【基于springboot+Vue+Element ui的电影推荐之协同过滤算法简单实现】
基于springboot+Vue+Element ui的电影推荐之协同过滤算法简单实现
- 1.基于用户的协同过滤算法的简单设计与实现
- 1.1获取某个用户的评分矩阵
- 1.2获取该用户与其他用户的相似度矩阵
- 1.3获取两个用户之间的相似度并存储
- 1.4返回推荐列表
- 2.基于物品的协同过滤算法的简单设计与实现
- 2.1计算物品相似度
- 2.2生成推荐列表
- 3.完整的RecommendAlgorithmService文件
- 4.关于改进的思考
文件说明:
MovieSimilarityDao 功能是与电影相似度相关的操作
RatingMatrixDao 功能是与用户对电影的评分矩阵相关的数据操作
SimilarityDao 功能是与用户相似度矩阵相关的数据操作
MovieSimilarityService 功能是获取电影的相似度矩阵以及获取与当前电影的相似度最高的前若干部电影id
SimilarityService 功能是获取用户的相似度矩阵以及获取与当前用户的相似度最高的前若干个用户id
RatingMatrixService是查询某个用户的评分矩阵以及某个电影的评分矩阵,还有获取整个用户评分矩阵
RecommendAlgorithmService 功能是两种协同过滤算法的简单实现
项目采用springboot+Vue+Element ui,mysql 8.0,以及Maven项目管理工具,持久层框架是MyBatis,建议采用注解开发
1.基于用户的协同过滤算法的简单设计与实现
思路:先获取用户评分矩阵,再计算根据余弦相似度计算公式计算用户之间的相似度获取相似度矩阵,然后给出推荐列表。
1.1获取某个用户的评分矩阵
getRating方法是根据用户id获取该用户的评分矩阵
public List<Map<Integer,Double>> getRating(Integer userid){//获取某个用户的评分矩阵List<Map<Integer,Double>> ratings=ratingMatrixService.getRatings(userid);System.out.println("该用户的评分矩阵:"+ratings);return ratings;}
评分实体类如下:
import lombok.*;
import org.springframework.stereotype.Component;@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class RatingMatrix {//评分矩阵实体类private Integer userid;private Integer movieId;private Double rating;
}获取该用户的评分矩阵
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class RatingMatrixService {@Resourceprivate JdbcTemplate jdbcTemplate;public RatingMatrixService(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}public List<Map<Integer, Double>> getRatings(Integer userid) {//获取用户评分矩阵String query = "SELECT userid, movieId, rating FROM ratings where userid="+userid;List<Map<Integer, Double>> userRatings = new ArrayList<>();jdbcTemplate.query(query, rs -> {while (rs.next()) {int movieId = rs.getInt("movieId");double rating = rs.getDouble("rating");// 将评分数据存入MapMap<Integer, Double> userRatingMap = new HashMap<>();userRatingMap.put(movieId, rating);// 将Map添加到List中userRatings.add(userRatingMap);}});return userRatings;}public List<Map<Integer, Double>> getRatingsByMovieId(Integer movieId) {//获取电影评分矩阵String query = "SELECT userid, rating FROM ratings where movieId="+movieId;List<Map<Integer, Double>> ratings = new ArrayList<>();List<Map<String, Object>> movieRatings = jdbcTemplate.queryForList(query);for(Map<String, Object> row:movieRatings){int userid = (int) row.get("userid");double rating = (double) row.get("rating");// 将评分数据存入MapMap<Integer, Double> movieRatingMap = new HashMap<>();movieRatingMap.put(userid,rating);// 将Map添加到List中ratings.add(movieRatingMap);}return ratings;}public List<Map<Integer, Map<Integer, Double>>> getRatingMatrix() {//获取整个用户评分矩阵List<Map<Integer, Map<Integer, Double>>> ratingMatrix = new ArrayList<>();String sql = "SELECT * FROM ratings";List<Map<String, Object>> rows = jdbcTemplate.queryForList(sql);for (Map<String, Object> row : rows) {int userid = (int) row.get("userid");int movieId = (int) row.get("movieId");double rating = (double) row.get("rating");Map<Integer, Double> movieRatings = new HashMap<>();movieRatings.put(movieId, rating); // 将电影ID放在前面boolean found = false;for (Map<Integer, Map<Integer, Double>> userRatings : ratingMatrix) {if (userRatings.containsKey(userid)) {userRatings.get(userid).put(movieId, rating); // 将用户ID放在前面found = true;break;}}if (!found) {Map<Integer, Map<Integer, Double>> userRatingsMap = new HashMap<>();userRatingsMap.put(userid, movieRatings); // 将用户ID放在前面ratingMatrix.add(userRatingsMap);}}return ratingMatrix;}}
1.2获取该用户与其他用户的相似度矩阵
用户相似度的实体类如下
import lombok.*;
import org.springframework.stereotype.Component;@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class Similarity {//用户相似度实体类private Integer userid1;private Integer userid2;private double similarity;
}
获取相似度矩阵
public List<Map<Integer,Double>> getSimilarity(Integer userid){//获取用户的相似度矩阵List<Map<Integer,Double>> similarities=similarityService.getSimilarities(userid);System.out.println("用户相似度矩阵:"+similarities);return similarities;}
其中的SimilarityService.java如下
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.*;@Service
public class SimilarityService {@Resourceprivate JdbcTemplate jdbcTemplate;public List<Map<Integer, Double>> getSimilarities(Integer userid1){//获取用户相似度矩阵String query = "SELECT userid2, similarity FROM similarities where userid1='" + userid1 + "'";List<Map<Integer, Double>> userSimilarity = new ArrayList<>();List<Map<String, Object>> resultList = jdbcTemplate.queryForList(query);for (Map<String, Object> row : resultList) {int userid2 = (int) row.get("userid2");double similarity = (double) row.get("similarity");// 将评分数据存入MapMap<Integer, Double> userRatingMap = new HashMap<>();userRatingMap.put(userid2, similarity);// 将Map添加到List中userSimilarity.add(userRatingMap);}return userSimilarity;}//遍历相似度矩阵找出相似度最高的前五个用户public List<Integer> getTopFiveSimilarUsers(List<Map<Integer,Double>> similarityMatrix){List<Integer> topFiveUsers = new ArrayList<>();// 将相似度矩阵转换为一个包含所有相似度的列表List<Double> allSimilarities = new ArrayList<>();for (Map<Integer, Double> userSimilarities : similarityMatrix) {for (Double similarity : userSimilarities.values()) {allSimilarities.add(similarity);}}// 对相似度进行快速排序allSimilarities.sort(Collections.reverseOrder());// 取出前五个相似度最高的用户for (int i = 0; i < Math.min(5, allSimilarities.size()); i++) {Double similarity = allSimilarities.get(i);for (Map<Integer, Double> userSimilarities : similarityMatrix) {for (Map.Entry<Integer, Double> entry : userSimilarities.entrySet()) {if (entry.getValue().equals(similarity) && !topFiveUsers.contains(entry.getKey())) {topFiveUsers.add(entry.getKey());break;}}}}return topFiveUsers;}
}
1.3获取两个用户之间的相似度并存储
public Double getSimilarity(Integer user1,Integer user2){//获取两个用户之间的相似度CollaborativeFiltering collaborativeFiltering=new CollaborativeFiltering();List<Map<Integer, Double>> list1 = ratingMatrixService.getRatings(user1);//2List<Map<Integer, Double>> list2 = ratingMatrixService.getRatings(user2);//5double similarity = collaborativeFiltering.calculateSimilarity(list1,list2);Similarity similarity1=new Similarity(user1,user2,similarity);//存储用户相似度similarityDao.addSimilarity(similarity1);System.out.println("用户"+user1+"和用户"+user2+"之间的相似度为:"+similarity);return similarity;}
其中的CollaorativeFiletering.java如下
import java.util.*;
public class CollaborativeFiltering {//采用余弦相似度计算公式计算两个用户的相似度public Double calculateSimilarity(List<Map<Integer, Double>> list1, List<Map<Integer, Double>> list2){//计算用户相似度// 计算余弦相似度double dotProduct = 0.0;double normA = 0.0;double normB = 0.0;for (Map<Integer, Double> map1 : list1) {for (Map<Integer, Double> map2 : list2) {for (Map.Entry<Integer, Double> entry1 : map1.entrySet()) {for (Map.Entry<Integer, Double> entry2 : map2.entrySet()) {if (entry1.getKey().equals(entry2.getKey())) {dotProduct += entry1.getValue() * entry2.getValue();normA += Math.pow(entry1.getValue(), 2);normB += Math.pow(entry2.getValue(), 2);}}}}}if (normA == 0 || normB == 0) {return 0.0; // 避免除以零}double similarity = dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));return similarity;}
}
这里采用的是余弦相似度计算公式计算用户的相似度,具体内容点击这里
1.4返回推荐列表
public Set<Integer> getRecommendList(Integer userid){System.out.println("获取推荐列表");//获取用户相似度矩阵List<Map<Integer,Double>> similarities=similarityService.getSimilarities(userid);//遍历该相似度矩阵找出最相似的前五个用户idList<Integer> userids=similarityService.getTopFiveSimilarUsers(similarities);//把这些用户喜欢的电影,评分高的电影推荐给当前用户//获取这些用户喜欢的电影Set<Integer> movieids=movieService.getUsersLikedMovies(userids);//获取这些用户里评分最高的电影idSet<Integer> movieids1=movieService.getMaxRatingMovie(userids);//把两个集合合并并去重movieids.addAll(movieids1);System.out.println("电影的推荐列表为:"+movieids);return movieids;}
2.基于物品的协同过滤算法的简单设计与实现
原理是物品A与物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B,因此先计算两个item的相似度,再基于物品相似度以及用户喜好的item类型生成推荐列表。
2.1计算物品相似度
public double calculateItemSimilarity(Integer movie1,Integer movie2){//计算两个电影的相似度CollaborativeFiltering collaborativeFiltering=new CollaborativeFiltering();//获取电影1和电影2的评分集合List<Map<Integer,Double>> list1=ratingMatrixService.getRatingsByMovieId(movie1);List<Map<Integer,Double>> list2=ratingMatrixService.getRatingsByMovieId(movie2);System.out.println(list1);System.out.println(list2);//计算电影1和电影2的余弦相似度double similarity=collaborativeFiltering.calculateSimilarity(list1,list2);//存储电影相似度movieSimilarityDao.addMovieSimilarity(movie1,movie2,similarity);return similarity;}
这里同样采用余弦相似度计算公式计算两个电影的相似度,值得注意的是从数据库里查询到的结果需要先存到Map集合里再存到list里
2.2生成推荐列表
public Set<Integer> getRecommendMovieList(Integer movieId){//获取与该电影的推荐列表System.out.println("获取电影的推荐列表");//获取电影相似度矩阵List<Map<Integer,Double>> similarities=movieSimilarityService.getSimilarities(movieId);//遍历该相似度矩阵找出最相似的前十个电影idList<Integer> movieids=movieSimilarityService.getTopTenSimilarMovies(similarities);//把和当前电影相似度高的电影推荐给用户Set<Integer> recommendMovieList=new HashSet<>();if(movieids.isEmpty()){//按电影类型推荐String movieType=movieService.getMovieByType(movieId);List<String> movieTypes=splitStringByComma(movieType);for(String type:movieTypes){Set<Integer> typeMovies=movieService.getMoviesByType(type,movieId);System.out.println("该类型电影为:"+typeMovies);recommendMovieList.addAll(typeMovies);}}else{String movieType=movieService.getMovieByType(movieId);List<String> movieTypes=splitStringByComma(movieType);for(String type:movieTypes){Set<Integer> typeMovies=movieService.getMoviesByType(type,movieId);recommendMovieList.addAll(typeMovies);}recommendMovieList.addAll(movieids);}return recommendMovieList;}
其中的MovieSimilarityService.java如下:
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.*;@Service
public class MovieSimilarityService {@Resourceprivate JdbcTemplate jdbcTemplate;public List<Map<Integer, Double>> getSimilarities(Integer movieId1){//获取电影相似度矩阵String query = "SELECT movieId2, similarity FROM moviesimilarity where movieId1='" + movieId1+ "'";List<Map<Integer, Double>> movieSimilarity = new ArrayList<>();List<Map<String, Object>> resultList = jdbcTemplate.queryForList(query);for (Map<String, Object> row : resultList) {int movieId2 = (int) row.get("movieId2");double similarity = (double) row.get("similarity");// 将评分数据存入MapMap<Integer, Double> movieRatingMap = new HashMap<>();movieRatingMap.put(movieId2, similarity);// 将Map添加到List中movieSimilarity.add(movieRatingMap);}return movieSimilarity;}public List<Integer> getTopTenSimilarMovies(List<Map<Integer, Double>> similarityMatrix) {List<Integer> topTenMovies = new ArrayList<>();// 将相似度矩阵转换为一个包含所有相似度的列表List<Double> allSimilarities = new ArrayList<>();for (Map<Integer, Double> movieSimilarities : similarityMatrix) {for (Double similarity : movieSimilarities.values()) {allSimilarities.add(similarity);}}// 对相似度进行快速排序allSimilarities.sort(Collections.reverseOrder());// 取出前五个相似度最高的用户for (int i = 0; i < Math.min(10, allSimilarities.size()); i++) {Double similarity = allSimilarities.get(i);for (Map<Integer, Double> movieSimilarities : similarityMatrix) {for (Map.Entry<Integer, Double> entry : movieSimilarities.entrySet()) {if (entry.getValue().equals(similarity) && !topTenMovies.contains(entry.getKey())) {topTenMovies.add(entry.getKey());break;}}}}return topTenMovies;}
}
3.完整的RecommendAlgorithmService文件
import com.example.Dao.MovieSimilarityDao;
import com.example.Dao.SimilarityDao;
import com.example.entity.Similarity;
import com.example.utils.CollaborativeFiltering;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.*;@Service
public class RecommendAlgorithmService{//推荐算法的完整过程@Resourceprivate RatingMatrixService ratingMatrixService;@Resourceprivate SimilarityService similarityService;@Resourceprivate SimilarityDao similarityDao;@Resourceprivate MovieService movieService;@Resourceprivate MovieSimilarityDao movieSimilarityDao;@Resourceprivate MovieSimilarityService movieSimilarityService;//(1)基于用户的协同过滤算法的简单设计与实现//1.获取用户评分矩阵//2.计算用户之间的相似度,获取相似度矩阵//3.给出推荐列表public List<Map<Integer,Double>> getRating(Integer userid){//获取某个用户的评分矩阵List<Map<Integer,Double>> ratings=ratingMatrixService.getRatings(userid);System.out.println("该用户的评分矩阵:"+ratings);return ratings;}public List<Map<Integer,Double>> getSimilarity(Integer userid){//获取用户的相似度矩阵List<Map<Integer,Double>> similarities=similarityService.getSimilarities(userid);System.out.println("用户相似度矩阵:"+similarities);return similarities;}public List<Map<Integer,Map<Integer,Double>>> getRatingMatrix(){//获取整个评分矩阵List<Map<Integer,Map<Integer,Double>>> mapList=ratingMatrixService.getRatingMatrix();System.out.println("整个用户的评分矩阵:"+mapList);return mapList;}public Double getSimilarity(Integer user1,Integer user2){//获取两个用户之间的相似度CollaborativeFiltering collaborativeFiltering=new CollaborativeFiltering();List<Map<Integer, Double>> list1 = ratingMatrixService.getRatings(user1);//2List<Map<Integer, Double>> list2 = ratingMatrixService.getRatings(user2);//5double similarity = collaborativeFiltering.calculateSimilarity(list1,list2);Similarity similarity1=new Similarity(user1,user2,similarity);//存储用户相似度similarityDao.addSimilarity(similarity1);System.out.println("用户"+user1+"和用户"+user2+"之间的相似度为:"+similarity);return similarity;}public Set<Integer> getRecommendList(Integer userid){System.out.println("获取推荐列表");//获取用户相似度矩阵List<Map<Integer,Double>> similarities=similarityService.getSimilarities(userid);//遍历该相似度矩阵找出最相似的前五个用户idList<Integer> userids=similarityService.getTopFiveSimilarUsers(similarities);//把这些用户喜欢的电影,评分高的电影推荐给当前用户//获取这些用户喜欢的电影Set<Integer> movieids=movieService.getUsersLikedMovies(userids);//获取这些用户里评分最高的电影idSet<Integer> movieids1=movieService.getMaxRatingMovie(userids);//把两个集合合并并去重movieids.addAll(movieids1);System.out.println("电影的推荐列表为:"+movieids);return movieids;}//(2)基于物品的协同过滤算法的简单设计与实现//物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B//1.计算物品之间的相似度//2.基于物品的相似度和用户的喜好生成推荐列表public double calculateItemSimilarity(Integer movie1,Integer movie2){//计算两个电影的相似度CollaborativeFiltering collaborativeFiltering=new CollaborativeFiltering();//获取电影1和电影2的评分集合List<Map<Integer,Double>> list1=ratingMatrixService.getRatingsByMovieId(movie1);List<Map<Integer,Double>> list2=ratingMatrixService.getRatingsByMovieId(movie2);System.out.println(list1);System.out.println(list2);//计算电影1和电影2的余弦相似度double similarity=collaborativeFiltering.calculateSimilarity(list1,list2);//存储电影相似度movieSimilarityDao.addMovieSimilarity(movie1,movie2,similarity);return similarity;}public Set<Integer> getRecommendMovieList(Integer movieId){//获取与该电影的推荐列表System.out.println("获取电影的推荐列表");//获取电影相似度矩阵List<Map<Integer,Double>> similarities=movieSimilarityService.getSimilarities(movieId);//遍历该相似度矩阵找出最相似的前十个电影idList<Integer> movieids=movieSimilarityService.getTopTenSimilarMovies(similarities);//把和当前电影相似度高的电影推荐给用户Set<Integer> recommendMovieList=new HashSet<>();if(movieids.isEmpty()){//按电影类型推荐String movieType=movieService.getMovieByType(movieId);List<String> movieTypes=splitStringByComma(movieType);for(String type:movieTypes){Set<Integer> typeMovies=movieService.getMoviesByType(type,movieId);System.out.println("该类型电影为:"+typeMovies);recommendMovieList.addAll(typeMovies);}}else{String movieType=movieService.getMovieByType(movieId);List<String> movieTypes=splitStringByComma(movieType);for(String type:movieTypes){Set<Integer> typeMovies=movieService.getMoviesByType(type,movieId);recommendMovieList.addAll(typeMovies);}recommendMovieList.addAll(movieids);}return recommendMovieList;}public List<String> splitStringByComma(String input) {//将电影类型按照逗号分割// 检查输入字符串是否为空if (input == null || input.isEmpty()) {return Collections.emptyList();}// 使用逗号分隔字符串,并返回结果return Arrays.asList(input.split(","));}
}
4.关于改进的思考
可以看到当前我们的功能里面采用余弦相似度计算公式计算物品相似度的时候会出问题。为什么呢?首先,以图书为例,如果两个用户都买过新华字典,这丝毫不能说明他们爱好相似,因为我们小时候曾经都买过新华字典但如果两个用户都买过数据挖掘导论,那么可以认为他们爱好比较相似,因为只有研究数据挖掘的人才会买这本书。换句话说,两个用户对冷门物品的相似购买行为更能说明用户之间的相似度,因此可以继续在此基础上基于用户行为计算用户的爱好相似度,这里不再赘述,请自行搜索各位大佬的相似度改进方法。
关于代码只是自己关于协同过滤算法的简单实现,若有错误或者需要改进的地方欢迎各位大佬给出宝贵意见。
相关文章:

【基于springboot+Vue+Element ui的电影推荐之协同过滤算法简单实现】
基于springbootVueElement ui的电影推荐之协同过滤算法简单实现 1.基于用户的协同过滤算法的简单设计与实现1.1获取某个用户的评分矩阵1.2获取该用户与其他用户的相似度矩阵1.3获取两个用户之间的相似度并存储1.4返回推荐列表 2.基于物品的协同过滤算法的简单设计与实现2.1计算…...

签约仪式如何策划和安排流程?如何邀约媒体现场见证报道
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 签约仪式的策划和安排流程,以及邀约媒体现场见证报道,都是确保活动成功和提升影响力的关键环节。以下是一些建议: 签约仪式的策划和安排流程 明确目标…...
k8s-生产级的k8s高可用(1) 24
高可用集群 实验至少需要三个master(控制节点),一个可以使外部可以访问到master的load balancer(负载均衡)以及一个或多个外部节点worker(也要部署高可用)。 再克隆三台主机 清理并重启 配置两…...

python中lambda简介及用法
什么是lambda? lambda是python中的一个关键字,它用于创建匿名函数,也就是没有名字的函数。lambda函数通常用于一些简单的操作,比如作为参数传递给其他函数,或者作为返回值返回给调用者。lambda函数的语法如下…...

AI新工具 百分50%算力确达到了GPT-4水平;将音乐轨道中的人声、鼓声、贝斯等音源分离出来等
1: Pi 百分50%算力确达到了GPT-4水平 Pi 刚刚得到了巨大的升级!它现在由最新的 LLMInflection-2.5 提供支持,它在所有基准测试中都与 GPT-4 并驾齐驱,并且使用不到一半的计算来训练。 地址:https://pi.ai/ 2: Moseca 能将音乐…...

websocket前端应用
基本了解 首先要对websocket有一个基本了解:WebSocket是一种在Web浏览器和Web服务器之间创建持久连接的技术。它允许在客户端和服务器之间进行全双工通信,而不需要在每次通信时都发起新的HTTP请求。主要作用包括实时通信、减少延迟、减少宽带消…...

SpringMVC05、结果跳转方式
5、结果跳转方式 5.1、ModelAndView 设置ModelAndView对象 , 根据view的名称 , 和视图解析器跳到指定的页面 . 页面 : {视图解析器前缀} viewName {视图解析器后缀} <!-- 视图解析器 --> <bean class"org.springframework.web.servlet.view.InternalResourc…...

STM32基础--位带操作
位带简介 位操作就是可以单独的对一个比特位读和写,这个在 51 单片机中非常常见。51 单片机中通过关键字 sbit 来实现位定义,STM32 没有这样的关键字,而是通过访问位带别名区来实现。 在 STM32 中,有两个地方实现了位带ÿ…...

C# winform 重启电脑
一、重启电脑指令 windows7系统的启动文件夹为“开始菜单”——“所有程序”里面就有“启动”文件夹,其位置是 “C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup” 如果没有,则需要将其中的"administrator…...

波奇学Linux: 信号捕捉
sigaction:修改信号对应的handler方法 act输入型参数,oldact输出型参数 void (*sa_handler) (int) //修改的自定义函数 sigset_t sa_mask // void handler(int signo) {cout<<"catch a signal, signal number: "<<signo<<endl; } int …...
Flink hello world
下载并且解压Flink Downloads | Apache Flink 启动Flink. $ ./bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host harrydeMacBook-Pro.local. Starting taskexecutor daemon on host harrydeMacBook-Pro.local. 访问localhost:8081 Flin…...
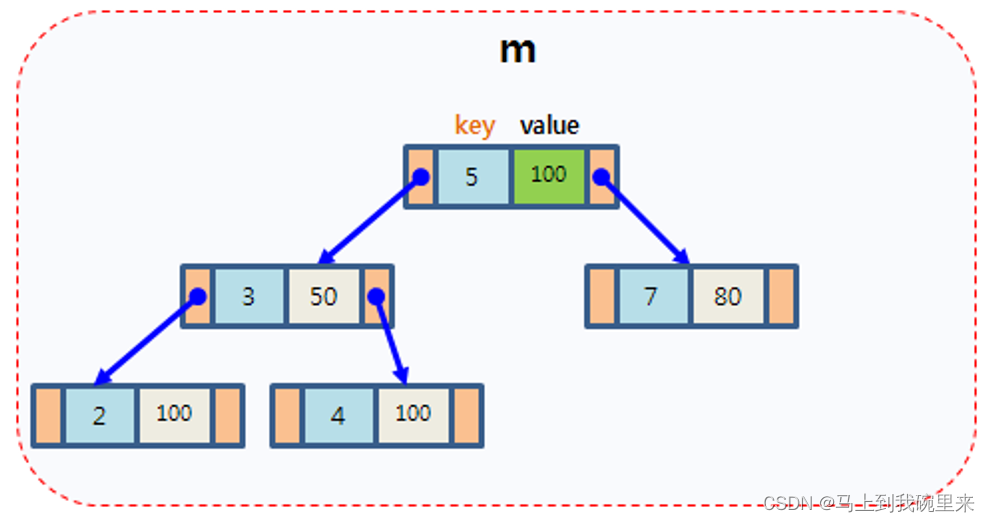
STL之map容器代码详解
基础概念 简介: map中所有元素都是pair。pair中第一个元素为key(键值),起到索引作用,第二个元素为value(实值)。所有元素都会根据元素的键值自动排序。 本质: map/multimap属于关…...
使用GRU进行天气变化的时间序列预测
本文基于最适合入门的100个深度学习项目的学习记录,同时在Google clolab上面是实现,文末有资源连接 天气变化的时间序列的难点 天气变化的时间序列预测涉及到了一系列复杂的挑战,主要是因为天气系统的高度动态性和非线性特征。以下是几个主…...

uniapp 小程序AP配网
一、TCPSocket.js 封装TCP协议 class socket {constructor() {this.connection {};}// 创建一个TCP实例establish(monitor) {this.connection wx.createTCPSocket();this.connection.connect({ address: "000.000.0.0", port: 6800 });}// 发送消息connect(messag…...
Stable Diffusion ———LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo等版本之间关系现原理详解
一、简介 2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffusion Models,DM)在图像生成领域开始超越传统的GAN模型,进一步推动了DM的应用。 然而,早期的DM直接作用于像…...

GESP5级T1真题 [202309] 因数分解——O(sqrt(n))的时间复杂度,值得一看
描述 每个正整数都可以分解成素数的乘积,例如:62*3、2022 *5 现在,给定一个正整数N,请按要求输出它的因数分解式。 输入描述 输入第一行,包含一个正整数N。约定2<N<10^12 输出描述 输出一行,为N…...

Stable Diffusion 3报告
报告链接:https://stability.ai/news/stable-diffusion-3-research-paper 文章目录 要点表现架构细节通过重新加权改善整流流量Scaling Rectified Flow Transformer Models灵活的文本编码器RF相关论文 要点 发布研究论文,深入探讨Stable Diffuison 3的…...

一个足球粉丝该怎么建个个人博客?
做一个个人博客第一步该怎么做? 好多零基础的同学们不知道怎么迈出第一步。 那么,就找一个现成的模板学一学呗,毕竟我们是高贵的Ctrl c v 工程师。 但是这样也有个问题,那就是,那些模板都,太!…...

缩放算法优化步骤详解
添加链接描述 背景 假设数据存放在在unsigned char* m_pData 里面,宽和高分别是:m_nDataWidth m_nDataHeight 给定缩放比例:fXZoom fYZoom,返回缩放后的unsigned char* dataZoom 这里采用最简单的缩放算法即: 根据比…...

[axios]使用指南
axios使用指南 Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中。 axios 安装 npm安装 $ npm install axios 使用cdn <script src"https://unpkg.com/axios/dist/axios.min.js"></script> axios API axios(config)…...

CANoe COM接口深度探索:如何像查字典一样使用Type Library和对象层次图
CANoe COM接口深度探索:如何像查字典一样使用Type Library和对象层次图 当你在深夜调试CANoe自动化脚本时,是否曾被满屏的"Method not found"错误折磨得抓狂?作为经历过数百小时COM接口调试的老手,我发现大多数开发者卡…...
)
50元搞定远程开机:米家智能插座+BIOS设置保姆级教程(附休眠模式小技巧)
50元实现远程开机:智能插座BIOS设置全攻略 远程办公和数字游民生活方式的兴起,让远程控制电脑成为刚需。但传统方案要么价格昂贵,要么设置复杂。今天分享一个成本仅50元、稳定性极高的解决方案——智能插座配合BIOS设置,让你随时随…...
)
告别‘不安全’警告!5分钟搞定内网开发HTTPS,用mkcert生成本地SSL证书(保姆级教程)
5分钟实现本地开发HTTPS:mkcert实战指南 每次在localhost调试网页时,那个刺眼的"不安全"警告是否让你烦躁?作为开发者,我们清楚这只是本地测试环境,但浏览器可不会区别对待。传统自签名证书需要手动导入CA的…...
)
S32K144时钟配置避坑指南:手把手教你用S32DS的clock_manager组件搞定外设时钟(附代码)
S32K144时钟配置实战:从原理到避坑的完整指南 第一次接触S32K144的时钟系统时,我被它的灵活性震惊了——但随之而来的是配置时的迷茫。记得有一次调试FlexCAN模块,程序莫名其妙地进入复位中断循环,花了整整两天才发现是时钟门控没…...
)
告别手动点点点:用Python+pywin32脚本化你的CANoe自动化测试(附完整代码)
Pythonpywin32实现CANoe自动化测试的工程实践 每次手动点击CANoe界面执行重复测试时,我总想起第一次在产线看到测试工程师机械地重复操作——他们像被编程的机器人,而真正的机器人却闲置在一旁。这种场景在汽车电子测试领域并不罕见,直到我发…...

3分钟看懂B站评论区:你的专属“读心“助手
3分钟看懂B站评论区:你的专属"读心"助手 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-checker 你是否…...

目标检测精度上不去?试试YOLOv4/PP-YOLOE都在用的CSPNet Backbone配置实战
目标检测精度上不去?试试YOLOv4/PP-YOLOE都在用的CSPNet Backbone配置实战 在工业级目标检测任务中,模型精度和推理速度的平衡始终是开发者面临的终极难题。当你在COCO数据集上反复调整数据增强参数却收效甚微时,或许该把注意力转向更本质的B…...
下属的质量管理和质量保证技术委员会(ISO/TC 176)制定的国际质量管理体系标准)
ISO 9000系列标准是由国际标准化组织(ISO)下属的质量管理和质量保证技术委员会(ISO/TC 176)制定的国际质量管理体系标准
ISO 9000系列标准是由国际标准化组织(ISO)下属的质量管理和质量保证技术委员会(ISO/TC 176)制定的国际质量管理体系标准,旨在帮助各类组织建立、实施和优化质量管理体系,提升产品和服务质量,增强…...

赋能AR/VR应用:Lingbot-Depth-Pretrain-ViTL-14实现实时场景理解与交互
赋能AR/VR应用:Lingbot-Depth-Pretrain-ViTL-14实现实时场景理解与交互 最近几年,增强现实和虚拟现实的应用越来越多了,从手机上的趣味滤镜到专业的工业设计,都能看到它们的身影。但不知道你有没有发现,很多AR效果看起…...

用MCNP模拟NaI探测器:从137铯源设置到能谱分析的全流程实战
用MCNP模拟NaI探测器:从137铯源设置到能谱分析的全流程实战 在核技术研究领域,精确模拟探测器响应是实验设计的关键环节。NaI(Tl)闪烁体探测器因其高探测效率和良好的能量分辨率,成为测量伽马射线的首选设备之一。本文将带你完成一个完整的MC…...