文献阅读:DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾
- 1、研究背景
- 2、方法提出
- 3、相关知识
- 3.1、DEConv
- 3.3、多重卷积的计算
- 3.3、FAM
- 3.4、CGA
- 4、实验
- 4.1、数据集
- 4.2、评价指标
- 4.3、实验结果
- 5、贡献
- 二、CGA模块代码学习
- 1、空间注意力模块
- 2、通道注意力模块
- 3、像素注意力模块
- 总结
摘要
本周主要阅读了文章,DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾。该论文提出了提出了一种细节增强注意力块(DEAB),该模块由一个细节增强卷积(DEConv)和一个内容引导的注意力(CGA)机制组成,使得模型能够更好地保留图像的细节信息,同时又能关注图像中的重要信息,从而达到更好的去雾效果。除此之外,还学习学习了CGA模块的注意力代码模块的学习。
Abstract
This week, I mainly read the article DEA-Net: Single Image De-Fogging Based on Detail Enhancement Convolution and Content Guided Attention. This paper proposes a detail enhancement attention block DEAB, which consists of a detail enhancement convolution DEConv and a content guided attention CGA mechanism. This module enables the model to better preserve the details of the image while also focusing on important information in the image, thus achieving better de-fogging effects. In addition, I also learned about the attention code module of the CGA module.
文献阅读:DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾
Title: DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
Author:Zixuan Chen, Zewei He†, Zhe-Ming Lu
From:JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 1
1、研究背景
单张图像去雾是一个低级视觉任务,旨在从单张受雾影响的图像中恢复其清晰的场景。图像去雾在许多计算机视觉应用中都有需求,例如自动驾驶、无人机、监控系统等。在这些应用中,准确的场景感知和物体识别对于系统的可靠性和安全性至关重要。当然单图像去雾是一个具有挑战性的问题,它从观测到的雾图像中估计潜在的无雾图像。一些现有的基于深度学习的方法致力于通过增加卷积的深度或宽度来提高模型性能。卷积神经网络(CNN)的学习能力仍然没有得到充分探索。
2、方法提出
本文提出了一种细节增强注意力块(DEAB),DEA-Net是一种用于单张图像去雾的深度学习网络。它采用类似U-Net的编码器-解码器结构,由三部分组成:编码器部分、特征转换部分和解码器部分。在去雾等低级视觉任务中,从编码器部分融合特征与解码器部分的特征是一种有效的技巧。该模块由一个细节增强卷积(DEConv)和一个内容引导的注意力(CGA)机制组成。DEConv包含并行的普通卷积和差异卷积,五个卷积层(四个差异卷积和一个普通卷积),这些卷积层并行部署用于特征提取。 此外,复杂的注意力机制(即CGA)是一个两步注意力生成器,它可以首先产生粗略的空间注意力图,然后对其进行细化。

3、相关知识
3.1、DEConv
DEConv包含五个卷积层(四个差异卷积和一个普通卷积),这些卷积层并行部署用于特征提取。具体来说,采用中心差分卷积(CDC)、角差分卷积(ADC)、水平差分卷积(HDC)和垂直差分卷积(VDC)将传统的局部描述符集成到卷积层中,从而可以增强表示能力和泛化能力。在差异卷积中,首先计算图像中的像素差异,然后与卷积核卷积以生成输出特征图。通过设计像素对的差异计算策略,可以将先验信息显式编码到CNN中。这些卷积用于特征提取和学习,可以增强表示能力和泛化能力。
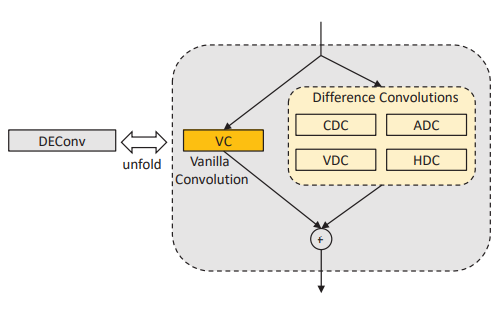
3.3、多重卷积的计算
VC、CDC、ADC、HDC和VDC的核函数,与图像进行卷积,最后并行卷积结合在一起。
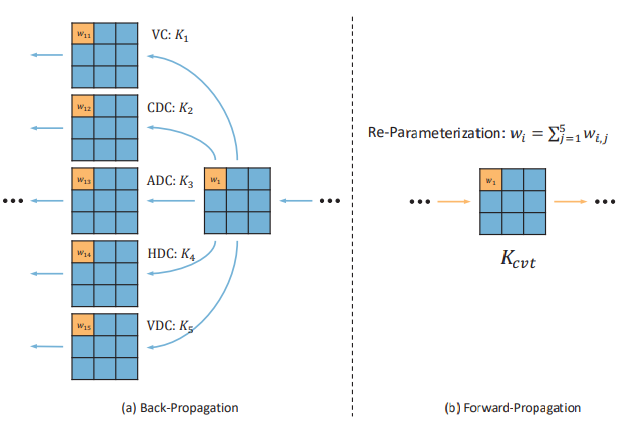
3.3、FAM
FAM(Feature attention module)是一种用于图像去雾的注意力机制模块,它包含通道注意力和空间注意力两部分。FAM通过对不同通道和像素进行不平等处理,提高了去雾性能。然而,FAM的空间注意力只能在图像级别上解决不均匀的雾分布问题,忽略了其他维度。以此有以下几个缺点:
- 空间注意力机制:FAM中的空间注意力只能在图像级别上解决不均匀的雾分布问题,这意味着它无法处理多尺度维度的雾分布问题。在处理具有复杂雾分布的图像时,这可能会导致去雾效果不佳。
- 通道特异性SIMs(空间注意图):FAM在计算注意力权重时,只使用了一个单一通道来表示输入特征的重要区域,而输入特征的通道数量相对较大。这可能导致注意力权重的计算不够准确,从而影响去雾效果。
- 两个注意力权重之间缺乏信息交换:在FAM中,通道注意力和空间注意力是顺序计算的,它们之间没有信息交换。这意味着它们可能无法充分考虑彼此的特点,从而影响去雾效果。
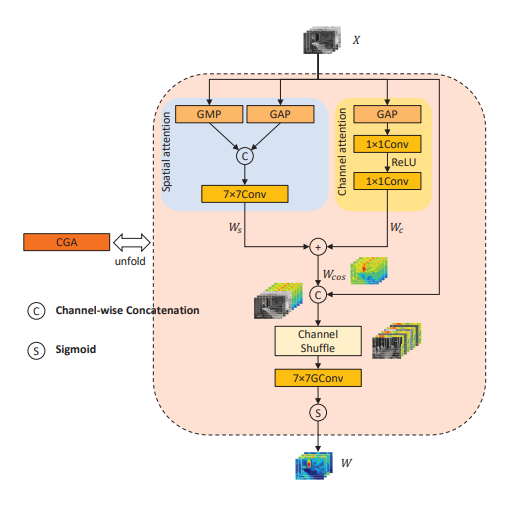
3.4、CGA
CGA(Content-Guided Attention)是一种内容引导注意力机制,用于提高图像恢复任务中神经网络的性能。CGA是一种粗细处理过程,首先生成粗略的空间注意力图,然后根据输入特征图的每个通道进行细化,以产生最终的空间注意力图。CGA通过使用输入特征的内容来引导注意力图的生成,从而更加关注每个通道的唯一特征部分,可以更好地重新校准特征,学习通道特定的注意力图,以关注通道之间的雾霾分布差异。CGA的工作过程分为两步:
- 生成粗略的空间注意力图。这是一个粗细处理过程,通过生成一个粗略的注意力图,可以快速捕捉到图像中的主要特征。
- 根据输入特征图的每个通道对注意力图进行细化。这一步的目的是使注意力图更加精确,能够关注到特征图中的独特部分。
4、实验
4.1、数据集
- SOTS:SOTS是一个包含1000张室内和室外清晰图像以及对应的带有不同雾度的模糊图像的数据集。该数据集分为训练集、验证集和测试集。SOTS数据集的图像具有丰富的场景和复杂的雾度,因此可以有效地评估图像去雾方法在各种情况下的性能。
- Haze4K:Haze4K数据集包含4000张带有不同雾度的室内和室外图像,用于训练和测试图像去雾方法。该数据集分为训练集和测试集。Haze4K数据集的图像具有较高的分辨率和丰富的场景,可以有效地训练和评估图像去雾方法。
4.2、评价指标
- PSNR:峰值信噪比(Peak Signal-to-Noise Ratio)是一种用于衡量图像质量的评价指标。它通过计算去雾图像与清晰图像之间的均方误差(MSE)来评估图像去雾方法的性能。PSNR的计算公式为:PSNR = 10 * log10(255^2 / MSE) 。其中,255是像素值的范围,MSE是去雾图像与清晰图像之间的均方误差。PSNR值越高,说明去雾图像的质量越好,图像去雾方法的性能也就越好。
- SSIM:结构相似度指数(Structural Similarity Index)是一种用于衡量图像结构信息的评价指标。它通过比较去雾图像与清晰图像之间的亮度、对比度和结构信息来评估图像去雾方法的性能。SSIM的计算公式为:SSIM = (2 * μx * μy + C1) * (2 * σxy + C2) / ((μx^2 + μy^2 + C1) * (σx^2 + σy^2 + C2))。其中,μx和μy分别是去雾图像和清晰图像的平均灰度值,σx2和σy2分别是去雾图像和清晰图像的方差,σxy是去雾图像和清晰图像的协方差,C1和C2是常数。SSIM值越高,说明去雾图像的结构信息与清晰图像越相似,图像去雾方法的性能也就越好。
4.3、实验结果

5、贡献
-
Detail-Enhanced Convolution (DEConv)
作者提出了Detail-Enhanced Convolution (DEConv),这是一种包含并行的vanilla和difference卷积的新型卷积方式。DEConv第一次引入差分卷积来解决图像去噪问题。传统的卷积操作主要是通过滑动窗口在输入图像上进行操作,而差分卷积则是在卷积操作中引入了差分的思想,使得卷积核在不同的位置具有不同的权重,这样可以更好地捕捉图像中的细节信息,提高去噪效果。DEConv的引入,使得模型能够更好地保留图像的细节信息,提高图像去雾的性能。 -
Content-Guided Attention (CGA)
作者还提出了Content-Guided Attention (CGA),这是一种创新的注意力机制。CGA为每个通道分配唯一的SIM,引导模型关注每个通道的重要区域。这样可以强调编码在特征中的更多有用信息,以有效提高去雾性能。CGA的引入,使得模型能够更加关注图像中的重要信息,忽略无关的信息,从而提高图像去雾的效果。此外,作者还将DEConv与CGA相结合,提出了DEA-Net的主要模块,即细节增强注意模块 (DEAB)。DEAB的引入,使得模型能够更好地保留图像的细节信息,同时又能关注图像中的重要信息,从而达到更好的去雾效果 。
二、CGA模块代码学习
1、空间注意力模块
class SpatialAttention(nn.Module):def __init__(self):super(SpatialAttention, self).__init__()self.sa = nn.Conv2d(2, 1, 7, padding=3, padding_mode='reflect', bias=True)# 定义一个二维卷积层self.sa,输入通道数为2,输出通道数为1,卷积核大小为7x7 # padding=3表示在输入数据的周围填充3个像素,保持空间尺寸不变 # padding_mode='reflect'表示使用反射填充方式 # bias=True表示卷积层使用偏置项 def forward(self, x): x_avg = torch.mean(x, dim=1, keepdim=True) # 计算输入x在通道维度(dim=1)上的平均值,并保持输出的维度与输入相同 x_max, _ = torch.max(x, dim=1, keepdim=True) # 找到输入x在通道维度上的最大值,并忽略最大值的索引(用_表示) # 同样保持输出的维度与输入相同 x2 = torch.cat([x_avg, x_max], dim=1) # 将x_avg和x_max沿着通道维度(dim=1)拼接起来,得到新的张量x2 # 此时x2的通道数是x的两倍 sattn = self.sa(x2) # 将x2作为输入传递给之前定义的卷积层self.sa,得到输出sattn return sattn # 返回计算得到的空间注意力图sattn
2、通道注意力模块
class ChannelAttention(nn.Module): def __init__(self, dim, reduction=8): # 初始化方法,接收输入特征的通道数dim和一个可选的通道数减少比例reduction(默认为8) super(ChannelAttention, self).__init__() # 定义了一个自适应平均池化层,输出大小为1x1,用于对每个通道内的所有元素进行平均 self.gap = nn.AdaptiveAvgPool2d(1) # 定义了一个顺序模型self.ca,包含两个卷积层和一个ReLU激活函数 self.ca = nn.Sequential( # 第一个卷积层将输入特征的通道数从dim减少到dim // reduction,使用1x1的卷积核,无填充,并使用偏置 nn.Conv2d(dim, dim // reduction, 1, padding=0, bias=True), # ReLU激活函数对第一个卷积层的输出进行非线性变换,inplace=True表示直接在输入数据上进行修改 nn.ReLU(inplace=True), # 第二个卷积层将通道数从dim // reduction恢复到原始的dim,同样使用1x1的卷积核和无填充 nn.Conv2d(dim // reduction, dim, 1, padding=0, bias=True), ) def forward(self, x): # 对输入x进行自适应平均池化操作,得到每个通道的平均值 x_gap = self.gap(x) # 将池化后的结果x_gap传递给self.ca顺序模型,计算通道注意力权重 cattn = self.ca(x_gap) # 返回计算得到的通道注意力权重 return cattn
3、像素注意力模块
class PixelAttention(nn.Module): def __init__(self, dim): super(PixelAttention, self).__init__() # 定义一个二维卷积层,输入通道数为2*dim,输出通道数为dim, # 卷积核大小为7x7,填充大小为3(使用reflect模式),分组数为dim,并使用偏置项。 self.pa2 = nn.Conv2d(2 * dim, dim, 7, padding=3, padding_mode='reflect', groups=dim, bias=True) # 定义一个Sigmoid激活函数 self.sigmoid = nn.Sigmoid() def forward(self, x, pattn1): """ 前向传播方法,接收两个输入:特征图x和另一个注意力图pattn1。 """ # 获取输入x的形状 B, C, H, W = x.shape # 在x的通道维度之后增加一个新的维度,大小为1 x = x.unsqueeze(dim=2) # 在pattn1的通道维度之后增加一个新的维度,大小为1 pattn1 = pattn1.unsqueeze(dim=2) # 将x和pattn1在第二个维度(现在的大小为2)上进行拼接 x2 = torch.cat([x, pattn1], dim=2) # 使用Rearrange函数对x2的形状进行重排,将通道数和第二个维度的大小合并成一个维度 x2 = Rearrange('b c t h w -> b (c t) h w')(x2) # 将重排后的x2输入到卷积层self.pa2中 pattn2 = self.pa2(x2) # 对卷积层的输出应用Sigmoid激活函数 pattn2 = self.sigmoid(pattn2) # 返回计算得到的像素注意力权重pattn2 return pattn2 总结
本周主要阅读了文章,DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾。该论文提出了提出了一种细节增强注意力块(DEAB),该模块由一个细节增强卷积(DEConv)和一个内容引导的注意力(CGA)机制组成,使得模型能够更好地保留图像的细节信息,同时又能关注图像中的重要信息,从而达到更好的去雾效果。除此之外,我还学习学习了CGA模块的注意力代码模块的学习。下周再接再厉
相关文章:
文献阅读:DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract文献阅读:DEA-Net:基于细节增强卷积和内容引导注意的单图像去雾1、研究背景2、方法提出3、相关知识3.1、DEConv3.3、多重卷积的…...

2024想要赚点小钱真的很容易!帮你们找的10个搞钱第二职业
我们都希望在空闲时间里增加一些额外收入,并有机会找到自己热爱的事业,每天贝兼几十上百元是一个不错的开始,小钱也是钱, 搞钱的经验会积少成多。今天分享10个搞钱第二职业,2024想要赚点小钱真的很容易。 一.摆摊卖花 …...

【Linux网络】再谈 “协议“
目录 再谈 "协议" 结构化数据的传输 序列化和反序列化 网络版计算器 封装套接字操作 服务端代码 服务进程执行例程 启动网络版服务端 协议定制 客户端代码 代码测试 使用JSON进行序列化与反序列化 我们程序员写的一个个解决我们实际问题,满…...

猫头虎分享已解决Bug || 系统监控故障:MonitoringServiceDown, MetricsCollectionError
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

Java中的基本数据类型有哪些
在Java编程语言中,基本数据类型(Primitive Types)是预定义的数据类型,它们不是由用户定义的类创建的,而是由语言本身提供的。这些基本数据类型是构成Java程序的基础,用于存储不同类型的值,如整数…...

二叉树遍历(前中后序的递归/非递归遍历、层序遍历)
二叉树的遍历 1. 二叉树的前序、中序、后序遍历 前、中、后序遍历又叫深度优先遍历 注:严格来说,深度优先遍历是先访问当前节点再继续递归访问,因此,只有前序遍历是严格意义上的深度优先遍历 首先需要知道下面几点: …...
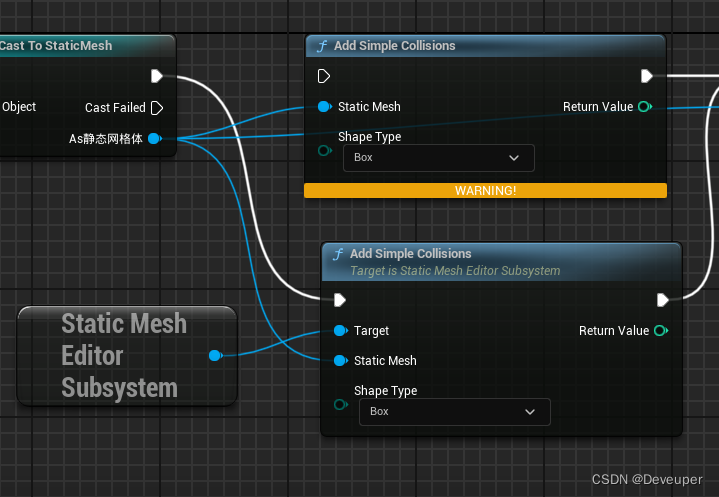
UE4升级UE5 蓝图节点变更汇总(4.26/27-5.2/5.3)
一、删除部分 Ploygon Editing删除 Polygon Editing这个在4.26、4.27中的插件,在5.1后彻底失效。 相关的蓝图,如编辑器蓝图 Generate mapping UVs等,均失效。 如需相关功能,请改成Dynamic Mesh下的方法。 GetSupportedClass删…...
【python】异常处理
前言 省略各种废话,直接快速整理知识点 try-except 基础 作用 程序不可能永远都是对的,当7除a,a由用户输入时,用户输入0就会报错。try-except就是解决这些问题。 结构 多分支自定义错误类型 上方的exception是一个错误类型…...

【xv6操作系统】Lab systems calls
一、实验前须知 阅读 xv6 文档的第 2 章和第 4 章的 4.3 节和 4.4 节以及相关源文件: 系统调用的用户空间代码在 user/user.h 和 user/usys.pl 中。 内核空间代码在 kernel/syscall.h 和 kernel/syscall.c 中。 与进程相关的代码在 kernel/proc.h 和 kernel/proc.c…...

python的scripts文件夹作用
Windows系统: Scripts文件夹通常位于Python的安装目录下,如C:\Python\Scripts。该文件夹内包含了各种有用的工具,例如pip、virtualenv等,这些工具有助于管理和配置Python环境和依赖包。 Linux系统: 在Linux系统中&…...

Discuz论坛网站报错Discuz!Database Error(0)notconnect的解决办法
运营服务器大本营有段时间了,在运营期间遇到两次Discuz!Database Error(0)notconnect报错,和你们分享遇到Discuz报错的解决办法,希望可以帮助到你。 首先网站报错(0)notconnect&…...

掌握mysql,看完这篇文章就够了
数据库 对大量数据进行存储和管理(增删改查) 客户端: 黑窗口终端navicat 熊掌软件数据库分类: 关系型数据库 通过表与表产生关联关系,每个表中都存储结构化数据,支持sql结构化查询语言MysqlOracleSQLS…...

守护Web安全:了解Web攻击与防护策略
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

变换,动画
面试题——需求:在不知道父元素与子元素的宽高时 如何让子元素在父元素内居中? 1.定位 父相子绝 2.子元素 top:50% left:50% 3.子元素 transform: translate(-50%,-50%) .parent{height: 500px;background-color: red;position: relative;}.c…...
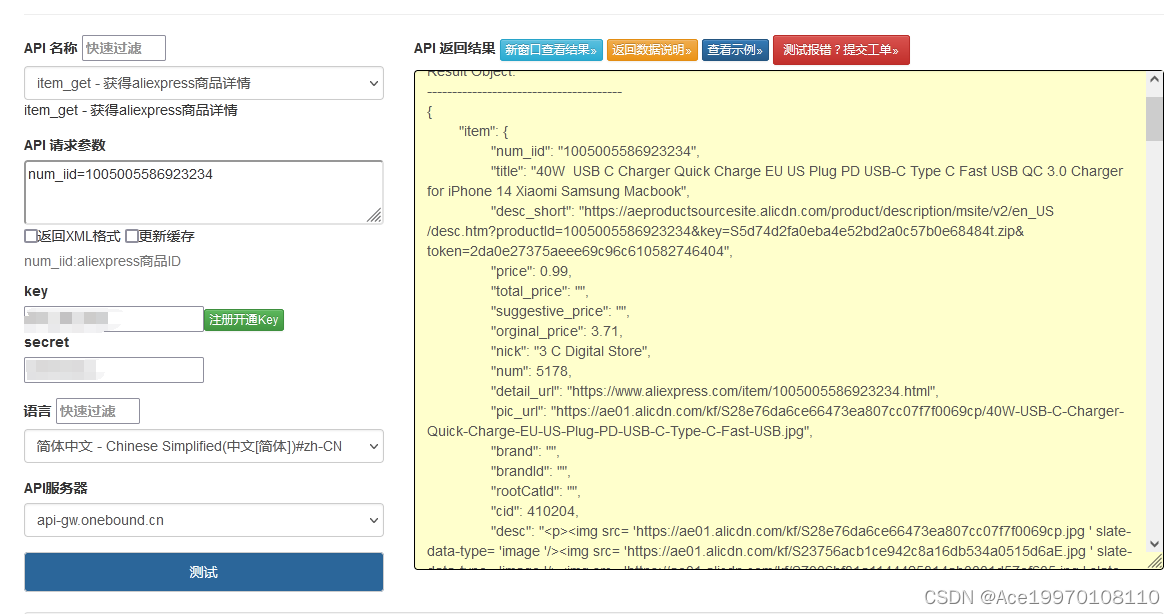
深度解析速卖通商品详情API:Python实战与高级技术探讨
速卖通商品详情API接口实战:Python代码示例 一、准备工作 在开始之前,请确保你已经完成了以下步骤: 在速卖通开放平台注册账号并创建应用,获取API密钥。阅读速卖通商品详情API接口的文档,了解接口的使用方法和参数要…...

背包问题算法
背包问题算法 0-1背包问题二维数组一维数组 完全背包问题二维数组一维数组 多重背包问题一维数组 0-1背包问题 问题:背包的容量为9,有重量分别为[2, 4, 6, 9]的四个物品,价值分别为[3, 4, 5, 6],求背包能装的物品的最大价值是多少…...
echarts柱状图可鼠标左击出现自定义弹框,右击隐藏弹框并阻止默认右击事件
每项x轴数据对应有两条柱图和一条阴影效果是学习其它博客得到的效果,这个是学习的原文链接:echarts两个合并柱体(普通柱状图象形柱图)共享一个柱体阴影 因为这次情况比较特殊,不仅需要自定义弹框内容,而且…...
存算一体成为突破算力瓶颈的关键技术?
大模型的训练和推理需要高性能的算力支持。以ChatGPT为例,据估算,在训练方面,1746亿参数的GPT-3模型大约需要375-625台8卡DGX A100服务器训练10天左右,对应A100 GPU数量约3000-5000张。 在推理方面,如果以A100 GPU单卡…...

Pytorch_1_基本语法
一、Pytorch的基本元素操作 1.引入torch from __future__ import print_function import torch 2.创建矩阵 x torch.empty(5,3) print(x) 3.输出结果: tensor([[7.9191e34, 1.1259e24, 1.2359e-42], [4.0824e-40, 1.1379e-35, 2.5353e30], [8.…...

2024上海国际玻璃纤维及新材料展览会
2024上海国际玻璃纤维及新材料展览会 时间:2024年12月18~20日 地点:上海新国际博览中心 ◆ 》》》展会概况: 玻璃纤维是一种性能优异的无机非金属材料,比有机纤维耐温高,不燃,抗腐ÿ…...

构建可持续迭代的 Agent:反馈闭环怎么做
构建可持续迭代的 Agent:反馈闭环怎么做 1. 标题 (Title) 构建可持续迭代的 Agent:反馈闭环怎么做 从零到一:打造智能体的自我进化反馈系统 Agent 可持续发展之道:反馈闭环设计与实现 让你的 AI 智能体学会学习:反馈闭环实战指南 智能体进化引擎:反馈闭环的设计原理与最…...
)
别再死记硬背了!用‘点火公式’Wallis快速搞定高次幂三角积分(附Python验证脚本)
高次幂三角积分速算秘籍:Wallis点火公式实战指南 第一次遇到∫sin⁶xdx这样的积分时,我盯着题目发了半小时呆。传统的分部积分法需要反复套用公式,计算过程堪比俄罗斯套娃。直到发现Wallis公式——这个被学生们戏称为"点火公式"的神…...
算法的前世今生与核心思想)
从CT扫描到雷达成像:一文讲透后向投影(BP)算法的前世今生与核心思想
从CT扫描到雷达成像:后向投影算法的跨学科智慧 1971年,英国工程师Godfrey Hounsfield发明了第一台医用CT扫描仪时,或许没想到这项技术会彻底改变医学诊断方式,更不会预料到它启发了另一种完全不同的成像技术——合成孔径雷达&…...

2025届学术党必备的六大AI学术方案推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 此时此刻,伴随AI技术被广泛运用,针对AI生成内容的检测变得日益严谨。…...
✅)
计算机毕业设计:Python农作物产量智能预估与数据看板 Flask框架 XGBoost 机器学习 数据分析 可视化 大数据 大模型(建议收藏)✅
1、项目介绍 技术栈 采用 Python 语言开发,基于 Flask 框架搭建后端服务,使用 MySQL 数据库进行数据存储,通过 pymysql 连接数据库,运用 XGBoost 机器学习模型实现产量预测,前端结合 HTML、CSS、JavaScript、Echarts 和…...

SOCD Cleaner终极指南:如何用键盘映射提升游戏操作精度
SOCD Cleaner终极指南:如何用键盘映射提升游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在竞技游戏中,你是否曾因同时按下相反方向键而导致操作失误?SOCD Clea…...

MySQL Explain 执行计划性能对比
MySQL Explain执行计划性能对比:优化查询的关键利器 在数据库性能优化中,MySQL的Explain执行计划是分析SQL查询效率的重要工具。通过Explain,开发者可以直观地了解查询的执行路径、索引使用情况以及潜在的性能瓶颈。本文将从多个角度对比Exp…...

【一文搞懂本地模型调用-AI知识点】
还在傻傻分不清?一文带你彻底搞懂“本地调用”与“调用本地API” 摘要 本地调用大模型是“自己在家做饭”的战略选择,而调用本地API是“通过传菜口点菜”的具体方法。本文通过生动的比喻、实战代码及与云端API的深度对比,帮你彻底分清这两个易混概念,并解析了为何“本地化…...

CSS移动端实现自适应图片比例_设置height auto保证等比缩放
Max-Age 优先级高于 Expires,覆盖其设置;Expires 依赖客户端时间且需 GMT 格式,省略则为会话 Cookie;Max-Age 以秒为单位、不依赖本地时间,值为 0 或负数时立即删除。Cookie 的生命周期由 Expires 和 Max-Age 两个属性…...

OmenSuperHub:惠普OMEN游戏本硬件控制框架解析
OmenSuperHub:惠普OMEN游戏本硬件控制框架解析 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一个专为惠普OMEN系列游戏笔记本…...