断小表不大于1G的情况下,使用map join
2、对于group by或distinct,设定 hive.groupby.skewindata=true
3、尽量使用上述的SQL语句调节进行优化
相关文章:
优化及常见异常)
Hive SQL 开发指南(三)优化及常见异常
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指…...

Spring Boot 自动装配的原理!!!
SpringBootApplication SpringBootConfiguration:标识启动类是一个IOC容器的配置类 EnableAutoConfiguration: AutoConfigurationPackage:扫描启动类所在包及子包中所有的组件,生…...

Linux运维_Bash脚本_编译安装Wayland-1.22.0
Linux运维_Bash脚本_编译安装Wayland-1.22.0 Bash (Bourne Again Shell) 是一个解释器,负责处理 Unix 系统命令行上的命令。它是由 Brian Fox 编写的免费软件,并于 1989 年发布的免费软件,作为 Sh (Bourne Shell) 的替代品。 您可以在 Linu…...

Python数字类型
文章目录 Python数字类型1. 数字类型1.1 数字类型概述1.2 整数类型1.3 浮点数类型1.4 复数 2. 数字类型的操作2.1 内置的数值运算操作符2.2 内置的数值运算函数2.3 内置的数字类型转换函数 思考与练习 Python数字类型 1. 数字类型 1.1 数字类型概述 数字是自然界计数活动的抽…...
)
每天一个数据分析题(一百九十六)
在多元线性回归模型的自变量选择方法中,关于向后回归法和逐步回归法的描述,以下哪些是正确的? A. 向后回归法开始时包含所有自变量,并逐步剔除每个不显著的变量。 B. 逐步回归法结合了向前回归法和向后回归法,可以在…...
华为北向网管NCE开发教程(1)闭坑选接口协议
华为北向网管NCE开发教程(1)闭坑选接口协议 华为北向网管NCE开发教程(2)REST接口开发 华为北向网管NCE开发教程(3)CORBA协议开发 本文一是记录自己开发华为北向网管遇到的坑,二是给需要的人&…...
JavaScript极速入门-综合案例(3)
综合案例 猜数字 预期效果 代码实现 <button type"button" id"reset">重新开始一局游戏</button><br>请输入要猜的数字:<input type"text" id"number"><button type"button" id"button&q…...
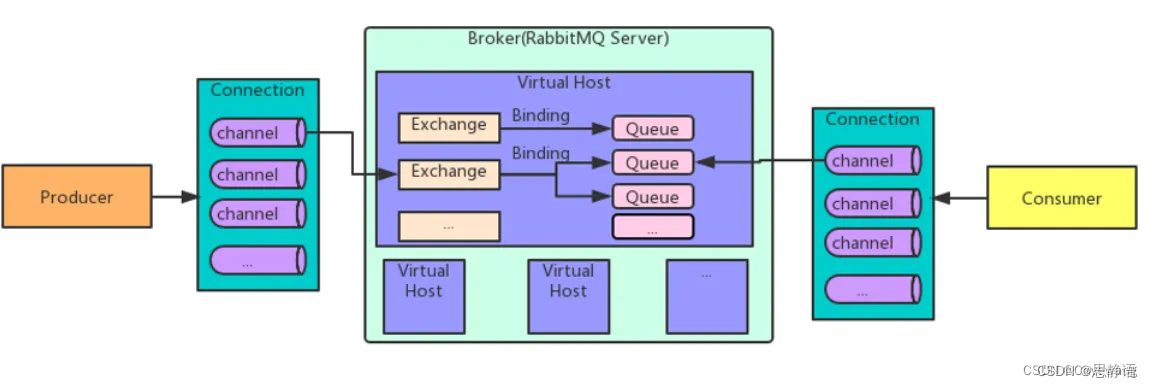
RabbitMQ架构详解
文章目录 概述架构详解核心组件虚拟主机(Virtual Host)RabbitMQ 有几种广播类型 概述 RabbitMQ是⼀个高可用的消息中间件,支持多种协议和集群扩展。并且支持消息持久化和镜像队列,适用于对消息可靠性较高的场合 官网https://www.…...
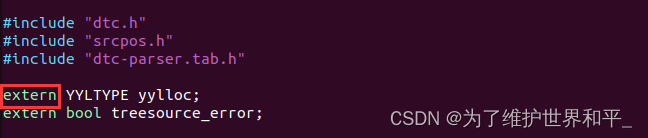
编译内核错误 multiple definition of `yylloc‘
编译内核错误 # make ARCHarm CROSS_COMPILEarm-mix410-linux- uImageHOSTLD scripts/dtc/dtc /usr/bin/ld: scripts/dtc/dtc-parser.tab.o:(.bss0x10): multiple definition of yylloc; scripts/dtc/dtc-lexer.lex.o:(.bss0x0): first defined here collect2: error: ld ret…...

深度学习模型部署(四)常用模型及推理平台评估指标
判断选择什么模型,什么量化方案,什么推理框架,最基础的知识就是如何评估自己的模型以及推理平台。 模型衡量标准 衡量一个模型的最直接标准就是运算速度,但是运算速度是无法计算的,所以定义了一些间接标准来推测模型的…...
【控制台警告】npm WARN EBADENGINE Unsupported engine
今天用webpack下载几个loader依赖,爆出了三个警告,大概的意思就是本地安装的node和npm的版本不是很匹配? 我的解决思路是: 先检查node和npm版本 然后去官网查找版本的对应 靠,官网404 Node.js (nodejs.org) 就找到…...

ArmSoM Rockchip系列产品 通用教程 之 GPIO 使用
1. GPIO简介 GPIO,全称 General-Purpose Input/Output(通用输入输出),是一种在计算机和嵌入式系统中常见的数字输入输出接口。它允许软件控制硬件的数字输入和输出,例如开关、传感器、LED灯等。GPIO通常由一个芯片或…...

npm镜像源地址
镜像源地址替换问题(重要) 2024 年 1 月 22 日 ,registry.npm.taobao.org 的 SSL 证书正式过期。 2022 年 5 月 淘宝源发布了公告: (大家应该没有太多关注哦,也包括我,哈哈) &am…...

Java的Writer类详解
咦咦咦,各位小可爱,我是你们的好伙伴——bug菌,今天又来给大家普及Java SE相关知识点了,别躲起来啊,听我讲干货还不快点赞,赞多了我就有动力讲得更嗨啦!所以呀,养成先点赞后阅读的好…...
R语言基础的代码语法解译笔记
1、双冒号,即:“::” 要使用某个包里的函数,通常做法是先加载(library)包,再调用函数。最新加载的包的namespace会成为最新的enviroment,某些情况下可能影响函数的结果。而package name::funct…...

【蓝桥杯】蓝桥杯算法复习(一)
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!Ǵ…...

移动端精准测试简介
在测试领域每隔一段时间,就会有一些主流的测试技术,比如说:接口自动化,WebUI, AppUI自动化,然后就是测试平台的开发,各类专项测试(性能,安全),再到前几年的手机集群云测平…...

CCProxy代理服务器地址的设置步骤
目录 前言 一、下载和安装CCProxy 二、启动CCProxy并设置代理服务器地址 三、验证代理服务器设置是否生效 四、使用CCProxy进行代理设置的代码示例 总结 前言 CCProxy是一款常用的代理服务器软件,可以帮助用户实现网络共享和上网代理。本文将详细介绍CCProxy…...
)
探秘分布式神器RMI:原理、应用与前景分析(二)
本系列文章简介: 本系列文章将深入探究RMI远程调用的原理、应用及未来的发展趋势。首先,我们会详细介绍RMI的工作原理和基本流程,解析其在分布式系统中的核心技术。随后,我们将探讨RMI在各个领域的应用,包括分布式计算…...

[项目设计] 从零实现的高并发内存池(三)
🌈 博客个人主页:Chris在Coding 🎥 本文所属专栏:[高并发内存池] ❤️ 前置学习专栏:[Linux学习] ⏰ 我们仍在旅途 目录 4.CentralCache实现 4.1 CentralCache整体架构 4.2 围绕Span的相关设计…...

2025届学术党必备的十大AI科研工具实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 通过人工智能用来撰写开题报告,能够明显提高文献梳理跟框架构建的效率ÿ…...

安卓开发者的新玩具:在Android Studio里集成DeepSeek模型,打造你的专属AI助手App
安卓开发者的新玩具:在Android Studio里集成DeepSeek模型,打造你的专属AI助手App 作为一名长期奋战在Android开发一线的工程师,我最近发现了一个令人兴奋的新趋势:将本地化AI模型直接集成到移动应用中。这不再是科幻电影里的场景&…...

Rust 并发模型中的所有权转移
Rust 并发模型中的所有权转移 在并发编程中,数据竞争和内存安全问题一直是困扰开发者的难题。Rust 语言通过独特的所有权机制,为并发编程提供了高效且安全的解决方案。所有权转移是 Rust 并发模型的核心之一,它确保数据在多线程环境下安全传…...

GBase 8s ER 影子列解析
影子列是复制的表上被隐藏的列,其包含由数据库服务器提供的值。数据库服务器使用影子列来执行内部操作。可以 CREATE TABLE 或 ALTER TABLE 语句来将影子列添加至复制的表。 要查看影子列的内容,必须在 SELECT 语句的投影列表中显式地指定该列࿱…...

3分钟掌握浏览器音高检测:PitchDetect让音乐分析触手可及
3分钟掌握浏览器音高检测:PitchDetect让音乐分析触手可及 【免费下载链接】PitchDetect Pitch detection in Web Audio using autocorrelation 项目地址: https://gitcode.com/gh_mirrors/pi/PitchDetect 在音乐学习、乐器调音或音频分析中,实时获…...

如何快速获取中国行政区划数据:5个实用技巧实现JSON与CSV格式无缝转换
如何快速获取中国行政区划数据:5个实用技巧实现JSON与CSV格式无缝转换 【免费下载链接】Administrative-divisions-of-China 中华人民共和国行政区划:省级(省份)、 地级(城市)、 县级(区县&…...

解放双手!明日方舟自动化助手MAA:让游戏回归乐趣的智能解决方案
解放双手!明日方舟自动化助手MAA:让游戏回归乐趣的智能解决方案 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项…...

手机号码定位终极指南:3分钟快速免费查询地理位置信息
手机号码定位终极指南:3分钟快速免费查询地理位置信息 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirr…...

如何用RyzenAdj解锁AMD笔记本隐藏性能?实用电源管理技巧大揭秘
如何用RyzenAdj解锁AMD笔记本隐藏性能?实用电源管理技巧大揭秘 【免费下载链接】RyzenAdj Adjust power management settings for Ryzen APUs 项目地址: https://gitcode.com/gh_mirrors/ry/RyzenAdj RyzenAdj是一款专为AMD Ryzen移动处理器设计的开源电源管…...

如何快速掌握ExifToolGUI:新手到专家的完整图形化元数据编辑指南
如何快速掌握ExifToolGUI:新手到专家的完整图形化元数据编辑指南 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 还在为照片元数据管理而烦恼吗?面对成千上万的旅行照片,…...