Linux上安装torch-geometric(pyg)1.7.2踩坑记录
重点:1.一定要在创建虚拟环境的时候设置好python版本。2.一定要先确定使用1.X还是2.X的pyg库,二者不兼容。3.一定要将cuda、torch、pyg之间的版本对应好。所以,先确定pyg版本,再确定torch和cuda的版本。
结论:如果在ubuntu上安装python=3.7,torch=1.7.0,cuda=11.0,pyg=1.7.2,只用四行代码。
1)创建虚拟环境conda create -n <evn name> python==3.7
2)安装torch、torchvision、torchaudio、cudatoolkit
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0
3)安装scatter、sparse、cluster、spline_conv
pip install torch_scatter-2.0.5-cp37-cp37m-linux_x86_64.whl torch_sparse-0.6.8-cp37-cp37m-linux_x86_64.whl torch_cluster-1.5.8-cp37-cp37m-linux_x86_64.whl torch_spline_conv-1.2.0-cp37-cp37m-linux_x86_64.whl
4)安装pyg,如果要安装2.X版本的可以不加版本号
pip install torch-geometric==1.7.2
-----------------------------手动分割线,下面内容分析了怎么老是安装出错,下次再安装的时候来看看,内容有点乱----------------------------------
安装torch-geometric(pyg)的坑
踩坑一:无需自行安装CUDA,安装torch-gpu时,安装相应的cudatoolkit就可以了。所以nvcc -V找不到cuda版本时没关系。
踩坑二:没有先确定pyg的版本。还有就是pip install torch-geometric的时候没有加上版本号。这两种情况都会报错 RuntimeError: The ‘data’ object was created by an older version of PyG. If this error occurred while loading an already existing dataset, remove the ‘processed/’ directory in the dataset’s root folder and try again.
原因是跑人家的代码中pyg版本与你安装的版本不匹配,看一下别人的代码有没有说明pyg的版本。pip install torch-geometric安装的是2.X版本的。所以要先确定安装1.X还是2.X的torch-geometric。比如,你跑别人的代码别人用的是1.X的pyg,而你自己下载的是2.X版本的pyg,就会报上面的错误。也可以不降低pyg版本,对data进行修改
踩坑三:RuntimeError: CUDA error: no kernel image is available for execution on the device.
原因是显卡和CUDA算力不匹配。第一次配环境的时候随便装了一个版本cudatoolkit=10.2,我的显卡的算力是80,cuda10.2最大算力是75,所以报下面的错误。
点这里查看显卡算力,点这里查看CUDA算力

报错的意思是当前GPU的算力与当前版本Pytorch依赖的CUDA算力不匹配(A100算力为8.0,而当前版本的pytorch依赖的CUDA算力仅支持3.7,5.0,6.0,7.0, 7.5)
那么怎么确定安装哪个版本的cuda?
nvidia-smi先看一下自己显卡支持的最大cuda版本(安装的cudatoolkit<=右上角的CUDA Version即可,但是这里还有个坑,目前还是不能确定到底用哪个版本的cuda),我的cuda最高版本不能超过11.4,但是如果觉得最高版本也太低的话,可以去下载新的驱动。

再参考下面这张表,比如我的显卡的算力是80,所以我安装的11.0<= cudatoolkit <=11.4
确定python、pyg、pytorch、cuda版本对应的思路
安装pyg之前要确定好python、pyg、pytorch、cuda的版本。我已经确定了python=3.7,pyg=1.X,11.0<=cuda<=11.4。
然后这四个网址要来回看。
地址1:pytorch历史版本对应
地址2:pytorch的wheel文件下载地址
地址3:pyg依赖包的wheel文件下载地址
地址4:pyg官方文档
- step1:已经确定了pyg是1.X,去地址4找一下torch和cuda对应的版本。
这有pyg的各种版本。(地址4点进去之后左下角绿色的地方,可以点开所有1.X版本的都看看)
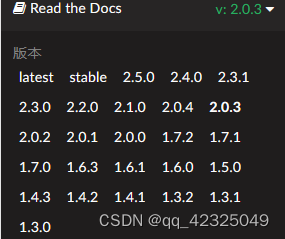
下面是1.7.2版本的pyg官方文档,要求python<3.9(我的python3.7,满足要求)

CUDA version包括(cpu、cu92、cu101、cu102、cu110、cu111)
1.4.0<= torch <= 1.9.0
所以11.0<= cudatoolkit <=11.1,对于我的显卡,cuda的版本只能选择110或者111,现在就又缩小了cuda的范围。然后确定torch的版本。
-
step2:点地址2查看torch的版本

cuda=110的话,torch只有1.7.0和1.7.1
cuda=111的话,torch从1.8.0到1.10.1都有(没放图,可以点地址2看一下)
所以:torch=1.7.0/1.7.1-cu110 或者 1.8.0<=torch<=1.10.1 -cu111 -
step3:安装pyg之前,还要安装pyg的四个依赖包scatter、sparse、cluster、spline_conv,但是对我来说安装wheel文件最好用,比较推荐wheel安装pyg的依赖包。
点开地址3看一下有没有torch-cu110=1.7.0/1.7.1 或者 1.8.0<=torch-cu111<=1.10.1的组合,这里面都是pyg依赖包的wheel文件。(点进去之后可以看到要安装pyg的依赖包要求torch最低是1.4)有torch-1.7.0/1.7.1-cu110 也有torch-1.8.0<=torch<=1.10.1 -cu111,所以可以安装torch=1.70,cuda=11.0。

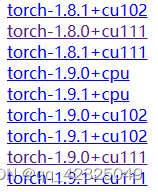

安装pyg只需四行代码
- 首先新建虚拟环境,加上python版本
conda create -n <evn name> python==3.7 - 安装torch-1.7.0+cu110
方法一:pytorch官网安装
进入地址1找到cuda=11.0对应的torch、torchvision和torchaudio版本。
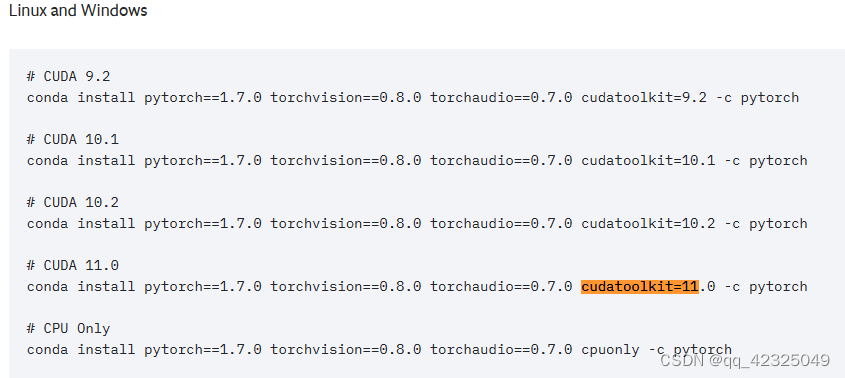
不要加-c pytorch,否则有可能是cpu版本的torch,而且安装得会快一点。
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0
方法二:如果conda安装不了这几个包的话,点地址2找到这几个包对应的版本下载其wheel文件。然后在终端进入下载的文件夹内,pip install XXX.whl
我用的方法一,发现torchaudio不是gpu版本的,然后去地址2也找了一下,确实没有torchaudio-cu110,不过不影响我跑代码,不知道后面会不会有问题。

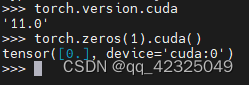
测试torch-gpu是否安装成功,true说明安装成功,cuda可用,cuda的版本是11.0,torch的版本是1.7.0+cu110。(安装了cudatoolkit,所以不用自己安装CUDA。)

- 安装pyg的四个依赖包
点地址3进入torch-1.7.0+cu110

进入之后在这个页面里下载cp37-linux(python、OS根据自己情况选择)的scatter、sparse、cluster、spline_conv这四个wheel文件。

终端进入下载好的wheel的文件夹里,pip安装。
pip install torch_scatter-2.0.5-cp37-cp37m-linux_x86_64.whl torch_sparse-0.6.8-cp37-cp37m-linux_x86_64.whl torch_cluster-1.5.8-cp37-cp37m-linux_x86_64.whl torch_spline_conv-1.2.0-cp37-cp37m-linux_x86_64.whl - 安装pyg=1.7.2,一定要加上版本号,否则默认安装2.X,当然也可以安装2.X版本,只不过要和torch、cuda、python版本要对应好。
pip install torch-geometric==1.7.2(会自动安装依赖scikit-learn pandas networkx)
测试:没报错就说明安装pyg成功了

相关文章:
Linux上安装torch-geometric(pyg)1.7.2踩坑记录
重点:1.一定要在创建虚拟环境的时候设置好python版本。2.一定要先确定使用1.X还是2.X的pyg库,二者不兼容。3.一定要将cuda、torch、pyg之间的版本对应好。所以,先确定pyg版本,再确定torch和cuda的版本。 结论:如果在u…...
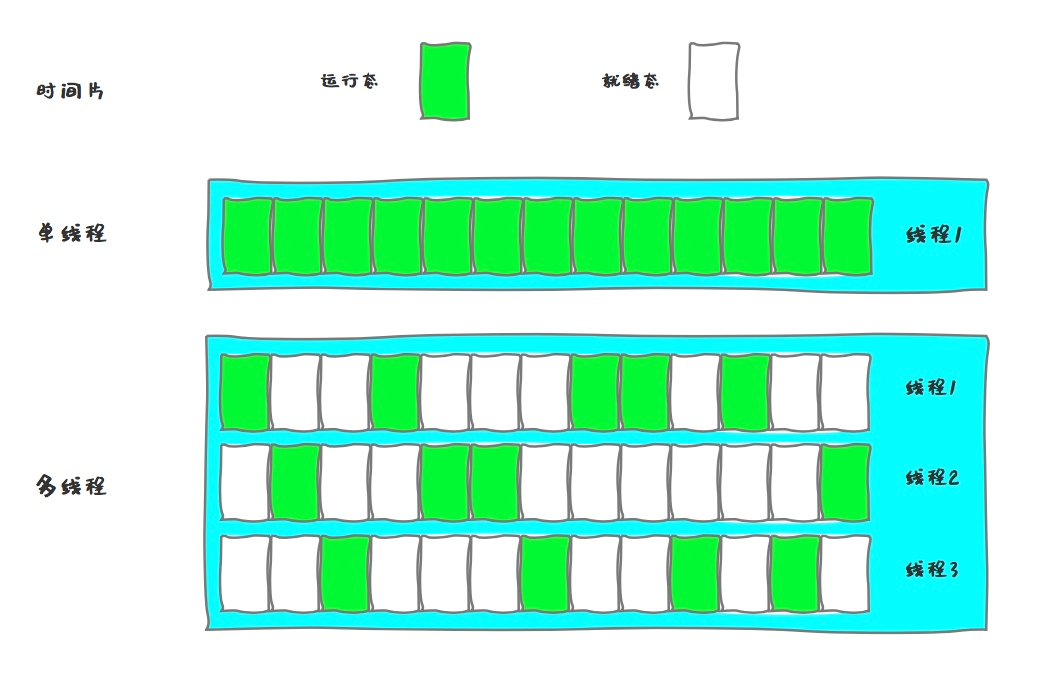
线程有几种状态,状态之间的流转是怎样的?
Java中线程的状态分为6种: 1.初始(NEW):新创建了一个线程对象,但还没有调用start()方法。 2.运行(RUNNABLE):Java线程中将就绪(READY)和运行中(RUNNING)两种状态笼统的称为“运行”…...
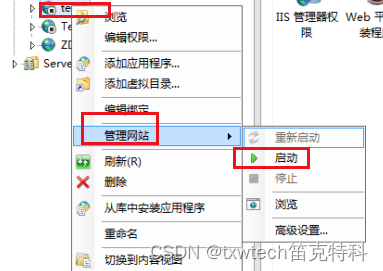
vs创建asp.net core webapi发布到ISS服务器
打开服务器创建test123文件夹,并设置共享。 ISS配置信息: 邮件网站,添加网站 webapi asp.net core发布到ISS服务器网页无法打开解决方法 点击ISS Express测试,可以成功打开网页。 点击生成,发布到服务器 找到服务器IP…...

【解读】OWASP大语言模型应用程序十大风险
OWASP大型语言模型应用程序前十名项目旨在教育开发人员、设计师、架构师、经理和组织在部署和管理大型语言模型(LLM)时的潜在安全风险。该项目提供了LLM应用程序中常见的十大最关键漏洞的列表,强调了它们的潜在影响、易利用性和在现实应用程序…...

LLM实施的五个阶段
原文地址:Five Stages Of LLM Implementation 大型语言模型显着提高了对话式人工智能系统的能力,实现了更自然和上下文感知的交互。这导致各个行业越来越多地采用人工智能驱动的聊天机器人和虚拟助手。 2024 年 2 月 20 日 介绍 从LLMs的市场采用情况可以…...
——初识篇)
C++学习随笔(1)——初识篇
前面一章我们简单介绍了一下C与C语言之间的关系,本章就让我们来正式入门学习一下C吧! 目录 1.第一个C程序 2.头文件 (1)简介 (2)常见的头文件: 2. 命名空间 2.1 命名空间定义 2.2 命名空…...
线上应用部署了两台load为1四核服务器
线上应用部署了两台服务器。 项目发布后,我对线上服务器的性能进行了跟踪,发现一台负载为3,另一台负载为1,其中一台四核服务器已经快到瓶颈了,所以我们紧急排查原因。 1、使用TOP命令查看占用CPU较大的负载和进程&…...

GPT实战系列-LangChain如何构建基通义千问的多工具链
GPT实战系列-LangChain如何构建基通义千问的多工具链 LLM大模型: GPT实战系列-探究GPT等大模型的文本生成 GPT实战系列-Baichuan2等大模型的计算精度与量化 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF GPT实…...
【vue2基础教程】vue指令
文章目录 前言一、内容渲染指令1.1 v-text1.2 v-html1.3 v-show1.4 v-if1.5 v-else 与 v-else-if 二、事件绑定指令三、属性绑定指令总结 前言 Vue.js 是一款流行的 JavaScript 框架,广泛应用于构建交互性强、响应速度快的现代 Web 应用程序。Vue 指令是 Vue.js 中…...
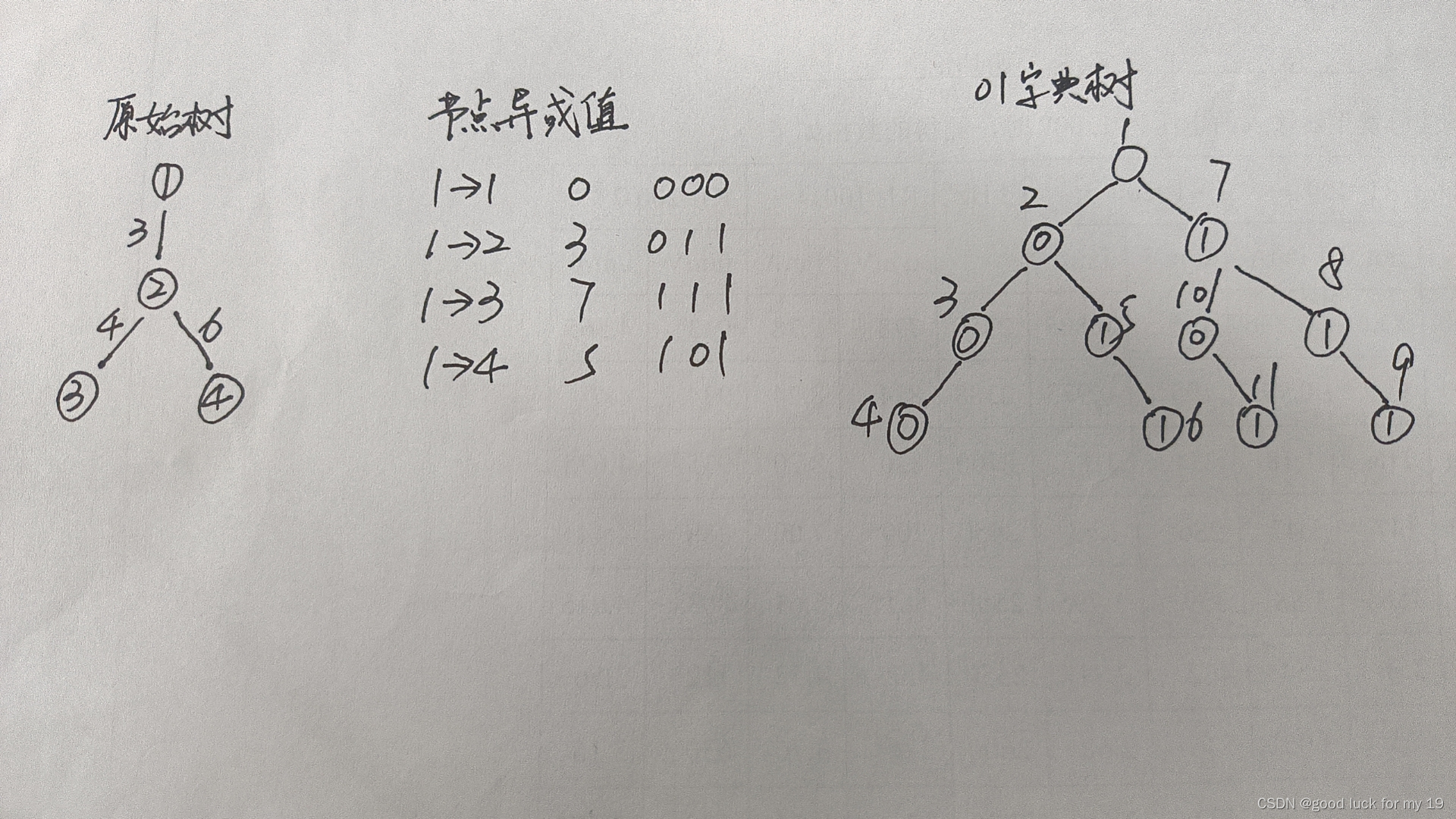
P4551 最长异或路径
最长异或路径 题目描述 给定一棵 n n n 个点的带权树,结点下标从 1 1 1 开始到 n n n。寻找树中找两个结点,求最长的异或路径。 异或路径指的是指两个结点之间唯一路径上的所有边权的异或。 输入格式 第一行一个整数 n n n,表示点数…...
鸿蒙OpenHarmony HDF 驱动开发
目录 序一、概述二、HDF驱动框架三、驱动程序四、驱动配置坚持就有收获 序 最近忙于适配OpenHarmonyOS LiteOS-M 平台,已经成功实践适配平台GD32F407、STM32F407、STM32G474板卡,LiteOS适配已经算是有实际经验了。 但是,鸿蒙代码学习进度慢下…...

深度学习:如何面对隐私和安全方面的挑战
深度学习技术的广泛应用推动了人工智能的快速发展,但同时也引发了关于隐私和安全的深层次担忧。如何在保护用户隐私的同时实现高效的模型训练和推理,是深度学习领域亟待解决的问题。差分隐私、联邦学习等技术的出现,为这一挑战提供了可能的解…...
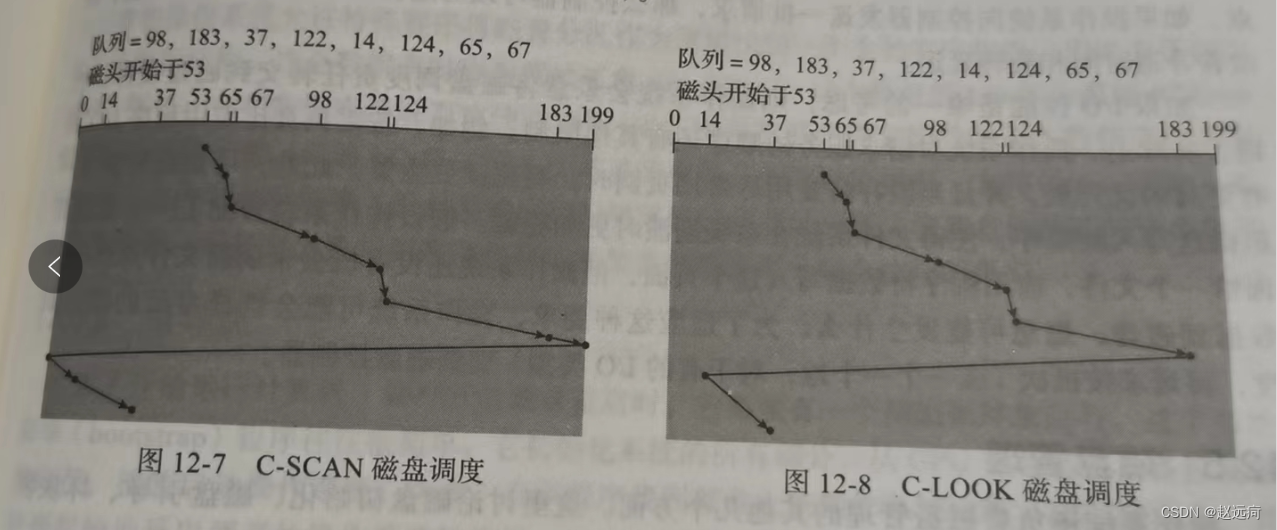
【操作系统概念】第12章:大容量存储阶段
文章目录 0.前言12.1 概述12.2磁盘结构12.3 磁盘调度12.3.1 FCFS调度12.3.2 SSTF调度12.3.3 SCAN调度12.3.4 C-SCAN调度12.3.5 如何选择磁盘调度 0.前言 文件系统从逻辑上来看包括三部分。第10章讨论了文件系统的用户和程序员的接口。第11章描述了操作系统实现这种接口的内部数…...
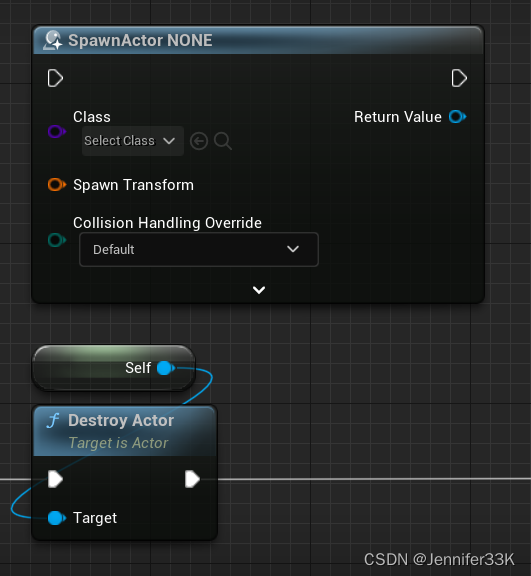
UE5.1_使用技巧(常更)
UE5.1_使用技巧(常更) 1. 清除所有断点 运行时忘记蓝图中的断点可能会出现运行错误的可能,务必运行是排除一切断点,逐个排查也是办法,但是在事件函数多的情况下会很复杂且慢节奏,学会一次性清除所有很有必…...

rust开发100问?
Rust如何管理内存?Rust的所有权是什么?生命周期在Rust中如何工作?什么是借用在Rust中?如何在Rust中创建枚举类型?Rust中的trait是什么?如何定义并实现一个结构体(struct)的方法&…...
.net6Api后台+uniapp导出Excel
之前的这个是vue3写法,后端是.net6Api.net6Api后台VUE3前端实现上传和下载文件全过程_vue3 下载文件-CSDN博客 在现在看来似乎搞的复杂了,本次记录一下.net6Api后台uniapp导出Excel。 后端和之前的不一样,前端也和之前的不一样,…...

【OD】算法二
开源项目热度榜单 某个开源社区希望将最近热度比较高的开源项目出一个榜单,推荐给社区里面的开发者。对于每个开源项目,开发者可以进行关注(watch)、收藏(star)、fork、提issue、提交合并请求(MR)等。 数据库里面统计了每个开源项目关注、收藏、fork、…...
《深度学习风暴:掀起智能革命的浪潮》
在当今信息时代,深度学习已经成为科技领域的一股强大力量,其应用领域涵盖了从医疗到金融再到智能交互等方方面面。随着技术的不断进步和应用的不断拓展,深度学习的发展势头愈发迅猛,掀起了一股智能革命的浪潮。本文将从基本原理、应用实例、挑战与未来发展方向、与机器学习…...
Arduin ESP32+epaper(电子墨水屏)时钟相册制作教程
Arduin ESP32 epaper(电子墨水屏)时钟相册制作教程 🔖epaper(电子墨水屏)采用的是:合宙1.54“ 电子墨水屏(e-paper)📍相关篇《Arduino框架下ESP32/ESP8266合宙1.54“ 电子墨水屏(e-paper)驱动显…...
Django模型层(附带test环境)
Django模型层(附带test环境) 目录 Django模型层(附带test环境)连接数据库Django ORM在models.py中建表允许为空指定默认值数据库迁移命令 开启测试环境建表语句补充(更改默认表名)数据的增加时间数据的时区 多表数据的增加一对多多对多 数据的删除修改数据查询数据查询所有数据…...

从零到一:Anaconda与PyCharm联手打造专属Python虚拟环境
1. 为什么需要Python虚拟环境? 刚接触Python开发时,我最常遇到的困惑就是:为什么明明在A项目能运行的代码,放到B项目就报错?后来才发现是因为两个项目依赖的库版本不同。比如项目A需要numpy 1.20,而项目B需…...
)
Vue项目实战:用3d-force-graph和Neo4j打造炫酷的3D知识图谱(附完整代码)
Vue与Neo4j深度整合:构建高性能3D知识图谱的工程实践 知识图谱作为结构化知识的表现形式,正在成为企业知识管理和智能应用的核心基础设施。本文将深入探讨如何利用Vue.js前端框架与Neo4j图数据库,结合3d-force-graph可视化库,构建…...

DeepSeek-R1-Distill-Qwen-1.5B快速部署:vLLM启动,GPU显存优化方案
DeepSeek-R1-Distill-Qwen-1.5B快速部署:vLLM启动与GPU显存优化方案 1. 模型与框架介绍 1.1 DeepSeek-R1-Distill-Qwen-1.5B模型特点 DeepSeek-R1-Distill-Qwen-1.5B是DeepSeek团队基于Qwen2.5-Math-1.5B基础模型,通过知识蒸馏技术融合R1架构优势打造…...

从踩坑到精通:Element el-date-picker 与后端 API 联调的那些‘坑’和最佳实践
从踩坑到精通:Element el-date-picker 与后端 API 联调实战指南 在前后端分离的开发模式中,日期选择器作为高频交互组件,其与后端的数据对接往往成为初级开发者的"隐形杀手"。Element UI 的 el-date-picker 组件虽然功能强大&#…...

低查重AI教材生成工具,开启AI教材写作的高效新时代!
教材的格式问题是每位编写者都无法避免的烦恼。比如,标题字号需要几号、层级如何划分?参考文献是遵循GB/T7714标准,还是各出版机构的特定要求?习题的排版是选择单栏还是双栏?面临各种规定,让人感到眼花缭乱…...

android 14.0 framework下service下引用 opt目录下相关类编译不过的功能实现
1.前言 在14.0的系统rom定制化开发中,在某些产品中,对于在service下引用framewroks/opt下面的类 比如GsmSMSDispatcher类等,会出现找不到文件类的问题,接下来分析下相关问题的原因,然后 解决这个问题 2.framework下service下引用 opt目录下相关类编译不过的功能实现的核…...

SEONIB 如何重新定义电商卖家的全球增长路径
一个普遍存在的认知误区及其现实后果 在当前的数字商业环境中,存在一个广泛流传但极具误导性的观点,即搜索引擎优化是一项仅适用于大型企业或拥有专门技术团队的复杂工程。这种认知导致无数电商卖家——无论是独立站运营者、平台卖家,还是新…...

OmenSuperHub完整指南:三步彻底掌控惠普游戏本性能与散热
OmenSuperHub完整指南:三步彻底掌控惠普游戏本性能与散热 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN游戏…...

从PWM到BCM:深入浅出讲解HUB75 LED屏如何实现256级灰度与全彩动画
从PWM到BCM:HUB75 LED屏的256级灰度与全彩动画实现指南 当你在深夜调试HUB75 LED屏时,是否遇到过这样的困境:明明代码逻辑正确,屏幕却只能显示几种基础颜色,动画效果更是惨不忍睹?这不是你的技术问题&…...

3步重塑下载体验:开源工具如何彻底解放城通网盘限速困境
3步重塑下载体验:开源工具如何彻底解放城通网盘限速困境 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾因城通网盘那令人绝望的下载速度而放弃重要资源?面对几十KB/s的…...