Stable Diffusion ———LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo等版本之间关系现原理详解
一、简介
2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffusion Models,DM)在图像生成领域开始超越传统的GAN模型,进一步推动了DM的应用。
然而,早期的DM直接作用于像素空间,这意味着要优化一个强大的DM通常需要数百个GPU天,而推理成本也很高,因为需要多次迭代。为了在有效的计算资源上训练DM,并保持其质量和灵活性,作者提出将DM应用于强大的预训练自动编码器的潜空间(Latent Space),这也是为什么提出的模型叫LDM的原因。与以往的方法相比,这种方式首次实现了在降低复杂性和保留细节之间的平衡,并显著提高了视觉逼真度。
此外,作者还在模型中引入了交叉注意力层,使得可以轻松地将文本、边界框等条件引入到模型中,将DM转化为强大而灵活的生成器,实现高分辨率的生成。作者提出的LDM模型在图像修复、条件生成等任务中表现良好,并且与基于像素空间的扩散模型相比,大大降低了计算要求。在Stable Diffusion(LDM)的基础上,SDXL将U-Net主干扩大了三倍:主要是使用了第二个文本编码器,因此还使用了更多的注意力块和交叉注意力上下文。此外,作者设计了多分辨率训练方案,训练了具有不同长宽比的图像。他们还引入了一个细化模型,以进一步提高生成图像的视觉逼真度。结果表明,与之前的Stable Diffusion版本相比,SDXL的性能有了显著提升,并且取得了与其他非开源模型相当的效果。这个模型和代码都是完全开源的。
在SDXL的基础上,作者提出了对抗性扩散蒸馏技术(Adversarial Diffusion Distillation,ADD),将扩散模型的步数减少到1-4步,同时保持很高的图像质量。结果表明,这个模型在1步生成方面明显优于现有的几步生成方法,并且仅用4步就超越了最先进的SDXL性能。这个训练出的模型被称为SDXL-Turbo。
二、 Latent Diffusion Model(LDM)
LDM 和其他扩散生成模型的结构类似,其结构包括自编码器、条件部分和降噪 U-Net,总体上包括三个主要组件:
1. 自编码器(Auto Encoder)
- 编码器(Encoder):将输入图像编码为低维度的表示,通常称为隐变量或隐向量。这一步的目的是将输入数据压缩到一个更紧凑的表示,捕捉输入数据的主要特征。
- 解码器(Decoder):将编码后的低维表示解码为原始图像。解码器的作用是从隐变量中重建输入数据,使得重建图像尽可能地接近原始输入。
2.条件部分(Conditioning)
- 用于对各种条件信息进行编码,以辅助生成过程。这些条件信息可以是多样化的,比如文本描述、图像修复或分割条件等。
- 不同类型的条件需要不同的编码器模型,以便将它们转换为嵌入向量。这些嵌入向量将会被整合到生成过程中。
- 在生成过程中,这些条件信息可以通过连接(Concatenation)或注意力机制与噪声或隐变量相结合,以影响生成图像的特征。
3. 降噪 U-Net(Denoising U-Net)
- 用于从随机噪声中生成隐变量,并通过多步迭代的方式逐渐改进这些隐变量,以便生成最终的图像。
- 这个过程通常涉及到 U-Net 结构,它是一种常见的用于图像生成和修复的神经网络结构,具有编码器-解码器的形式,并且在中间包含跨层连接,以帮助保留图像的细节信息。
- 在生成过程中,各种条件信息通过交叉注意力机制与隐变量相结合,以确保生成的图像能够与条件信息匹配。
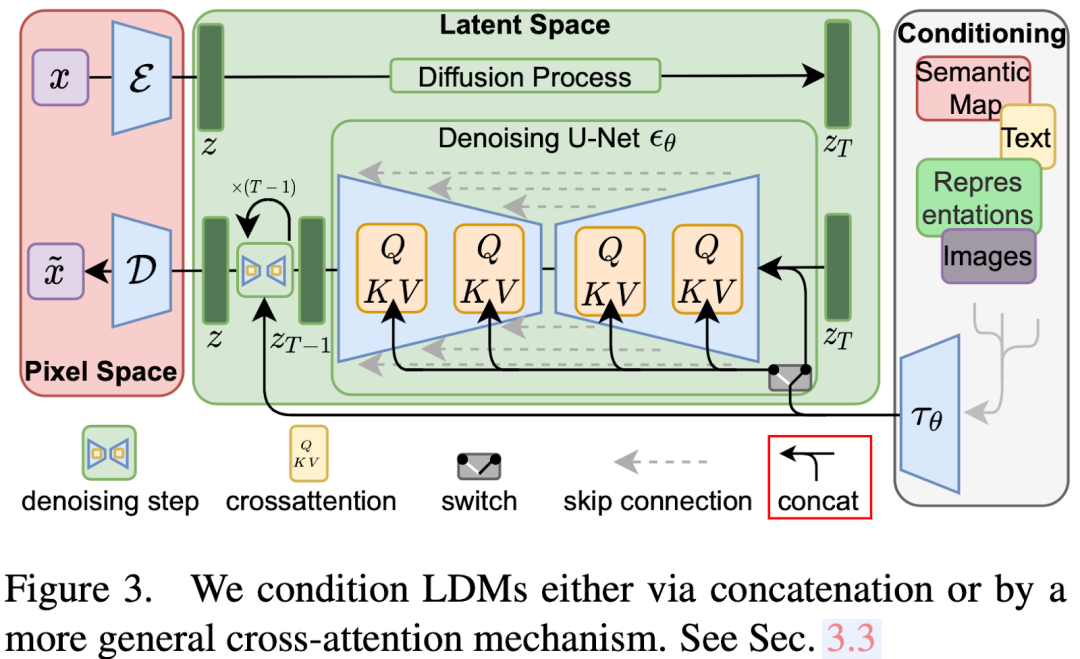
在AutoEncoder中,Encoder用于对图像进行压缩,生成latent code。假设输入图像的分辨率为HxW,则压缩率为f时,对应的latent code大小为H/f x W/f。举例来说,如果图像分辨率为512x512,那么f=4时的压缩率对应的latent code大小为64x64,即z的大小为64x64。
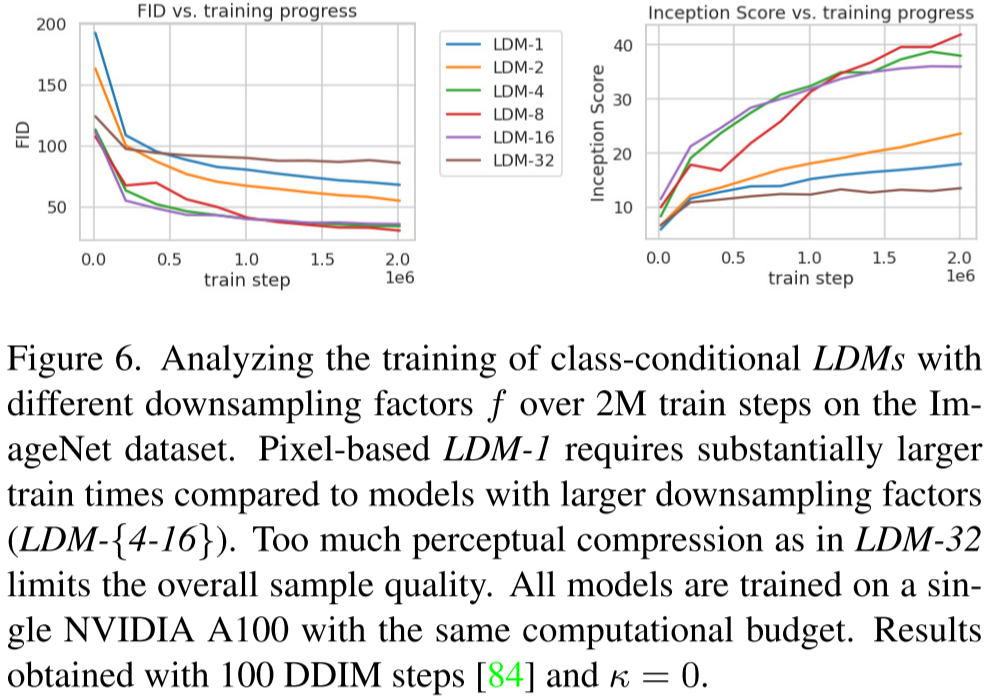
作者进行了一系列实验,探究不同压缩率下的模型性能,对应的模型命名为LDM-{f},包括LDM-1、LDM-2、LDM-4、LDM-8、LDM-16和LDM-32。在这个命名规则下,LDM-1相当于没有压缩,直接作用于像素空间;而LDM-32则是压缩率最高的情况,512x512分辨率的图像对应的latent code大小只有16x16。
实验结果显示,在压缩率为4、8和16时,模型获得了最佳平衡点,这意味着在生成图像质量和模型复杂度之间找到了一个合适的折中点。然而,当压缩率为32时,生成图像的质量下降,这可能是因为压缩率太高,导致信息丢失,latent code无法捕捉到足够多的图像信息,从而影响了生成图像的质量。
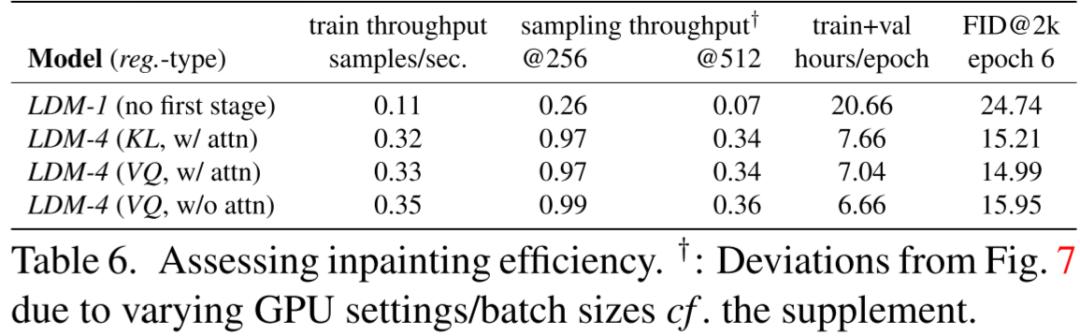
如下图 Table 6 所示,作者同样在图像修复任务上验证了不同压缩率、Cross Attention 的影响,可以看出 LDM-4 的训练、推理吞吐相比 LDM-1 有明显提升,并且 Attention 对吞吐的影响也不大。同时 LDM-4 还获得更好的效果(更低的 FID):
4. Latent Diffusion Models
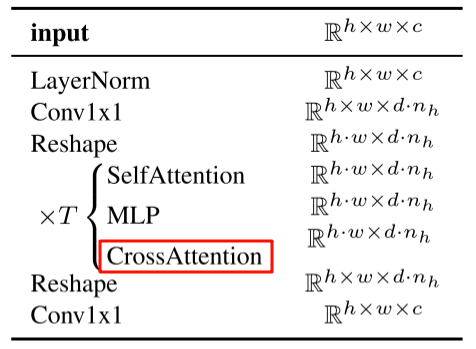
本文中作者使用的 U-Net 模型是基于 OpenAI Diffusion Models Beat GANs 中的 Ablated U-Net 修改而来,具体来说是将其中的 Self-Attention 替换为 T 个 Transformer block,每个 block 中包含一个 Self-Attention,一个 MLP 和一个 Cross-Attention,如下图所示,其中的 Cross Attention 就是用于和其他条件的 embedding 进行交叉融合:
5. Conditioning 机制
LDM 支持多种条件类型,比如类别条件、文本条件、分割图条件、边界框条件等。
对于文本条件,可以使用常用的文本 Encoder,比如 Bert 模型,或者 CLIP 的 Text Encoder,其首先将文本转换为 Token,然后经过模型后每个 Token 都会对应一个 Token embedding,所以文本条件编码后变为一个 Token embedding 序列。
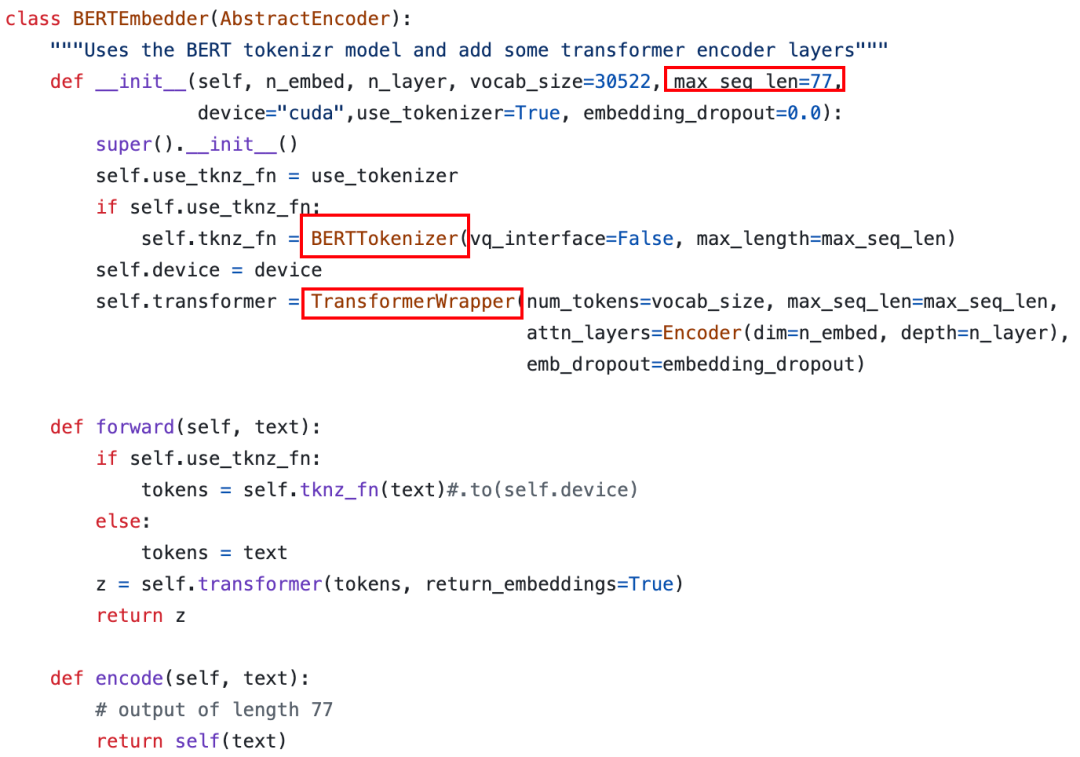
对于 layout 条件,比如常见的边界框,每个边界框都会以(l,b,c)的方式编码,其中 l 表示左上坐标,b 表示右下坐标,c 表示类别信息。
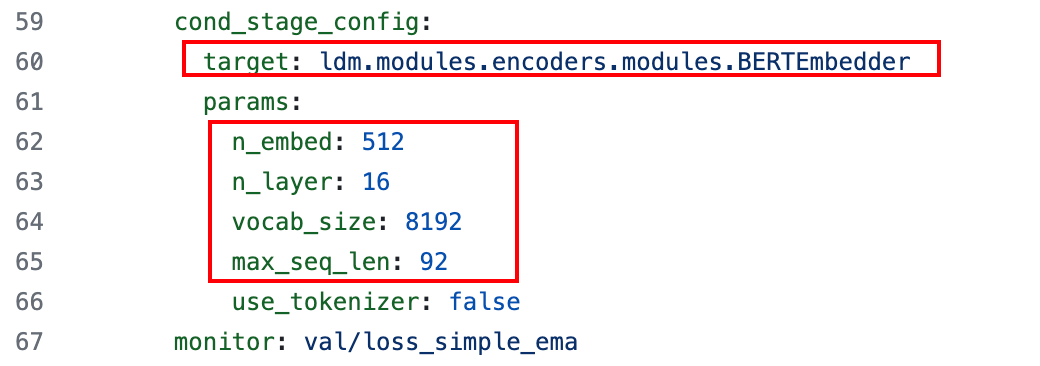
对于类别条件,每个类别都会以一个可学习的 512 维向量表示,同样通过 Cross-Attention 机制融合。
对于分割图条件,可以将图像插值、卷积后编码为 feature map,然后作为条件。



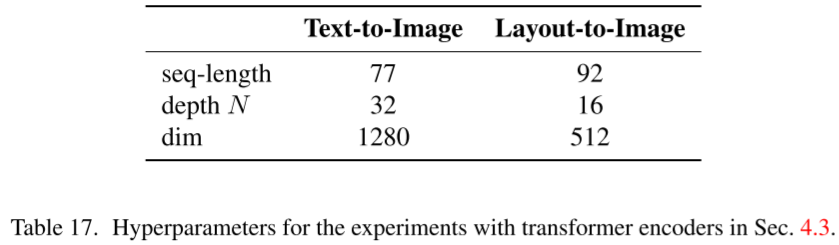
其中文本条件和 layout 条件都通过 Transformer Encoder 编码,对应的超参如下图 Table 17 所示,也就是文本最多只能编码为 77 个 Token,Layout 最多编码为 92 个 Token:
所谓的 layout-to-image 生成如下图所示,给定多个边界框,每个边界框有个类别信息,生成的图像要在对应的位置生成对应的目标:

6. 实验结果
3.5.1. 无条件生成
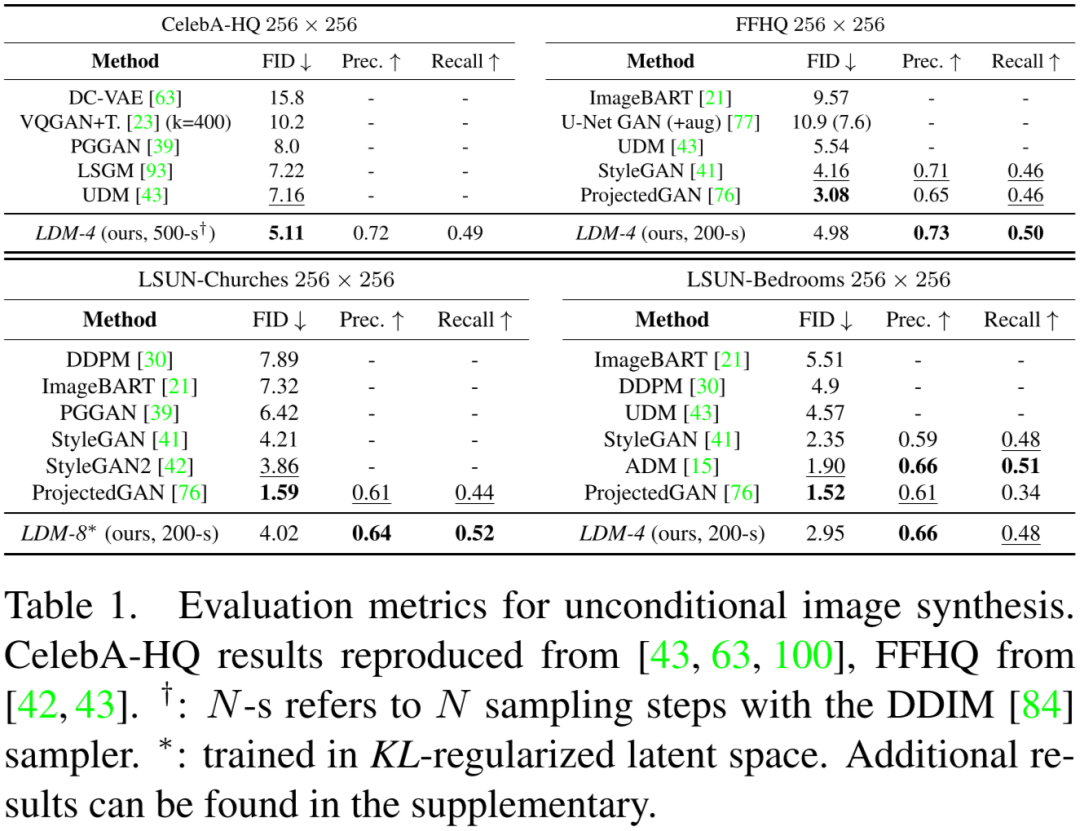
如下图 Table 1 所示,作者在多个任务上评估了 LDM-4 和 LDM-8 的无条件图像生成效果,可以看出,在大部分任务上都获得了很不错的结果:
5.2. 类别条件生成
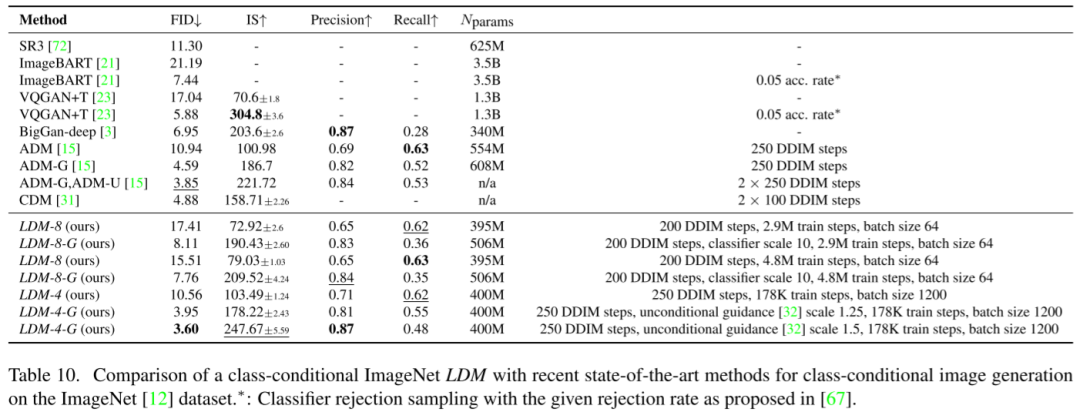
如下图 Table 3 所示,作者同样在 ImageNet 上与 ADM(Diffusion Model Beat GANs)等模型进行了类别条件图像生成对比,可见在 FID 和 IS 指标上获得了最优或次优的结果:
7.LDM-BSR
作者同样将 BSR-degradation 应用到超分模型的训练,获得了更好的效果,BSR degradation Pipeline 包含 JPEG 压缩噪声、相机传感器噪声、针对下采样的不同图像插值方法,高斯模糊核以及高斯噪声,并以随机顺序应用于图像(具体可参考代码 https://github.com/CompVis/stable-diffusion/blob/main/ldm/modules/image_degradation/bsrgan_light.py),最终获得了不错的效果:

8. 计算需求
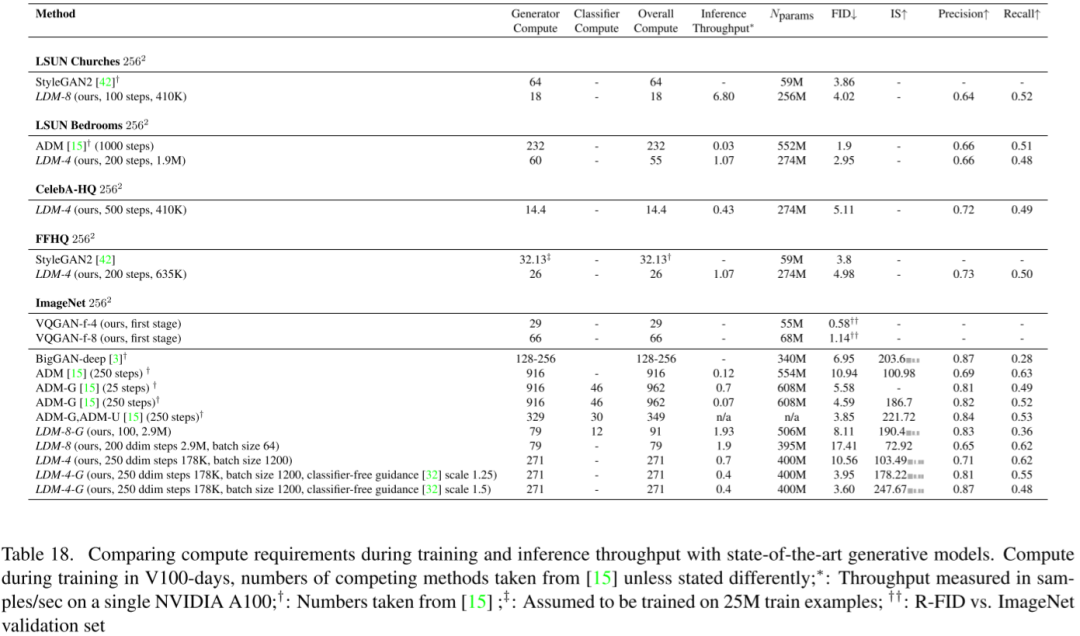
作者与其他模型对比了训练和推理的计算需求和相关的参数量、FID、IS 等指标,提出的模型在更小的代价下获得更好的效果:
三、SDXL
1. SDXL 模型概览
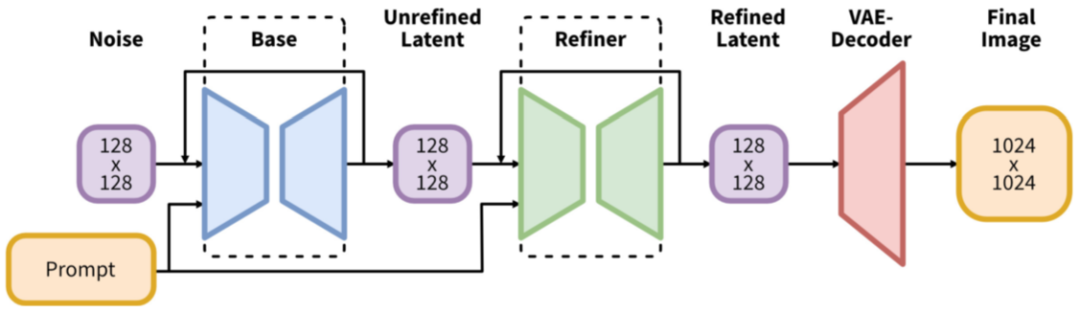
如下图所示,SDXL 相比 SD 主要的修改包括(模型总共 2.6B 参数量,其中 text encoder 817M 参数量):
增加一个 Refiner 模型,用于对图像进一步地精细化
使用 CLIP ViT-L 和 OpenCLIP ViT-bigG 两个 text encoder
基于 OpenCLIP 的 text embedding 增加了一个 pooled text embedding
2 微条件(Micro-Conditioning)
2.1. 以图像大小作为条件
在 SD 的训练范式中有个明显的缺陷,对图像大小有最小长宽的要求。针对这个问题有两种方案:
丢弃分辨率过小的图像(例如,SD 1.4/1.5 丢弃了小于 512 像素的图像)。但是这可能导致丢弃过多数据,如下图 Figure 2 所示为预训练数据集中图像的长、宽分布,如果丢弃 256x256 分辨率的图像,将导致 39% 的数据被丢弃。
另一种方式是放大图像,但是可能会导致生成的样本比较模糊。
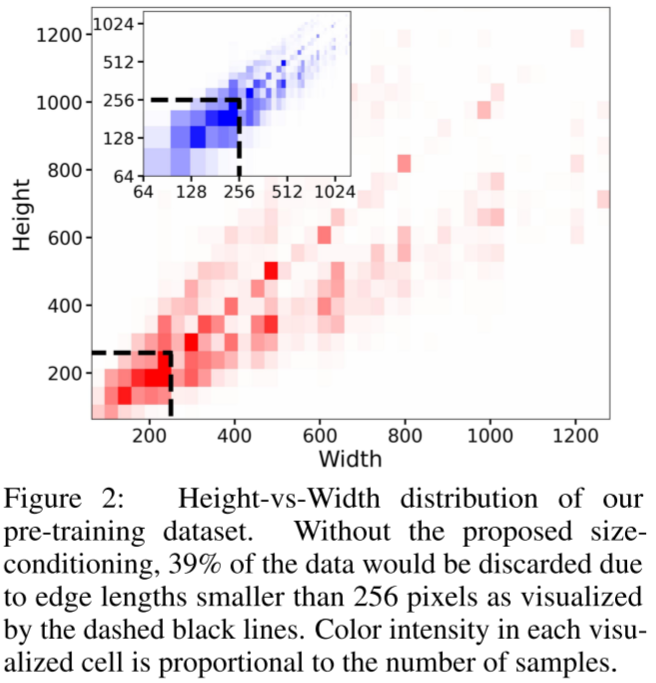
针对这种情况,作者提出将原始图像分辨率作用于 U-Net 模型,并提供图像的原始长和宽(csize = (h, w))作为附加条件。并使用傅里叶特征编码,然后会拼接为一个向量,把它扩充到时间步长 embedding 中并一起输入模型。
如下图所示,在推理时指定不同的长宽即可生成相应的图像,(64,64)的图像最模糊,(512, 512)的图像最清晰:

2.2. 以裁剪参数作为条件
此外,以前的 SD 模型存在一个比较典型的问题:生成的物体不完整,像是被裁剪过的,如下图 SD1.5 和 SD 2.1 的结果。作者猜测这可能和训练阶段的随机裁剪有关,考虑到这个因素,作者将裁剪的左上坐标(top, left)作为条件输入模型,和 size 类似。如下图 Figure 4 中 SDXL 的结果,其生成结果都更加完整:

如下图 Figure 5 所示,在推理阶段也可以通过裁剪坐标来控制位置关系:

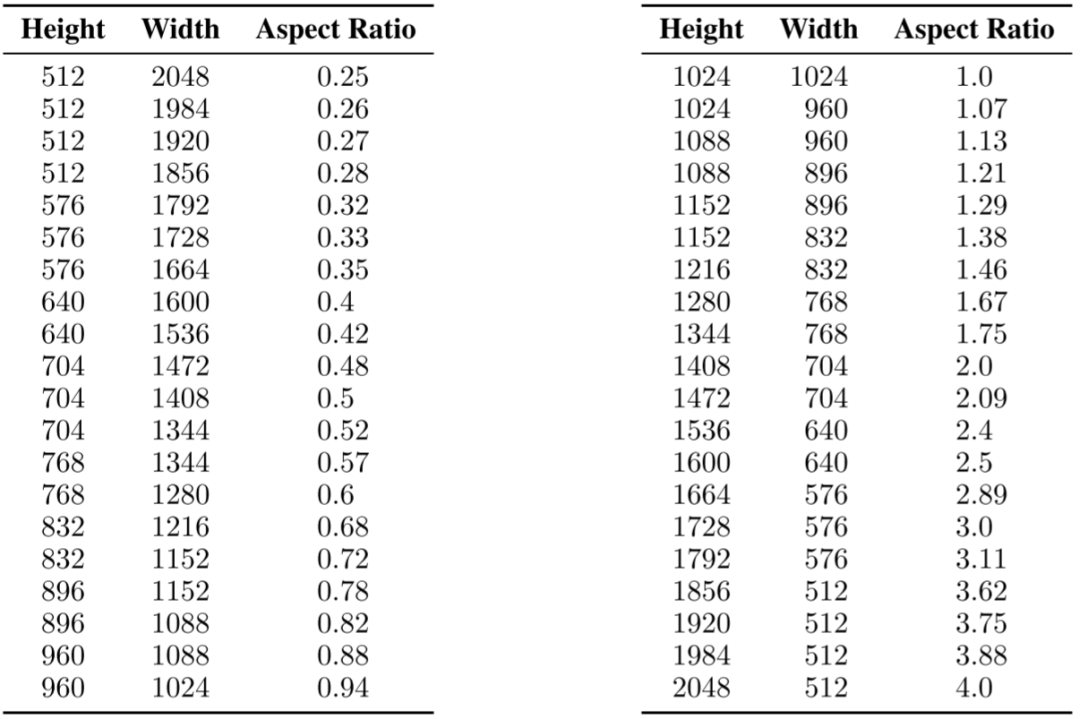
3 多分辨率训练
真实世界的图像会包含不同的大小和长宽比,而文本到模型生成的图像分辨率通常为 512x512 或 1024x1024,作者认为这不是一个自然的选择。受此启发,作者以不同的长宽比来微调模型:首先将数据划分为不同长宽比的桶,其中尽可能保证总像素数接近 1024x1024 个,同时以 64 的整数倍来调整高度和宽度。如下图所示为作者使用的宽度和高度。在训练过程中,每次都从同样的桶中选择一个 batch,并在不同的桶间交替。此外,和之前的 size 类似,作者会将桶的高度和宽度 (h, w)作为条件,经傅里叶特征编码后添加到时间步 embedding 中:
4. 训练
SDXL 模型的训练包含多个步骤:
基于内部数据集,以 256x256 分辨率预训练 6,000,000 step,batch size 为 2048。使用了 size 和 crop 条件。
继续以 512x512 分辨率训练 200,000 step。
最后使用多分辨率(近似 1024x1024)训练。
根据以往的经验,作者发现所得到的的模型有时偶尔会生成局部质量比较差的图像,为了解决这个问题,作者在同一隐空间训练了一个独立的 LDM(Refiner),该 LDM 专门用于高质量、高分辨率的数据。在推理阶段,直接基于 Base SDXL 生成的 Latent code 继续生成,并使用相同的文本条件(当然,此步骤是可选的),实验证明可以提高背景细节以及人脸的生成质量。
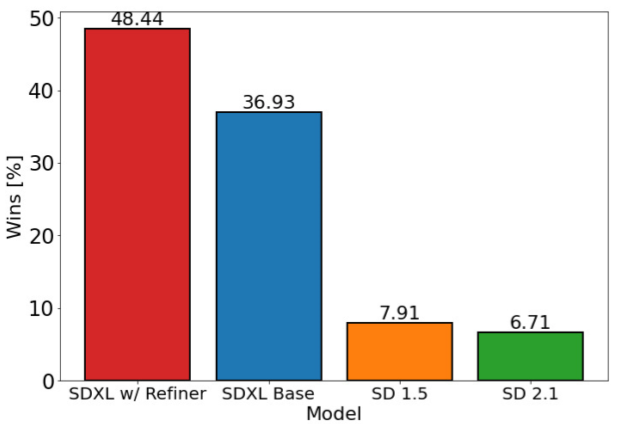
5. 实验结果
如下图所示,作者基于用户评估,最终带有 Refiner 的 SDXL 获得了最高分,并且 SDXL 结果明显优于 SD 1.5 和 SD 2.1。
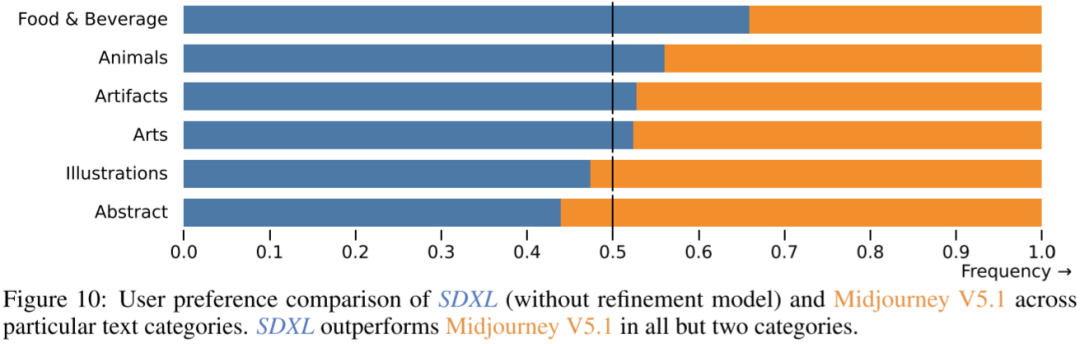
如下图 Figure 10 所示为 SDXL(没有 Refiner) 和 Midjourney 5.1 的对比结果,可见 SDXL 的结果略胜一筹:
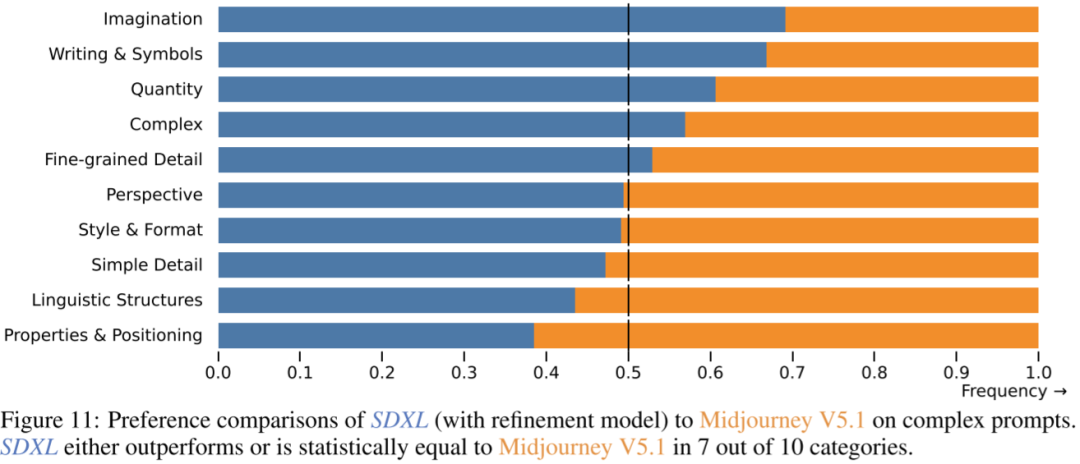
如下图 Figure 11 所示为 SDXL(带有 Refiner) 和 Midjourney 5.1 的对比结果,可见 SDXL 的结果同样略胜一筹:
四、SDXL-Turbo
1. SDXL-Turbo 方法
SDXL-Turbo 在模型上没有什么修改,主要是引入蒸馏技术,以便减少 LDM 的生成步数,提升生成速度。大致的流程为:
从 Tstudent 中采样步长 s,对于原始图像 x0 进行 s 步的前向扩散过程,生成加噪图像 xs。
使用学生模型 ADD-student 对 xs 进行去噪,生成去噪图像 xθ。
基于原始图像 x0 和去噪图像 xθ 计算对抗损失(adversarial loss)。
从 Tteacher 中采样步长 t,对去噪后的图像 xθ 进行 t 步的前向扩散过程,生成 xθ,t。
使用教师模型 DM-student 对 xθ,t 进行去噪,生成去噪图像 xψ。
基于学生模型去噪图像 xθ 和教师模型去噪图像 xψ 计算蒸馏损失(distillation)。
根据损失进行反向传播(注意,教师模型不更新,因此会 stop 梯度)。
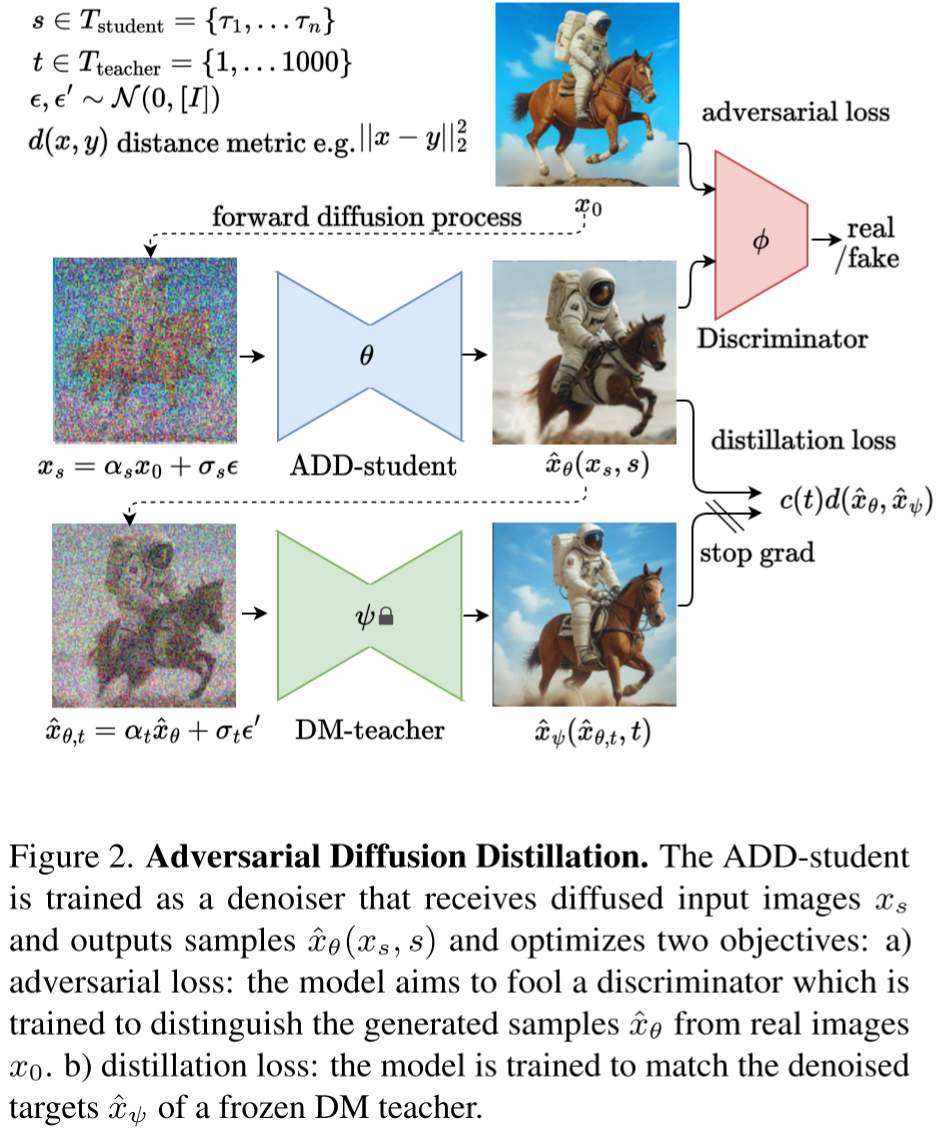
需要说明的是,通常 ADD-student 模型需要预训练过程,然后再蒸馏。此外,Tstudent 的 N 比较小,作者设置为 4,而 Tteacher 的 N 比较大,为 1000。也就是学生模型可能只加噪 1,2,3,4 步,而教师模型可能加噪 1-1000 步。
此外,作者在训练中还用了其他技巧,比如使用了 zero-terminal SNR;教师模型不是直接作用于原始图像 x0,而是作用于学生模型恢复出的图像 xθ,否则会出现 OOD(out of distribution) 问题;作者还应用了 Score Distillation Loss,并且与最新的 noise-free score distillation 进行了对比。
2. 消融实验
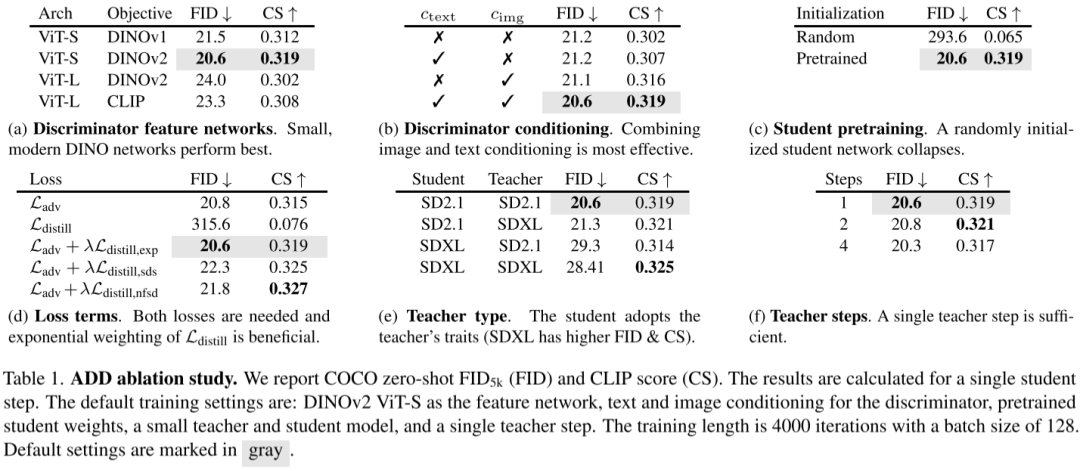
作者进行了一系列的消融实验:
(a) 在判别器(Discriminator)中使用不同模型的结果。
(b) 在判别器中使用不同条件的效果,可见使用文本+图像条件获得最好结果。
© 学生模型使用预训练的结果,使用预训练效果明显提升。
(d) 不同损失的影响。
(e) 不同学生模型和教师模型的影响。
(f) 教师 step 的影响。
3. 实验结果
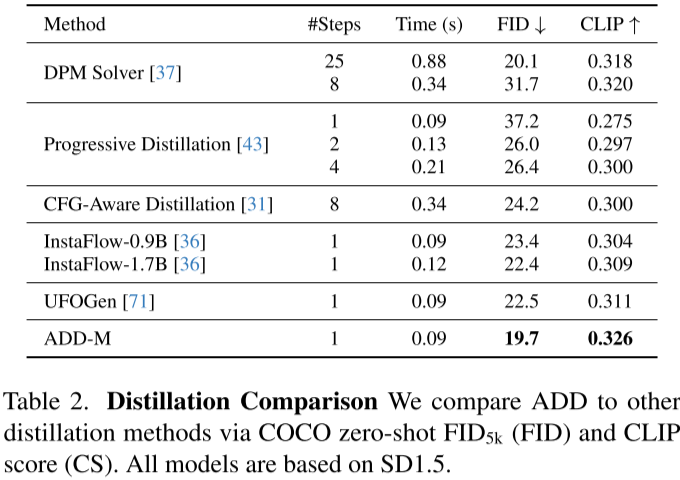
如下图所示,作者与不同的蒸馏方案进行了对比,本文提出的方案只需一步就能获得最优的 FID 和 CLIP 分数:
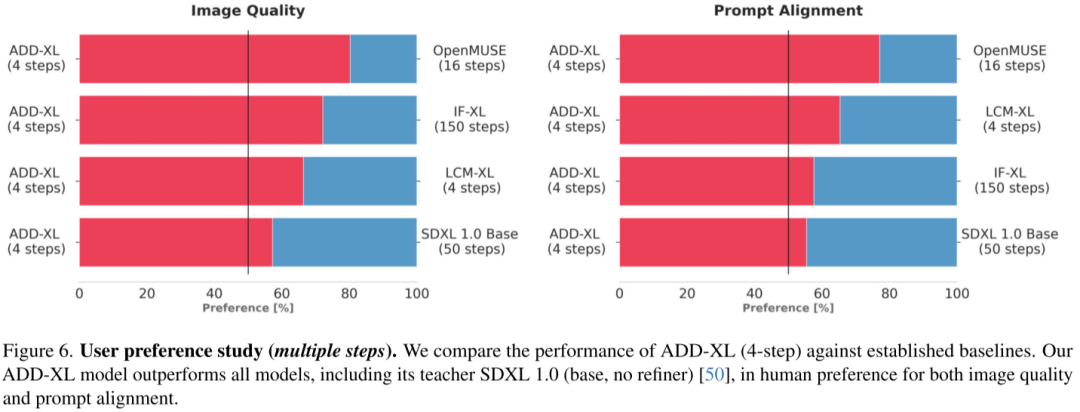
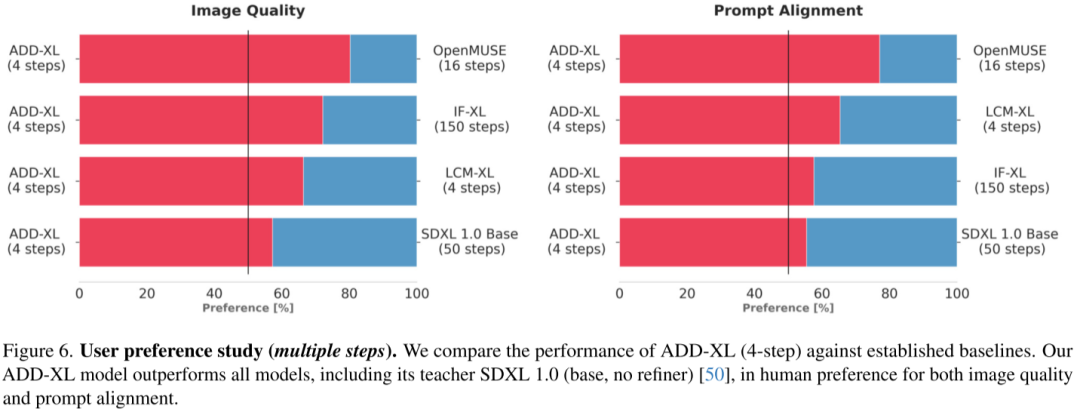
如下图 Figure 5 和 Figure 6 所示为性能和速度的对比,ADD-XL 1 步比 LCM-XL 4 步的效果更好,同时 ADD-XL 4 步可以超越 SDXL 50 步的结果,总之,ADD-XL 获得了最佳性能:
五、演进
1. Latent Diffusion
Stable Diffusion 之前的版本,对应的正是论文的开源版本,位于代码库 High-Resolution Image Synthesis with Latent Diffusion Models 中。
该版本发布于 2022 年 4 月,主要包含三个模型:
文生图模型:基于 LAION-400M 数据集训练,包含 1.45B 参数。
图像修复模型:指定区域进行擦除。
基于 ImageNet 的类别生成模型:在 ImageNet 上训练,指定类别条件生成,获得了 3.6 的 FID 分数。使用了 Classifier Free Guidance 技术。
代码实现参考了 OpenAI 的 Diffusion Models Beat GANs 代码实现。
2. Stable Diffusion V1
Stable Diffusion 的第一个版本,特指文生图扩散模型,位于代码库 GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model 中。
该版本发布于 2022 年 8 月,该模型包含 2 个子模型:
AutoEncoder 模型:U-Net,8 倍下采样,包含 860M 参数。
Text Encoder 模型:使用 CLIP ViT-L/14 中的 Text encoder。
模型首先在 256x256 的分辨率下训练,然后在 512x512 的分辨率下微调。总共包含 4 个子版本:
sd-v1-1.ckpt:
在 LAION-2B-en 数据集上以 256x256 分辨率训练 237k step。
在 LAION-high-resolution(LAION-5B 中超过 1024x1024 分辨率的 170M 样本)上以 512x512 分辨率继续训练 194k step。
sd-v1-2.ckpt:
复用 sd-v1-1.ckpt,在 LAION-aesthetics v2 5+(LAION-2B-en 中美观度分数大于 5.0 的子集) 上以 512x512 分辨率继续训练 515k step。
sd-v1-3.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 195k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
sd-v1-4.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 225k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
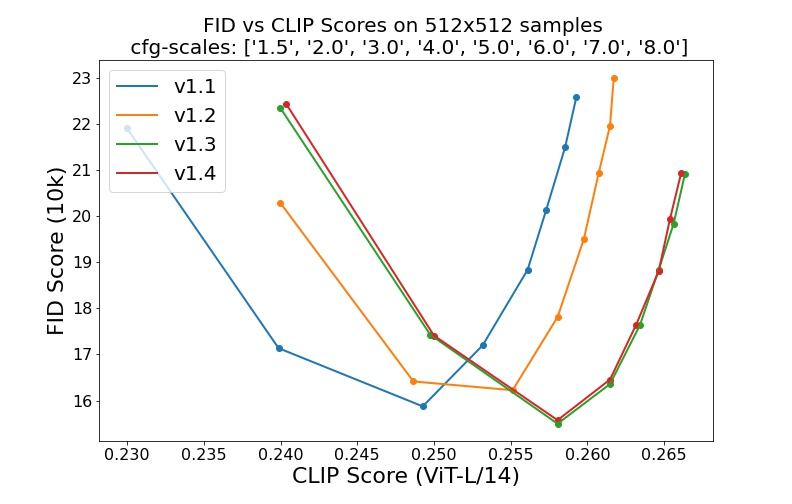
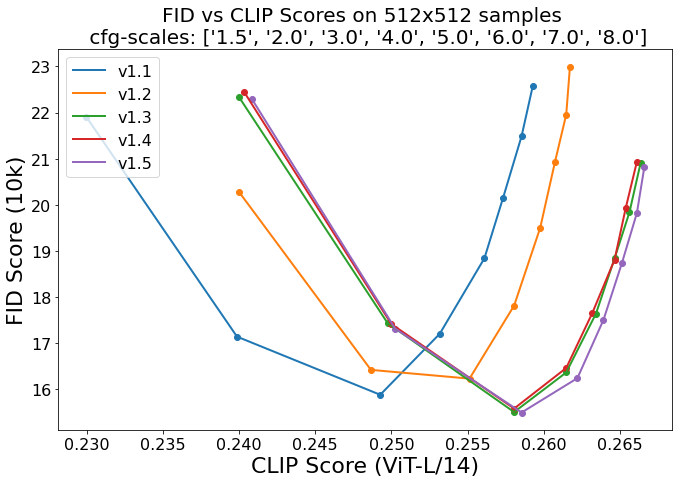
对应的 FID 和 CLIP 分数如下图所示,可见从 v1-1 到 v1-2,再到 v1-3 提升都很明显,v1-3 和 v1-4 差距不大:
3. Stable Diffusion V1.5
Stable Diffusion 的 V1.5 版本,由 runway 发布,位于代码库 GitHub - runwayml/stable-diffusion: Latent Text-to-Image Diffusion 中。
该版本发布于 2022 年 10 月,主要包含两个模型:
sd-v1-5.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 595k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
sd-v1-5-inpainting.ckpt:
复用 sd-v1-5.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率以 inpainting 训练了 440k step,使用 Classifier Free Guidance 技术,以 10% 概率删除文本条件。在 U-Net 的输入中额外加了 5 个 channel,4 个用于 masked 的图像,1 个用于 mask 本身。
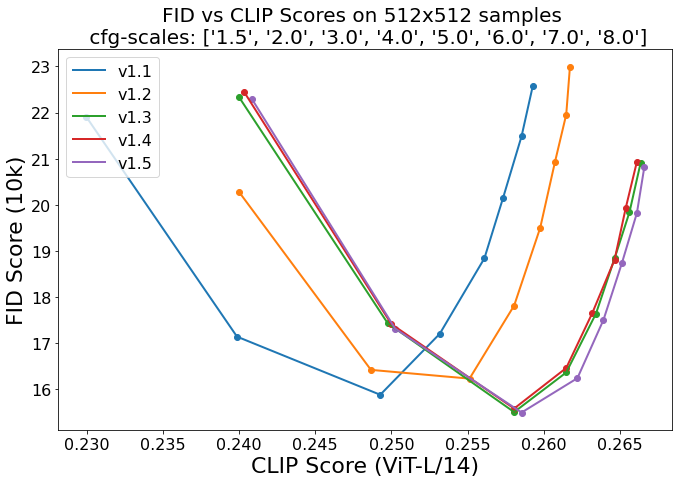
对应的 FID 和 CLIP 分数如下图所示,可以看出,v1.5 相比 v1.4 的提升也不是很明显:
6.3. Stable Diffusion V1.5
Stable Diffusion 的 V1.5 版本,由 runway 发布,位于代码库 GitHub - runwayml/stable-diffusion: Latent Text-to-Image Diffusion 中。
该版本发布于 2022 年 10 月,主要包含两个模型:
sd-v1-5.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 595k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
sd-v1-5-inpainting.ckpt:
复用 sd-v1-5.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率以 inpainting 训练了 440k step,使用 Classifier Free Guidance 技术,以 10% 概率删除文本条件。在 U-Net 的输入中额外加了 5 个 channel,4 个用于 masked 的图像,1 个用于 mask 本身。
对应的 FID 和 CLIP 分数如下图所示,可以看出,v1.5 相比 v1.4 的提升也不是很明显:
如下图所示为图像修复的示例:
4. Stable Diffusion V2
Stable Diffusion 的 V2 版本,由 Stability-AI 发布,位于代码库 GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models 中。
V2 包含三个子版本,分别为 v2.0,v2.1 和 Stable UnCLIP 2.1:
v2.0:
发布于 2022 年 11 月,U-Net 模型和 V1.5 相同,Text encoder 模型换成了 OpenCLIP-ViT/H 中的 text encoder。
SD 2.0-base:分别率为 512x512
SD 2.0-v:基于 2.0-base 微调,分辨率提升到 768x768,同时利用 [2202.00512] Progressive Distillation for Fast Sampling of Diffusion Models 提出的技术大幅降低 Diffusion 的步数。
发布了一个文本引导的 4 倍超分模型。
基于 2.0-base 微调了一个深度信息引导的生成模型。
基于 2.0-base 微调了一个文本信息引导的修复模型。
v2.1:
发布于 2022 年 12 月,模型结构和参数量都和 v2.0 相同。并在 v2.0 的基础上使用 LAION 5B 数据集(较低的 NSFW 过滤约束)微调。同样包含 512x512 分辨率的 v2.1-base 和 768x768 分辨率的 v2.1-v。
Stable UnCLIP 2.1:
发布于 2023 年 3 月,基于 v2.1-v(768x768 分辨率) 微调,参考 OpenAI 的 DALL-E 2(也就是 UnCLIP),可以更好的实现和其他模型的联合,同样提供基于 CLIP ViT-L 的 Stable unCLIP-L 和基于 CLIP ViT-H 的 Stable unCLIP-H。
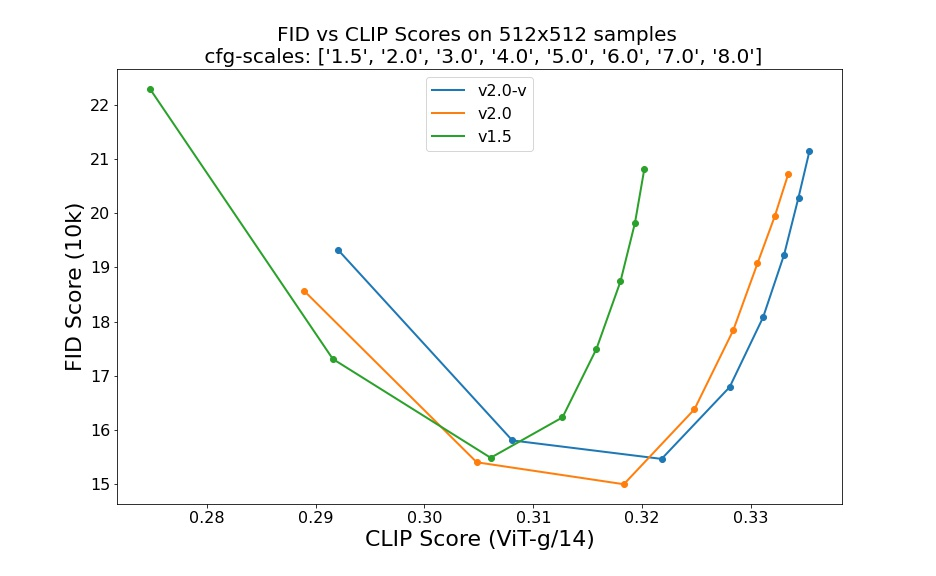
如下图所示为 v2.0 和 v2.0-v 与 v1.5 的对比,可见其都有明显提升:
5. Stable Diffusion XL
Stable Diffusion 的 XL 版本,由 Stability-AI 发布,位于代码库 Generative Models by Stability AI。
该版本发布于 2023 年 06 月,主要包含两个模型:
SDXL-base-0.9:基于多尺度分辨率训练,最大分辨率 1024x1024,包含两个 Text encoder,分别为 OpenCLIP-ViT/G 和 CLIP-ViT/L。
SDXL-refiner-0.9:用来生成更高质量的图像,不应直接使用,此外文本条件只使用 OpenCLIP 中的 Text encoder。
2023 年 07 月发布 1.0 版本,同样对应两个模型:
SDXL-base-1.0:基于 SDXL-base-0.9 改进。
SDXL-refiner-1.0:基于 SDXL-refiner-0.9 改进。
2023 年 11 月发表 SDXL-Trubo 版本,也就是优化加速的版本。
相关文章:
Stable Diffusion ———LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo等版本之间关系现原理详解
一、简介 2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffusion Models,DM)在图像生成领域开始超越传统的GAN模型,进一步推动了DM的应用。 然而,早期的DM直接作用于像…...

GESP5级T1真题 [202309] 因数分解——O(sqrt(n))的时间复杂度,值得一看
描述 每个正整数都可以分解成素数的乘积,例如:62*3、2022 *5 现在,给定一个正整数N,请按要求输出它的因数分解式。 输入描述 输入第一行,包含一个正整数N。约定2<N<10^12 输出描述 输出一行,为N…...

Stable Diffusion 3报告
报告链接:https://stability.ai/news/stable-diffusion-3-research-paper 文章目录 要点表现架构细节通过重新加权改善整流流量Scaling Rectified Flow Transformer Models灵活的文本编码器RF相关论文 要点 发布研究论文,深入探讨Stable Diffuison 3的…...

一个足球粉丝该怎么建个个人博客?
做一个个人博客第一步该怎么做? 好多零基础的同学们不知道怎么迈出第一步。 那么,就找一个现成的模板学一学呗,毕竟我们是高贵的Ctrl c v 工程师。 但是这样也有个问题,那就是,那些模板都,太!…...

缩放算法优化步骤详解
添加链接描述 背景 假设数据存放在在unsigned char* m_pData 里面,宽和高分别是:m_nDataWidth m_nDataHeight 给定缩放比例:fXZoom fYZoom,返回缩放后的unsigned char* dataZoom 这里采用最简单的缩放算法即: 根据比…...

[axios]使用指南
axios使用指南 Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中。 axios 安装 npm安装 $ npm install axios 使用cdn <script src"https://unpkg.com/axios/dist/axios.min.js"></script> axios API axios(config)…...
HTML5基础2
drag 可以把拖放事件拆分成4个步骤 设置元素为可拖放。为了使元素可拖动,把 draggable 属性设置为 true 。 <img draggable"true"> 拖动什么。ondragstart 和 setData() const dragestart (ev)>{ev.dataTransfer.setData(play,ev.target.id)} …...
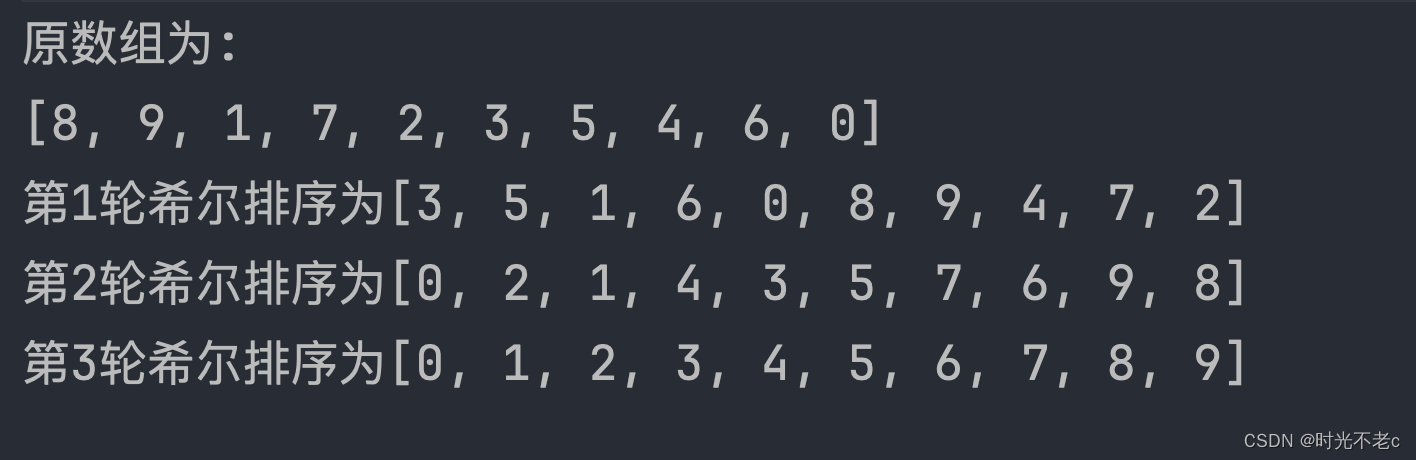
数据结构与算法-希尔排序
引言 在计算机科学中,数据结构和算法是构建高效软件系统的基石。而排序算法作为算法领域的重要组成部分,一直在各种应用场景中发挥着关键作用。今天我们将聚焦于一种基于插入排序的改进版本——希尔排序(Shell Sort),深…...

蓝桥杯算法错题记录
这里写目录标题 本文还在跟新,最新更新时间24/3/91. nextInt () next() nextLine() 的注意事项2 . 转换数据类型int ,string,charint -> string , charstring -> int ,charchar -> int , string 进制转换十六进制转化为10 进制 最大公约数 本文还在跟新&am…...

【Python 图像处理 PIL 系列 13 -- PIL 及 Image.convert 函数介绍】
文章目录 Python PIL 介绍PIL 使用介绍PIL convert 介绍PIL convert 使用示例 Python PIL 介绍 PIL 是 Python Image Library 的简称。PIL 库中提供了诸多用来处理图片的模块,可以对图片做类似于 PS(Photoshop) 的编辑。比如:改变…...

使用docker datascience-notebook进行数据分析
Jupyter/datascience-notebook 简介 jupyter/datascience-notebook 是 Docker Hub 上可用的 Docker 镜像:https://hub.docker.com/。该镜像提供了一个开箱即用的环境,用于数据科学任务,包括: Jupyter Notebook: 一个基于 Web 的…...
VR全景技术在VR看房中有哪些应用,能带来哪些好处
引言: 随着科技的不断发展,虚拟现实(VR)技术在房地产行业中的应用也越来越广泛。其中,VR全景技术在VR看房中的运用尤为突出。今天,让我们一起深入探讨VR全景技术在VR看房中的应用及其带来的种种好处。 一、…...
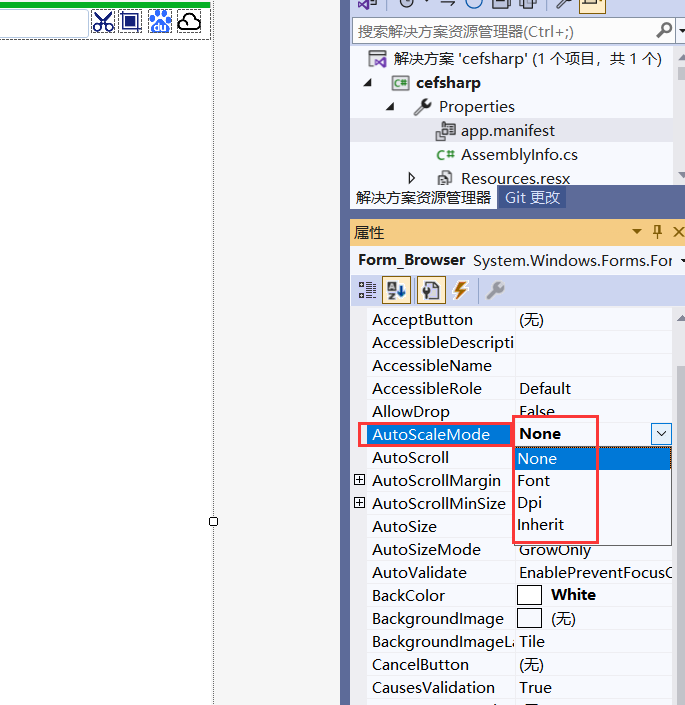
Winform窗体随着屏幕的DPI缩放,会引起窗体变形及字体变形,superTabControl标签字体大小不匹配
一、前言 superTabControl做的浏览器标签(cefsharp)在缩放比例(125%,150%时字体不协调) 物联网浏览器,定制浏览器,多媒体浏览器(支持H264)参考栏目文章即可 二、配置参数 app.manifest参数 dpiAware =true <application xmlns="urn:schemas-microsoft-c…...

java网络编程 01 IP,端口,域名,TCP/UDP, InetAddress
01.IP 要想让网络中的计算机能够互相通信,必须为计算机指定一个标识号,通过这个标识号来指定要接受数据的计算机和识别发送的计算机,而IP地址就是这个标识号,也就是设备的标识。 ip地址组成: ip地址分类:…...
第十篇 - 如何利用人工智能技术做好营销流量整形管理?(Traffic Shaping)- 我为什么要翻译介绍美国人工智能科技巨头IAB公司
IAB平台,使命和功能 IAB成立于1996年,总部位于纽约市。 作为美国的人工智能科技巨头社会媒体和营销专业平台公司,互动广告局(IAB- the Interactive Advertising Bureau)自1996年成立以来,先…...

npm ERR! errno -13具体问题处理
npm ERR! errno -13具体问题处理 出现问题的报错 npm ERR! code EACCES npm ERR! syscall open npm ERR! path /Users/xxxx/.npm/_cache/index-v5/c6/06/xxxxx npm ERR! errno -13 npm ERR! npm ERR! Your cache folder contains root-owned files, due to a bug in npm ERR! …...
【Python】3. 基础语法(2) -- 语句篇
顺序语句 默认情况下, Python 的代码执行顺序是按照从上到下的顺序, 依次执行的. print("1") print("2") print("3")执行结果一定为 “123”, 而不会出现 “321” 或者 “132” 等. 这种按照顺序执行的代码, 我们称为 顺序语句. 这个顺序是很关…...
IPsec VPN之安全联盟
一、何为安全联盟 IPsec在两个端点建立安全通信,此时这两个端点被称为IPsec对等体。安全联盟,即SA,是指通信对等体之间对某些要素的约定,定义了两个对等体之间要用何种安全协议、IP报文的封装方式、加密和验证算法。SA是IPsec的基…...

012集——显示高考天数倒计时——vba实现
以下代码实现高考倒计时: Sub 高考倒计时() 高考日期 CDate("06,07," & Year(Date)) If Date > 高考日期 Then高考日期 CDate("06-07-" & Year(Date) 1) End If 年月日 Year(Date) & "年" & Month(Date) &am…...
1.1 深度学习和神经网络
首先要说的是:深度学习的内容,真的不难。你要坚持下去。 神经网络 这就是一个神经网络。里面的白色圆圈就是神经元。神经元是其中最小的单位。 神经网络 单层神经网络: 感知机 (双层神经网络) 全连接层: …...

解锁硬件潜能:Universal x86 Tuning Utility 让你的电脑性能全面释放
解锁硬件潜能:Universal x86 Tuning Utility 让你的电脑性能全面释放 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility …...

从一次失败的下载说起:给运维新手的Linux HTTPS工具链兼容性自查清单
从一次失败的下载说起:给运维新手的Linux HTTPS工具链兼容性自查清单 那天凌晨两点,服务器上的自动化脚本突然报错,屏幕上一行刺眼的红色文字让我瞬间清醒:"SSL routines:SSL23_GET_SERVER_HELLO:tlsv1 unrecognized name&qu…...

从航模到创客:手把手教你用Arduino UNO和好盈40A电调DIY一个小型动力测试台
从航模到创客:用Arduino UNO和好盈40A电调构建专业级动力测试平台 当无刷电机从航模领域走向创客工作台,如何安全高效地测试其性能成为每个硬件爱好者的必修课。本文将带你用Arduino UNO和好盈40A电调打造一个可测量转速、绘制特性曲线、适配多种负载的…...
)
告别机械音:用Android TTS API实现更自然的语音播报(调整语速、音调与实时回调实战)
告别机械音:用Android TTS API实现更自然的语音播报(调整语速、音调与实时回调实战) 有声阅读类App的用户反馈中,"语音生硬"是最常见的问题之一。当一位儿童教育产品的开发者告诉我,他们的用户抱怨"故事…...
)
解锁GeniE自动化:手把手教你用JScript脚本批量创建梁板模型(告别重复点击)
解锁GeniE自动化:手把手教你用JScript脚本批量创建梁板模型(告别重复点击) 在海洋工程结构设计领域,效率往往决定着项目成败。当面对数十个相似但尺寸各异的立柱或甲板模块时,传统的手动建模不仅耗时费力,还…...
)
Apache DolphinScheduler日志把磁盘撑爆了?别慌,教你两招搞定日志清理(附crontab定时脚本)
Apache DolphinScheduler日志爆盘应急指南:从手动清理到自动化防护 凌晨三点,服务器告警铃声刺破夜空——/var分区使用率100%。作为运维负责人,你迅速SSH登录排查,发现罪魁祸首是DolphinScheduler堆积如山的日志文件。这种场景对于…...

MQTTX+Qt联合调试指南:手把手搭建物联网通信测试环境
MQTTXQt联合调试指南:手把手搭建物联网通信测试环境 在物联网开发中,MQTT协议因其轻量级和高效性成为设备通信的首选方案。而Qt框架的跨平台特性与MQTTX工具的直观可视化界面,为开发者提供了从原型验证到产品落地的完整工具链。本文将带您从零…...

AzurLaneAutoScript技术架构深度解析:构建碧蓝航线7x24小时智能自动化系统
AzurLaneAutoScript技术架构深度解析:构建碧蓝航线7x24小时智能自动化系统 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoSc…...

Joplin跨设备同步冲突:数据一致性保障机制解析
Joplin跨设备同步冲突:数据一致性保障机制解析 【免费下载链接】joplin Joplin - the privacy-focused note taking app with sync capabilities for Windows, macOS, Linux, Android and iOS. 项目地址: https://gitcode.com/GitHub_Trending/jo/joplin 你在…...

AGI如何重构人力资源管理闭环:从人才画像到组织健康度预测的7步落地方法论
第一章:AGI驱动的人力资源管理范式跃迁 2026奇点智能技术大会(https://ml-summit.org) 传统人力资源管理正经历由通用人工智能(AGI)引发的结构性重构——从流程自动化迈向认知协同、从经验决策转向因果推演、从岗位适配升维至潜能涌现。AGI不…...