Elasticsearch从入门到精通-03基本语法学习
Elasticsearch从入门到精通-03基本语法学习
👏作者简介:大家好,我是程序员行走的鱼
📖 本篇主要介绍和大家一块学习一下ES基本语法,主要包括索引管理、文档管理、映射管理等内容
1.1 了解Restful
ES对数据进行增、删、改、查是以Restful方式对服务端发送请求的,所以在我们学习基本语法之前先了解一下Restful是什么?
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful。Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI (Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和DELETE。
在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、PUT、DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。
1.2 Elasticsearch的数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库MySQL 存储数据的概念进行一个类比
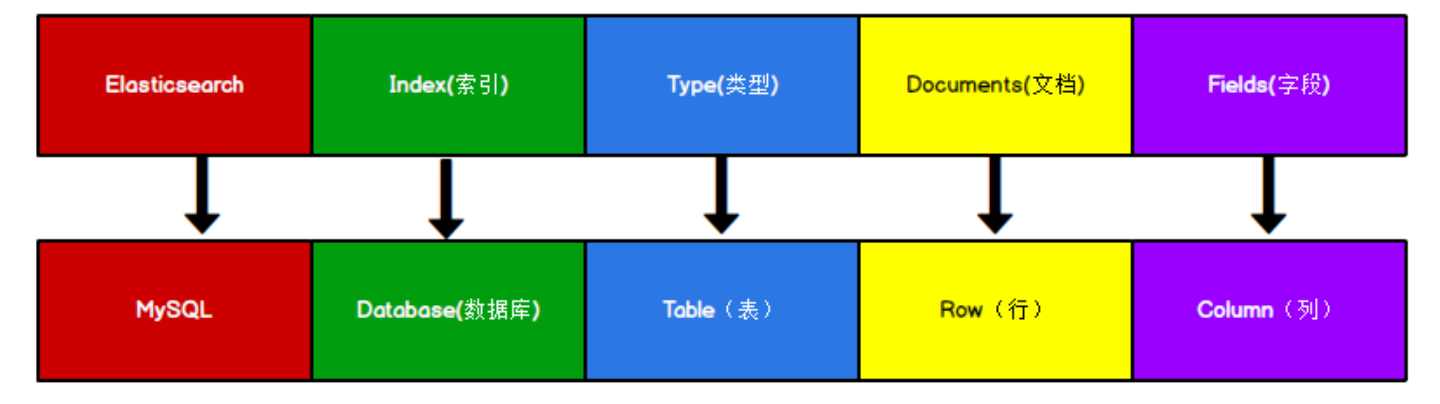
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
1.3 索引操作
1)创建索引
语法:put /索引名
示例:

{
“acknowledged”【响应结果】: true, # true 操作成功
“shards_acknowledged”【分片结果】: true, # 分片操作成功
“index”【索引名称】: “shopping”
}
注意:创建索引库的分片数(7.0.0之后)默认1片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
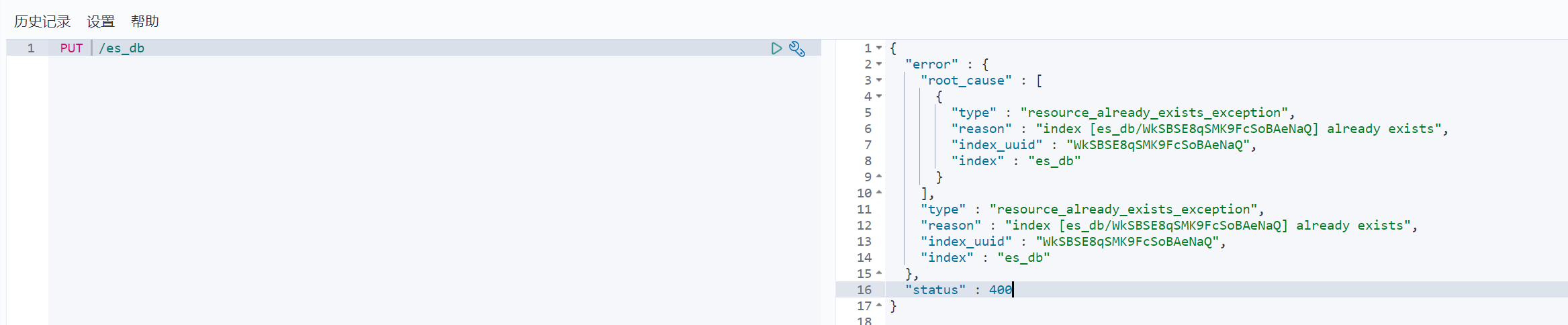
当然ES是不允许我们重复创建索引的,如果重复创建索引出报以下错误:
2)查询索引
语法:GET /索引名
示例:
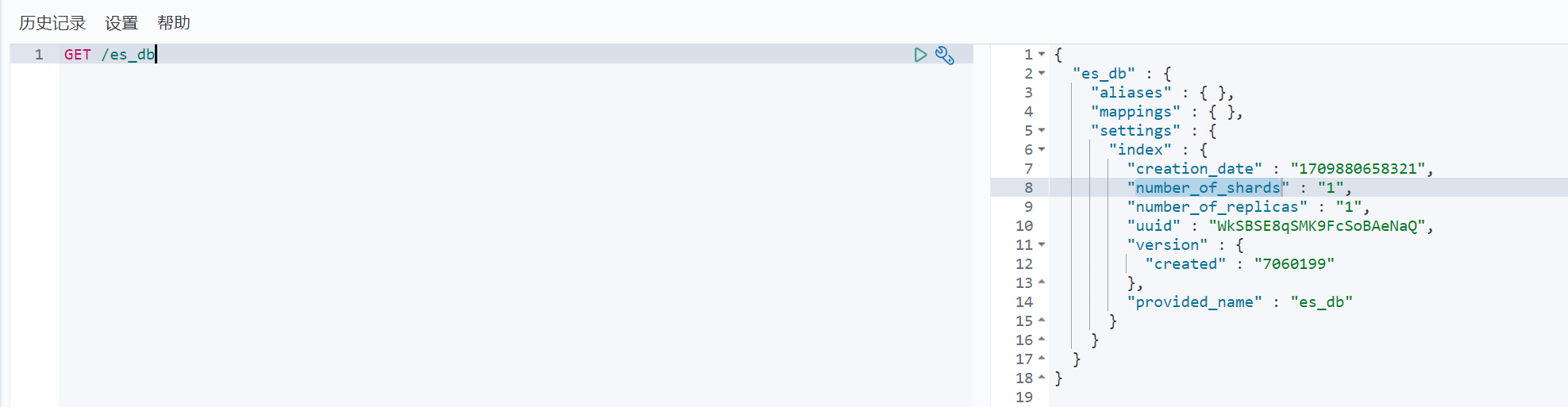
{"es_db": { //索引名"aliases": {}, //别名"mappings": {},//映射"settings": {//设置"index": { //【设置 - 索引"creation_date": "1669733081007",//设置 - 索引 - 创建时间"number_of_shards": "1",//设置 - 索引 - 主分片数量"number_of_replicas": "1",//设置 - 索引 - 副分片数量"uuid": "qhr5DAFeSrOGex2vElBwag", //设置 - 索引 - 唯一标识"version": { //设置 - 索引 - 版本"created": "7080099"},"provided_name": "shopping" //设置 - 索引 - 名称}}}
}
3)查询所有索引
语法:GET /_cat/indices?v
这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉.
示例:

字段说明:
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态:green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
4)删除索引
语法:DELETE /索引名称
示例:

1.4 文档操作
1)创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
PUT /es_db/_doc/1
{"name": "张三","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"
}PUT /es_db/_doc/2
{"name": "李四","sex": 1,"age": 28,"address": "广州荔湾大厦","remark": "java assistant"
}PUT /es_db/_doc/3
{"name": "rod","sex": 0,"age": 26,"address": "广州白云山公园","remark": "php developer"
}PUT /es_db/_doc/4
{"name": "admin","sex": 0,"age": 22,"address": "长沙橘子洲头","remark": "python assistant"
}PUT /es_db/_doc/5
{"name": "小明","sex": 0,"age": 19,"address": "长沙岳麓山","remark": "java architect assistant"
}
结果:

"_index" : "es_db",//索引"_type" : "_doc",//类型-文档"_id" : "1",//唯一标识 可以类比为 MySQL 中的主键,不指定随机生成"_version" : 1,//版本"result" : "created",//这里的 create 表示创建成功"_shards" : {//分片"total" : 2, //分片 - 总数"successful" : 1,//分片 - 成功"failed" : 0//分片 - 失败},"_seq_no" : 0,"_primary_term" : 1
}
使用put名称添加数据的时候必须指定id,使用post可以不需要添加id,系统会默认随机生成一个id
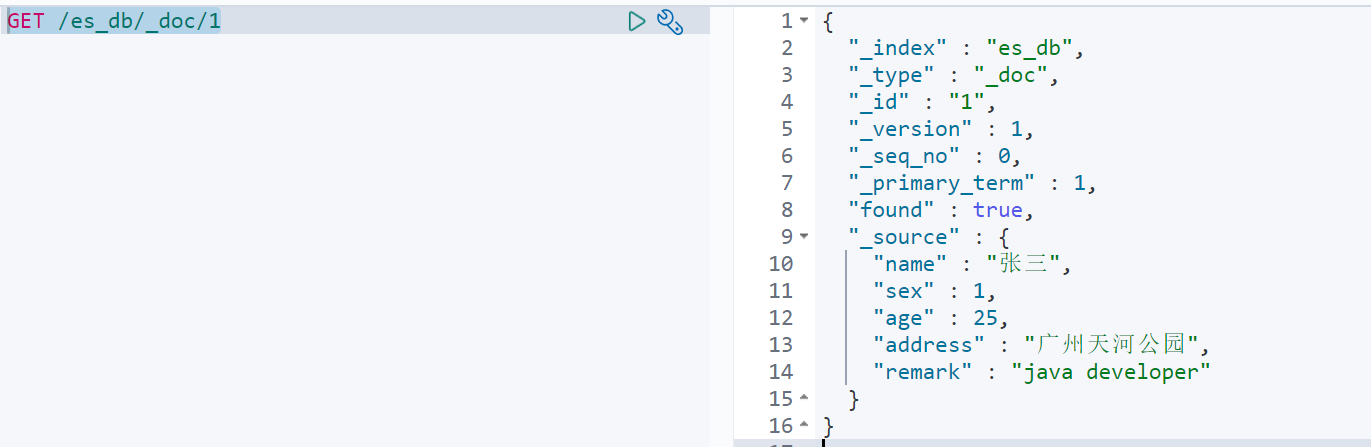
2)查看文档
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
语法: PUT /索引名称/类型/id
示例:
{"_index" : "es_db", //索引"_type" : "_doc",//文档类型"_id" : "1",//文档id"_version" : 1,//文档版本"_seq_no" : 0,"_primary_term" : 1,"found" : true,//查询结果 true 表示查找到,false 表示未查找到"_source" : {//文档源信息"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}
}
3)修改文档
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖。
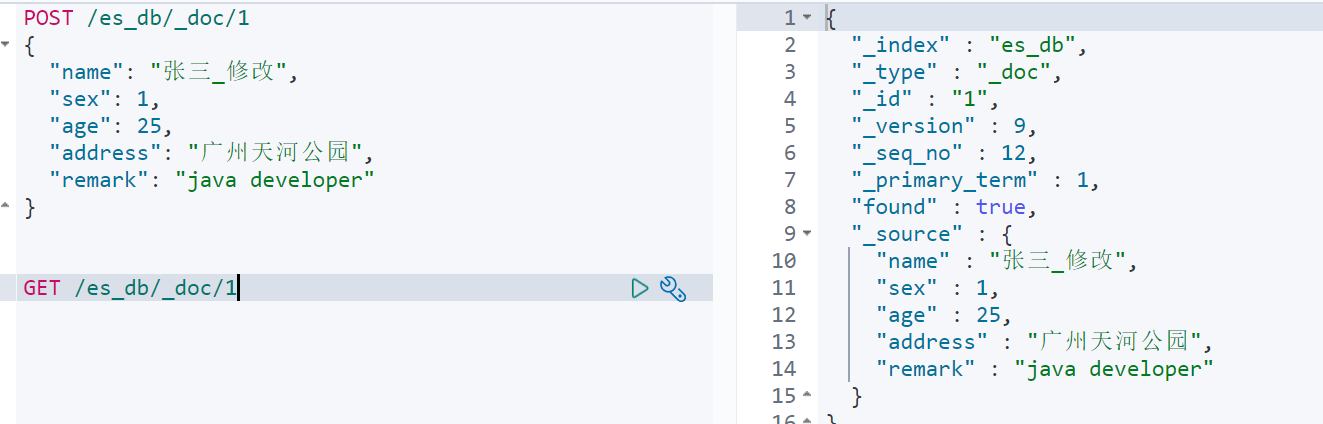
POST /es_db/_doc/1
{"name": "张三_修改","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"
}
示例:
4)删除文档
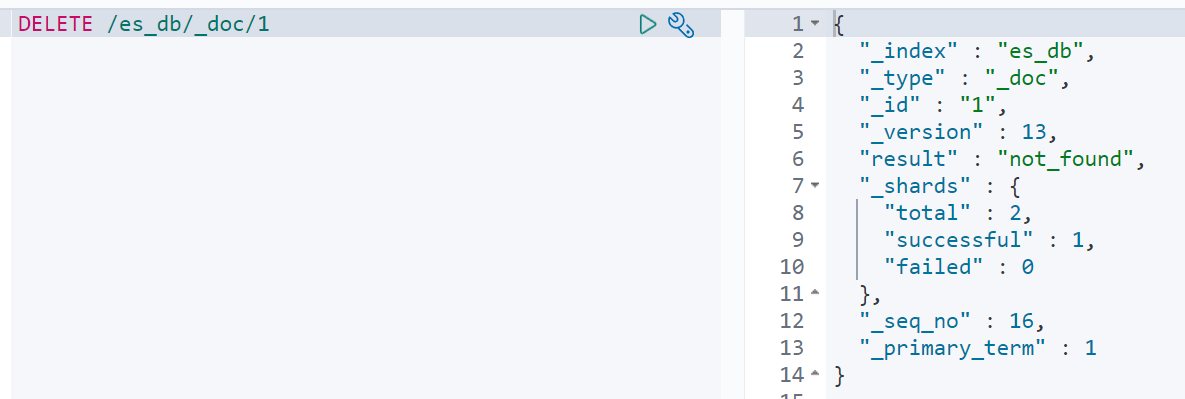
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
语法: DELETE /索引名称/类型/id
示例:
5)批量获取文档
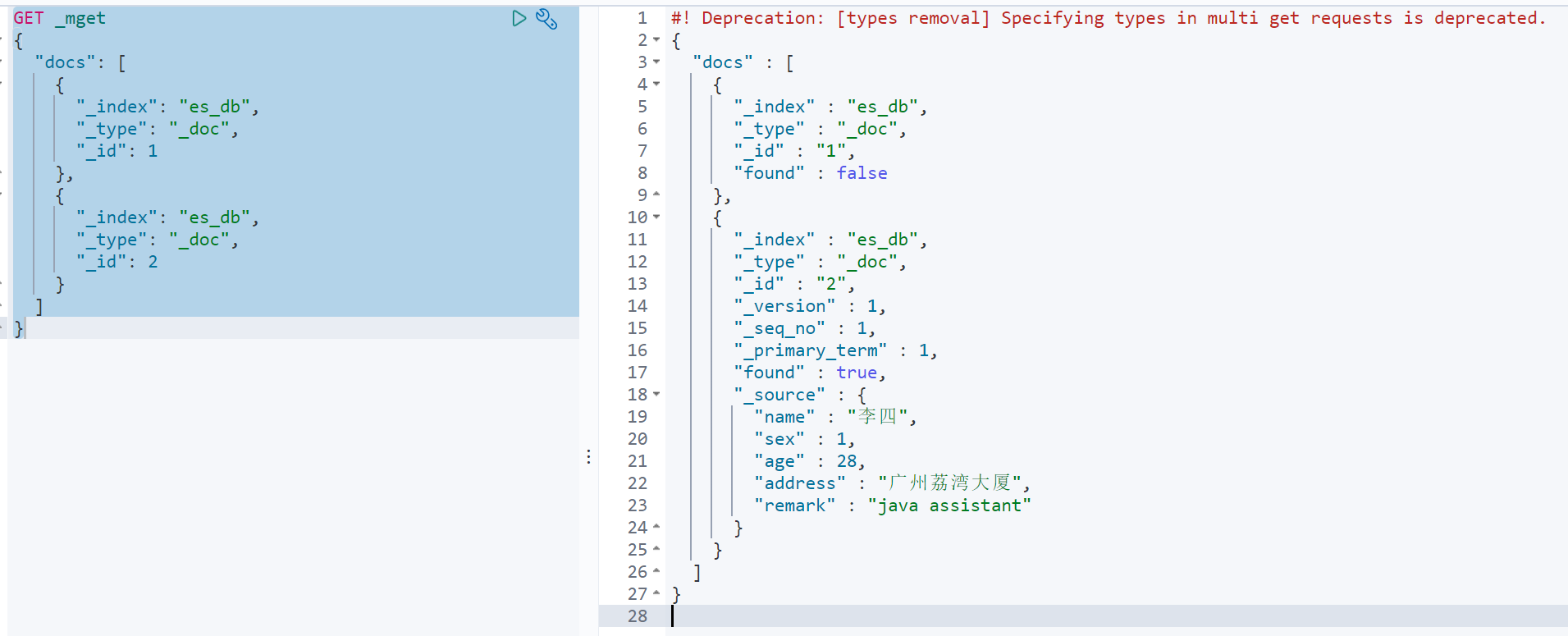
方式1:
GET _mget
{"docs": [{"_index": "es_db","_type": "_doc","_id": 1},{"_index": "es_db","_type": "_doc","_id": 2}]
}
示例:
方式2:
GET /es_db/_mget
{"docs": [{"_type": "_doc","_id": 3},{"_type": "_doc","_id": 4}]
}
示例:

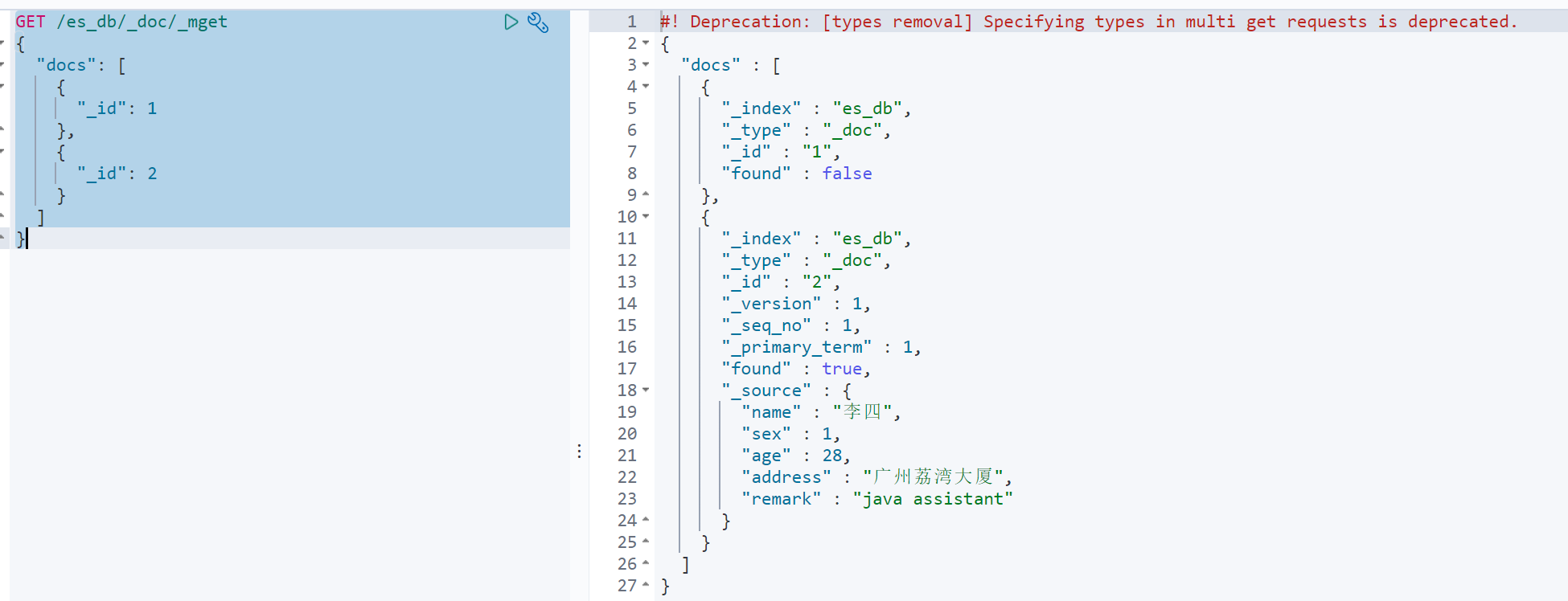
方法3:
GET /es_db/_doc/_mget
{"docs": [{"_id": 1},{"_id": 2}]
}
6)批量操作文档
格式:
批量对文档进行写操作是通过_bulk的API来实现的
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
- 第一行参数为指定操作的类型和操作的对象
- 第二行参数才是操作的数据
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
- actionName:表示操作类型,主要有create,index,delete和update
批量创建文档:
POST _bulk
{"create":{"_index":"es_db","_type":"_doc","_id":6}}
{"id":6,"name" : "李四","sex" : 1,"age" : 28,"address" : "广州荔湾大厦", "remark" : "java assistant"}
{"create":{"_index":"es_db","_type":"_doc","_id":7}}
{"id":6,"name" : "李四","sex" : 1,"age" : 28,"address" : "广州荔湾大厦", "remark" : "java assistant"}
普通创建或者全量替换INDEX
- 如果原文档不存在,则是创建
- 如果原文档存在,则是替换(全量修改原文档)
POST _bulk
{"index":{"_index":"es_db","_type":"_doc","_id":6}}
{"id":6,"name":"李四_修改"}
{"index":{"_index":"es_db","_type":"_doc","_id":8}}
{"id":8,"name":"李四","sex":1,"age":28,"address":"广州荔湾大厦","remark":"java assistant"}
批量删除:
POST _bulk
{"delete":{"_index":"es_db", "_type":"_doc", "_id":6}}
{"delete":{"_index":"es_db", "_type":"_doc", "_id":7}}
批量修改:
POST _bulk
{"update":{"_index":"es_db", "_type":"_doc", "_id":3}}
{"doc":{"name":"李四_修改"}}
{"update":{"_index":"es_db", "_type":"_doc", "_id":4}}
{"doc":{"name":"李四_修改"}}
1.5 索引映射
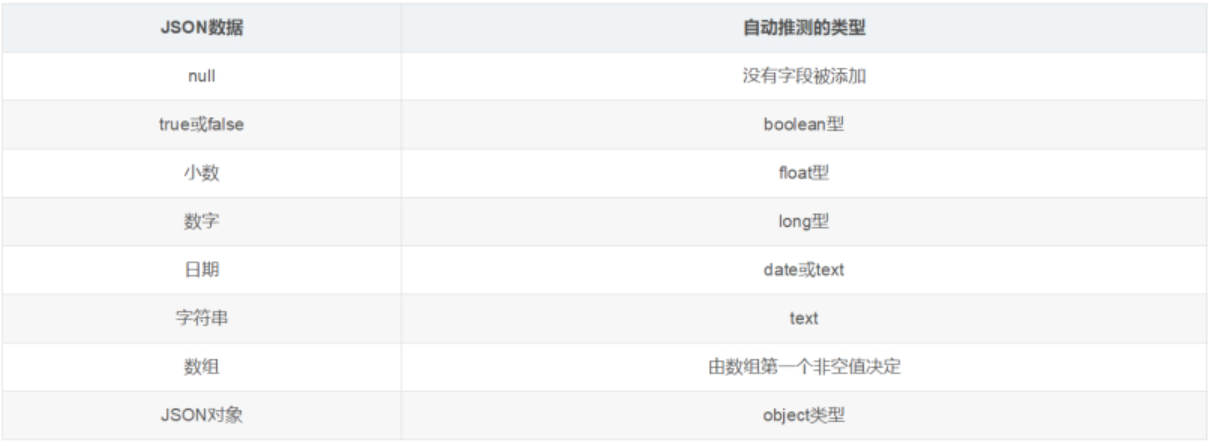
有了索引库,等于有了数据库中的 database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。ES中映射可以分为动态映射和静态映射
动态映射:
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下:
静态映射:
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
1)创建映射
创建student索引
PUT /student
创建student索引映射
语法:
PUT /student/_mapping
{"properties":{"name":{"type":"text","index":true},"sex":{"type":"text","index":false},"age":{"type":"long","index":false}}
}
映射数据说明:
-
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
-
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
- String 类型,又分两种:
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String 类型,又分两种:
-
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
-
store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
2)修改映射
一个索引库如果创建好了索引映射,是无法直接进行修改的,会提示一下错误:
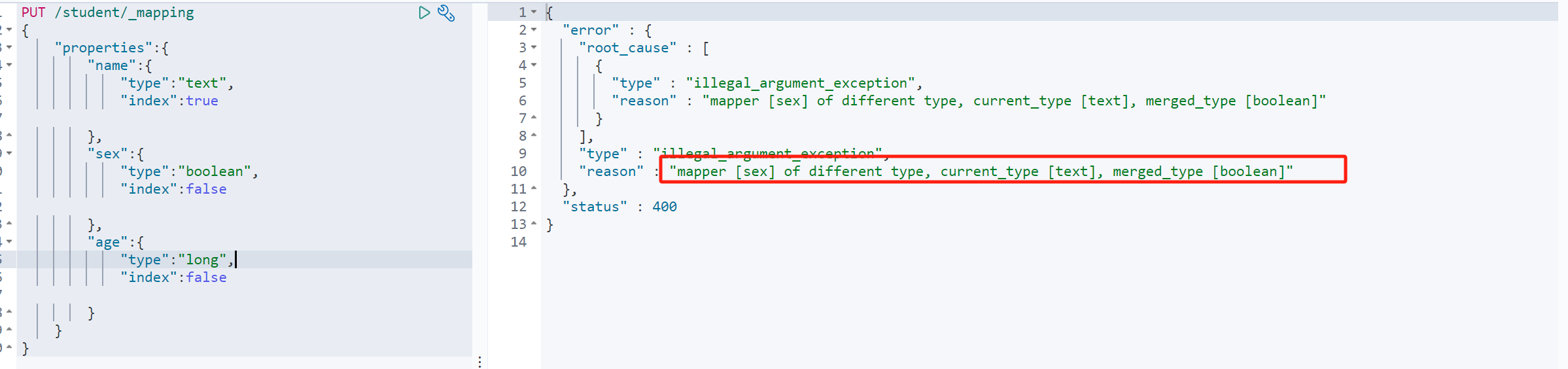
那么我们如何做一个不修改代码、不停机的前提下去做一个索引映射的调整呢?那我们接着往下看
上边我们已经为student创建过映射,现在查看下库里的数据
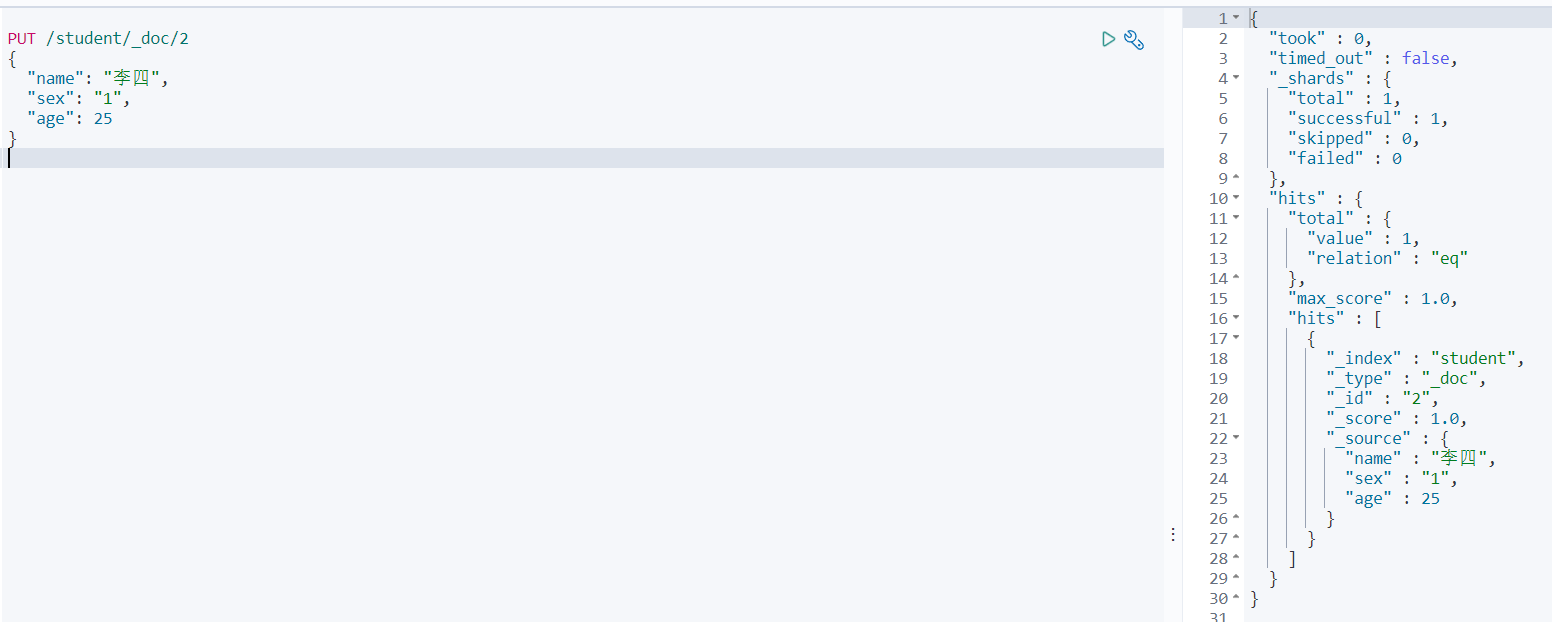
这时候我们需要把name改为keyword类型,先创建一个新的索引student1
PUT /student1
{"settings":{},"mappings":{"properties": {"age": {"type": "long","index": false},"name": {"type": "keyword","index": false},"sex": {"type": "text","index": false}}}}

开始数据迁移:
POST _reindex
{"source": {"index": "student"},"dest": {"index": "student1"}
}
删除老索引:
DELETE /student
给新索引起别名
PUT /student1/_alias/student
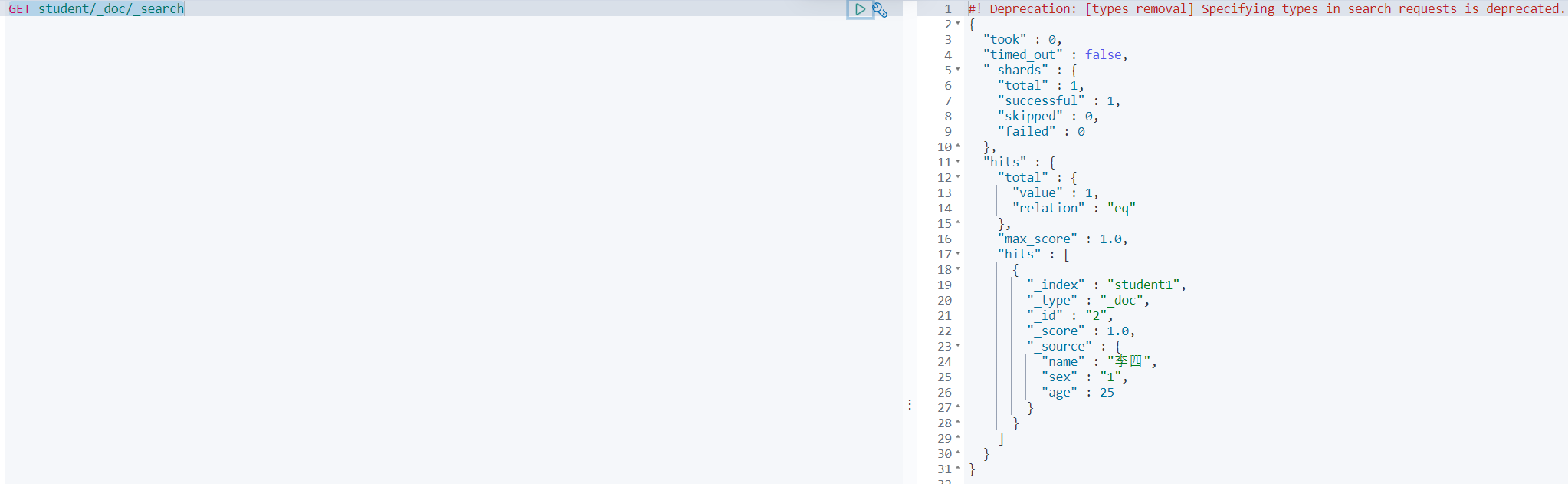
再看下新索引映射:
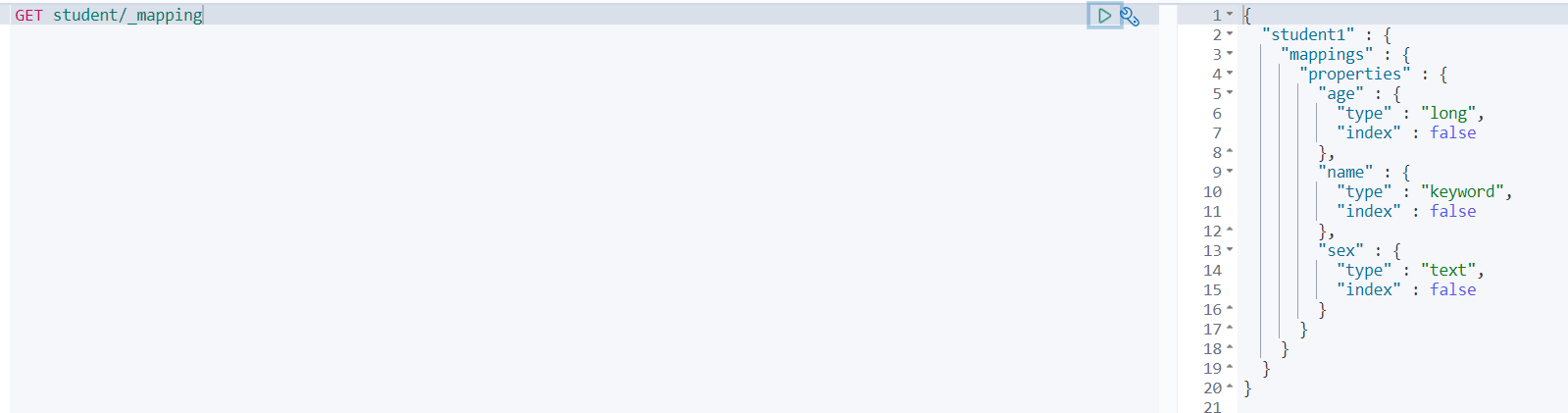
再看下新索引数据:
"index": false},"sex": {"type": "text","index": false}}}
}
[外链图片转存中...(img-H1Q2H8Kq-1709993484097)]开始数据迁移:```json
POST _reindex
{"source": {"index": "student"},"dest": {"index": "student1"}
}
删除老索引:
DELETE /student
给新索引起别名
PUT /student1/_alias/student
再看下新索引映射:
[外链图片转存中…(img-taiTtOom-1709993484097)]
再看下新索引数据:
[外链图片转存中…(img-K1oj3rAC-1709993484098)]
🌟至此本篇就结束了,下一篇将介绍ES高级语法DSL!
相关文章:
Elasticsearch从入门到精通-03基本语法学习
Elasticsearch从入门到精通-03基本语法学习 👏作者简介:大家好,我是程序员行走的鱼 📖 本篇主要介绍和大家一块学习一下ES基本语法,主要包括索引管理、文档管理、映射管理等内容 1.1 了解Restful ES对数据进行增、删、改、查是以…...
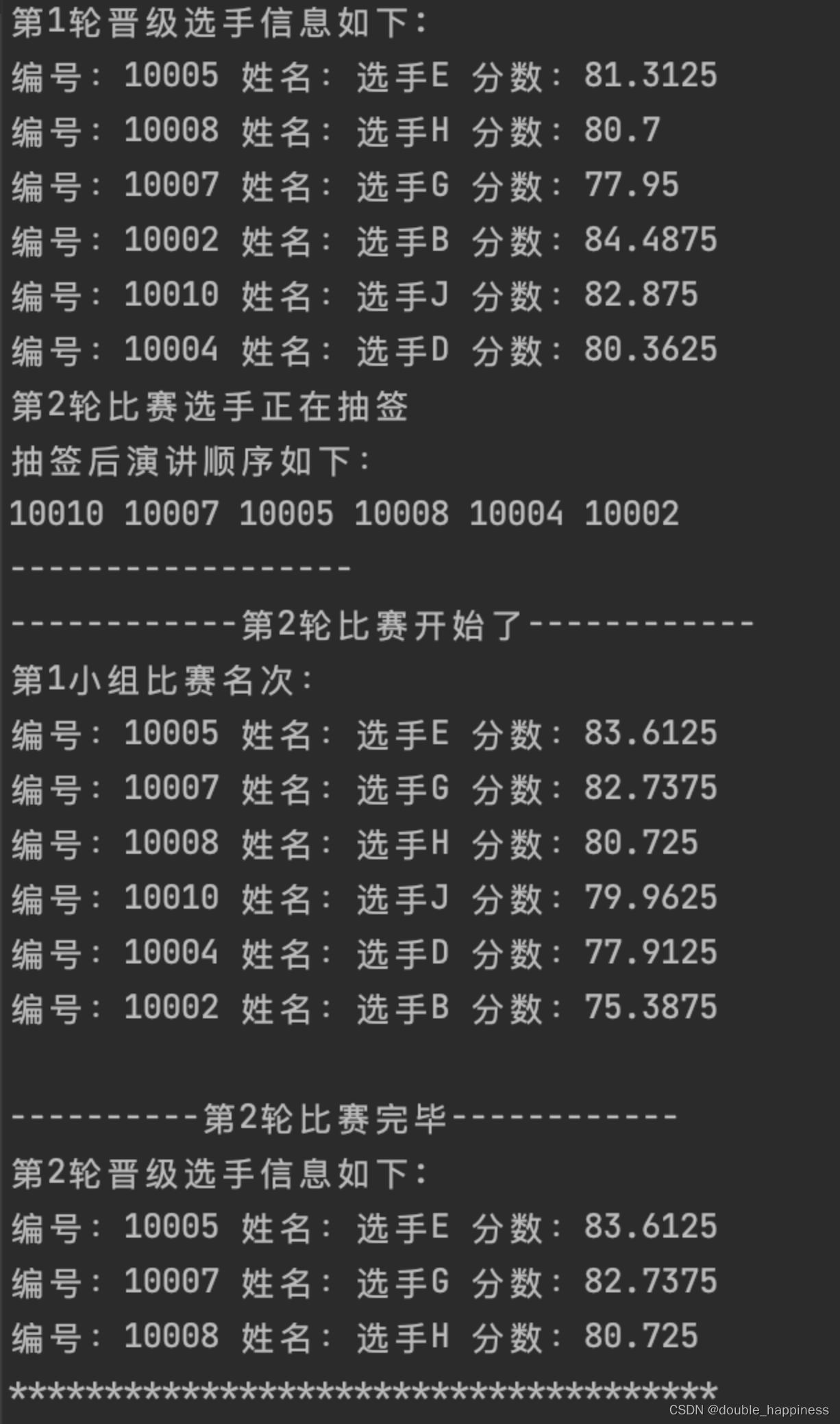
【黑马程序员】STL实战--演讲比赛管理系统
文章目录 演讲比赛管理系统需求说明比赛规则程序功能 创建管理类功能描述创建演讲比赛管理类 菜单功能添加菜单成员函数声明菜单成员函数实现菜单功能测试 退出功能添加退出功能声明退出成员函数实现退出功能测试 演讲比赛功能功能分析创建选手类比赛成员属性添加初始化属性创建…...
一文帮助快速入门Django
文章目录 创建django项目应用app配置pycharm虚拟环境打包依赖 路由传统路由include路由分发namenamespace 视图中间件orm关系对象映射操作表数据库配置model常见字段及参数orm基本操作 cookie和sessiondemo类视图 创建django项目 指定版本安装django:pip install dj…...
基于springboot实现图书推荐系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现图书馆推荐系统演示 摘要 时代的变化速度实在超出人类的所料,21世纪,计算机已经发展到各行各业,各个地区,它的载体媒介-计算机,大众称之为的电脑,是一种特高速的科学仪器,比…...

微信小程序实现上拉加载更多
一、前情提要 微信小程序中实现上拉加载更多,其实就是pc端项目的分页。使用的是scroll-view,scroll-view详情在微信开发文档/开发/组件/视图容器中。每次上拉,就是在原有数据基础上,拼接/合并上本次上拉请求得到的数据。这里采用…...
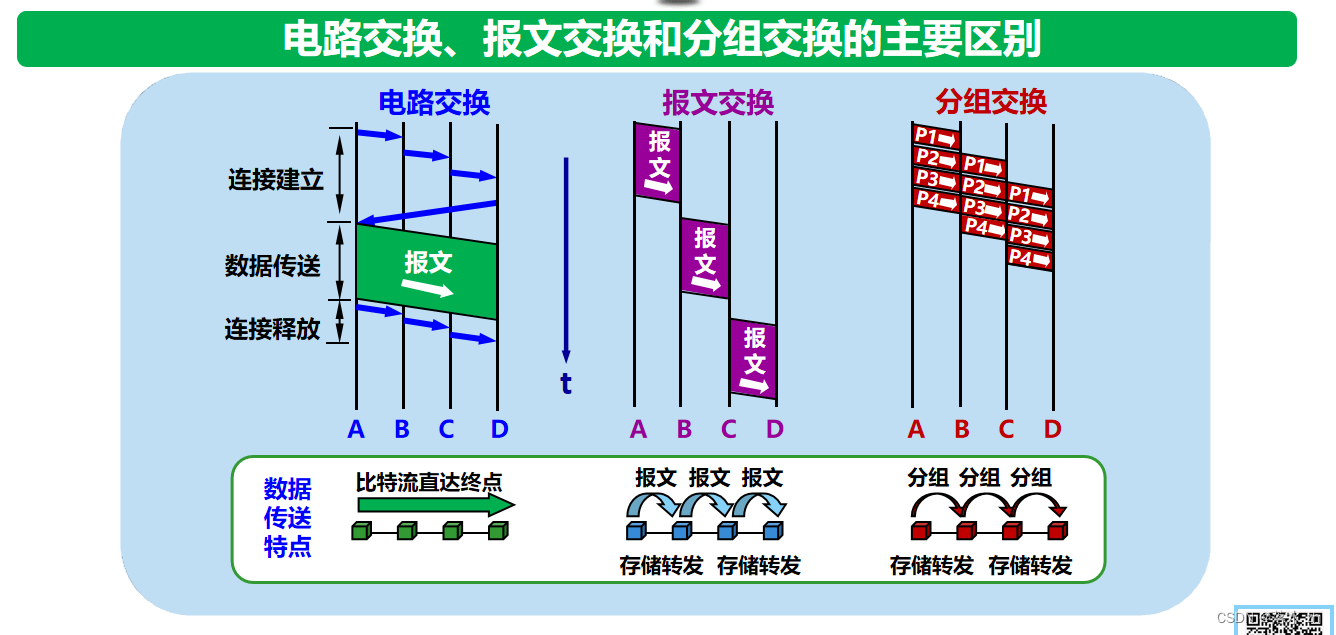
计算机网络——概述
计算机网络——概述 计算机网络的定义互连网(internet)互联网(Internet)互联网基础结构发展的三个阶段第一个阶段——APPANET第二阶段——商业化和三级架构第三阶段——全球范围多层次的ISP结构 ISP的作用终端互联网的组成边缘部分…...

kafka Interceptors and Listeners
Interceptors ProducerInterceptor https://www.cnblogs.com/huxi2b/p/7072447.html Producer拦截器(interceptor)是个相当新的功能,它和consumer端interceptor是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。 对于producer而言&…...

【面试题】mysql常见面试题及答案总结
事务中的ACID原则是什么? Mysql是如何实现或者保障ACID的? ACID原则是数据库事务管理中必须满足的四个基本属性,确保了数据库事务的可靠性和数据完整性。 简写全称解释实现A原子性(Atomicity)一个事务被视为一个不可分割的操作序列&#…...

C++ 类的前向声明的用法
我们知道C的类应当是先定义,然后使用。但在处理相对复杂的问题、考虑类的组合时,很可能遇到俩个类相互引用的情况,这种情况称为循环依赖。 例如: class A { public:void f(B b);//以B类对象b为形参的成员函数//这里编译错位&…...
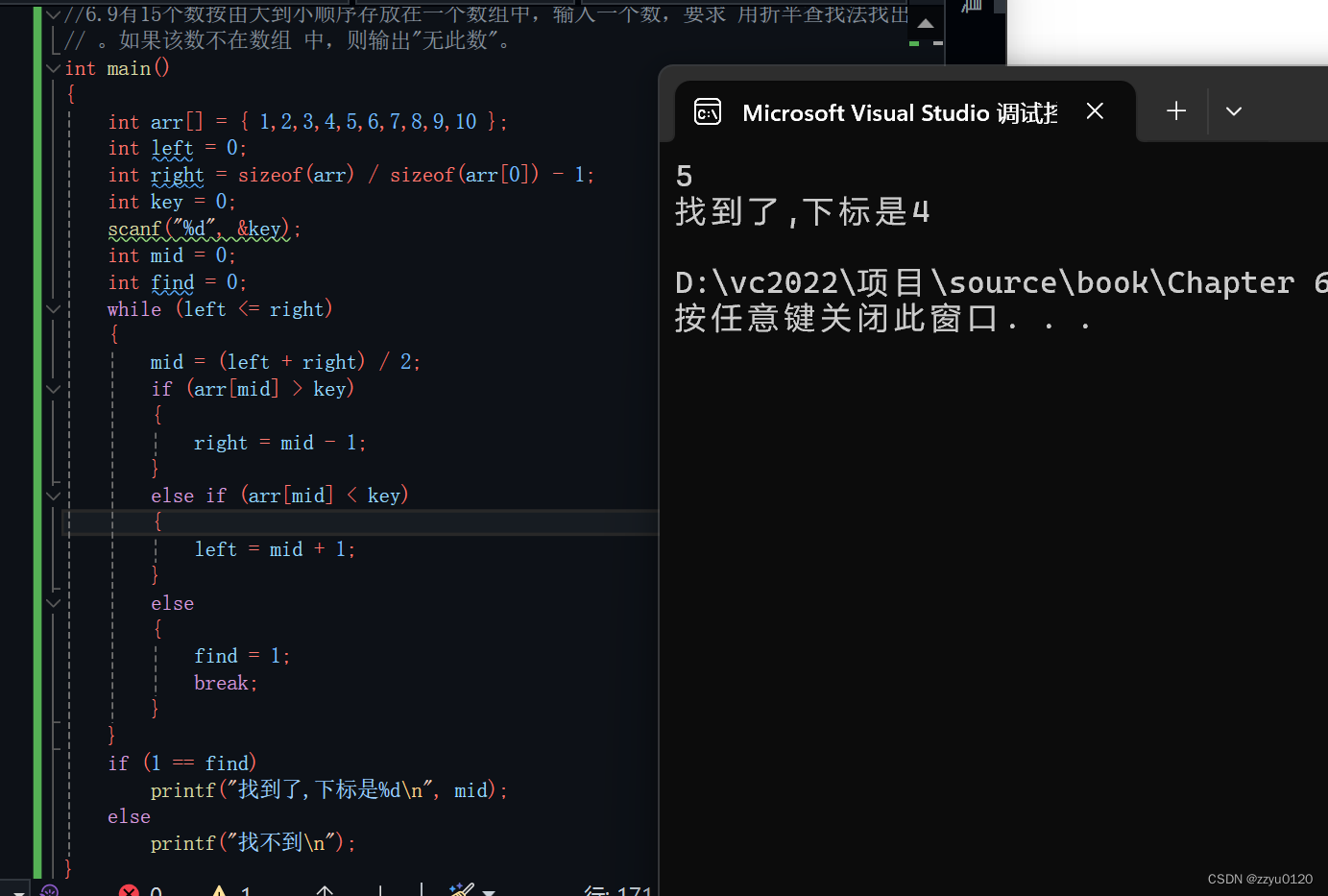
二分查找(c语言)
二分查找 一.什么是二分查找二.代码实现 一.什么是二分查找 在⼀个升序的数组中查找制定的数字n,很容易想到的⽅法就是遍历数组,但是这种⽅法效率⽐较低, ⽐如我买了⼀双鞋,你好奇问我多少钱,我说不超过300元。你还是好…...

【记录31】elementUI el-tree 虚线、右键、拖拽
父组件 <eltree :treeData"treeData"></eltree>import eltree from "../../components/tree.vue"; export default {name: ,components: { // org_tree ,eltree},watch: {},data() {return {orgFormchoose: {},orgForm: { type: 0, limits: 1…...

【C++】函数重载
🦄个人主页:修修修也 🎏所属专栏:C ⚙️操作环境:Visual Studio 2022 目录 📌函数重载的定义 📌函数重载的三种类型 🎏参数个数不同 🎏参数类型不同 🎏参数类型顺序不同 📌重载…...

【深度学习模型】6_3 语言模型数据集
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.3 语言模型数据集(周杰伦专辑歌词) 本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级…...

技术选型思考:分库分表和分布式DB(TiDB/OceanBase) 的权衡与抉择
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 在当今数据爆炸的时代,数据库作为存储和管理数据的核心组件,其性能和扩展性成为了企业关注的重点。随着业…...

React改变数据【案例】
State传统方式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>React Demo</title> <!--…...
ChatGPT Plus 自动扣费失败,如何续订
ChatGPT Plus 自动扣费失败,如何续订 如果您的 ChatGPT Plus 订阅过期或扣费失败,本教程将指导您如何重新订阅。 本周更新 ChatGPT Plus 是一种每月20美元的订阅服务。扣费会自动进行,如果您的账户余额不足,OpenAI 将在一次扣费…...

Rust: Channel 代码示例
在 Rust 中,通道(Channel)通常使用 std::sync::mpsc(多生产者单消费者)或 tokio::sync::mpsc(在异步编程中,特别是使用 Tokio 运行时)来创建。下面是一个使用 std::sync::mpsc 的简单…...

基于华为atlas的unet分割模型探索
Unet模型使用官方基于kaggle Carvana Image Masking Challenge数据集训练的模型。 模型输入为572*572*3,输出为572*572*2。分割目标分别为,0:背景,1:汽车。 Pytorch的pth模型转化onnx模型: import torchf…...

机器学习--循环神经网络(RNN)1
一、简介 循环神经网络(Recurrent Neural Network)是深度学习领域中一种非常经典的网络结构,在现实生活中有着广泛的应用。以槽填充(slot filling)为例,如下图所示,假设订票系统听到用户说&…...

基于java+springboot+vue实现的学生信息管理系统(文末源码+Lw+ppt)23-54
摘 要 人类现已进入21世纪,科技日新月异,经济、信息等方面都取得了长足的进步,特别是信息网络技术的飞速发展,对政治、经济、军事、文化等方面都产生了很大的影响。 利用计算机网络的便利,开发一套基于java的大学生…...
)
AGI产品上市前最后72小时必做3项法律验证——2026奇点大会认证流程全图解(含官方模板下载密钥)
第一章:2026奇点智能技术大会:AGI的法律框架 2026奇点智能技术大会(https://ml-summit.org) 全球首部AGI权责白皮书发布 大会正式发布《通用人工智能系统责任归属与治理原则白皮书(2026)》,确立“开发者—部署者—使…...

【绝密级】AGI战场决策黑箱溯源技术首度解禁:如何用可解释性XAI逆向还原AI开火逻辑?——来自DARPA TRUST-AI项目的3项未公开专利方法
第一章:AGI与军事应用的伦理边界 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)在军事系统中的深度集成正以前所未有的速度推进,从自主侦察分析到动态战术推演,其能力已超越传统自动化范畴。然而&…...

实战复盘:我是如何绕过那个烦人的Shiro反序列化长度限制拿到Shell的
突破Shiro反序列化长度限制的实战手记 那天凌晨三点,咖啡杯已经见底,我盯着屏幕上那个熟悉的Shiro登录界面,手指在键盘上无意识地敲击着。这已经是本周遇到的第三个使用Shiro框架的系统了,前两个都轻松拿下,但这个系统…...
)
从手机热点到云平台:ESP8266 Wi-Fi模块的完整入网调试指南(含STA模式配置避坑点)
从手机热点到云平台:ESP8266 Wi-Fi模块的完整入网调试指南 在物联网设备开发中,稳定可靠的网络连接是项目成功的关键前提。ESP8266作为一款高性价比的Wi-Fi模块,其灵活的工作模式和丰富的AT指令集使其成为众多开发者的首选。然而,…...

3步解密B站抢票神器:为什么别人总比你快0.1秒?
3步解密B站抢票神器:为什么别人总比你快0.1秒? 【免费下载链接】biliTickerBuy b站会员购购票辅助工具 项目地址: https://gitcode.com/GitHub_Trending/bi/biliTickerBuy 你是否曾经在B站会员购抢票时,眼睁睁看着心仪的演唱会门票在几…...

【SITS2026权威前瞻】:全球TOP12AI代码引擎实测对比,3大生产级陷阱你避开了吗?
第一章:SITS2026圆桌:智能代码生成未来 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026圆桌论坛上,来自GitHub、Tabnine、DeepMind与国内大模型实验室的七位核心研发者共同探讨了智能代码生成从“补全助手”迈向“协同编程伙伴”…...

如何快速实现PDF双语翻译?BabelDOC完整指南帮你轻松搞定
如何快速实现PDF双语翻译?BabelDOC完整指南帮你轻松搞定 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为阅读英文PDF文档而头疼吗?🤔 BabelDOC是一个专…...

3步永久保存微信聊天记录:WeChatExporter完整指南
3步永久保存微信聊天记录:WeChatExporter完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因手机损坏、系统升级或误删而丢失了珍贵的微信聊天…...

NaViL-9B图文问答指南:如何构造高质量prompt提升识别准确率
NaViL-9B图文问答指南:如何构造高质量prompt提升识别准确率 1. 认识NaViL-9B多模态模型 NaViL-9B是上海人工智能实验室研发的原生多模态大语言模型,它不仅能处理纯文本问答,还具备强大的图片理解能力。这意味着你可以上传一张图片ÿ…...

StructBERT文本相似度模型C语言调用指南:轻量级嵌入式集成方案
StructBERT文本相似度模型C语言调用指南:轻量级嵌入式集成方案 如果你正在为嵌入式设备或资源受限的边缘计算场景寻找一个简单可靠的文本相似度解决方案,那么你来对地方了。今天,我们不聊复杂的Python环境部署,也不讲沉重的模型加…...