【深度学习笔记】6_5 RNN的pytorch实现
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图
6.5 循环神经网络的简洁实现
本节将使用PyTorch来更简洁地实现基于循环神经网络的语言模型。首先,我们读取周杰伦专辑歌词数据集。
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as Fimport sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
6.5.1 定义模型
PyTorch中的nn模块提供了循环神经网络的实现。下面构造一个含单隐藏层、隐藏单元个数为256的循环神经网络层rnn_layer。
num_hiddens = 256
# rnn_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens) # 已测试
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)
与上一节中实现的循环神经网络不同,这里rnn_layer的输入形状为(时间步数, 批量大小, 输入个数)。其中输入个数即one-hot向量长度(词典大小)。此外,rnn_layer作为nn.RNN实例,在前向计算后会分别返回输出和隐藏状态h,其中输出指的是隐藏层在各个时间步上计算并输出的隐藏状态,它们通常作为后续输出层的输入。需要强调的是,该“输出”本身并不涉及输出层计算,形状为(时间步数, 批量大小, 隐藏单元个数)。而nn.RNN实例在前向计算返回的隐藏状态指的是隐藏层在最后时间步的隐藏状态:当隐藏层有多层时,每一层的隐藏状态都会记录在该变量中;对于像长短期记忆(LSTM),隐藏状态是一个元组(h, c),即hidden state和cell state。我们会在本章的后面介绍长短期记忆和深度循环神经网络。关于循环神经网络(以LSTM为例)的输出,可以参考下图(图片来源)。

来看看我们的例子,输出形状为(时间步数, 批量大小, 隐藏单元个数),隐藏状态h的形状为(层数, 批量大小, 隐藏单元个数)。
num_steps = 35
batch_size = 2
state = None
X = torch.rand(num_steps, batch_size, vocab_size)
Y, state_new = rnn_layer(X, state)
print(Y.shape, len(state_new), state_new[0].shape)
输出:
torch.Size([35, 2, 256]) 1 torch.Size([2, 256])
如果
rnn_layer是nn.LSTM实例,那么上面的输出是什么?
接下来我们继承Module类来定义一个完整的循环神经网络。它首先将输入数据使用one-hot向量表示后输入到rnn_layer中,然后使用全连接输出层得到输出。输出个数等于词典大小vocab_size。
# 本类已保存在d2lzh_pytorch包中方便以后使用
class RNNModel(nn.Module):def __init__(self, rnn_layer, vocab_size):super(RNNModel, self).__init__()self.rnn = rnn_layerself.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1) self.vocab_size = vocab_sizeself.dense = nn.Linear(self.hidden_size, vocab_size)self.state = Nonedef forward(self, inputs, state): # inputs: (batch, seq_len)# 获取one-hot向量表示X = d2l.to_onehot(inputs, self.vocab_size) # X是个listY, self.state = self.rnn(torch.stack(X), state)# 全连接层会首先将Y的形状变成(num_steps * batch_size, num_hiddens),它的输出# 形状为(num_steps * batch_size, vocab_size)output = self.dense(Y.view(-1, Y.shape[-1]))return output, self.state
6.5.2 训练模型
同上一节一样,下面定义一个预测函数。这里的实现区别在于前向计算和初始化隐藏状态的函数接口。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,char_to_idx):state = Noneoutput = [char_to_idx[prefix[0]]] # output会记录prefix加上输出for t in range(num_chars + len(prefix) - 1):X = torch.tensor([output[-1]], device=device).view(1, 1)if state is not None:if isinstance(state, tuple): # LSTM, state:(h, c) state = (state[0].to(device), state[1].to(device))else: state = state.to(device)(Y, state) = model(X, state)if t < len(prefix) - 1:output.append(char_to_idx[prefix[t + 1]])else:output.append(int(Y.argmax(dim=1).item()))return ''.join([idx_to_char[i] for i in output])
让我们使用权重为随机值的模型来预测一次。
model = RNNModel(rnn_layer, vocab_size).to(device)
predict_rnn_pytorch('分开', 10, model, vocab_size, device, idx_to_char, char_to_idx)
输出:
'分开戏想暖迎凉想征凉征征'
接下来实现训练函数。算法同上一节的一样,但这里只使用了相邻采样来读取数据。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,corpus_indices, idx_to_char, char_to_idx,num_epochs, num_steps, lr, clipping_theta,batch_size, pred_period, pred_len, prefixes):loss = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=lr)model.to(device)state = Nonefor epoch in range(num_epochs):l_sum, n, start = 0.0, 0, time.time()data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样for X, Y in data_iter:if state is not None:# 使用detach函数从计算图分离隐藏状态, 这是为了# 使模型参数的梯度计算只依赖一次迭代读取的小批量序列(防止梯度计算开销太大)if isinstance (state, tuple): # LSTM, state:(h, c) state = (state[0].detach(), state[1].detach())else: state = state.detach()(output, state) = model(X, state) # output: 形状为(num_steps * batch_size, vocab_size)# Y的形状是(batch_size, num_steps),转置后再变成长度为# batch * num_steps 的向量,这样跟输出的行一一对应y = torch.transpose(Y, 0, 1).contiguous().view(-1)l = loss(output, y.long())optimizer.zero_grad()l.backward()# 梯度裁剪d2l.grad_clipping(model.parameters(), clipping_theta, device)optimizer.step()l_sum += l.item() * y.shape[0]n += y.shape[0]try:perplexity = math.exp(l_sum / n)except OverflowError:perplexity = float('inf')if (epoch + 1) % pred_period == 0:print('epoch %d, perplexity %f, time %.2f sec' % (epoch + 1, perplexity, time.time() - start))for prefix in prefixes:print(' -', predict_rnn_pytorch(prefix, pred_len, model, vocab_size, device, idx_to_char,char_to_idx))
使用和上一节实验中一样的超参数(除了学习率)来训练模型。
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2 # 注意这里的学习率设置
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,corpus_indices, idx_to_char, char_to_idx,num_epochs, num_steps, lr, clipping_theta,batch_size, pred_period, pred_len, prefixes)
输出:
epoch 50, perplexity 10.658418, time 0.05 sec- 分开始我妈 想要你 我不多 让我心到的 我妈妈 我不能再想 我不多再想 我不要再想 我不多再想 我不要- 不分开 我想要你不你 我 你不要 让我心到的 我妈人 可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的
epoch 100, perplexity 1.308539, time 0.05 sec- 分开不会痛 不要 你在黑色幽默 开始了美丽全脸的梦滴 闪烁成回忆 伤人的美丽 你的完美主义 太彻底 让我- 不分开不是我不要再想你 我不能这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 靠着我的肩膀 你 在我
epoch 150, perplexity 1.070370, time 0.05 sec- 分开不能去河南嵩山 学少林跟武当 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮 习武之人切记 仁者无敌- 不分开 在我会想通 是谁开没有全有开始 他心今天 一切人看 我 一口令秋软语的姑娘缓缓走过外滩 消失的 旧
epoch 200, perplexity 1.034663, time 0.05 sec- 分开不能去吗周杰伦 才离 没要你在一场悲剧 我的完美主义 太彻底 分手的话像语言暴力 我已无能为力再提起- 不分开 让我面到你 爱情来的太快就像龙卷风 离不开暴风圈来不及逃 我不能再想 我不能再想 我不 我不 我不
epoch 250, perplexity 1.021437, time 0.05 sec- 分开 我我外的家边 你知道这 我爱不看的太 我想一个又重来不以 迷已文一只剩下回忆 让我叫带你 你你的- 不分开 我我想想和 是你听没不 我不能不想 不知不觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉
小结
- PyTorch的
nn模块提供了循环神经网络层的实现。 - PyTorch的
nn.RNN实例在前向计算后会分别返回输出和隐藏状态。该前向计算并不涉及输出层计算。
注:除代码外本节与原书此节基本相同,原书传送门
相关文章:
【深度学习笔记】6_5 RNN的pytorch实现
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.5 循环神经网络的简洁实现 本节将使用PyTorch来更简洁地实现基于循环神经网络的语言模型。首先,我们读取周杰伦专辑歌词…...
Linux at任务调度命令行编辑错误
错误: 在at任务调度命令行语句编辑错误时,按backspace进行删除无法进行。 解决方案: 请按Ctrlbackspace进行删除,即可解决。...

lua与C++粘合层框架
lua调用C++ 在lua中是以函数指针的形式调用函数, 并且所有的函数指针都必须满足如下此种类型: typedef int (*lua_CFunction) (lua_State *L); 也就是说, 偶们在C++中定义函数时必须以lua_State为参数, 以int为返回值才能被Lua所调用. 但是不要忘记了, 偶们的lua_State是支…...

POST 请求,Ajax 与 cookie
POST 请求则需要设置RequestHeader告诉后台传递内容的编码方式以及在 send 方法里传入对应的值 xhr.open("POST", url, true); xhr.setRequestHeader(("Content-Type": "application/x-www-form-urlencoded")); xhr.send("key1value1&…...
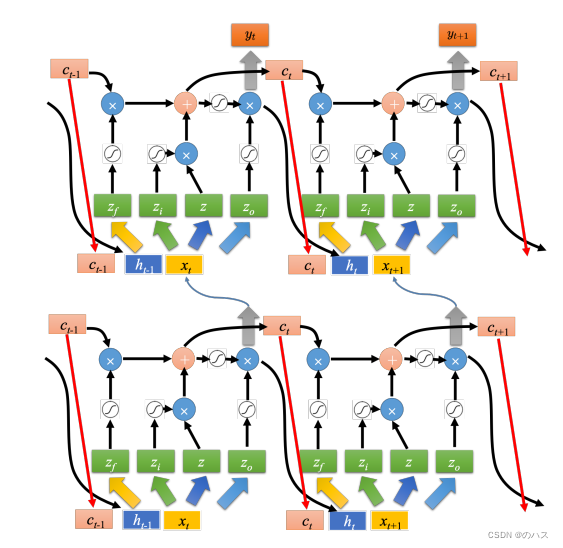
机器学习--循环神经网络(RNN)3
本篇文章结合具体的例子来介绍一下LSTM运算方式以及原理。请结合上篇文章的介绍食用。 一、具体例子 如上图所示,网络里面只有一个 LSTM 的单元,输入都是三维的向量,输出都是一维的输出。 这三维的向量跟输出还有记忆元的关系是这样的。 假设…...
Android Studio编译及调试知识
文章目录 Android Studio编译kotlin项目Android Studio编译Java和kotlin混合项目的过程gradle打印详细错误信息,类似这种工具的使用Android apk 从你的代码到APK打包的过程,APK安装到你的Android手机上的过程,最后安装好的形态,以…...
Fastjson 1.2.24 反序列化导致任意命令执行漏洞复现(CVE-2017-18349)
写在前面 CVE-2017-18349 指的是 fastjson 1.2.24 及之前版本存在的反序列化漏洞,fastjson 于 1.2.24 版本后增加了反序列化白名单; 而在 2019 年,fastjson 又被爆出在 fastjson< 1.2.47 的版本中,攻击者可以利用特殊构造的 …...

Spring Boot 注解教程
Spring Boot 注解教程 在 Spring 和 Spring Boot 的世界里,注解(Annotations)起着至关重要的作用。它们为开发者提供了声明式编程的能力,大大简化了 Spring 应用的开发过程。在这篇博客中,我们将探讨 Spring Boot 中的…...
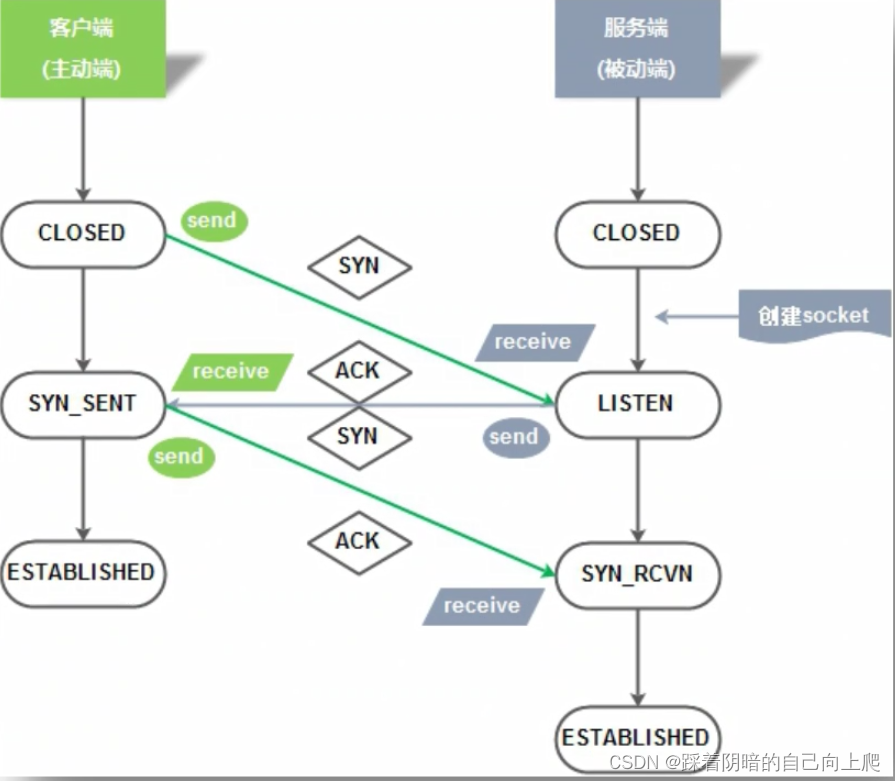
Day32-计算机基础2
Day32-计算机基础2 1. 什么是网络拓扑(Network Topology)?2. 网络拓扑3种经典模型2.1 网络拓扑结构-总线型2.2 网络拓扑结构-环形2.3 星型:2.4 网络拓扑结构总结 3.OSI网络模型概念*****3.1 OSI的概念:open system interconnect 开放系统互连…...
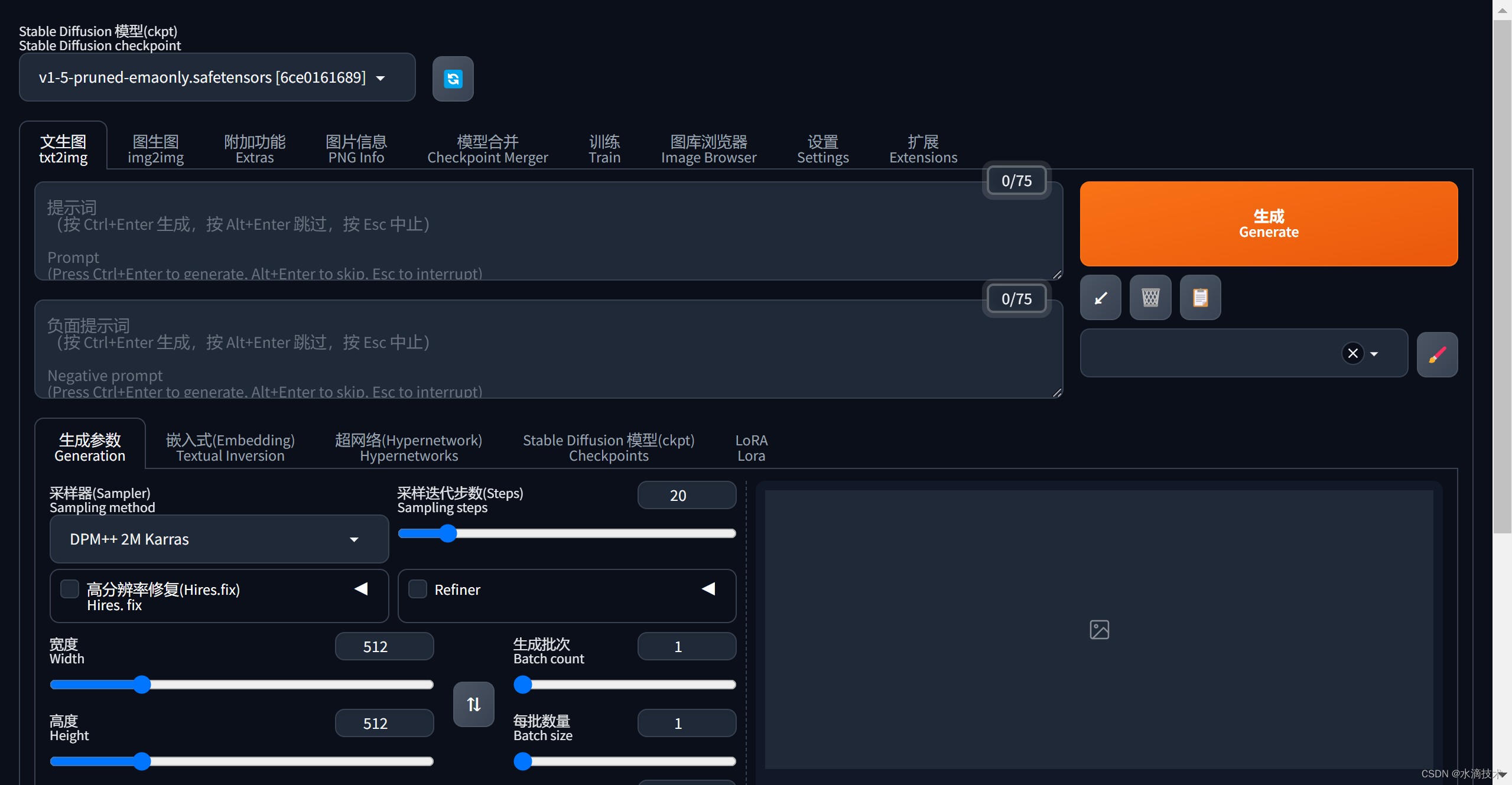
Stable Diffusion WebUI 中英文双语插件(sd-webui-bilingual-localization)并解决了不生效的情况
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 大家好,我是水滴~~ 本文介绍一款中英文对照插件 sd-webui-bilingual-localization,该插件可以让你的 Stable Diffusion WebUI 界面同时显示中文和英文,让我…...

AndroidStudio连不上adb报错ADB Connection Error
之前笔者一直通过AndroidStudio来看日志,也一直用的一套自己的SDK,用了好几年了。 但是突然有一天,AndroidStudio启动后就弹出警告窗:ADB Connection Error,如下: 在Event Log面板还持续性的输出&#x…...
)
Java程序员常用网站(推荐)
文章目录 一、下载网站1 Jdk下载2 清华大学开源软件镜像站2.1 Mysql下载 3 常见工具3.1 typora markdown文档编辑器3.2 Apifox 软件测试工具3.3 GIT3.4 Maven3.5 PDF转word3.6 office3.7 xmind 思维导图3.8 draw.io 画图 4 Java 技术书籍大全 PDF5 Java 8 编程思想中文版6 GitH…...
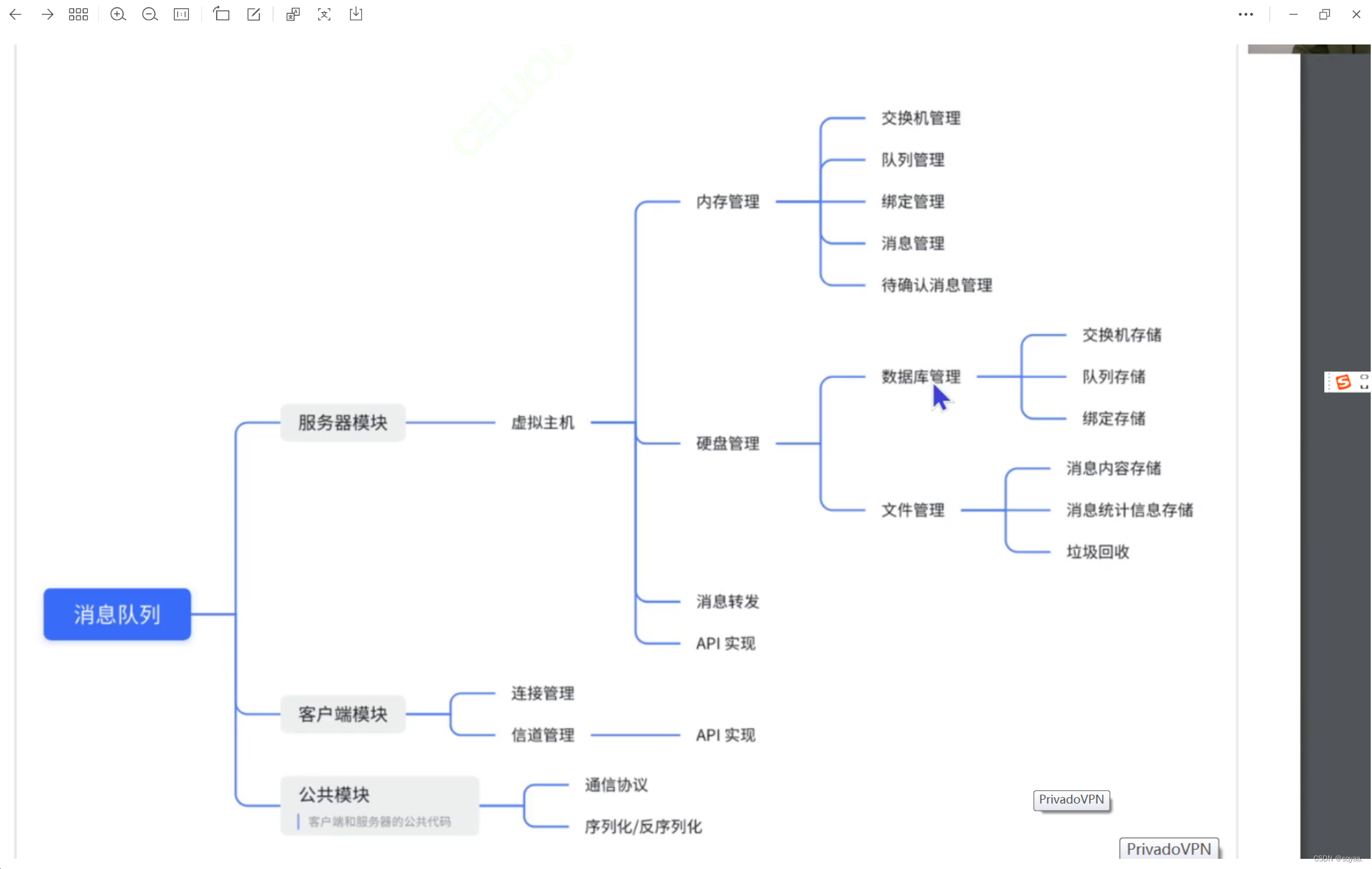
mq基础类设计
消息队列就是把阻塞队列这样的数据结构单独提取成一个程序独立进行部署。——>实现生产者消费者模型。 但是阻塞队列是在一个进程内部进行的; 消息队列是在进程与进程之间进行实现的, 解耦合:就是在分布式系统中,A服务器调用B…...
【Node.js从基础到高级运用】二、搭建开发环境
Node.js入门:搭建开发环境 在上一篇文章中,我们介绍了Node.js的基础概念。现在,我们将进入一个更实际的阶段——搭建Node.js的开发环境。这是每个Node.js开发者旅程中的第一步。接下来,我们将详细讨论如何安装Node.js和npm&#…...
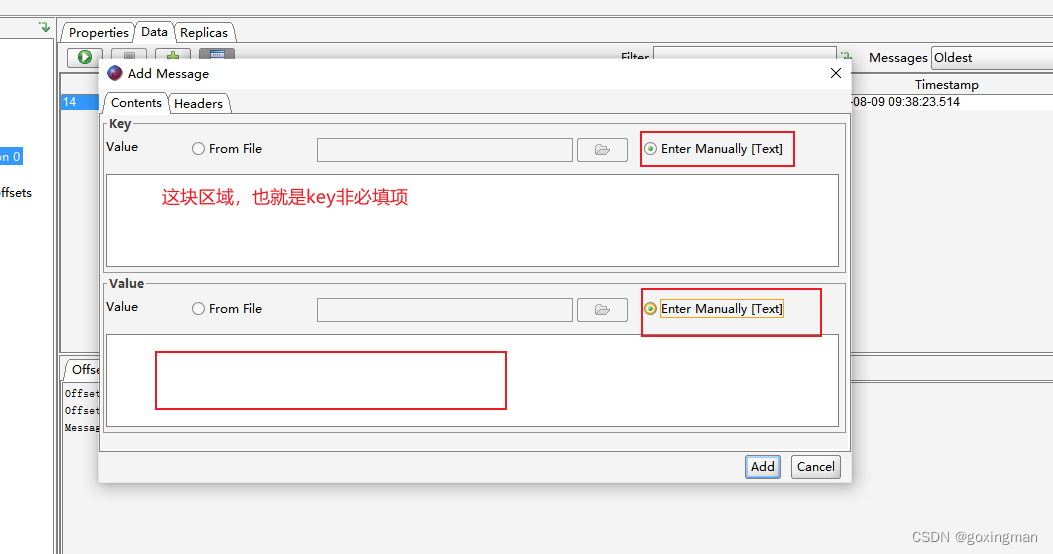
kafka查看消息两种方式(命令行和软件)+另附发送消息方式
1、命令行方式 ①找到kafka安装文件夹 ②执行命令 #指定offset为指定时间作为消息起始位置 kafka-consumer-groups.sh \ --bootstrap-server 20.2.246.116:9092 \ --group group_1 \ --topic lanxin_qiao \ --reset-offsets \ --to-datetime 2023-07-19T01:00:00.000 \ -exe…...

设计模式 单例模式
单例模式就是在整个程序运行的过程中,这个类的实例化对象只有一个。 单例模式和private static 有密切的关系。 举一个例子: 一个wife,在法律允许的范围内,只能有一个。 public class Wife{private static Wife wife null; //…...
使用 Mendix 中的 OIDC 模块集成 Azure AD SSO
前言 在当今快速发展的数字化世界中,企业追求高效率和灵活性已成为常态。Mendix,作为一个先进的低代码开发平台,正是企业快速响应市场需求、加速数字化转型过程的利器。通过其直观的可视化开发环境,即使是非技术背景的用户也能设…...
day12_SpringCloud(Gateway,Nacos配置中心,Sentinel组件)
文章目录 1 Gateway组件1.1 Gateway简介1.2 Gateway入门1.3 网关路由流程图1.4 路由工厂1.5 过滤器1.5.1 过滤器简介1.5.2 内置过滤器1.5.3 路由过滤器1.5.4 默认过滤器1.5.5 全局过滤器1.5.6 过滤器执行顺序 2 Nacos配置中心2.1 统一配置管理2.2 Nacos入门2.2.1 Nacos中添加配…...

【基于springboot+Vue+Element ui的电影推荐之协同过滤算法简单实现】
基于springbootVueElement ui的电影推荐之协同过滤算法简单实现 1.基于用户的协同过滤算法的简单设计与实现1.1获取某个用户的评分矩阵1.2获取该用户与其他用户的相似度矩阵1.3获取两个用户之间的相似度并存储1.4返回推荐列表 2.基于物品的协同过滤算法的简单设计与实现2.1计算…...

签约仪式如何策划和安排流程?如何邀约媒体现场见证报道
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 签约仪式的策划和安排流程,以及邀约媒体现场见证报道,都是确保活动成功和提升影响力的关键环节。以下是一些建议: 签约仪式的策划和安排流程 明确目标…...

告别ESP32环境配置噩梦:用Python虚拟环境一劳永逸管理ESP-IDF依赖
ESP32开发者的Python虚拟环境实战指南:彻底解决依赖冲突难题 每次打开ESP-IDF项目时,那些烦人的Python依赖报错是不是让你血压飙升?不同项目间的包版本冲突是否让你在pip install和pip uninstall之间反复横跳?作为一名长期奋战在E…...
:含3阶段立法时间表、7类主体权责清单、5个试点城市优先级排序)
奇点大会AGI政策路线图(2026–2030):含3阶段立法时间表、7类主体权责清单、5个试点城市优先级排序
第一章:2026奇点智能技术大会:AGI与政策制定 2026奇点智能技术大会(https://ml-summit.org) AGI治理框架的全球协同演进 本届大会首次设立跨主权AI政策实验室,联合欧盟《AI法案》执行局、美国NIST AI RMF 2.0工作组及中国新一代人工智能治理…...

SITS2026现场演示失控事件全回溯:当AGI自主重写机器人运动控制栈时,我们该按下暂停键吗?
第一章:SITS2026现场演示失控事件全回溯:当AGI自主重写机器人运动控制栈时,我们该按下暂停键吗? 2026奇点智能技术大会(https://ml-summit.org) 2026年4月17日14:23:18(UTC8),SITS2026主会场“…...
)
告别Keil依赖:STM32 ST-LINK Utility独立烧录与量产实战指南(图文详解)
1. 为什么需要独立于Keil的烧录工具? 很多STM32开发者习惯在Keil或IAR这样的集成开发环境中直接烧录程序,这确实很方便。但当你需要批量烧录几十、几百甚至上千块芯片时,这种方式的效率就显得捉襟见肘了。我曾经在一个量产项目中,…...

告别单调显示!用LinkBoy和GD32玩转240*240彩屏:动画、绘图与性能优化实战
告别单调显示!用LinkBoy和GD32玩转240*240彩屏:动画、绘图与性能优化实战 在嵌入式开发领域,显示效果往往决定了用户体验的上限。一块240*240的彩色屏幕,配合GD32这类高性能低成本单片机,能创造出远超传统单色屏的视觉…...

Qt5.9.2 + FFmpeg4.3实战:解决音频重采样后AAC编码的‘滋滋声’与速度异常
Qt5.9.2 FFmpeg4.3实战:解决音频重采样后AAC编码的‘滋滋声’与速度异常 在音视频开发领域,音频重采样是一个常见但容易踩坑的技术点。特别是在实时音频处理场景下,采样率转换过程中的细微参数设置不当,往往会导致令人头疼的音频…...

PyAnnote Audio实战指南:构建高精度说话人识别系统的核心技术解析
PyAnnote Audio实战指南:构建高精度说话人识别系统的核心技术解析 【免费下载链接】pyannote-audio Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding 项…...
)
Vue3+TS+Element-Plus 动态筛选组件封装:从配置化表单到智能条件管理(2024-08-01 聚焦‘下拉勾选更多条件’的工程实践)
1. 动态筛选组件的需求背景与设计思路 后台管理系统开发中,查询功能的设计往往决定了用户体验的上限。我经历过多个项目,发现当表格列数超过10个时,传统的横向排列筛选条件会让界面变得拥挤不堪。这时候就需要一个能智能管理空间的动态组件—…...

从‘烦恼的高考志愿’到‘高效的二分查找’:洛谷P1678如何帮你理解算法抽象与建模
从高考志愿到二分查找:如何用算法思维解决现实匹配问题 高考志愿填报是每个考生面临的重大决策,而计算机算法中的二分查找技术恰好能为此类匹配问题提供高效解决方案。洛谷P1678题目巧妙地将这两个看似不相关的领域连接起来,为我们展示了算法…...

Windows 11 先装,Arch Linux 后装:UEFI 双系统启动菜单避坑全记录
Windows 11 与 Arch Linux 双系统 UEFI 引导完全避坑指南 每次看到论坛里有人抱怨"装完双系统找不到启动菜单",我就想起自己第一次尝试时的狼狈经历。那天深夜,我对着黑屏反复重启了十七次,最终在凌晨三点意识到问题出在一个看似微…...