【论文阅读】Mamba:选择状态空间模型的线性时间序列建模(一)
文章目录
- Mamba:选择状态空间模型的线性时间序列建模
- 介绍
- 状态序列模型
- 选择性状态空间模型
- 动机:选择作为一种压缩手段
- 用选择性提升SSM
- 选择性SSM的高效实现
- 先前模型的动机
- 选择扫描总览:硬件感知状态扩展
Mamba论文
Mamba:选择状态空间模型的线性时间序列建模
摘要:结构化状态空间模型表现得不如注意力,我们认为这些模型的缺陷是缺乏能力去实现基于内容的推理,并且作了一些改进。首先,让SSM参数是输入的函数来解决它们处理离散模态的不足,使模型取决于当前token沿着长度维度选择性地传播或者遗忘信息。第二,尽管这些改变阻止了使用高效地卷积,我们在循环模式设计了一种硬件感知的并行算法。我们将这些选择性SSM集合到一个简化的端到端神经网络结构没有注意力甚至是MLP(Mamba)。Mamba可以快速推断(5倍于transformer)和序列长度的线性缩放。
介绍
最近,结构化状态序列模型成为一类有前景的序列建模结构。这些模型可以被解释成循环神经网络和卷积神经网络的结合,从经典状态空间模型中获得启发。这类模型可以被高效计算无论是卷积还是递归形式。但在建模离散和信息密集的模态如文本时没有那么有效。
我们提出一类新的选择性状态空间模型。
选择机制
首先,我们得出先前模型的一个关键不足:以依赖输入的范式高效选择输入的能力。(即关注或者遗忘特定输入)。我们设计了一种简单的选择机制,通过基于输入来参数化SSM参数。无限地遗忘不相关信息或记忆相关信息。
硬件感知算法
实际上,所有前面的SSM模型都是时间和输入不变的以确保高效计算。我们通过硬件感知的算法解决这一点。循环计算模型,通过扫描而不是卷积,但并不实例化扩展的状态,以避免不同层级GPU存储间的IO。
结构
我们简化先前的序列模型结构通过结合先前SSM的设计和Tansformer的MLP块为单个块。
选择SSM,以及扩展Mamba结构,是一个完全的循环模型,有使它们在序列处理上作为通用基础模型的属性
(i) 高质量:选择性在密集模态例如语言和基因上带来更强的表现。
(ii)训练和推断快
(iii) 长文本
我们在经验上验证了Mamba作为通用序列FM backbone的潜力,在预训练和特定领域任务表现上。一些模态和任务的种类
- 合成
- 语音和基因
- 语言建模

结构化SSM独立地映射输入 x x x的每个通道(例如D = 5)到输出 y y y通过一个更高维的隐式状态(例如N = 4)。先前的SSM避免实例化这个大的有效状态 ( D N , t i m e s b a t c h s i z e B a n d s e q u e n c e l e n g t h L ) (DN, times \ batch\ size\ B \ and \ sequence\ length\ L) (DN,times batch size B and sequence length L)需要时间不变性的巧妙交替计算路径: ( Δ , A , B , C ) (\Delta, \textbf A, \textbf B, \textbf C) (Δ,A,B,C)参数在时间上是不变的。我们的选择机制添加了后输入依赖动态,也需要一个合适的硬件感知算法在GPU存储层级中的高级别实例化扩展状态。
状态序列模型
这一部分详见专栏其他文章,如Mamba状态空间模型背景,这里不再赘述
SSM 结构
SSM是独立的序列变换可以结合端到端神经网络结构(我们有时也叫SSM结构SSNN,像CNN对于线性卷积层,SSM层对于SSNN。)我们讨论一些最知名的SSM结构,很多同时作为我们的原始baseline。
- 线性注意力是自注意力的一个估计,包含一个递归可以被看作是线性SSM的退化。
- H3泛化了这个递归去使用S4,可以被看作两个门控连接中间夹一个SSM。H3也插入了标准的局部卷积,在主要SSM层前框架化维一个shift-SSM
- Heyena使用H3相同的结构但是用一个MLP参数化全局卷积替代S4层。
- RetNet在结构中添加了额外的门来使用更简单的SSM,允许一个可选的并行化计算路径,使用多头注意力的变种代替卷积。
- RWKV是最近的设计用于语言建模的RNN,基于另一个线性注意力估计。它的主要"WKV"机制包含时不变递归,可以被看作两个SSM的调和
选择性状态空间模型
我们使用从合成任务而来的直觉驱动我们的选择机制,之后解释如何结合状态空间模型和这个机制。得出的时变SSM不能使用卷积,造成了如何高效计算它们的技术挑战。我们通过利用现代硬件存储层级的一个硬件感知算法克服这个问题。我们之后描述一个简单SSM结构没有注意力甚至MLP块。最后,我们讨论选择机制的额外属性。
动机:选择作为一种压缩手段
我们提出序列建模的一个基本问题是压缩内容到一个更小的状态。事实上,从这一观点我们可以看到流行的序列模型的权衡。例如,注意力是同时是有效和低效的,因为它显然一点也没有压缩内容,从自回归推断需要存储整个内容(例如KV缓存)可以看到这一事实,直接导致了线性时间推断和Transformers的二次方训练时间。换句话说,循环模型是高效的因为它们有有限状态,实现常数时间推断和线性时间训练。然而他们的有效性被这些状态压缩内容有多好而限制。
为了理解这一原则,我们注意两个合成任务的运行示例。
- 选择复制任务通过打乱token的位置来记忆。它需要内容感知推断来记忆相近的tokens(上色的)过滤掉无关的(白色的)
- 注意力机制是著名的机制假说解释LLM内容内学习能力,它需要内容感知推断来了解何时在合适上下文中产生正确输出
这些任务揭示了LTI模型的失效机制。从循环角度,他们固定的动态(例如 ( A ‾ , B ‾ ) (\overline{\textbf A}, \overline{\textbf B}) (A,B))不能让他们从他们的内容中选择合适的信息或者以输入依赖的范式影响序列传递的隐藏状态。从卷积角度上看,已知全局卷积可以解决原始的复制任务,因为它只需要时间感知,但对于选择性复制任务有困难,因为它缺少内容感知,更具体的,在输入到输出的空间是变化的不能被建模成一个固定的卷积核。
总而言之,序列模型效率和有效的权衡由他们压缩状态压缩得有多好定义:高效率得模型必须有较少得状态,而有效得模型必须由可以保存内容中所有必须信息的状态。反过来,我们提出一个搭建序列模型的基本法则是选择性:或者内容感知能力来关注于或过滤输入到序列状态。特别是,一个选择机制控制信息是如何在序列维度传播和交互的。
用选择性提升SSM
(左)标准版本的复制任务包含常数空间在输入输出元素间可以通过时不变模型如线性递归和全局卷积解决。(右上)选择复制任务在输入间有随机的空间需要时变模型集合他们的内容来选择性记住或者忽略输入。(右下)归纳头任务是联想回忆的一个例子,需要根据上下文检索答案,是LLM的一项关键能力。


算法一和算法而描述了我们使用的主要选择机制。主要的不同是让一些参数 Δ , B , C \Delta, \textbf B, \textbf C Δ,B,C是输入的函数,以及贯穿始终的张量形状变化。特别是,我们高亮这些参数现在有·一个长度维 L L L,意味着模型从时不变变成时变。(注意形状标注在第二部分有描述)这失去了卷积的等价性,对其效率有影响,在之后讨论。
我们特别选择 s B ( x ) = L i n e a r N ( x ) , s C ( x ) = L i n e a r N ( x ) , s Δ ( x ) = B r o a d c a s t D ( L i n e a r 1 ( x ) ) s_B(x) = Linear_N(x),s_C(x) = Linear_N(x),s_{\Delta}(x) = Broadcast_D(Linear_1(x)) sB(x)=LinearN(x),sC(x)=LinearN(x),sΔ(x)=BroadcastD(Linear1(x))
和 τ Δ = s o f t p l u s \tau_\Delta = softplus τΔ=softplus, L i n e a r d Linear_d Lineard是一个参数映射到维度 d d d。 s Δ s_\Delta sΔ和 τ Δ \tau_\Delta τΔ的选择是由于和RNN门控机制的联系在3.5描述。
选择性SSM的高效实现
然而,如之前提到的SSM使用的核心缺陷是计算有效性,是为什么S4和所有衍生使用LTI(非选择性)模型,通常以全局卷积的形式。
先前模型的动机
我们先回顾一下我们方法克服前面方法限制的动机和总览。
-
在高层次,循环模型例如SSM总是在表达性和速度间取得平衡,像是在3.1讨论的那样,有更大隐藏状态维度的模型应该更有效但更慢。因此我们想要最大化隐藏状态维度而不付出速度和存储代价。
-
注意循环模式比卷积模式更灵活,因为后者是由前者扩展而来。然而,这可能需要计算和实例化 ( B , L , D , N ) (B,L,D,N) (B,L,D,N)的潜在状态 h h h,相比于 ( B , L , D ) (B,L,D) (B,L,D)的输入 x x x和输出 y y y大 N N N倍。因此更高效的卷积被引入,可以跳过状态计算并实例化一个卷积核
( B , L , D ) (B,L,D) (B,L,D)
-
前面的LTI SSM利用对偶循环-卷积模式以一个因子 N ( ≈ 10 − 100 ) N(\approx10-100) N(≈10−100)来提升有效状态,比传统RNN大得多,没有效率损失。
选择扫描总览:硬件感知状态扩展
选择机制设计被用来克服LTI模型的限制。在同时,我们需要回顾SSM计算问题。我们解决它用了三种经典技术:核融合,并行扫描和重计算。我们作了两个主要观察:
- 原始的循环计算使用了 O ( B L D N ) F L O P s O(BLDN)FLOPs O(BLDN)FLOPs而卷积计算使用 O ( B L D l o g ( L ) ) O(BLDlog(L)) O(BLDlog(L))FLOPs,但是前者有更小的常数因子。因此对于长序列和不大的状态维度 N N N,循环模式实际用了更少的FLOPs。
- 两个挑战是递归的序列性质和大存储使用量。为了解决后者,就像卷积模式一样,我们可以尝试不实际实现完整状态 h h h
最后,我们还必须避免保存中间状态,这对于反向传播是必要的。我们谨慎地应用经典的重新计算技术来降低内存需求:当输入从HBM加载到SRAM时,中间状态不会被存储,而是在后向通道中重新计算。因此,融合的选择性扫描层具有与FlashAttention优化Transformer实现相同的内存需求。
相关文章:
【论文阅读】Mamba:选择状态空间模型的线性时间序列建模(一)
文章目录 Mamba:选择状态空间模型的线性时间序列建模介绍状态序列模型选择性状态空间模型动机:选择作为一种压缩手段用选择性提升SSM 选择性SSM的高效实现先前模型的动机选择扫描总览:硬件感知状态扩展 Mamba论文 Mamba:选择状态空间模型的线性时间序列建…...

漏洞复现-蓝凌LandrayOA系列
蓝凌OA系列 🔪 是否利用过 优先级从高到低 发现日期从近到远 公司团队名_产品名_大版本号_特定小版本号_接口文件名_漏洞类型发现日期.载荷格式LandrayOA_Custom_SSRF_JNDI漏洞 LandrayOA_sysSearchMain_Rce漏洞 LandrayOA_Custom_FileRead漏洞...

计算机网络 路由算法
路由选择协议的核心是路由算法,即需要何种算法来获得路由表中的各个项目。 路由算法的目的很明显,给定一组路由器以及连接路由器的链路,路由算法需要找到一条从源路由器到目的路由器的最佳路径,通常,最佳路径是由最低…...
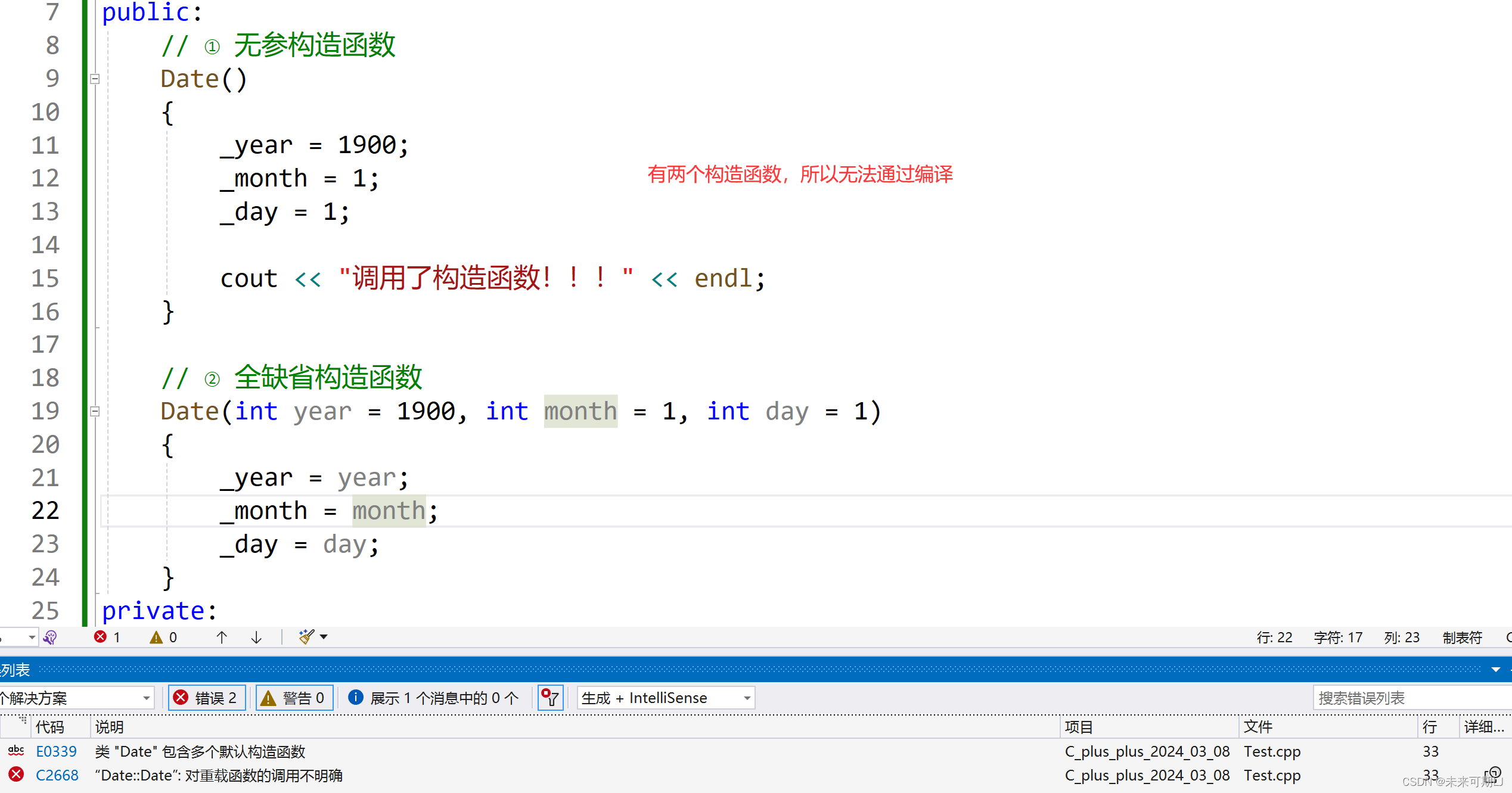
【C++ 学习】构造函数详解!!!
1. 类的6个默认成员函数的引入 ① 如果一个类中什么成员都没有,简称为空类。 ② 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 ③ 默认成员函数:用户没有显式实现&…...
——代码随想录算法训练营Day55)
【LeetCode】72. 编辑距离(中等)——代码随想录算法训练营Day55
题目链接:72. 编辑距离 题目描述 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 示例 1: 输入:w…...
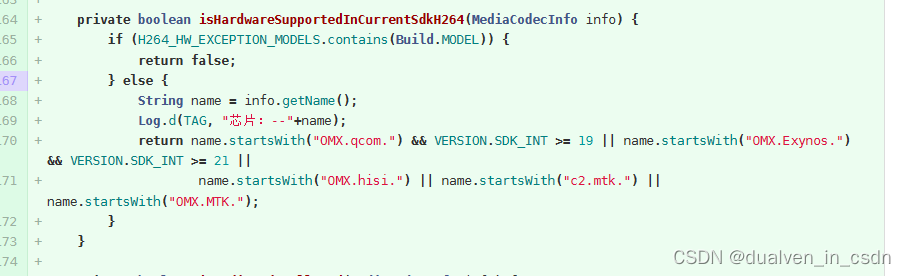
关于手机是否支持h264的问题的解决方案
目录 现象 原理 修改内容 现象 开始以为是手机不支持h264的编码 。机器人chatgpt一通乱扯。 后来检查了下手机,明显是有h264嘛。 终于搞定,不枉凌晨三点起来思考 原理 WebRTC 默认使用的视频编码器是VP8和VP9,WebRTC内置了这两种编码器…...
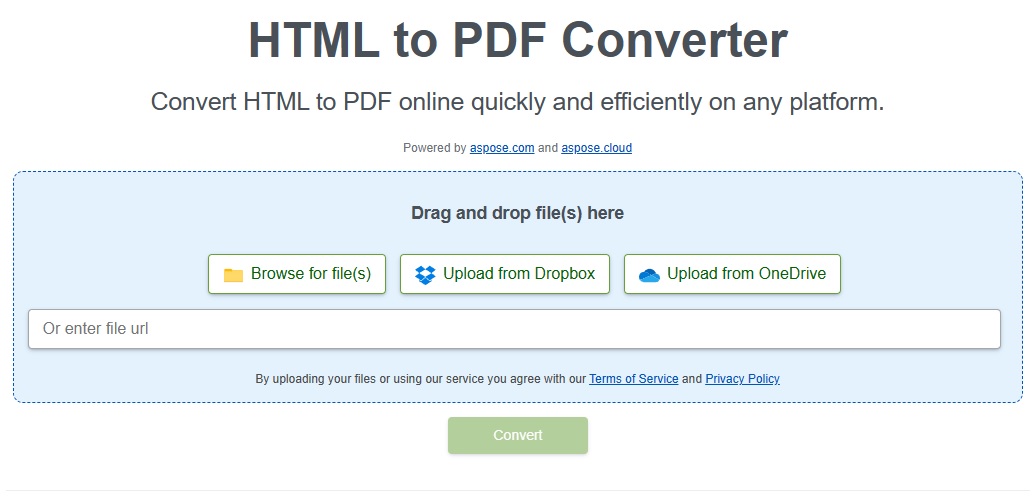
借助Aspose.html控件,在 Java 中将 URL 转换为 PDF
如果您正在寻找一种将实时 URL 中的网页另存为 PDF文档的方法,那么您来对地方了。在这篇博文中,我们将学习如何使用 Java 将 URL 转换为 PDF。从实时 URL转换HTML网页可以像任何其他文档一样保存所需的网页以供离线访问。将网页保存为 PDF 格式可以轻松突…...
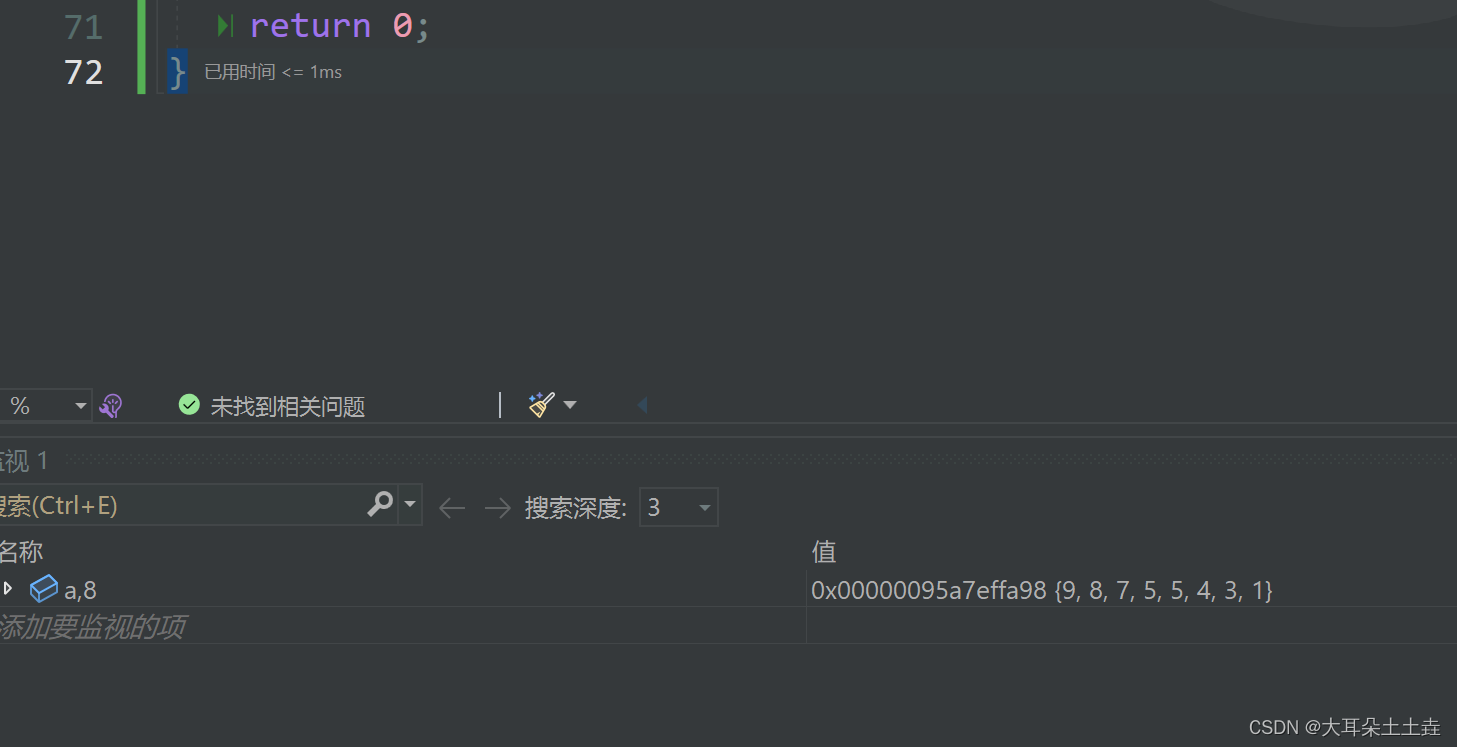
数据结构——堆的应用 堆排序详解
💞💞 前言 hello hello~ ,这里是大耳朵土土垚~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 💥个人主页&#x…...
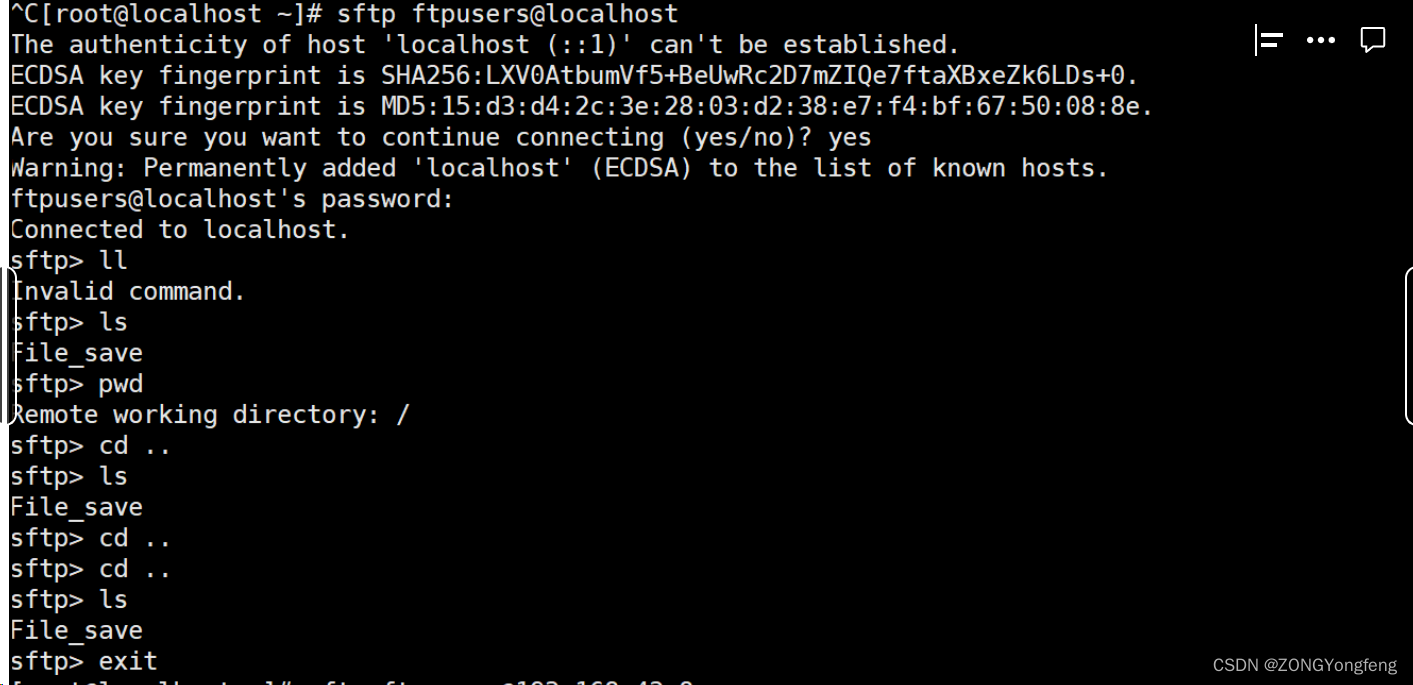
Sftp服务器搭建(linux)
Sftp服务器搭建(linux) 一、基本工作原理 FTP的基本工作原理如下: 1)建立连接:客户端与服务器之间通过TCP/IP建立连接。默认情况下,FTP使用端口号21作为控制连接的端口。 2)身…...
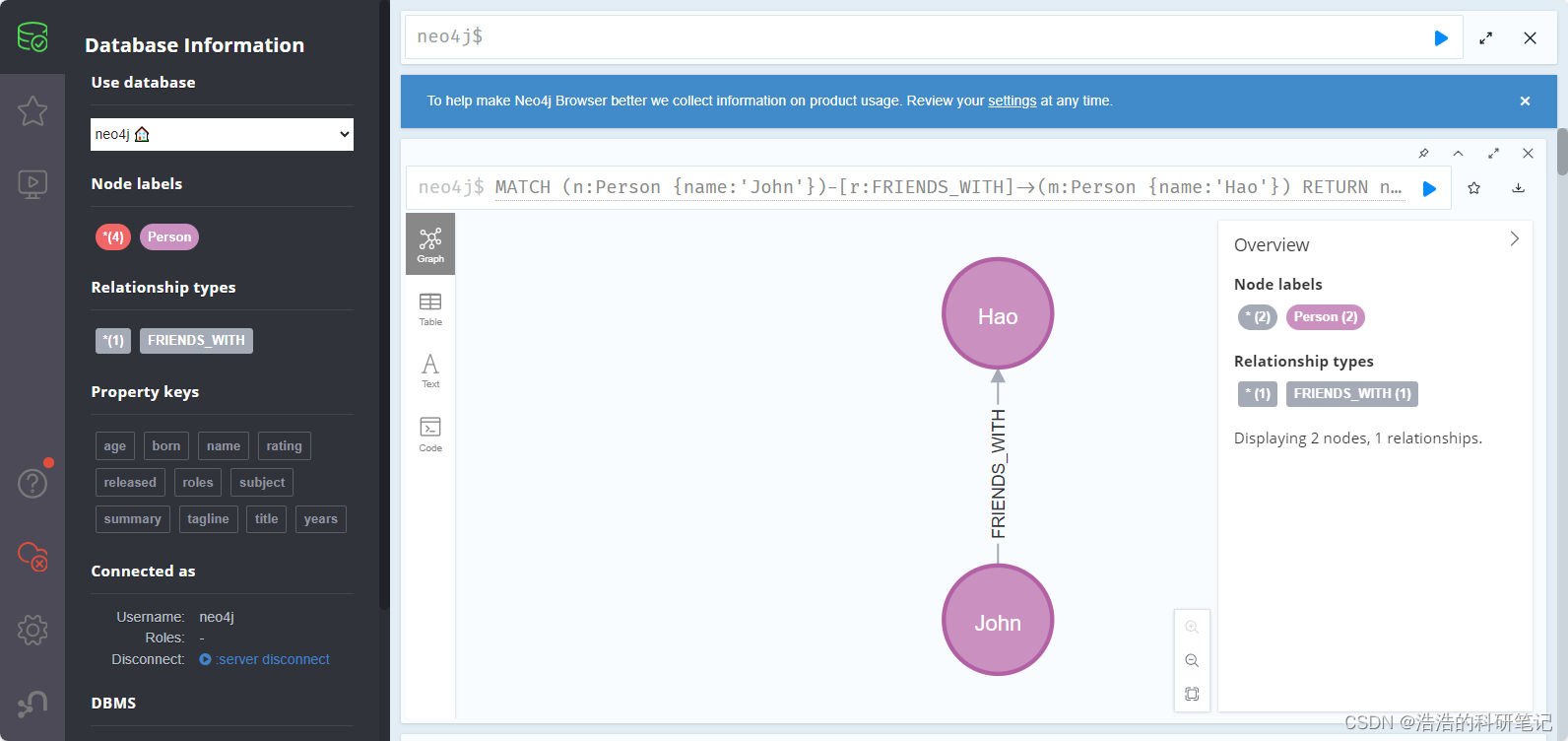
Neo4j 新手教程 环境安装 基础增删改查 python链接 常用操作 纯新手向
Neo4j安装教程🚀 目前在学习知识图谱的相关内容,在图数据库中最有名的就是Neo4j,为了降低入门难度,不被网上很多华丽呼哨的Cypher命令吓退,故分享出该文档,为自己手动总结,包括安装环境,增删改查…...
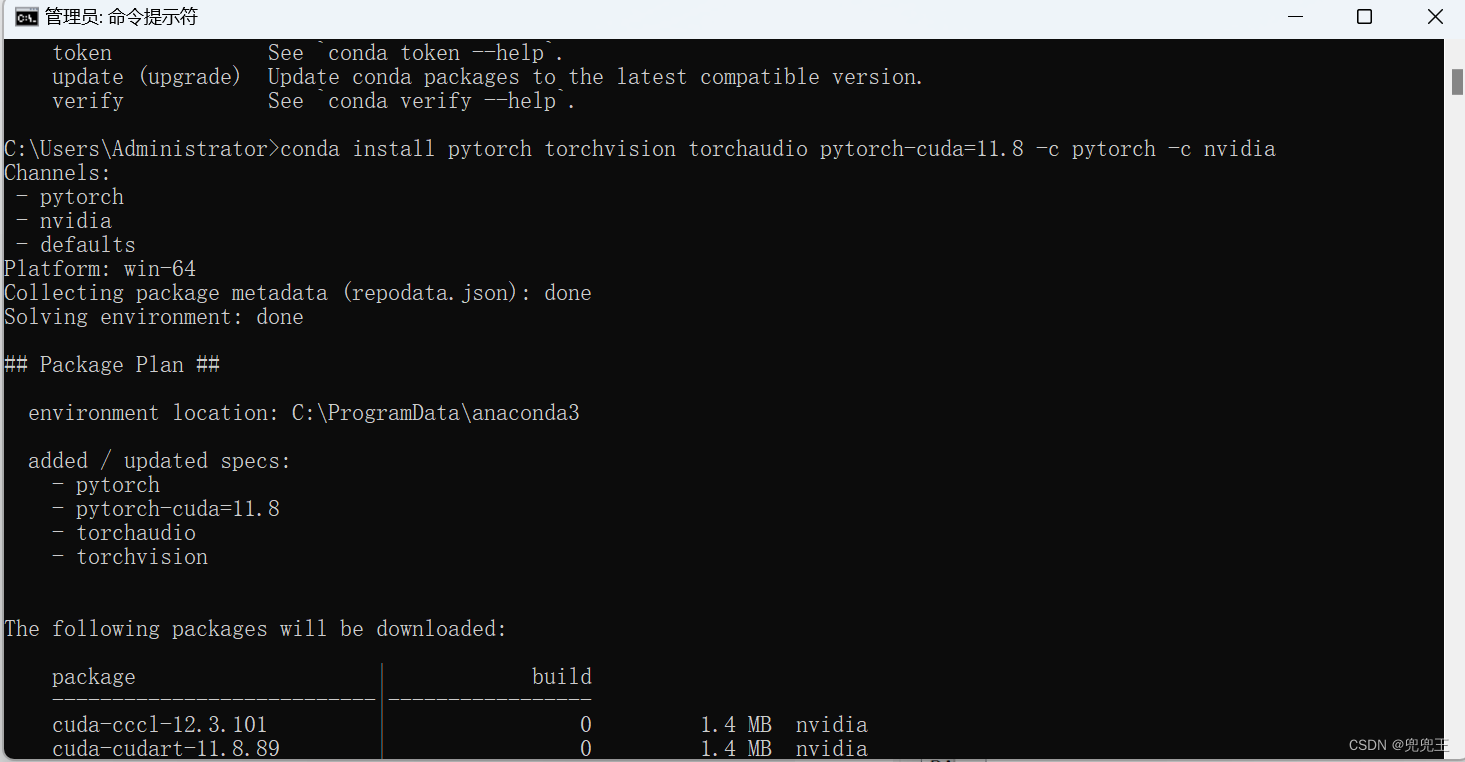
PyTorch2.0 环境搭建详细步骤(Nvidia显卡)
Step 1 、查看显卡驱动版本 Step2、下载CUDA 11.7 或者11.8(我自己用的这个)也行,稍后我会贴出来版本匹配对应表 https://developer.nvidia.com/cuda-toolkit-archive Step3、下载CUDNN cuDNN 9.0.0 Downloads | NVIDIA Developer Step4、安装anconda&…...

Python逆向:pyc字节码转py文件
一、 工具准备 反编译工具:pycdc.exe 十六进制编辑器:010editor 二、字节码文件转换 在CTF中,有时候会得到一串十六进制文件,通过010editor使用查看后,怀疑可能是python的字节码文件。 三、逆向反编译 将010editor得到…...

提示词工程技术:类比、后退、动态少样本、自动生成CoT
类比提示 “类比提示”利用类比推理的概念,鼓励模型生成自己的例子和知识,从而实现更灵活和高效的解决问题。 后退提示 “后退提示”专注于抽象,引导模型推导出高级概念和原理,进而提高其推理能力。 使用一个基本的数学问题来…...

【深度学习笔记】6_5 RNN的pytorch实现
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.5 循环神经网络的简洁实现 本节将使用PyTorch来更简洁地实现基于循环神经网络的语言模型。首先,我们读取周杰伦专辑歌词…...
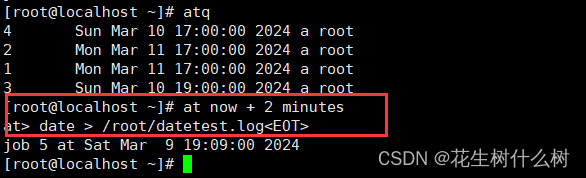
Linux at任务调度命令行编辑错误
错误: 在at任务调度命令行语句编辑错误时,按backspace进行删除无法进行。 解决方案: 请按Ctrlbackspace进行删除,即可解决。...

lua与C++粘合层框架
lua调用C++ 在lua中是以函数指针的形式调用函数, 并且所有的函数指针都必须满足如下此种类型: typedef int (*lua_CFunction) (lua_State *L); 也就是说, 偶们在C++中定义函数时必须以lua_State为参数, 以int为返回值才能被Lua所调用. 但是不要忘记了, 偶们的lua_State是支…...

POST 请求,Ajax 与 cookie
POST 请求则需要设置RequestHeader告诉后台传递内容的编码方式以及在 send 方法里传入对应的值 xhr.open("POST", url, true); xhr.setRequestHeader(("Content-Type": "application/x-www-form-urlencoded")); xhr.send("key1value1&…...
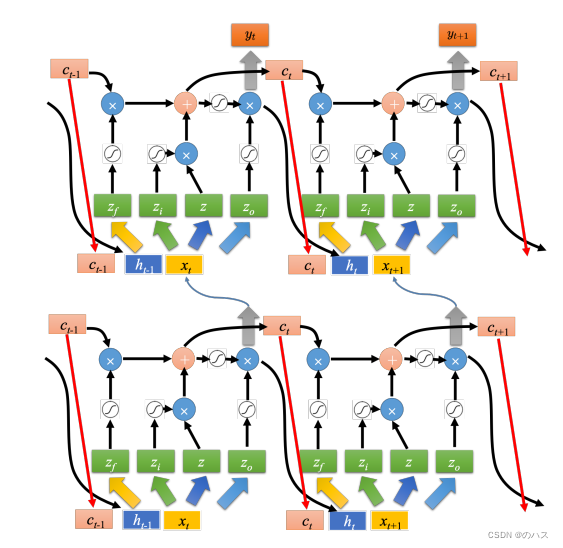
机器学习--循环神经网络(RNN)3
本篇文章结合具体的例子来介绍一下LSTM运算方式以及原理。请结合上篇文章的介绍食用。 一、具体例子 如上图所示,网络里面只有一个 LSTM 的单元,输入都是三维的向量,输出都是一维的输出。 这三维的向量跟输出还有记忆元的关系是这样的。 假设…...
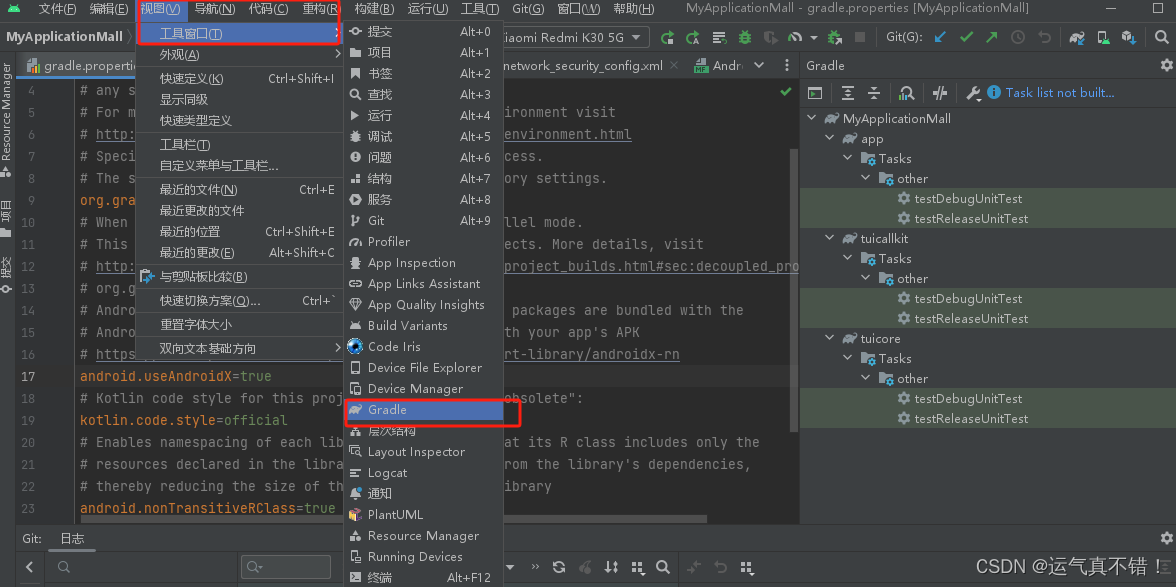
Android Studio编译及调试知识
文章目录 Android Studio编译kotlin项目Android Studio编译Java和kotlin混合项目的过程gradle打印详细错误信息,类似这种工具的使用Android apk 从你的代码到APK打包的过程,APK安装到你的Android手机上的过程,最后安装好的形态,以…...
Fastjson 1.2.24 反序列化导致任意命令执行漏洞复现(CVE-2017-18349)
写在前面 CVE-2017-18349 指的是 fastjson 1.2.24 及之前版本存在的反序列化漏洞,fastjson 于 1.2.24 版本后增加了反序列化白名单; 而在 2019 年,fastjson 又被爆出在 fastjson< 1.2.47 的版本中,攻击者可以利用特殊构造的 …...

共享内存数据残留怎么办?深入理解shmget/shmctl的生命周期管理与清理实战
共享内存数据残留怎么办?深入理解shmget/shmctl的生命周期管理与清理实战 在Linux系统编程中,共享内存是进程间通信(IPC)最高效的方式之一,但它的生命周期管理却常常让开发者感到困惑。你是否遇到过这样的情况:测试程序明明已经退…...

AI教材写作大揭秘:实用工具推荐,助力低查重教材快速编写!
传统资料整合困境与AI写教材的优势 编写教材离不开丰富的资料支持,但传统的资料整合方式已经难以满足我们日益增长的需求。过去,想要从课程标准、学术文献、教学案例中提炼出有价值的信息,得在知网、教研平台等各个渠道间费时费力࿰…...

三步掌握Textractor:让外语游戏对话不再困扰你
三步掌握Textractor:让外语游戏对话不再困扰你 【免费下载链接】Textractor Extracts text from video games and visual novels. Highly extensible. 项目地址: https://gitcode.com/gh_mirrors/te/Textractor 还在为外语游戏中的对话看不懂而烦恼吗&#x…...

从‘地图管理’模块实战出发:手把手拆解一个Vue2 + Vuex的中后台项目store配置
从地图管理模块实战解析Vue2 Vuex状态管理架构设计 在构建中后台管理系统时,状态管理往往是决定项目可维护性的关键因素。以地图资源管理模块为例,我们将深入探讨如何基于Vue2和Vuex设计一个可扩展、易维护的状态管理架构。不同于简单的API调用示例&…...

如何彻底修复Windows 11任务栏和开始菜单崩溃问题:ExplorerPatcher技术深度解析与实战指南
如何彻底修复Windows 11任务栏和开始菜单崩溃问题:ExplorerPatcher技术深度解析与实战指南 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatch…...
)
告别‘黑盒’:用改进的U-Net+数据增强,实战搞定皮肤镜图像分割(附ISIC 2017数据集代码)
医学图像分割实战:改进U-Net在皮肤镜分析中的应用详解 当第一次看到皮肤镜图像时,大多数人都会被那些看似随机分布的色素沉着和复杂纹理所困惑。作为一名长期从事医学影像分析的研究者,我清楚地记得刚开始接触ISIC数据集时的挫败感——那些模…...

STK与Python联合仿真实战:构建Walker星座并自动化评估覆盖性能
1. 从零开始:STK与Python联合仿真环境搭建 第一次接触STK和Python联合仿真时,我花了两天时间才把环境配置明白。现在回想起来,其实关键步骤就几个,但当时没人指点确实走了不少弯路。先说说最基础的准备工作,我会尽量把…...

终极指南:使用LeetDown为iPhone和iPad进行快速降级恢复
终极指南:使用LeetDown为iPhone和iPad进行快速降级恢复 【免费下载链接】LeetDown a GUI macOS Downgrade Tool for A6 and A7 iDevices 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown 你是否拥有一台运行缓慢的iPhone 5s或iPad 4?苹果的…...

WindowsCleaner终极指南:3步解决C盘爆红,让系统重获新生
WindowsCleaner终极指南:3步解决C盘爆红,让系统重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘空间不足的警告…...

终极指南:用Mac Mouse Fix让普通鼠标超越苹果触控板体验
终极指南:用Mac Mouse Fix让普通鼠标超越苹果触控板体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾经在Mac上使用第三…...