13:大数据与Hadoop|分布式文件系统|分布式Hadoop集群
大数据与Hadoop|分布式文件系统|分布式Hadoop集群
- Hadoop
- 部署Hadoop
- HDFS分布式文件系统
- HDFS部署
- 步骤一:环境准备
- HDFS配置文件 查官方手册
- 配置Hadoop集群
- 日志与排错
- mapreduce 分布式离线计算框架
- YARN集群资源管理系统
- 步骤一:安装与部署hadoop
Hadoop
Hadoop是一种分析和处理海量数据的软件平台,基于java语言开发,可以提供一个分布式基础架构。
特点:高可靠性、高扩展性、高效性、高容错性、低成本


部署Hadoop
本案例要求安装单机模式Hadoop:
热词分析:
最低配置:2cpu,2G内存,10G硬盘
虚拟机IP:192.168.1.50 hadoop1
安装部署 hadoop
数据分析,查找出现次数最多的单词
1)配置主机名为hadoop1,ip为192.168.1.50,配置yum源(系统源)
2)安装java环境
[root@hadoop1 ~]# yum -y install java-1.8.0-openjdk-devel java-1.8.0-openjdk-devel
[root@hadoop1 ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
[root@hadoop1 ~]# jps
1235 Jps
3)安装hadoop
[root@hadoop1 ~]# cd hadoop/
[root@hadoop1 hadoop]# ls
hadoop-2.7.7.tar.gz kafka_2.12-2.1.0.tgz zookeeper-3.4.13.tar.gz
[root@hadoop1 hadoop]# tar -xf hadoop-2.7.7.tar.gz
[root@hadoop1 hadoop]# mv hadoop-2.7.7 /usr/local/hadoop
[root@hadoop1 hadoop]# chown -R 0.0 /usr/local/hadoop # 为了安全 修改所有者和所属组
[root@hadoop1 hadoop]# vim /etc/hosts
192.168.1.50 hadoop1
[root@hadoop1 hadoop]# vim /usr/local/hadoop/etc/hadoop-env.sh
25: export JAVA_HOME="/usr" # java安装路径
33: export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop" # hadoop配置文件命令
[root@hadoop1 hadoop]# /usr/local/hadoop/bin/hadoop version
[root@hadoop1 ~]# cd /usr/local/hadoop/
[root@hadoop1 hadoop]# ./bin/hadoop # 运行
5)词频统计
[root@hadoop1 hadoop]# mkdir /usr/local/hadoop/input
[root@hadoop1 hadoop]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt input README.txt sbin share
[root@hadoop1 hadoop]# cp *.txt /usr/local/hadoop/input
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input output //wordcount为参数 统计input这个文件夹,存到output这个文件里面(这个文件不能存在,要是存在会报错,是为了防止数据覆盖)
[root@hadoop1 hadoop]# cat output/part-r-00000 //查看

HDFS分布式文件系统

HDFS是Hadoop体系中数据存储管理的基础,是一个高度容错的系统,用于在低成本的通用硬件上运行。
HDFS角色和概念:
- Client :客户端 负责 切分文件 访问HDFS 与NameNode交互,获取文件位置信息 与DataNode交互,读取和写入数据
Block 每块缺省128MB大小,没块可以多个副本 - Namenode:Master节点 管理HDFS的名称空间和数据块映射信息(fsimage) 配置副本策略,处理所有客户端请求
- Secondarynode:定期合并fsimage和fsedits,推送给NameNode fsimage:名称空间和数据库的映射信息中 fsedits:数据变更日志 紧急情况下 可辅助恢复NameNode 但Secondary NameNode并非NameNode热备
- Datanode:数据存储节点,存储实际的数据 汇报存储信息给NameNode
HDFS部署
准备集群环境
最低配置:2CPU,2G内存,10G硬盘
虚拟机IP:
192.168.1.50 hadoop1
192.168.1.51 node-0001
192.168.1.52 node-0002
192.168.1.53 node-0003
要求:禁用selinux、禁用firewalld (所有主机)
安装java-1.8.0-openjdk-devel,并配置 /etc/hosts(所有主机)
设置hadoop1 免密登录其他主机、并不用输入 yes
使所有节点能够ping通,配置SSH信任关系
节点验证
步骤一:环境准备
1)编辑/etc/hosts(四台主机同样操作,以hadoop1为例)
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.51 node-0001
192.168.1.52 node-0002
192.168.1.53 node-0003
2)安装java环境,在node-0001,node-0002,node-0003上面操作(以node-0001为例)
[root@node-0001 ~]# yum -y install java-1.8.0-openjdk-devel
3)布置SSH信任关系
[root@hadoop1 ~]# vim /etc/ssh/ssh_config //第一次登陆不需要输入yes
Host *GSSAPIAuthentication yesStrictHostKeyChecking no
[root@hadoop1 .ssh]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:Ucl8OCezw92aArY5+zPtOrJ9ol1ojRE3EAZ1mgndYQM root@hadoop1
The key's randomart image is:
+---[RSA 2048]----+
| o*E*=. |
| +XB+. |
| ..=Oo. |
| o.+o... |
| .S+.. o |
| + .=o |
| o+oo |
| o+=.o |
| o==O. |
+----[SHA256]-----+
[root@hadoop1 .ssh]# for i in hadoop1 node-{0001...0003};do ssh-copy-id -i /root/.ssh/id_ras.pub ${i} done
//部署公钥给hadoop1,node-0001,node-0002,node-0003
4)测试信任关系
[root@hadoop1 .ssh]# ssh node-0001
Last login: Fri Sep 7 16:52:00 2018 from 192.168.1.60
[root@node-0001 ~]# exit
logout
Connection to node-0001 closed.
[root@hadoop1 .ssh]# ssh node-0002
Last login: Fri Sep 7 16:52:05 2018 from 192.168.1.60
[root@node-0002 ~]# exit
logout
Connection to node-0002 closed.
[root@hadoop1 .ssh]# ssh node-0003
HDFS配置文件 查官方手册
- 环境配置文件:hadoop-env.sh
- 核心配置文件:core-site.xml
- HDFS配置文件:hdfs-site.xml
- 节点配置文件:slaves
1)修改slaves文件
[root@hadoop1 ~]# cd /usr/local/hadoop/etc/hadoop
[root@hadoop1 hadoop]# vim slaves
node-0001
node-0002
node-0003
2)hadoop的核心配置文件core-site
[root@hadoop1 hadoop]# vim core-site.xml
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value></property><property><name>hadoop.tmp.dir</name><value>/var/hadoop</value></property>
</configuration>
[root@hadoop1 hadoop]# mkdir /var/hadoop //hadoop的数据根目录
3)配置hdfs-site文件
[root@hadoop1 hadoop]# vim hdfs-site.xml
<configuration><property><name>dfs.namenode.http-address</name><value>hadoop1:50070</value> # 主机名:端口号 查手册</property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop1:50090</value></property><property><name>dfs.replication</name><value>2</value> # 副本数量</property>
</configuration>

配置Hadoop集群
启动集群(以下操作仅在hadoop1上执行)
[root@hadoop1 ~]# for i in node-{0001..0001};do rsync -aXSH --delete /usr/local/hadoop ${i}:/usr/local/ done
[root@hadoop1 ~]# mkdir /var/hadoop
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs namenode -format
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-dfs.sh
验证集群配置
[root@hadoop1 ~]# for i in hadoop1 node-{0001..0003};do echo ${i}; ssh ${i} jps; echo -e "\n"; done
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report


日志与排错
日志文件夹在系统启动时会被自动创建
/usr/local/hadoop/logs
日志名称
- 服务名 - 用户名 - 角色名 - 主机名.out 标准输出
- 服务名 - 用户名 - 角色名 - 主机名.log 日志输出
mapreduce 分布式离线计算框架


1)配置mapred-site(hadoop1上面操作)
[root@hadoop1 ~]# cd /usr/local/hadoop/etc/hadoop/
[root@hadoop1 ~]# mv mapred-site.xml.template mapred-site.xml
[root@hadoop1 ~]# vim mapred-site.xml
<configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
YARN集群资源管理系统
在之前创建的 4 台虚拟机上部署 Yarn
在虚拟机上安装部署 Yarn
hadoop1 部署 resourcemanager
node(1,2,3) 部署 nodemanager
在之前创建的 4 台虚拟机上部署 Yarn


步骤一:安装与部署hadoop
1)配置yarn-site(hadoop1上面操作)
[root@hadoop1 hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property><name>yarn.resourcemanager.hostname</name><value>hadoop1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
2)同步配置(hadoop1上面操作)
[root@hadoop1 ~]# for i in node-{0001..0003}; dorsync -axXSH --delete /usr/local/hadoop/etc ${i}:/usr/local/hadoop/done
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-yarn.sh
3)验证配置(hadoop1上面操作)
[root@hadoop1 ~]# for i in hadoop1 node-{0001..0003}; do echo ${i};ssh ${i} jps;echo -e "\n";done
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn node -list

4)web访问hadoop
namenode: http://hadoop1:50070
firefox http://hadoop1:8088 (resourcemanager)
firefox http://node-0001:8042 (nodemanager)
相关文章:
13:大数据与Hadoop|分布式文件系统|分布式Hadoop集群
大数据与Hadoop|分布式文件系统|分布式Hadoop集群 Hadoop部署Hadoop HDFS分布式文件系统HDFS部署步骤一:环境准备HDFS配置文件 查官方手册配置Hadoop集群 日志与排错 mapreduce 分布式离线计算框架YARN集群资源管理系统步骤一:安装…...
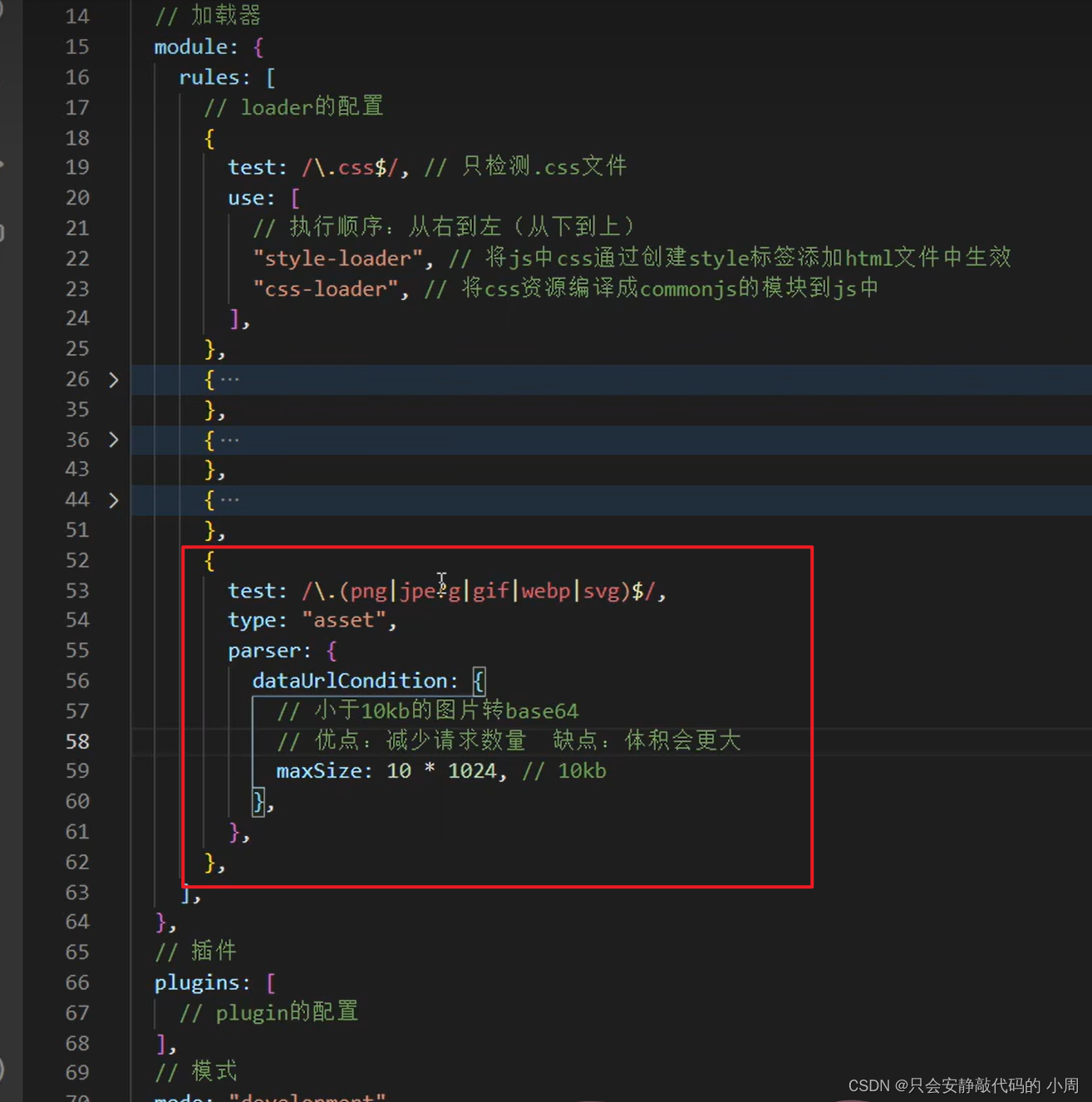
前端知识点、技巧、webpack、性能优化(持续更新~)
1、 请求太多 页面加载慢 (webpack性能优化) 可以把 图片转换成 base64 放在src里面 减少服务器请求 但是图片会稍微大一点点 以上的方法不需要一个一个自己转化 可以在webpack 进行 性能优化 (官网有详细描述)...

红队专题-开源漏扫-巡风xunfeng源码剖析与应用
开源漏扫-巡风xunfeng 介绍主体两部分:网络资产识别引擎,漏洞检测引擎。代码赏析插件编写JSON标示符Python脚本此外系统内嵌了辅助验证功能文件结构功能 模块添加IP三. 进行扫描在这里插入图片描述 )
统计接口调用耗时情况设计思路(大厂面试题)
gateway统计接口调用耗时情况设计思路(大厂面试题) 详情视频可以去看尚硅谷2024周阳老师的springCloud P86 知识出处自定义全局过滤器官网https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gateway-combined-global-filter-…...

Elasticsearch:什么是 DevOps?
DevOps 定义 DevOps 是一种现代软件开发方法,它将公司软件开发 (Dev) 和 IT 运营 (Ops) 团队的工作结合起来并实现自动化。 DevOps 提倡这样一种理念:这些传统上独立的团队在协作方面比在孤岛中更有效。 理想情况下,DevOps 团队共同努力改进…...

C语言基础练习——Day03
目录 选择题 编程题 记负均正 旋转数组的最小数字 选择题 1、已知函数的原型是:int fun(char b[10], int *a);,设定义:char c[10];int d;,正确的调用语句是 A fun(c,&d);B fun(c,d);C fun(&c,&d);D fun(&c,d); 答…...

膜厚测量仪在半导体应用中及其重要
随着科技的不断发展,半导体行业已成为当今世界的核心产业之一。在这个领域中,半导体膜厚测量仪作为关键设备,其精度和可靠性对于产品质量和生产效率具有至关重要的作用。本文将详细介绍半导体膜厚测量仪的工作原理、应用领域以及其在半导体制…...

【前端】-初始前端以及html的学习
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...

uni-app navigateTo路由传参传递对象
传递参数 先通过JSON.stringify将对象转成字符串 toNextPage(obj) {uni.navigateTo({url:/pages/nextpage/index?obj${JSON.stringify(obj)}}); },接收参数 再通过JSON.parse将传递过来的字符串转成对象 onLoad(options) {this.obj JSON.parse(options.obj) }...

99 centos 7 服务器上面 增加了 2181 的防火墙配置, 但是客户端连接不上
呵呵 最近部署 zookeeper 的时候出现这样的一个问题 centos 7 服务器上面 增加了 2181 的防火墙配置, 但是客户端连接不上 # 但是再 另外的一个虚拟机环境, ubuntu 16 的环境, docker 启动 2181 的服务, 然后 安装 firewalld, 配置 开放 2181 的 tcp 服务, 客户端能够正常连接…...

云计算科学与工程实践指南--章节引言收集
云计算科学与工程实践指南–章节引言收集 //本文收集 【云计算科学与工程实践指南】 书中每一章节的引言。 我已厌倦了在一本书中阅读云的定义。难道你不失望吗?你正在阅读一个很好的故事,突然间作者必须停下来介绍云。谁在乎云是什么? 通…...

探索Web中的颜色选择:不同取色方法的实现
在Web开发中,提供用户选择颜色的功能是很常见的需求。无论是为了个性化UI主题,还是为了图像编辑工具,一个直观且易用的取色器都是必不可少的。本文将介绍几种在Web应用中实现取色功能的方法,从简单的HTML输入到利用现代API的高级技…...
)
突破编程_C++_设计模式(策略模式)
1 策略模式的概念 策略模式(Strategy Pattern)是 C 中常用的一种行为设计模式,它能在运行时改变对象的行为。在策略模式中,一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为模式。 在策略模式中,需…...

【uniapp】uniapp小程序中实现拍照同时打开闪光灯的功能,拍照闪光灯实现
一、需求前提 特殊场景中,需要拍照的同时打开闪光灯,(例如黑暗场景下的设备维护巡检功能)。 起初我是用的uviewui中的u-upload组件自带的拍照功能,但是这个不支持拍照时打开闪光灯,也不支持从通知栏中打开…...

在python model train里如何驯服野生log?
关键词:python 、epoch、loss、log 🤖: 记录模型的训练过程的步骤如下: 导入logging模块。配置日志记录器,设置日志文件名、日志级别、日志格式等。在每个epoch结束时,使用logging模块记录性能指标、损失值、准确率等信…...

产品推荐 - Xilinx FPGA下载器 XQ-HS/STM2
1 FPGA下载器简介 1.性能优良 FPGA下载器XQ-HS/STM2采用Xilinx下载模块设计而成(JTAG-SMT2NC模块,该模块与Xilinx官方开发板KC705,KCU105,ZC702,ZC706,Zedboard等板载下载器一样,下载速度快…...

STM32 SDRAM知识点
1.SDRAM和SRAM的区别 SRAM不需要刷新电路即能保存它内部存储的数据。而SDRAM(Dynamic Random Access Memory)每隔一段时间,要刷新充电一次,否则内部的数据即会消失,因此SRAM具有较高的性能,但是SRAM也有它…...

手写分布式配置中心(六)整合springboot(自动刷新)
对于springboot配置自动刷新,原理也很简单,就是在启动过程中用一个BeanPostProcessor去收集需要自动刷新的字段,然后在springboot启动后开启轮询任务即可。 不过需要对之前的代码再次做修改,因为springboot的配置注入value("…...
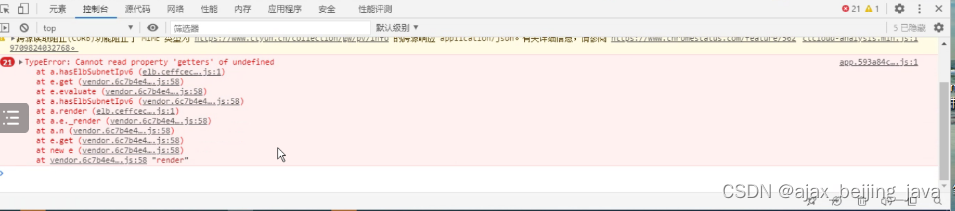
记录一次排查负载均衡不能创建的排查过程
故障现象,某云上,运维同事在创建负载均衡的时候,发现可以创建资源,但是创建完之后,不显示对应的负载均衡。 创建负载均衡时候,按f12发现console有如下报错 后来请后端网络同事排查日志发现,是后…...

数据推送解决方案调研
需求 文档编辑类型的需求,左侧是菜单栏,右侧是内容块,现在的需求时,如果多人同时编辑这个方案,当添加章节/调整章节顺序/删除章节时,其他用户能够及时感知到。 解决方案调研 前端轮询 最简单的方案&…...
)
R 4.5并行计算终极配置清单(含17个环境变量、9个.Rprofile隐藏指令、5个Makevars强制编译开关)
第一章:R 4.5并行计算优化方法概览R 4.5 引入了对并行计算基础设施的多项底层增强,包括对 parallel 包的线程安全改进、future 框架的原生支持升级,以及对 foreach 与 doParallel 组合执行效率的显著提升。这些变更使得多核 CPU 利用率更稳定…...

从运维视角看Spine-Leaf:当SDN接管了网络配置,传统网工该如何转型与避坑?
从CLI到策略:Spine-Leaf架构下网络工程师的生存指南 凌晨三点,某金融公司数据中心告警灯突然亮起——核心交易系统的延迟飙升到800毫秒。值班的王工习惯性地打开终端准备检查路由表,却发现眼前不再是熟悉的CLI界面,而是一套全新的…...

大麦网终极抢票指南:Python自动化脚本告别手速烦恼
大麦网终极抢票指南:Python自动化脚本告别手速烦恼 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?每次开票瞬间就被秒光ÿ…...

3分钟搞定演唱会门票:大麦网抢票脚本让你告别抢票焦虑
3分钟搞定演唱会门票:大麦网抢票脚本让你告别抢票焦虑 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?每次开票瞬间秒光࿰…...

WarcraftHelper终极指南:如何让魔兽争霸3在现代Windows系统完美运行
WarcraftHelper终极指南:如何让魔兽争霸3在现代Windows系统完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争…...

抖音批量下载终极指南:5分钟掌握高效视频管理技巧
抖音批量下载终极指南:5分钟掌握高效视频管理技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

C++ 初级程序员核心知识全集
C 初级程序员核心知识全集 一、变量的本质与内存基础 概念:变量就是向系统申请一块内存空间来存数据。核心操作: 取地址:&变量名看大小:sizeof(变量) 代码示例: #include <iostream> using namespace std;in…...

GLM-4.1V-9B-Base部署教程:双GPU自动分层加载与nvidia-smi监控
GLM-4.1V-9B-Base部署教程:双GPU自动分层加载与nvidia-smi监控 1. 模型介绍 GLM-4.1V-9B-Base是智谱开源的一款强大的视觉多模态理解模型,专门设计用于处理图像内容识别、场景描述、目标问答和中文视觉理解任务。这个9B参数规模的模型在视觉理解方面表…...

MySQL从库出现数据同步异常中断_重新获取binlog坐标同步
SHOW SLAVE STATUS中Seconds_Behind_Master为NULL且IO/SQL线程为No,表明复制已中断而非延迟;需据Last_IO_Error或Last_SQL_Error类型采取对应措施:网络问题查连通性,SQL错误需确认数据一致性,binlog缺失则需重设坐标&a…...

Java开发者快速上手:Phi-4-mini-reasoning本地API调用集成教程
Java开发者快速上手:Phi-4-mini-reasoning本地API调用集成教程 1. 开篇:为什么选择Phi-4-mini-reasoning 如果你是一名Java开发者,最近可能已经注意到AI模型集成正在成为后端开发的新常态。Phi-4-mini-reasoning作为一款轻量级推理模型&…...