Pytorch学习 day07(神经网络基本骨架的搭建、2D卷积操作、2D卷积层)
神经网络基本骨架的搭建
- Module:给所有的神经网络提供一个基本的骨架,所有神经网络都需要继承Module,并定义_ _ init _ _方法、 forward() 方法
- 在_ _ init _ _方法中定义,卷积层的具体变换,在forward() 方法中定义,神经网络的前向传播具体是什么样的
- 官方代码样例如下:
import torch.nn as nn
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))
- 表明输入 x 经过一个卷积层A,一个非线性层a,一个卷积层B,一个非线性层b,最后输出,如下图:
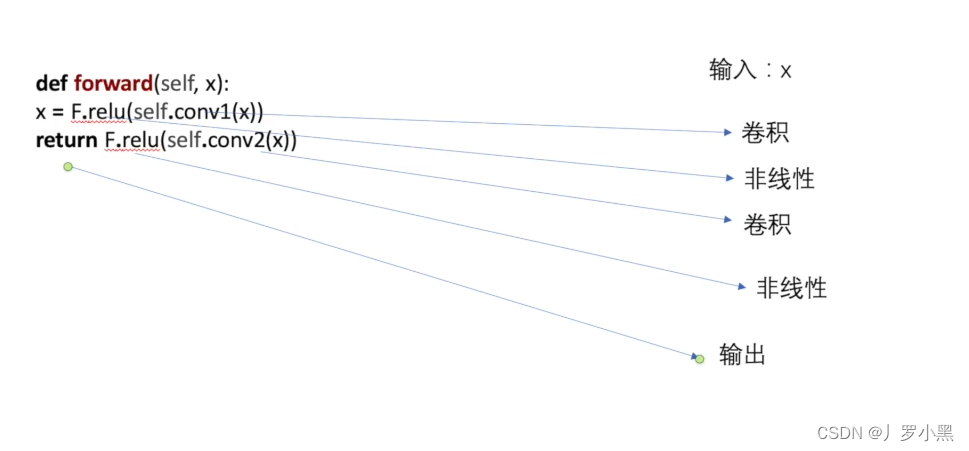
- 简单模型代码如下:
from torch import nn
import torch# 定义一个简单的Module
class Tudui(nn.Module):def __init__(self): # 初始化函数super().__init__() # 调用父类的初始化函数def forward(self, input): # 前向传播函数output = input + 1 # 定义张量的加法运算return output # 返回输出张量tudui = Tudui() # 实例化一个Tudui对象
x = torch.tensor(1.0) # tensor()函数可以将任意数据转换为张量
print(tudui(x))
* 注意:可以在调试模式中,选择单步执行代码,一步一步执行更清晰
2D卷积操作(了解原理即可,实际直接使用卷积层)
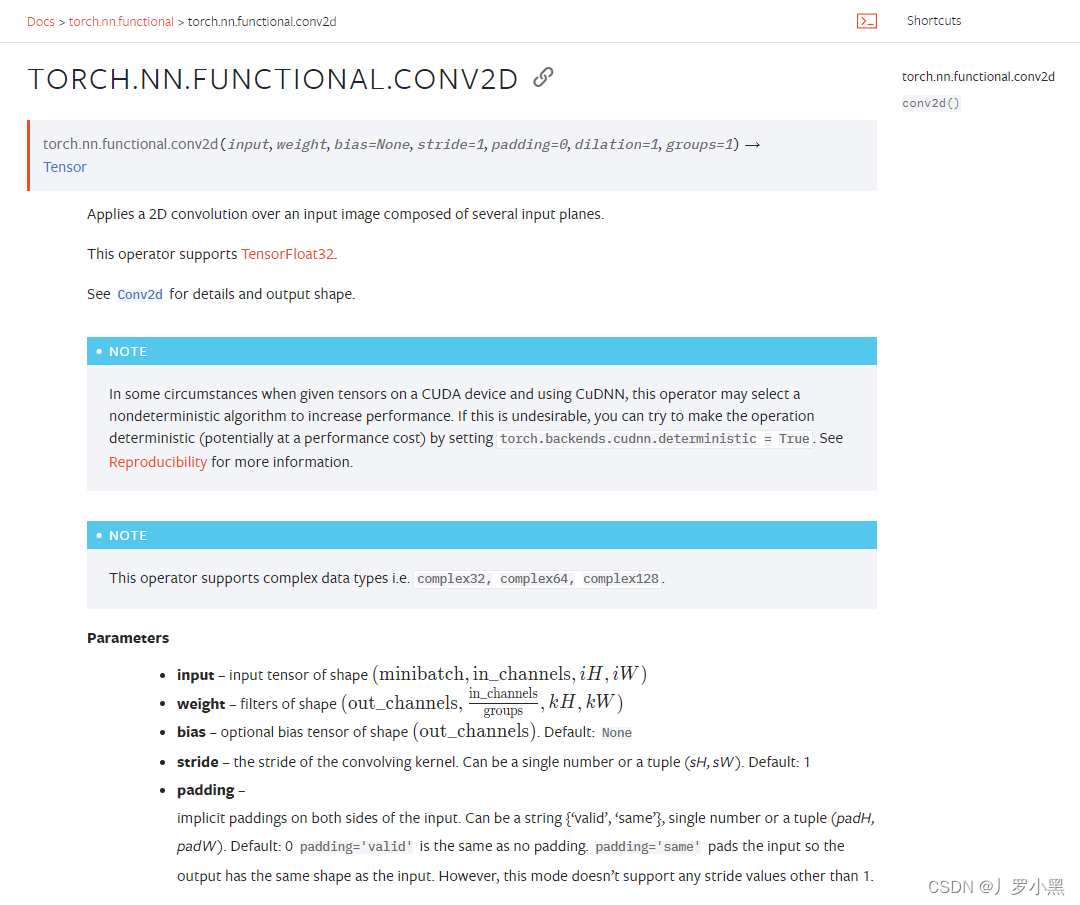
- 2D卷积操作:卷积核在输入图像上不断移动,并把对应位相乘再求和,最后得到输出结果,以下是参数设置:
- input:输入张量的维数要是四维,batch表示一次输入多少张图像,channel表示通道数,RGB图像的通道数为3,灰度图像(一层二维张量)的通道数为1,H为高度,W为宽度
- weight:卷积核,维数也要是四维,out_channel表示(输出通道数)卷积核的数量,in_channel表示输入图像的通道数,一般groups为1,H为高度,W为宽度
- stride:卷积核每次移动的步长(为整数或者长度为2的元组),如果是整数,表示在水平和垂直方向上使用相同的步长。如果是元组,分别表示在水平和垂直方向上的步长。默认为1。
- padding:控制在输入张量的边界周围添加的零填充的数量(为整数或长度为2的元组),如果是整数,表示在水平和垂直方向上使用相同的填充数量。如果是元组,分别表示在水平和垂直方向上的填充数量。默认为0
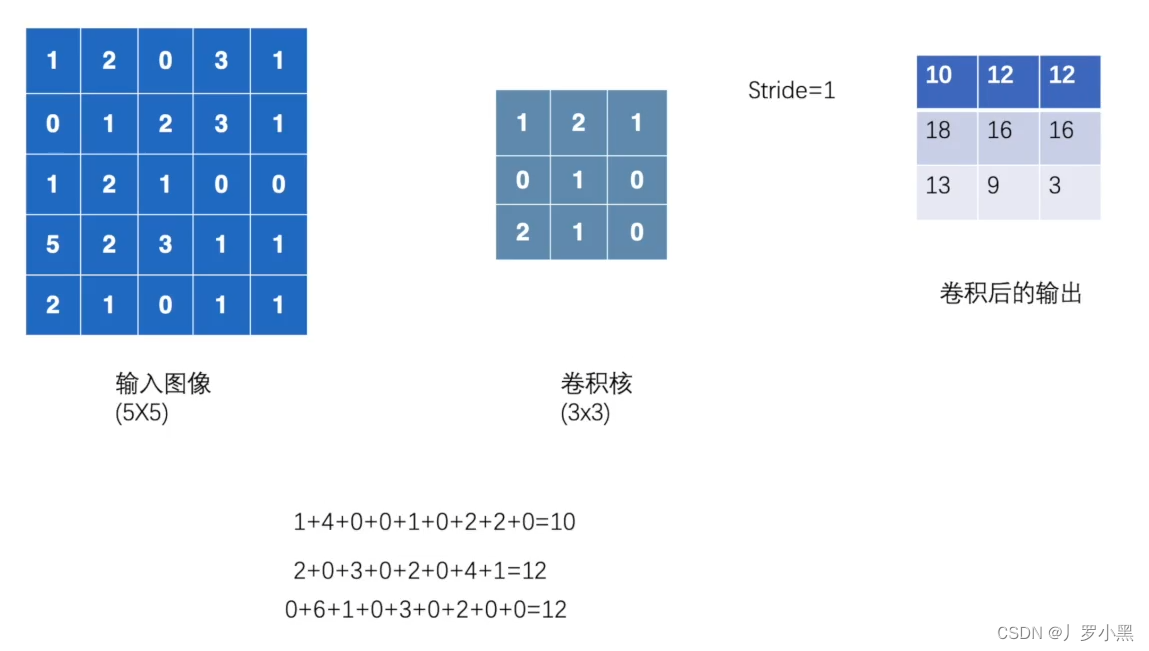
- 例如,将一张灰度图经过2D卷积操作得到输出的代码,如下:
import torch# 因为想让输入数据是tensor类型的,所以使用torch.tensor
input = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])# 因为想让卷积核是tensor类型的,所以使用torch.tensor
kernel = torch.tensor([[1,2,1],[0,1,0],[2,1,0]])
print(input.shape) # torch.Size([5, 5])
print(kernel.shape) # torch.Size([3, 3])# 由于卷积核的尺寸和输入的尺寸都不满足卷积运算的要求,所以需要对输入和卷积核进行维度的扩展
input = torch.reshape(input, [1,1,5,5]) # 输入是一张二维图片,所以batch_size=1(一张),通道数为1(二维张量)
kernel = torch.reshape(kernel, [1,1,3,3]) # 卷积核的个数为1,所以输出通道数为1,输入通道数由上可知为1print(input.shape) # torch.Size([1, 1, 5, 5])
print(kernel.shape) # torch.Size([1, 1, 3, 3])output = torch.nn.functional.conv2d(input, kernel, stride=1) # 经过2D卷积运算后的输出
print(output)
- 可视化图如下:
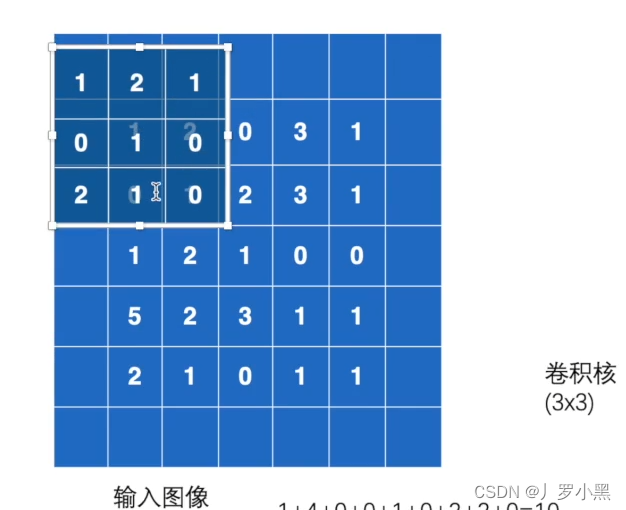
- padding设置为1的可视化图如下:
2D卷积层


- 2D卷积层,通常我们直接使用卷积层即可,上一节仅供了解,以下是参数设置:
- in_channels:输入通道数,RGB图像为3,灰度图像为1,一层二维张量为1
- out_channels:输出通道数,即卷积核的个数
- kernel_size:卷积核的高宽(整数或元组),整数时表示高宽都为该整数,元组时表示分别在水平和垂直方向上的长度。我们只需要设置卷积核的高宽,而卷积核内部的具体参数不需要我们指定,它是在神经网络的训练中不断地对分布进行采样,同时进行不断调整
- stride:卷积核每次移动的步长(整数或元组),整数时表示在水平和垂直方向上使用相同的步长。元组时分别表示在水平和垂直方向上的步长。默认为1。
- padding:控制在输入张量的边界周围添加的零填充的数量(为整数或元组),如果是整数,表示在水平和垂直方向上使用相同的填充数量。如果是元组,分别表示在水平和垂直方向上的填充数量。默认为0
- padding_mode:控制以什么样的模式进行填充,默认为 zeros 零填充
- dilation:卷积核内部元素之间的距离,空洞卷积
- groups:默认为1
- bias:给输出加一个偏置,默认为True
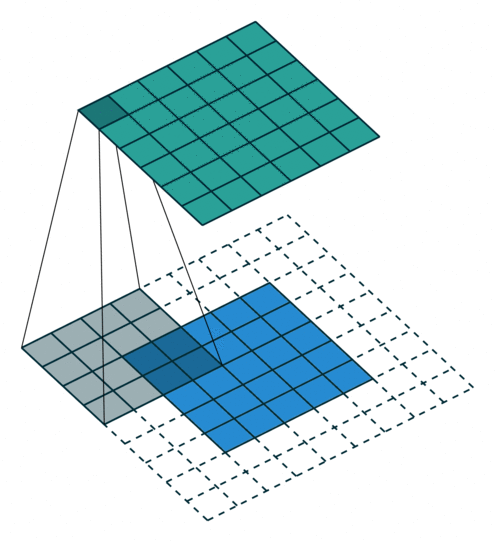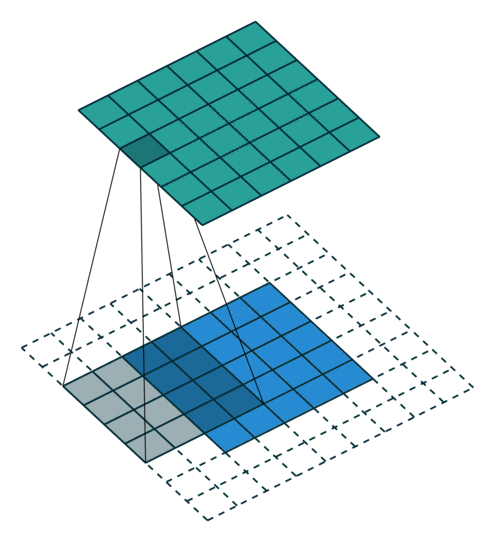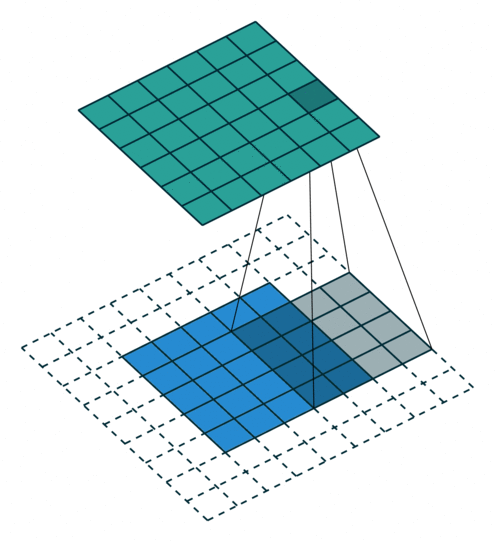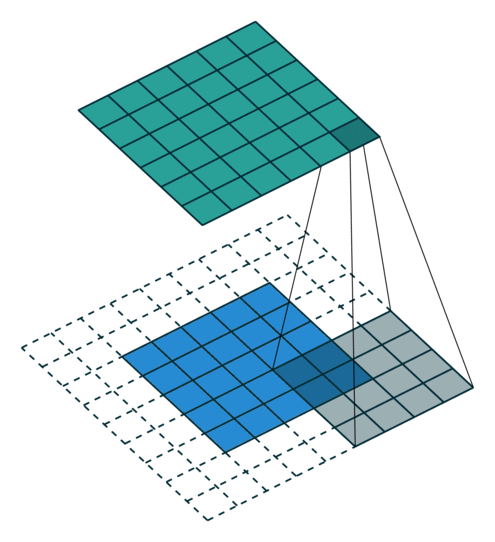
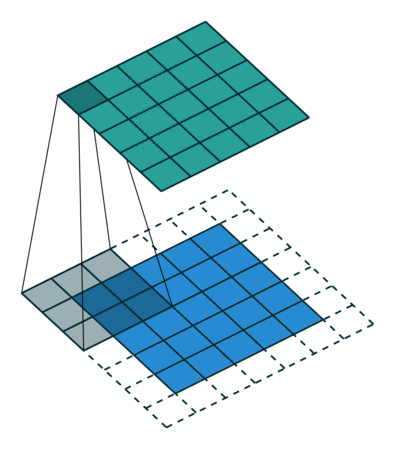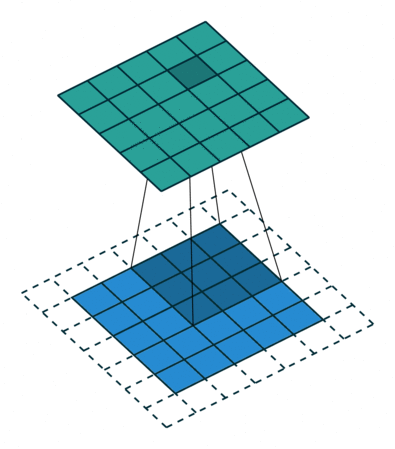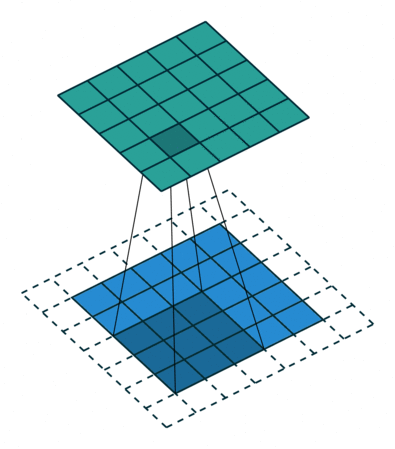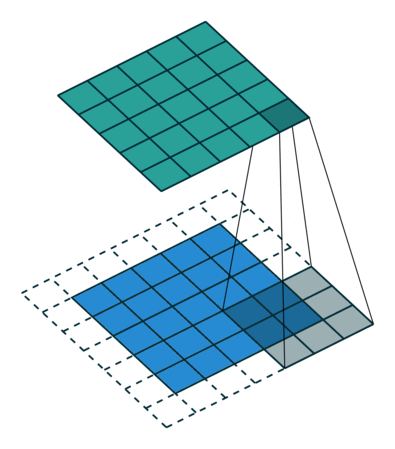
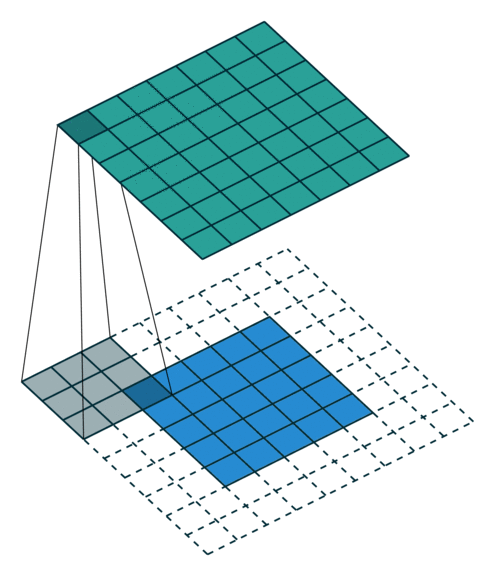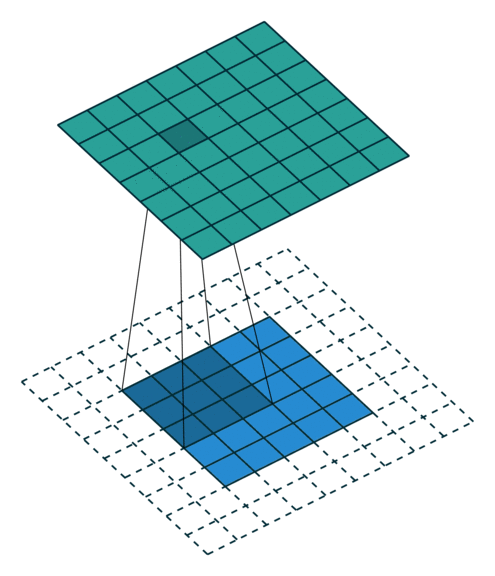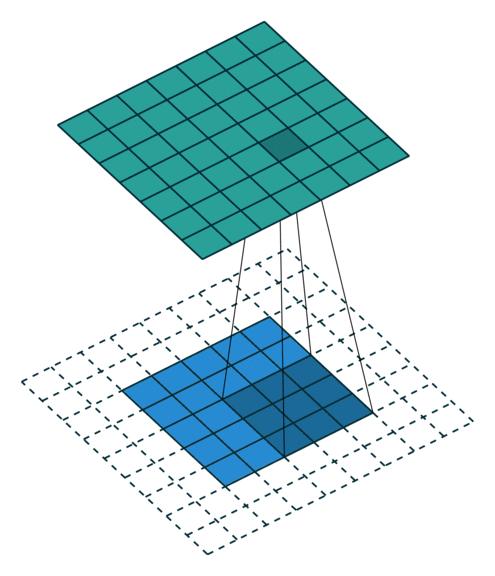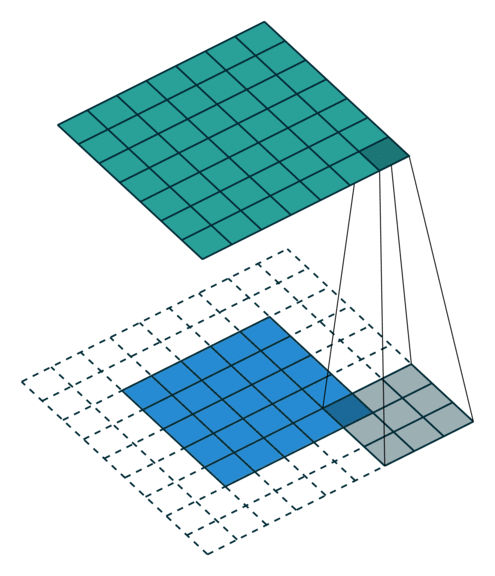
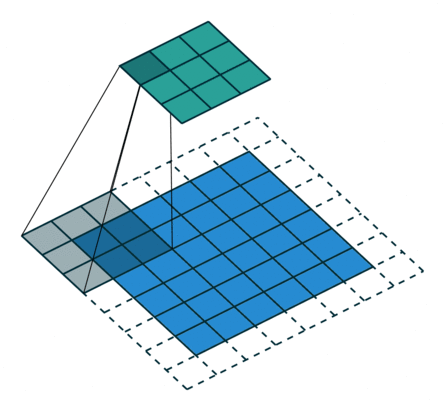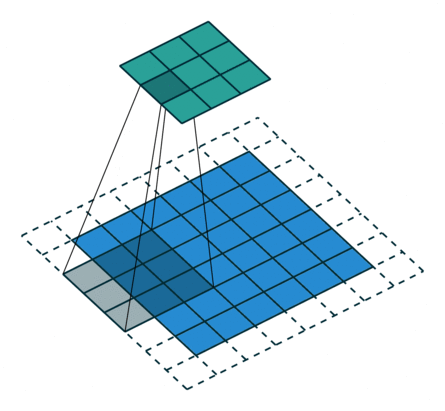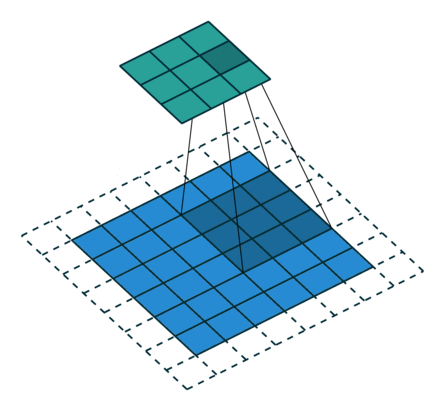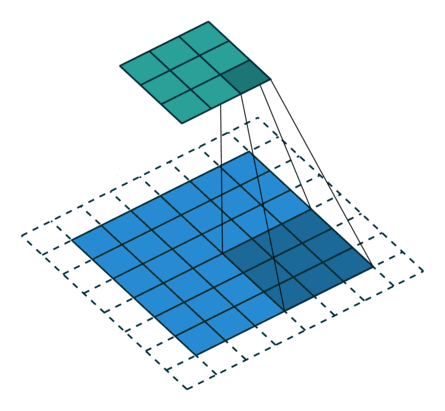
- 以下是2D卷积层的可视化图像,青色的为输出图像,蓝色为输入图像,深蓝色为卷积核:
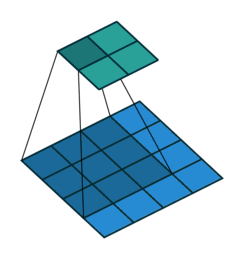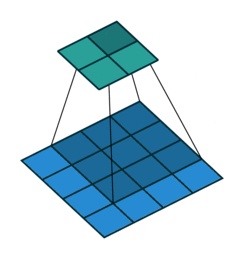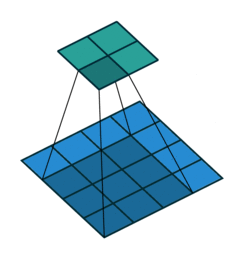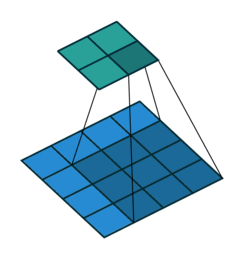 |  |
|---|---|
| No padding,No strides | Aribitrary padding,No strides |
 |  |
|---|---|
| Half padding,No strides | Full padding,No strides |
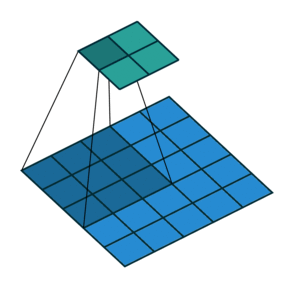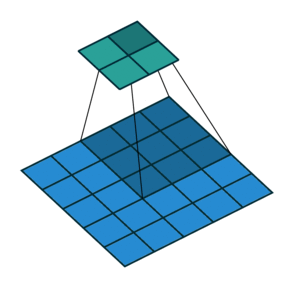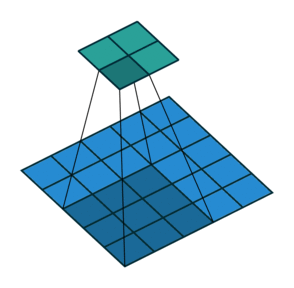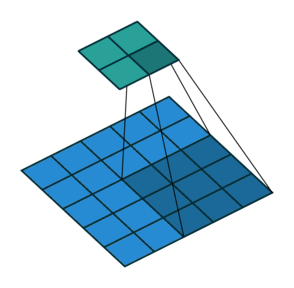 | 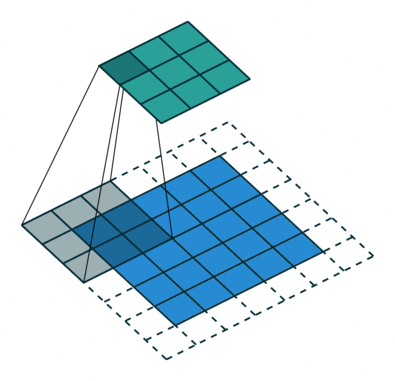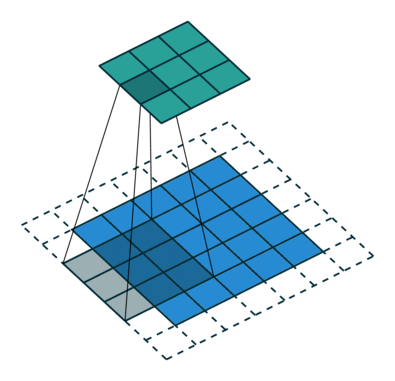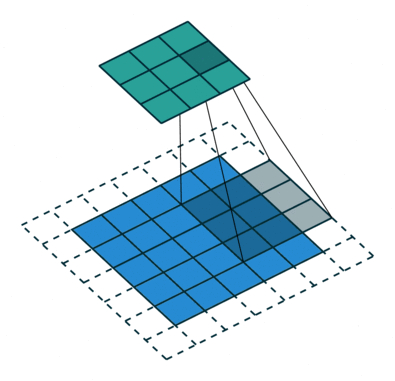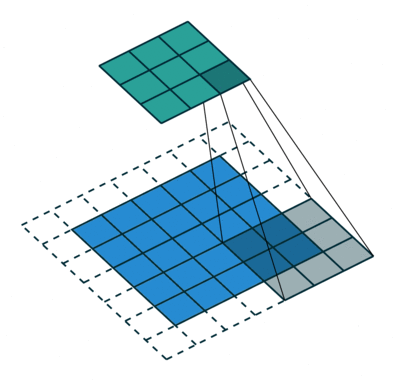 |  |
|---|---|---|
| No padding,strides | Padding,strides | Padding,strides(odd) |
- 当out_channel 为2时,卷积核也为2个,会先拿第一个卷积核与输入图像进行卷积,得到第一个输出,然后会拿第二个卷积核与输入图像进行卷积,得到第二个输出,这两个卷积核内部的具体参数可能会不同,最后把这两个输出叠加起来得到最终的输出,以下是可视化图像:
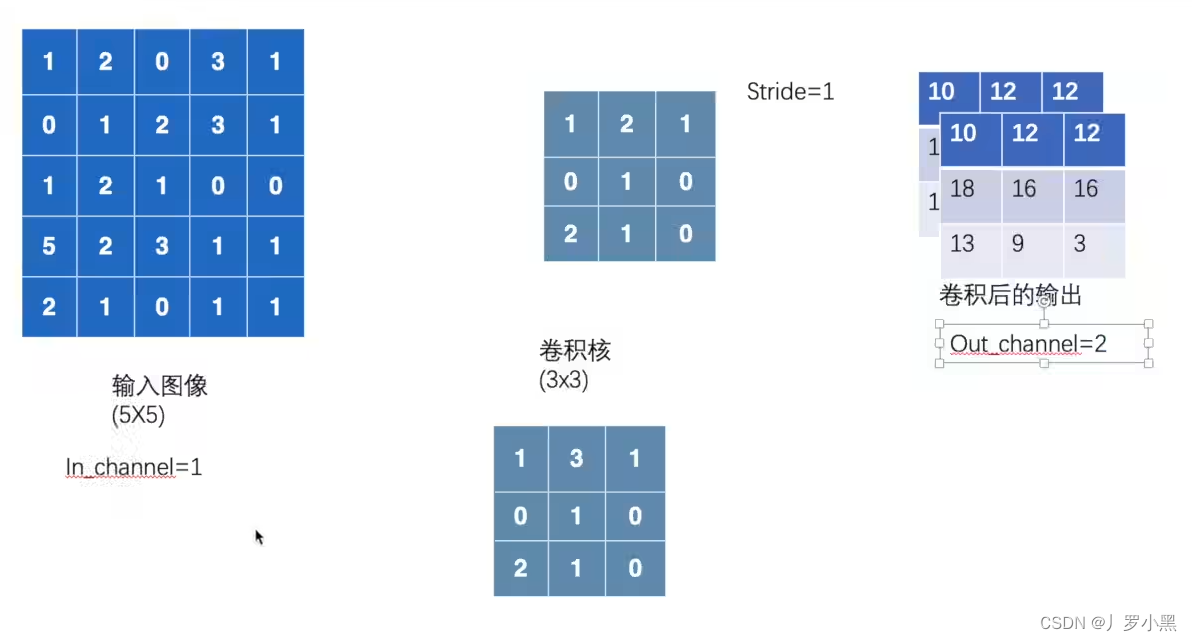
- 构建一个包含一层简单2D卷积层的神经网络模型,代码如下:
import torch
import torch.nn as nn
import torchvisiontest_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0)class Tudui(nn.Module):def __init__(self): # 初始化super().__init__() # 继承父类的初始化self.conv1 = nn.Conv2d(3, 6, 3, 1, 0) # 输入通道数3,输出通道数6,卷积核大小3*3,步长1,填充0def forward(self, x): # 前向传播x = self.conv1(x) # 调用卷积层对输入x进行卷积return xtudui = Tudui() # 实例化网络模型print(tudui) # 打印网络结构# 输出结果:
# Files already downloaded and verified
# Tudui(
# (conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
# )
- 打印输入和输出的代码如下:
- 注意:由于输入经过了一层卷积,所以输出尺寸会变小
for data in test_loader:imgs, targets = dataoutputs = tudui(imgs) # 调用网络模型进行前向传播print(imgs.shape) # 打印输入数据的形状,torch.Size([64, 3, 32, 32])print(outputs.shape) # 打印输出数据的形状,torch.Size([64, 6, 30, 30])
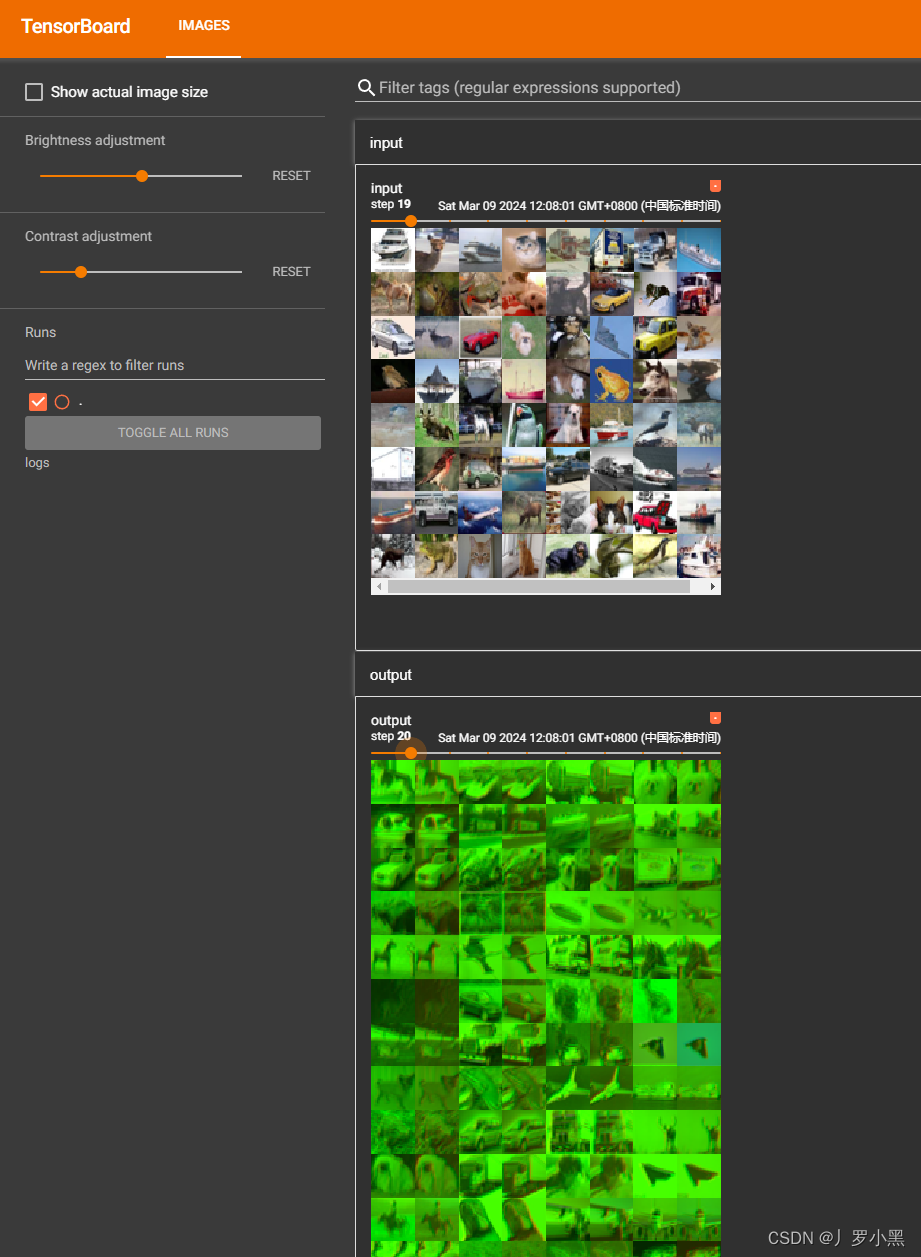
- 可以通过tensorboard来展示输入图像和输出图像,代码如下:
- 注意: 由于outputs的channel为6,而add_images函数要求channel为3,所以需要对outputs进行处理
- 把torch.Size([64, 6, 30, 30]) -> torch.Size([xx, 3, 30, 30]) 把6个通道变成3个通道,多出来的部分就打包放入batch_size中
- 如果不知道变换后的batch_size是多少,可以写-1,PyTorch会自动计算
import torch
import torch.nn as nn
import torchvision
from torch.utils.tensorboard import SummaryWritertest_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0)class Tudui(nn.Module):def __init__(self): # 初始化super().__init__() # 继承父类的初始化self.conv1 = nn.Conv2d(3, 6, 3, 1, 0) # 输入通道数3,输出通道数6,卷积核大小3*3,步长1,填充0def forward(self, x): # 前向传播x = self.conv1(x) # 调用卷积层对输入x进行卷积return xtudui = Tudui() # 实例化网络模型writer = SummaryWriter("logs") # 创建一个SummaryWriter对象,指定日志文件保存路径
step = 0
for data in test_loader:imgs, targets = dataoutputs = tudui(imgs) # 调用网络模型进行前向传播writer.add_images("input", imgs, step) # 将输入数据imgs写入日志文件# 由于outputs的channel为6,而add_images函数要求channel为3,所以需要对outputs进行处理# 把torch.Size([64, 6, 30, 30]) -> torch.Size([xx, 3, 30, 30]) 把6个通道变成3个通道,多出来的部分就打包放入batch_size中# 如果不知道变换后的batch_size是多少,可以使用-1,PyTorch会自动计算outputs = torch.reshape(outputs, (-1, 3, 30, 30)) # 将outputs的channel从6改为3writer.add_images("output", outputs, step) # 将输出数据outputs写入日志文件step += 1writer.close() # 关闭日志文件
- 结果如下:
- 注意:如果别人论文里没有写stride、padding具体为多少,那么我们可以根据以下式子进行推导:
- N:batch_size
- C:channel
- H:高
- W:宽

相关文章:
Pytorch学习 day07(神经网络基本骨架的搭建、2D卷积操作、2D卷积层)
神经网络基本骨架的搭建 Module:给所有的神经网络提供一个基本的骨架,所有神经网络都需要继承Module,并定义_ _ init _ _方法、 forward() 方法在_ _ init _ _方法中定义,卷积层的具体变换,在forward() 方法中定义&am…...
StarUML6.0.1使用
1. 简介 作为一个软件开发人员,平时免不了做一定的软件设计,标准做法就是采用UML来设计: 讨论功能流程时采用时序图、活动图来表达;做业务功能架构时采用组件图来表达;做系统部署架构时采用部署图来表达;做…...

Java开发与配置用到的各类中间件官网
开发配置时用到了一些官网地址,记录一下。 activemq 官网:ActiveMQ elk 官网:Elasticsearch 平台 — 大规模查找实时答案 | Elastic nginx 官网:nginx maven 官网:Maven – Welcome to Apache Maven nexus 官网&a…...
GitHub和Gitee的基本使用和在IDEA中的集成
文章目录 【1】GitHub1.创建仓库2.增加和修改文件3.创建分支4.删除仓库5.远程仓库下载到本地 【2】Gitee1.创建仓库2.远程仓库下载到本地. 【3】IDEA集成GitHub【4】IDEA集成Gitee1.在Gitee中修改,同步到本地2.从Gitee中下载项目 【1】GitHub 1.创建仓库 先登陆这…...

[Electron]中screen屏幕
Electron中screen 检索有关屏幕大小、显示器、光标位置等的信息。可以实现以下两个功能 窗口全屏 显示在额外显示器上 方法 screen.getCursorScreenPoint() 返回 Point当前鼠标的绝对位置。 screen.getPrimaryDisplay() 返回主窗口Display screen.getAllDisplays() 返…...
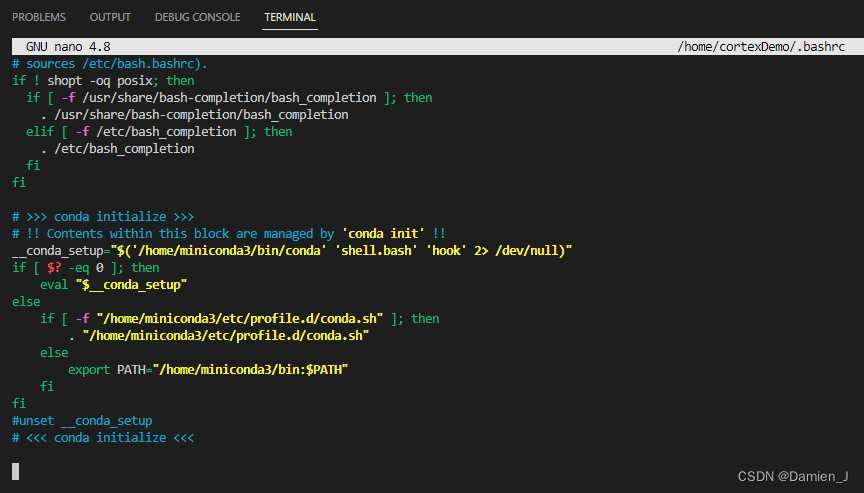
ubuntu 卸载miniconda3
一开始安装路径错了,需要重新安一次,就一起记录了。 前提是这种方式安装: ubuntu安装miniconda3管理python版本-CSDN博客 删除Miniconda的安装目录 这目录就是你选择安装的时候指定的,如果记不得了,可以这样查看 which conda 这…...

光致发光谱荧光量子效率测量系统
荧光量子积分球是一个专门用于测量荧光量子效率的设备。荧光量子效率是指物质吸收光后所发射的荧光光子数与所吸收的激发光光子数之间的比值。这种设备通过比较待测荧光物质和已知荧光量子产率的参比物质,在相同激发条件下所测得的积分荧光强度(即校正的…...

c++ 常用的STL
前言 写这篇博客目的是为了记录在刷算法题中使用过的STL,因为有些不太常用的会遗忘。这篇博客只是作为笔记,不是详细的STL,因此只会对常用方法说明,不会详细介绍。此外在后面用到新的STL内容时会再补充。 列队 基础列队 基本列…...

接口自动化测试思路和实战 —— 编写线性测试脚本实战!
接口自动化测试框架目的 测试工程师应用自动化测试框架的目的: 增强测试脚本的可维护性、易用性(降低公司自动化培训成本,让公司的测试工程师都可以开展自动化测试)。 自动化测试框架根据思想理念和深度不同,渐进式的分为以下几种: 线性脚本框架 模块…...

python控制语句-1.2
目录 循环结构 while循环 for循环 循环结构练习-1 循环嵌套 循环结构练习-2 循环控制语句(continue & break) 循环结构 while循环 语法 Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序&am…...

HTML 学习笔记(一)开始
一、介绍: 首先引用百度百科的一段话作为介绍: HTML的全称为超文本标记语言,是一种标记语言。它包括一系列标签,通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。HTML文本是由HTML命令组成的描述性文本…...

查看自己的ip地址的网站
有时候需要知道自己的ip地址,可以上这个网站查看: What Is My IP? Best Way To Check Your Public IP Address 网站的域名是https://www.whatismyip.com/ 还是挺好记的。...

ES分布式搜索-索引库操作
索引库操作 1、mapping映射属性 可以查看官方文档学习:ES官方手册 mapping是对索引库中文档的约束,常见的mapping属性包括: type:字段数据类型,常见的简单类型有: 字符串:text(可…...
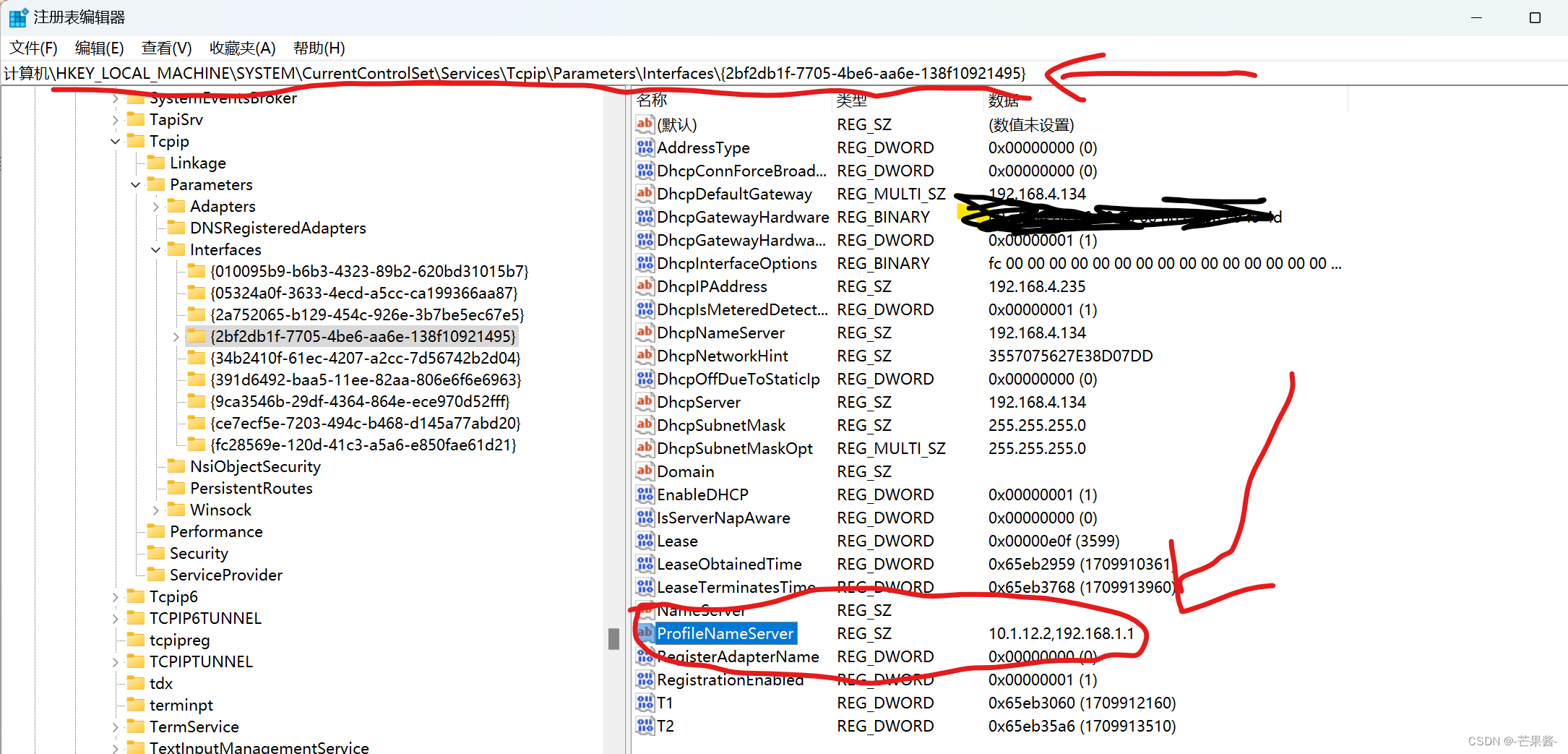
Win11 没有网络bug
1.问题描述 没有网络,dns一直是固定的,但是dns已经是自动获取了(MAC地址随机) 2.解决办法 1.首先,删除所有网络的手动dns配置,控制中心那个dns管理没有用,在设置中删除网络,不然问题还会出现 - 2.然后,进入注册表\HKEY_LOCAL_MACH…...

洛谷 1025.数的划分
这道题用的知识点是DFS剪枝。难的不在DFS上,而是在剪枝上如何选择。 思路:这道题我们看到是按照字典序排的,但是,我们注意到,看似是全排列的递归,实则不是。 我们前面也了解过,全排列的数字大…...

MySQL实战:SQL优化及问题排查
有更合适的索引不走,怎么办? MySQL在选取索引时,会参考索引的基数,基数是MySQL估算的,反映这个字段有多少种取值,估算的策略为选取几个页算出取值的平均值,再乘以页数,即为基数 查…...

加密与安全_使用Java代码操作RSA算法生成的密钥对
文章目录 Pre概述什么是非对称加密算法?如何工作?示例:RSA算法特点和优势ECC:另一种非对称加密算法 Code生成公钥和私钥私钥加密私钥加密私钥解密 ( 行不通 )私钥加密公钥解密公钥加密和公钥解密 (行不通)保…...

Spring Boot中实现图片上传功能的两种策略
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...

07.axios封装实例
一.简易axios封装-获取省份列表 1. 需求:基于 Promise 和 XHR 封装 myAxios 函数,获取省份列表展示到页面 2. 核心语法: function myAxios(config) {return new Promise((resolve, reject) > {// XHR 请求// 调用成功/失败的处理程序}) …...
【Linux】第四十一站:线程控制
一、Linux线程VS进程 1.进程和线程 进程是资源分配的基本单位线程是调度的基本单位线程共享进程数据,但也拥有自己的一部分数据:线程ID一组寄存器(上下文)栈errno信号屏蔽字调度优先级 2.进程的多个线程共享 同一地址空间,因此Text Segment、…...

C++函数模板:OOP中的万能利器
C 面向对象编程中的函数模板在C面向对象编程(OOP)中,类和对象是核心概念。函数模板是一种强大的特性,允许我们编写通用的、可复用的代码,适用于多种数据类型。结合OOP,函数模板可以用于类的方法中ÿ…...
告别DrawCall卡顿!Unity 2022最新Sprite Atlas图集打包保姆级教程(含旧版本迁移指南)
Unity 2022 Sprite Atlas图集优化全攻略:从原理到性能调优实战 最近在优化一个Unity项目时,发现UI界面在低端设备上频繁出现卡顿。通过Profiler分析,发现DrawCall数量高达200,而其中大部分都来自UI精灵的渲染。这让我重新审视了Sp…...

HarmonyOS原子化服务:轻量化应用的未来形态
这里写自定义目录标题HarmonyOS原子化服务:轻量化应用的未来形态引言:移动应用范式的第三次革命第一章:原子化服务的哲学思辨与技术演进1.1 从“应用商店”到“服务生态”的范式转移1.2 原子化服务的技术架构演进第二章:服务卡片&…...
)
别再只改YAML了!手把手教你从零实现YOLOv8的MSAM注意力模块(附完整代码)
从零构建YOLOv8的MSAM注意力模块:多尺度特征融合实战指南 在目标检测领域,YOLOv8凭借其出色的速度和精度平衡成为工业界的热门选择。但当你面对复杂场景中的多尺度目标时,是否发现模型对小物体或遮挡目标的检测效果不尽如人意?传统…...
)
为什么92%的“智慧交通”项目三年后停摆?AGI时代城市治理的3大认知断层与破局公式(内部推演纪要)
第一章:AGI驱动的城市交通治理范式革命 2026奇点智能技术大会(https://ml-summit.org) 传统交通治理长期受限于静态模型、滞后响应与孤岛式数据协同,而具备自主推理、多源语义理解与跨域决策能力的通用人工智能(AGI)正从根本上重…...

从网络到本地:根治Android/Flutter项目Gradle SSL连接重置的实战指南
1. 当Gradle遇上SSL连接重置:开发者的噩梦时刻 "又卡在Gradle下载了!"这可能是Android和Flutter开发者最常发出的抱怨之一。想象一下这样的场景:你刚接手一个老项目,满心欢喜地点击运行按钮,结果控制台突然抛…...

SpringBoot+Vue教务管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...
)
QtDataVisualization实战:用三维图表打造一个酷炫的数据仪表盘(附完整源码)
QtDataVisualization三维数据仪表盘开发实战 三维数据可视化在现代数据分析中扮演着越来越重要的角色。QtDataVisualization模块为开发者提供了强大的工具,能够将复杂数据转化为直观的三维图表。本文将带你从零开始,构建一个功能完善、视觉效果出色的数据…...

客户流失预警提前4.8小时达成!揭秘某电商AGI体验引擎中埋藏的6层实时反馈增强回路
第一章:AGI的客户服务与体验优化 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)正从根本上重塑客户服务的价值链——不再局限于响应式问答或流程自动化,而是以跨模态理解、长期记忆建模与自主目标推理能力&…...

A.每日一题:1855. 下标对中的最大距离
题目链接:1855. 下标对中的最大距离(中等) 算法原理: 解法一:二分查找 25ms击败5.31% 时间复杂度O(N logN) 以nums1数组的每个元素为基准,要想满足题述条件更新结果,那么nums2的下标 j 必须在 i…...