Django模型层(附带test环境)
Django模型层(附带test环境)
目录
- Django模型层(附带test环境)
- 连接数据库
- Django ORM
- 在models.py中建表
- 允许为空
- 指定默认值
- 数据库迁移命令
- 开启测试环境
- 建表语句补充(更改默认表名)
- 数据的增加
- 时间数据的时区
- 多表数据的增加
- 一对多
- 多对多
- 数据的删除
- 修改数据
- 查询数据
- 查询所有数据
- 去重查询
- 排序查询
- 统计
- 剔除指定数据
- 多表查询
- 示例
- 一对多:图书与出版社
- 多对多:图书和作者
- 方式【1】**推荐**
- 方式【2】**不推荐**
- 校验数据是否存在
- 字段的筛选查询
- 连表查询
- 正向查询
- 反向查询
- 聚合函数(aggregate)
- 分组查询
- F与Q查询
- F查询
- Q查询
- Django开启事务
- choices参数
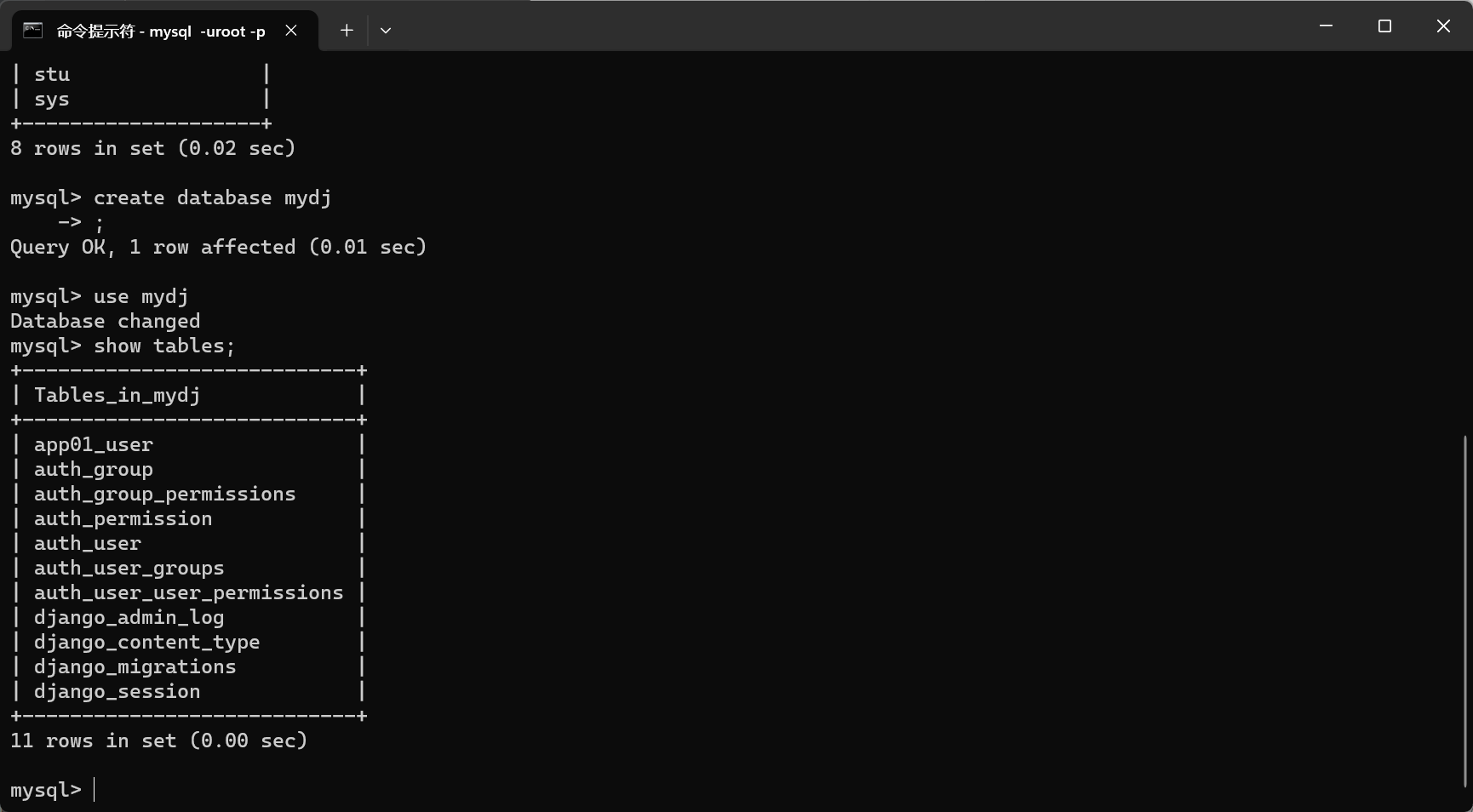
连接数据库
这是Django默认的数据库
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3','NAME': BASE_DIR / 'db.sqlite3',}
}
修改为我们需要的配置
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'mydj','USER': 'root','PASSWORD': '7997','HOST': '127.0.0.1','PORT': 3306,'CHARSET': 'utf8',}
}
django 默认使用mysqldb模块链接mysql
但是该模块的兼容性不好,需要手动修改为pymysql链接
在项目下的init或者任意的应用名下的init文件中书写一下代码
init.py
import pymysqlpymysql.install_as_MySQLdb()
Django ORM
在models.py中建表
id字段Django会自动帮忙创建
from django.db import models# Create your models here.
class User(models.Model):username = models.CharField(max_length=32)password = models.CharField(max_length=32)
允许为空
class MyModel(models.Model):name = models.CharField(max_length=50, null=True) # 允许name字段为空
指定默认值
class MyModel(models.Model):age = models.IntegerField(default=18) # 默认年龄为18岁
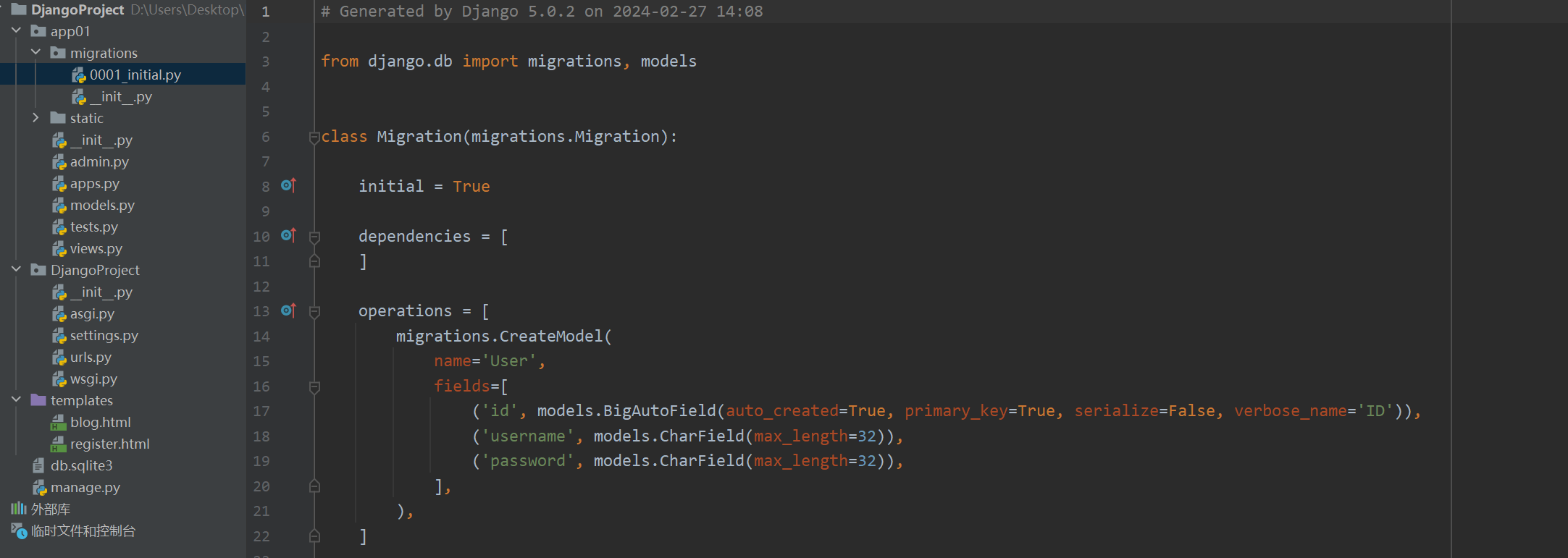
数据库迁移命令
-
创建操作记录
-
python manage.py makemigrations操作完后Django会自动在migrations目录下生成sql语句文件
-
-
同步到数据库
-
python manage.py migrate
-
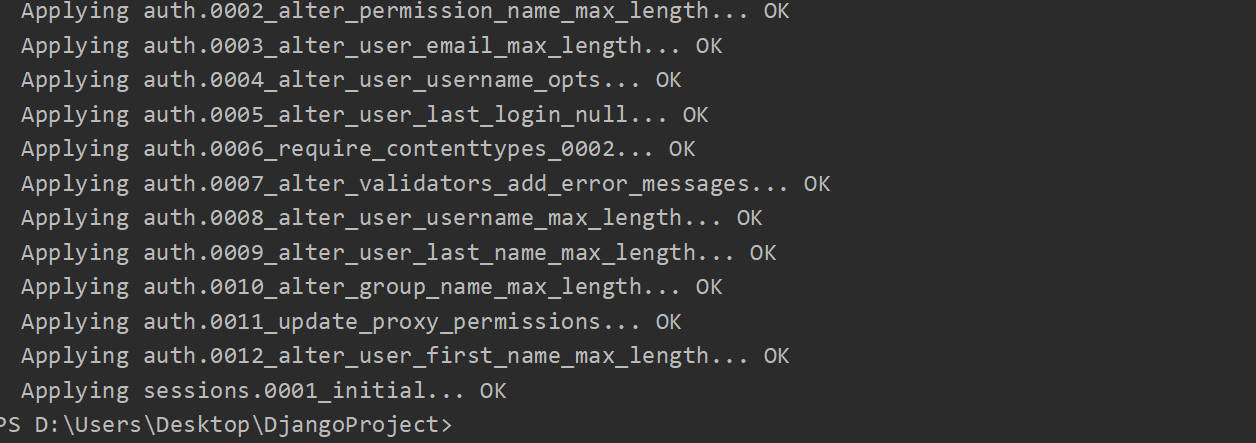
等待表创建完毕
这样就是成功执行建表语句了
删除字段只要在models中删除对应的字段行,然后重新makemigrations即可生成新的sql语句
开启测试环境
首先在app下找到tests.py文件并进入
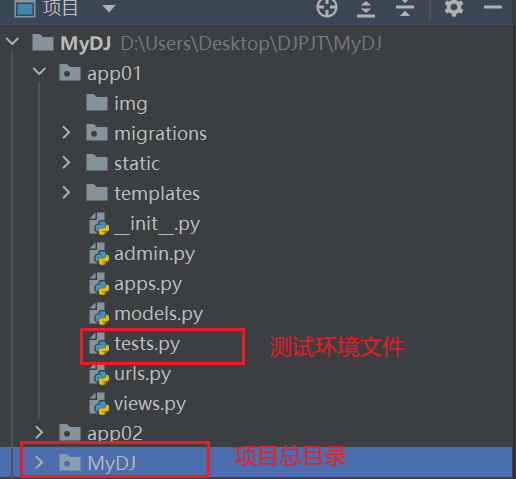
'MyDJ.settings'要换成自己的项目名,我的是MyDJ
import osfrom django.test import TestCaseif __name__ == '__main__':# 导入一句话 : 来自于 manage.py 中的第一句话os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetime# 启动Djangodjango.setup()from app01 import models# 开始业务代码user = models.user.objects.create(username='张三',password='222')
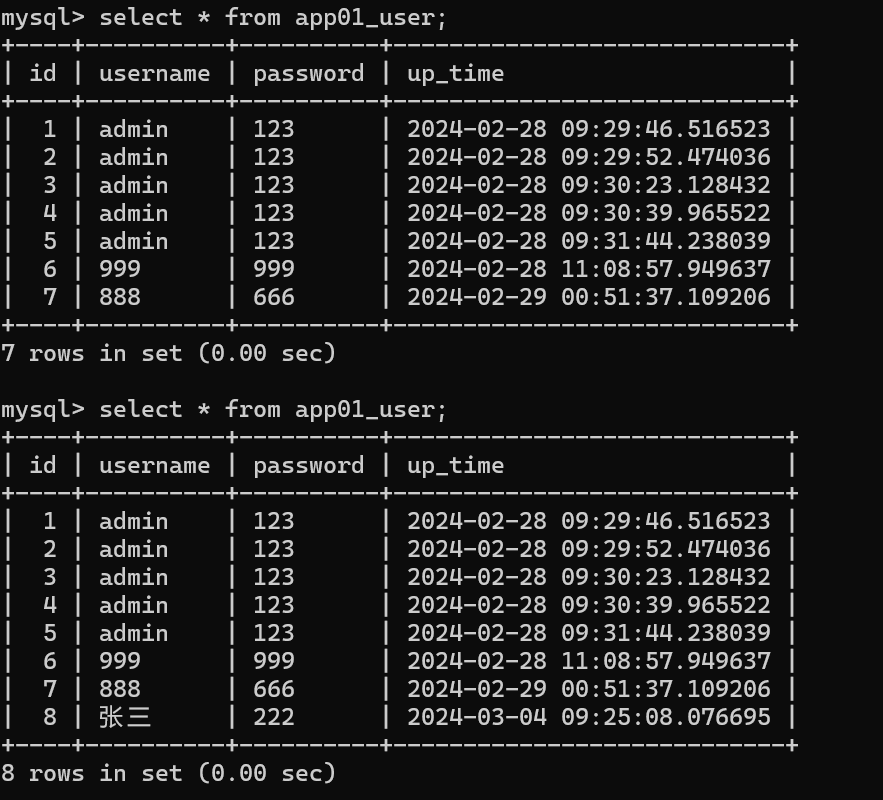
成功~
建表语句补充(更改默认表名)
class Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=True)# 绑定出版社外键publish = models.ForeignKey('Publish', on_delete=models.CASCADE, to_field='id', default=1)# 绑定图书表和作者表,用ManyToManyField自动创建第三张表author = models.ManyToManyField('Author')class Meta():# 不添加的话默认表名app01_bookdb_table = 'book'
数据的增加
data = models.user.objects.create(username="李四",password=929)
data = models.user(username="陈五",password=909)
data.save()
时间数据的时区
创建时间字段(如:DateTimeField())
中国时区需要将settings中部分设置修改为:
LANGUAGE_CODE = 'zh-hans'TIME_ZONE = 'Asia/Shanghai'
多表数据的增加
一对多
此时有一张作者表和作者详情表
作者详情表绑定这作者表的id
class Author(models.Model):# 作者名name = models.CharField(max_length=32, unique=True)# 年龄age = models.IntegerField()class Meta():db_table = 'author'class AuthorDetail(models.Model):# 作者电话phone = models.CharField(max_length=11)# 作者地址addr = models.CharField(max_length=132)# 作者名 绑定外键author_name = models.ForeignKey('Author', on_delete=models.CASCADE, to_field='id', default=1, null=True)class Meta():db_table = 'authordetail'
对外键关系表进行增加操作
import osfrom django.test import TestCase
import datetimeif __name__ == '__main__':os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetimedjango.setup()from app01 import models# author_name内必须是一个Author实例对象,不能直接使用参数内容models.Author.objects.create(name='张三', age=11)detail_id = models.Author.objects.get(id=1)models.AuthorDetail.objects.create(phone='123', addr="北京", author_name=detail_id)
多对多
假设有一张图书表和作者表,两者由第三张表绑定外键关系
class Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=True)# 绑定图书表和作者表,用ManyToManyField自动创建第三张表author = models.ManyToManyField('Author')class Meta():# 不添加的话默认表名app01_bookdb_table = 'book'class Author(models.Model):# 作者名name = models.CharField(max_length=32, unique=True)# 年龄age = models.IntegerField()class Meta():db_table = 'author'
import osfrom django.test import TestCase
import datetimeif __name__ == '__main__':os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetimedjango.setup()from app01 import models# 为作者和图书的多对多的第三张表添加信息author_obj = models.Author.objects.get(id=1)book_obj = models.Book.objects.get(id=1)book_obj.author.add(author_obj)# 删除外键关系'''author_obj = models.Author.objects.get(id=1)book_obj = models.Book.objects.get(id=1)book_obj.author.remove(author_obj)'''# 修改外键关系'''author_obj = models.Author.objects.get(id=2)book_obj = models.Book.objects.get(id=1)book_obj.author.set([author_obj])'''# 清空外键关系'''book_obj = models.Book.objects.get(id=1)book_obj.author.clear()'''
author_obj:获取作者表实例
book_obj:获取图书表实例
book_obj.author.add(author_obj):add内的参数是author表的实例
数据的删除
data = models.user.objects.filter(username="张三").delete()
data = models.user.objects.get(id=9)
data.delete()
修改数据
data = models.user.objects.get(id=10)
data.password=111
data.save()
data = models.user.objects.filter(id=10).update(username="张三")
查询数据
data = models.user.objects.filter(id=3)
print(data.values())
# get不能查询不存在的数据,否则会报错
data = models.user.objects.get(id=1)
查询所有数据
# 查询所有数据
data = models.user.objects.values()
# id=1的所有字段
data = models.user.objects.filter(id=1).values()
# 元组查询,结果只有值没有键
data = models.user.objects.values_list()
data = models.user.objects.filter(id=1).values_list()
去重查询
# 相同的username字段不会被多次查询
data = models.user.objects.values('username').distinct()
print(data)
data = models.user.objects.values('username','password').distinct()
排序查询
# 从小到大
data = models.user.objects.order_by('id').values('id')
# 从大到小
data = models.user.objects.order_by('-id').values('id')
统计
# 统计库中所有数据
data = models.user.objects.values().count()
# 库中名为admin的数量
data = models.user.objects.filter(username="admin").count()
剔除指定数据
# 排除id=1的数据
data = models.user.objects.values().exclude(id=1)
多表查询
假设有user、user2两个模型
# 一对多
data = models.user.objects.select_related('user2').all()
# 多对多
users = User.objects.prefetch_related('user2').all()
示例
创建book(书籍),Publish(出版社),Author(作者),AuthorDetail(作者详情)四个表
import datetimefrom django.db import modelsclass Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=datetime.datetime.now())class Publish(models.Model):# 出版社名name = models.CharField(max_length=32)# 出版社地址addr = models.CharField(max_length=132)# 出版社邮箱email = models.CharField(max_length=32)class Author(models.Model):# 作者名name = models.CharField(max_length=32)# 年龄age = models.IntegerField()class AuthorDetail(models.Model):# 作者电话phone = models.CharField(max_length=11)# 作者地址addr = models.CharField(max_length=132)
# 创建迁移文件
python manage.py makemigrations
python manage.py migrate
一对多:图书与出版社
一个出版社可以有多本图书,但是一本书只能有一个出版社
class Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=datetime.datetime.now())# 绑定出版社外键publish = models.ForeignKey('Publish',on_delete=models.CASCADE,to_field='id',default=1, null=True)
models.ForeignKey('Publish'):与Publish表关联
on_delete=models.CASCADE:指定外键关系(当图书信息被删除时出版社信息也会被删除)
to_field='id',default=1:绑定author表的id主键,并默认为1
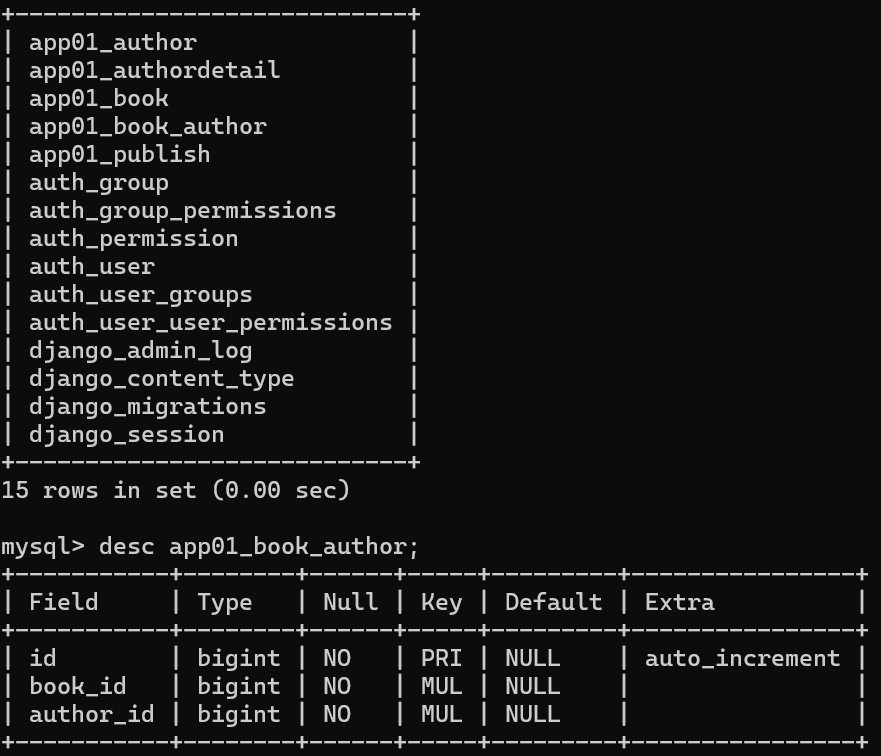
多对多:图书和作者
一本书可以有多个作者,一个作者也可以创作多本书
方式【1】推荐
在Book类中使用ManyToManyField自动创建第三张表
# 绑定图书表和作者表,用ManyToManyField自动创建第三张表
author = models.ManyToManyField('Author')
方式【2】不推荐
手动创建第三张表
class Book_Author(models.Model):book = models.ForeignKey('Book',on_delete=models.CASCADE())author = models.ForeignKey('Author',on_delete=models.CASCADE())
手动制定ManyToManyField参数:
through:绑定的第三张表
through_fields:绑定所需的字段
author = models.ManyToManyField(to='Author',through='Book_Author',through_fields=('book','author'))
校验数据是否存在
data = models.user.objects.filter(id=1).exists()
print(data) # True/False
字段的筛选查询
条件运算
- 大于
gt
data = models.user.objects.filter(id__gt=5)
- 小于
lt
data = models.user.objects.filter(id__lt=5)
- 大于等于
gte
data = models.user.objects.filter(id__gte=5)
- 小于等于
lte
data = models.user.objects.filter(id__lte=5)
- 或
in
data = models.user.objects.filter(id__in=[1, 2, 3])
- 两个条件之间
range
# 顾头顾尾 因此返回id=1,2,3的数据
data = models.user.objects.filter(id__range=[1,3]).values()
- 模糊查询
contains(默认区分大小写)
data = models.user.objects.filter(username__contains='三').values()
- 模糊查询取消大小写限制
icontains
data = models.user.objects.filter(username__icontains='三').values()
- 以指定字符开头/结尾
startswith/endswitch
data = models.user.objects.filter(username__startswith='张').values()
- 过滤指定时间区间
time
# 过滤时间小于当前时间的数据
current_time = datetime.datetime.now()
data = models.user.objects.filter(up_time__lt=current_time).values()
连表查询
对于已经绑定了外键的字段,可以使用连表查询一次查询不同表中的数据
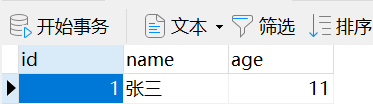

示例中有一个author表和authordetail表,authordetail的author_name_id字段绑定了author的id主键
正向查询
于是便可以通过获取author表中的示例然后.values('authordetail__phone')获取authordetail表中的phone字段,如下:
author_obj = models.Author.objects.filter(name='张三').values('authordetail__phone')
print(author_obj)
反向查询
当要使用没有绑定外键的字段来查询有外键字段的内容时:
author_obj = models.AuthorDetail.objects.filter(author_name__name='张三').values('author_name__name','phone')print(author_obj)
聚合函数(aggregate)
聚合函数需要在分组的情况下使用,并且需要导入Django中内置的聚合模块
from django.db.models import Avg, Sum, Max, Min, Countavg_price = models.Book.objects.aggregate(Avg('price'))
print(avg_price) # 获取书的平均价格
sum_price = models.Book.objects.aggregate(Sum('price'))
print(sum_price) # 获取书的总价
max_price = models.Book.objects.aggregate(Max('price'))
print(max_price) # 获取最贵的书
min_price = models.Book.objects.aggregate(Min('price'))
print(min_price) # 获取最便宜的书
count_price = models.Book.objects.aggregate(Count('price'))
print(count_price) # 获取书的数量
分组查询
查询每本书有几个作者(作者绑定外键)
书
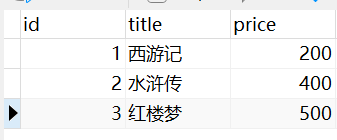
作者
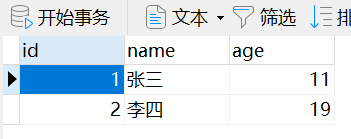
绑定的外键表
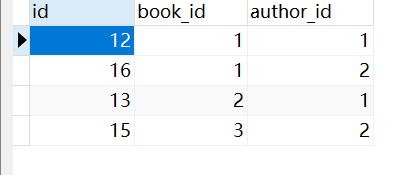
book_obj = models.Book.objects.annotate(a=Count("author")).values('a')
print(book_obj)
# <QuerySet [{'a': 2}, {'a': 1}, {'a': 1}]>
F与Q查询
首先要导入模块
from django.db.models import Count, F, Q, Value
from django.db.models.functions import Concat
F查询
将所有书的价格增加100
# 将所有书的价格增加100
book_obj = models.Book.objects.update(price=F('price')+100)
Q查询
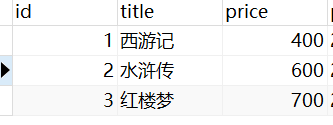
# 原语句
# book_obj = models.Book.objects.filter(price__gt=400,price__lt=700)
# Q语句
book_obj = models.Book.objects.filter(Q(price__gt=400),Q(price__lt=700)
print(book_obj.values('title'))
# <QuerySet [{'title': '水浒传'}]>
获取价格大于400或小于700的数据
book_obj = models.Book.objects.filter(Q(price__gt=400) or Q(price__lt=700))print(book_obj.values('title'))
book_obj = models.Book.objects.filter(Q(price__gt=400) | Q(price__lt=700))print(book_obj.values('title'))
or和|的区别:
- 使用
|运算符时,两个条件都会被考虑,并返回满足任何一个条件的结果 - 使用
or运算符时,只有第一个条件会被返回,不会考虑第二个条件
Django开启事务
from django.db import transaction
try:# 开启事务with transaction.atomic():# 在事务开启前的保存点save_id = transaction.savepoint()# 这部分代码会在事务中执行models.Book.objects.create(title='三国演义',price=1000)transaction.savepoint_commit(save_id)
except Exception as e:# 出错后回滚到save_id开始的地方transaction.savepoint_rollback(save_id)
choices参数
gender_choice 是一个元组列表,用于定义 Author 模型中 gender 字段的选项
class Author(models.Model):gender_choice = ((0,'男'),(1,'女'),(2,'保密'))# 作者名name = models.CharField(max_length=32, unique=True)# 年龄age = models.IntegerField()# 性别gender = models.IntegerField(choices=gender_choice,default=2)
if __name__ == '__main__':os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetimedjango.setup()from app01 import modelsfrom django.db import transactionauthor_obj = models.Author.objects.get(id=1)print(author_obj.gender)# 直接获取得到的是实际值:2print(author_obj.gender_choice)# 获取关联的choice元组:((0, '男'), (1, '女'), (2, '保密'))print(author_obj.get_gender_display())# 获取展示给用户的值:保密
相关文章:
Django模型层(附带test环境)
Django模型层(附带test环境) 目录 Django模型层(附带test环境)连接数据库Django ORM在models.py中建表允许为空指定默认值数据库迁移命令 开启测试环境建表语句补充(更改默认表名)数据的增加时间数据的时区 多表数据的增加一对多多对多 数据的删除修改数据查询数据查询所有数据…...
知识点:神经网络(深度学习)分析)
(AliyunAIACP17)知识点:神经网络(深度学习)分析
摘要: 案,详细阐述了神经网络的实现步骤,并提供了相应的代码示例。此外,文章还涵盖了神经网络中的技巧与实践、性能优化与测试,以及常见问题与解答。最后,对神经网络在深度学习中的应用前景进行了展望。 …...
基于 HBase Phoenix 构建实时数仓(1)—— Hadoop HA 安装部署
目录 一、主机规划 二、环境准备 1. 启动 NTP 时钟同步 2. 修改 hosts 文件 3. 配置所有主机间 ssh 免密 4. 修改用户可打开文件数与进程数(可选) 三、安装 JDK 四、安装部署 Zookeeper 集群 1. 解压、配置环境变量 2. 创建配置文件 3. 创建新…...

XS2185:八通道PSE控制器产品
八通道PSE控制器产品-XS2185 芯片特性 八通道PSE 支持标准PD供电 支持非标PD供电 每个端口功率最大30W 12位端口电流监测 12位电源电压监测 支持直流负载断开检测 支持LED供电状态指示 支持过流保护 支持短路保护 Sifos基本测试通过 32-PIN…...

Selenium WebDriver API 中涉及的一些常用方法和类
Selenium WebDriver API 是 Selenium 提供的一组方法和类,用于控制浏览器和操作 Web 元素。这些 API 提供了丰富的功能,包括但不限于: 1. **查找元素**:通过不同的定位方式(如ID、Class Name、XPath等)在页…...

OJ_复数集合
题干 C实现 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <queue> #include <string> using namespace std;struct Complex {int re;int im;//构造函数Complex(int _re, int _im) {//注意参数名字必须不同re _re;im _im;} };//结构体不支…...
文档)
【学一点RISC-V】ACLINT(高级核心本地中断控制器)文档
RISCV架构 ACLINT文档 ACLINT原文档:https://github.com/riscv/riscv-aclint/blob/main/riscv-aclint.adoc 在这里进行了翻译以及校对,仅供参考,不正确的地方欢迎指出 1、介绍 【此 RISC-V ACLINT 规范定义了一组内存映射设备,这…...
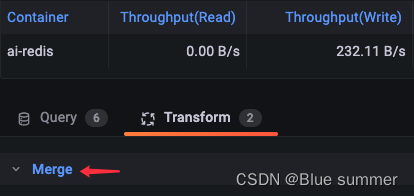
grafana table合并查询
注:本文基于Grafana v9.2.8编写 1 问题 默认情况下table展示的是一个查询返回的多个field,但是我想要的数据在不同的metric上,比如我需要显示某个pod的读写IO,但是读和写这两个指标存在于两个不同的metirc,需要分别查…...

编程笔记 html5cssjs 007 文章排版 颜真卿《述张长史笔法十二意》
编程笔记 html5&css&js 007 文章排版 颜真卿《述张长史笔法十二意》 一、代码二、解释 这段代码定义了一个古文展示页面的结构和样式,同时本文内容也是书法爱好者的珍贵资料。 一、代码 <!DOCTYPE html> <html lang"zh-CN"> <hea…...

Yolov8模型用torch_pruning剪枝
目录 🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀 原理 遍历所有分组 高级剪枝器 🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀…...
C++字符串操作【超详细】
零.前言 本文将重点围绕C的字符串来展开描述。 其中,对于C/C中字符串的一些区别也做出了回答,并对于C的(string库)进行了讲解,最后我们给出字符串的不同表达形式。 开发环境: VS2022 一.字符串常量跟字…...

Ps:画笔工具
画笔工具 Brush Tool是 Photoshop 中最常用的工具,可广泛地用于绘画与修饰工作之中。 快捷键:B ◆ ◆ ◆ 常用操作方法与技巧 1、熟练掌握画笔工具的操作对于使用其他工具也非常有益,因为 Photoshop 中许多与笔刷相关的工具有类似的选项和操…...
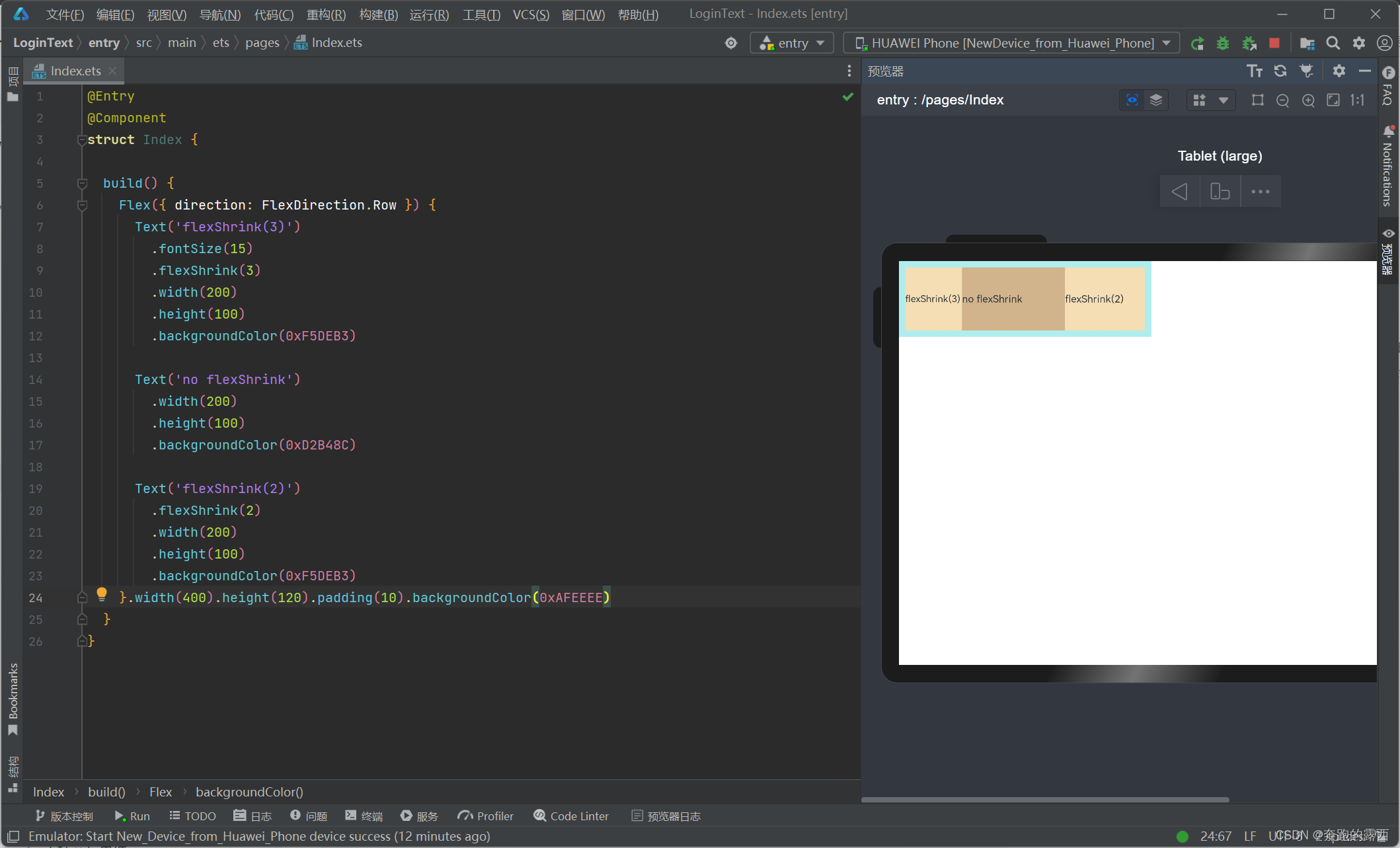
【鸿蒙 HarmonyOS 4.0】弹性布局(Flex)
一、介绍 弹性布局(Flex)提供更加有效的方式对容器中的子元素进行排列、对齐和分配剩余空间。容器默认存在主轴与交叉轴,子元素默认沿主轴排列,子元素在主轴方向的尺寸称为主轴尺寸,在交叉轴方向的尺寸称为交叉轴尺寸…...

Java 客户端向服务端上传文件(TCP通信)
一、实验内容 编写一个客户端向服务端上传文件的程序,要求使用TCP通信的的知识,完成将本地机器输入的路径下的文件上传到D盘中名称为upload的文件夹中。并把客户端的IP地址加上count标识作为上传后文件的文件名,即IP(count&#…...
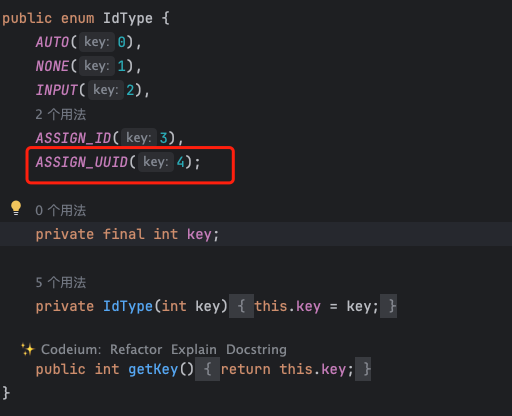
问题:前端获取long型数值精度丢失,后面几位都为0
文章目录 问题分析解决 问题 通过接口获取到的数据和 Postman 获取到的数据不一样,仔细看 data 的第17位之后 分析 该字段类型是long类型问题:前端接收到数据后,发现精度丢失,当返回的结果超过17位的时候,后面的全…...

Day26:安全开发-PHP应用模版引用Smarty渲染MVC模型数据联动RCE安全
目录 新闻列表 自写模版引用 Smarty模版引用 代码RCE安全测试 思维导图 PHP知识点: 功能:新闻列表,会员中心,资源下载,留言版,后台模块,模版引用,框架开发等 技术:输…...
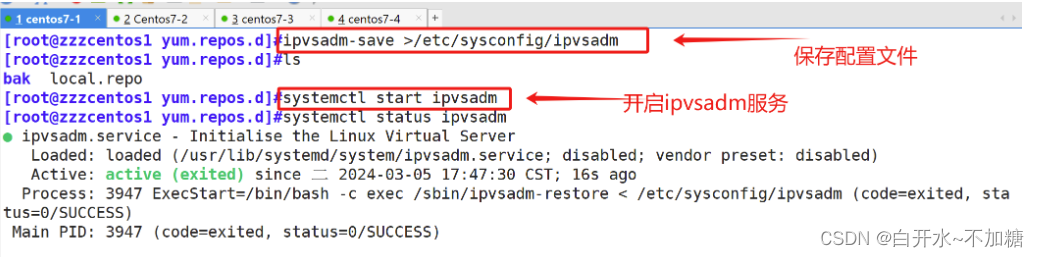
LVS集群(Linux Virtual server)介绍----及LVS的NAT模式部署(一)
群集的含义 ●Cluster,集群、群集由多台主机构成,但对外只表现为一个整体,只提供访问入口(域名或IP地址),相当于一台大型计算机 问题: 互联网应用中,随着站点对硬件性能、响应速度、服务稳定性、数据可靠…...

海外媒体宣发套餐如何利用3种方式洞察市场-华媒舍
在当今数字化时代,媒体宣发成为了企业推广产品和品牌的重要手段之一。其中,7FT媒体宣发套餐是一种常用而有效的宣传方式。本文将介绍这种媒体宣发套餐,以及如何利用它来洞察市场。 一、关键概念 在深入讨论7FT媒体宣发套餐之前,让…...

开发知识点-Apache Struts2框架
Apache Struts2 介绍S2-001S2CVE-2023-22530 介绍 Apache Struts2是一个基于MVC(模型-视图-控制器)设计模式的Web应用程序框架,它是Apache旗下的一个开源项目,并且是Struts1的下一代产品。Struts2是在Struts1和WebWork的技术基础…...

【Spring高级】第3讲 Bean的生命周期
目录 基本的生命周期后处理器总结 基本的生命周期 为了演示生命周期的过程,我们直接使用 SpringApplication.run()方法,他会直接诶返回一个容器对象。 import org.springframework.boot.SpringApplication; import org.springframework.context.Config…...

WechatDecrypt:3步解锁你的加密微信聊天记录
WechatDecrypt:3步解锁你的加密微信聊天记录 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 你是否曾因误删重要聊天记录而懊恼?是否想备份珍贵对话却无从下手?微信聊天…...
从《黑神话:悟空》到独立游戏:聊聊Avatar肌肉设置如何塑造角色个性走姿
从《黑神话:悟空》到独立游戏:如何用Avatar肌肉参数打造角色灵魂步态 在《黑神话:悟空》的实机演示中,主角一个转身抖落披风的动作让全网沸腾——这不仅是美术的胜利,更是动画系统的精妙设计。当大多数独立游戏还在使用…...
)
告别鼠标!用AutoHotKey一键搞定音量调节(附开机自启设置)
解放双手:用AutoHotKey打造专业级音量控制方案 在视频剪辑、远程会议或深夜观影时,频繁伸手去够物理音量键不仅打断工作流,还影响沉浸感。AutoHotKey(AHK)作为Windows平台的自动化神器,能让我们用键盘组合键…...

AI技术带来的SEO关键词优化新方向与应用探索
AI技术的快速发展正在为SEO关键词优化带来全新思维。通过智能化的数据处理和分析,营销人员能够获取到精准的关键词推荐,这使得选择高效关键词变得更加灵活与高效。在此基础上,AI还能够实时监测用户行为变化和市场动态,动态调整关键…...

欧姆龙CP系列项目级PLC程序模板:即拿即用,地址分配明确,逻辑已验证
欧姆龙PLC程序 欧姆龙CP系列项目级PLC程序模板,拿过来可以直接做项目,逻辑关系很多项目验证过,只需要加进去工艺流程即可,各地址分配明确;有专用的CP系列地址分配表做参考;对欧姆龙PLC学习和提高有很大的帮…...

打破平台壁垒:WorkshopDL如何让非Steam玩家也能畅享创意工坊模组
打破平台壁垒:WorkshopDL如何让非Steam玩家也能畅享创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 想象一下这个场景:你在GOG平台购买了一…...

构建高性能HDF5数据可视化架构:ViTables模块化设计指南
构建高性能HDF5数据可视化架构:ViTables模块化设计指南 【免费下载链接】ViTables ViTables, a GUI for PyTables 项目地址: https://gitcode.com/gh_mirrors/vi/ViTables 在科学计算和大数据时代,HDF5格式已成为存储复杂结构化数据的行业标准&am…...

Visual Syslog Server终极指南:Windows免费日志监控神器快速上手
Visual Syslog Server终极指南:Windows免费日志监控神器快速上手 【免费下载链接】visualsyslog Syslog Server for Windows with a graphical user interface 项目地址: https://gitcode.com/gh_mirrors/vi/visualsyslog 还在为网络设备日志分散、管理混乱而…...

实战深度解析:Armbian系统在Amlogic S912等芯片上的完整移植指南
实战深度解析:Armbian系统在Amlogic S912等芯片上的完整移植指南 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l…...

PMP认证备考全攻略:费用、周期与机构选择常见问题解答
PMP(项目管理专业人士)认证作为项目管理领域的“黄金标准”,近年来在国内职场的热度持续走高。对于想要系统提升项目管理能力或获取资质背书的职场人来说,报考前往往会有诸多疑问。针对大家最关心的费用投入、备考周期以及如何选择…...